自适应业务场景的数据库冷热数据识别算法
2022-04-13陈又咏
梁 懿,陈又咏,李 森,王 明
(1.福建亿榕信息技术有限公司,福建 福州 350003;2.西安交通大学 电子与信息学部,陕西 西安 710049;3.国网信息通信产业集团有限公司,北京 102211)
0 引 言
随着互联网规模不断扩张,数据量不断增大,各类系统都需要消耗大量的资源用于数据存储和数据访问查询。数据的访问模式大多具有一定的“局部性”,即有些数据被频繁访问,称为热数据,有些数据很少或几乎不被访问,称为冷数据。而数据库系统性能由访问数据速度快慢、数据存储成本大小决定。在现代存储系统设计中,通过考虑数据的冷热程度,将冷热数据识别并分开存储,热数据驻留在内存,冷数据迁移到价格便宜的外部存储中,对整体系统性能影响很小,提升了数据库系统存储性能和数据访问效率。因此如何高效地识别冷热数据是数据库数据存储和访问查询研究的热点方向。
近年来,我国一直重视开发具有自主版权的国产数据库产品,现在国产自主可控的数据库处于一个快速发展的阶段。同时在冷热数据方面也在进行不断探索,华为基于PosgreSQL开发的GaussDB数据库、中兴基于MySQL的GoldenDB数据库都在存储优化中考虑冷热数据的情况,达梦数据库在物理备份中引入了冷备份和热备份。可见识别冷热数据的查询优化也是数据库优势性技术之一,国产数据库经过长期发展也积累了很多查询、存储优化机制,有效提升了整体性能。
数据库系统中常用以下两种方法识别冷热数据。
1)时间识别方法,即:越早入库的数据越“冷”,越晚入库的数据越“热”,在时间识别方法中,通常使用FIFO算法维护数据的插入顺序,利用LRU算法局部性量化数据的冷热程度。但时间识别方法存在一定局限性,其忽略了数据访问频率对数据冷热程度的影响。如果最早入库的数据在入库后的某段时间内被频繁地访问,则该数据通常会被认为是热数据,而不单单按照数据入库时间认为其是队列中的冷数据。在很多的热门信息业务场景中,无法真实反映数据的冷热情况,因此通常不可取。
2)频率识别方法,即:在过去一段时间内,访问频率越高的数据越“热”,访问频率越低的数据越“冷”,通常使用LFU算法按历史数据访问频繁程度维护数据的顺序,从而量化数据的冷热程度。但频率识别方法也存在一定局限性,只考虑数据的访问频率对数据冷热程度的影响,忽略了数据建立时间对冷热数据的影响。如果数据在很早一段时间内访问频繁,之后不再被访问,则该数据不能再被称为热数据,因此这种方案也片面估计了数据冷热情况。
由此可见,基于LRU类型算法着重分析访问数据入库时间的局部性特征,仅关注于最近访问的数据。
LRU算法存在如下缺点:无法区分线性访问模式下的热数据;不能区分具有不同访问概率的数据。基于LFU类型算法着重分析数据的访问频率特征,仅注重于数据的访问频繁程度,优先将总体访问频率最少的数据替换出缓存。
LFU算法存在如下缺点:无法确定过早的高频数据是否仍高频;对于线性访问模式中数据访问频率一样的场景,无法有效区分冷热数据。
为了克服冷热数据识别的局限性,提高数据库系统性能,本文提出一种有效的冷热数据识别算法HF-ARC(Hot First-Adaptive Replacement Cache)。该算法基于传统缓存替换算法的ARC(Adaptive Replacement Cache)算法,结合LRU算法的局部特性和LFU算法,着重分析数据访问频率的特性,兼顾数据时效性和频率性,并在结构设计上优化,使得其节约内存空间。针对不同系统的业务情景工作负载,预测未来一段时间内的冷热数据趋势,自定义数据时效性和数据访问频率的标准,自适应调整系统所采用的冷热数据识别策略。
1 相关工作
在计算机系统中,存在着各种各样的存储器结构,而不同存储器的访问速度存在着数据级上的巨大差异。大多对冷热数据识别的研究是基于缓存区替换策略开展,引入缓存替换,更好的利用内存,仅将经常访问的数据放入内存汇总,达到节约成本的效果。
缓存替换策略主要针对磁盘I/O对称性设计。许多存储系统使用LRU算法作为缓存替换策略,依据缓存局部性原理,LRU算法最长访问间隔是缓存总容量,此时具有较好的收敛速度。近年来出现大量基于LRU原理提出的算法,如添加冷标志位的LRU-WSR算法、用于闪存系统的CF-LRU算法、通过权值兼顾访问时间和频率的LRFU算法。
冷热数据识别是对过去数据访问模式和未来访问模式行为特点的分析及预测,通过识别冷热数据并将其分开存储,降低数据的存储开销。在冷热数据识别方面,国内外进行了大量的研究。文献[11]提出索引热点数据缓存技术和热度累积缓存替换策略,兼顾数据时间局部性和访问热度累积,有效判断数据访问特性。LRU-算法维护两个队列,历史队列保存每次访问的数据页面,缓存队列保存访问次的页面,缓存队列中的数据即为热数据,但维护多个队列成本较大。文献[13]提出通过日志访问记录区分冷热数据,他们基于平滑指数和实验正确评价给出四种估计算法评估记录访问频率,从而区分冷热数据。
现有识别算法大多是针对特定业务场景设计的,当业务场景改变时则需要改变识别策略,无法做到自适应业务场景调优。
2 HF-ARC冷热数据识别算法
本文提出了HF-ARC算法,基于ARC缓存替换算法原理,并在ARC算法结构设计上优化,更加准确地判断业务场景类型,通过设置访问位的方式减少链表使用,节省内存空间。在不确定冷热数据规律的前提下,克服现有冷热数据识别算法单一化不足,综合考虑冷热数据情况,根据业务场景需要,自适应调整冷热数据识别策略。
ARC算法将缓存区分成两部分,使用LRU链表和LFU链表管理。其中LRU链表用于存储最近只被访问一次的数据页,ARC算法认为在短时间内被访问两次及以上的数据是“高频”热数据,因此LFU链表用于存储最近被访问两次及以上的数据页。另外设置两个辅助链表分别存储从缓存区链表LRU或LFU淘汰数据的页号信息,根据数据页号信息,动态调整LRU和LFU链表长度。但存在一定问题,算法需要两个辅助链表,在时间和空间上存在资源消耗,而命中两次的数据页将进入LFU链表,在一些业务场景中,导致系统片面认为该页为频繁访问的数据,使得识别策略偏向于数据访问频繁类型。
2.1 HF-ARC算法设计
本算法使用LRU和LFU两个链表作为缓存区,LRU链表存储最近访问一次的数据页,LFU链表存储访问次及以上的数据页,访问次及以上的数据页为访问频繁的数据页。两个链表长度动态可变,根据调整LRU链表和LFU链表长度以适应实际中不同的业务场景。HF-ARC算法用一个辅助链表取代ARC算法中两个ghost链表,记录从LFU和LRU链表中淘汰数据页的页面信息,在这些页面信息中增设标志访问位,置0或置1,用于区分该页面信息来自LRU链表或LFU链表淘汰的数据页,辅助链表仅存放页面信息,不存储具体的数据页,由辅助链表命中情况,判断业务场景的访问数据特征倾向于时效性或频率性,从而动态自适应调整LRU链表和LFU链表长度。算法整体结构如图1所示。

图1 HF-ARC冷热数据识别算法整体结构
2.2 HF-ARC算法实现
HF-ARC算法将缓存划分为LRU链表部分(T1)和LFU链表部分(T2),两部分遵从各自的缓存淘汰规则,即LRU偏向最近访问的数据,反映业务场景中数据的时效性,LFU偏向访问频繁数据,反映业务场景中数据的频率性。首次进入缓存的数据页默认先进入T1链表,同时访问位OF设为-1,并为每个数据页定义一个参数ref,表示缓存区命中次数,ref初始为0,当缓存区的热数据页命中,则该页的ref加1,以记录在T1链表的命中次数,根据不同业务场景,设置阈值,当ref等于时,则认为该数据页的数据是访问频繁的热数据。同时用一个链表(H)存储从T1、T2链表淘汰的数据页的页号信息和访问位,H中的数据不存入到缓存区中。
1)将缓存区分为LRU(T1)链表和LFU(T2)链表两部分,T1保存最近仅访问一次的数据页,T2保存访问次及次以上的数据页,阈值的大小根据不同业务场景自定义设置,如图2所示。

图2 首次访问的数据
2)首次进入缓存区的数据页将加入T1链表的头部,随着T1链表中数据页加入,不断地向尾部移动,当再次命中时ref加1,当ref等于时,将该命中的数据页移至T2链表的头部,如图3所示。
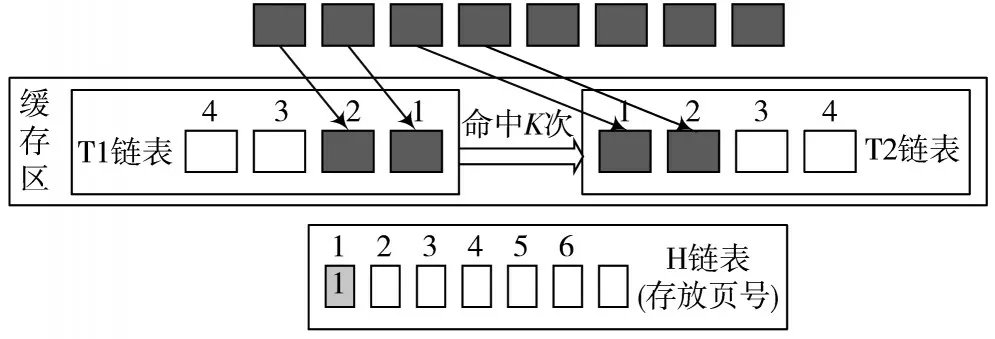
图3 访问频繁的数据
3)当缓存区已满,数据页在T1链表命中且ref等于,将T2链表尾部数据页淘汰,并淘汰数据页的页号放入H链表首部,访问位设为1,最后将T1链表命中的数据页插入至T2链表首部,如图4所示。

图4 T2链表中淘汰的数据
4)当缓存区已满,数据页在T1链表中命中,但ref不等于时,则将该数据页移至链表头部,并将ref加1。当缓存区已满,数据页不在缓存区命中且页号也未在H链表命中时,则将T1链表尾部的数据页淘汰出去,并将记录的淘汰数据页的页号放入H链表,同时访问位设为0,如图5所示。

图5 T1链表中淘汰的数据
5)当缓存区已满且数据页不在缓存区命中时,LRU链表淘汰的数据页(该数据页的页号能在H链表命中,且访问位OF为0),则从存储介质中将该访问位对应的数据页找出,再次加入到缓存区的T1链表,同时删除H链表中的数据记录,并将T1链表长度加1,T2链表长度减1。LFU链表淘汰的数据页(该数据页的页号能在H链表命中,且访问位OF为1),从存储介质中将该访问位对应的数据页找出,再次加到缓存区T2链表,同时删除H链表中的记录,并将T2链表长度加1,T1链表长度减1,如图6所示。

图6 动态调整缓存链表
HF-ARC算法在ARC算法基础上优化,减少辅助链表的使用,使用访问位达到相同效果,并重新定义数据访问频繁的阈值,更加准确地识别业务场景属于哪种类型。HF-ARC算法通过对缓存区中LRU链表和LFU链表长度的动态调整,如果业务场景访问偏向于时效性数据,LRU链表长度将变的很长;如果偏向于访问频率性数据,则LFU链表长度将变的很长。随着业务场景的变化,动态调整冷热数据识别机制,可有效克服现有识别冷热数据的不足,自适应调整冷热识别策略,能更优地识别冷热数据。
3 实验与分析
3.1 实验方案设计
本文采用Flash-DBSim平台模拟冷热数据识别实验环境。Flash-DBSim是一个可配置、高效的闪存系统仿真软件,它能模拟出不同特性的固态硬盘,方便提供各种关于算法的性能测试环境,所以本文通过此平台进行闪存系统缓冲区淘汰算法仿真,对冷热数据识别算法进行模拟,分析算法性能。
本文构建代表三种数据访问分布规律的数据集,用于模拟局部访问模式、概率访问模式和线性访问模式的仿真实验。分别模拟最近数据访问方式、对数据的访问符合zipf分布方式、顺序访问方式,利用这些模式模拟不同业务场景,用于对各种识别算法测试和验证。缓存命中率是缓存中最重要的性能评判标准之一,本文通过闪存仿真实验对缓冲区命中率进行比较,以此对比不同业务场景的冷热数据识别算法的效果和不同算法的差异。
3.2 实验结果与分析
3.2.1 仿真测试结果及分析
图7~图9分别表示在局部、概率和线性三种模式下,LRU、LFU类型算法和自适应类型算法的缓存命中率情况。本算法中值原是根据不同业务场景的工作负载情况定义的频繁数据的参数,由于在仿真环境中不好体现效果,实验中默认参数为2,表示访问2次以上的数据为访问频繁的数据。

图7 局部模式下缓存命中率比较

图9 线性模式下缓存命中率比较
图7在局部模式下,访问数据类型为时效性数据,最近访问的数据为热数据,HF-ARC算法动态调整偏向于时效性数据访问,命中率情况趋近于LRU类型算法,并比LRFU算法命中率高。图8为在概率模式下,访问数据类型为概率性数据,访问频率高的数据为热数据,HF-ARC动态调整识别策略偏向于概率性数据访问,命中率趋近于LFU类型算法,随着缓存区增大,命中率稍高于LRU类型算法。图9为在线性模式下,数据按顺序访问,LFU类型和LRU类型算法命中率较低,随着缓冲区内存增大,LRFU命中率比原始LRU、LFU算法明显增高,由于参数不同,命中率会相应改变,而HF-ARC算法命中率根据数据类型动态调整,自适应调整识别策略,效果表现良好,命中率相比LRU和LFU类型算法较高。

图8 概率模式下缓存命中率比较
实验得出,随着缓存区增大,HF-ARC算法相比非自适应识别算法命中率提高5%~15%,相比其他适应性算法提高1.3%~2.5%,提高了系统性能。
3.2.2 HF-ARC算法性能分析
HF-ARC算法对ARC算法优化,并应用于冷热数据识别方面。在ARC算法中有两个辅助链表存储从LRU链表和LFU链表淘汰的数据信息,这不仅消耗了两个链表的空间,且在数据信息遍历时要遍历两个链表。本文算法将两个辅助链表合并为一个辅助链表。新合并的辅助链表以设置访问位为0或1的方式,分别标记淘汰数据页信息来自LRU链表或LFU链表。通过这种方式,在时间消耗方面减少一次辅助链表遍历,只需一次遍历即能判断淘汰数据来源,因此HF-ARC算法比ARC算法减少了遍历时间。在空间消耗方面,虽然新合并的辅助链表新增访问位,但只占用一个二进制位,对链表内存空间影响可以忽略;由于总体上减少了一个辅助链表的使用,因此HF-ARC减少了内存空间的使用。
4 结 语
本文针对数据库系统冷热数据识别策略的片面性问题,提出了基于ARC算法优化的自适应冷热数据识别的HF-ARC算法。充分考虑访问数据时效性和频繁程度识别冷热数据,并分别通过采用局部、概率、线性三种访问模式模拟数据时效性、频率性、综合性业务场景,仿真模拟冷热数据识别过程。实验结果表明,采用本文算法在冷热数据识别性能方面优于LRU、LFU算法及LRFU自适应算法,能够动态调整冷热识别策略,因此提高了系统性能。
