基于混合数据库的水电数据中心存储平台研究
2022-04-18黄金龙秦小元
徐 丹,夏 晨,黄金龙,秦小元
(1. 南京南瑞继保电气有限公司研究院数据平台部,江苏 南京 211102;2. 向家坝水力发电厂,四川 宜宾 644612)
0 引言
大型水力发电站前期建立了大量的监控、监测和管理系统来满足日常运维工作的需要和解决特定的管理问题。这些系统功能各有侧重,管理的信息既有交集、也存在差异和互补的内容。由于建设时间、供应商和采用技术的不同,各系统的业务模型、信息描述、数据含义等自成体系,虽然系统之间也有一些点对点的数据交互,但总体上形成了信息单独存放、共享困难、无法综合分析利用的信息孤岛[1]。
随着水电站的发展和管理要求的提高,各个专业应用之间、水电站和上级管理部门之间的信息共享和协作要求越来越高。当前各业务系统的信息孤岛形态使得数据难以得到综合利用,无法为多业务系统数据协同分析提供支持,也无法为现场一线技术人员提供业务优化的平台。
为适应水电站运行精细化管理的要求,迫切需要一个能整合水电厂现有各业务系统的实时数据、历史数据、视频、波形文件等各种信息,满足水电站各级部门进行实时综合监视、高效应用分析、支撑各专业持续优化改进的水电站一体化数据中心[2,3]。数据中心通过对大量业务子系统实时数据的采集和存储,为企业建立了全业务全景模型,也为企业保留了极为重要的历史数据。在对历史数据和实时数据分析的基础上,可以对企业设备资源实施监控及管理,如设备维护、故障预警、应急响应等,在计划管理和生产管理之间架起一座桥梁,成为大中型水电企业信息系统中数据的“存储中心”,在整个“智慧电厂”建设中起着关键作用[4]。
数据中心最迫切需要解决的问题是数据怎么存和怎么取,也就是数据的存储和服务问题。本文针对大型水电站机房可容纳服务器数量少、数据类型多和实时数据量大等情况,提出了一种基于混合数据库的水电数据中心存储服务平台[5],有效解决了当前面临的不同数据类型和不同频率数据的存储和服务问题[6]。本文给出了基于混合数据库的水电数据中心存储服务平台的设计与实现,包括详细的模块设计,不同层次间的协作机制,平台不同数据库间数据的管理机制,并在此基础上详细介绍了混合数据库存储服务平台各模块的功能。最后分析了基于混合数据库的水电数据中心存储服务平台的性能和经济优势,对比分析数据,并给出进一步研究工作。
1 基于混合数据库的数据中心存储服务平台
一体化水电数据中心需要整合水电站所有子业务系统,将会面对海量数据和各种数据类型两大难题。
面对海量数据难题,采用自研实时数据库作为前端采集和后端存储的缓冲池,从而使得前后端异步存储,相互独立。实时数据库采用面向对象的数据模型,支持类之间的继承、聚集关系以及对象标识等面向对象的特性,能够构造复杂的结构模型,支持用户自定义数据类型和方法。面向对象的数据模型,不仅易于描述水电相关系统及其拓扑关系,更能直接定义类结构,不需要任何映射和模型转换,是最容易接纳标准,并适应其版本变化的数据模型。在面向对象数据模型中,每个对象都有一个在系统内唯一不变的标识符,称为对象标识符,简称OID。OID的生成和管理既是面向对象数据库不可缺少的重要组成部分,也是开放系统中数据交换的需要。实时数据库的OID采用物理对象标识符与逻辑对象标识符相结合的表示方法,OID结构及其索引是高效的对象访问基础。
实时数据库支持不同程序对实时库内的同一数据集进行并发访问。其中与实时库的连接对应用而言是透明的,应用通过连接管理可以与分布于系统中任何结点的实时库建立连接,从而实现了对实时库的透明访问。并采用先进的连接池技术对连接进行动态管理, 实现了实时库连接的复用,大大降低系统的开销。在实时库服务器故障情况下,系统将根据连接分发策略自动重连到负载较轻的服务器;一旦本地服务器恢复可用,连接又将转至本地,保持高的数据访问速度。在以上技术的支撑下,单个实时库的数据处理能力达到100万条/s,通过分布式扩展方式,最多可支持1 000万条/s。
另一个难题是水电数据中心需要存储的类型包括标准化编码后的全景模型数据、各业务系统抽取的结构化低频数据(秒和分钟级数据)、业务系统直接转发的结构化高频数据(毫秒级数据)、经过统计分析后结果数据、视频和文件等非结构化数据。水电数据中心综合考虑各种数据类型的特性和数据量,设计了数据混合存储框架,用于满足不同业务数据的存储要求,如图1所示。
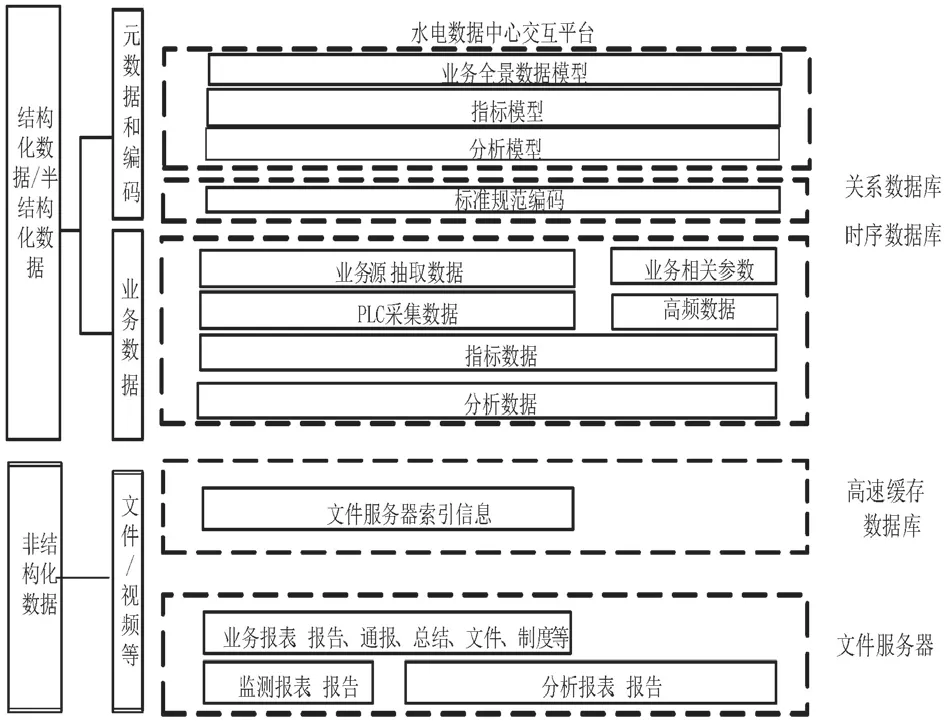
图1 数据混合存储分类图
元数据和模型数据相对稳定,后期数据增、删、改等操作较少,且没有实时更新和改写的要求,但是对数据的可靠性要求较高,数据都是结构化类型,因此传统的关系型数据库更适合,能满足性能和可靠性要求。
各业务系统抽取的生产数据,变化大、实时性要求高(秒级和分钟级),且随着业务发生量的不断增加而增大。用户需要实时的对这部分数据进行交互查询和统计分析,因此数据处理的响应时间需要在秒级以内,在数据量不超过PB级别的情况下,传统关系型数据库集群就可以满足存储和查询要求;但如果数据量增长到PB级以上时,关系型数据库就有些力不从心了,需要引入大数据平台技术来解决海量数据的存储、查询、统计和分析等工作。
特殊业务系统的毫秒级采样数据结构简单,对精度和速度的要求非常高,关系数据库和大数据平台无法支持如此高频的数据插入,需引入时间序列数据库针对性处理。时间序列数据库省去了关系库的复杂校验和关联性检查,大大缩短了具有时间序列数据的处理时间,且通过压缩技术降低了所需的存储空间。
对于文件和视频类非结构化数据,例如序列化记录文件、报表、报告、结算单等,文件数量巨大,需要引入Redis等高速缓存数据库来解决数据量大、实时性强的数据文件检索功能,通过将索引信息存储在高速缓存中,通过索引快速定位文件存储路径,从而达到快速获取文件的要求。
每种数据库都有各自的特性和适用范围,对于水电数据中心这种数据类型复杂的系统,没有哪种数据库可以通吃,因此我们设计了混合存储平台,时序库、关系库、自研实时库、文件服务器等组件可以通过自由组合的方式,部署所需的组件,满足水电各类数据中心的建设要求。
2 混合数据库存储服务平台的设计与实现
2.1 混合数据库存储设计与实现
为了屏蔽底层各种不同类型数据库的差异,设计开发了历史接口平台和历史采样集群,以保证上层应用调用的透明性。具体如图2所示。
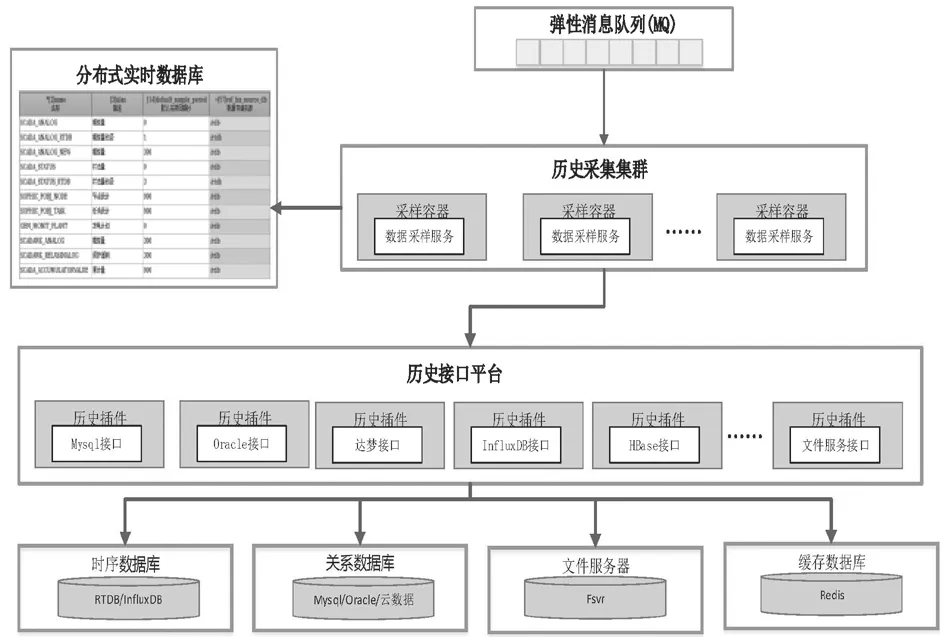
图2 混合数据库存储架构
历史采样集群采用分布式架构设计,可根据采集的数据量进行弹性扩展,每个实例负责一部分数据采样。历史采样集群在自研实时库中维护一张“测点-数据库”映射表,自动从前置库中同步测点模型,并可通过手动配置每个测点的采样频率和存储数据库类型。当需要存历史的数据从弹性消息队列获取后,历史采样集群通过查询“测点-数据库”映射表,获取存储数据库种类(时序数据库、关系数据库、文件服务等),调用历史接口平台封装的通用数据库接口,进行数据的存储。
为了保证历史数据存储的可靠性,历史采样集群在自研实时库中建立了历史缓冲区,用于保存插入失败的记录,以便在故障恢复后补录数据,保证数据不丢失。对于数据插入失败的情况有很多种,历史接口平台会对各种错误码进行判断,除数据库连接失败由底层历史接口平台直接处理外,其他都将反馈给历史采样集群,历史采样服务判断错误码,将失败的记录存入历史缓冲区。历史采样集群有一个专用线程,用于负责判断对应数据库服务是否恢复,并尝试补录数据,补录成功的记录将从历史缓冲区清除,当历史缓冲区满时,将采用覆盖最早记录的方式写入。
历史接口平台采用插件化和动态加载方式运行,针对时序数据库、关系数据库、文件服务器等不同种类的存储服务,定义一套统一的对外接口,历史采集服务就是根据配置信息,调用对应存储服务的对外接口,不需要关心该存储服务下加载的具体数据库类型,底层差异性都将由历史接口平台来屏蔽。
历史接口平台针对每种具体数据库类型,都开发一个数据库插件,继承统一的对外服务接口类,在插件内部处理数据类型、SQL语句、内置函数、错误码和元数据等的差异性。以关系数据库为例,数据中心内部定义了18种数据结构,每种关系数据库类型都需定义18种数据结构的映射关系,上层应用直接存储和获取数据中心定义结构,不需要关心底层关系库数据存储类型转换,转换工作都在接口插件中完成。另外,为了方便独立监视等应用查询和统计关系数据库性能指标,在每类关系数据库中创建类似Oracle的元数据视图,简化应用程序开发。
2.2 混合数据库对外服务设计与实现
一体化水电数据中心不仅要解决混合数据库存储问题,还要对第三方应用提供透明化的数据服务。在IEC61850全景模型的基础上,设计开发了Rest风格的微服务化的统一数据服务平台。每一个数据服务都基于Rest风格的SpringBoot架构开发,数据交互采用标准的Json格式,同时结合了基于Oauth2技术的权限校验模块,对访问历史数据的微服务用户权限进行控制。统一数据服务平台整体架构如图3所示。

图3 统一数据服务平台架构
根据上层应用的开发需求,抽象和剥离出高复用的数据微服务:实时数据微服务、智能预警数据微服务、模型数据微服务、设备巡检微服务、文件数据微服务和权限微服务等,按照统一的接口规范,给第三方应用提供数据接口支撑。所有类型的数据微服务,都会在统一数据服务总线和网关上进行注册,应用在发起数据请求时,微服务网关首先根据应用的鉴权信息调用权限微服务进行权限鉴定,权限鉴定通过后,按照负载均衡策略,将请求路由到注册在总线上的指定数据微服务,该微服务处理请求后返回Json格式的结果数据。
每个数据微服务以统一编码为唯一关键字,对外提供实时和历史数据的查询和订阅功能。微服务内部接收到请求后,根据编码信息查询“测点-数据库”映射表,获取测点存储数据库类型,再将编码、数据库类型、数据服务类型等关键信息发送给对应的后端处理进程,后端进程根据需求执行相关操作后,将结果封装成标准Json格式,返回给前端微服务,由微服务将Json返还给对应的第三方应用。
数据微服务支持多层次、不同粒度、面向应用的复合数据服务,包含请求/响应、订阅/发布两种服务形式。请求/响应模式,平台提供基于Rest风格的Springboot微服务接口,由上层应用按照接口调用规范文档,主动调用该数据服务接口,接口会返回对应的Json格式的结果数据。对于实时性要求较高的实时类、准实时类数据,则需要通过订阅/发布的数据交互模型,将数据推送给应用。首先,各类型的数据微服务,将实时测点采集数据、告警数据等,通过数据发布接口,将数据实时发布至分布式数据总线,然后各应用程序按需订阅,订阅的数据会被实时推送至应用端,同时满足数据的实时和准实时的时效要求。
3 混合数据库存储服务平台实验验证
水电站机房和信息化规模有限,三区若采用大数据平台,也只能配置4-8台服务器的小型集群。本实验搭建了2套环境进行对比:第1套为混合存储平台,采用2台物理服务器+2台虚拟机的模式,物理服务器配置为2颗共64核Intel CPU,主频为2.5 GHz,256 G内存;虚拟机为12虚核,128 G内存。混合存储平台部署了Oracle RAC关系数据库、毫秒级时序库和文件服务器。第2套为4台物理服务器的Hadoop大数据平台,每台服务器为2颗共64核Intel CPU,主频为2.5 GHz,256 G内存。真实的实验环境导入了1年的历史数据,目前分钟级采样点为102 669个,秒级采样点为73 381个,毫秒级采样点为5 306个,数据记录每条固定为40字节。
以每次写入5 000条记录为例,混合存储服务平台最高支持每秒50次的采样存储,而大数据平台在每秒10次采样时,会偶尔出现写出失败情况,具体记录如表1所示。

表1 数据写入实验对照表
数据查询方面,从两个维度进行比较,并采用两种大数据平台SQL引擎,全面反映大数据平台性能。第一个维度是多表级联查询,每张表记录条数都在200万及以上,当进行8张表级联查询时,混合存储服务平台优势明显,在1 s以内返回,但大数据平台最快的Impala也需要3 s多;第二个维度是统计记录数,在1 000万条记录以内时,混合存储服务平台有一定的优势,而当统计记录超过1 000万条后,混合存储服务平台性能下降明显,而大数据平台整体都比较稳定,这个跟大数据平台数据都加载入内存的机制有关。具体如表2、表3所示。
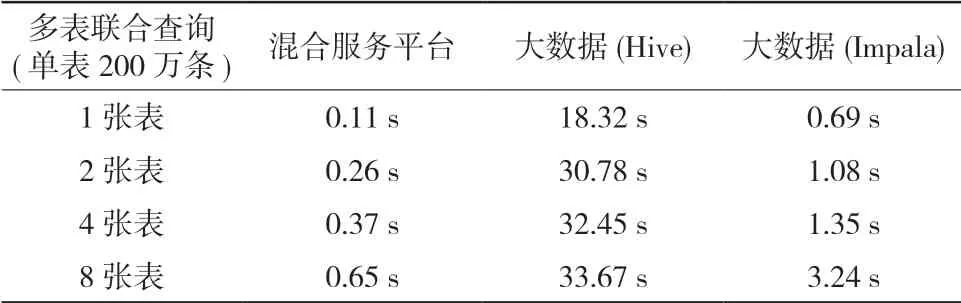
表2 多表级联实验数据对照表
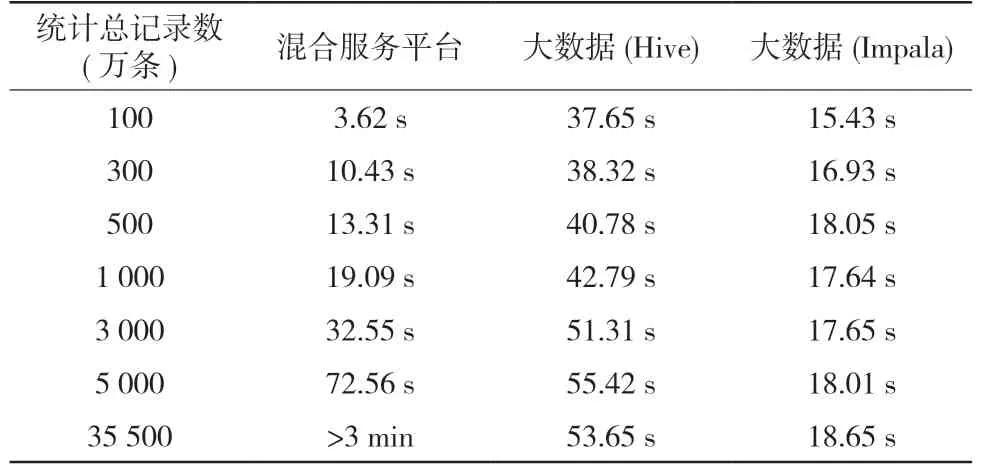
表3 统计数据实验数据对照表
上述实验充分证明了在大型水电站数据中心系统中,当存储服务器规模小于10台,采集数据量在30万点以内时,混合存储服务平台是有性能和经济优势的,具备应用推广前景,主要体现在:
首先,混合存储服务平台最小化部署只需要2台物理服务器和2台虚拟机,在大型水电站数据中心这类应用场景下,性能可与6-10台物理服务器组成的大数据平台媲美。不仅节约了硬件成本,也节省了数据中心机房的空间,贴合水电站信息化机房空间有限的实际情况。
其次,大数据平台组件多、运维复杂,需要配置专业的运维团队进行日常管理,这对于水电站这种生产单位不太现实。混合存储服务平台将时序数据库、关系数据库和文件服务器的状态监视集成到统一的运维监视界面上,服务故障会发出告警,只需针对特定的模块进行排查诊断,底层模块间耦合度低,不需要关联修复。
再次,不同的大数据平台选配组件不同,无法做到接口兼容,对于上层应用开发者需要重新适配,增加了第三方厂家的开发难度。混合存储服务平台屏蔽了底层不同类型数据库的差异性,不管是Oracle、Mysql,还是国产数据库达梦、金仓,对应用提供的都是同一套接口,数据库的更换通过配置和动态加载技术实现,应用完全透明,只需维护一套代码。
4 小结
本文结合大型水电站数据中心的应用背景,提出了基于混合数据库的水电数据中心存储服务平台架构,并阐述了详细的设计框架和实验验证。本文主要做了以下几方面工作。
(1)给出了混合数据库存储服务平台中,各类数据的存储原则,并对核心模块自研实时库的功能进行详细描述;
(2)结合混合数据库存储架构图,详细介绍了混合数据库存储服务平台中数据存储的原理和特点,实现应用层透明访问;
(3)结合统一数据服务平台架构图,给出了混合数据库存储服务平台中数据对外服务的原理和特点,高度微服务化,在提供数据访问便利的同时,进行权限鉴定,加强安全管控;
(4)结合实验验证数据,分析了混合数据库存储服务平台的性能和经济优势,解决了水电站数据中心系统数据存储和对外服务的难题;
(5)设计并实现了原型系统,并应用到实际的项目中,提升了数据中心系统的核心竞争力。
混合数据库存储服务平台得到了初步的实现和应用,已部署于多个水电站数据中心系统,该平台还在不断的优化和演进。但毋庸置疑的是,混合数据库存储服务平台架构是适应当前大型水电站数据中心系统需要的,它在机房和硬件资源受限的情况下发挥巨大的性能优势,保证了上层应用便捷交互和高效运行,也为系统今后的扩容提供了更好的支持。
