一种面向NTFS的海量小文件高速读写方法
2022-04-22彭涵钧黄传波胡晓勤
彭涵钧,黄传波,涂 磊,胡晓勤
(1.四川大学网络空间安全学院,成都 610200;2.成都云祺科技有限公司,成都 610041)
0 引言
随着信息技术的不断发展,社交平台、电商等数据密集型应用的普及,数据量呈爆炸式增长。其中,最常用的数据为图片、日志和电子邮件等小于1MB的小文件。目前的文件系统大多是针对大文件设计,其元数据管理机制、数据存储机制以及缓存机制在处理小文件时效率会大幅下降,海量小文件问题已成为工业界和学术界共同的难题。
目前,学者主要针对HDFS等分布式文件系统的海量小文件读写性能进行了优化,并没有很好的方法解决本地文件系统上的海量小文件问题。NTFS是Windows环境下主流的本地文件系统,在Windows 2000及以上版本的操作系统中,分区文件系统默认格式化为NTFS。因其具有安全性高、可靠性强、高效、文件碎片少等特点,已经取代了Windows98的FAT32文件系统。本文提出了一种面向NTFS的海量小文件高速读写方法。
1 NTFS系统结构
NTFS系统结构如图1所示,其主要结构为卷,一个NTFS卷由文件组成,文件分为元文件和用户文件。其中,元文件是隐藏的系统文件,用户不能直接对元文件进行访问,是NTFS文件系统中最重要的部分。除根目录外,元文件的文件名均以“$”符号开头。除$Boot文件固定在第0簇外,NTFS中其他文件的位置都是不固定的。在本文提出的方法中,主要对$Boot和$MFT进行了解析。
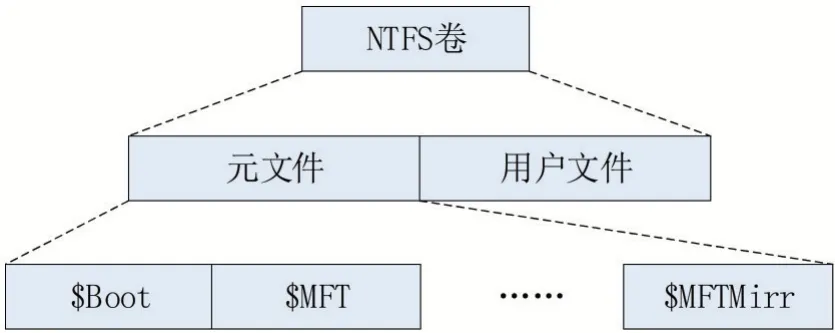
图1 NTFS系统结构
$Boot文件是用于系统启动的元文件,该文件的数据流指向卷的启动扇区,包含有卷大小、簇大小、扇区大小等文件系统基本信息,其位置固定在卷中的第0簇。
NTFS中的每个文件都有一个或多个文件记录来记录文件数据的位置以及文件的其他信息,$MFT文件是NTFS中所有文件记录的集合。每个文件记录都有其序号,又称文件记录号。文件记录号从0开始,第0号文件记录是基本文件记录,是整个文件记录自身的文件记录,通过解析基本文件记录可以获取全部文件记录在磁盘上的位置。
文件记录由文件记录头和属性列表组成。文件记录头保存文件记录大小等一些基本信息并指向属性列表中的入口;属性列表由一个个属性组成,属性是保存文件特征信息的数据结构,例如要获得文件数据在磁盘上的位置,需要查找文件记录中的80属性。常见属性的描述如下。
a)30属性:存放文件名。
b)80属性:数据文件专用,存放或指向文件数据。
c)90属性:目录文件专用,存放目录项。
d)A0属性:目录文件专用,90属性的扩展属性,存放索引节点的位置。
e)B0属性:位图属性。基本文件记录中,B0属性用于记录每个文件记录的使用情况;在目录文件的文件记录中,B0属性用于记录每个索引节点的使用情况。
2 海量小文件读写方法
本文提出的NTFS海量小文件读写方法由采集模块、定位模块、提取模块和写入模块四部分组成。采集模块读磁盘获取其他模块所需的数据后,定位模块根据目录路径定位目录的文件记录,提取模块通过解析文件记录指向的目录项结构得到目录下的文件列表并将每个文件的文件记录号推入写队列,队列中每个文件记录号出队后进入写入模块,写入模块访问内存中采集模块预读的数据,向文件系统发送写指令,将数据写入指定位置。方法的模块结构如图2所示,采集模块、定位模块、提取模块模拟了NTFS的读操作,最后由写入模块通过系统调用实现写操作。
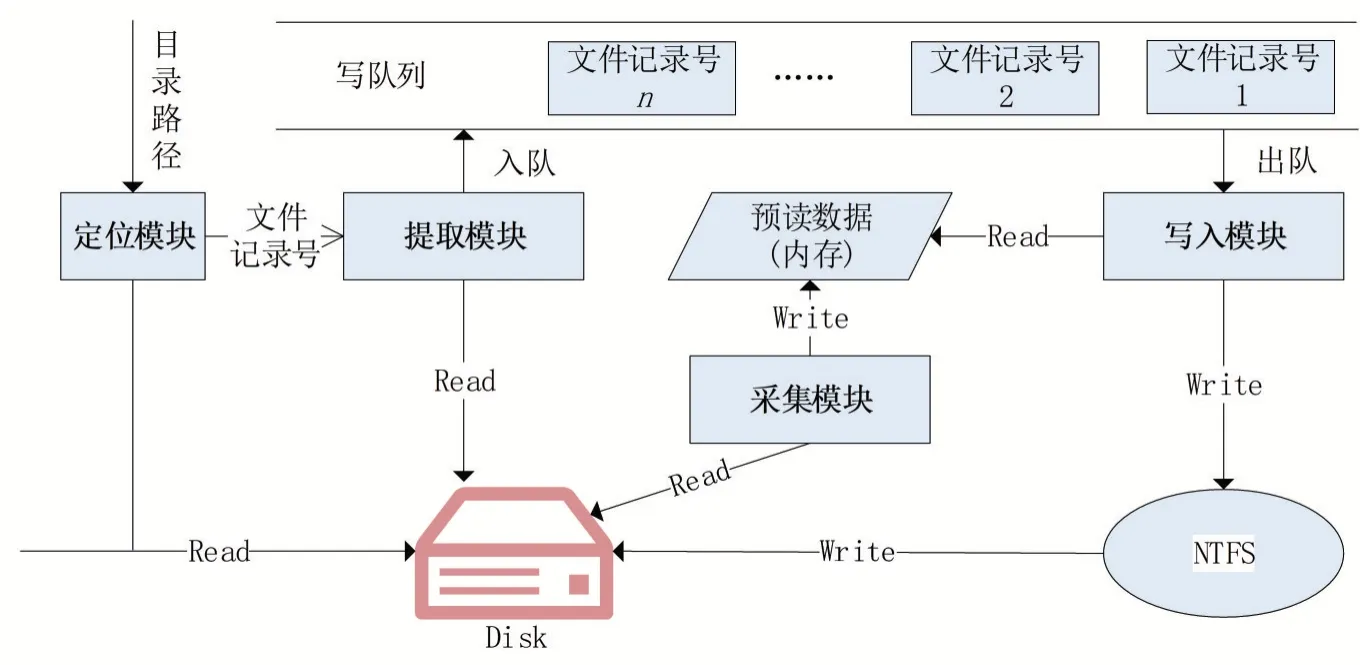
图2 NTFS海量小文件读写方法结构
2.1 采集模块
采集模块具有四个功能。
(1)采集文件系统基本信息。采集模块通过读起始扇区,解析$Boot文件的结构,获取文件系统基本信息。$Boot文件中部分偏移量的含义如表1所示。其中,每个扇区的字节数、每个簇的扇区数、每个文件记录的簇数和每个索引记录的簇数是文件系统存储单元的基本信息,对这部分信息的采集是模拟文件系统读操作的必要条件。

表1 $Boot偏移量含义
(2)定位文件记录。定位是预读的前提。$Boot文件中偏移量为0x30的数据为$MFT起始簇号,采集模块据此访问$MFT起始位置,也就是基本文件记录。通过解析基本文件记录的80属性,定位整个$MFT文件在磁盘上的位置。
(3)预读文件记录。写入模块接收写队列中的文件记录号后需要读取对应的文件记录,单个文件记录的大小通常为1 KB,通过预读机制可以大幅提升后续文件记录的访问效率。采集模块定位文件记录后,将文件记录拆分成若干个段。在写入模块需要访问文件记录时,从磁盘中将其所在的整个文件记录段读入内存,在接收到段内其他文件记录号时,写入模块可以直接访问文件记录。采集模块在内存中开辟若干块的空间用于存放文件记录段,并采用LRU(least recently used,最近最少使用)算法实现文件记录段的置换。每个文件记录段维护一个计时器,每当写入模块处理完一个文件记录号后,其所在的文件记录段计时器不变,内存中其他文件记录段的计时器加1,当需要进行置换时,优先置换计时器值大的文件记录段。此外,当一个文件记录段内的全部文件记录被访问过后,释放该部分内存。
(4)预读文件数据。该功能的实现方法与预读文件记录相同,一次性预读大段数据,从而降低读取次数,减少开销。
2.2 定位模块
定位模块的功能是根据给定的目录路径,定位目录的文件记录。根据目录量级的不同,NTFS存放目录项的方式也不同,随着目录下文件数量的增多可分为以下4种情况,分别是小索引、单索引节点、多索引节点、多级索引节点,后三种索引节点统称为大索引。
(1)小索引。当目录下文件数量比较小时(一般是7个以下),文件名直接存放在目录文件记录的90属性中。一般情况下,90属性后无A0和B0属性。
(2)单索引节点。文件数量增多(一般为8~20个),90属性无法存放全部的文件名。此时文件名会存放在一个索引节点中,90属性只存放索引节点号,索引节点的数据运行列表(可以指向某个位置的数据)存放在A0属性中。
(3)多索引节点。文件数量再次增多(一般为20~200个),一个索引节点无法存放全部的文件名,此时NTFS系统会再申请新的索引节点,多个索引节点共同存放文件名。此时90属性存放部分文件名和索引节点号,索引节点的数据运行列表存放在A0属性中。
(4)多级索引节点。文件数量非常大(一般为200个以上),90属性无法存放所有的索引节点号,此时NTFS系统会用一个新索引节点存放索引节点号和文件名。90属性存放索引节点号和部分文件名,A0属性存放多个索引节点的数据运行列表。此时的目录结构为B-树。
综上所述,小索引的目录项一定只存放在90属性中,3种大索引的目录项一定存放在A0属性中,而90属性可能存放部分目录项。无论是大索引还是小索引,90属性都可能存放需要的文件名,因此先解析90属性,未匹配到需要的文件名时,判断目录为大索引还是小索引,如为大索引,无需考虑索引节点的结构,只需解析A0属性,遍历其指向的所有索引节点即可。如为小索引,说明未能找到所需的文件名。
定位模块从根目录开始,循环获取下一级目录的文件记录号,根目录的文件记录号固定为5,即元文件“.”。定位模块流程如图3所示。
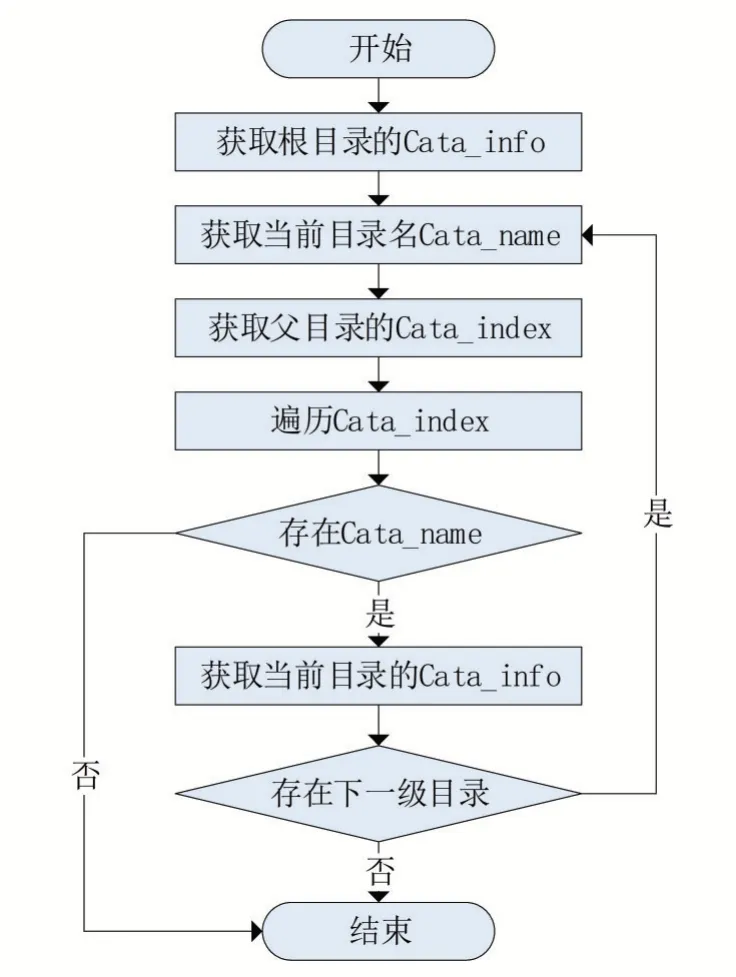
图3 定位模块流程图
2.3 提取模块
提取模块的功能是提取目录下所有的目录项信息。模块分为三个过程,①通过定位模块得到的文件记录号获取文件记录。②遍历目录项,提取目录项信息。海量小文件目录的目录项通常为多级索引节点,相对于定位模块要庞大和复杂的多。③对目录项排序并推入写队列中。通常情况下,连续生成的小文件在磁盘上的分布也是连续的。提取模块按照文件的创建时间对目录项进行排序,使磁盘上数据的分布顺序与入队顺序尽可能的相似,从而提升数据预读时的命中率。
2.4 写入模块
写入模块的流程如图4所示。写入模块接收写队列中依次出队的文件记录号,若对应的文件记录已被采集模块采集,可直接从内存中访问;若未被采集,由采集模块将整段文件记录读入内存。写入模块解析文件记录的80属性得到文件数据在磁盘上的偏移,通过采集模块实现数据的预读后,向NTFS发送写命令将该数据写入指定文件中。
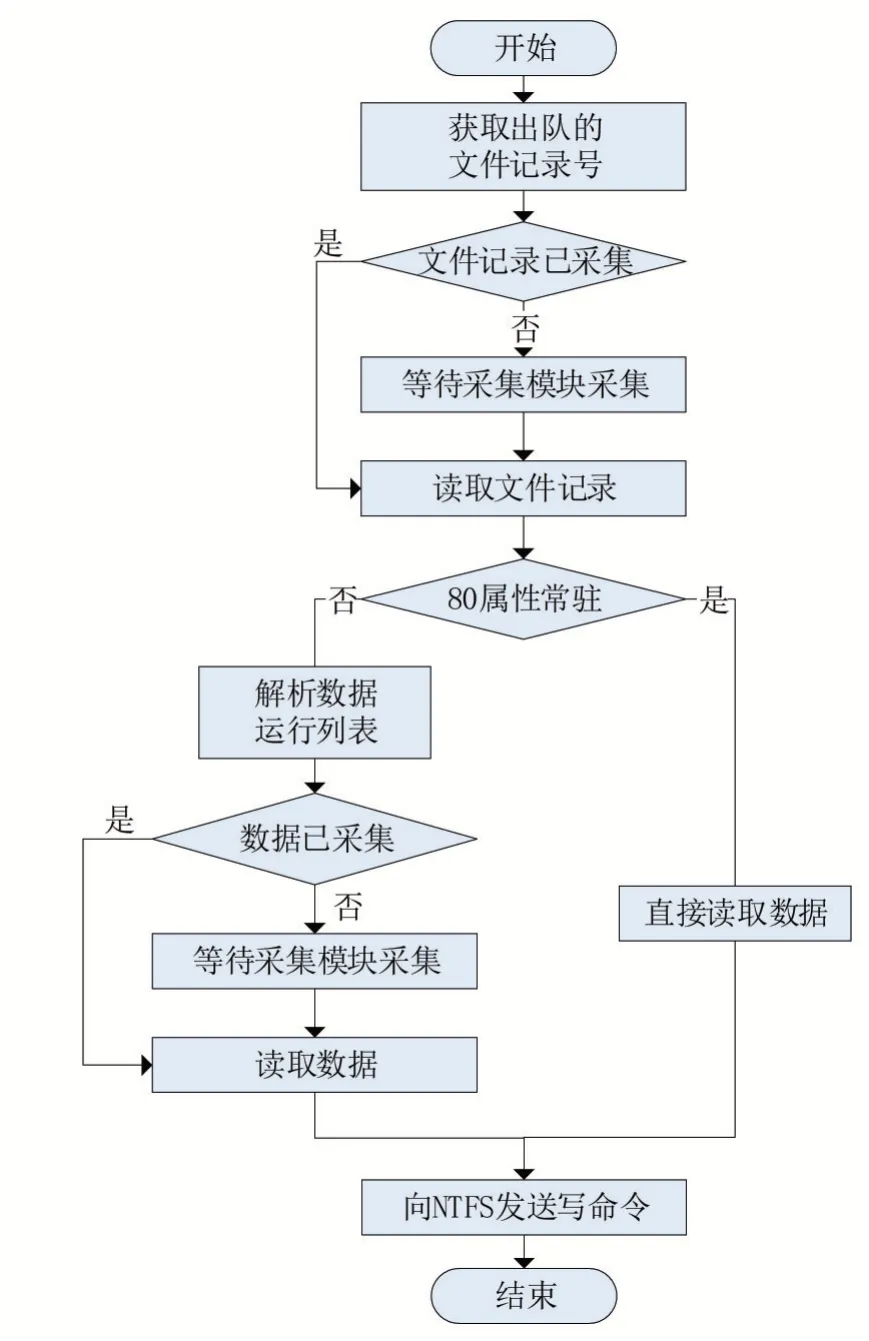
图4 写入模块流程
NTFS中文件数据有两种存储方式。当文件非常小时,文件记录的80属性为常驻,即数据可以直接存放在80属性中,写入模块直接从80属性读取数据;80属性为非常驻时,属性中存放指向文件数据的数据运行列表,解析后即可得到数据在磁盘上的偏移。写入模块通过属性头内偏移量为0x08的字节判断其是否常驻,0表示常驻,1表示非常驻。
3 实验与评估
3.1 实验环境
本实验的实验环境如表2所示。文件系统版本为NTFSV3.1,于2001年秋季发布并用于Win⁃dows XP及后续版本,是目前最为常见的NTFS版本。

表2 实验环境
3.2 实验内容
本文设计了一组对比实验,给定几个目录,先获取目录下所有文件的信息,再读取每个文件的数据,写入到指定文件中。与本文方法对比的是系统调用,通过opendir、readdir和stat获取文件列表信息,通过C标准库函数fopen、fread、fwrite和fclose实现文件数据的读写。本实验的评价指标为获取文件列表信息时间和读写文件时间。
本实验分别对量级为1万、10万、100万、1000万的小文件目录进行实验,目录下既有数据常驻的小文件,又有存放在其他簇上的“较大”的小文件,其总大小与量级成正比。实验数据如表3所示,图5、图6分别为获取文件列表速率和读写文件速率。
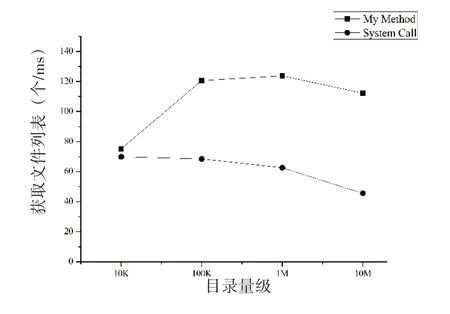
图5 获取文件列表速率
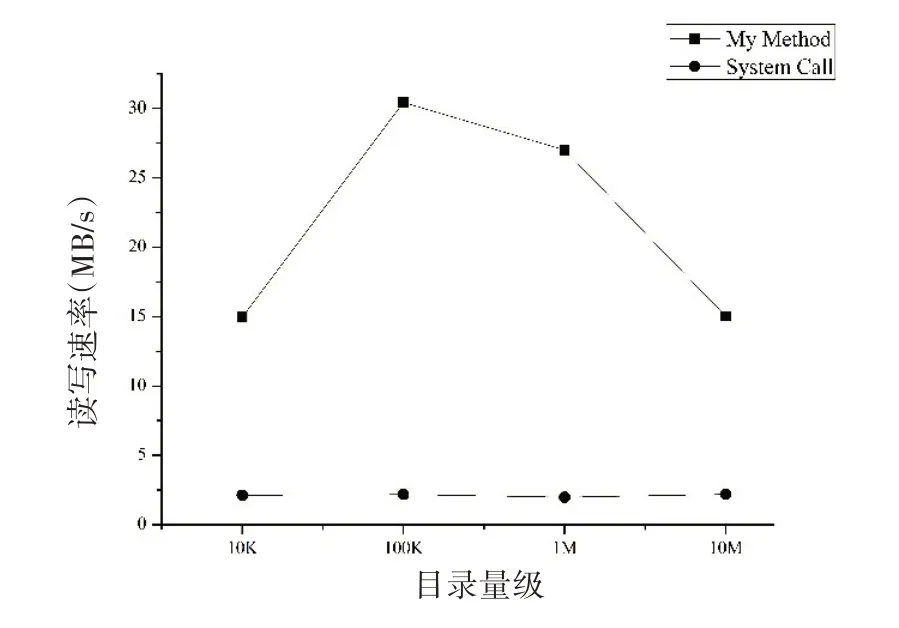
图6 读写文件速率
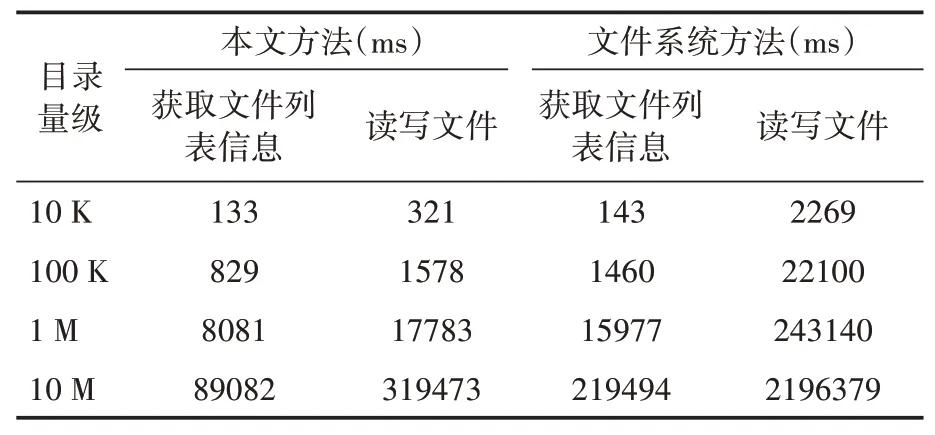
表3 海量小文件对比实验数据
如图5所示,在目录量级较小时,本文提出的方法没有明显提升获取文件列表信息的速率,其原因在于采集模块和定位模块会有一定的时间开销,而这一开销与目录量级无关。随着目录量级的增大,提取模块遍历目录项的时间开销占比增大,遍历时间与目录量级等比增长,获取文件列表速率提升并趋于稳定,而系统调用的获取速率随着量级的增大逐渐降低。因此,在海量小文件的情形下,本文提出的方法能够提升获取文件列表信息的速率。
与获取文件列表信息时相同,读取文件时,采集模块实现文件记录分段有一定的开销。随着目录量级的增大,读写文件速率提升。但由于预读机制的随机性,当目录下文件的磁盘分布相对零散时,本实验的实验结果可能不与预期结果完全一致。如图6所示,不同量级目录的速率没有呈现逐步提升的趋势,这是可以接受的。与系统调用读写文件速率的对比结果表明,在海量小文件的情形下,本文提出的方法能够大幅提升读写速率。
4 结语
本文提出了一种面向NTFS的海量小文件读写方法。该方法对NTFS结构进行解析,提取了文件拷贝时使用的有效元数据;对文件记录进行解析,获取了文件属性从而查找到文件数据或索引节点的位置;对NTFS目录项结构进行解析,实现了目录路径的分级依次查找;通过遍历目录项,获取了目录下文件列表信息;通过文件记录分段和预读,提升了文件记录的访问速率;通过数据的预读,提升了用户数据的读取速率。实验结果表明,该方法能大幅提升NTFS环境下海量小文件的读写速率。同时,本文并未对采集模块实现内存置换时的命中率进行深入研究,如果能够优化置换算法,读写效率可以进一步提高。
