基于Word2vec和SVM的在线图书评论情感识别系统实现
2022-04-13柴源
柴源
(西安航空学院图书馆,陕西西安 710077)
文本情感识别是指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程[1]。近年来,在网上商城中,用户产生了大量对图书及其服务评论的主观性文本[2],挖掘这些文本信息,获取其中隐藏的有价值信息,能有效提高图书馆图书采选质量[3]。但是,这些文本隐含有较强的语义信息,在词向量的训练中,词袋模型无法表征词语之间的语义信息;其次,这些文本文档不能通过一个线性分类器(直线、平面)来实现分类;第三,人工监控分析不仅耗费大量人工成本,而且有很强的滞后性[4]。
Word2vec 模型通过词向量来表征语义信息,即在词向量的训练过程中引入了词的上下文。SVM 可以将低维空间映射到高维空间,解决线性不可分问题[5]。因此,文中构建了一种基于Word2vec和SVM的在线图书评论情感识别系统。
1 Word2vec与SVM的基本原理
1.1 Word2vec
Word2vec 是一种词嵌入(Word Embedding)方法,它根据语料中词汇共现信息,将词汇编码成一个向量,可以计算每个词语在给定语料库环境下的分布式词向量[6]。它包含两种训练模型,即跳字模型(Skipgram)和连续词袋模型(Continuous Bag of Words,CBOW),如图1 所示。
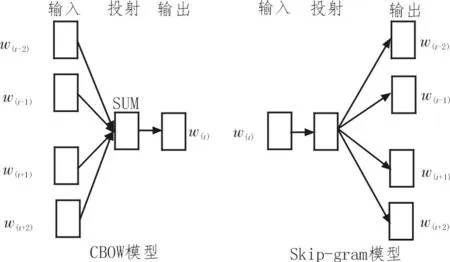
图1 Word2vec训练模型
CBOW 模型是一个三层神经网络,利用上下文或周围的词语来预测当前位置词语w(t)的概率,即P(w(t)|w(t-k),w(t-(k-1)),…,w(t-1),w(t+1),w(t+2),…,w(t+k))[7];Skip-gram模型的计算方法逆转了CBOW的因果关系,利用当前位置词语w(t)来预测上下文中词的概率,即P(w(i)|w(t)),其中,t-k≤i≤t+k且i≠k[8]。
Word2vec 通过训练词向量,可以定量地度量词与词之间的相似程度,挖掘词语之间的语义关系,适合做情感分类。
1.2 SVM
支持向量机(Support Vector Machine,SVM)是Vapnik 等人于1995 年提出的,它是通过某种事先选择的非线性映射,将输入向量映射到一个高维空间中,构造最优分类超平面,将不同类别的样本分开[9]。超平面是指比原特征空间少一个维度的子空间,在二维情况下是一条直线,在三维情况下是一个平面。研究表明,支持向量机在处理二分类任务时是非常成功的[10]。
在线图书评论情感识别只有正向和负向两种结果,本质上也是二分类问题。因此,可构造SVM 分类器,实现在线图书评论的情感识别。基本原理表述如下:

2 在线图书评论情感识别系统的设计
基于Word2vec和SVM的在线图书评论情感识别系统的设计主要包括数据预处理、Word2vec 词向量表示、构造SVM 分类器、文本分类结果等,如图2所示。
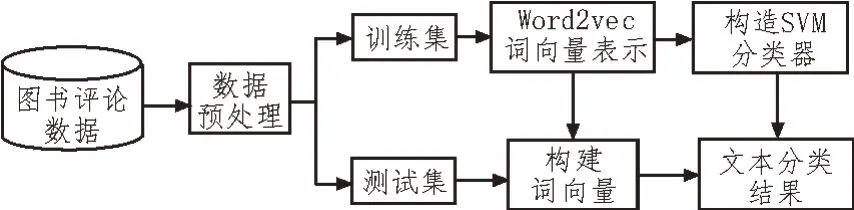
图2 系统设计
2.1 数据预处理
1)数据清洗。去除字母、数字、汉字以外的所有符号。
2)构建用户情感词典。采用jieba 技术进行预分词,提取程度副词和否定词,程度副词表示情感强弱,否定词会将句子情感转向相反的方向,而且通常是叠加的,并融合相关情感词典等构建用户情感词典。
3)形成研究数据集。在1)、2)的基础上过滤掉“的”、“了”等不影响情感表达的词语,进行二次分词,形成研究数据集,并将数据集按照0.25的比例划分为训练集和测试集,训练集用于模型的训练,测试集用于结果测试。
2.2 Word2vec词向量表示
1)模型设置与训练。Gensim 是一款开源的第三方Python 工具包,用于从原始的非结构化文本中,无监督地学习到文本隐层的主题向量表达,支持包括TF-IDF、LSA、LDA和Word2vec 在内的多种主题模型算法。文中采用Gensim 中的Word2vec 类对训练集数据进行向量化表示,生成训练词表。
2)构建建模矩阵。如图3 所示,将训练词表通过DataFrame 转化为词向量矩阵,由于在线图书评论文本长度各异,所以用各词向量直接平均(MEAN)的方式生成句向量,完成建模矩阵的构建,实现整个文本文档的分类处理。
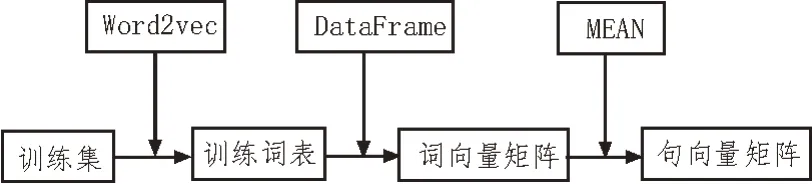
图3 构建建模矩阵
2.3 构造SVM分类器
SVM 分类器的构造主要包括训练SVM 分类器、验证分类器、评估分类器、优化分类器以及分类器测试运用等,如图4 所示。
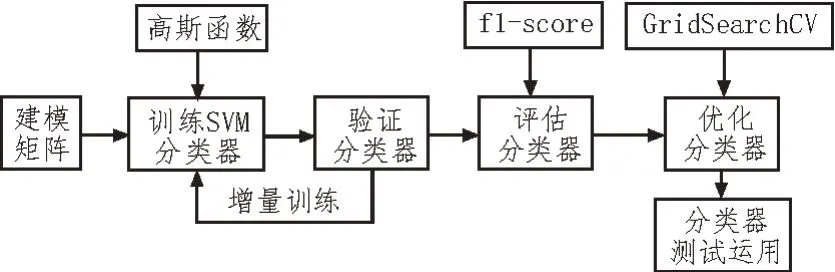
图4 构造SVM分类器
1)训练SVM分类器。在Python环境下,利用sklearn.svm中的SVC类,使用rbf核,设置参数gamma、degree,输入建模矩阵训练分类器。选取高斯核函数K(x,xi)=exp(-xi)2,x为训练集样本向量,xi为测试集样本向量,利用训练集对参数进行训练。
2)验证分类器。利用已构造的SVM 分类器,对训练集中的在线图书评论文本进行情感识别,将识别错误的文本返回训练集,进行增量训练。增量训练指机器学习不仅可以保留已经学习过的知识,也可以从新的样本中学习新的知识,这种学习是可以迭代的[13]。分类器在初次训练结束后,将训练数据的特征向量在训练好的分类器上进行预测,若预测结果与实际结果不一致,则将该条数据加入到新的训练集中,之后将所有训练集中预测失败的数据作为新的训练数据进行增量训练,增加难以预测的训练集样本的权重。
3)评估分类器。混淆矩阵和f1-score 是评估分类器性能的重要指标[14],混淆矩阵是一个误差矩阵,矩阵的每一行表示真实类中的实例,每一列表示预测类中的实例,如表1 所示。
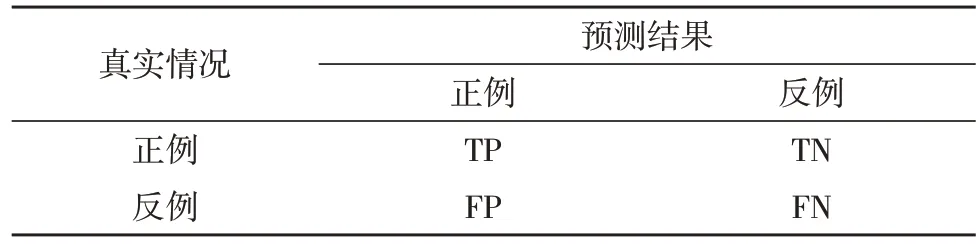
表1 分类结果混淆矩阵
表1 中,TP(True Positive)表示将正例预测为正例;FN(False Negative):将反例预测为反例;FP(False Positive)表示将反例预测为正例;TN(True Negative)表示将正例预测为反例。通过分类结果混淆矩阵,可以判断不同类型分类的正误数量。
f1-score 是精确率和召回率的调和平均数,最大为1,最小为0[14],计算流程如下:
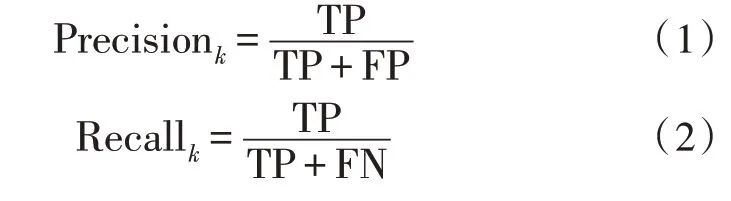
计算每个类别下的精确率(Precision)和召回率(Recall),精确率指被分类器判定正例中的正样本的比重,召回率指的是被预测为正例的占总的正例的比重。计算方式如下:
计算每个类下的f1-score,计算方式如下:
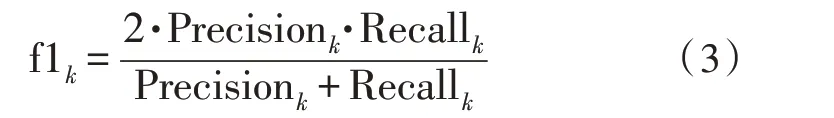
对各个类的f1-score 求均值,得到最后的评测结果,计算方式如下:
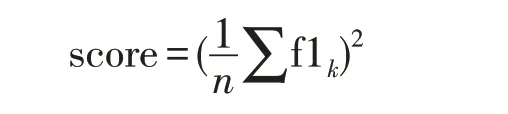
4)优化分类器。GridSearchCV 即网格搜索和交叉验证,输入参数列表,模型可计算出最优的结果和参数,是普遍使用的一种自动调参方式[15]。研究通过选择不同的degrees、gammas 参数构造列表,通过循环来寻找预测效果最优的模型。
5)分类器测试运用。Tkinter 模块是Python的标准Tk GUI 工具包的接口[16],利用Tkinter 构建在线图书评论情感识别系统应用界面,并在测试集上进行应用。
3 在线图书评论情感识别系统的实现
3.1 数据来源与预处理
实验语料为online_shopping_10_cats 数据集中的图书评论部分,共4 117 条,正向评论(用1 表示)2 100 条,负向评论(用-1 表示)2 017 条。
实验在数据清洗、提取程度副词和否定词的基础上,融合知网情感词典、BosonNLP 情感词典等,构建用户情感词典user_dict。基于此,进行二次分词,形成研究数据集,并利用sklearn 中的train_test_split将分词结果、情感分类按照test_size=0.25的比例划分为训练集x_train、y_train和测试集x_test、y_test。
3.2 Word2vec词向量表示
1)模型设置与训练。实验用Gensim训练Word2vec模型,调用gensim.models.word2vec()函数对训练集x_train 数据进行训练,并生成训练词表。参数设置如下:
①size=300,表示特征向量的维度,维度设置越大,需要的训练数据越多,训练出来的效果越好;
②window=5,表示窗口大小,即当前词与预测词在一个句子中的最大距离;
③min_count=5,表示最小词频。训练时,首先对预处理后的数据集进行词频统计,发现小于5的词语数量庞大且没有研究意义,所以实验将最小词频设置为5。
2)构建建模矩阵。首先构造整句所对应的所有词条的词向量矩阵,然后用各词向量直接平均的方式生成对应的句向量,完成建模矩阵train_vecs的构建。部分数据如图5 所示。
图5 train_vecs建模矩阵(部分)
3.3 构造SVM分类器
在生成train_vecs 建模矩阵后,利用sklearn 中的SVC 分类器建立支持向量机模型[17-18],设置kernel=“rbf”,即使用rbf 核,gamma=0.05,即rbf 核相对应的参数为0.05,degree=3 表示模型的幂次方等于3。得到模型后,使用转换后的矩阵train_vecs和训练集x_train 数据对模型进行训练。
分类器训练完成后,编写预测函数对训练集的数据进行验证,将验证结果与实际结果不一致的数据加入到新的训练集中,作为新的训练数据进行增量训练,重复多次。准确率在每轮增量训练时均在上升,但是在后面的迭代时会下降,如图6 所示。究其原因,在于数据特征向量维度较高,数据集中含有一些与分类关系不大的无关特征。

图6 精确率与迭代次数关系图
增量训练后,查看模型的混淆矩阵、f1-score,如表2 所示。
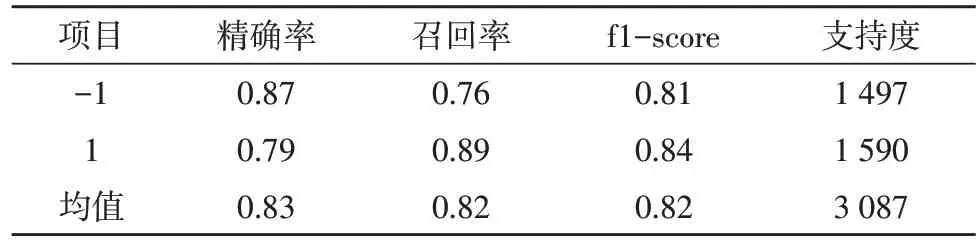
表2 模型的性能指标
支持度表示相应类中,有多少样例分类正确。由表2 可知,类别-1的精确率为0.87,类别1的精确率为0.79,精确率均值为0.83,召回率均值为0.82,f1-score 均值为0.82,表明模型具有一定的优化空间。
调用sklearn.model_selection 中的GridSearchCV进行模型优化,设置degrees=[2,3,4,5],gammas=[0.05,0.5,5],通 过{"gamma":gammas,"degree":degrees}寻 找预测效果最优的模型。实验结果显示,当degree=5,gamma=5 时,类别-1的精确率为0.96,类别1的精确率为0.91,精确率均值为0.94,召回率均值为0.94,f1-score 均值为0.93,模型的泛化能力得到了一定的提升,如表3 所示。
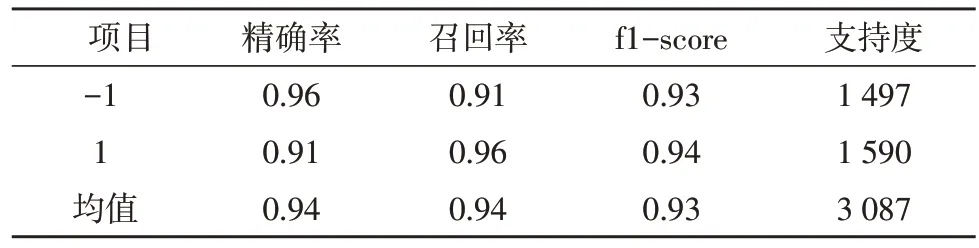
表3 优化后模型的性能指标
3.4 SVM分类器的测试应用
利用Tkinter 构建在线图书评论情感识别系统应用界面,如图7 所示,对测试集数据进行测试应用。图7 中,当输入在线图书评论内容后,点击“识别”,实现对文本内容的情感判断。例如,输入文本text=“《海底的秘密》是适合全体读者的,是无文字,无国界的,充满了爱,可以让人永葆青春的,要用心阅读的书。”时,识别结果为正向。
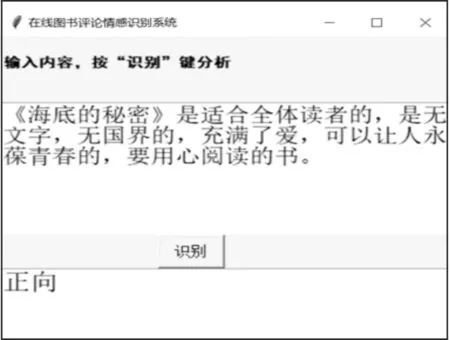
图7 在线图书评论情感识别系统应用界面
4 结束语
在线图书评论反映了消费者对图书的各种情感色彩和情感倾向,具有一定的研究价值和使用价值。研究以online_shopping_10_cats 数据集中的图书评论部分为实验数据,经过jieba 分词、用户情感词典整合等文本预处理,采用Word2vec 将词语转化为可计算、结构化的向量,得到语义化的特征矩阵;构造SVM 分类器模型,采用增量训练和GridSearchCV 优化分类器,并应用Tkinter 实现文本信息情感识别可视化。实验结果表明,该系统精确率为0.94,召回率为0.94,f1-score 为0.94,泛化能力较强。
