32 位RISC-V 处理器中乘法器的优化设计
2022-04-13唐俊龙汤孟媛吴圳羲卢英龙邹望辉
唐俊龙,汤孟媛,吴圳羲,卢英龙,邹望辉
(1.长沙理工大学物理与电子科学学院,湖南长沙 410114;2.柔性电子材料基因工程湖南省重点实验室,湖南 长沙 410114)
乘法器作为处理器的重要组成部分,一般由部分积产生、部分积压缩和最终结果相加3 部分组成,乘法器的性能制约着处理器算术运算的整体性能[1]。“蜂鸟E203”是国内研发团队开发的面向嵌入式或物联网领域的低功耗开源RISC-V 处理器,它的乘法器采用基4 Booth 编码产生部分积,每个周期使用迭代加法器的方法压缩部分积,经过多个周期的迭代得到最终的乘积。部分积压缩使用迭代加法器的方法消耗的硬件资源少,但完成一次乘法操作的迭代周期数多,使得乘法器运算速度慢,处理器无法满足在物联网应用领域中高速运算的需求[2]。因此,需要设计高速的乘法器来提高低功耗“蜂鸟E203”处理器的运算性能,而高速乘法器设计的关键是加快部分积压缩的速度,目前主要通过优化部分积压缩中4-2、5-2、6-3和7-3等压缩器或者设计合适的Wallace 树压缩结构达到提升乘法器运算速度的目的,而6-3 与7-3 等高阶压缩器消耗的硬件资源多、功耗高且面积大,在对硬件资源和功耗有要求的嵌入式或物联网领域中,Wallace 树压缩结构通常采用4-2和5-2 压缩器[3]-7]。为了提高“蜂鸟E203”处理器中乘法器的运算能力,该文提出一种新型的5-2 压缩器,根据基4 Booth 编码算法生成部分积的个数将4-2 压缩器与新型5-2 压缩器合理排列,组成新型的Wallace 树压缩结构代替原乘法器中的加法器。采用Synopsys的Design Compile 工具在SMIC180 nm 工艺下对改进的乘法器综合,结果表明,乘法器的运算能力得到了显著提升。
1 RISC-V处理器中乘法器的优化
该文主要针对RISC-V 处理器中乘法器部分积压缩延时高,执行整数乘法指令周期过长的问题,结合RISC-V 架构的整数乘法指令集的特点,对乘法器进行优化设计。
1.1 RISC-V架构的乘法指令分析
“蜂鸟E203”处理器支持RISC-V 架构的整数乘法指令,共有MUL、MULH、MULHU、MULHSU 4 条乘法指令[8-10],乘法指令分析如表1 所示,其中rd 表示目的寄存器,rs1和rs2 表示源寄存器。4 条乘法指令分别按符号扩展操作和结果高低位选取操作生成相应的控制信号,MULHU 指令乘法的两个操作数(被乘数和乘数)的符号扩展位都为0;MULHSU 指令被乘数的符号扩展位为被乘数的最高位,乘数的符号扩展位为0,MUL和MULH 指令的两个操作数的符号扩展位分别为被乘数和乘数的最高位。MUL 指令选取Wallace 树形结构压缩结果的低32 位,其余乘法指令选取Wallace 树形结构压缩结果的高32 位。控制信号控制部分积产生和部分积压缩对操作数和部分积的处理,从而完成乘法器的乘法运算。

表1 RISC-V乘法指令分析
1.2 改进型乘法器的结构设计
“蜂鸟E203”处理器中的乘法器如图1 所示。该文提出一种改进的乘法器结构如图2 所示,该乘法器支持32 位有/无符号数的乘法运算,主要包括部分积产生(基4 Booth 编码)、部分积压缩(Wallace 树形结构)和选择器MUX 3 个部分,部分积压缩采用新型的Wallace 树形结构代替图1 中加法器对部分积进行压缩,增加选择器并通过控制信号选取4 种乘法指令需要的Wallace 树形结构的压缩结果。图2 中,译码模块对乘法指令进行译码,基4 Booth 编码接收控制信号对被乘数和乘数进行符号扩展并产生18个规整的部分积,经Wallace 树形结构压缩,得到求和Sum与进位Carry两个部分积,选择器MUX 通过控制信号选取Carry和Sum两个部分积的高32 位或低32 位,传输到“蜂鸟E203”处理器中的ALU 运算模块进行运算,得到最终结果。
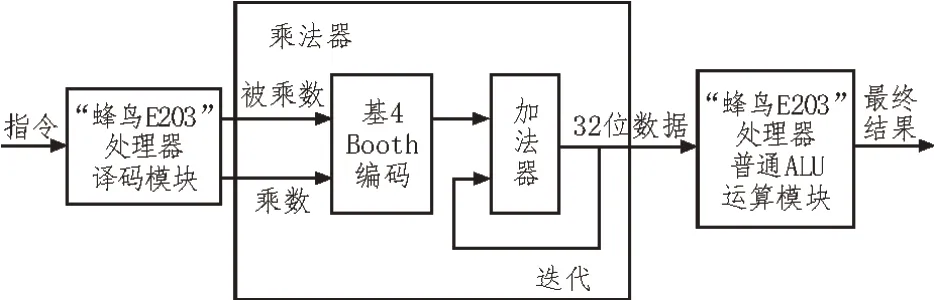
图1 “蜂鸟E203”处理器中的乘法器整体框图
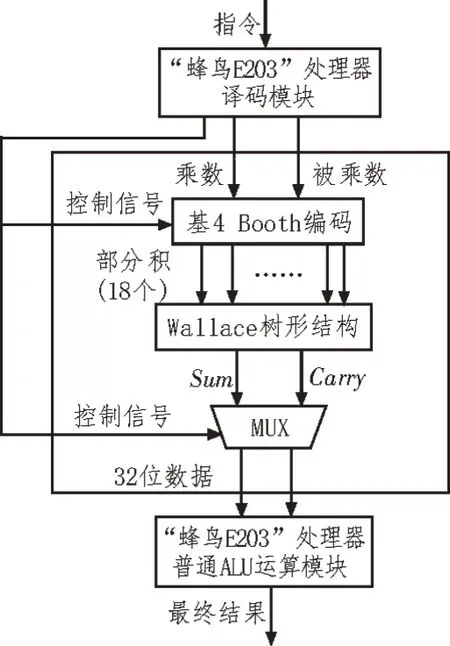
图2 改进型乘法器整体框图
2 新型的Wallace树形结构设计
图2 改进型乘法器结构中新型的Wallace 树形压缩结构的核心是压缩器,在乘法器运算中,压缩器对部分积快速压缩时产生大量延时,降低处理器的运算性能[11-12]。对压缩器的优化和对压缩器的合理排列能有效提高Wallace 树形压缩结构的压缩速度。
2.1 新型压缩器的设计
2.1.1 传统5-2压缩器
图3 与图4 分别是5-2 压缩器的示意图和传统5-2 压缩器的结构图[13],其中,X1~X5表示部分积输入,Cin1和Cin2表示上一级部分积压缩的进位输入(即低位的进位),Cout1和Cout2表示本级部分积压缩产生的横向进位输出,求和Sum与进位Carry表示部分积压缩的纵向输出,图3 中输入输出的关系式如式(1)所示[5],图4的逻辑表达式如式(2)~(5)所示。

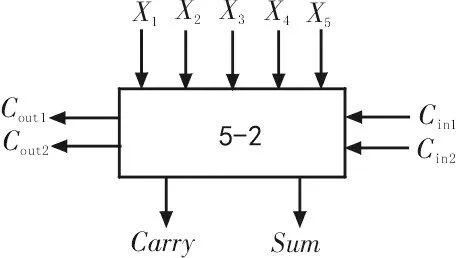
图3 5-2压缩器示意图
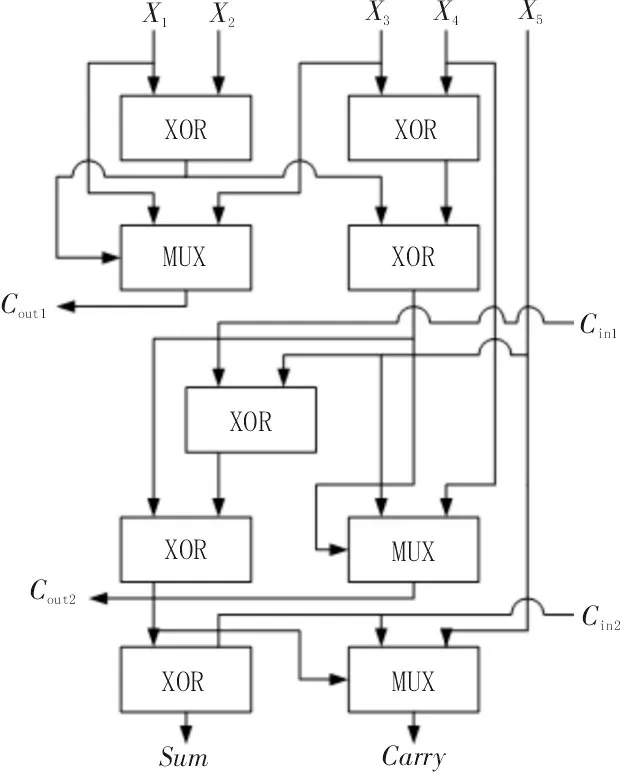
图4 传统5-2压缩器结构图
2.1.2 新型5-2压缩器
图4 传统5-2 压缩器结构中,横向输出Cout2在逻辑上与低位进位Cin1相关,Cout2需等待Cin1的输入,这种逻辑依附关系会产生额外的延时;纵向输出Carry由X1和X2异或门开始经过4 级XOR 与1 级MUX 运算产生结果,Sum由X1和X2异或门开始经过5 级异或门XOR 运算产生结果。Sum处于压缩器最长路径的末端,以一个XOR 延时为单位,传统5-2 压缩器的关键路径延时为5 个XOR 延时,延时较大影响乘法器的性能[13]。该文基于式(1),对式(2)~(5)进行优化,提出一种新型的5-2 压缩器,逻辑表达式为式(6)~(9),对应的结构如图5 所示,相比于图4 传统5-2 压缩器结构,横向输出Cout2与X1、X2、X4和X5信号有关,而与Cin1无关,没有额外延时;纵向输出Sum和Carry的产生路径上减少了1 级XOR,新型的5-2 压缩器关键路径延时减少到4 个XOR 延时,有效降低了纵向输出的延时。基于SIMC 180 nm的工艺库,通过H-spice 工具,该文对图5 新型5-2 压缩器进行电路仿真,温度为27 ℃,电源电压为1.8 V,X1~X5、Cin1和Cin2均为200 MHz的脉冲信号,关键路径延时和功耗仿真结果分别为0.12 ns和0.12 mW。
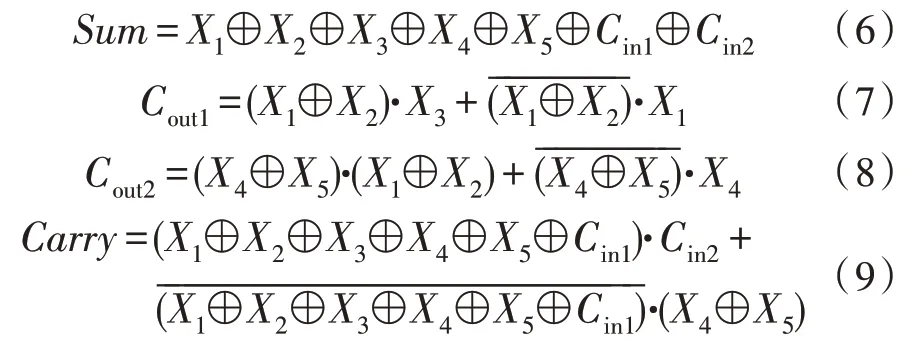
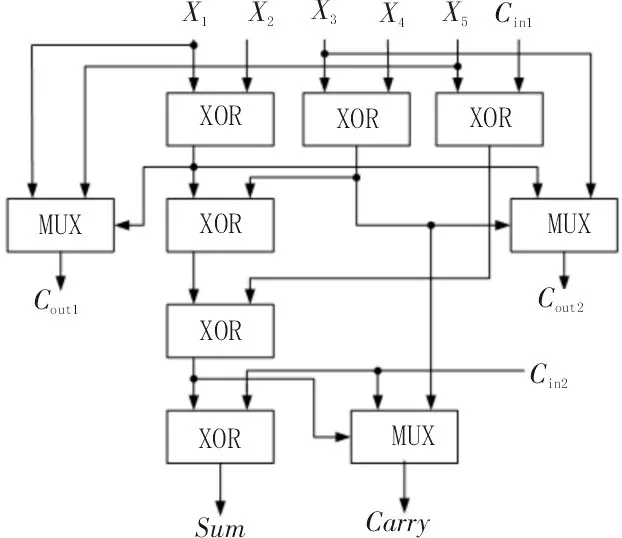
图5 新型的5-2压缩器结构
2.2 新型的树形压缩结构
图2 中,Wallace 树形结构主要功能是压缩部分积,由基4 Booth 编码产生的18 个部分积仅用新型5-2 压缩器不能将其完全压缩,而仅用4-2 压缩器能够完全压缩[14-15],但需要4 级4-2 压缩器,增加了关键路径的延时,且组成的Wallace 树形结构不对称,不利于后端版图的设计。该文对改进型5-2 压缩器与4-2 压缩器进行合理排列,提出了一种改进的Wallace 树形压缩结构,如图6 所示,通过1 级5-2 压缩器和2 级4-2 压缩器将18 个部分积完全压缩,该压缩结构对称,关键路径延时少。
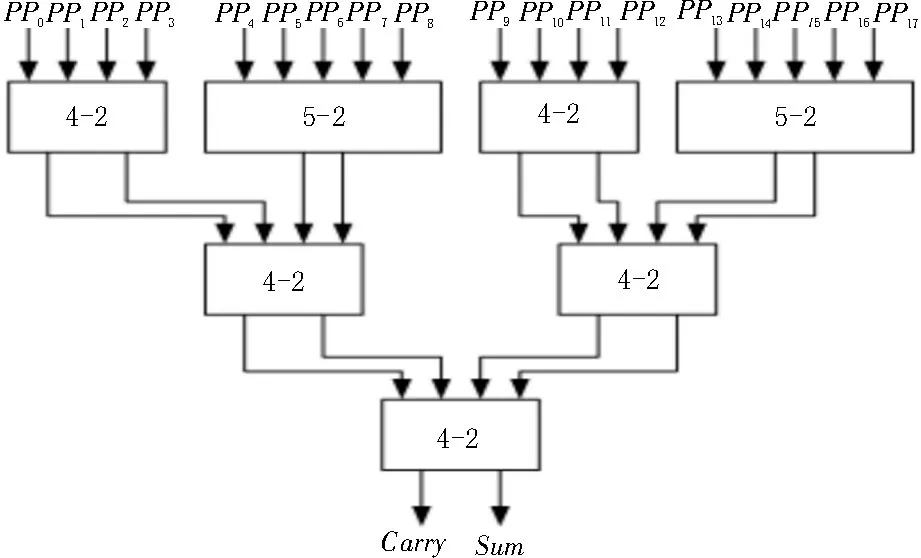
图6 新型的Wallace树形压缩结构
3 仿真结果
3.1 乘法器功能验证与分析
该文采用Verilog HDL 语言对优化设计的乘法器进行描述,并嵌入到“蜂鸟E203”处理器中,使用Modelsim 工具对MUL、MULH、MULHU和MULHSU[16]4 种乘法指令进行功能仿真,通过与Modelsim 工具自带乘法符号的运算结果的对比验证乘法器功能的正确性。图7 是执行4 种乘法指令的仿真结果和自带乘法符号运算结果的对比图,信号result_op1与result_op2 分别为乘法指令执行结果的低32 位和高32 位,信号final_result 是乘法指令的完整运算结果,信号result 是Modelsim 自带乘法符号的运算结果,将信号final_result和result的数据对比,两个结果完全一致。因数据量较多,图7 截选了仿真结果的一部分。
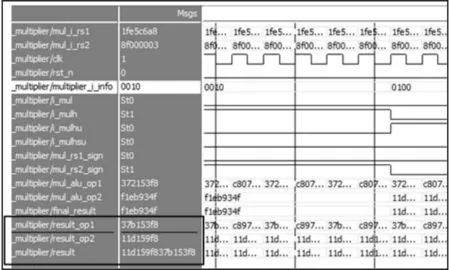
图7 乘法运算结果对比图
3.2 乘法器性能仿真与分析
该设计基于SIMC 180 nm的工艺库,使用Synopsys公司的Design Compile 工具对改进型乘法器进行综合,电路面积为0.012 mm2,总单元数目为6 844,延时和周期数与“蜂鸟E203”处理器的原乘法器[17-18]对比如表2。该文设计的乘法器速度性能提升了88.2%,电路最大延时降低了39%。

表2 乘法器性能对比
4 结束语
该文根据RISC-V 指令集中整数乘法指令的特点,优化“蜂鸟E203”处理器中的乘法器,提出了一种新型的5-2 压缩器,并应用新型的5-2 压缩器构建了Wallace 树形结构,设计了改进型乘法器。利用Modelsim 工具验证了乘法器功能仿真的正确性,并采用SIMC 180 nm 工艺,使用Synopsys 公司的Design Compile 工具对乘法器进行综合,结果表明,该文设计的乘法器单次乘法指令执行周期数为2,关键路径延时为2.43 ns,相比于“蜂鸟E203”处理器原乘法器在速度上提升了88.2%,电路最大延时降低了39%,大大提高了乘法器的运算速度,适用于嵌入式或物联网领域中对高速运算有需求的应用。
