多尺度特征融合网络的视网膜OCT 图像分类
2022-04-21韩璐毕晓君
韩璐,毕晓君
(1.哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001;2.中央民族大学 信息工程学院,北京 100081)
近年来,患有视网膜黄斑病变的患者数量明显增加,并且随着病情的加深,该病会对视力产生不可逆转的影响,严重情况下会导致失明[1-3]。因此,黄斑病变的早期发现和临床诊断至关重要,通过适当的治疗和定期的筛查可以使黄斑病变引起的失明减少90%。
光学相干断层扫描技术(optical coherence tomography,OCT)可以提供高分辨率的视网膜截面图像,是目前用于检验视网膜疾病最为先进的技术手段,具有非接触、无创、成像快等优点[4-7],医生通过对视网膜OCT 图像的分析对眼底疾病做出诊断。然而,利用OCT 技术对视网膜疾病进行人工诊断面临以下问题:视网膜黄斑病变患者逐年增加,医生面临巨大的阅片任务,依靠专业医生的诊断已经无法满足大量患者的诊疗需求;OCT 图像为灰度图像,个别病变特征不明显,医师诊断时有误诊和漏诊情况发生;个别地区医疗水平较差,导致大量患者在患病初期没有及时发现,造成疾病恶化[8-10]。
计算机辅助诊断技术[11-13](computer-aided diagnosis,CAD)是解决这一问题的有效方法。早期的CAD 技术使用基于手工特征的传统机器学习分类方法,尽管在视网膜OCT 图像的分类领域取得了一些成果,但是存在严重依赖于人工设计特征,特征级别低,在网络训练过程中存在计算代价高、处理流程复杂等问题。近年来,深度学习迅速发展,并在计算机视觉领域表现优异。深度学习使用卷积神经网络在不同的层次上自动学习从低级到高级的图像特征,弥补了传统技术需要手工提取特征这一缺陷,成为解决视网膜OCT 图像分类的主流算法。其中具有代表性的有2017 年,Karri等[14]提出了一种基于迁移学习的视网膜OCT 图像分类方法。该方法通过微调预训练后的GoolgeNet 网络,减小网络对大量数据的依赖,在训练数据有限的情况下实现对DME[15-16]、AMD 和正常图像的分类,分类精度分别为 86%、89%和99%。2020 年,张添福等[17]提出了一种轻量化OCT 图像分类网络。使用深度可分离卷积代替普通卷积层从而减小网络的参数。同时使用全局平均池化代替全连接层,提高空间鲁棒性,其网络准确率可达97%。
以上研究对视网膜OCT 分类任务做出了突出贡献,但是尚存以下两点问题:1)视网膜OCT图像存在大量冗余,在特征提取过程中,显著病变特征容易被忽略,造成有用信息的丢失;2)玻璃疣(Drusen)病变位置小且形态模糊,导致Drusen这类疾病的分类难度大,目前该类别的准确率尚需提高。
针对以上问题,本文主要做了以下3个方面的工作:1) 设计了一种双通道的多尺度融合网络,有效利用包含了丰富语义信息的深层特征以及包含纹理信息的浅层特征;2)引入扩张卷积,通过在网络中加入一系列并行的扩张卷积,实现在不降低特征图分辨率的同时,增大感受野,按不同比例获得上下文信息;3)引入门控注意力模块,利用深层特征作为选通信号传递给浅层特征,在消除冗余特征的同时,获得更细尺度的细节信息。
1 双分支多尺度特征融合网络
2014 年,牛津大学著名研究组Visual Geometry Group 提出VGG 网络[18],斩获该年ImageNet 竞赛定位任务第一名和Classification Task 分类任务第二名。该工作探索了卷积神经网络的深度对图像分类任务性能的影响,在固定网络架构中其他参数的同时,通过增加卷积层来平稳地增加网络深度,分类准确率获得显著提升。
VGG 网络由卷积层、最大池化下采样层和全连接层组成。其中,卷积层均采用卷积核大小为3×3,步距为1,填充为1 的卷积操作。VGG16 相比于AlexNet,采用连续的几个3×3 卷积核代替AlexNet 中的较大卷积核。两个3×3 卷积的堆叠层具有5×5 的感受野,3个这样结构堆叠获得的感受野是7×7。使用小卷积核堆叠代替大卷积核可以整合非线性映射层,使决策函数更加具有判别性;在拥有相同感受野的前提下能够减少网络所需参数;同时增加网络非线性,让网络学习到更复杂、深层的特征。VGG 提出的网络深度从11层到19 层不等,本文选择VGG16 作为基线网络。
本文提出了一种基于改进VGG16 的视网膜图像分类网络−双分支多尺度特征融合网络。主要改进点如下:
1)在VGG16 网络中引入针对医学图像的门控注意力机制模块,从而消除医学图像中的大量冗余,突出病变区域信息抑制图像中的无关区域;
2)在VGG16 网络中使用并行的扩张卷积在不减小特征图大小的同时,获得较大感受野,得到病变的细节信息,并与深度抽象特征融合,提高分类精度。
1.1 门控注意力机制
近年来,注意力机制作为一种可以即插即用在网络模型中的模块,在自然图像处理领域取得了良好的效果。其中最具代表性的工作有2017 年HU 等[19]提出的通道注意力机制、2018 年Woo 等[20]提出的融合了通道注意力以及空间注意力的CBAM机制以及2020 年Wang 等[21]提出的改进通道注意力机制。这种机制在通道和空间两个维度加权生成注意力图,使网络能够关注重要的通道特征以及空间上的位置信息。
相比于自然图像,医学图像具有目标区域局部化这一特性。尤其是本文使用的眼部OCT 图像,其病变位置均占整张OCT 图像很小的区域。鉴于医学图像这一特性,若将通道和空间注意力机制串联至网络中,会导致获得的加权注意力图谱单一。尽管这种机制串联在网络深处能够取得良好效果,但是网络的加深使特征图减小,导致相关病变的细节信息丢失,因此基于深度学习的视网膜OCT 图像分类技术中采用通道和空间注意力机制效果不佳。
本文引入了一种针对医学图像中目标局部化这一特性,重点关注医学图像中病变细节信息的门控注意力机制模块(attention gate module,AG),如图1 所示。
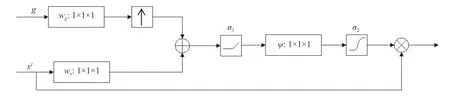
图1 门控注意力机模块Fig.1 Attention gate module
深层的粗糙特征包含目标对象的位置信息,并在全局范围内建立它们之间的关系。图1 中:g代表网络中获取到的深层特征;xl代表特征提取过程中任意某一层获取的浅层特征,浅层特征中包含目标的细节信息,比如形状、大小等。浅层特征中包含着严重影响分类任务准确性的细节信息。AG 模块将深层特征和浅层特征融合并生成注意力图谱,然后将该注意力图普与浅层特征相乘,用深层信息消除xl中与任务无关的特征内容,修剪冗余特征,突出显著目标区域。其公式为
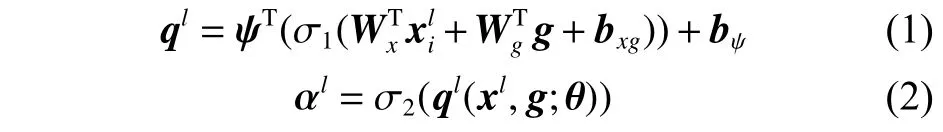
式中:σ1是RELU 非线性激活函数;σ2是归一化sigmoid 函数,将门控系数范围控制在[0,1]。因此,AG 可以由以下参数描述:线性变换Wx和Wg偏置bψ,这里的线性变换采用1×1×1卷积实现。;
本文在VGG16 网络中采用AG 模块,该网络经过5 次下采样,得到大小为7×7×512 的特征图,该特征图即为选通信号g。由于影响分类准确率的浅层特征可能分布在网络的不同层次,因此,AG 模块将选通信号g提供的上下文全局信息分别与VGG16 中第9 层和第13 层的浅层特征融合,在消除浅层特征中冗余的同时,获得更细尺度的病变抽象特征,进而融合多尺度特征。其中第9 层和第13 层的特征图大小分别为28×28 和14×14。最终网络得到14×14、28×28 以及7×7 等3 种尺度的特征图,经过全局平均池化以及展平处理后,将3 种尺度信息拼接起来,并通过分类层(softmax)进行分类。综上,本文通过在VGG16中加入AG 模块,可以有效解决OCT 图像中病变局部化这一问题,突出病变区域同时抑制背景噪声,让网络进一步挖掘到病变特征,提升分类准确率。
1.2 空洞空间金字塔模块
视网膜病变具有局部性,且病变区域在OCT图像中占据位置小。其中Drusen 的此特点最为明显,其变位置小且模糊。此特点严重影响OCT图像的分类效果,目前提出的相关分类方法中,Drusen 类别的分类准确率最高为92.5%,相比于视网膜OCT 图像分类应用中其他3个类别的分类精度尚有待提高。
现阶段的经典分类网络通过加深网络深度,从而获得更大的感受野以及丰富的上下文信息。但是针对医学图像的特性,在分辨率小的特征图上进行分类将损失大量有用信息。为解决该问题,本文设计了双分支网络,在骨干网络经过3 次下采样操作,加入并行扩张卷积空洞空间金字塔模块,以不同比例捕捉全局上下文信息。
扩张卷积(dilated convolution)由Chen 等[22]于2016 年提出,与普通卷积相比,扩张卷积引入扩张率这一参数,在基础卷积上加入间隔,卷积核各点间的间隔为扩张率减1,如图2 所示。
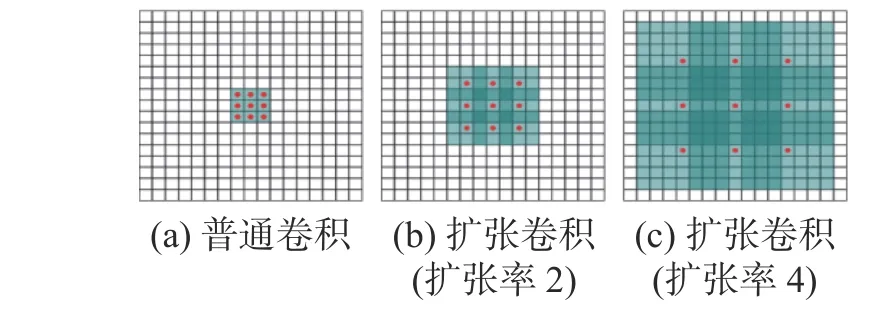
图2 普通卷积和扩张卷积Fig.2 Ordinary convolution and dilated convolution
扩张卷积对应的卷积核实际大小以及感受野大小均大于普通卷积,但实际参数不变,以图2 中不同扩张率的3×3 卷积为例,它们均只有9个点有参数,与普通的3×3 卷积参数相同,其余扩张位置的参数均为0。扩张卷积对应的实际卷积核以及感受野大小计算公式为
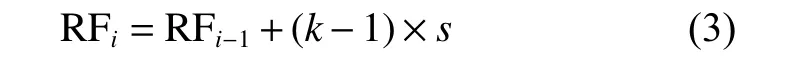
式中:k为卷积核尺寸;s是步长,是上一层感受野大小。通过加入扩张卷积,能够在不进行下采样操作的前提下,同样获得更大的感受野。在大尺度特征图上实现细节信息的保留以及丰富上下文信息的获取。更好地保留了较小病变的形状以及轮廓特征,有利于提升小目标分类精度。本文在VGG16 网络中采用的空洞空间金字塔模块(atrous spatial pyramid pooling,ASPP)如图3 所示。
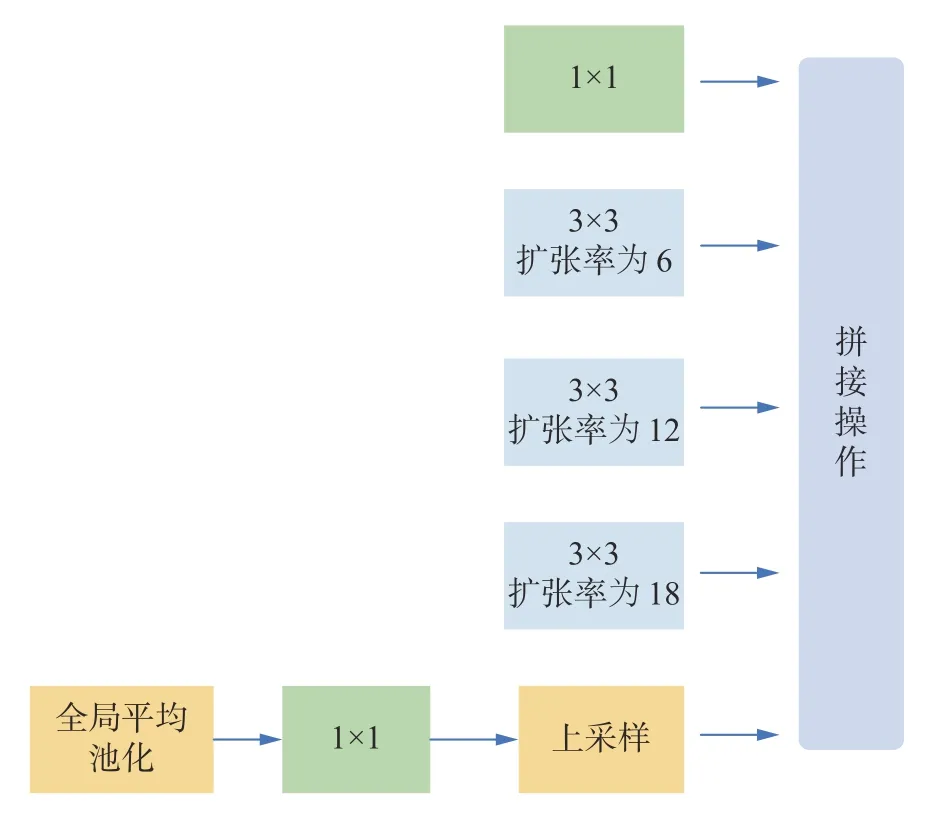
图3 空洞空间金字塔模块Fig.3 Atrous spatial pyramid pooling module
骨干网络经过3 次下采样后的特征图作为该模块的输入,分别经过并行的1×1 卷积以及3个扩张率分别为6、12、18 的扩张卷积。为了融入全局上下文信息,该模块采用了图像级特征,通过对该模块的输入进行全局平均池操作,并将得到的图像级特征输入到1×1×256 的卷积核中,然后经过双线性插值将特征上采样到所需的空间尺寸。最后将这4 部分特征拼接输入到1×1 卷积进一步加强特征提取。
综上,本文通过采用不同扩张率的空洞空间金字塔模块,在不减小特征图大小的同时,按不同比例捕捉上下文信息,同时扩大感受野。在特征提取过程中,不会因为过度下采样而损失病变信息,同时又利用扩张卷积和图像级特征融合了全局信息,较好地提升了网络对小目标Drusen 病变的特征提取能力。
1.3 整体模块设计以及网络架构
基于门控注意力机制和空洞空间金字塔模块两个创新点,本文提出了一种基于改进VGG16 的双分支多尺度特征融合网络,如图4 所示。网络经过3 次下采样后分成两个分支,3 次下采样后得到的大小为28×28×512 的特征图作为接下来两路分支的输入。一路分支继续下采样,得到最深层的特征g作为选通信号,为第3 次、第4 次下采样后的特征图提供上下文信息,修剪浅层特征中的冗余信息,突出病变区域显著特征。
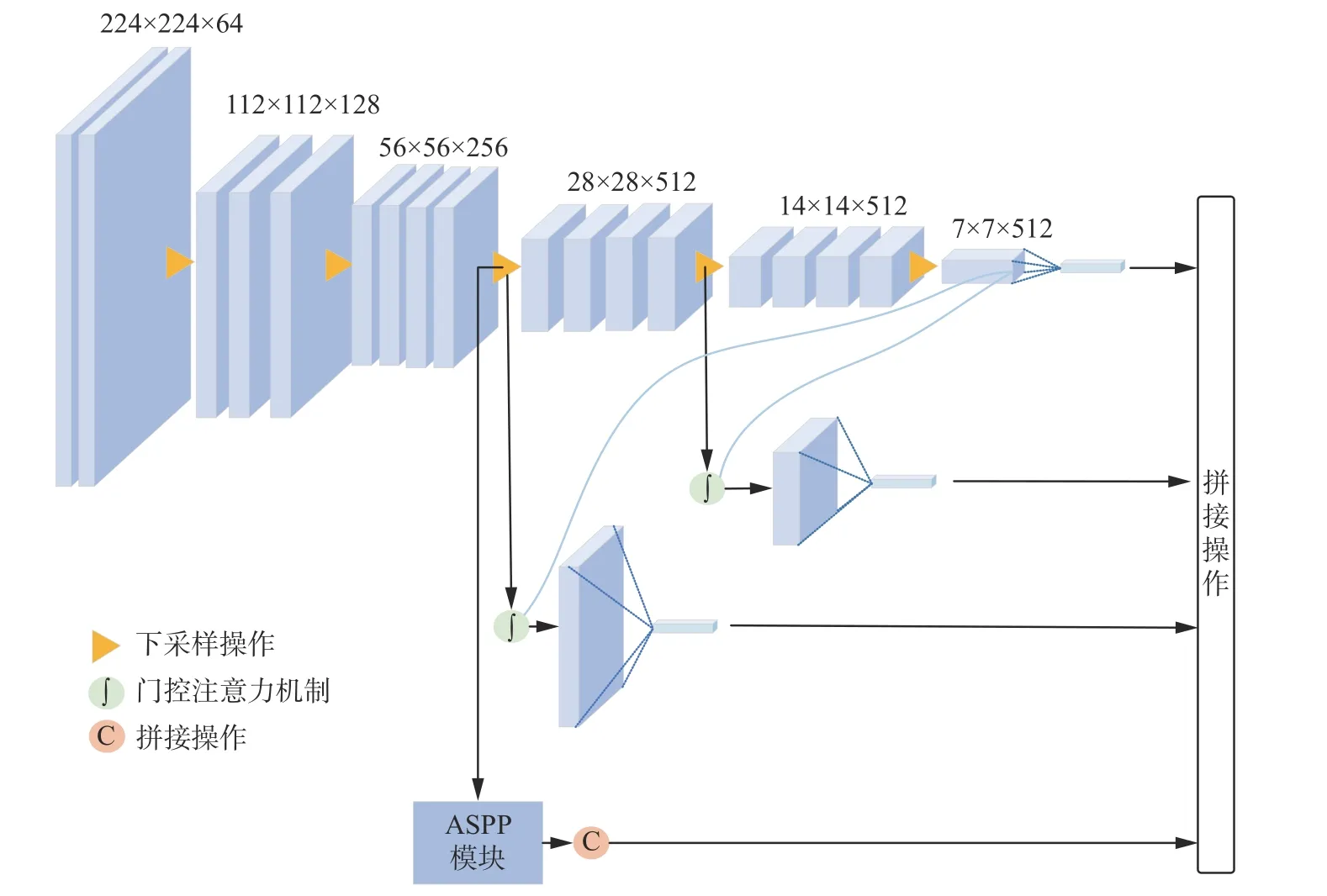
图4 本文方法演示图Fig.4 Method demonstration diagram of this paper
另一路分支进入空间空洞金字塔模块,分别进行不同扩张率的扩张卷积,输出特征图大小为28×28×512,尺度不变。在AG 模块中,选通信号g和第3 次下采样后特征图融合得到的特征和空间空洞金字塔模块的输出大小维度均相同,将两部分特征融合,进一步获得融合了选通信息以及多尺度信息的特征。并且,该融合后的特征为大尺度特征,实现了让网络在分辨率大的特征图上进行分类。为了让小目标病变获得良好的分类效果,需要网络获取丰富的病变区域信息,包括病变的形状、大小特征等。这种特征通常蕴藏在浅层网络中,但是由于病变区域过小,这些浅层特征会在特征提取过程中,损失大量病变区域的细节信息。本文提出的方法不仅融合了多尺度特征,还通过在大分辨率特征图上进行分类避免了细节特征的丢失,有效解决了现有方法对小目标病变分类效果不佳这一问题。
2 实验结果及分析
为验证本文提出方法的有效性与先进性,实验部分主要做了以下两个方面的工作:1)消融实验,本文提出的两个创新点分别引入实验以及最终的改进网络与基线网络的实验效果对比实验;2)与现有代表性算法的对比实验。
2.1 实验环境
本文使用的实验环境如表1 所示。本实验采用SGD 优化算法,一共训练150个epoch,初始学习率设置为0.001,学习率衰减采用指数衰减,衰减底数gamma 设置为0.98。

表1 实验环境配置Table1 Experimental environment configuration
2.2 数据集
本文使用的数据集是 Kaggle 平台提供的开源视网膜OCT 病变图像,该数据集由加利福尼亚大学圣地亚哥分校(UCSD)于2017 年公开。该数据集包含4 种类别,分别是玻璃膜疣(Drusen)、脉络膜新生血管(CNV)、糖尿病黄斑水肿(DME)和正常类别,如图5 所示。数据集包含训练集和测试集,训练集中4 种类别分别包含8 616、37 205、11 348、26 315 张图片。测试集由每类250 张图片组成,共1 000 张OCT 图像。本文按照8∶2 的比例将训练集划分为训练集和验证集。
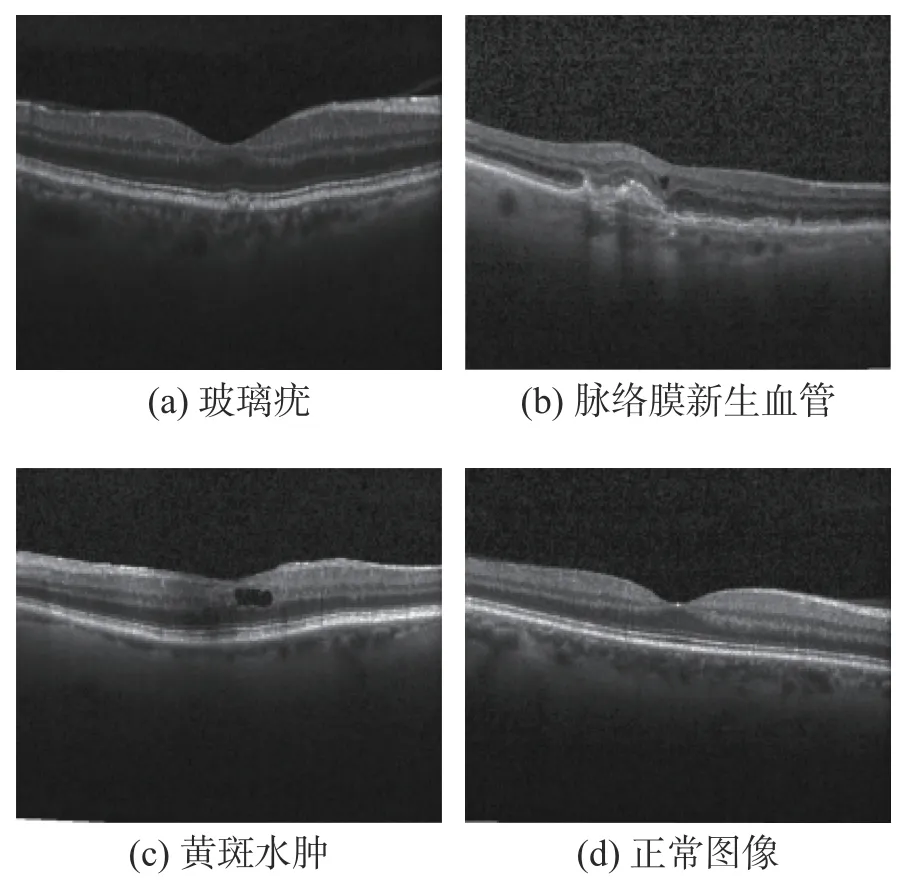
图5 视网膜OCT 图像示例Fig.5 Retinal OCT image example
2.3 评价指标
本文使用准确率(Accuracy)、召回率(Recall)精确率(Precision)、特异性(Specifity)作为视网膜OCT 分类任务的评价指标,具体公式如式(4)~(7)所示。

式中:TP 是将正样本正确分类的个数;TN 为将负样本正确分类的个数;FP 为将正样本分类错误的个数;FN 为将负样本分类错误的个数。本文中的视网膜分类任务属于多分类任务,这里的正样本是指定的某一特定类别,例如玻璃疣,而此时的负样本为除玻璃疣外的其他3 种类别。同时,本文绘制了4 种类别的混淆矩阵,可直观看出各类别的分类情况以及与基线网络分类情况的对比。
2.4 实验分析
2.4.1 算法的有效性验证
为了验证本文提出方法的有效性,这里对改进后的网络(引入AG 模块和空间空洞金字塔模块)与只加入AG 模块以及基线网络进行了消融实验,实验在同样的数据集、实验环境以及相同的网络参数配置上进行,实验结果如表2 所示。
由表2 可以看出,加入AG 模块后,网络的识别率较基线网络提高了1.9%,由此看出通过引入AG 模块,网络更好地学习了病变区域特征,降低了大量背景冗余的影响。在此基础之上,加入本文的第二个改进点,网络的准确率进一步提高到97.9%,较基线网络提高了3.7%。其中Drusen 病变有了明显的提高,提高了1.5%。由该实验结果可以看出,加入扩张卷积使网络在大尺度特征图上进行分类,让小目标病变的细节信息不会随特征提取过程的深入而损失,Drusen 的识别效果显著地提升。
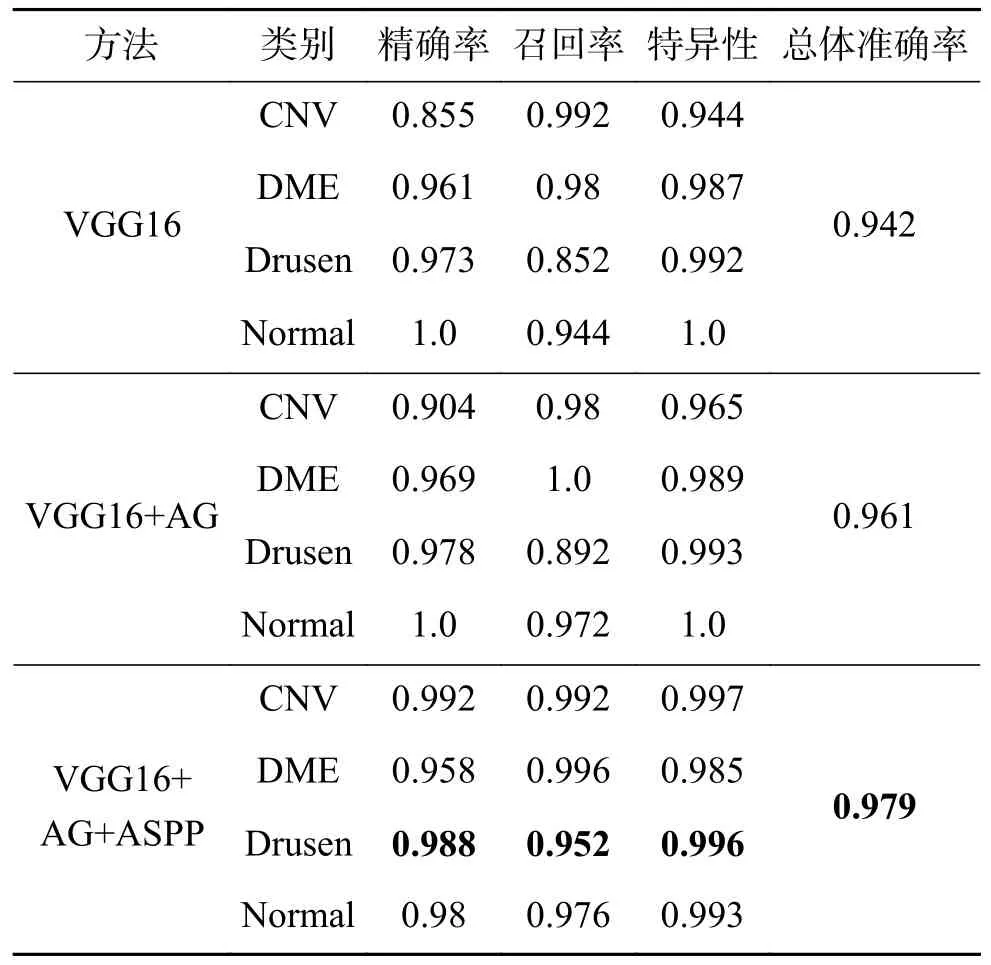
表2 算法有效性验证实验Table2 Algorithm validation experiment
为了进一步直观地看出网络对4个类别的分类效果,这里绘制了基线网络以及加入AG 模块和加入AG 模块、空间空洞金字塔模块的混淆矩阵,如图6 所示。在混淆矩阵中,对角线上的数字代表每个类别正确分类的样本个数,对角线上数值越大说明分类越准确。从图6 可以看出,加入AG 模块后,虽然各类别分类效果有所提高,但是由于Drusen 病变小而模糊,且与CNV 表现相似,对Drusen 的分类效果相比于其他3个类别差。再加入空间空洞金字塔模块后,Drusen 的分类效果有了明显的改善。
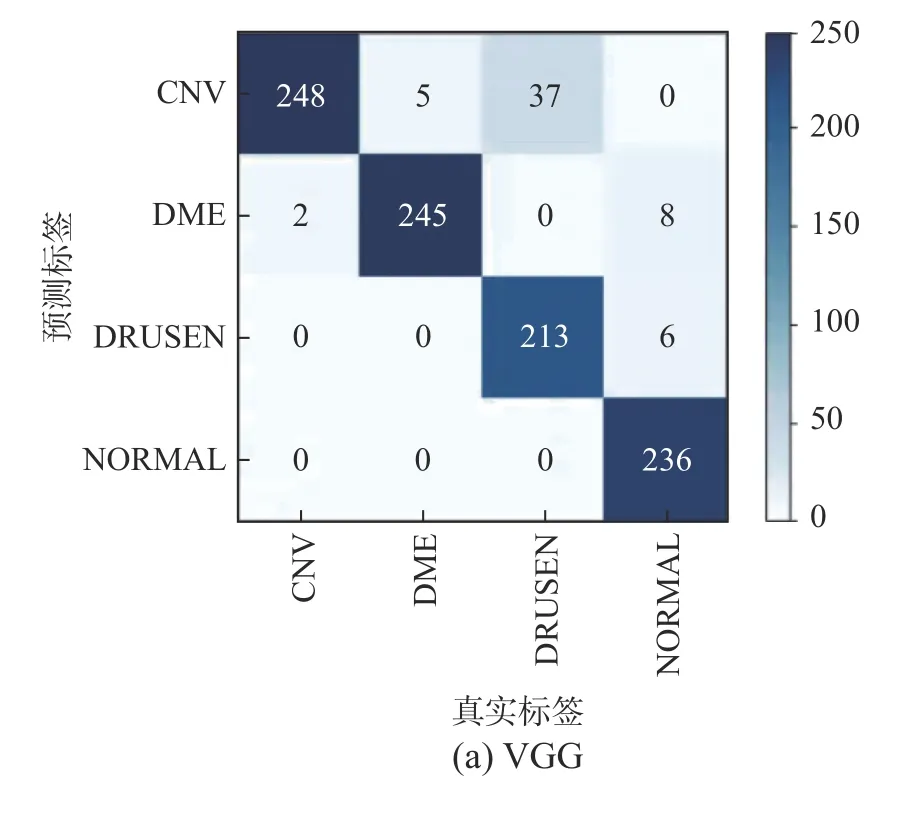
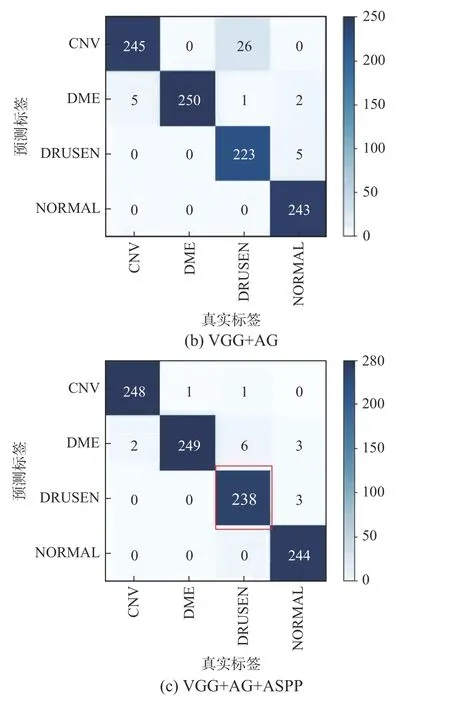
图6 混淆矩阵Fig.6 Confusion matrix
2.4.2 算法的先进性验证
为验证本文方法的先进性,将本文提出算法与现阶段具有代表性的基于深度学习的视网膜OCT 分类算法进行对比,对比结果如表3 所示。首先,从表3 可以看出,现有方法对Drusen 的分类准确率不高,该类别的最高准确率仅达92.5%,远低于另外3 种类别的分类精度。这是因为现有方法针对小目标病变的特征提取能力不强,在特征提取过程中,Drusen 这一病变的细节信息损失严重。针对这一问题,本文通过加入门控注意力机制突出病变区域信息,以及加入空间空洞金子塔模块减小网络下采样的次数,在大分辨率的特征图上进行分类,从而保留小目标病变区域的细节特征,本文对Drusen 病变的分类准确率较现有文献有了显著提升,较文献[17-24]分别提高了6.3%和9.8%。同时,本文方法在CNV、DME 两种类别病变上也获得了最好的分类效果。本文对Normal类别的分类准确率较文献[17]低0.5%,但本文方法的整体分类准确率依然是现有视网膜OCT 图像分类任务中最高的,相比于文献[17]提出的轻量化视网膜OCT 图像分类网络,本文算法准确率提高了0.9%,较文献[23]提出的多层次可选择卷积分类方法准确率提高了2.51%,较文献[24]提出的迁移学习方法准确率提高了1.4%,较文献[25]提出的基于通道注意力机制的分类方法提升了0.4%,这充分验证了本文改进网络模型的先进性。
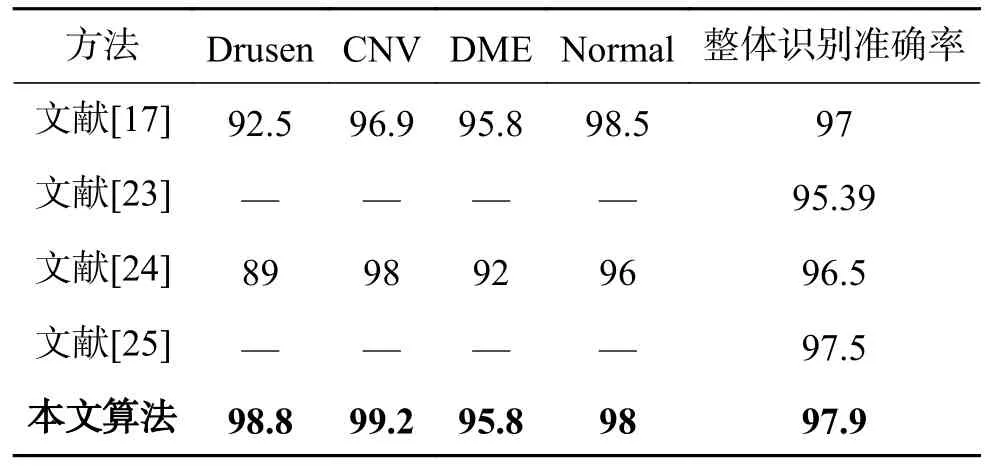
表3 算法先进性验证实验Table3 Algorithm advanced verification experiment %
3 结束语
本文提出了一种应用于视网膜OCT 图像分类任务的双分支多尺度特征融合网络。通过加入门控注意力机制模块,让深层特征作为选通信号修剪浅层特征中的冗余信息,突出OCT 图像中的病变区域,消除背景噪声的影响。同时引入空洞空间金字塔模块,利用并行扩张卷积代替下采样过程,在不降低特征图大小的前提下按不同比例捕捉上下文信息,获得更大的感受野。本文提出的方法有效解决了现有方法中因Drusen 病变位置小、形态模糊导致的该类别分类难度大、精度低的问题,进一步提高了计算机辅助诊断的能力。针对目前视网膜黄斑病变患者多、医生诊断压力大以及医疗行业逐渐智能化的现状,本文具有显著的研究价值。利用深度学习技术特征提取能力强大、可处理大量数据的优势,对本课题进一步深入研究,可以让计算机辅助诊断技术提升至人类专家水平,在实际应用中辅助人类医师更加高效、准确地诊断疾病,同时可以挖掘大量医疗数据中的巨大价值,实现医疗系统智能化的转变。
