基于多分支结构的不确定性局部通道注意力机制
2022-04-18伍邦谷张苏林朱鹏飞王旗龙胡清华
伍邦谷,张苏林,石 红,朱鹏飞,王旗龙,胡清华
(1. 天津大学智能与计算学部,天津 300350;2. 中汽数据(天津)有限公司,天津 300380)
1 引言
深层卷积神经网络已经被广泛应用到多种人工智能相关的任务中,例如图像分类、目标检测、实例分割等,并在相应任务中都取得了卓越的性能和效果. 但是如何在复杂场景和任务上进一步提升卷积神经网络的准确率和稳定性仍是一个非常具体挑战性的问题. 解决该问题的一个重要思路就是提升卷积神经网络的特征学习能力,从而提升神经网络的表达和泛化能力[1].沿着这个思路,近年来研究者们在如何进一步提升深层卷积神经网络性能方面做了大量的工作[2~8],包括不断扩增深层卷积神经网络的深度和宽度[3~5],利用跳跃连接[6]和密集连接[7]提升深层卷积神经网络的训练稳定性和特征利用率. 特别地,视觉注意力机制[8]通过自适应学习特征的重要性,对不同的特征进行加权,突出对特定任务重要的特性,压制对任务无用或者有害的特征,实现样本级别的自适应特征选择,从而增强特征学习能力,提升卷积神经网络的表达和泛化能力.
SENet[8]是利用视觉注意力机制提升深层卷积神经网络性能最具有代表性的工作之一,它通过聚合和激发操作来学习通道之间的相关性,并生成通道级的注意力图对卷积特征进行加权. 其中,聚合操作通过全局平均池化对输入的卷积特征进行全局编码,激发操作通过两层全连接层学习通道之间的全局相关性,最后使用Sigmoid 函数对学习的相关性进行激活从而获得各个通道的权重.SENet在图像分类任务上取得了非常优异的性能,并且启发了后续一系列关于视觉注意力机制的探索[9~14]. 例如,CBAM[9]在聚合操作中同时引入了全局均值池化和全局极大值池化,并且额外加入空间维度的视觉注意力模块,进一步提升了视觉注意力机制的性能. 此外,还有一些工作[10~14]通过设计一些更为精巧的视觉注意力模块学习所有通道之间的非局部非线性相关性. 虽然这些方法在性能上得到了一定的提升,但是不可避免地引入了更多的参数和计算量,从而提升了模型复杂度,并限制了计算效率.
对于通道注意力机制而言,通道相关性建模是一个至关重要的环节.ECA-Net[15]提出一种局部通道相关性建模的思想,打破了之前全局通道相关性建模的必要性假设,在效率和性能上得到了非常好的平衡. 然而,无论是ECA-Net还是现有其他的视觉注意力方法都忽略了卷积通道相关性建模中不确定性带来的影响.例如,由输入数据或标签噪声和缺失导致的卷积特征噪声和异常值会给通道相关性估计带来明显的偏差和不确定性,在一定程度上限制了注意力机制的泛化能力和稳定性. 类似的不确定性问题已经在深层神经网络模型中得到了研究者的关注. 贝叶斯神经网络[16]通过对深层神经网络的输出进行概率化建模,是实现神经网络不确定性建模的重要手段. 然而这些贝叶斯神经网络通常具有较高的计算复杂度,特别是其推理过程. 为了缓解贝叶斯神经网络计算复杂度高的问题,研究者针对后验分布的建模提出多种近似算法[17,18]. 其中,文献[18]提出了一种MC Dropout 方法,并取得了较好的性能.
受到ECA-Net[15]和MC Dropout[18]的启 发,本文提出一种多分支局部通道注意力模块(Multi-Branch Local Channel Attention,MBLCA). 如图1 所示,在模型训练阶段,MBLCA模块对聚合后特征向量进行多重采样,使用Dropout[19]得到多个随机生成重采样的特征,利用权重共享的1D 卷积学习所有重采样特征各自的局部通道之间的相关性,最终通过平均融合和Sigmoid 函数得到通道权重. 因此,MBLCA 模块可以通过快速1D 卷积和MC Dropout 实现局部通道注意力机制的不确定性建模. 在模型推理阶段,为了避免随机性,直接使用训练好的1D 卷积进行运算,这也使得MBLCA 方法的推理效率与ECA-Net[15]完全一致. 通过训练不确定性局部通道注意力模块,可以进一步提升深层卷积神经网络中视觉注意力机制的泛化能力和稳定性. 为了验证所提方法的有效性,本文在ImageNet[3]和MS COCO[20]数据集上进行了大量的实验. 主要贡献总结如下.
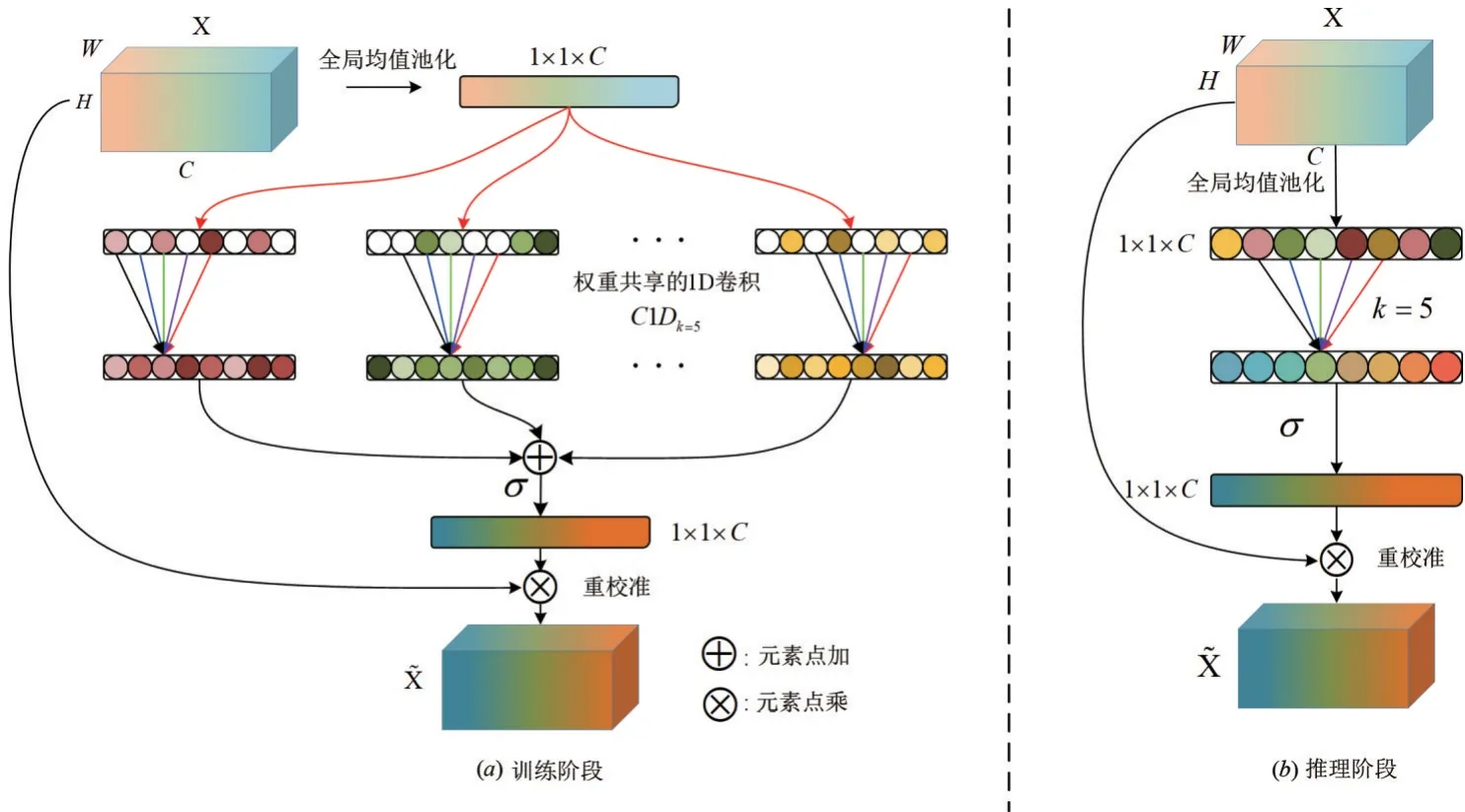
图1 多分支局部通道注意力(MBLCA)模块整体框图
(1)尝试通过对局部通道注意力机制进行不确定性建模,以提高视觉注意力模块的泛化能力和稳定性.为此,提出了一种多分支局部通道注意力模块(MBLCA),该模块采用权重共享的快速1D 卷积和MC Dropout 来学习通道之间的局部相关性和建模模型的不确定性.
(2)提出的MBLCA 方法在ImageNet-1K 和MS COCO2017 数据集上针对图像分类、目标检测以及实例分割等多种任务进行了大量的实验验证. 实验结果表明,MBLCA方法相比于其他同类方法具有更低的模型复杂度和更好的性能,在模型复杂度和性能之间实现了较好的平衡.
2 相关工作
2.1 视觉注意力机制
视觉注意力机制在提升深层卷积神经网络性能方面展现了强大的潜力.SENet[8]在学习视觉注意力时建模所有通道之间的相互依赖关系,利用了通道的全局上下文信息. 在SENet[8]的基础上,CBAM[9]同时引入了通道维度和空间维度的注意力模块,并且探索了2个模块之间不同融合方式的影响. 文献[21]将注意力学习与相关滤波跟踪算法结合,引入对目标的空时域特性的考虑,提升了算法的精确度和成功率. DSCA-Net[22]提出了一种基于双流信息与通道注意力的室内检测方法以解决计数问题中目标尺度多样性的问题. 此外,一些研究者探索了更加复杂的通道相关性学习方法以获得更高的性能. 其中,非局部神经网络[14]提出了一种非局部模块用于捕获跨通道和空间位置的全局依赖关系,在视频识别任务中取得了显著的性能提升. 文献[23]将基于深度学习的非局部注意力模块应用于增强网络的图像去雨效果,有效地解决了不同雨密度和不同大小雨条纹的问题.GCNet[24]简化了非局部模块[14],并且将之与SE模块相结合得到一种更高效的全局通道依赖关系学习方式. DANet[12]、A2-Net[11]和AANet[10]在非局部模块[14]的基础上探索了更加有效的全局的依赖关系学习模块.GSoP 模块[13]从二阶统计信息的角度发掘通道和空间的全局二阶相关性. 上述的方法主要基于2种思路对注意力模块进行设计:第一种思路是计算空间维度或者通道维度的注意力图,通过利用注意力图重加权策略实现特征增强[8,9,13];另一种思路是学习并利用空间与通道之间的长距离非局部的相关性以提升模型的表达能力的方法[10~12,14]. 但是,这些方法在通过利用注意力机制提升深层神经网络模型性能的同时,也引入了大量参数量和计算复杂度,影响了网络模型的计算效率. 与这些方法不同,MBLCA 模块采用局部通道视觉注意机制,用一种更加高效的方式达到同样甚至更好的性能. 本文方法与ECANet[15]在建模通道相关性上具有相似思想,它们均采用高效的1D 卷积学习通道局部相关性. 然而,与ECANet[15]不同的是,MBLCA 通过对通道注意力模块进行不确定性建模,进一步提升模型的泛化能力和稳定性,同时不引入额外的推理代价.
2.2 模型不确定性
近年来,深度学习中的不确定性建模引起了研究者们的广泛关注. 贝叶斯神经网络[16]随之被提出来用于解决这个问题. 然而其存在计算复杂度高的问题,很难应用到实际任务中. 为此,研究者提出了多种贝叶斯神经网络的近似算法,其中包括基于抽样的变分推理和随机变分推理方法[18,25~27]. 特别地,文献[18]提出了使用MC Dropout 方法对贝叶斯推断进行近似以完成深层神经网络的不确定性建模. 与此同时,不确定性建模在多个领域都得到了广泛的应用. 文献[28]将不确定性建模应用于高密度椒盐噪声降噪方法中,并显著提升了算法的综合性能. 文献[29]提出了一种新的空间数据不确定性建模方法,并在图像数据上验证了该方法的有效性. 上述现有的不确定性建模方法主要关注数据的不确定性和整体模型预测的不确定性,极少关注整体模型中局部模块的不确定性. 本文提出的MBLCA 受MC Dropout[18]的启发,引入MC Dropout 策略对局部注意力模块进行不确定性建模,从而进一步提升整体神经网络模型的泛化能力和稳定性.
2.3 多分支结构
在深度学习的模型设计中,多分支结构经常被用于学习多尺度、多视角的信息等,以提升模型的表征能力. 文献[30]提出一种全局多分支RNN 对时间序列数据中时间延迟进行建模,以增强网络的表征能力. 不同于文献[30],本文的方法(MBLCA)所设计的多分支结构是一种局部模块,其目的是建模通道注意力机制的不确定性,以提高神经网络的泛化能力和稳定性. Inception 网络[5]和双通路网络(Dual Path Network,DPN)[31]设计了局部多分支结构用于提升神经网络的性能,其中Inception 网络[5]采用不同尺寸的卷积运算,形成了一种多分支结构用于提取图像多尺度特征;DPN[31]结合了ResNet[6]和DenseNet[7]的优势,一边利用残差旁支通路复用特征,另一边利用密集连接旁支通路探索新特征. 不同于上述这些方法,MBLCA 基于MC Dropout方法设计了多分支结构对通道注意力机制进行不确定性建模.
3 多分支局部通道注意力机制
3.1 SENet中的通道注意力机制
SE模块通过建模所有通道之间的关系学习每个通道的权重. 对于任意卷积层的输出X∈RW×H×C,其中W,H和C分别表示特征图的宽度,高度以及通道的维度,SE模块通过引入聚合,激发以及重校准三个连续的操作得到加权后的特征图,具体计算过程如下:
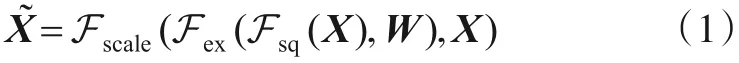
其中,W是一组可学习参数,用于建模聚合后特征所有通道之间的相关性.
SE模块的聚合操作Fsq(X)通过对卷积特征进行全局均值池化得到其维度上的全局分布. 具体而言,对于给定的特征图X,Fsq:X→s∈RC对X进行聚合操作,其中s的第c个元素计算如下:
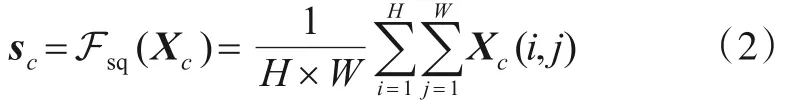
其中,Xc表示卷积特征的第c维通道的特征图.
随后,激发操作Fex(s,W)采用2 个全连接层和Sigmoid 激活函数生成每一个通道的权重,其中两个全连接层用于建模所有通道之间的相关性. 最终生成的权重ω计算如下:
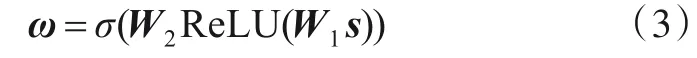
其中,W=,ReLU 表示线性整流函数[32],σ为Sigmoid 激活函数. 为了降低模型的复杂度,W1和W2为2 个低秩矩阵,对特征向量进行了降维,而r表示降维的比例. 最后,权重ω通过通道级的点积运算对卷积特征进行加权重校准.
3.2 多分支局部通道注意力机制(MBLCA)
MBLCA 模块同样采用全局均值池化(Global Average Pooling,GAP)生成特征向量s. 与以往关注于建模全局通道相关性的注意力方法不同,MBLCA 方法旨在更高效建模通道之间的相关性,从而降低模型复杂度.受ECA-Net[15]的启发,本文采用快速1D 卷积建模通道之间的局部相关性. 具体而言,在聚合后的特征向量上利用快速1D 卷积计算通道的局部相关性,采取Sigmoid函数获得各通道的权重,整体运算过程如下:

其中,C1Dk(·)表示卷积核大小为k的1D 卷积,σ为Sigmoid激活函数.
上述的局部通道注意力机制(式(4))可以非常高效地建模通道之间的相关性,并生成较为有效的通道权重. 然而,通道局部交互范围的限制(例如,不同的通道存在不同的交互范围)以及输入信息自身复杂性(例如,通道特征存在潜在的噪声或者异常点)都会对这种通道局部相关性的建模,带来明显的不确定性. 为了能够建模局部通道注意力机制存在的不确定性,在式(4)的基础上引入了MC Dropout 机制,通过近似贝叶斯推断的方式,对视觉注意力模型中的不确定性进行建模.
在具体实现过程中,MBLCA 模块中引入了一个可学习参数. 对于给定的输入s和期望权重参数,MBLCA模块期望可以学习到以下分布:

然而,式(5)是很难计算得到的. 因此,本文采用蒙特卡洛方法在较小计算量的前提下,对s进行有限次数的重采样. 同时,Dropout 作为一个天然的随机生成器,对重采样的特征进行随机扰动,以近似后验分布于是,构造了一种多分支结构,利用蒙特卡洛采样和Dropout生成多分支通道特征向量:
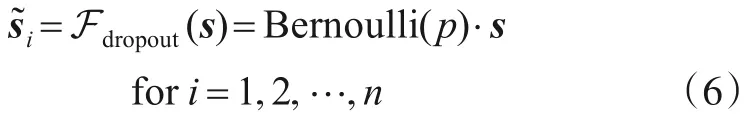
如图1(a)所示,在训练过程中对于聚合的通道特征先进行重采样和Dropout 操作,利用带有共享权重的1D 卷积计算多分支通道特征向量的局部相关性,最后对多分支的输出结果进行平均聚合. 根据式(4),MBLCA模块在训练过程中的权重ω可以有如下公式计算:
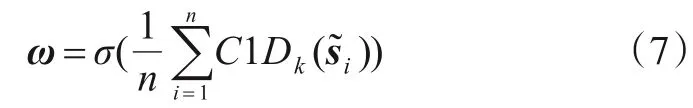
由式(7)可以看出,通过对输入特征进行多重随机采样,可以建模共享权重的不确定性,从而获得更好的泛化能力和稳定性.
在训练阶段,所有的分支都共享同样的1D 卷积核,因此在推理的过程中,如图1(b)所示,未使用MC Dropout 策略以消除随机性,并采用单分支用于最终预测. 与SENet和其他的注意力方法相比,MBLCA模块具有更低的模型复杂度,详见3.3节.
3.3 模型复杂度分析
本节从引入的参数量和每秒浮点运算量(FLOPs)的角度分析了提出的MBLCA 模块的模型复杂度. 对比了3 个同类方法(即ECA 模块[15],SE 模块[8]和CBAM 模块[9]). 4 种注意力模块的参数量和每秒浮点运算计算量如表1 所示,其中B表示训练批次的大小,H和W分别表示输入特征图的高度和宽度,k和n分别表示ECA模块和MBLCA 模块中1D 卷积核的大小以及分支数量. 如表1 所示,SE 模块包含2 个全连接层,它的参数量和计算量分别为2C2/ r和2C2·B/r.CBAM 将通道和空间维度的注意力机制相结合,其包含的参数量和计算量分别为2C2/ r +49·2 和2C2·B/r+H·W·49·2. ECA模块采用1D 卷积的方式学习局部通道之间的相关性,其包含的参数量和计算量分别为k和kC·B.MBLCA 模块和ECA 模块具有相同的参数量. 在模型训练阶段,MBLCA模块的计算量是ECA模块的n倍(n为分支的数量,通常n=6). 但值得一提的是,MBLCA 模块在模型推理阶段的计算量与ECA-Net 完全相同. 因此一旦模型训练完成,MBLCA 模块相比ECA 模块未带来额外的计算代价,但提高了泛化能力和稳定性. 显然,相比于SE 模块和CBAM 模块,MBLCA 模块具有更低的模型复杂度. 值得注意的是,这里k和n的取值通常不超过15和6.
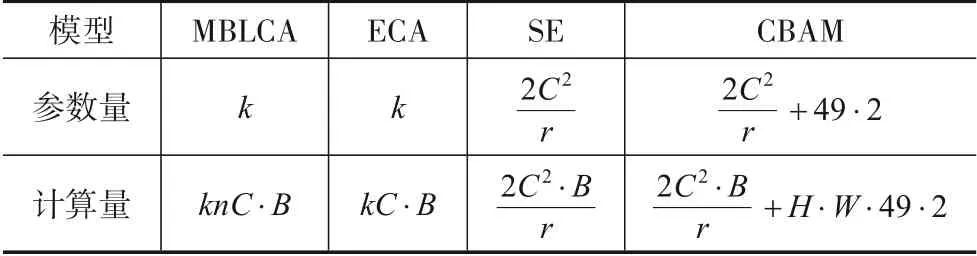
表1 不同注意力机制方法的模型复杂度分析
4 实验分析
为了验证MBLCA 方法在提升深层卷积神经网络的泛化能力和稳定性方面的有效性. 本节利用ImageNet-1K[3]和MS COCO[20]数据集在大规模图像分类、目标检测和实例分割任务,以及噪声图像分类上对MBLCA模块进行验证. 首先,为了探索MBLCA 模块中所包含的超参数对模型的影响,同时找到最优的参数组合与相关工作进行公平比较,本节在大规模图像分类任务上对MBLCA 模块中分支数量n,Dropout 概率p以及快速1D卷积核大小k进行了消融实验. 之后,基于选取的最优超参数组合在ImageNet-1K 数据集上对比了当前最新的同类相关方法,以验证MBLCA 模块的有效性.此外,为了进一步验证本文方法在不同任务上的泛化能力,以ImageNet 预训练的网络模型作为骨干网络,采用Mask R-CNN[33]作为基础检测器,在MS COCO 数据集上进行了目标检测和实例分割实验. 最后,为了验证MBLCA 方法在提升噪声鲁棒性和稳定性方面的有效性,采用ImageNet 预训练的网络模型在ImageNet-C 数据集[34]进行相关的对比实验. 相关程序均使用PyTorch实现,并运行在装备4 块Titan Xp 显卡和Intel Xeon(R)Silver 4112@2.60 GHz CPU的服务器上.
4.1 实验设置
在ImageNet-1K 数据集上训练网络模型时,采用了与ResNet[6]相同的数据增广方式,包括随机裁剪、随机水平翻转和缩放. 采用权重衰减为1e-4,动量为0.9,批次大小为256 的随机梯度下降算法(Stochastic Gradient Descent,SGD)优化网络模型参数. 初始学习率为0.1,每30 轮迭代减小为原来的1/10. 所有的模型都训练100 轮迭代. 对于MS COCO 数据集,本文以Resnet-50和ResNet-101 作为基础网络,并采用带有FPN[35]的Mask R-CNN[33]作为基础检测器. 输入图像的短边调整为800,所有模型都使用权重衰减为1e-4,动量为0.9的SGD 优化算法进行训练. 训练批次大小为8(即每张显卡上运算2张图片). 初始学习率为0.01,分别在训练8和10轮迭代后缩减为原来的1/10,总计训练12轮迭代.
4.2 在ImageNet-1K上的大规模分类实验
4.2.1 消融实验
本文首先在ImageNet-1K 数据集上分析MBLCA 方法中一些关键的超参数带来的影响,主要包括分支的数量(n),Dropout的概率(p)以及快速1D 卷积的卷积核大小(k). 在该部分实验中采用ResNet-50为基础模型.
(1)分支数量和Dropout 概率的影响.MBLCA 模块中1D 卷积主要是为了学习局部通道之间的相关性,其在ECA-Net[15]中通常设置为7或者9. 分支数量和Dropout 概率是不确定性建模的2 个重要影响因素. 为了更好地验证2个因素的影响,此处将局部通道相关性建模范围进行扩大,将k设置为11. 因为通常较大的交互范围中的不确定性越显著. 这里的实验将p和n分别设置为0.25、0.50、0.75 和4、6、8,共计9 种组合. 实验结果如图2所示,可以看到n和p对MBLCA 的性能有着明显的影响. 当n=6,p=0.5 时,MBLCA 方法得到了最优的性能(77.56%). 相比于基线模型(n=1,p=0,77.04%),MBLCA 方法引入不确定性建模后可以得到0.52%的性能提升,这证明了适当的不确定性引入以及多样性扰动对于MBLCA 方法的不确定性建模十分重要. 特别是当分支数量固定时,Dropout概率取0.5时一直取得最优的性能. 当Dropout 概率固定时,分支数量取6 时一直取得最优的性能. 从实验结果可以看出n=6 和p=0.5是最优的参数组合.
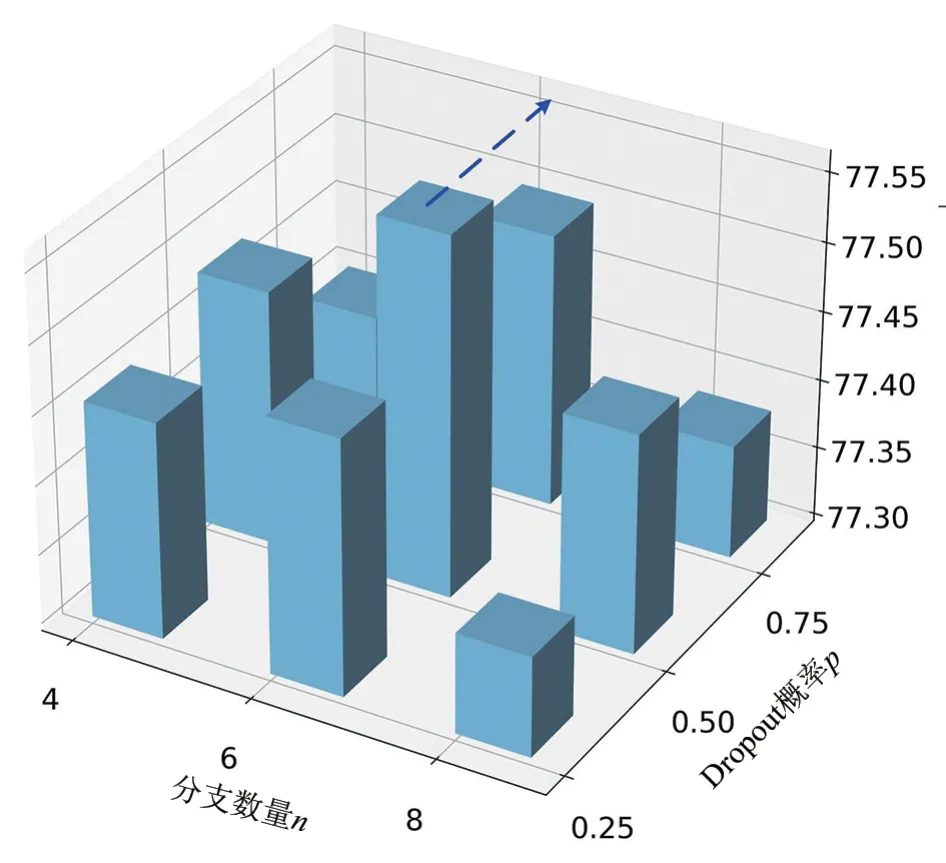
图2 MBLCA模块对于不同分支数量(n)和Dropout概率(p)组合的消融实验
(2)快速1D 卷积核大小k 的影响.接下来的实验采用上述最优的参数(n=6,p=0.5)进一步验证卷积核大小k的影响.1D卷积核的大小k控制着局部通道注意力机制的交互范围. 如图3 所示,同样使用ResNet-50作为骨干网络,分别将k设置为3,5,7,9,11,13,15 进行了7 组实验. 相比于SENet,MBLCA 模块在不同的设置下均保持着明显的优势. 同时,k的变化也对模型的性能有一定的影响. 当k=13时,MBLCA 方法取得了最优性能(77.59%). 当k>13 时,MBLCA 的性能有所损失,同时会引入更多的计算代价. 当k≤9时,MBLCA 模块的性能比较稳定,且均低于k=13 时的结果. 同时可以看出此时MBLCA 模块对于k的敏感度也比较低,说明相对较大局部交互范围中的不确定性会更突出,不确定性建模的作用也相应越明显. 这种现象表明适当范围的局部通道相关性建模是十分重要的. 实验结果表明,快速1D 卷积核大小的最优设置是k=13. 综上所述,在后续的实验中均以n=6,p=0.5,k=13 的超参数组合作为默认设置.
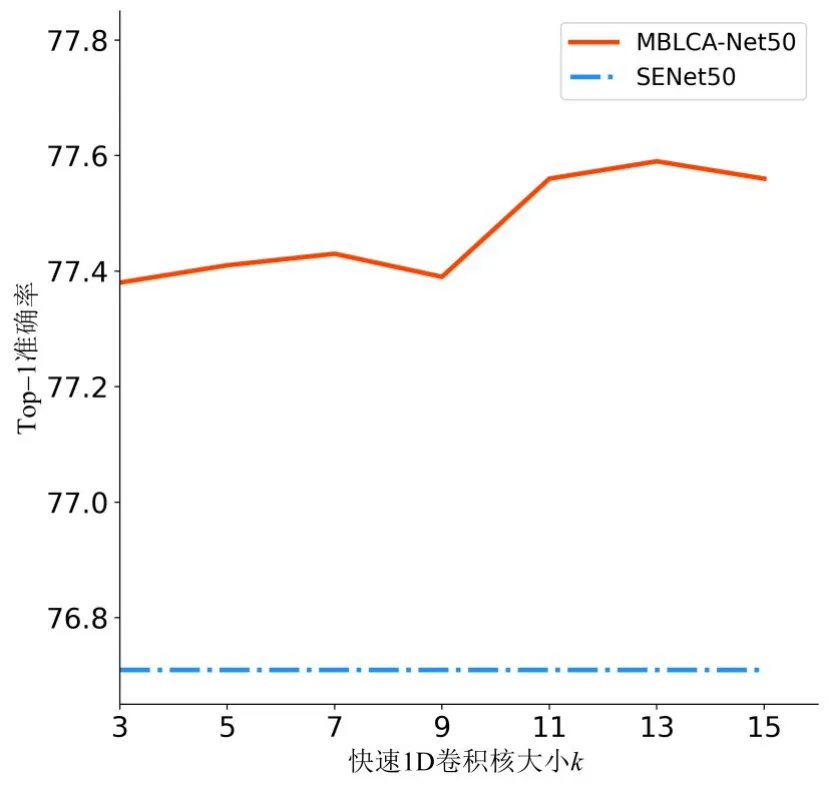
图3 MBLCA模块对于卷积核大小k的消融实验
4.2.2 比较当前最优的同类方法
首先,以ResNet-50 和ResNet101 作为骨干网络,本文比较了多种当前最优的视觉注意力方法,包括SENet[8],CBAM[9],A2-Net[11],AA-Net[10],GSoPNet1[13]和ECA-Net[15],实验结果如表2所示. 在该部分实验中,与文献[15]一样使用自适应尺寸的1D 卷积,可以得到0.1%~0.2%的性能提升. 当ResNet-50 作为骨干网络时,MBLCA方法相比于原始的网络模型,在几乎相同的模型复杂度的情况下可以带来2.58%的Top-1 精度提升. 与其他注意力模型相比,MBLCA 方法利用更低的模型复杂度获得了几乎相同甚至更好的分类精度. 当ResNet-101作为骨干网络时,MBLCA 方法的Top-1精度比原始的ResNet-101 高出2.02%,与其他同类方法相比,在效率和效果上实现了更佳的平衡. 与ECA-Net相比,嵌入MBLCA 模块的模型具有一样的模型复杂度,同时带来了0.3%左右的精度提升. 此外,10 次随机试验中MBLCA 方法具有更小的方差,即更好的稳定性.上述实验证明了MBLCA 方法可以提升多种网络架构的分类准确率,同时令分类结果更加稳定.
为了验证MBLCA 方法在更轻量化的网络上的有效性,在上述实验的基础上还以ResNet-18 作为骨干网络与上述系列方法进行了对比,实验结果表明,在保持与ResNet 和ECA-Net 几乎相同的模型复杂度的情况下,MBLCA 方法分别带来了0.48%和0.1%的性能提升. 同时,在10次重复实验中,MBLCA方法具有更稳定的性能.
最后,还与更深更复杂的卷积神经网络模型进行了对比,包括ResNet-200[36],DenseNet[7],Inceptionv3[37]. 如表2 所示,与ResNet-200 相比,MBLCA 方法使用ResNet-101 作为基础网络只有其近一半的模型复杂度,但是在Top-1 的准确率上提升了0.65%. 另外,基于ResNet-50 的MBLCA 模型比Inception-v3 拥有更低的模型复杂度和更优的性能. 与DenseNet-161 相比,基于ResNet-50的MBLCA模型拥有相似的分类精度,但是仅利用接近一半的计算量(FLOPs). 基于ResNet-101 的MBLCA 模型与DenseNet-161 具有几乎一样的计算量,但是在Top-1精度上提升了1.2%. 综上所述,MBLCA 方法在模型分类准确率与模型复杂度之间实现了更好的平衡,在较低模型复杂度的条件下取得了与目前主流方法相近甚至更优的分类准确率.
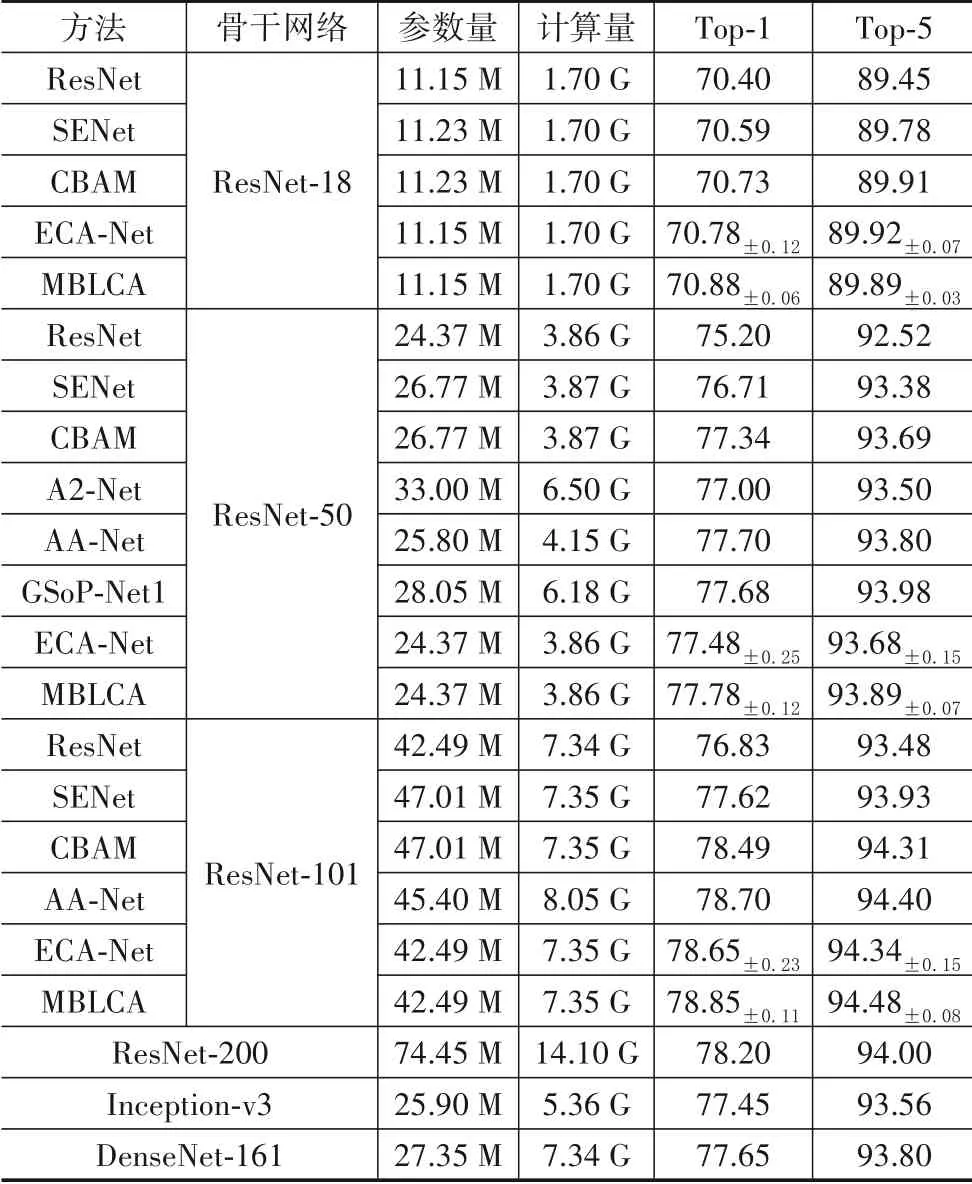
表2 各种当前最优的视觉注意力方法的分类结果
4.3 MS COCO上的目标检测与实例分割实验
本节使用Mask R-CNN[30]作为基础检测器在目标检测和实例分割任务上验证MBLCA 模块的泛化能力.实验中所有检测器的训练都是在MS COCO2017训练集上完成的,并在MS COCO2017 验证集上进行测试. 实验结果如表3 所示,本节在参数量、每秒浮点运算量以及平均准确率(mAP)等多个指标上对所有方法进行评估. 实验结果表明,MBLCA 模块在目标检测和实例分割任务上都明显优于原始的ResNet. 用ResNet-50 和ResNet-101 作为骨干网络,提出的MBLCA 方法在目标检测(实例分割)任务上分别比SENet 提高了0.4%(0.1%)和0.7%(0.6%)的平均准确率(mAP),同时降低了模型的复杂度. 与ECA-Net50(ECA-Net101)相比,MBLCA 方法在保证相同的推理复杂度的前提下,也分别得到了0.1%的平均准确率提升. 上述结果表明,提出的MBLCA模块在多种视觉任务上均具有良好的表现能力,能够有效提升神经网络在下游任务上的泛化能力.
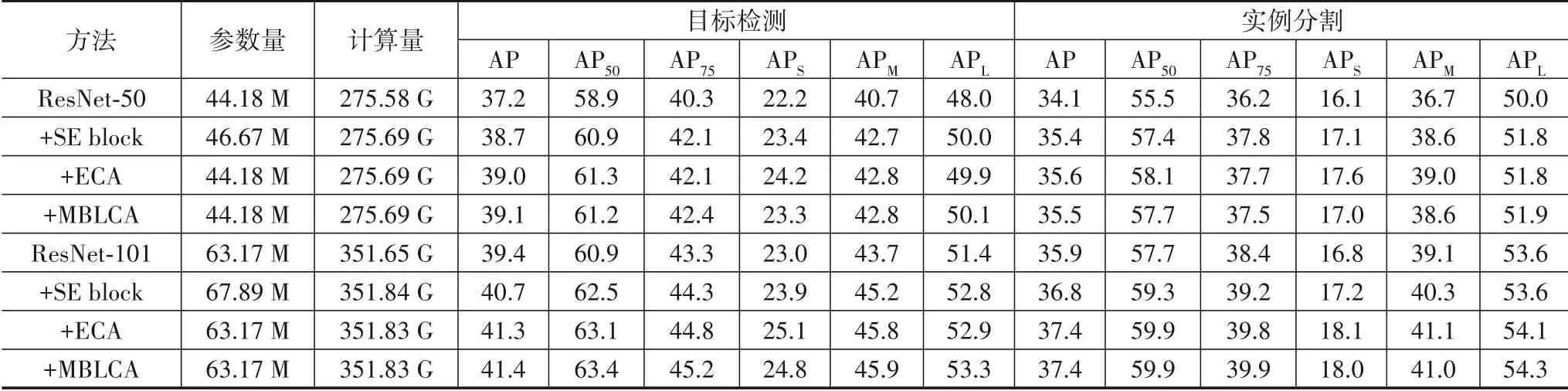
表3 各种方法在MS COCO2017验证集上的目标检测和实例分割结果
4.4 鲁棒性和稳定性实验
为了进一步验证MBLCA方法对噪声数据的鲁棒性和稳定性,本文利用ImageNet-C[34]噪声数据集进行了相关实验.ImageNet-C[34]数据集在ImageNet-1K[3]验证集数据的基础上引入了15 种不同的扰动类型,主要涵盖噪声(Noise)、模糊(Blur)、天气情况(Weather)、数字压缩(Digital)四大类扰动,每种扰动的强度分为5个级别. 评估阶段采用文献[34]中的评价指标mCE 来评价模型的泛化能力和稳定性,该指标的数值越低表示模型的泛化能力和稳定性更强. 实验结果如表4所示,从表4中可以看到:当ResNet50(ResNet101)作为骨干网络时,MBLCA方法相比于基础模型ResNet50(ResNet101)的mCE值分别降低了5.5(3.77);与SENet 和ECA-Net 相比,MBLCA方法在mCE 指标上分别降低了1.6(2.6)和0.87(0.54).上述结果进一步证明了MBLCA模块可以较为明显地提升模型对于噪声的鲁棒性和稳定性.
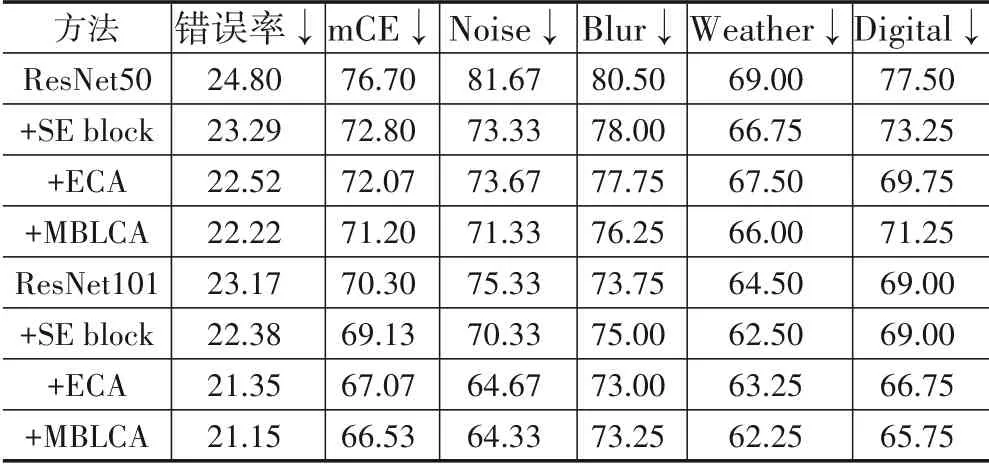
表4 各种方法在ImageNet-C数据集上测试结果
5 结论
本文提出了一种多分支局部通道注意力模块(MBLCA),核心思想是在局部通道注意力机制中引入不确定性建模,从而提升注意力模型的泛化能力和稳定性. 实验结果表明,该方法在图像分类、目标检测以及实例分割任务上都具有良好的性能. 本文主要探索了高效通道注意力机制中局部通道交互情况下的不确定性建模方法,如何引入非局部通道交互和空间维度的注意力机制,并对其进行不确定性建模仍是一个值得研究的方向. 未来将在该方向上进行深入探索,并将该思想应用到更多的深度卷积神经网络架构中,如MobileNets[38]和Inception[5,36,37,39].
