基于联合剪枝深度模型压缩的种子分选方法研究
2022-04-18李环宇李卫杰李春雷刘洲峰
董 燕,李环宇,李卫杰,李春雷,刘洲峰
(中原工学院电子信息学院,河南 郑州 450007)
种子纯度直接影响种子育种和后续加工产品的质量,如种子收获和贮藏过程中,可能会混入许多杂质或杂交种,给农业生产及加工带来不同程度的经济损失。因此,需要对种子中的杂质和杂交种进行分选,以保证农作物种子的纯度达到市场标准。传统人工分选方式存在分选效率低、人工成本高等不足,而基于机器视觉的自动分选方法,已经成为目前研究的热点。传统种子自动分选方法基于手工设计特征进行图像表征,如颜色、纹理和形状等特征,然后选择分类器如支持向量机(Support vector machine,SVM)、线性判别分析(Linear discriminant analysis,LDA)和人工神经网络(Artificial neural network,ANN)等来实现种子的分类[1-3],这类识别需要依赖专业知识针对不同种子特点设计特征提取方法,泛化能力和鲁棒性较差。
近年来深度学习在图像分类[4]、目标检测[5]及图像分割[6]等多个领域取得了显著的效果。其中以卷积神经网络(Convolutional neural network,CNN)为代表的深度学习模型无需经过繁琐的预处理、特征选择等中间建模过程,由数据驱动自动提取一些深层的抽象特征,减少了人工设计特征的不完备性。许多研究学者将Vgg[7]、ResNet[8]和GoogleNet[9]等经典的CNN 网络模型运用到植物病害检测和农作物类型划分等方面,并取得了比传统识别方法更好的效果[10-13]。如朱荣胜等[12]构建一个简单的6 层卷积神经网络用于对正常和异常大豆种子的识别,实现了98.8%的识别准确率。HUANG 等[13]利用Vgg19和GoogleNet 对玉米种子缺陷进行分类,并分析了2个不同深度的网络对玉米缺陷识别性能的影响。
基于CNN 的农作物识别分类方法性能依赖于模型深度,因此,研究者往往依靠提升模型复杂度来提高检测识别系统的性能。然而随着网络深度的增加,模型的参数量和计算量增大,导致模型推理速度变慢,难以有效部署到计算资源受限的边缘设备上,特别是吞吐量较高的种子分选系统。此外,研究表明,现有的过度参数化卷积神经网络模型存在大量的参数冗余,导致计算资源和存储资源的浪费。为了能够有效减少神经网络的计算量和内存占用,深度模型压缩提供了一种有效的解决思路,如神经网络搜索、低秩近似、剪枝和量化等。其中,神经网络剪枝具有操作简单、实施高效、可降低网络复杂度和解决过拟合问题等优势,成为了卷积神经网络模型压缩的主流方法。
卷积神经网络剪枝方法可实现权重参数[14]、通道(滤波器)[15-16]和卷积层[17-18]等3 种模式的剪枝。HAN 等[14]根据神经元连接权重参数的范数值大小,删除范数小于阈值的连接,并重新训练恢复性能。尽管这种细粒度的剪枝方法压缩率高,灵活性大,但需要配合专门做稀疏矩阵运算的软硬件才能达到实用效果。而基于滤波器和卷积层的剪枝,灵活性较高而且不用相应的软硬件配合,因此被广泛研究。但是滤波器剪枝方法没有明显降低数据访问频率,模型推理速度的提升有限,而卷积层剪枝在计算效率方面具有显著优势。鉴于此,利用易于部署的Vgg 网络模型,提出一种通道和卷积层联合剪枝的方法,在实现模型压缩的同时,提升算法执行效率,最后利用知识蒸馏技术(Knowledge distilling,KD)[19]对剪枝网络进行知识迁移,补偿网络因为剪枝而造成的精度损失,为开发基于嵌入式设备的种子分选识别系统提供模型构建技术支持。
1 材料和方法
1.1 方法
针对现有卷积神经网络模型参数量和计算量高使其难以有效部署的问题,提出一种基于通道和卷积层联合剪枝的模型压缩方法用于种子分选,其过程如图1所示。在通道剪枝阶段,对BN层参数进行稀疏正则化训练,迫使冗余通道的比例因子趋于0,获得稀疏的卷积神经网络模型,并将BN 层的特征缩放系数作为衡量通道重要性的标准,通过手工选取最优阈值,实现最大限度无损压缩。在层剪枝阶段实现最大限度的通道剪枝压缩,通过自适应平均池化和全连接层为每个中间层构造一个线性分类器,即线性探针[20],然后基于预定义的阈值来去除贡献小的卷积层。最后利用知识蒸馏技术提高修剪模型的性能。最终在保持模型识别精度及提升模型推理速度的同时,实现将复杂的神经网络模型压缩为更紧凑的神经网络结构。
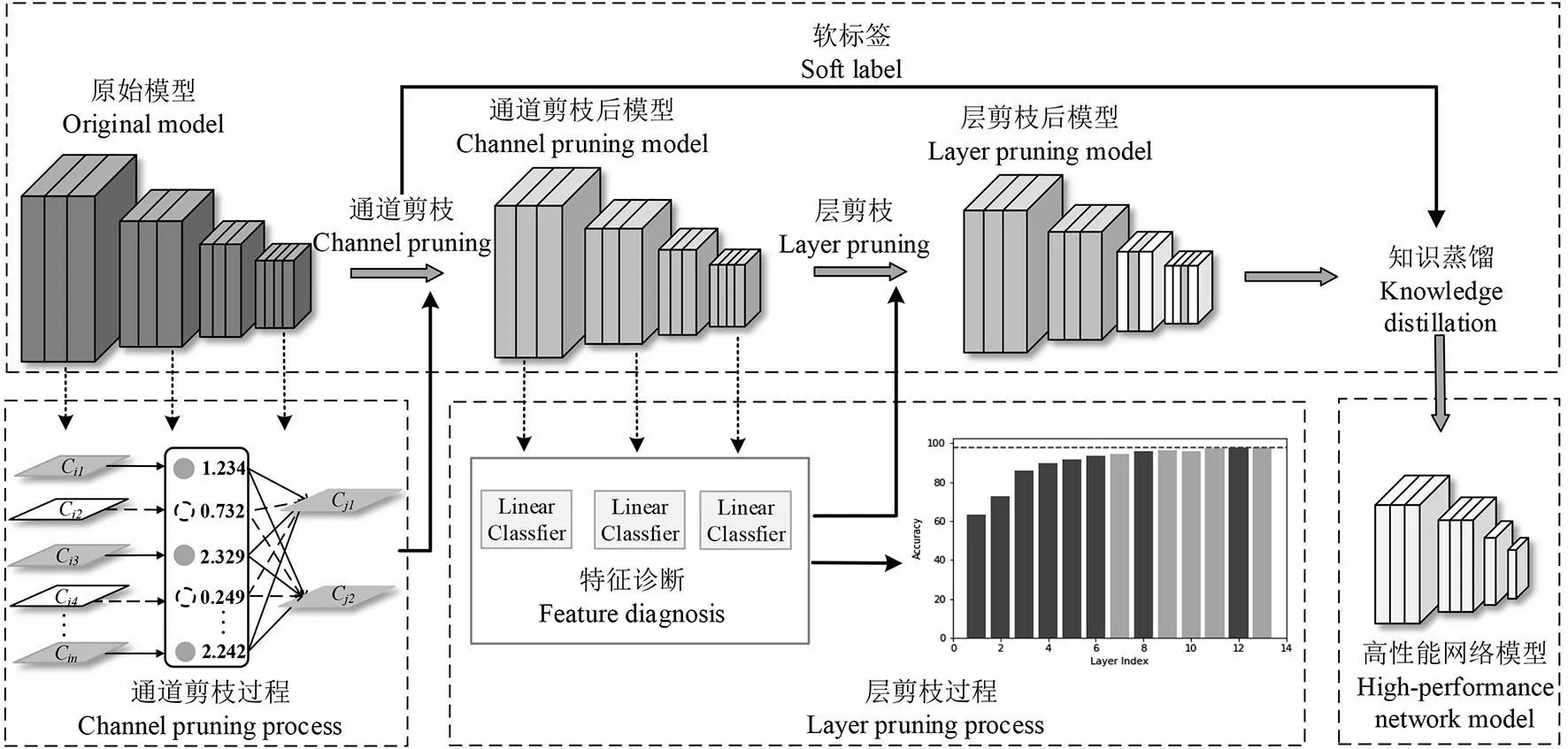
图1 基于通道和卷积层联合剪枝的模型压缩方法示意图Fig.1 Schematic diagram of model compression method based on joint pruning of channels and convolutional layers
1.1.1 卷积神经网络模型构建 Vgg 网络具有结构简单、模型推理速度快和易于部署等优点,在工业界和学术界被广泛使用[21]。本研究利用一种改进Vgg16 作为特征提取网络[22],其采用自适应平均池化替换3 层的全连接网络结构,极大减少了模型参数,使得模型抗过拟合能力更强,并提升了模型训练速度。具体网络结构如图2所示。卷积层主要用于特征提取,其中低卷积层可表征种子的边缘、角点、颜色等细节纹理信息,高层卷积更加关注图像复杂特征,比如形状、轮廓等,通过在卷积运算中不断迭代,从而实现农作物种子特征的有效提取。
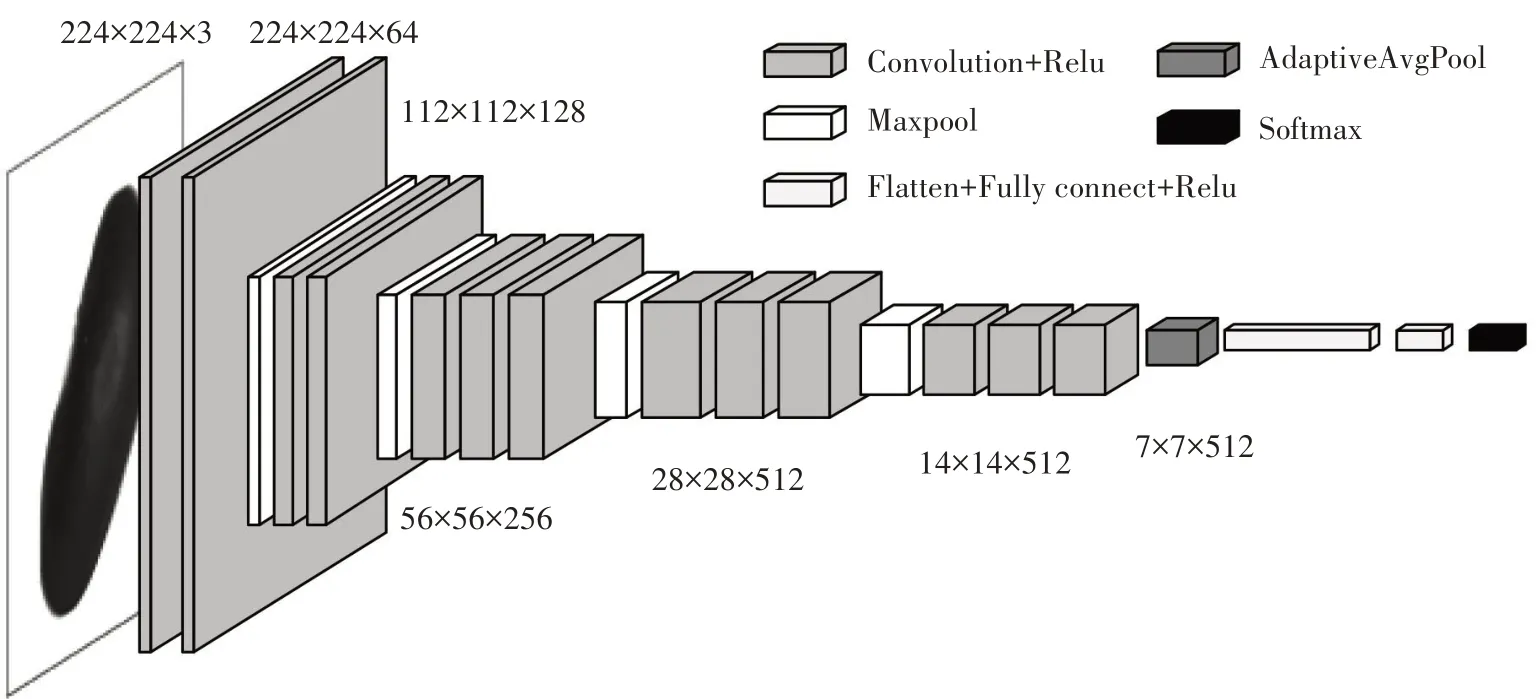
图2 用于种子分选的Vgg16深度模型结构图Fig.2 Structure diagram of Vgg16 depth model for seed sorting
1.1.2 通道剪枝 通道剪枝方法主要通过分析卷积层通道的重要性,在不损失模型精度的前提下,删除不重要的滤波器,实现对模型的压缩。其中,如何衡量通道重要性是模型压缩的关键。由于BN层具有加速收敛和正则化的作用,所以广泛存在于卷积神经网络中。因此,选用BN 层缩放因子作为衡量通道重要性的标准,通过引入通道稀疏正则化训练,迫使冗余通道的比例因子趋于0,然后移除小于设定阈值对应的次要通道,从而进行模型压缩[16],具体过程如图3所示。
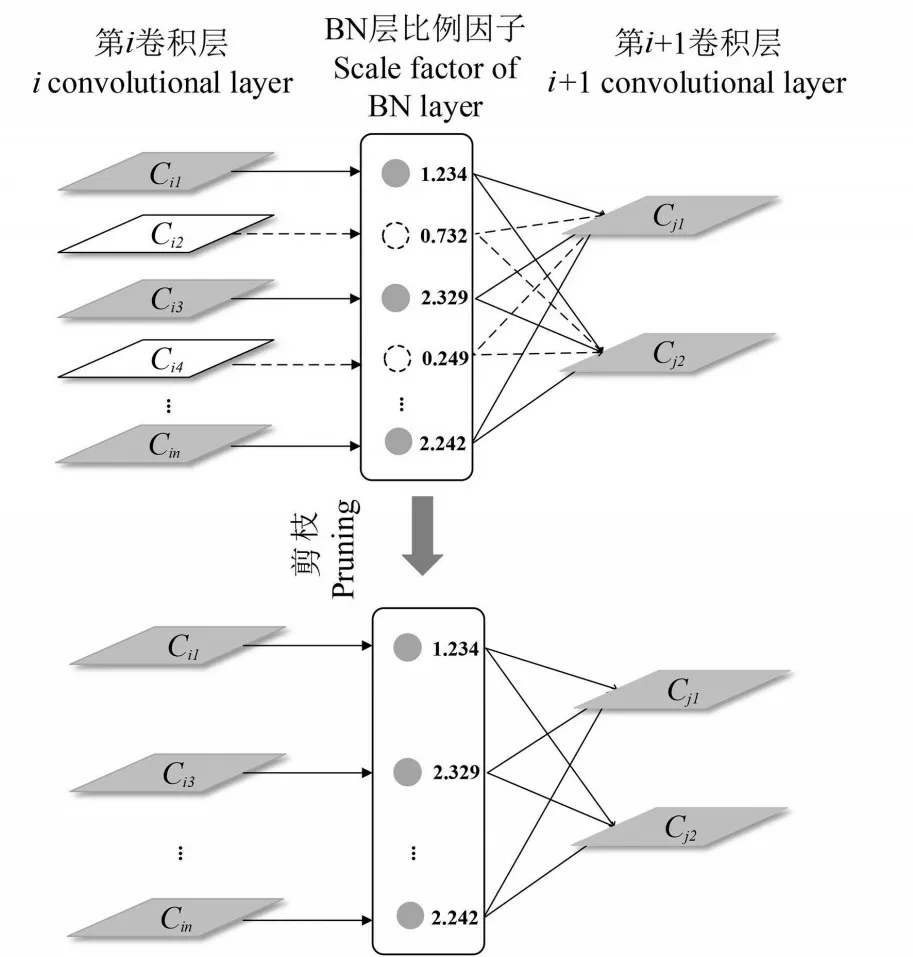
图3 通道剪枝示意图Fig.3 Schematic diagram of channel pruning
BN 层的比例因子代表对应通道的激活程度,其计算方法如公式(1)所示:
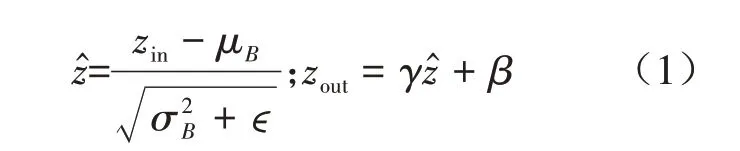
其中,zin和zout分别是BN 层的输入和输出,B表示当前的批量大小,μB和σB分别为输入的激活值均值与方差,γ和β分别为对应激活通道的缩放系数和偏移系数。为了便于剪枝且保持模型精度,本研究在损失函数中添加了惩罚因子,对BN 层的比例因子进行约束,将模型稀疏化,则损失函数可表示如公式(2):
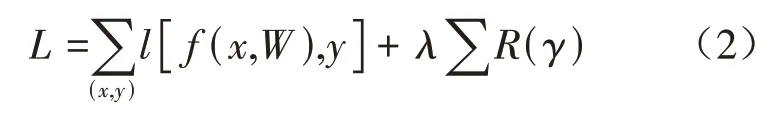
其中,x和y是训练的输入和输出,W是模型权重参数,l[f(x,W),y]是原损失函数,λ是正则化系数,λ越大,约束力度越大,R(γ) = |γ|表示正则化范数。由于L1范数正则化具有稀疏解特性,适合关键特征的选择,因此,选用L1 范数对比例因子进行约束求解,从而使不重要特征通道对应的比例因子置为零或逼近零,便于剪枝操作。

然后根据计算出的剪枝阈值θ将符合剪枝要求的滤波器进行修剪,从而生成剪枝后的精简模型。最后,通过对剪枝后的模型进行微调,以恢复损失的准确率。
1.1.3 层剪枝 通道剪枝在保证模型精度的前提下,实现对模型的压缩,然而由于网络深度使数据读写频繁,模型推理速度改善有限。层剪枝技术,可实现在压缩模型的同时,显著提升模型计算效率。因此,提出通道和卷积层联合剪枝的方法。在通道剪枝的基础上,采用层剪枝进一步对模型压缩处理。
层剪枝主要通过评价不同卷积层的重要程度,删除不重要的卷积层,进而实现对模型的裁剪。现有基于层剪枝的方法是粗粒度的,由于不同种类的种子区分度小,导致种子识别精度下降明显。实际上,中间卷积层包括更多与任务相关的重要信息,通过分析层与层直接的关联性,可以实现更为准确的剪枝,从而保持识别精度。因此,提出一种基于线性探针的层剪枝方法,利用层之间的关联性,在尽可能保持模型精度的前提下,实现模型剪枝并提升推理速度。
该方法使用一个全连接层作为线性分类器来评估各卷积层的有效性。由于每一层都有不同的输出特征形状,因此采用自适应平均池化统一嵌入长度,从而使每个卷积层输出尺寸相同的特征图:
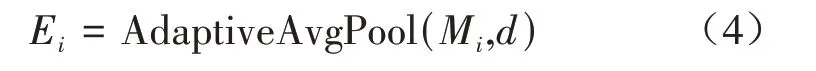
其中,Mi为i(1 ≤i≤L)层输出的特征图,自适应平均池化将输出特征图的Mi减少为Ei∈Rn×d×d,最后通过flatten(·)函数将每层输出转化为向量ti,送入线性分类器fi(ti),具体如公式(5)(6)所示:
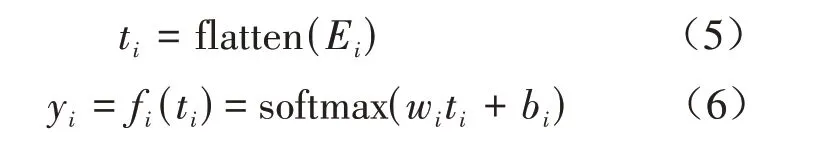
其中,wi和bi分别为线性分类器的权重和偏置项。在训练线性层时,首先固定已经训练好的原始网络参数,然后通过反向传播对线性分类器进行逐层的微调,每一层得到最佳识别精度,将相邻层最佳识别精度的差值作为评价卷积层重要性的指标,然后基于预定义的阈值χ来去除不重要的卷积层。具体算法实现流程如表1所示。

表1 基于线性探针的层剪枝算法实现流程Tab.1 Implementation process of layer pruning algorithm based on linear probe
1.1.4 知识蒸馏 经过剪枝后,得到了一个更加紧凑的网络模型。然而由于剪枝过程中,不可避免地损失了部分有效信息,导致模型性能有所下降。知识蒸馏技术可以将原始模型学习到的丰富特征信息迁移到剪枝后的小模型上,进而提升其性能。因此,采用知识蒸馏技术[19],提升压缩模型的性能。
教师模型为训练出过参数化的原始模型,学生模型为经过通道和层联合剪枝生成的紧凑模型。通过在原始损失函数中引入附加项(即两模型的输出结果的差),实现大模型对小模型的指导,从而提升小模型性能。具体实现可描述如下,通过在Softmax 层引入温度参数T使输出变得更加平滑,以突出不同类别的信息表征,具体如公式(6)所示:
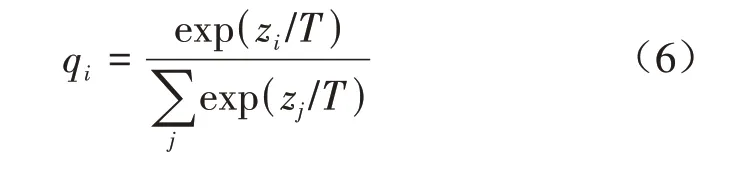
其中,zi为Softmax 层输出的类别概率,exp(·)为指数运算,qi是得到的教师网络与学生网络软目标输出,然后通过作差得到蒸馏损失,作为目标损失的附加项。除此以外,学生网络还存在与真实标签值之间的损失项。所以学生网络的最终目标函数为两者的加权平均,具体如公式(7)所示:
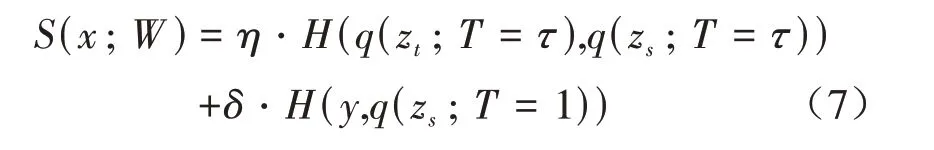
其中,S(x;W)为学生网络总损失函数,x为输入,W为学生网络权重参数,H为交叉熵函数,y为数据集真标签,q(·)为上式的软目标函数,η与δ分别是相应损失项的系数,zt与zs分别为教师网络与学生网络的Softmax 层输出的类别概率。最终通过迭代训练,实现大模型对小模型的指导,从而提升小模型性能。
1.1.5 模型训练 本研究基于分类模型配置网络参数,并通过反向传播损失函数的梯度来更新网络权重。输入图片尺寸224×224,并使用小批量随机梯度下降(SGD)对网络进行训练,正则化系数λ设为0.000 1,初始学习率为0.001,Batch_size 为16,Epoch 为64,在1/2 和3/4 的步数中学习率调整为原来的1/10,动量参数设为0.9,权重衰减参数设为0.000 1。在进行知识蒸馏时温度参数T为3,δ为0.3。此外还采用了水平、竖直翻转和旋转等方法进行数据增强。
本研究中建模及模型训练在Ubuntu 18.04系统上进行。软件主要基于深度学习架构的Pytorch 和Python 开发环境的Spyder。硬件基于英特尔(R)酷睿(TM)i7-6770K@4.00 GHz CPU 和1 个NVIDIA GTX1080 图形处理器,并采用CUDA10.0 进行加速。为了评价模型性能,采用的评价指标有准确度、参数量、计算量和推理速度(ms/p)。
1.2 材料
为验证基于通道和卷积层联合剪枝的模型压缩方法的自适应性,选用公开的玉米种子数据集及自建的红芸豆数据集进行试验。
1.2.1 玉米种子数据集 玉米种子数据集是土耳其萨卡里亚玉米研究所公开的单倍体和双倍体玉米种子数据集,包括3 000 个RGB 图像的玉米种子[23]。在该数据集中,有1 230个单倍体种子图像和1 770 个双倍体种子图像。根据种子的大小,数据集中图像的分辨率在300×289 像素和610×637 像素之间变化,典型图像如图4 所示。选用861 幅单倍体图像和1 239 幅双倍体图像作为训练集,其余图像用于测试。
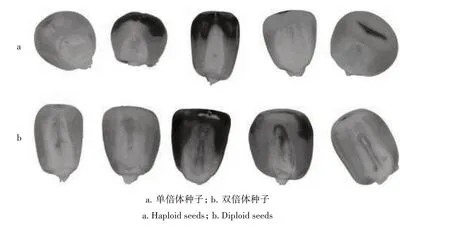
图4 玉米种子数据集Fig.4 Maize seed dataset
1.2.2 红芸豆数据集 玉米种子数据集是针对二分类种子分选问题。为了验证基于通道和卷积层联合剪枝的模型压缩方法在多分类种子分选任务中的有效性,自建了红芸豆种子数据集。采集设备为1 台1/2.5CMOS 相机,采用白色环形光源进行补光,并利用白色背景板使红芸豆种子和背景更容易区分。按照企业对红芸豆品质分级的要求,将红芸豆样本图像分为丰满豆、破皮豆、干瘪豆和破损豆4类,典型图像如图5 所示。共计采集3 831 张,其中丰满豆1 661 张、破皮豆509 张、干瘪豆1 173 张、破损豆488张,其中训练集与测试集的比例为7∶3。
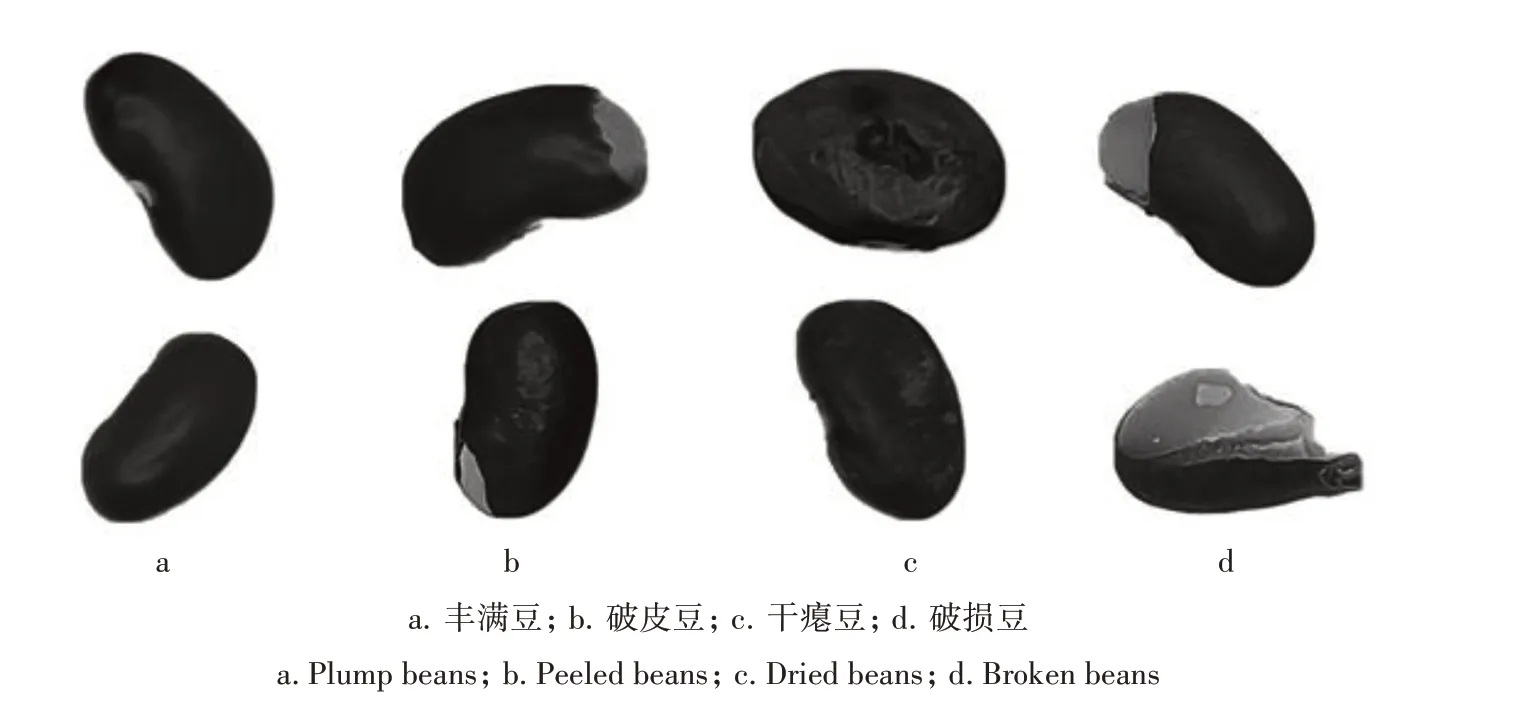
图5 红芸豆数据集Fig.5 Red kidney bean dataset
2 结果与分析
2.1 基准试验结果
首先在红芸豆和玉米种子数据集上对模型进行训练,其结果如表2 所示。其中Vgg16_B 为基准网络,Vgg16_S 指加入L1 正则项,目的是使不重要特征通道对应的比例因子置为零或逼近零,便于通道剪枝。从结果可以看出,加入稀疏正则化使红芸豆和玉米种子分类准确度分别为97.56% 和96.78%。

表2 Vgg16在加入正则化前后结果对比Tab.2 Comparison of Vgg16 results before and after regularization
2.2 通道剪枝试验结果分析
将稀疏训练后的模型进行通道剪枝以获取更紧凑的网络模型,从图6可以看到,经过剪枝的神经网络模型准确度甚至高于原始网络,这是因为原始模型参数是冗余的,并不是一个最优网络的结构,而神经网络修剪本质是一个最优子网络结构搜索问题(Neural architecture search,NAS),所以经过修剪的模型,甚至可以达到比原始模型更优的结果。同时也可以观察到,当通道剪枝比例设置过小,节省的资源会很有限;设置过大时,会因剪掉过多的通道而导致模型性能显著下降。综合考虑准确率与模型尺寸之间的平衡,本研究选择了两者的最佳折衷点,即玉米种子和红芸豆数据集都以60%的剪枝率进行修剪。2种数据集在该比例下的通道剪枝结果如表3所示,在该剪枝比例下,原始模型的参数是剪枝模型的5 倍以上,而且计算量仅是原始模型的17.35%(红芸豆)和16.44%(玉米种子),同时精度并没有明显降低,甚至在玉米种子数据集下模型性能得到了一定程度的提升。
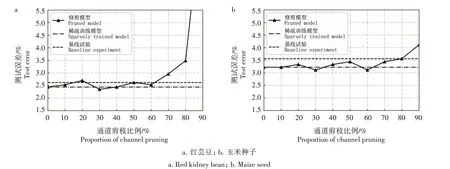
图6 通道剪枝比例对识别准确度的影响Fig.6 The influence of the pruning ratio on the recognition accuracy
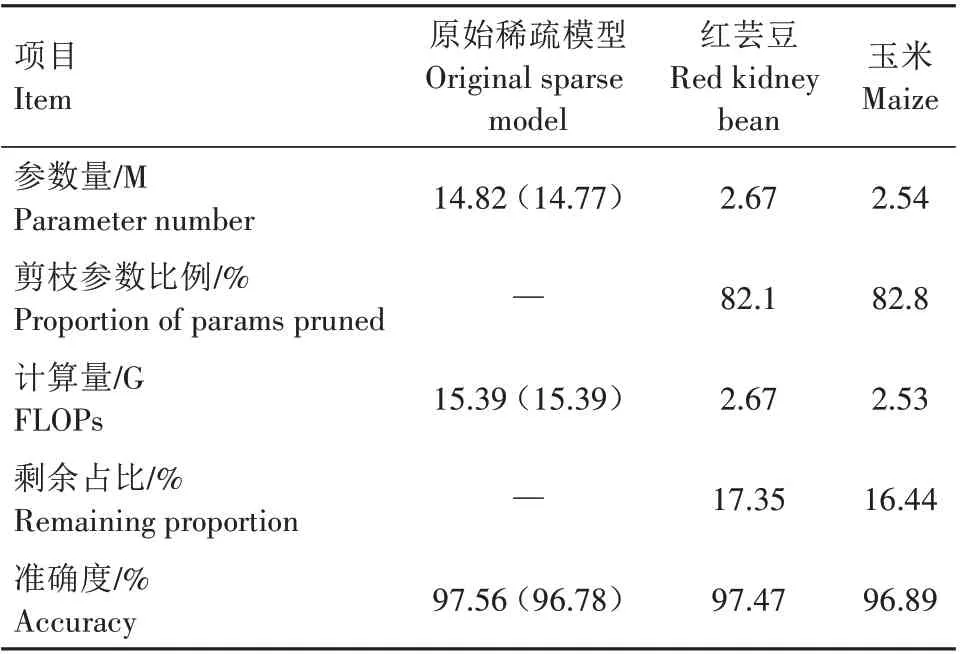
表3 60%通道剪枝试验结果Tab.3 Experimental results after 60%channels were pruned
2.3 层剪枝与知识蒸馏试验结果分析
层剪枝技术可实现在模型压缩的同时显著提升模型推理速度。由于不同种子差别体现在纹理、形状及边缘等低层特征,而高层语义特征对种子分选性能影响很小。因此可以对高层特征进行直接剪枝操作;对于低层特征,本研究提出基于线性探针的层剪枝方法对模型进一步压缩。为了验证不同层对识别的影响,根据表1 算法,将阈值设为0.4,在红芸豆和玉米种子数据集上利用通道剪枝后的网络模型,生成卷积层的诊断结果。如图7 所示,虚线是验证精度,对识别贡献较小的层采用网格柱表示,对识别贡献度大的层采用条纹柱表示。通过特征诊断可视化,突出显示了修剪后的层次,依据该结果,在红芸豆和玉米种子数据集上分别删除第10、11、12、13 和第6、7、9、10、11、12 层,这也验证了高层语义特征对种子分选性能影响较小的结论。
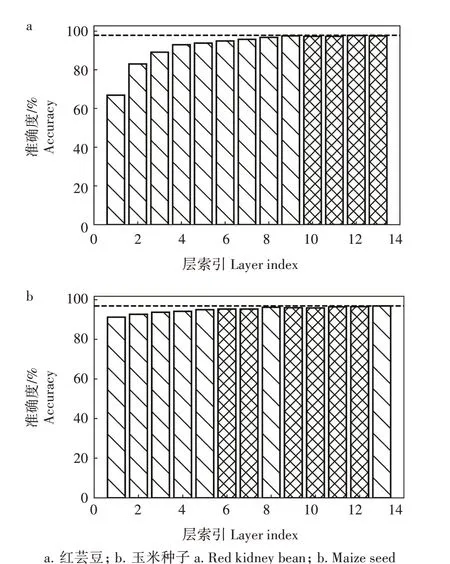
图7 通道剪枝后模型线性探针诊断结果Fig.7 The results of linear probe diagnosis of the model after channel pruning
表4对比原始稀疏模型Vgg16_S(teacher)、直接训练层剪枝后模型Vgg16_Pruned 和利用知识蒸馏技术训练层剪枝后模型Vgg16_Pruned(student)的试验结果。可以看出,本研究提出的深度模型压缩方法能够显著降低计算成本,并取得与原始深度模型相当的性能。例如,在红芸豆和玉米种子数据集上,所提出的方法使模型计算量减少86.55%(红芸豆)和91.55%(玉米)的情况下,模型获得了97.38%(vs.97.56%)和96.56%(vs.96.78%)的分类准确度。此外,通过知识蒸馏技术,学生模型可以充分获取教师模型中获取的知识,从而提升模型性能。如表4所示,知识蒸馏相较于直接训练层剪枝后的模型,准确度分别提高了0.26(红芸豆)、0.56(玉米种子)个百分点。以上试验结果表明,采用线性探针去除冗余的特征表示层,并使用知识蒸馏技术重新训练修剪后的网络结构,可得到紧凑而高效的种子分选模型。
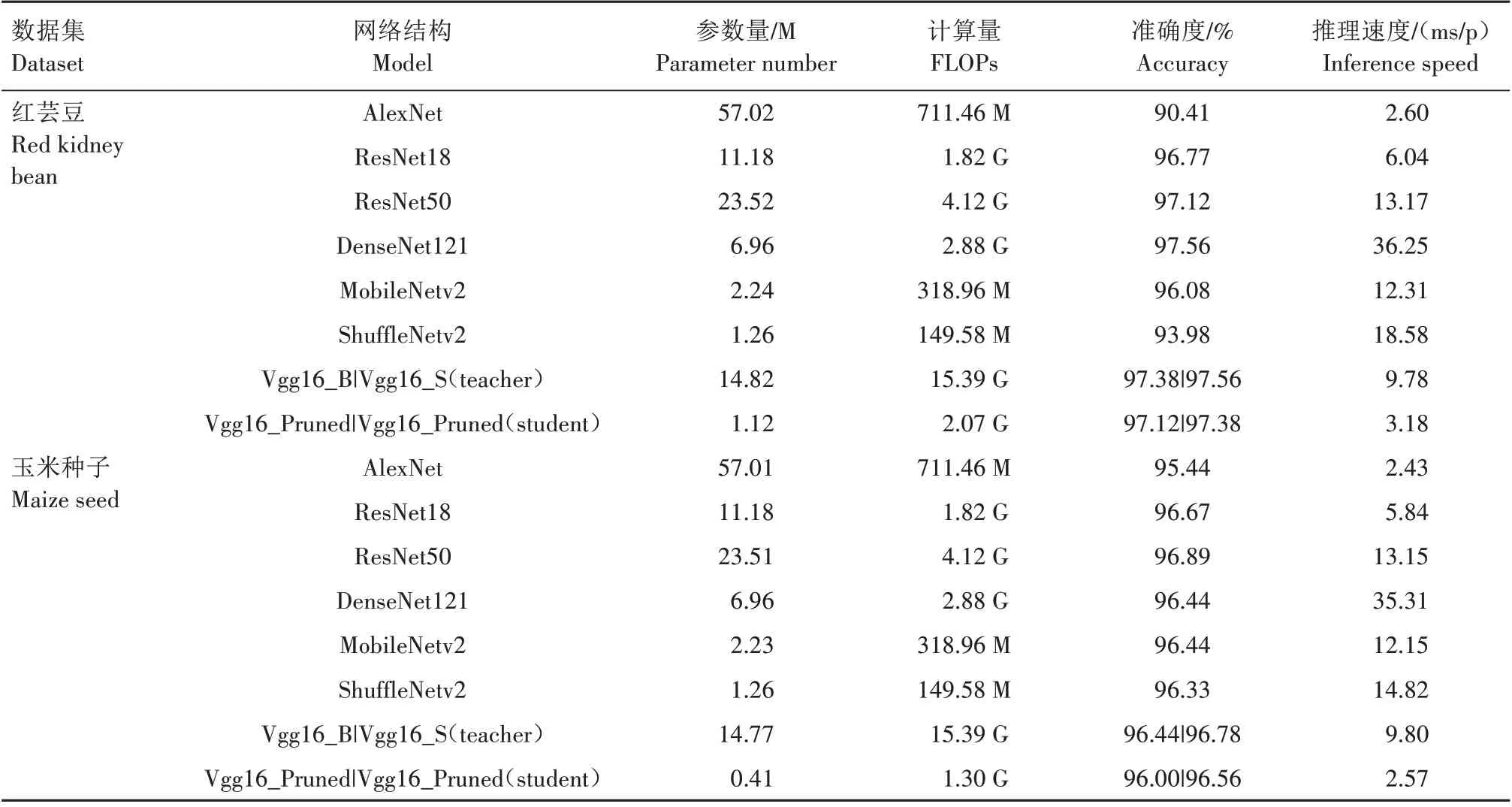
表4 剪枝后模型与典型CNN网络性能对比Tab.4 Performance comparison between model after pruning and typical CNN network
2.4 典型网络性能对比
将基准模型Vgg16_B、剪枝蒸馏后网络模型Vgg16_Pruned(student)和一些典型卷积网络模型( 如AlexNet、ResNet18、ResNet50、DenseNet121、MobileNetv2 和ShuffleNetv2 等)加载到NVIDIA 公司生产的Quadro M5000 GPU进行推理速度测试,结果如表4 所示,其中Vgg16 在联合剪枝前后,对1 张红芸豆(玉米种子)图片的推理速度分别为9.78 ms/p(9.80 ms/p)和3.18 ms/p(2.57 ms/p),提高了2.1 倍(2.8 倍)。与Vgg16_Pruned(student)相比,尽管ResNet50 在玉米数据集上获得了96.89%(vs.96.56%)的分类准确度,但是参数量和推理速度分别达到了23.51 M(vs.0.41 M)和13.15 ms/p(vs.2.57 ms/p),并不利于部署在资源受限的边缘设备上。此外,与典型的轻量化网络(MobileNetv2、ShuffleNetv2)相比,Vgg16_Pruned(student)在参数量和计算量较少的情况下,也得到了最好的分类准确度和推理速度,如在玉米种子数据集上,在参数量为0.41 M(vs.2.23 M、1.26 M)条件下,学生网络获得了96.56%(vs. 96.44%、96.33%)的分类准确度和2.57 ms/p(vs. 12.15 ms/p、14.82 ms/p)的推理速度,这也说明所提方法在实际部署条件下具有高效性。
3 结论
为了解决目前用于种子分选的深度学习模型参数量大且执行效率不高的难题,本研究结合模型压缩和知识蒸馏技术,提出了一种基于通道和卷积层联合修剪网络的模型压缩方法,并应用于种子分选问题。结果表明,在2个数据集上,所提出的方法在使模型计算量减少86.55%(红芸豆)和91.55%(玉米)的情况下,实现了实际推理速度2.1 倍和2.8倍的提升,且仍保持较好的识别准确度(97.38%和96.56%)。同时,通过在Quadro M5000 GPU 上的试验也证实,压缩后模型与典型的轻量化CNN 网络相比(如MobileNetv2、ShuffleNetv2)在移动端设备上有更好的测试性能和推理速度。
本模型包含着诸多间断的处理步骤,后期考虑将此过程进行串联,设计一种端到端的学习模型,并对模型进行量化,为模型部署到移动端进行农作物的分级分选提供支撑。
