基于Flask框架的社交网站数据爬取及分析
2022-04-20余晓帆朱丽青
余晓帆, 朱丽青
(杭州网易云音乐科技有限公司,浙江,杭州 310052)
0 引言
随着互联网的飞速发展,人们在网上寻找信息的渠道越来越多[1-2]。互联网用户只能从少数门户网站获取知识和信息的时代已经一去不复返了。更专业、更详细的信息来源逐渐形成。与以往的网站相比,新的信息渠道主要有2个突出特点。一个特点是流动性和碎片化[3-4]。几年前,互联网用户只能通过一台通过电缆连接到互联网的个人电脑来获取信息。如今的互联网用户只要拥有一部带有数据服务的普通手机,就可以随时随地获取丰富的信息。另一个特点是用户参与度增加[5-6]。过去,互联网用户只能被动地接收门户网站提供的信息和服务,很少有机会产生或传播信息。但是现在,越来越多的用户生成内容(User Generated Content,UGC)服务被越来越频繁地使用[7-11]。其中,社交平台Facebook和Twitter是典型的由用户创建所有信息的平台。例如,视频网站AcFun和BiliBili上的所有视频和弹出字幕都是由用户生成和上传的。
在这些平台中,社交问答平台发展尤其迅速[12]。社交问答平台是指用户可以以特定格式发布特定主题问题的平台。社交问答平台允许所有用户通过浏览平台、回答问题、发表评论、投票赞成或反对答案等方式参与在线讨论。同时,大多数用户认同的答案也将在平台中凸显出来。在社交问答社区,如知乎,每分钟都会有很多热门话题和新闻被讨论,甚至被创造出来。近年来,许多新闻舆论的发源地也不再是传统媒体,而是社会问答社区。究其原因,是新闻和意见虽然粗糙但真实,没有经过新闻人的加工和润色。此外,用户可以表达自己的真实想法,不必担心自己的话是否会被曲解或修改。
因此,有必要对社会问答社区的数据进行采集和分析。本文的主要创新点如下。
(1)选择一个适合本研究的问答平台,并且能够扩展到其他类似平台。分析该平台数据采集的难点,提出实现数据采集系统的解决方案。系统包括用户信息存储模块、高度匿名、高可用的代理维护模块、节点采集解析模块和数据存储模块,在不受平台限制的情况下快速采集数据并格式化存储数据。
(2)设计并实现热度分析与分级模块。基于Echarts项目,设计历史热度显示模块和实时热度显示模块,实现历史热度和趋势热度的实时显示。
(3)利用提出的数据爬行模块和热度分析显示系统,对31 520个规范化独立主题的数据和979 815个问题的实时数据进行爬行。在此基础上,展示该平台的历史和实时热度分析。实验结果表明,该系统完全达到了设计目标。
(4)对所提出的数据采集系统和热度分析显示系统进行分析和总结,为今后的研究提供了参考和方向。
1 设计和部署
1.1 系统架构
图1显示了系统的总体结构,包括代理采集模块、数据爬虫模块(由节点采集子模块、历史最热门问答采集子模块和最新问答采集子模块组成)、数据存储模块、热度解析模块和热度显示模块。数据爬虫模块和热度话题显示模块是系统的关键模块,其他模块的设计支持其运行。
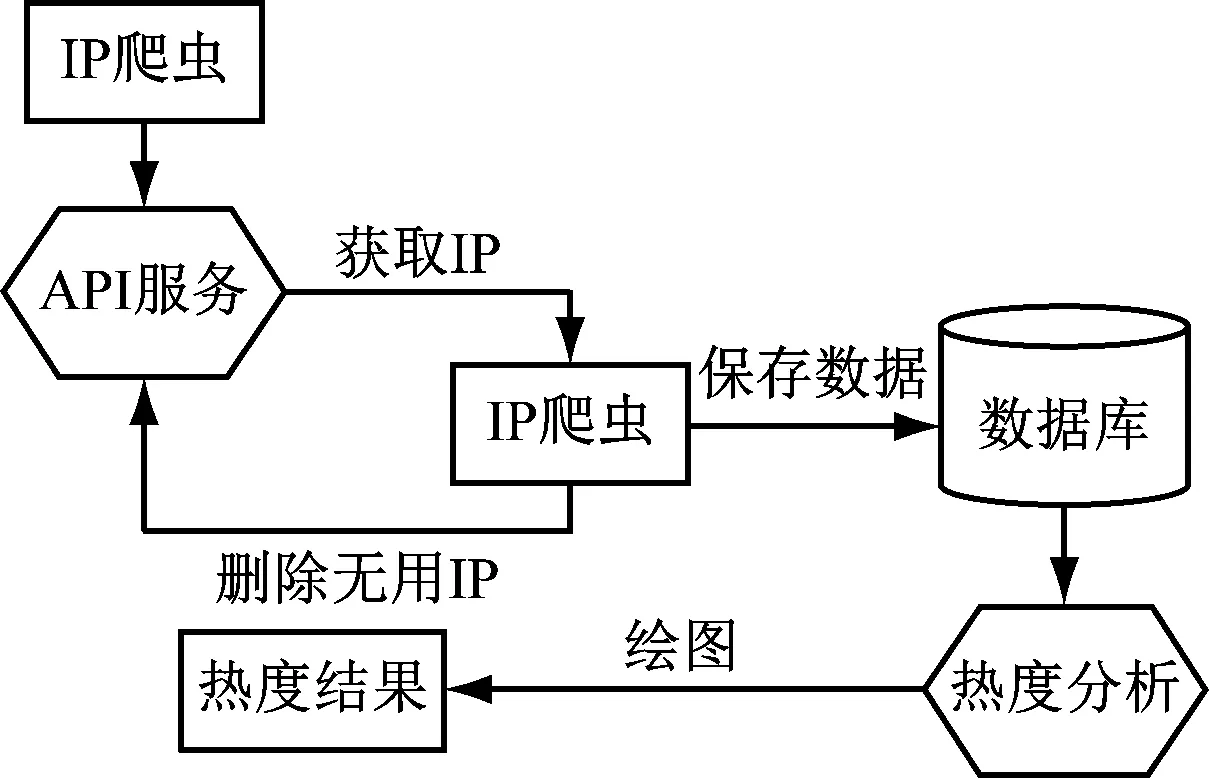
图1 系统架构
1.2 代理模块
一些设计糟糕的数据爬取程序只追求高效率,而不考虑错误[13]。因此,它们可能会对目标网站造成巨大的资源消耗,如消耗过多的带宽、浪费服务器资源、泄露自己的数据等。为了打击数据采集程序的滥用,许多站点可能会限制每个IP的访问速度或次数。在这种情况下,数据爬虫程序将暂停一小段时间,然后继续爬取数据。当IP的次数或频率受到限制时,数据爬取程序需要确保每个IP的页面浏览量或频率低于网站允许的阈值。一个可行的解决方案是依次通过代理IP访问目标网站。因此,许多数据爬取程序需要建立和维护一个有效的代理IP池。
图2显示了本文使用的代理模块的结构,包括IP获取模块、IP验证模块、IP持久化模块和API模块。

图2 代理模块示意图
IP获取模块通过解析提供代理IP服务的目标网站的不同代理IP格式和页面格式,从5个代理源获取IP信息。
将在数据爬网两步后验证代理IP。首先,在数据爬行过程中,测试IP是否可用,以及它们的访问速度是否能满足我们的要求。
为了将它们与数据爬行模块集成,使用这些良好的IP作为快速数据爬行的API。本文使用Flask框架来创建代理服务。
1.3 Flask框架
Flask是用Python语言基于Werkzeug工具箱编写的一个轻量级Web开发的框架[14-15]。由于Flask本身就是相当于一个内核,其结构并不含有数据库抽象层以及表单特征,所以Flask体积很小。但是Flask具有非常强大的扩展性,用户可以自由选择和组合需要的功能。这也使得Flask变得灵活多变。这些特性让Flask框架一经推出就受到广大用户的喜爱。
Flask的工作流程如图3所示,在Flask中每一个URL代表一个是视图函数。当用户访问这些URL时,系统就会调用相对应视图函数,并将函数结果返回给用户。

图3 Flask的工作流程
2 数据采集与分析
2.1 数据集获取
数据爬行的总体效率往往会因过于耗时的数据采集(网络延迟、服务器效率低下、服务器错误、网络中断等)而降低。因此,需要同时打开多个线程进行数据采集。在编程时,设计了多线程异步从网站获取信息的程序,大大提高了信息获取的效率。
网页信息获取后需要进行解析。本文利用Beautiful Soup对采集到的信息进行解析。编译解析模块时,需要特别注意以下几个方面。
控制范围:为了避免被蜜罐检测到,只从指定的DOM获取数据。
一致性:考虑到解析到存储过程中可能出现的错误,每个解析的存储过程都是原子性的,这样,如果出现任何问题,就不会在数据库中重复存储数据。
2.2 热度分析
在对所有数据进行采集、解析和存储后,本文实现了热度分析模块,对目标网站的历史热度和趋势热度进行分析。
从订阅人气、订阅活动、订阅差异等3个维度对历史热度进行分析。
三维算法用如下式:
(1)
式(1)表示订阅普及度。它描述节点的普及程度,与订阅数量正相关。订阅受欢迎度最高的节点用作标准化所有其他节点的订阅受欢迎度的比例。
(2)
式(2)表示订阅活动。它的意思是以订阅数量为单位生成的节点的活动程度,与最高的点赞平均数(即该节点下获取的答案的点赞平均数)正相关。订阅活动最高的节点用作标准化所有其他节点的订阅活动的比例。
(3)
式(3)是订阅区分。它指节点关系中显示的节点区分程度,与节点订阅数正相关,但与其父节点和子节点的平均节点订阅数负相关。使用订阅差异最大的节点作为标准化所有其他节点的订阅差异的比例。
hisheat(n)=Kspsubpopular(n)+
Ksasubactive(n)+Ksdsubdist(n)
(4)
式(4)是历史热度算法,即订阅人气、订阅活动和订阅差异的加权平均值。
从趋势活动和趋势区分2个维度对趋势热进行分析。
(5)
式(5)表示趋势活动。它指节点此时的活动,与节点订阅数和此时讨论节点的平均间隔呈负相关。使用趋势活动最高的节点作为标准化所有其他节点的趋势活动的尺度。
(6)
式(6)表示趋势差异。它指节点在这一时刻的差异,它与讨论其父节点和子节点的平均间隔正相关,但与讨论节点的平均间隔负相关。使用趋势差异最大的节点作为标准化所有其他节点趋势差异的尺度。
历史热度与节点的趋势热度呈负相关,
treheat(n)=Ktatreactive(n)+Ktdtredist(n)
(7)
式(7)给出趋势热度算法,即趋势活动和趋势区分的加权平均值,去掉历史热。
具体热度分析算法如下。
算法:热度分析算法
输入:采集到的数据
输出:热度
1.利用式(1)计算订阅数量,得到订阅普及度
2.利用式(2)通过点赞数计算订阅活动
3.利用式(3)结合订阅数计算订阅区分
4.通过式(4)计算订阅普及,订阅活动,订阅区分三者的加权平均值的和,得到历史热度
5.利用式(5)计算趋势活动
6.利用式(6)计算趋势差异
7.通过历史热度与节点趋势热度利用式(7)计算得到趋势热度
整个程序框图如图4所示。

图4 程序框图
3 实验与评估
3.1 实验环境
整个实验环境部署在一台台式电脑上,该电脑配置为Windows 10、64位操作系统、英特尔I7 2.7 GHz处理器,32 GB内存。整个实验用Python 3.0语言实现,实验设计过程中主要使用了百度开源纯JavaScript的图表库项目Echarts。
3.2 节点数据
共对31 520个正则化节点信息进行了数据爬取,共有613 332 546个订阅,每个节点平均有19 458个订阅。在这些节点中,排名前十的分别是“电影”“心理学”“美食”“设计”“自然科学”“商业”“健身”“经济”“旅游”“时尚”。前十大节点的总订阅量超过500万,订阅量最大的节点关注度超过1 000万,可见目的地网站用户数量众多,超过千万。
3.3 热度回答
获得了目的地网站的384 884条答案信息,共被青睐713 932 419次,每个答案的平均得宠次数为n,其中得宠次数最多的前十名分别分布在“美食”“文学艺术”“生活”“性健康”“组织”“制度”“文艺”“失踪”“生命”“交流”(因为答案可能包含多个节点,所以这里只显示其中一个节点)。
3.4 讨论时间间隔信息
以平均2 963 021 s的讨论时间间隔获得目的地站点上473 117个讨论时间间隔信息(即节点最新消息发布时刻与数据获取时间的间隔),其中讨论最活跃的前十个节点分别为“生命”“文化”“实体”“社会”“东亚”“学科”“人”“中国”“亚洲”“大学”。
3.5 历史话题
图5显示了历史热度话题的结果,其中有4条曲线,分别是订阅热门度曲线、订阅活动热门度曲线、订阅区分度曲线和最终历史热度话题热门度曲线,以10个历史热度为横轴(按历史热度的倒序排列),分数为纵轴。从图5可以看出:日常行为、生活以及求职类的4条曲线波动范围较大,其中最大的是日常行为类话题;心理学类话题的曲线波动较小;其他热度话题的曲线变化都较为相似。
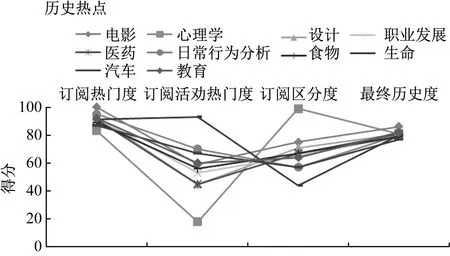
图5 历史热度话题
3.6 趋势分析
图6显示了即时热门话题的结果,其中有3条曲线,分别是活动趋势曲线、区分趋势曲线和最终趋势热门话题曲线。从图中可以知道,年度库存的将会成为人们最终关注的热度。对于2019年的话题,由于是新增话题所以是没有区分趋势和活动趋势的。
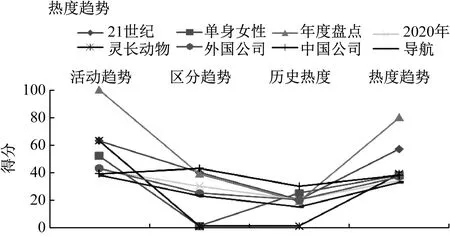
图6 即时热门话题
4 总结
随着互联网的不断发展,社交问答平台已经成为一个新的具有吸引力的平台,用户可以在这个平台上讨论各种主题,也可以相继创造热门话题甚至新闻,以热度分析为维度,对目标社交问答平台进行数据采集和热度分析。采用多种设置和策略保证数据爬行的稳定运行,提出了用于社会问答平台热度分析的不同调查维度和多个调查指标。本文共获得目的地31 520个规范化节点信息和847 205个相关问题,并对其历史热度和趋势热度进行了分析。分析结果表明,调查维度和指标能够较好地反映目的地的热度状态。
在本文工作的基础上,还值得开展以下工作。
虽然经过多次处理和改进,但本文的爬行率仍然达不到理想的效果,一次完成所有数据的爬行需要很长的时间。由于数据爬行有时间跨度,记录信息的时间不尽相同,与实时数据相比会产生一些错误。最理想的目标是进行实时分析。可行的解决方案包括:寻找新的数据接口,提高数据访问速度;目的地开放的API,可以实时获取一些开放数据的结果等。
作为社交问答平台的内容创造者,用户对热度的产生和传播有着巨大的影响。由于目的地站点策略不允许获取此维度,因此本文不进行相关用户数据的爬行和分析,如果未来相关策略发生变化,则可以在此维度进行探索。
