基于机器学习算法建立2型糖尿病患者冠心病辅助诊断模型
2022-04-16黄浩东刘小株张祖跃向天雨
黄浩东 刘小株 龚 军 刘 杰 张祖跃 向天雨
(1重庆医科大学医学数据研究院,2医学信息学院 重庆 400016;3重庆医科大学附属大学城医院信息中心 重庆 401331)
2型糖尿病是一种胰岛素分泌不足、胰岛素作用效果差或两者兼而有之的慢性代谢性疾病。随着我国居民生活方式的改变与人口老龄化的加剧,截至2019年我国糖尿病患者数量达到了1.16亿[1]。尽管对于糖尿病是先于冠心病发生还是在疾病早期并存的问题仍有争议,但糖尿病引起的氧化应激、晚期糖基化终末产物和慢性炎症反应对血管内皮功能有害,从而导致心血管疾病的观点已被广泛接受[2],这表明2型糖尿病是发生微血管和大血管并发症的主要危险因素。糖尿病患者发生心血管疾病的相对风险比非糖尿病患者高2~4倍[3-4],冠心病是其中最严重的并发症之一,且与非糖尿病的冠心病患者相比,2型糖尿病患者症状往往不典型,可能是因为2型糖尿病患者常伴有严重的自主神经功能障碍[5-6],使得机体痛阈值增高,即使发生严重心肌缺血,患者心绞痛症状也不明显。冠状动脉造影术虽是诊断冠心病的金标准,但属于有创性检查,且价格昂贵、操作复杂、易产生不良反应,加之2型糖尿病患者痛阈值较高、患病早期无明显疼痛感,易导致疾病治疗延误。因此,本研究从数据驱动的角度,使用机器学习与统计学相关理论方法,对行冠状动脉造影术的2型糖尿病患者建立分类模型,以辅助诊断是否合并冠心病。
资料和方法
数据来源数据来源于重庆医科大学医学大数据平台,该平台汇集了重庆7家医疗中心的电子病历数据,所有数据均已脱敏。本研究纳入2014年1月1日至2019年12月31日入院行冠状动脉造影术的2型糖尿病患者。纳入标准:(1)既往史中有明确的2型糖尿病的患病年数以及控糖史;(2)住院期间行冠状动脉造影手术且造影记录保存完整。排除标准:(1)糖尿病急性并发症、妊娠期糖尿病以及近期(半年以内)确诊2型糖尿病;(2)患风湿性心脏病、系统性红斑狼疮等自身免疫病;(3)合并癌症;(4)既往已被诊断为冠心病;(5)严重器官衰竭;(6)全身性感染。共计纳入944例2型糖尿病患者,根据冠状动脉造影情况分为2型糖尿病合并冠状动脉狭窄<50%(T 2DM组,229例)和2型糖尿病合并冠状动脉狭窄≥50%(T 2DM-CAD组,715例)。T 2DM组中男性94例,女性135例,年龄33~87岁;T 2DM-CAD组中男性422例,女性293例,年龄34~90岁。
指标选取根据冠心病临床指南和2型糖尿病合并冠心病相关研究[7-9]收集患者行冠状动脉造影术前的35项指标,包括一般资料(如年龄、性别、合并症等)和患者入院后第一次检验的实验室指标(如尿常规、肝肾功能、血脂指标等)。
统计学处理采用SPSS 25.0和R3.6.1进行统计分析,缺失指标使用missForest算法填补。采用Matchit包的邻近匹配(nearest neighbor matching)方法对收集的原数据按照性别、年龄和是否合并高血压进行倾向评分匹配(propensity score matching,PSM),卡钳值设定为0.02,T 2DM组与T 2DMCAD组按1∶2匹配。采用KS方法检验计量资料的正态性,计量资料以x±s或M(P25,P75)表示,组间比较采用t检验或Mann-Whitney U检验;计数资料以例(%)表示,组间比较采用χ2检验。将两组间有差异的指标纳入逐步向前Logistic回归(α入=0.05,α出=0.10)分析2型糖尿病合并冠心病的危险因素,具体变量名与赋值如表1所示。P<0.05为差异有统计学意义。

表1 变量赋值Tab 1 Variables and their assignments
机器学习模型构建分类模型构建采用python 3.8.5版本、anaconda3集成开发环境。将数据按4∶1分为训练集和测试集,训练集用于分类模型的构建。采用Scikit-learn包分别构建Logistic回归模型、随机森林(Random Forest,RF)模型、支持向量(Support Vector Machine,SVM)模型和极限梯度上升(eXtreme Gradient Boosting,XGB)模型。采用 bayes_opt包 中 贝 叶 斯 优 化(Bayesian Optimization,BO)算法分别优化XGB算法5个主要超 参 数 n_estimators、subsample、max_depth、learning_rate和min_chid_weight;RF算法3个主要超 参 数 n_estimators、min_samples_split、max_features;SVM算法2个主要超参数C和gamma以及Logistic回归超参数C,设定寻找模型最大AUC对建立的4种机器学习模型进行参数优化。
模型评估采用5折交叉验证法和验证集评估模型性能,评价指标为准确率、精确率、召回率、F1分数、ROC曲线下面积(AUC),以F1分数和AUC的最大值判断模型是否为最优模型。
结 果
匹配前后两组基线资料比较T 2DM-CAD组匹配前后,冠状动脉单支病变分别为218例(30.49%)和115例(29.56%),冠状动脉两支病变分别为199例(27.83%)和101例(25.96%),冠状动脉三支病变298例(41.68%)和173例(44.47%)。匹配后T 2DM病程、心率、吸烟史、糖尿病肾病差异有统计学意义(P<0.05),其余基线资料差异无统计学意义(表2)。匹配后共筛选出610例患者,其中T 2DM-CAD组389例,T 2DM组221例(表2,图1)。
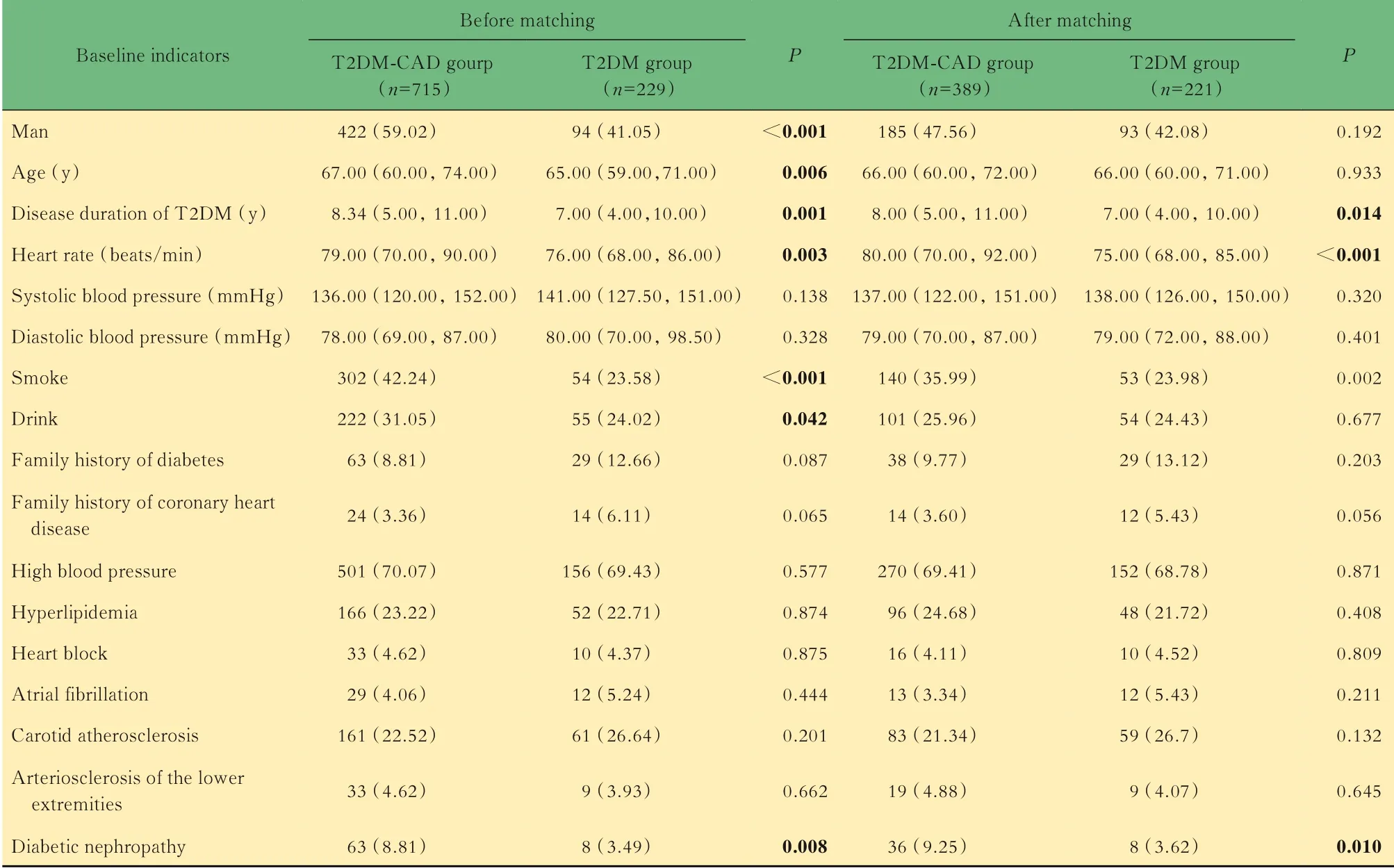
表2 匹配前后两组基线指标对比Tab 2 Comparison of baseline indicators between the two groupsbefore and after matching
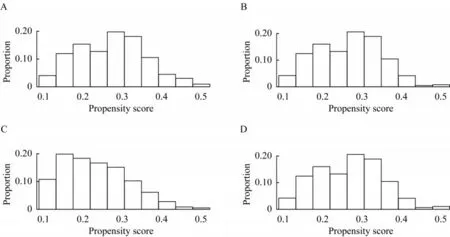
图1 根据PSM筛选与剔除的患者倾向评分分布图Fig 1 Distribution of patient propensity scores screened and excluded according to PSM
单因素分析结果共纳入22项指标,包括4项基线指标和18项检验指标。单因素分析结果显示,两组间T 2DM病程、心率等20项指标差异有统计学意义(P<0.05),谷氨酰转肽酶和谷丙转氨酶差异无统计学意义(表3)。
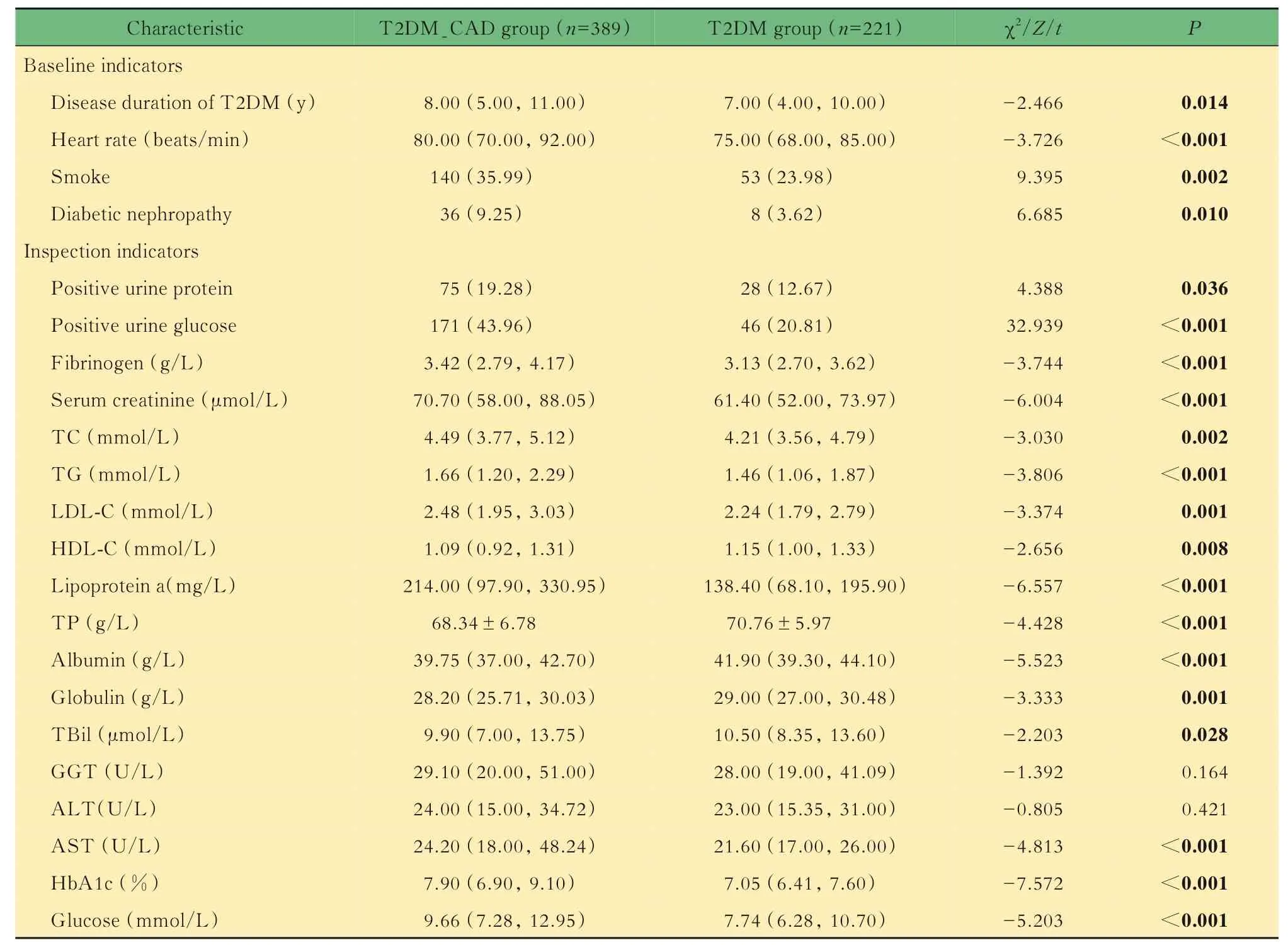
表3 T2DM组与T2DM-CAD组相关指标的单因素分析Tab 3 Univariate analysis of related indexes in T2DM group and T2DM-CAD group
Logistic回归分析结果将单因素分析有意义的20个指标进行逐步向前Logistic回归分析,其中11个变量纳入最佳回归方程(表4)。
机器学习模型结果将表4中的11项指标纳入4种机器学习分类模型,并用BO算法优化4种分类模型,结果显示当n_estimators=2、min_samples_split=10、max_features=69时(表5),无论是5折交叉验证结果还是单独的验证集,RF算法性能最优(表6~7)。图2为4种分类模型的5折交叉验证ROC曲线图。
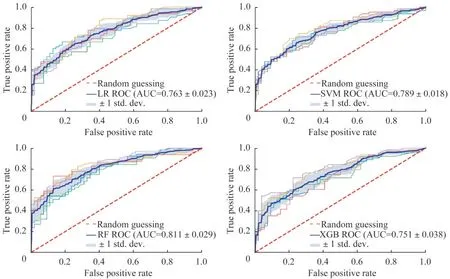
图2 4种分类模型5折交叉验证ROC曲线图Fig 2 5-fold cross-validation ROC of 4 classification models

表4 2型糖尿病合并冠心病差异性指标Logistic回归分析结果Tab 4 Logistic regression analysis results of difference index of type 2 diabetes mellitus complicated with coronary heart disease
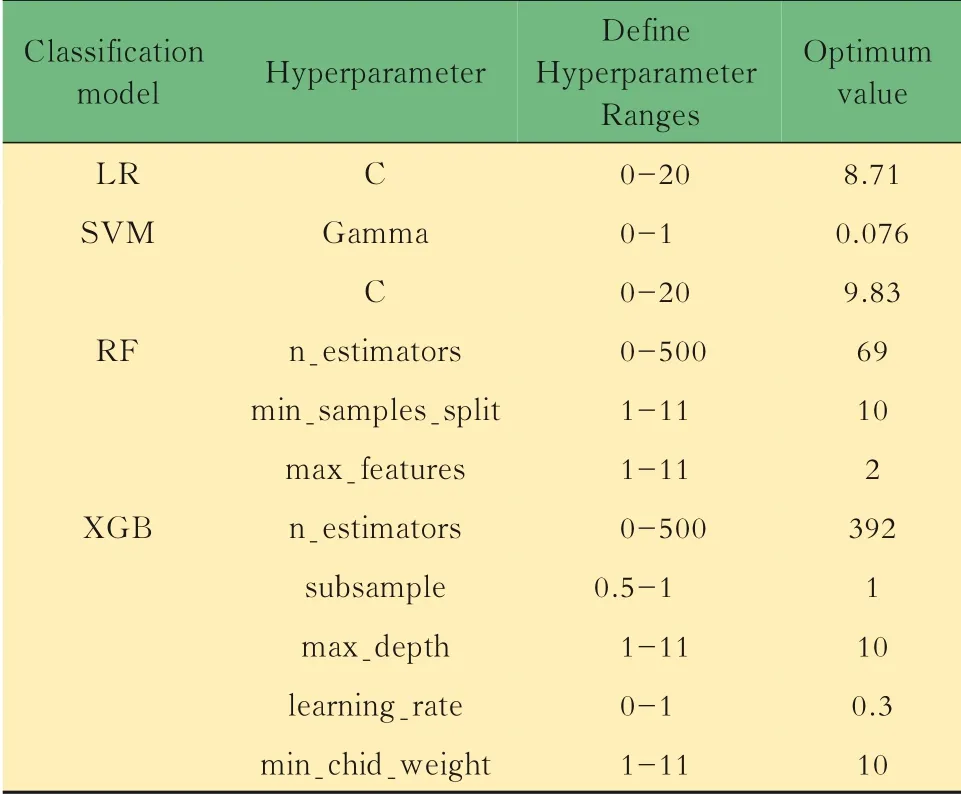
表5 参数选择与优化Tab 5 Parameter selection and optimization
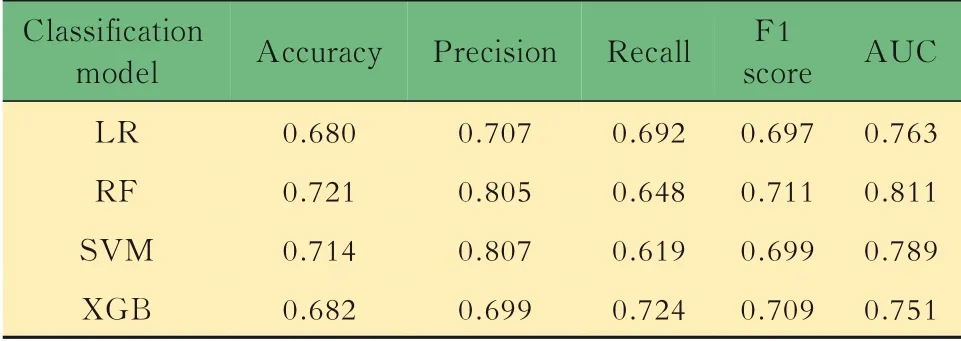
表6 4种机器学习模型5折交叉验证性能评价表Tab 6 Performance evaluation table of 4 machine learning models by 5-fold cross-validation
讨 论
本研究对行冠状动脉造影术的2型糖尿病患者就诊数据进行回顾性分析。由于存在选择偏倚,因此采用“PSM+单因素分析+多因素分析”筛选出2型糖尿病合并冠心病的危险因素,并比较了Logistic回归、SVM、RF、XGB4种分类算法性能,为2型糖尿病在慢病管理中是否发生合并症(本文为冠心病)提供了研究思路,有利于及早启动冠心病的二级预防,减少致死性心血管事件的发生。

表7 4种机器学习模型在验证集中的性能评价表Tab 7 Performance evaluation table of four machine learning models in validation set
本研究筛选出的2型糖尿病合并冠心病的11项危险因素,包括心率、吸烟、糖尿病肾病、血肌酐、甘油三酯、脂蛋白a、白蛋白、总胆红素、谷草转氨酶、糖化血红蛋白和尿糖。其中血肌酐、糖尿病肾病、尿糖、谷草转氨酶在既往研究中报道较少。血肌酐在临床上常用于评估肾脏功能是否正常,糖尿病肾病是糖尿病最主要的微血管并发症之一[10],尿糖可作为检测糖尿病患者早期肾损伤的标志物。高浓度血肌酐、合并糖尿病肾病、出现尿糖现象都表明患者肾功能下降[11],肾功能降低可增加冠心病风险[12-13]。Salim等[14]对非糖尿病新加坡华人进行了一项病例对照研究,发现在传统危险因素中添加血肌酐可以更好地预测冠心病患病风险,这与本研究相符合。谷草转氨酶主要分布于心肌细胞中,约80%的谷草转氨酶作为一种非特异性的细胞内功能酶存在于心肌细胞的线粒体中。心肌损伤时,线粒体受损,谷草转氨酶显著升高[15-16]。因此,谷草转氨酶可以反映心肌细胞损伤的严重程度。研究表明谷草转氨酶与冠心病及其严重程度呈正相关,可以将该指标纳入各种冠心病风险预测模型[17-19]。而在本研究中谷草转氨酶为2型糖尿病合并冠心病的独立危险因素,说明对于2型糖尿病患者,谷草转氨酶依然可以作为鉴别冠心病的一种生物标志物。而其余的7项危险因素,包括心率、吸烟、甘油三酯、脂蛋白a、白蛋白、总胆红素、糖化血红蛋白,在2型糖尿病合并冠心病的研究报道中多见,与本研究的结论相似[7,20-24]。
虽然利用机器学习模型对冠心病进行疾病诊断已有较多研究[25-27],但都存在以下缺点:(1)冠心病起因不同,应分人群研究;(2)对照组与研究组同质性不高;(3)对照组缺少冠心病风险评估,而患者做过冠状动脉造影术、冠状动脉CT成像等,冠心病评估准确性较高。本研究基于冠状动脉造影术选取糖尿病患者群,根据造影结果分为两组,同质性高,在一定程度上解决了以上缺点。本研究也是国内首次从机器学习的角度判断2型糖尿病患者是否发生冠心病的综合性研究。在机器学习参数调优中,只能看到模型的输入和输出,所以很难通过求导和凸优化的方法来选择模型最佳超参数。以往通常是通过经验来选择超参数,然而这种方式往往得不到性能最优的机器学习模型。BO算法[28]可以很好地解决该问题,其思想为使用贝叶斯网格概率模型来显式反映变量之间的依赖关系及可行解的分布,具体步骤为利用先验知识逼近未知函数的后验分布从而调节超参数。XGB算法[29]是以CART回归树模型为基分类器的一种提升学习算法,是当前比较前沿的基于boosting思想的集成学习算法。SVM算法[30]的目的是寻找一个超平面对样本数据进行分割,然后转换为凸二次规划问题来求解,并且SVM算法在处理线性和非线性数据的小样本条件下具有良好的学习能力。LR算法使用Sigmoid函数作为预测函数。输入变量x通过线性函数输出变量y,然后输出变量y通过Sigmoid函数转换为带标签的结果,有着计算速度快、可解释性好、易于扩展和实现的特点。RF算法由决策树作为基分类器,是一种结合了Bagging集成学习理论和随机子空间方法的集成学习算法[31]。以上4种分类算法在目前疾病风险预测与疾病诊断中运用最多。在本研究中,优化后的RF模型(5折交叉验证:AUC=0.811,测试集:AUC=0.810)分类性能优于优化后的Logistic回归模型(5折交叉验证:AUC=0.763,测试集:AUC=0.707)、SVM模型(5折交叉验证:AUC=0.789,测试集:AUC=0.702)与XGB模型(5折交叉验 证:AUC=0.751,测 试 集:AUC=0.709),而Logistic回归模型、SVM模型和XGB模型3者分类性能相差不大。RF算法具有分类精度高、运算速度快、鲁棒性好等优点。在一些样本量和指标数与本研究相似的研究中,RF算法的分类性能表现为最优[32-33],与本研究结果相似。
本研究存在一定的局限性:首先,MissForest算法对混合型缺失数据插补后为优良数据的缺失极限是缺失值<30%[34],因此本研究未纳入缺失值>30%的指标(如BMI、血清C肽)。其次,本研究为回顾性临床研究,且模型缺少外部验证,结果需要进一步验证。最后,本研究建立的模型召回率较低,临床应用有一定的局限性。
综上,本研究基于2型糖尿病患者就诊数据,筛选出11项冠心病危险因素,并基于危险因素建立风险分类模型,研究结果得出贝叶斯优化后的RF算法具有较好的分类能力。可将本研究建立的模型嵌入临床决策支持系统,实现2型糖尿病患者在内分泌科就诊时收到冠心病风险提示以减少漏诊。
作者贡献声明黄浩东 研究设计和实施,论文构思和撰写。刘小株,龚军 研究实施,数据采集和整理。刘杰,张祖跃 研究设计,论文修订。向天雨 研究选题和设计,论文终审。
利益冲突声明所有作者均声明不存在利益冲突。
