基于网评文本的LDA游客目的地印象分析
2022-04-14张超群郝小芳王大睿李晓翔完颜兵
张超群,郝小芳,王大睿,李晓翔,完颜兵
(1.广西民族大学人工智能学院,南宁 530006;2.广西民族大学电子信息学院,南宁 530006)
0 引言
随着大数据时代的到来,各类网络大数据百花齐放,信息量大、可获取性强、传播力广已成为网络大数据不可替代的优势。国家《“十三五”旅游业发展规划》专门提到“全面建成小康社会后对旅游业发展提出更高要求,为旅游发展提供重大机遇,旅游业将迎来新一轮黄金发展期。”旅游业顺应时代发展趋势,不断向前发展。游客满意度是游客在到达旅游地之前的期望与游客在目的地实际体验相对比,依据期望与实际体验的比较结果形成的愉快或失望的状态。目的地美誉度则是由多个因素影响,而游客对目的地的感知信任直接影响目的地美誉度。鉴于游客满意度直接影响目的地美誉度,国内外学者对此进行了相关研究。例如,有些研究者通过遗传算法支持向量回归、基于经验模型分解和神经网络模型、上下文知识方法和在线数据来预测目的地旅游需求;有些研究者使用决策树分析入境游客的行为,并从社会大数据中提取有用信息用于制定目的地管理策略;有些研究者运用多元回归分析、结构化方程建模、分析搜索引擎和运用SPSS等软件技术进行频数、方差、因子、相关性及回归分析获取游客目的地形象感知,从而了解游客的行为特征。这些研究主要分析游客的行为特征,以此预测游客的偏好。
在信息化时代,游客倾向于查阅各种旅游攻略来制定个人旅游计划,而如何从海量的网评文本数据中获得游客的旅游偏好,成为我们的研究目标。有别于已有的相关研究重点关注行为分析,本文侧重于主题分析,主要是对在线网评文本运用数据挖掘技术提取高频词汇,来分析游客的旅游趋向,从而了解游客的总体需求,进而优化旅游资源配置,提高游客满意度,提升目的地美誉度,促进旅游业的可持续发展。
1 研究方法
1.1 数据来源
本文需要分析的数据来源有两个:①由2021年第九届“泰迪杯”全国数据挖掘挑战赛官(https://www.tipdm.org:10010/#/competition/1354705811842195456/question)提供的数据;②爬取穷游网(https://place.qyer.com/china/citylist-0-0-1)获得的在线网评数据。这两个网站均提供不同类别的网评文本数据,也都包含游客对旅游目的地的印象评价。
1.2 数据处理
对源数据进行处理的总体流程如图1所示,主要包括数据预处理、数据分析、数据筛选。首先,对网评文本主要进行re去重和Jieba分词的预处理。然后用词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)算法提取关键字,通过K-means算法找出聚类中心,结合K最近邻(K-Nearest Neighbor,KNN)算法对其分类。最后,统计数据并将其按词频排序,在构建专业语料库的基础上,计算高频词与语料库长度,筛选出符合隐含狄利克雷分布(latent dirichlet allocation,LDA)主题模型分析的数据,并将其映射为特征需求,从而获得游客的旅游偏好。

图1 数据处理总体流程
1.2.1 数据预处理
(1)数据清理。数据清理一般是指清除噪声、补充缺失信息和删除离群点等过程。由于“泰迪杯”数据存在一定的单一性,在“泰迪杯”数据基础上,为了更好地对游客目的地印象进行分析,从穷游网爬取172个网评文本页面作为分析的基础语料库,该语料库包含中国全部城市、区域名称及相关评论。由于两者数据包含大量的标签信息、图片、视频以及一些特殊字符等无效信息,本文通过Python语言及re正则表达式,对网评文本进行数据清理,其处理过程如下:
1)清理原始数据中的特殊字符,如空格、标点符号等。
2)在大规模数据中将数据逐条读入,清理重复出现的字段、格式不正确、时间不匹配等记录。
3)利用re正则表达式清理每条记录中的属性和标签等其他与数据分析无关的特殊符号。
4)将非结构化的文本数据转换为计算机能够识别的结构化数据,并将结构化数据按UTF-8编码格式逐条写入CSV文件中。
(2)中文分词与停用词过滤。中文分词是指以空格作为分隔词来分割出构成文本的单词。中文文本是按单词连字的,并且单词之间没有间隙。因此,在处理中文文本消息时,首先需要做的一件事情是拆分单词,称其对应的技术为自动分词技术。中文分词技术主要分为如图2所示的四类。
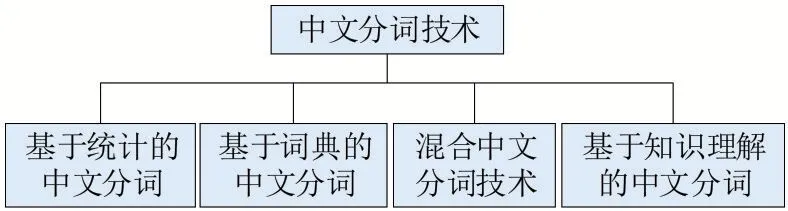
图2 中文分词技术分类
本文采用Python Jieba库对中文进行分词。Jieba库采用基于前缀词典实现高效词图扫描,获取每个词的词频,用正则表达式切分语句并对其分词,生成所有可能成词情况的有向无环图,采用动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用基于汉字成词能力的隐马尔科夫模型(hidden markov model,HMM),使得中文分词效果最优化。
在对文本数据分词后,仍然存在很多对数据分析无意义的词,这些词统称为停用词。为了进一步减轻数据分析难度和提高建模分析效果,需要对网评文本去停用词。本文中的停用词主要来源于网络中通用的停用词,通过过滤掉文档中的停用词,可以大大减少内存的占比并降低停用词带来的噪声,从而有效提高分词的精确性。
1.2.2 数据分析
(1)TF-IDF算法。在对网评文本数据分词后,需要把这些词语转化为向量,以供挖掘分析使用,这里采用TF-IDF算法,把网评信息转换为权重向量。TF-IDF算法的具体原理如下:
1)计算词频,即TF权重(term frequency)。

2)计算逆文档频率(inverse document frequency),即IDF权重。
建立一个语料库,用于模拟文本的使用情景。若文本中的词条与语料库吻合度低,则IDF越大,表明该词条类别区分能力较强。

TD-IDF与词条在文本中出现的次数成正比,与在整个语言中出现的次数成反比。求文本中每个词的TF-IDF值,并进行排序,词频较高的即为特征词。
生成TF-IDF向量的具体步骤如下:
1)运用TF-IDF算法,找出每个网评信息中与服务、位置、设施、卫生、性价比相关的关键词。
2)从网评文本中提取1)得到的关键词,组成集合,计算每个集合分词的词频,若无,则记为0。
3)按公式(3)计算每个网评信息的TF-IDF权重向量。
(2)特征提取。特征提取的流程如图3所示,文本处理一般是将词语作为特征项,如果直接使用分词后的数据不仅会造成“维数灾难”,而且会给后续的评分预测模型的构建与分析带来很大困难。若将无关词语提取出来,将会对模型评分预测造成干扰,影响最后结果,因此,需要根据词语在评论文本中的重要性,赋予其权重值,特征词权重越大就越能表示评论文本的情感,对最后结果影响越大。根据特征词的权重将影响评分预测的词语特征选出,运用TF-IDF过滤掉在网评文本中出现次数较少的词并计算特征词的权重。

图3 特征提取流程
(3)K-means聚类。通过去重后对文本进行分词,运用K-means算法提取五个关键词的聚类中心。根据“少数服从多数”判定聚类中心所属类别。K-means算法的大致步骤如图4所示。

图4 K-means算法步骤
(4)KNN算法。由K-means分类得到聚类中心,并结合KNN算法得出中心相似元素,从而判断其类别。KNN算法是一种简单的无参数的文本分类方法,不需要给定额外数据,即使存在噪声也可以对给定实验样本数据通过比较进行有效的分类,其处理流程如图5所示。

图5 KNN算法处理流程
1.2.3 数据筛选
对网评文本进行数据预处理后,统计每一条评论内容的中文字符数,并和爬取穷游网得到的语料库进行比较来区分评论文本的有效性。对数据分类,将其区分为有效评论和无效评论两类。其中,有效评论是指大于5个词且符合语料库的评论;而无效评论是指小于5个词且不符合语料库的评论。对网评文本进行分类处理的流程如图6所示。

图6 网评文本分类处理流程
图7、图8分别是对景区、酒店的评论数据进行处理前后的数据量变化对比图,这说明对网评文本进行数据处理可以有效减少后续分析要处理的数据量。

图7 景区评论数据数量变化对比

图8 酒店评论数据数量变化对比
2 旅游目的地形象感知分析
2.1 旅游感知形象高频特征词分析
通过对网评文本进行词频分析,从文本中提取出排名在前20名的热门旅游目的地,其结果如表1所示,词频越高表示游客对其关注度越高。用词云图对游客目的地进行可视化,其结果如图9所示,词频越高,词语呈现越大;反之,词频越低,词语呈现越小。

表1 排名前20的旅游目的地热门词

图9 游客目的地词云图
由表1和图9可知,频次较高的旅游目的地景点有温泉、公园、过山车、动物园、乐园、沙滩、瀑布、峡谷等,说明游客在业余时间喜欢户外游玩,偏向于去景点放松和参加集体游玩项目,体现当代广大人民群众的休闲旅游的特征。此外,频次较高的旅游目的地有广州、深圳、珠海等,说明游客倾向于去南方城市游玩。
2.2 旅游感知形象主题维度分析
利用LDA主题模型进行景区及酒店主题挖掘,并对聚类的结果进行可视化展示,呈现出聚类主题和每个主题中的关键词。根据主题中体现的游客评论的关注点,整理、归纳并总结出游客关注指标,对用户关注差异进行分析。
由于网评数据量大,从海量文本中直接获取有用的信息较为困难。在网评文本挖掘的过程中,对网评文本预处理后,用LDA模型对其进行主题识别,以挖掘网评语料中隐藏的用户需求,获得的主题识别图如图10—图14所示。
图10—图14是对网评文本数据进行主题分析,根据高频词的分布情况,将其从5个维度进行可视化。在主题识别图的左侧,每个圆圈代表海量文本的一个主题;圆圈之间的距离体现主题之间的相似度,如果距离越近,则说明两个主题越相似;圆圈的大小表示主题出现的概率,越大说明其所代表的主题核心度越高,小圆圈代表次要主题。在主题识别图右侧的条形图中,每列对应的主题词与文本词语的关联度表示为:
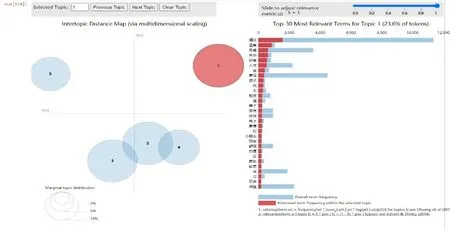
图10 评论数据识别主题1(服务)

图14 评论数据识别主题5(卫生)
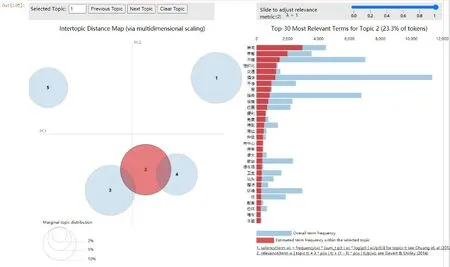
图11 评论数据识别主题2(位置)

图12 评论数据识别主题3(设施)

图13 评论数据识别主题4(性价比)

主题和文本词语间的关联度由词频和词语表现,并且可以通过调节参数λ(0≤λ≤1)来调节关联度。若λ越趋近于1,则认为该主题下词频越高的词与主题越相关,但这些出现次数较多的词可能同时出现在其他主题中。若λ越趋近于0,则表明该主题下特征词与主题越相关,这些词通常仅趋向于该主题。
本文取λ=1,对于图10—图14,图中5个圆圈的大小表示主题出现的概率大小,每个圆圈之间的距离为不同主题之间的关联度,条形图为每个主题的可视化展示,不同的主题对应不同的条形图,每个条形图中标红部分为该主题词在对应的主题中出现的频次,即为游客特征需求。从图10—图14中可知,主题1(服务)和主题5(卫生)清晰分明,与其他主题没有重叠和交叉现象;而主题2(位置)、主题3(设施)和主题4(性价比)之间有交叉重叠现象,说明这几个主题之间有重复的主题词。
通过LDA模型对网评文本进行主题识别,将图10—图14中条形图的每个主题映射为特征需求,根据每个主题的分类属性,可将所有的评论数据集识别为“服务”“位置”“设施”“性价比”“卫生”这5个主题,根据公式(4)可计算出每个主题词与文本词语之间的关联度分别为23.6%、23.3%、22.9%、15.6%和14.5%,关联度表示主题词与文本词语间的关联关系,具体关联程度由词频和词语表现,词频越高则表示与该主题的关联度越高,具体实验结果如表2所示。由表2可知,游客对服务的关联度最大,有酒店、温泉、早餐、房间、适合、感觉、体验等特征需求,这表明游客更关注对目的地服务的评价。
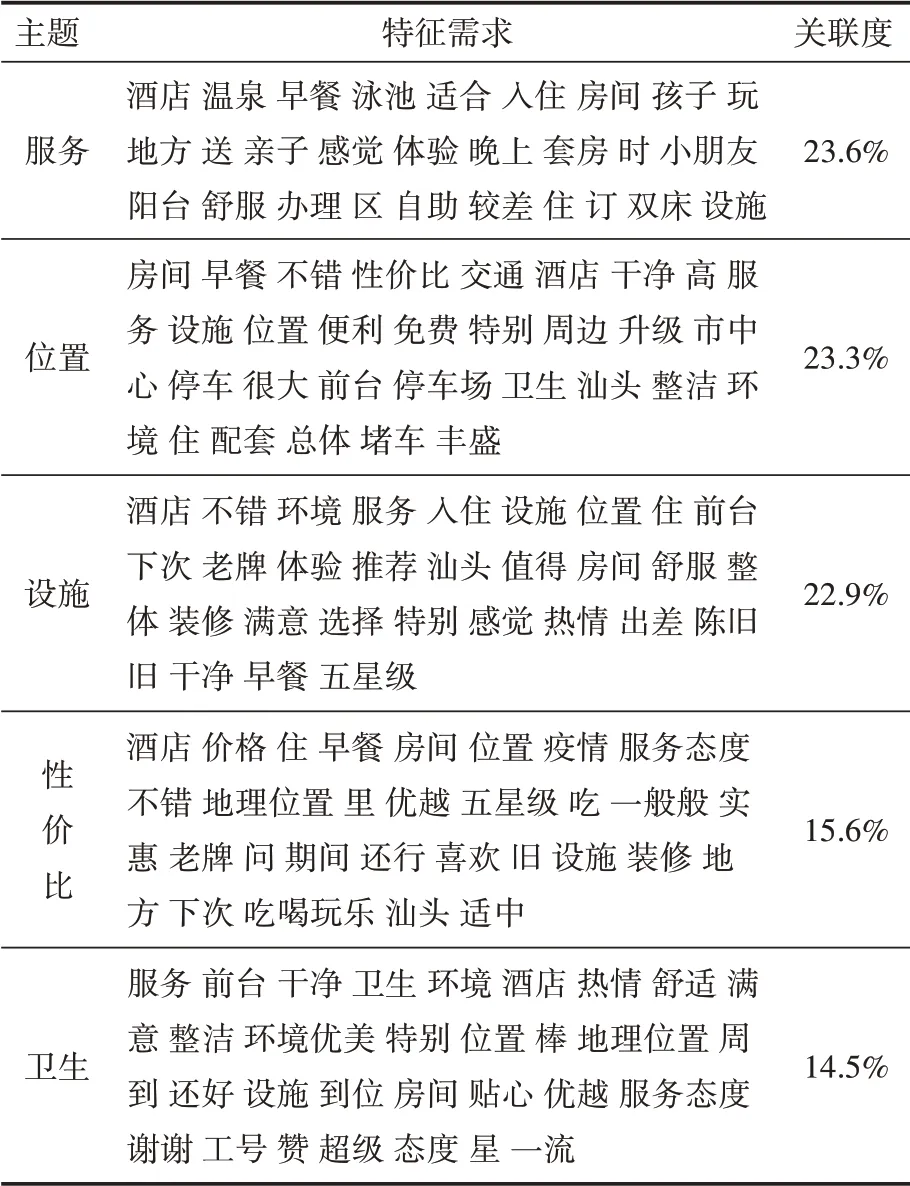
表2 游客特征主题需求映射
在旅游过程中,游客最关注景区及酒店的特征需求,游客通过对旅途的真实反馈,在一定程度上能将自身需求传递给旅游企业,以便企业对旅游方案做出针对性调整。表2正是将游客网评数据映射为企业最关注的特征需求,以此来挖掘游客更深层次的需求,有助于企业将未来规划与游客的旅游偏好密切联系起来。
3 旅游企业健康持续发展建议
网评文本数据已成为旅游企业获取游客需求的主要渠道。随着经济的不断发展,人们开始追求更高质量的生活,对旅游也有更高的要求。为了精准定位目标游客,旅游企业应充分了解游客喜好,提供大众喜闻乐见的服务。基于上文的分析结果,对旅游企业的健康持续发展建议如下:
(1)针对服务方面,了解游客真正需求,提供精准个性化服务。针对不同客户群体,推出多种特色旅游服务套餐。例如,针对亲子旅游,可选择成人和小孩游乐设施并存的景区,并提供家庭式的酒店客房;针对青年游客,可选择当下热门刺激、性价比高的游乐项目,并提供现代化简约风格的酒店客房;针对情侣游客,可为其提供浪漫的情侣套房,个性化定制浪漫景区的旅游路线,还提供旅行拍摄的服务;针对老年游客,可为其制定红色或自然景区路线,选择环境舒适、价格实惠的酒店。
(2)针对位置、设施和性价比方面,借助大数据分析与预测,开发旅游景区流量监控系统,为游客提供最佳的旅游路线,并且大力加强基础设施建设,建立智慧景区和智慧酒店,保证旅游服务和价值付出成正比。
近年来,旅游需求猛增和时空分布不均,热门景区高度集中,资源供不应求。对此应该充分利用交通、地理位置、社交媒体、气候、住宿等大数据,开发流量检测系统,提前对游客流量进行有效监控。同时应该推动旅游的信息化发展,如提供景区电子门票售票、进出口电子检票、智能排队、电子导游、二维码识别语音讲解、酒店自助入住等,不断提高景区和酒店基础设施建设,提高性价比。
(3)针对卫生方面,应该加强对酒店和景区的卫生监管,加大卫生的宣传力度。
随着景区的游客量增大,景区也面临着卫生问题,因此,在景区应该修建适量的卫生区,方便游客处理旅途中产生的垃圾。与此同时,应设立相应的监管部门,对破坏景区卫生的行为做出相应处罚。同时,政府加强保护环境的宣传力度,增强公民的卫生环保意识。
4 结语
随着大数据时代的到来及人民生活水平不断提高,旅游业发展也应顺势而为。有别于已有的相关研究重点关注游客的行为分析,本文主要根据文本分析理论,对“泰迪杯”挑战赛官网、穷游网的网评文本数据先用正则表达式等方法进行数据清理,再用Jieba库分词,接着用TF-IDF算法提取关键词,根据K-means聚类得出聚类中心,结合KNN算法将其分类,用LDA模型进行主题分析,并将主题词映射为特征需求。实验结果表明,游客主要关注目的地的服务、位置、设施、性价比、卫生,并根据分析得到这五个方面的特征需求对旅游企业健康持续发展提出三条有益建议,有助于旅游企业将游客的旅游偏好与企业的未来规划结合起来,优化旅游资源配置,不断提高游客满意度,从而提升目的地美誉度,尽量满足游客多元化的旅游需求。
由于数据的安全性和保密性,获取数据难度较大,本文仅对“泰迪杯”挑战赛官网和穷游网的网评文本数据进行分析。下一步将通过多渠道方式获取形式多样的数据进行全面深入的研究,使研究成果更具有普适性。
