Keras神经网络预测大乐透彩票的实现
2022-04-20高楷程
高楷程
(东北石油大学,计算机与信息技术学院,黑龙江,大庆 163000)
0 引言
随着大乐透彩票的普及,彩民的购买热情越来越高,反映非常热烈。在该玩法受欢迎的同时, 各种预测的方法都出现了。目前, 出现预测方法都是基于统计理论提出的, 如奇偶比、遗漏期K值、区段出号码数字、数字频率的次数等。因为采用的是统计方法, 具有一定的偶然性,其结果并不完全可靠。本文采用Keras神经网络搭建预测模型,进行训练之后预测下一期的号码,从结果上来说提高了中奖的概率。
1 预测
首先,大乐透的中奖序列为35选5+12选2,每个球的选取是随机的,因此,想使用机器学习精准地预测出获奖序列是很难的。可以类比于机器学习选股票。目前有很多机器学习应用在股票选择上的例子,并能够实现盈利[1-3]。但机器学习选股和选彩票有几点显著差异:股票的涨跌存在各种因子、K线、舆情等参数用于评估和训练,但彩票的中奖序列是随机产生的,可供参考的可能仅有时间上的序列的概率分布。
所谓的概率分布指的是,假设彩票的中奖序列是完全随机产生的,序列中每一个球在一次开奖过程中出现的概率应该是相同的(前区和后区要分开算),并且从时间序列上来看,连续的多次开奖中,每一个球的出现与否也应当满足某种规律(当然,这是宏观上讲,实际上肯定不会严格满足,但能够体现某种趋势或倾向)[4-6]。
2 数据
2.1 获取数据
在江苏体彩网获取数据,文件格式为csv。如图1所示。
2.2 处理数据
虽然数据已经获取到了,但显然这个数据无法直接应用于训练。需要对数据做一下简单的处理。
本文为中奖序列中的数字(或者说球)编号,从前往后它们的编号分别为1到7,其中1~5是前区的5个球,6~7是后区的2个球。
同理,对于给定的课题,假如我们有近一年以来的气温数据,需要预测明天的气温,一般的思路是用循环神经网络做序列的预测。假设按顺序给这近一年来的气温分别编号为1~365,其中t1表示第一天的气温,t365表示今天的气温。
气温的变化应该是有规律的(一般情况下),让机器来学习这种规律。选定一个合适的时间长度,比如30天,然后将这30天的连续数据作为输入(x),将接下来一天的气温数据作为输出(y),就构成了一条数据。然后使用长度为31天的扫描框,对一年的数据进行一次遍历,就得到了一组数据集。用它进行训练,完成后,输入30天前到今天的气温序列,即可预测明天的气温。
本文的课题和预测气温差不多,使用连续若干期的球1数据来预测下期球1的分布概率,球2~球7都是同样的方法。单从输入输出看来就是这样,实际上实现起来肯定会有更多的处理和优化[7-9]。
和预测气温的例子不同,气温预测时只有一种因子参与,就是当天的气温值。而在这个例子里,输入的是7个球,输出的也是7个概率分布,所以这是个多输入、多输出的模型。
3 编写模型
模型示意图如图2所示。

图2 模型示意图
使用连续若干期的球1数据来预测下期球1的分布概率,球2~球7都是同样的方法,但因为这些球本身并不独立,比如球1开出了3,球2~球5就不可能再开出3,而是在剩下的里面选。所以我们在预测最后的概率之前,对球1~球5的中间层进行了拼接,再分别预测,这样模型可能会学习到每一期中前区的球之间的某种关系。对于球6和球7,也做了类似操作。
球1~球5在前区,球6~球7在后区,两者没什么关系,所以这两部分之间没有进行拼接。
最后的输出预测层选择了Softmax,严格来说,Softmax对于这个问题来说,并不是一个很好的选择,因为开球应该是条件概率,比如球1开了5之后,开球2的概率计算应该是球1=5条件下的条件概率,球3~球5同理。但最终还是选择了Softmax,原因一是Softmax实现起来更加简单,二是模型输出本身设计的就不是预测头等奖的完全正确序列,而是尽可能多地选中球。
4 工具方法
4.1 训练
数据和模型都已经准备完毕,可以进行训练了。但这个模型不同于一般的分类模型,因此选择回测方法评估模型的效果。
划分一部分数据(比如90%)作为训练集的训练模型,剩下的10%作为测试集。划分是按照时间顺序划分的,保证后面10%的数据绝不出现在训练集的结果数据或过程数据中。在使用训练集完成模型的训练后,对测试集进行预测,并按照预测结果购买彩票,计算支出和奖金,以最终的净收入的多少来衡量模型效果[10-13]。
按照训练集∶测试集=9∶1的比例划分数据集,在训练集上训练模型,并使用测试集回测。训练60轮,每一轮训练完成后都会保存模型的参数,并进行回测。在训练结束后,将所有回测结果按时间顺序绘制出折线图和趋势线,如图3所示。

图3 预测趋势图
多次运行的结果可能差距明显,其原因分析如下。
(1)训练数据的原因
彩票选号其实是没有严格的规律可言的,否则,哪怕只有极少数一批人能稳定猜中,这个游戏也没法长期运行。如果非要强行说个规律出来,那也只有长期下来的概率分布能勉强凑合。但首先大乐透也只开了1 000多期,数据有限,其次概率这种东西从字面上来看,就知道它不是固定的(哪怕出现的概率最高,也不一定会出现)。这样,当模型的随机初始权重不同,训练数据又很难找到特别清晰的规律时,模型学习到的东西也会产生相应的区别,它们分别倾向到了概率分布的不同表现形式。
(2)回测时选择彩票号码的原因
选择号码时,同样不是一定选择出现概率最大的球,只是出现概率越大,被选中的概率就越大,这样保证了结果的多样性。
两者综合起来,两次的运行结果可能天差地别,但从多次运行的整体来看,还是有一定规律的。
训练一定次数之后,亏损金额大多分布在[-1 200,-900]左右,少数情况下在(-900,-400],极少数甚至还有盈余。
大部分都满足“随着训练次数的增加,损失逐步减少”的规律,即图中拟合的一次函数(一条斜直线)因为回测的随机性,单点结果是会出现起伏波动的,所以使用趋势来衡量整体结果会更加合适。
综上,模型应该起到了一定作用。
4.2 基线模型
基线模型指的是一个最基础、最简单的模型,它是从概率的角度上来说随机性最强的一个模型。
一般基线模型都是完全随机的。从前区选出5个球,后区选出2个球,每个球都随机选择,这就是基线模型。类似于彩票中心的机选方案。
模拟多次购买彩票来实现基线模型的预测亏损,模拟结果如图4所示。
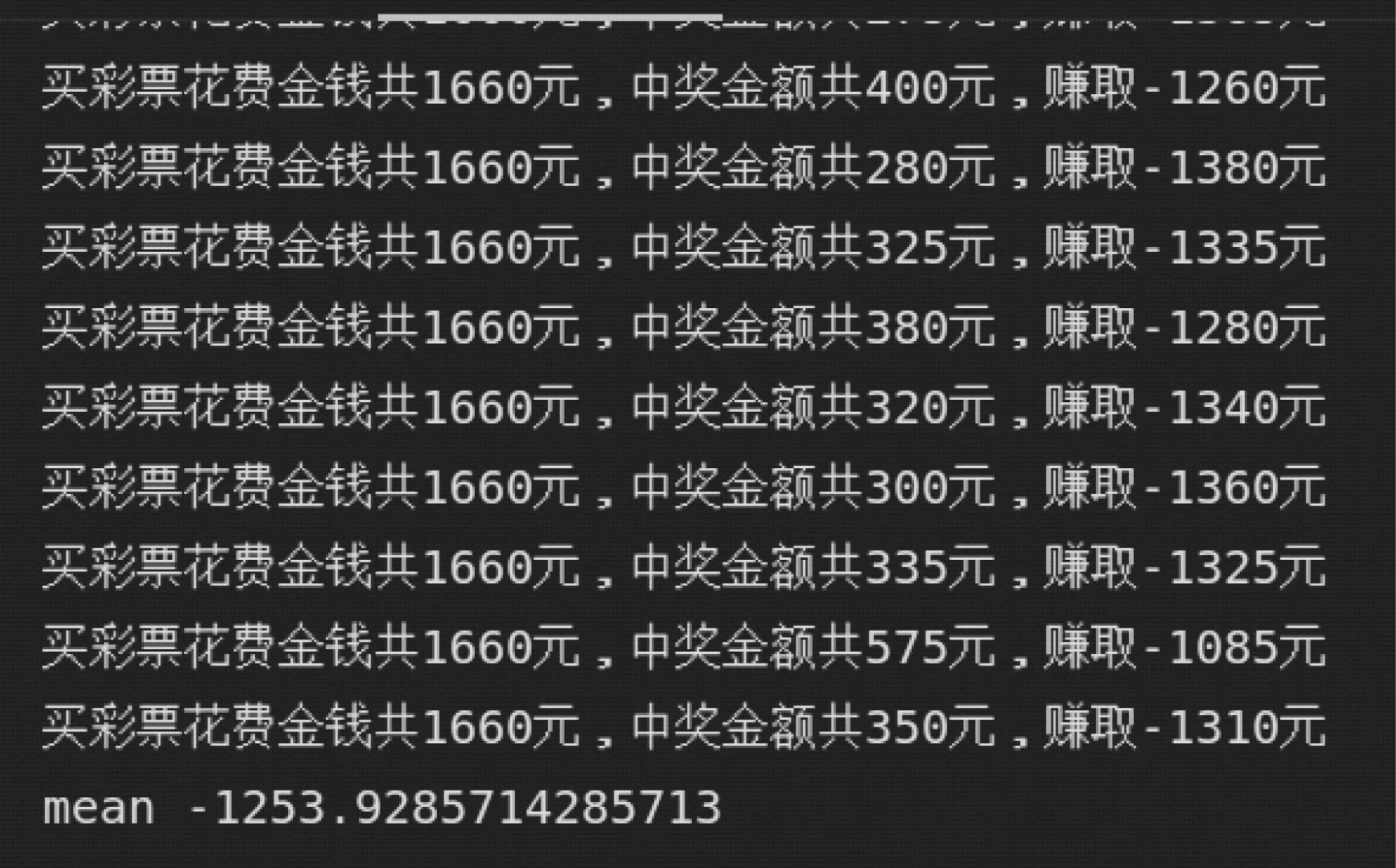
图4 基线模型预测结果
多次运行可以发现,最后的平均值绝大多数落在[-1 400,-1 200]之间,其中又以-1 250左右最多。少数亏得更少或更多,极少数能够小赚。
5 预测下期彩票序列
如果准备利用模型买彩票,可以分为2种情况。
(1)选择在上一步训练好的某个模型参数,加载这个参数,输入倒数第MAX_STEPS期到最近一期的数据序列,预测下一期序列。
(2)使用完整数据集作为训练集,重新训练模型并保存。然后和第一种情况一样,加载模型参数,输入倒数第MAX_STEPS期到最近一期的数据序列,预测下一期序列。
两者的区别在于:
第一种情况,有回测数据,在选择训练好的参数时有一定的参考;第二种情况,使用了完整数据集来训练,就没有回测数据可参考了。
第一种情况的训练数据少于第二种的训练数据。按理说更多的训练数据通常会产生更好的效果。
运行一下,模型输出如图5所示。
6 总结
本文通过神经网络算法来进行大乐透彩票预测实验,从概率的角度说明预测的可能性,分别介绍了数据的获取、模型的搭建以及进行实验网络的训练实验。
将算法应用在大乐透预测上,并且获取最近100期开奖记录作为样本数据,通过实验发现能在一定概率上提高中奖率。对其他彩票建立预测模型也有一定的参考价值。
