CBiA-PSL 抽油井异常工况预警模型
2022-04-21李克文杜苁聪黄宗超李潇柯翠虹
李克文,杜苁聪,黄宗超,李潇,柯翠虹
(中国石油大学(华东) 计算机科学与技术学院,山东 青岛 266580)
油田生产信息化建设,基本实现了油水井、站库数据的实时采集,油井的智能化管理需求日益突出。在油田生产过程中,油井受各种因素的影响出故障的概率很高,经常造成油井产量降低甚至躺井。目前,识别异常工况主要依靠简单的参数超阈值报警,导致报警频繁且有效率不高,问题原因仍主要采取人工分析,数据变化趋势难以自动跟踪、问题隐患难以超前发现、预防性治理和优化措施难以精准实施,难以满足信息化条件下“预警式管理”的要求。所以,预警油井异常工况,指导技术人员超前采取治理与优化措施,对于提高油井开采效率,降低躺井率与维护成本,实现智能化精细化管理具有重要意义[1]。
为了提高油井异常工况的识别精度,世界各地的学者进行了大量的研究。考虑到油井生产数据的特征,即异常工况样本少、维数大等特点,近年来识别异常工况的方法可分为两类:基于统计[2]和传统机器学习的方法[3]以及基于深度学习的方法[4-6]。对于第一类,Zhang 等[7]将支持向量机与遗传算法相结合,提出基于GA-SVM 与频域光谱法的变压器油浸绝缘体的湿度预测;周斌等[8]提出一种基于Hessian 正则化支持向量机(Hessian正则化SVM)的多视角协同识别抽油机井工况方法。这些研究提高了异常工况检测的准确性,但它们都忽略了工况数据类别不平衡的问题。王利君等[9]使用集成SMOTE、CLUSTER 与随机森林的集成学习方法SCRF 进行结蜡预测,考虑了类别不平衡,但忽略了高维数据的问题且目标数据集相对较小,模型的泛化性能和自学习能力不足。
近年来,由于深度学习模型具有强大的特征提取能力及拟合海量数据的能力,因此被广泛应用于故障检测领域[10]。例如,Wei 等[11]提出基于电机数据的深度学习的抽油杆泵故障诊断,利用CNN 作特征提取器弥补了专家经验的不足;Chen等[12]提出基于多尺度CNN 和LSTM 的轴承故障诊断,使用两个不同内核大小的CNN 从原始数据中提取不同的频率信号特征,然后利用LSTM 识别故障类型;Cabrera 等[13]提出基于LSTM 的往复式压缩机故障诊断模型,其中超参数搜索由在每次迭代中限制搜索空间的贝叶斯方法完成;魏晓良等[14]提出了一种基于长短时记忆(LSTM)和一维卷积神经网络(1D-CNN)相结合的空化故障诊断方法,用于高速柱塞泵故障诊断;Liang 等[15]提出一种使用自适应矩估计最大值(adamax)优化算法的双向门控递归神经网络(adamax-BiGRU)的瓦斯浓度预测模型,预警煤矿瓦斯事故。这些研究初步证明了深度学习模型在故障检测领域的有效性。但是,LSTM 具有许多参数和复杂的结构,容易出现过拟合的问题。作为LSTM 的变体,GRU具有简单的结构、较少的参数和较短的训练时间,这比LSTM 更具优势。但是,GRU 仅按顺序考虑前向信息,不考虑反向信息。由两个GRU 组成的双向GRU(BiGRU)可以利用附加的后向生产数据,从而进一步提高模型预警异常的准确性。
在上述方法中,存在一个主要问题:实际生产数据中抽油井异常记录远小于正常生产记录,即抽油井异常工况数据集往往存在类别不平衡的问题。上述方法仅考虑总体准确率,而忽略了类不平衡问题,导致少数类分类出错率较高,实际上的异常工况检测效果不理想。因此,本文提出了一种正共享损失函数[16],以增强少数类,即异常工况的检出效率。
本文的主要工作如下:
1)针对工况样本的灰度图像,在CNN-BiGRU联合网络模型上引入注意力机制,从而提高模型对特征的学习能力,进一步提高识别异常工况的准确率。
2)除了将CNN-BiGRU-Attention 网络用作特征提取器外,提出了正共享损失函数PSL。PSL引入一个额外的正则化项,以强调正负类的损失,且给样本少的正类更高的权重,旨在减弱不平衡,有助于更好地识别异常工况。
1 CNN-BiGRU 联合网络特征学习
CNN 网络主要有两个算子[17],一个是卷积层,另一个是池化层。卷积层作为特征提取器将数据集的工况样本的灰度特征矩阵分割成若干子矩阵,每个卷积层中所有的特征子矩阵与同一个权值矩阵(卷积核)做卷积运算,通过卷积核刻画图片的局部模式来提取图像的局部特征[18]。卷积运算可以提取数据集中人类无法理解的异常工况的局部抽象特征,起到过滤作用。池化层在卷积层之后,对卷积得来的特征进行筛查,减少特征数量来降低计算量,同时可以起到保留异常工况特征以及防止过拟合的作用。
门控循环单元(gate recurrent unit,GRU)是一种特殊的循环神经网络(recurrent neural network,RNN),其与长短期记忆网络(long-short term memory,LSTM)相似,是为了解决长期记忆和反向传播中的梯度爆炸、梯度消失和长距离依赖等问题而提出的。
GRU 适宜于处理时间序列数据,对比LSTM,GRU 在性能相当的同时参数量更少,结构简单,更易收敛,且计算速度比LSTM 更快。双向GRU[19]在输入序列上有两个GRU 互相连接,每一个输入的异常工况特征图都会从正向和反向经过GRU,为神经网络提供上下文的全局特征。在图1 中,每个GRU 单元都在两个方向上进行处理:GRU1是正向GRU,其内部结构如图2 所示;GRU2是反向GRU,其内部结构如图3 所示。
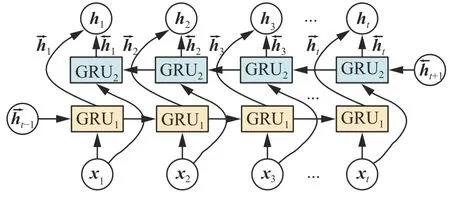
图1 BiGRU 的网络结构Fig.1 Network structure of BiGRU
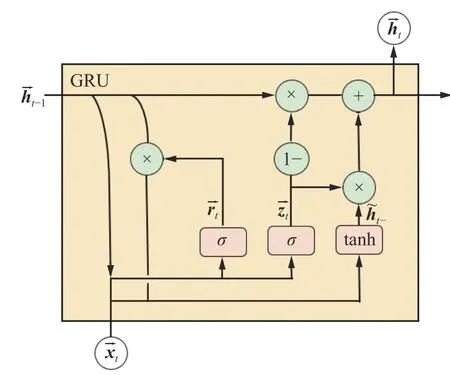
图2 正向GRU 单元的内部结构Fig.2 Internal structure of forward GRU unit
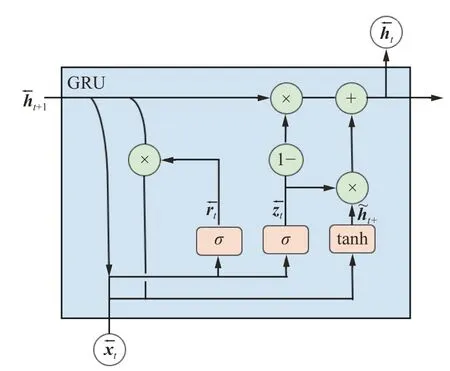
图3 反向GRU 单元的内部结构Fig.3 Internal structure of reverse GRU unit
图2 中的正向计算过程如下:
定义rt是正向GRU 在t时刻的重置门。公式如下:
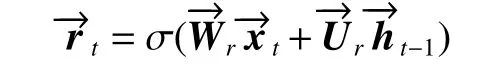
式中:σ为sigmoid 函数;xt和ht−1分别是当前输入值和上一个激活值;Wr是输入权重矩阵;Ur是循环连接的权重矩阵。
类似地,定义zt是正向GRU 在t时刻的更新门。公式如下:
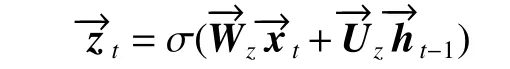
定义ht是正向GRU 在t时刻的激活值,即上一个激活值ht−1和候选激活值ht−之间的折中。
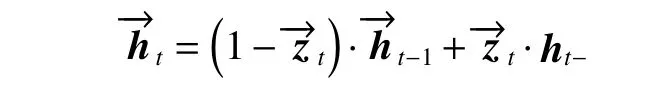
ht−公式如下:
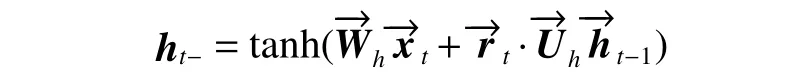
式中:“·”代表哈达玛乘积(Hadamard)。
当重置门rt关闭时,即其值接近于0,GRU 忽略先前的激活值ht−1,仅由当前输入xt决定。这允许ht丢弃不相关的信息,从而更有效地表达有用的信息。
另一方面,更新门zt控制将ht−1中的多少信息传递给当前ht。
同样,图3 中的反向计算过程如下:
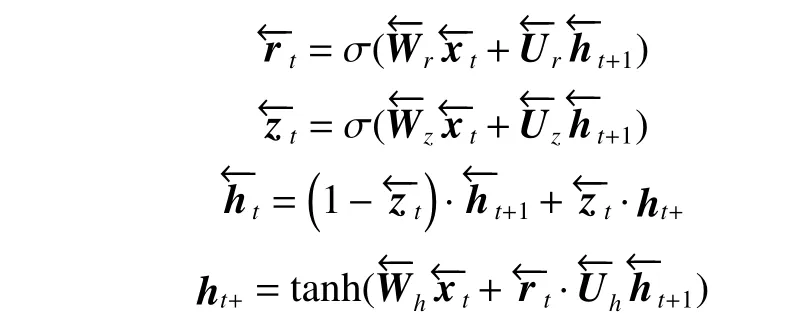
将两个方向的结果求平均,以获得最终输出ht。

2 CBiA-PSL 工况预警模型
为了更好地解决深度学习预测模型中工况属性的选择问题,且所提出的方法对图像处理更有效,将油井数据转化为灰度图像。数据集中共有41 维特征,为了保留数据集中每个样本的所有特征,用8个0 填充,将其转化为7×7 灰度图像。转化后的灰度图像如图4 所示,从左到右依次为无异常、泵漏、管漏,同一类别的图片几乎相同,但是不同类别的图片之间存在很大差异。

图4 样本灰度图像Fig.4 Sample gray image
2.1 CNN-BiGRU-Attention 特征筛选
本文提出的CBiA-PSL 模型是基于CNN-Bi-GRU-Attention 网络和正共享损失函数PSL。CNNBiGRU-Attention 在CNN-BiGRU 联合网络的基础上引入注意力机制,其结构如图5 所示。首先,7×7 工况样本灰度图像作为CNN 的输入,利用CNN、BiGRU 提取前后向相关特征,克服了CNN 缺乏对上下文的全局关注与BiGRU 缺乏对局部关注的不足,结合两者的优点从全局和局部对异常工况特征学习训练,并通过Attention 层增强相关特征表示[20-21],最后,通过softmax 层输出分类结果。
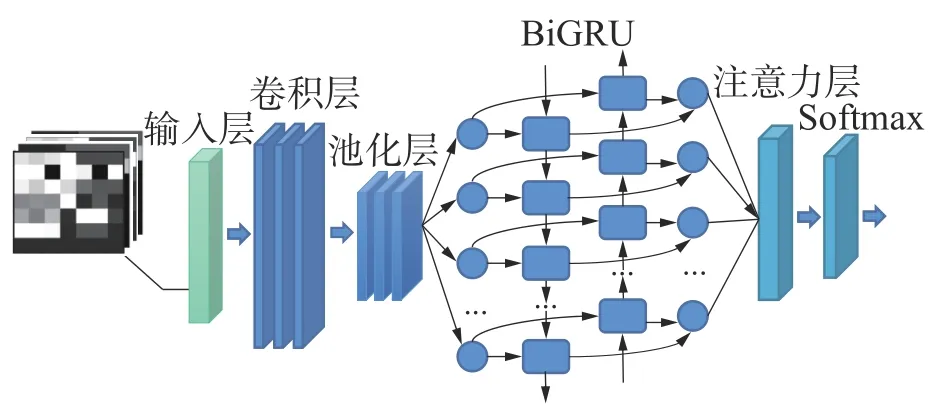
图5 CNN-BiGRU-Attention 模型结构Fig.5 Model structure of CNN-BiGRU-Attention
在CNN-BiGRU 联合网络架构的基础上增加注意力机制对隐藏状态加权计算以完成有效特征筛选。其核心是权重系数,首先学习每个特征的重要程度,而后根据重要程度为每个特征分配相应的权重,以区分各特征的重要性大小,提高工况识别的准确率。本文使用前馈注意力机制,其结构如图6 所示。
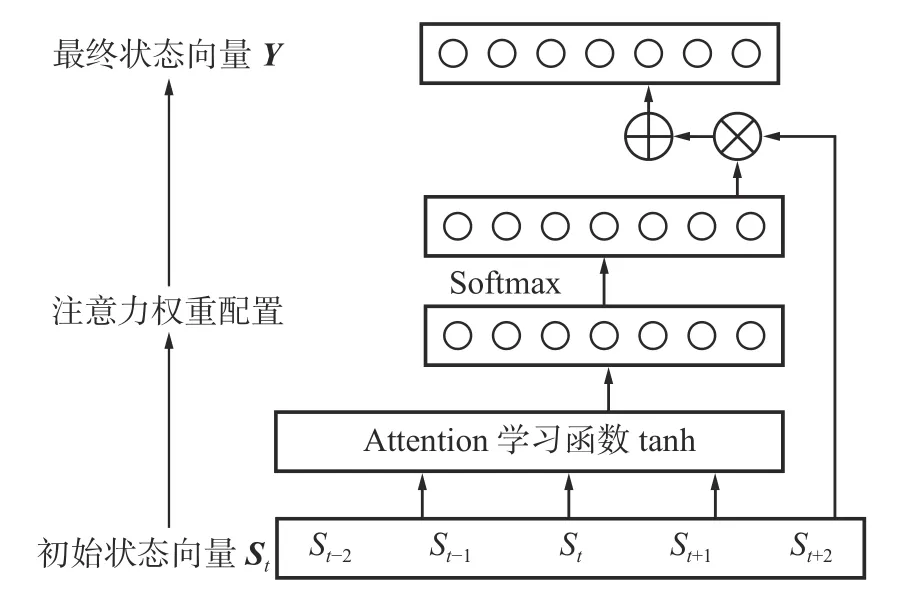
图6 注意力机制结构Fig.6 Structure of attention mechanism
首先生成目标注意力权重et,公式如下:
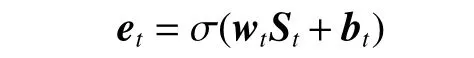
式中:σ是注意力学习函数tanh;St是第t个特征向量的初始状态向量;wt表示第t个特征向量的权重系数矩阵;bt表示第t个特征向量相对应的偏移量。
然后将注意力权重概率化,通过softmax 函数生成概率向量 αt,公式如下:
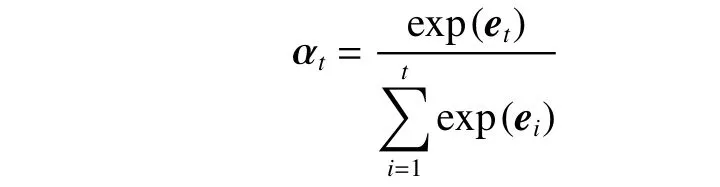
最后,注意力权重配置。将生成的注意力权重配置给对应的隐层状态St,使模型生成的注意力权重发挥作用,Y是最终输出的状态向量,为St的加权平均值,权值是 αt,公式如下:
2.2 正共享损失函数
在交叉熵损失函数中通过引入一个额外的正则化因子强调正类、负类的区别,构造正共享损失函数PSL,且给样本数少的正类更高的权重,以减弱不平衡,更好地区分各类异常与正常的生产状态,提高识别异常工况的准确率。
训练CNN-BiGRU-Attention 网络的目标是对异常工况特征进行提取,最大化识别异常工况的概率,这是通过最小化交叉熵损失函数实现的。给定一个包含m个样本的训练集:是第i个样本,y(i)∈{0,1,2,···,K}是它的标签。y(i)=0表示x(i)是负样本,y(i)=k>0 表示x(i)是正样本且x(i)属于第k种工况。表示Softmax层的输出,x(i)分类为j的概率(为)
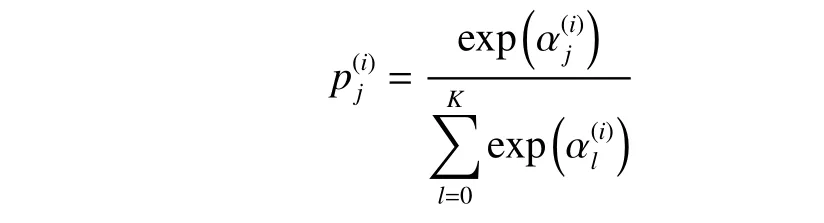
损失函数如下:
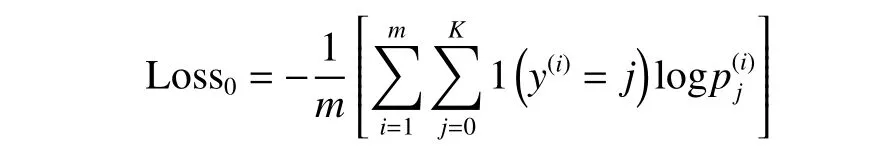
标准交叉熵损失函数会平均惩罚每个类的错分类误差。但在实际情况下,将正样本分类为错误的非零标签并不是重大错误,因为仍将其识别为异常。也就是说,异常类间的分类出错一般可以忽略,但异常和无异常间分类出错是不可容忍的,即应更关注零标签和非零标签之间的错误分类导致的损失。为此,引入了额外的正则化因子,增加了异常工况错分类到正常和正常错分类到异常类的损失。改进后的损失函数如下:
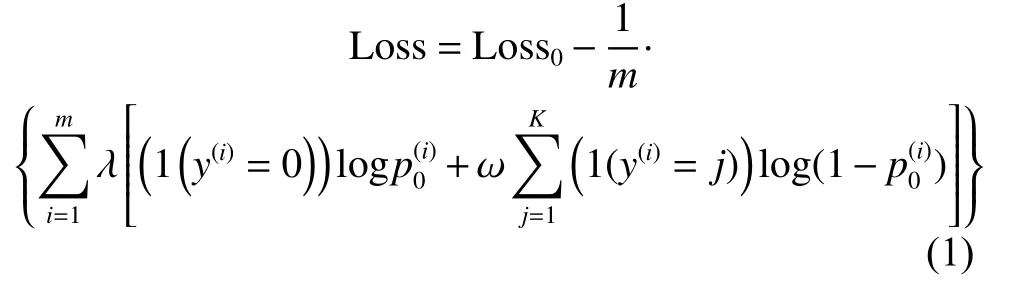
式中:λ为控制参数。当 λ趋向于0 时,式(1)为标准交叉熵损失函数;当 λ足够大时,区分不同异常工况的效果变弱,式(1)变为解决二分类问题的损失函数,旨在识别异常工况和正常生产数据。实验中,默认设置 λ =1。在实际情况下,我们更关注能不能识别出异常工况,而不是异常工况间被错分类的概率,因此引入的正则化项中各正类别的损失在其他正类间共享,称式(1)为正共享损失函数。
异常工况样本数少,数据集中正样本数远小于负样本数,数据不平衡,因此为正类项引入参数 ω,ω为负样本数与正样本数的比值,旨在减弱不平衡,公式如下:
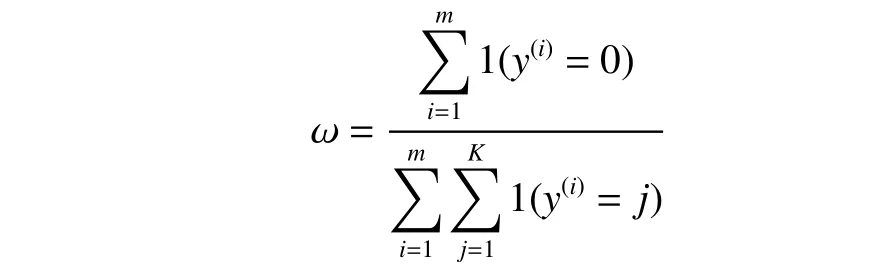
通过以上这两个措施,从而让CNN-BiGRUAttention 模型学习到更加具有辨别力的特征。通过标准反向传播来更新网络参数,Loss0为标准交叉熵损失函数,其导数已在文献[16]中提供,损失函数中第二部分的偏导数计算如下:
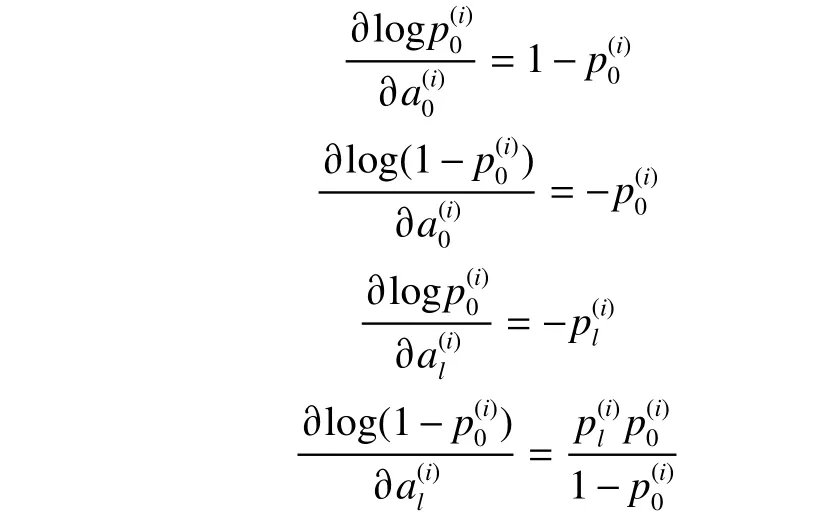
正共享损失函数的偏导数计算如下:
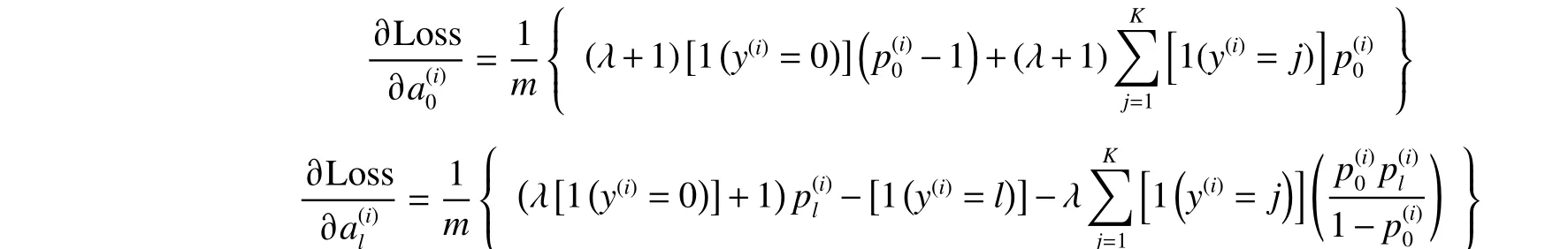
3 实验与结果分析
3.1 数据集描述
本文使用的数据集来源于胜利油田若干采油厂上百万条抽油井生产数据。原始的数据包括井组相关资料、日常管理资料、实时生产数据、示功图采集数据、功图分析数据、工况日志数据和管柱等资料,时间范围是2019~2020 年。井组相关资料主要存储单井基础信息,包括井号、井别、地质储量、对应的注水井配注量等数据资料;日常管理资料、实时生产数据、示功图采集数据和功图分析数据主要存储动态示功图及动态参数,如上下行电流、热洗周期、日产液量、日产油量、含水等;工况日志数据主要存储异常发生的井号、时间、工况类型、治理措施等;管柱资料主要存储管柱图、泵效、泵挂深等资料。以上数据在实际使用时往往存在问题:1)数据存在缺失、无效波动、重复值;2)数据时间段不连续;3)工况标签缺失等。因此,为提高工况预警的准确性和精度,在建立异常预测模型前需进行预处理,得到数据质量较高的数据集。
3.2 数据预处理
初始油井实时数据通过缺失值填写、光滑噪声数据、删除重复数据、去除无效波动、数值规约、切片等手段预处理,共保留135个特征字段。在数百个工况属性中,由于许多工况属性具有相似的公式和表达式,这些属性之间相关性很高,去冗余后保留38个特征字段。考虑到油井异常会导致示功图载荷和面积有较大变化,对示功图进行特征量分解,获取功图面积、载荷差、载荷比3个新的特征,同时构造工况标识字段,泵漏标记为1,管漏标记为2,正常标记为0。原始数据经过预处理后,得到样本数据集,共包含41个特征参数和1个目标参数。将异常工况类(含泵漏、管漏)统称为正类,无异常统称为负类。预处理后的样本情况如表1 所示,正负类样本极不平衡。划分数据集中70%作为训练集,30%作为测试集。
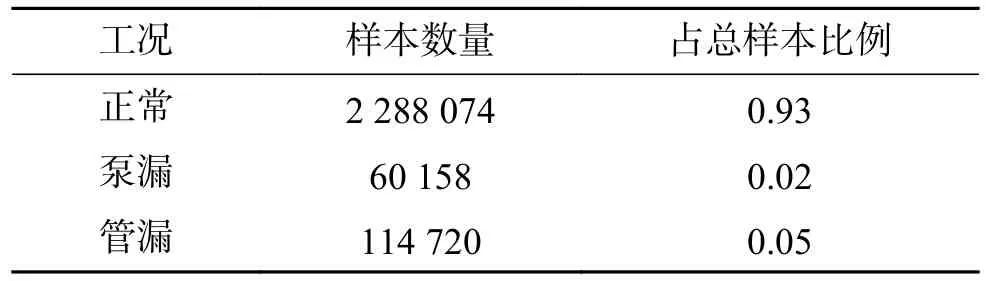
表1 预处理后的样本情况Table1 Sample condition after pretreatment
3.3 实验设置
本文实验在服务器下进行,硬件设备CPU 型号为Intel(R)Xeon(R)CPU E5-2630L v3 @ 1.80 GHz,内存大小48 GB。实验环境为Python3.8,借助Keras2.4.3 搭建神经网络,后端使用TensorFlow 2.4.0。
实验参数设置如下:卷积核大小设置为5×5,步长为1,隐藏层的数量为1,隐藏层单元数为128,隐藏层丢包率为0.5。学习率为0.01,BiGRU 的时间步长为8,隐层单元数为64,批次大小为128,迭代次数为50。
3.4 评价指标
3.4.1 对比度得分
可以通过测试集上每个样本的分类准确率来验证模型的有效性,但是对于检测问题,正样本和负样本之间的对比度更能反映模型性能。因此,定义对比度得分作为度量,为测试集,是模型把分为负类的概率。对比度得分定义如下:
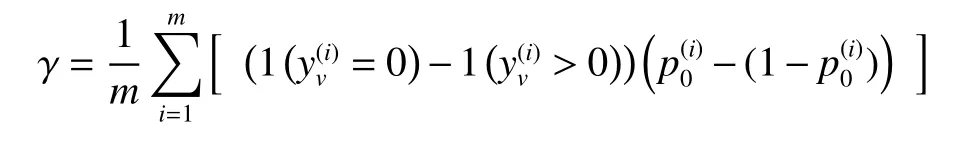
γ的取值范围是−1~1,表示模型识别正样本、负样本的能力。
3.4.2 混淆矩阵
混淆矩阵如表2 所示。TPm表示正确预测的m类阳性样本数,Emn表示m被归类为n的错误分类样本数。FNm表示m被归类为其他类的错分类样本数,FNA=EAB+EAC,FNBC可同样计算得到;FPm表示其他类被归类为m的错分类样本数,FPA=EBA+ECA;TNm表示正确预测的m类负样本数,TNA=S−FNA−FPA−TPA。真阳性率TPRm表示所有实际为m类的样本被正确判断为m类的比率,公式如式(1)所示;假阳性率FPRm表示所有实际为其他类的样本被错误判断为m类的比率,公式如式(2)所示。
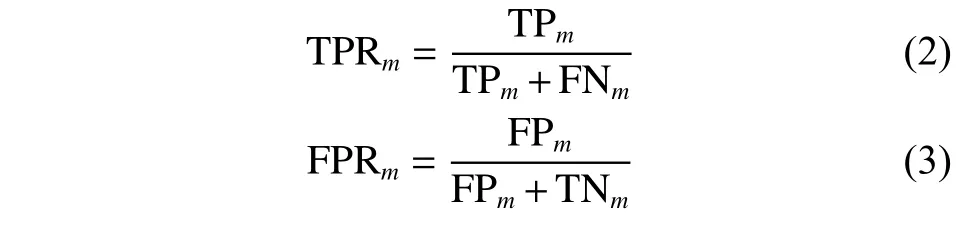
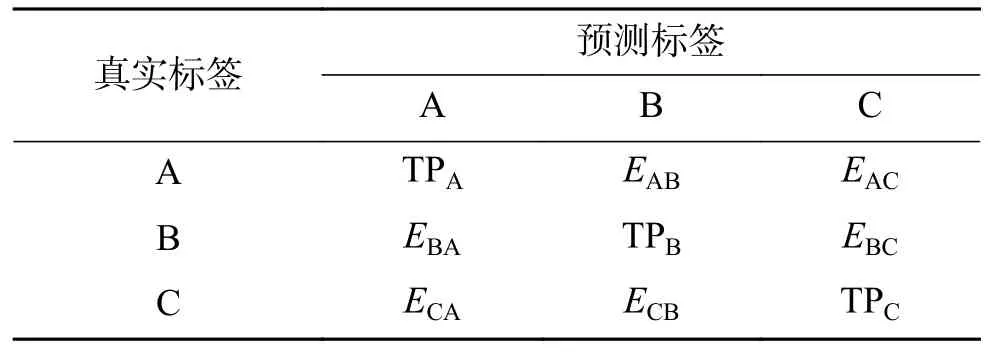
表2 多分类的混淆矩阵Table2 Confusion matrix of multi classification
为了评估CBiA-PSL 模型,本文选择了3个指标:AC(准确率)、DR(检出率)和FR(错误报警率):
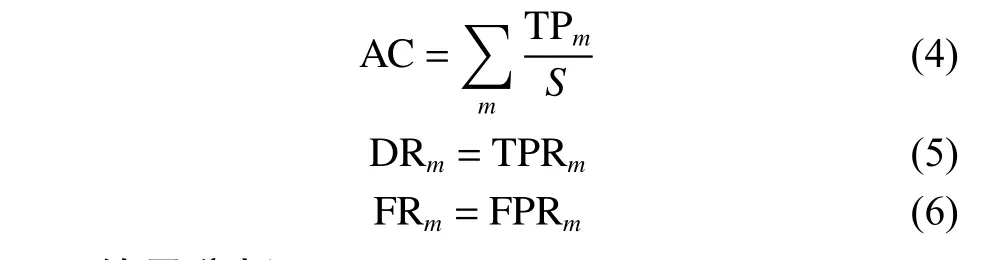
3.5 结果分析
将学习速率设置为0.01,对损失函数执行随机梯度下降(SGD),50 次迭代后,采用标准交叉熵损失函数(Loss0)的CNN-BiGRU-Attention 模型的对比度得分为0.58,采用正共享损失函数PSL(Loss)的CNN-BiGRU-Attention 模型的对比度得分为0.63,有0.05 的提高,如图7 所示。这表明引入正共享损失函数可以提高异常类的检出效率。
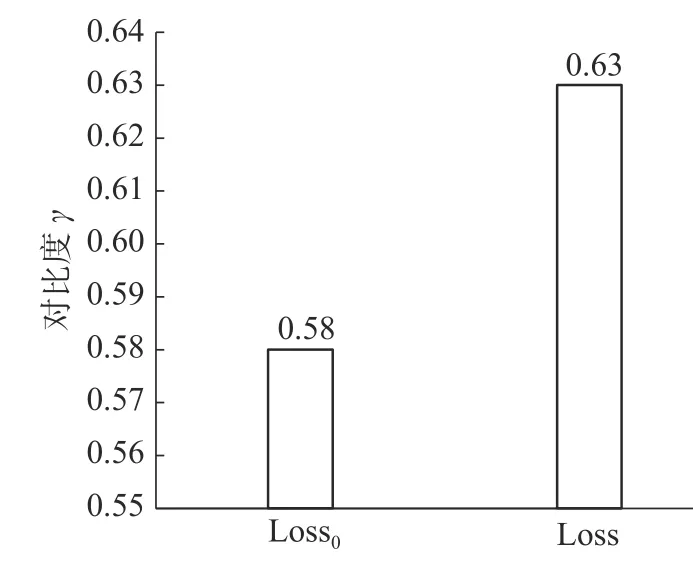
图7 对比度得分Fig.7 Contrast score
第2个实验将CBiA-PSL 与其他5 种用于异常工况检测的机器学习/深度学习方法进行比较,包括:CNN-BiGRU-Attention、卷积神经网络CNN、双向长短时记忆网络BiLSTM、双向门控循环单元BiGRU、随机森林RF。各模型的AC 值、DR 值、FR 值如图8、表3、表4 所示,CBiA-PSL模型训练过程的损失如图9 所示。从图8 可以看到,CBiA-PSL 的AC 值为88.2%,高于其他5 种方法。此外,分析表3 可以得出结论,CBiA-PSL 可以提高少数类(泵漏、管漏)的DR 值,且正常类的DR 值保持不变,即提高了异常类的检出率。分析表4,少数类的FR 值有时为0,式(1)~(5)表明该方法未检测到异常类别时,DR 和FR 均为0。表4 表明本文提出的方法可以将异常类的错误报警率维持在较低水平。因此,本文所提出的方法CBiA-PSL 可以在总体准确率较高的情况下,提高异常类的检出率,并降低错误报警率。

图9 模型训练集的损失图Fig.9 Loss graph of model training set
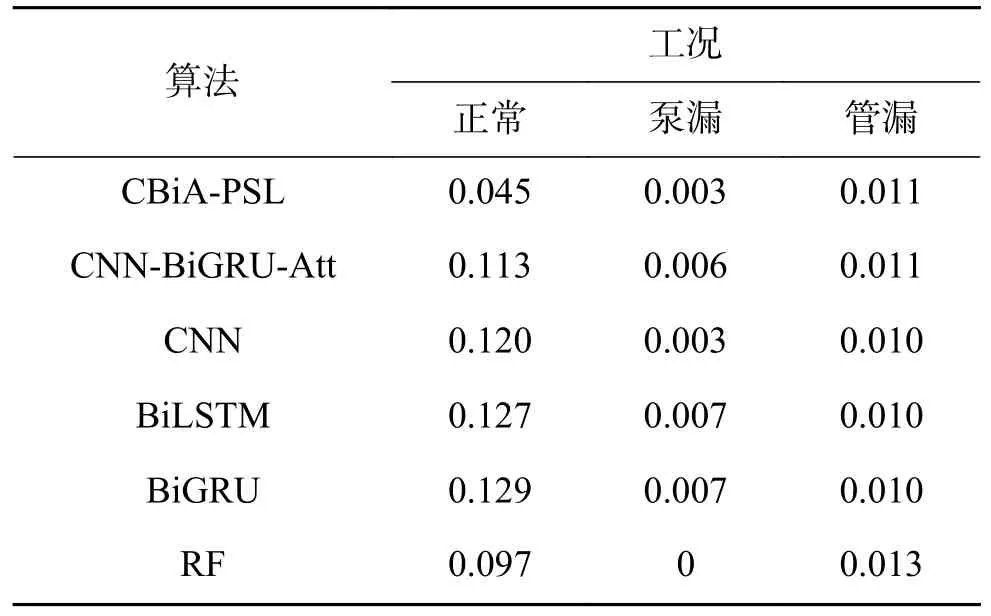
表4 各模型的FR 值Table4 FR value of each model
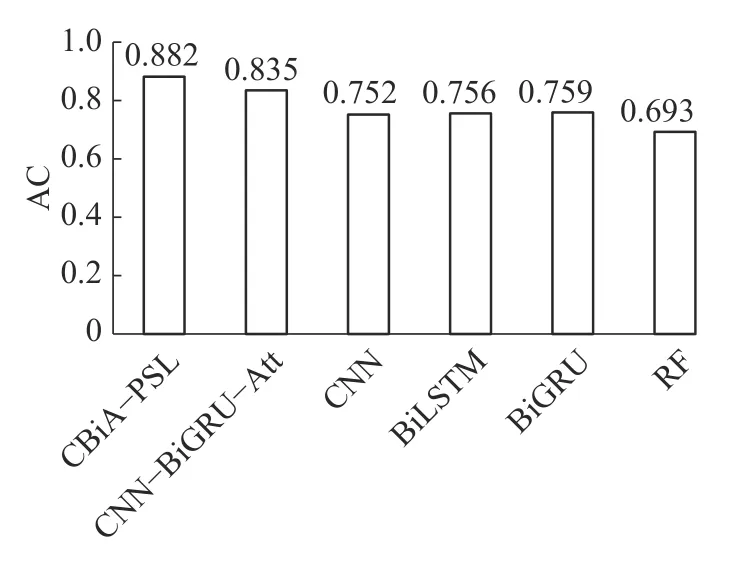
图8 各模型的AC 值Fig.8 AC value of each model
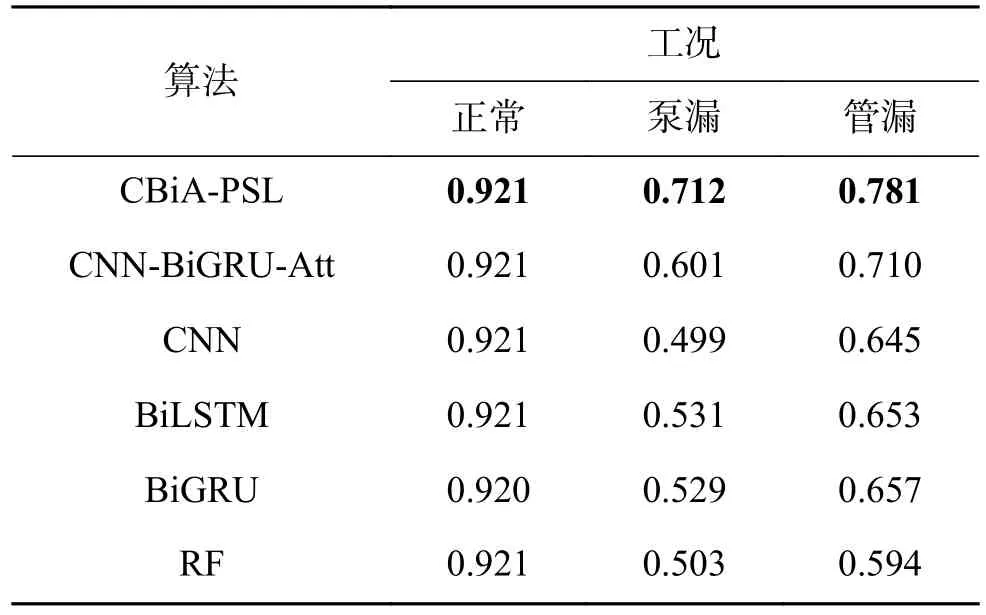
表3 各模型的DR 值Table3 DR value of each model
4 结束语
本文基于CNN-BiGRU 联合网络特征学习模型,使用改进的CBiA-PSL 网络进行抽油井异常工况预警,利用CNN 局部特征的强学习能力提取工况样本灰度图像的局部特征,BiGRU 提取全局前后向特征并加强CNN 池化层特征的联系,加入注意力机制获取样本中的重点特征,降低噪声特征的干扰,从而完成有效特征筛选,提高模型对异常工况特征的学习能力。除了将CNN-BiGRUAttention 网络用作特征提取器外,针对工况样本数据集不平衡的问题,本文提出正共享损失函数PSL,该函数强调异常类和非异常的损失,而不是每个子类的损失,有助于学习比Softmax 损失函数更多的判别特征,且给样本少的正类更高的权重,以学习参数,减弱了不平衡,有助于更好地识别异常工况。
实验结果表明,用本文提出的CBiA-PSL 网络模型进行异常工况预警,可以取得较高的AC值、DR 值,较低的FR 值,即本文提出的CBiAPSL 方法能有效处理不平衡数据集,并且对于异常类和整体的预测都有较高的精度。未来的工作如下,由于预警时间也是异常预警的关键,因此在保证准确率的同时必须确保模型能满足异常预警的时间要求,同时优化网络模型参数,进一步提升模型对异常工况预警的精度。
