金融市场极端风险状态预测模型及其应用
2022-04-20肖艳丽向有涛
肖艳丽 向有涛


















摘 要:随着经济全球化发展和国内金融市场的逐步开放,中国金融市场也遭受着来自国外金融风险的威胁与挑战。充分考量中国金融市场部分特征化事实,结合中国的现实情况,以中国金融市场为研究对象,选取了13个代表性指标,利用2005年1月—2021年6月的数据构建了中国金融市场风险指数,并且通过事件匹配方法检验指数识别作用的有效性。進一步,运用XGBoost模型预测中国金融市场极端风险,采用多种评价指标将其与传统的SVM、GBRT、RF和MLP模型进行比较研究,并利用配对样本T检验和弗里德曼检验对各个模型预测效果的差异进行显著性检验。最后结合SHAP和LIME方法展示了不同特征指标对中国金融市场风险的贡献度。实证结果表明:(1)所构建的指数较好地符合了我国金融市场风险变化的实际情况;(2)XGBoost预测模型对于极端金融风险样本识别能力较强、准确性较高,与其余模型相比,其预测性能更加优异,而且具有明显的统计检验意义。(3)利用Shapley和LIME方法挖掘出了影响中国金融市场风险的主要因素及其时变特征,且阈值效应的发现有利于金融部门对金融市场风险进行针对性的审慎监管。
关键词:金融市场风险;压力指数;极端风险预测模型;极端梯度提升树;Shapley值;可解释性
中图分类号:F832.5 文献标识码:B 文章编号:1674-2265(2022)03-0008-10
DOI:10.19647/j.cnki.37-1462/f.2022.03.002
一、引言
自20世纪以来,世界金融市场一直处于动荡发展中,连续不断的金融危机给有关国家及世界经济带来了严重影响。我国正处于向经济高质量发展的转型阶段,金融系统与实体经济存在结构性矛盾问题,因此,中国金融市场安全面临来自内部的压力和外部环境的冲击(郭娜等,2020)[1]。在全球金融一体化和数字信息技术的不断发展下,国际经济和金融环境愈发复杂、面临更大的不确定性,金融风险和危机的传染性增强。在错综复杂的外部环境和内部条件下,对我国过去十几年的金融风险演变过程、波动情况进行评价分析,测度金融市场风险和构建可靠有效的极端风险预测方法,具有重要的现实价值和意义。
从国内外研究来看,在金融市场风险的度量上,主要采取三种方法:第一种是模型法,主要通过DD(银行挤兑)模型、GARCH(广义自回归条件异方差)模型和NN(神经网络)等方法对金融市场风险进行刻画,评估一个国家发生金融风险的可能性(范小云等,2013)[2]。第二种是早期的信号法,借助已经发生过金融危机的国家的经济形势来研究风险发生的共同信号指标,但信号法作为一种借鉴他国的经验而建立的风险识别与预警方法,具有一定的片面性,难以适用中国这种没有真正爆发金融危机的国家(许涤龙和陈双莲,2015)[3]。第三种是金融压力指数(FSI)法,最早由Illing和Liu(2006)[4]提出,该指数通过度量给定时期内金融压力来分析市场风险的相对水平,可以克服指数时滞问题,综合反映金融市场的风险情况。如Manamperi(2015)[5]通过对不同的FSI的比较研究,发现所有指数均能够比较好地描述金融市场风险的变化状况。马勇和黄科(2019)[6]从货币、债券、股票、外汇和银行部门选取了10个代表性指标构建了FSI,结果显示其对宏观经济周期具有良好的预测能力。另外,丁岚等(2019)[7]结合CRITIC和标准差倒数权重法构建静态和动态权重的中国FSI。与前两种方法相比,金融压力指数法能够对包含银行、股票和债券等在内众多金融市场进行综合测度,具有计算方法灵活和计算结果直观的特点,在金融市场风险状态的识别上具有比较明显的优势(Louzis和Vouldis,2012)[8]。
鉴于上述,本文采用FSI对我国金融市场风险进行刻画和识别,进而为下文金融市场极端风险预测模型的构建奠定基础。极端金融风险预测一直都是学术界关注的焦点与热点,到目前为止,国内外学者已经运用Logit(逻辑回归)、NN和SVM(支持向量机)等对极端金融风险进行了有关预测研究(Chatzis等,2018)[9],并取得了不错的效果。但是也存在着假设条件苛刻、过拟合和易陷入局部最小等问题。其中SVM模型具有优越的泛化能力,被广泛运用于风险预测研究中,取得了良好的预测效果(温廷新和孔祥博,2020)[10]。Ahn等(2011)[11]通过实证研究发现,SVM模型在金融市场风险预测效果上要优于NN模型。然而,如果将其用来预测金融市场极端风险状态,可能存在预测效果较差的问题。原因在于SVM模型在面对极端金融风险这种非平衡样本时,其决策分类超平面会偏向少数样本,导致模型容易出现预测失误(王鹏和黄迅,2018)[12],而XGBoost(极端梯度提升树)作为一种高效的集成学习方法,能够有效地构建增强树和并行运算,与SVM相比,其模型效果和运行效率更好(肖艳丽和向有涛,2021)[13]。目前,已有文献多以SVM、NN及其改进方法为主,并且关于XGBoost模型的研究主要集中于用户分析、价格预测和信用评估等,没有发现将其应用于极端金融风险预测的实证研究。所以,本文引入XGBoost模型作为极端金融风险预测模型,以克服传统方法在极端风险预测中的不足,进而为中国金融监管部门和有关机构防范金融市场风险提供一种应用方法。
第一,本文基于前人的研究,结合我国金融市场的特点,从银行、债券、股票、外汇、保险和房地产等市场,选取13个代表性指标,结合CDF转换、等权重和主成分分析等方法综合得到了FSI,并通过事件识别方法,验证了其识别作用,其应用能够为中国金融市场风险状况的分析提供依据,对金融市场风险水平情况进行相应判断。第二,在运用FSI度量中国金融市场风险的基础之上,进一步构建了金融市场极端风险XGBoost预测模型,对整体金融市场风险进行了定量研究,并采用总体分类准确率TR、几何平均正确率G和少数类度量值F等多种评价指标,将其与其余模型进行比较研究,全面反映了XGBoost预测模型对于金融市场极端风险的预测能力,从而丰富了有关我国金融市场风险的研究内容和极端金融风险的预测方法。第三,引入Shapley和LIME解释模型对本文提出的XGBoost模型的预测结果进行分析,采用Shapley和LIME方法提炼出了特征指标对于中国金融市场极端风险的贡献度,加深了对金融市场风险时间变化特征以及指标阈值效应的认识。
二、金融市场极端风险状态预测模型设定
(一)XGBoost模型
XGBoost是一种开源的高度可扩展的梯度提升的集成学习方法(Chen和Guestrin,2016)[14],已经在各个领域中得到了广泛应用(He等,2018)[15]。与GBRT(传统梯度提升树)相比,兼具线性规模求解器和树学习算法。XGBoost通过将正则项引入损失函数中,且对损失函数进行了二阶泰勒展开,能够较好地权衡模型自身的复杂程度和损失函数的下降程度,从而可以更好地处理和控制过拟合问题的产生和提高模型的求解效率。
设数据样本为:
[S=(xi,yi),i=1,2,3,…,n,xi∈Rm,yi∈R] (1)
其中,[m]为数据样本的维数,[n]为样本个数。假设有[h]个决策树([h=1,2,3,…,t]),则定义损失函数如下:
[Objective(t)=i=1nl(yi,y(t)i)+h=1tΩ(fh)] (2)
其中[y(t)i=h=1tfh(xi)=y(t-1)i+ft(xi),fh∈E],E为回归树的集合空间,[fh]为回归树,[xi]为第i个数据的特征向量,[yi]为真实值,[y(t)i]表示预测值。此外,为了控制模型出现过拟合的现象,加入正则项①。结合上式,对损失函数进行泰勒展开可得:
[Objective(t)≈i=1n12wif2t(xi)+gift(xi)+Ω(ft)+C] (3)
其式(3)中[gi]和[wi]分别定义为[αy(t-1)l(yi,y(t-1))]和[α2y(t-1)l(yi,y(t-1))]。
(二)基于FSI的金融市场风险状态识别方法
FSI的主要作用是度量金融市场潜在风险,及时发现金融市场的运行情况,其在定量研究金融风险水平上具有明显优势:一方面,其计算出来的压力指数会与金融风险水平同步变化,能够为金融不稳定提供早期预警信号;另一方面,其可以对因金融体系的不确定性而承受的总体风险水平进行反映和刻画。目前,多数研究者和金融相关部门都采用它来度量金融市场风险的变化情况(淳伟德和肖杨,2018)[16]。FSI的构建方法主要有四种:等方差权重法,等权重法,因子分析法和CDF转换法。其中CDF转换法消除量纲和正态分布假定对指数的影响,不同于等方差权重法需要金融指标满足正态分布的要求。FSI的计算公式如下:
[FSIt=i=1nXitwit] [(3)]
其中,[FSIt]为t期的金融压力指数,[Xit]为第i个子市场在[t]时期的值,[wit]是指在[t]时期子市场所对应的权重。
在FSI的建立过程中,首先,利用经验累积分布函数对基础指标进行转换(Hollo等,2012)[17],从而保证所构建指数的可靠性。其次,对每个子市场已经完成转化的基础指标进行算术平均,进而合成子市场的风险压力指数[Xit=1sj=1sxi,j,t],其中[s]为第[i]个子市场中指标的个数。最后,由于金融压力可以被视为影响各子市场压力指数共同变动的主要因子(陈忠阳和许悦,2016)[18],所以本文采用主成分分析法对子市场指数的主要成分进行提取,从而确定子市场指数的权重[wit]。
基于上述,计算出来FSI后,需要对其进行识别,以确定金融市场是否存在极端风险。
(三)金融市场风险识别模型性能评价
为了对金融市场极端风险预测模型的综合性能进行更加全面地评价,不仅要评估模型的预测精度是否优越,还要对模型的稳健性进行考察。先运用TR和AUC对预测模型的整体情况进行评价。然后,采用针对不均衡样本的评估指标对金融市场极端风险预测模型预测精度进行评估(G和F)。其中,G值综合分析了预测模型对极端风险类与非极端风险类样本的预测效果,若G较大,则说明模型预测两类样本的精度都较高,反之,模型精度越小;而少数类样本的F主要考察了模型对负样本(金融市场极端风险类样本)的预测性能,若F较大,说明模型对金融极端风险类樣本的预测性能更优,反之亦反之。
设TP和TN分别表示对金融市场非极端风险样本和极端风险样本预测正确的数量,FN和FP分别表示预测错误的数量。混淆矩阵表示模型预测分类的结果(见表1)。根据表1中混淆矩阵的结果,可分别计算出TR、AUC、G和F,具体计算过程见表2。
三、实证研究与结果分析
(一)数据选取与处理
FSI不仅能够反映金融市场本身的脆弱性,而且可以体现来自外部的冲击所造成的风险和不确定性。金融市场是一个完整的系统,主要包括证券市场、银行信贷体系和国际金融市场等子金融市场。考虑到我国金融市场体系和监管的条件,各个市场之间存在一定分割,所以先通过构建各个子金融市场的压力指数,然后采用PCA法合成FSI。目前,指标主要来源于银行、保险、证券和外汇等市场(丁岚等,2019)[7],可以及时提供金融市场风险信息(包括信用风险、流动性风险和市场风险等),且指标包含的信息具有互补性,在金融市场风险较强时又具有相关性,其中银行市场体系是关注的重点(孙蕾,2016)[19]。此外,考虑到房地产市场在我国经济发展中的重要地位和作用,结合我国金融市场的实际特点,本文最终选取银行、股票、保险、债券、外汇和房地产等六大子金融市场中的13个特征指标用以构建我国FSI。
鉴于数据可得性和统计期限的约束,本文选取2005年1月—2021年6月的特征指标数据作为研究对象,能够比较全面地反映金融市场风险的变化。本文数据来源于国泰安数据库、中经网数据库、中国人民银行网站、中国统计局网站、中国银保监会网站和中央国债登记结算有限责任公司网站,部分缺失数据采用插值法补齐,部分季度数据使用Eviews转换为月度数据。
(二)金融市场风险状态评价
金融市场风险状态的准确划分是进行准确预测的前提和关键,所以,须对已经构建的FSI进行分析,并与金融市场实际情况进行比较,进而讨论该指数对金融市场风险状态划分的合理性和有效性。本文构建的FSI样本区间为2005年1月—2021年6月,如图1所示。此外,本文还提供了经过Hodrick-Prescott滤波方法处理后得到的FSI趋势项。
在图1中,FSI能够比较准确地刻画和描述金融体系的实际运行情况,其主要事件压力大小反映在了指数的走势变化上。可以大致发现中国金融市场经历了以下几个发展阶段:第一阶段为2006年1月—2008年2月,FSI出现持续震荡上行的趋势,并在2008年到达了峰值。这主要是受美国次贷危机所引起的全球性金融危机和国内股市泡沫破灭的影响。随着2008年11月中国政府扩大内需、刺激经济增长的十项措施出台,市场信心得到恢复,降低了中国金融市场风险压力水平。第二阶段为2009—2011年,中国金融市场风险开始上升,出现了较大的波动变化。此时段内,2009年底以希腊债务危机为开端的欧债危机爆发并于2011年下半年全面爆发,加之国内采取了紧缩的货币政策导致流动性减弱,这都导致了中国金融市场风险压力的增大。第三阶段为2014年6月—2015年6月,2014年下半年我国金融市场风险水平出现上升趋势,主要源于我国经济面临下行压力使得金融市场不确定性增加。紧接着2015年“股灾”导致股市出现较大震荡,FSI明显上升,出现相对高点。第四阶段为2018年3月—2019年4月,2018年中美贸易摩擦出现,并呈现越演越烈的趋势,对中国国际贸易和外汇市场造成了一定的冲击,引起FSI走高,指数出现阶段性高点。
(三)金融市场极端风险预测
通过以上对事件与指数的描述性分析,可以比较直观地发现FSI在不同时期的特征存在差异。此外,由于无法直接观察到整个金融市场是否处于极端风险状态,而Du Mouchel(1983)[20]选择10%左右的样本数据作为极端风险样本进行研究,取得了比较好的研究效果。所以,本文选取FSI最高的10%的样本作为金融市场极端风险样本(这些样本对应的FSI均在0.67026以上),即极值尾部,其他90%的数据作为非极端风险样本。根据极值理论,运用 EVT 对尾部建模主要有两种极值模型,即传统的分块样本最大值模型(BMM)和超越门限模型(POT),其中对于充分高的门槛值,超过门槛值的样本数据近似服从广义帕累托分布(GPD)簇。GPD的形式可以用下式表示:
[Gβ,γx=1-(1+γxβ)1γ,γ≠01-exp(-xβ),γ=0] (4)
其中[γ]为形状参数,[β]为规模参数。因此,本文对极值尾部样本使用“伪极大似然估计方法(QMLE)”估计GPD簇分布函数的参数,从而获得尾部GPD分布曲线与经验分布的拟合结果。从图2可以直观地看出,GPD分布与经验分布的拟合效果较好,表明本文设定的金融市场极端风险样本的门槛值是合适的。另外,本文采用前一期(t-1期)的特征指标预测当前(t期)中国金融市场的极端风险状态(0或1)。
为了让实证结果更加可靠和准确,本文利用K折交叉验证(K-fold cross-validation)方法对金融市场极端风险预测模型进行研究。已有研究表明,k在取5时对模型的预测效果影响不显著(崔少泽等,2021)[21],所以本文将k值确定为5。首先,5折交叉验证将所有样本集划分成5个大小相同的样本子集;其次,依次遍历5个样本子集,每次将当前子集j作为模型的测试集,其余样本子集作为交叉验证的训练集;最后,当5个样本子集遍历完成后,把5次模型评估指标的平均值作为最终的评估指标,用于考察XGBoost预测模型的有效性。
此外,以AUC最大化作为模型参数选择的目标,结合5折交叉验证和随机搜索法(Random Search,RS)对XGBoost模型的核心参数进行优化选择,有利于提高参数选取的效率和准确性,回避样本抽样的随机性对预测模型性能的影响,其最优参数如表4所示。
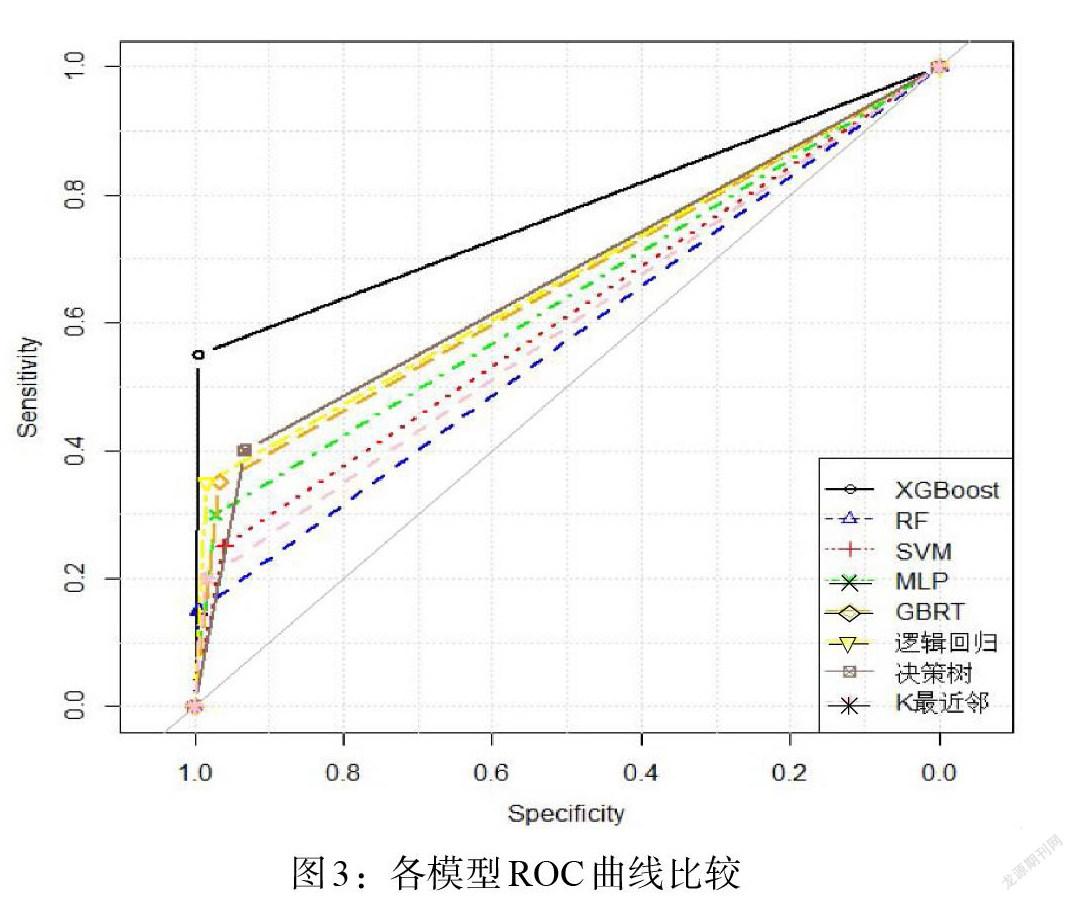
对本文所提出的XGBoost预测模型和其他模型分别绘制ROC曲线如图3所示。纵轴是Sensitivity,横轴是Specificity。XGBoost模型的ROC曲线明显包住了其余模型,表明XGBoost预测模型的预测能力要显著优于RF、SVM和K最近邻等方法。
为了对模型的预测精度进行更加全面地分析,进一步计算XGBoost预测模型的TR、AUC、G和F的评价指标值,且结合其他方法模型进行相应地比较研究,实验对比結果如表5所示。在表5中,加粗的数字为各个指标得分的最大值,结果显示XGBoost模型在预测金融市场极端风险状态的效果显著,其在各个指标上的表现突出,均优于其余模型方法,从而说明XGBoost预测模型能够有效提升我国金融市场极端风险的预测精度。另外,可以看出,RF、决策树和K最近邻的G和F值都较低,表明非对称样本对这几类方法的预测能力有比较严重的影响,而XGBoost模型为93.96%和68.58%,相比次优模型Logit分别提升了12.23%和50.72%,表明XGBoost在处理非平衡样本上具有良好性能,可以显著提高金融市场极端风险(少数类样本)的分类准确率。究其原因可能在于传统RF、SVM、决策树、K最近邻和GBRT没有对非极端风险样本和极端风险样本所造成的严重的非均衡样本的特征进行很好的考虑和处理,将许多极端风险样本错位判断为正常样本。
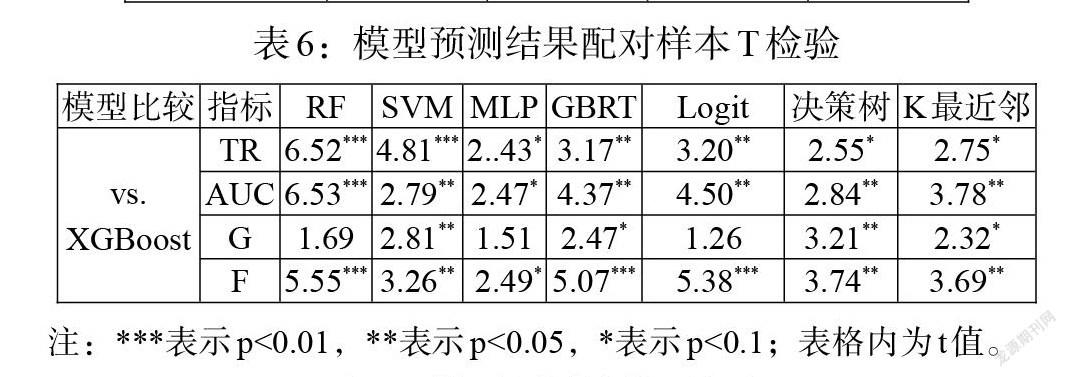
上述实验结果仅从各评估指标的数值大小上对模型的预测性能进行了分析,为验证结果在统计上的严谨性与可靠性,本文在表5结果的基础上,对预测结果进行配对样本T检验和弗里德曼检验,用以分析讨论各个模型的预测效果是否存在显著差异,检验结果见表6和表7。结果显示,XGBoost与其他模型在TR和AUC上的T检验显著,即表明XGBoost模型与其余7个模型的预测效果具有显著差异。进一步地,从少数类样本度量值F看,XGBoost与其他比较模型在10%的显著性水平上存在显著的差异性。需要注意的是,将极端风险样本预测为非极端风险样本所带来的影响和危害要大于将非极端风险样本预测为极端风险样本(吴庆贺等,2020)[22],所以在F值上的优势更能体现XGBoost模型在金融市场极端风险预测中的性能。综上可知,XGBoost金融市场极端风险预测模型可以有效提升对于非平衡样本的学习能力,比较好地识别和预测我国金融市场极端风险,从而为金融风险监管部门和金融机构应对和防范金融市场极端风险提供了有效的操作工具和方法。
(四)模型的可解释性
除了XGBoost模型的预测精度和稳定性,可解释性也是评价金融市场极端风险预测模型的另一重要指标。具有良好可解释性的预警模型可以克服传统机器学习方法“黑箱”的局限性。因此,本文采用SHAP和LIME方法来对中国金融市场极端风险的影响因素进行解释分析,让复杂的XGBoost模型具备可解释性。
1. 模型预测结果的全局解释。(1)总体影响因素分析。XGBoost与随机森林一样,只能反映出特征的重要程度,无法用单一的方程关系来表征各个变量的重要程度,难以分析特征变量对预测结果的具体影响程度,即不能衡量变量影响程度的大小以及作用程度的正负性。且对于单一样本来说,各个特征变量x映射至预测变量y的关系无法被解释。为了解决上述问题,增强模型的可解释性,本文将利用SHAP方法解释XGBoost模型的预测结果。SHAP解释模型的基础是Shapley于1953年提出的Shapley值法,该方法将模型中所有特征变量都定义为对模型结果的贡献者,某一个特征变量的Shapley值就是该特征对模型预测值的边际贡献。
图4直观地展示了每个特征Shapley值的分布,根据影响金融市场极端风险因素的重要性进行排序。该图右侧显示各个特征变量映射到Shapley值后的取值范围和大小,表示变量对模型预测值的作用。与此同时,结合图5的变量重要性排序来看,虽然二者排名的变量顺序不完全相同,但影响金融市场是否会发生极端风险的关键因素包括TS、BBI、IMV、SMV和ERMV,其中IMV、BBI、TS和SMV在两种变量重要性度量方法上均位于前5名,可见这四个因素是影响金融市场是否会发生极端风险最关键的因素,表明中国金融市场极端风险主要来源于银行、保险和股票等市场。此外,IMV、TS、SMV和BBI主要对金融市场极端风险产生正向影响,即这些变量值越高,Shapley值越大,对应的金融市场发生极端风险的概率越大。
为了研究各个变量的Shapely值如何随着时间变化,本文使用Shapley值法对中国2005年2月—2021年6月期间的金融市场风险值进行拆解,并将各个特征指标相应的Shapley值用折线图的形式呈现。图6直观地展现了在不同时点下不同特征指标对中国金融市场极端风险发生概率的贡献度。首先,BBI是拉高2007—2008年和2010—2011年中国金融市场风险水平的主要因素,对风险变动最为敏感,2007年的风险贡献度达到最大(3.2)。其次,2012年以前ERMV和REIC也是推动中国金融市场风险水平的重要因素,ERMV的Shapley值由2011年4月的0.27上升至9月的0.41,与REIC相比,ERMV对风险的敏感度更强。最后,2012年6月后各个特征指标对中国金融市场极端风险的贡献度均出现下降,尤其是BBI由最初推动中国金融市场极端风险的主要因素变为降低风险的主要因素。
(2)单变量影响因素与阈值效应分析。为进一步解释不同特征变量随着特征值的变化对中国金融市场极端风险水平的影响,本文将特征值及其对应的Shapley值的关系以散点图的形式进行呈现(见图7)。本文选择了三个比较有代表性的变量值散点图,可以发现BBI、ERMV和LRU对中国金融市场极端风险具有重大影响,尤其是存在一种阈值效应。当BBI超过0.75后,其对中国金融市场极端风险的贡献会由0上升至1.5左右,即超过阈值后BBI对中国金融市场极端风险的拉动作用会急剧增加,说明当银行业发展过热时会加剧风险的积累,导致整个金融市场极端风险水平的上升。另外,ERMV、LRU和SMV也存在这种阈值效应,其他指标并未表现出对中国金融市场极端风险的显著影响。
2. 模型预测结果的局部解释。SHAP法运用于本模型还存在一定的缺陷,表现为解释具有一定的局限性,所以本文选择LIME可解释方法对模型解释性进行补充分析(Ribeiro等,2016)[23]。具体而言,在样本集中各选取1个具有代表性的金融市场极端风险和非极端风险样本点,进一步解释特征指标对于单个样本分类贡献率,哪些特征与之冲突以及这些特征如何影响预测结果,以便更好地挖掘影响金融市场极端风险的关键因素。
如图8所示,左侧的图表示在2013年6月,模型以99%的置信水平预测为正常状态,即金融市场没有产生极端风险。其中柱状体的长度代表该变量的权重,具体地,负数表示该特征对预测结果产生负向作用,正数则相反。当金融市场未发生极端风险时,IMV、TS、ERMV和SMV等9个特征对模型预测为正常状态起积极作用,其余指标起阻碍作用。其中,特征变量IMV会在0.263和0.5之间,对极端风险的产生产生抑制作用(-0.038),降低金融市场发生极端风险的概率。总体而言,模型预测为正常状态的权重比预测为极端风险状态的权重更大,即大于0的贡献值的总和大于小于0的贡献值绝对值的总和,所以最后的预测结果为正常状态。该方法的应用不仅有利于金融监管部门分析该预测模型的有效性,而且有助于预测模型的改进以及理解模型预测背后的原理。此外,本文还提供了其他10个样本的特征变量对个体样本预测结果的影响(见图9)。
四、结论与启示
本文基于2005年1月—2021年6月的金融市场数据,为中国构建了FSI。该指数基于银行市场、债券市场、股票市场、保险市场、房地产市场和外汇市场所包含的13个金融市场基础指标计算,采用CDF转换法对原始指标进行处理,随后使用等权重法和主成分分析法分别为各子市场的指数和整个金融市场的指数进行赋权,最终合成了中国FSI。此外,通过事件匹配方法检验了其识别作用,结果显示,该指数走势与样本区间内实际经济事件发展趋势情况大致相同,其识别出的金融市场风险较高的阶段基本吻合了重要的压力事件,可以较好地监测我国金融市场的风险变化状况,为后文的金融市场极端风险预测提供了依据。进一步,依据该指数构建了中国金融市场极端风险预测模型,为了让模型实验结果更加准确可靠,本文运用5折交叉验证法和随机搜索法对预測模型进行实证研究,并采用多种评估指标与其余7种模型的预测性能进行比较分析,运用配对T检验和F检验对各模型预测结果的差异性进行统计检验。最后,采用SHAP和LIME法发掘出特征指标对金融市场极端风险的定量影响,提升了我们对主要影响因素的时间变化认识和指标阈值效应的理解。实验结果显示:第一,极端风险XGBoost预测模型能够反映金融市场风险状态变化情况,与RF、SVM、MLP和GBRT等模型相比,XGBoost预测模型不仅在预测精度上显著优于其余模型,而且具有明显的统计检验意义,其严谨性和可信性更强。第二,XGBoost预测模型具有更好综合预测能力和非均衡样本的学习能力,即AUC和F值较高,远远优于其他模型。第三,结合SHAP和LIME方法,以可视化的方式清晰地展示了不同特征指标对于金融市场极端风险的贡献度,提升了我们对于主要影响因素的时变特征和指标阈值效应的理解。
依据以上实证研究结果,本文所构建的能够反映金融市场整体风险情况的综合指数,可以比较有效地监测我国金融市场风险变化状况,为政府监管部门进行科学调控和审慎管理提供有效的前瞻性信息。另外,XGBoost模型能够有效地预测我国金融市场是否会发生极端风险,具有一定的实践价值。对金融监管当局而言,可以运用预测模型提前分析潜在风险,预防和防范金融市场风险的发生,从而维护金融市场的稳定健康发展。对于金融企业而言,可以利用XGBoost模型的预测结果评估发生极端金融风险的可能性,及时制定和实施风险管理措施,优化投资组合,提高自身抵抗市场风险的能力。对于投资者而言,可以运用该模型对金融产品的极端风险进行预判,提前发现可能存在的风险,及时地调整金融产品投资策略,做出正确的投资决策,从而减少或者避免相关投资损失。
注:
①[Ω(fh)=γT+12λω2],[λ]为叶子权重惩罚系数,[γ]为叶子树惩罚系数,[T]和[ω]分别为树叶子节点数目和叶子权重值。
参考文献:
[1]郭娜,祁帆,李金胜.中国系统性金融风险度量与货币政策影响机制分析 [J].金融论坛,2020,25(04).
[2]范小云,方意,王道平.我国银行系统性风险的动态特征及系统重要性银行甄别——基于CCA与DAG相结合的分析 [J].金融研究,2013,(11).
[3]许涤龙,陈双莲.基于金融压力指数的系统性金融风险测度研究 [J].经济学动态,2015,(04).
[4]Illing M,Liu Y. 2006. Measuring Financial Stress in a Developed Country:An Application to Canada [J].Journal of Financial Stability,2(3).
[5]Manamperi N. 2015. A Comparative Analysis on US Financial Stress Indicators [J].International Journal of Economics and Financial issues,5(02).
[6]马勇,黄科.金融压力指数及其政策应用:基于中国的实证分析 [J].金融监管研究,2019,(07).
[7]丁岚,李鹏涛,刘立新.中国金融压力指数的构建与应用 [J].统计与信息论坛,2019,34(10).
[8]Louzis D P,Vouldis A T. 2012. A Methodology for Constructing a Financial Systemic Stress Index:An Application to Greece [J].Economic Modelling,29(4).
[9]Chatzis SP,Siakoulis V,Petropoulos A,Stavroulakis S,Vlachogiannakis N. 2018. Forecasting Stock Market Crisis Events Using Deep and Statistical Machine Learning Techniques [J].Expert Systems with Applications, 112.
[10]温廷新,孔祥博.不平衡样本下的金融市场极端风险预警研究 [J].计算机工程与应用,2020,56(08).
[11]Ahn J J,Oh K J,Kim T Y,Kim D H. 2011. Usefulness of Support Vector Machine to Develop an Early Warning System for Financial Crisis [J].Expert Systems with Applications,38(4).
[12]王鹏,黄迅.基于Twin-SVM的多分形金融市场风险的智能预警研究 [J].统计研究,2018,35(02).
[13]肖艳丽,向有涛.企业债券违约风险预警——基于GWO-XGBoost方法 [J].上海金融,2021,(10).
[14]Chen T,Guestrin C. 2016. Xgboost:A Scalable Tree Boosting System [C].Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining.
[15]He H,Zhang W,Zhang S. 2018. A Novel Ensemble Method for Credit Scoring:Adaption of Different Imbalance Ratios [J].Expert Systems with Applications,98.
[16]淳偉德,肖杨.供给侧结构性改革期间系统性金融风险的SVM预警研究 [J].预测,2018,37(05).
[17]Hollo D,Kremer M,Lo Duca M. 2012. CISS-a Composite Indicator of Systemic Stress in the Financial System [J]. Social Science Electronic Publishing,2012.
[18]陈忠阳,许悦.我国金融压力指数的构建与应用研究 [J].当代经济科学,2016,38(01).
[19]孫蕾.基于主成份和灰色预测法的房地产金融风险预警体系研究 [J].金融监管研究,2016,(11).
[20]DuMouchel W H. 1983. Estimating the Stable Index $\alpha $ in order to Measure Tail Thickness:A Critique[J].the Annals of Statistics,11(4).
[21]崔少泽,赵森尧,王延章.基于ADASYN-IFA-Stacking的再入院患者风险预测方法 [J].系统工程理论与实践,2021,41(03).
[22]吴庆贺,唐晓华,林宇.创业板上市公司财务危机的识别与预警 [J].财会月刊,2020,(02).
[23]Ribeiro M T,Singh S,Guestrin C. 2016. "Why should I Trust You?"Explaining the Predictions of any Classifier [C].Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining.
Prediction Model of Extreme Risk State in Chinese Financial Market and its Application
Xiao Yanli/Xiang Youtao
(Hubei Academy of Social Sciences,Wuhan 430077,Hubei,China)
Abstract:With the development of economic globalization and the gradual opening of the domestic financial market, China's financial market is also facing threats and challenges from foreign financial risks. This paper fully considers some of the characteristic facts of Chinese financial market,combined with China's realities,China's financial market as the research object,selects 13 representative indicators,and uses data from January,2005 to June,2021 to construct Chinese financial market risks index,and tests the validity of index identification by event matching method. Further,the XGBoost model is used to predict the extreme risk in the Chinese financial market,and multiple evaluation metrics are used to compare it with the traditional SVM,GBRT,RF,and MLP models in a comparative study,and the differences in the predictive effects of each model are tested for significance using paired-samples t-tests and Friedman tests. Finally,the SHAP and LIME methods are combined to show the contribution of different characteristic indicators to the risk of Chinese financial markets. The empirical results show that(1)the constructed index better conforms to the actual situation of risk changes in China's financial market;(2)he XGBoost prediction model has a better ability to identify extreme financial risk samples with higher accuracy,and its prediction performance is superior compared with the rest of the models,and it has obvious statistical test significance;(3)The Shapley and LIME methods are used to uncover the main factors affecting the risk of China's financial market and their time-varying characteristics,and the discovery of threshold effects facilitates the financial sector's targeted prudential supervision of financial market risk.
Key Words:financial market risk,stress index,extreme risk prediction model,XGBoost,Shapley Value,interpretability
