基于图数据库的空间频繁并置模式挖掘
2022-04-13胡自松王丽珍VanhaTran周丽华
胡自松,王丽珍,Vanha Tran,周丽华
云南大学 信息学院,昆明650504
当前人们正处在一个大数据时代,随着科学技术的不断进步以及各种电子设备的研发,人们所面对的数据呈现爆炸式的增长趋势。这些数据不仅包括类别标签信息,还包括空间地理位置信息。例如,移动设备、带导航的车辆等所产生的数据;在流行病学中,记录病人(比如新冠肺炎感染者)的信息不仅包括症状、发病时间、就诊时间、个人基本信息,还包括家庭住址和工作地点等地理位置信息。
空间频繁并置模式(spatial prevalent co-location pattern,SPCP)表示空间特征的子集,其实例在空间邻域中可以被频繁地观察到。空间频繁并置模式挖掘的目标是发现在邻近区域经常一起被观察到的所有特征子集。图1 为一个空间实例分布示例,其中的每个实例(数据点)通过用它的特征和实例编号表示,例如.1。这些实例可以代表某种类型(特征)的对象在空间中具体的出现,比如犯罪事件、酒吧、商店/餐馆、植物/动物物种或者兴趣点等。度量两个实例间的邻近关系,可以根据不同的应用需求选择不同的度量方式,如欧氏距离和曼哈顿距离等。满足邻近关系的两个实例在图示中用一条实线连接。在图1 中,一个空间并置模式{,,}的模式实例是{.2,.1,.2}和{.4,.2,.1}(在空间邻近关系下形成团关系的实例子集称为模式实例)。一个空间频繁并置模式的频繁度可以使用参与度(participation index)或分数评分(fraction-score)方法来度量。如果一个空间特征集的频繁度不小于用户给定的一个最小频繁度阈值,则这个空间特征集被称为频繁并置模式。例如,特征集{,}的频繁度为0.66,{,}的频繁度为0.33,当给定的频繁度阈值为0.6 时,{,}为一个频繁并置模式。

图1 一个空间实例分布示例Fig.1 Example of spatial instances distribution
频繁并置模式挖掘具有许多的应用领域,包括基于位置的服务、城市规划、地理信息系统、公共安全管理、环境科学等。例如,从犯罪数据集中发现的频繁并置模式可以更好地给公共安全管理者提供安保预防措施;从植物分布数据集中发现的频繁并置模式有助于植物地理学和植物生物学研究;在自然灾害预防中,频繁并置模式可以给应急指挥部门对自然突发灾害提前做出预警,这样就能将可能造成的损失降到最低。
图数据库是当前比较流行的一种非关系型数据库,能方便地以图形的形式表示数据和知识,提供了管理高度连接的数据和复杂的数据库查询以及原生图形存储和处理的能力。NoSQL 图引擎中的属性图是带标签的有向图,它由通过关系连接的结点和以键值对形式的一个或一组属性组成。图数据库系统已经在社交网络、知识图谱、推荐系统和欺诈检测等领域得到应用。在空间并置模式挖掘中,模式的发现依赖于空间实例(数据)之间的邻近关系,利用关系型数据库不能很好地存储实例间的邻近关系,而利用图数据库可以将空间实例和它们之间的邻近关系存储为原生的图数据,基于图的特点能高效地对结点和边(邻近关系)访问并且可以使用图结构的自然伸展特性设计邻居结点遍历算法(图的遍历算法)来收集模式表实例。图数据库查找数据不受数据量大小的影响,因为邻近查询是对有限的局部数据搜索,不会对整个图数据库进行搜索。于是可以用图数据库来物化空间实例间的邻近关系,将频繁并置模式挖掘问题转化为邻近关系图(neighborhood graph)数据库上的团(clique)的查找问题,即利用图数据库技术有效地挖掘空间频繁并置模式。
现有的频繁并置模式挖掘算法,如基于Aprior-Like 框架提出的算法、基于分布式框架提出的算法等都具有较好的执行表现,但仍存在局限。其一,面向海量空间数据集时,单机操作会出现内存溢出、执行效率不可接受等问题;其二,重启系统后,需要从计算空间邻近关系开始重新执行挖掘算法。因为基于内存挖掘的算法是将空间邻近关系存储在内存中(如存储为树型结构),当数据量较大需要内外存交换时,如果设计的数据结构不支持内外存交换将出现内存溢出问题,当设计的数据结构支持内外存交换,则会出现运行效率极低,无法满足应用需求的问题。直接将经典的挖掘算法移植到图数据库上不能发挥图数据库的优势导致效率不高。此外,对于上述相关工作所采用的方法需要先收集模式的所有表实例,但计算一个特征的参与实例数是统计模式特征不重叠的实例个数,保存表实例的方法重复存储实例带来了很大的空间开销。例如,模式{,}涉及实例.2 的模式实例为{.1,.2}和{.2,.2},实例.2 被重复存储了两次,但是在计算特征的实例参与率时,.2 的参与贡献实际上为1。为此,提出了基于图数据库的一种实例参与验证的方法来挖掘空间频繁并置模式。
主要贡献总结如下:
(1)将空间频繁并置模式挖掘问题转化为基于图数据库的子图(团)查找问题。传统的并置模式挖掘方法通常是将物化的空间邻近关系存储到内存中,然后进行挖掘。本文彻底改变传统的挖掘方法,提出基于图数据库有效挖掘频繁并置模式的新方法。
(2)传统的方法每次启动程序都需要重新计算实例的邻近关系,提出的方法在第一次启动程序时将邻近关系图存储在图数据库中,同时一些中间计算结果也存储在图数据库中。因此,冷启动后的执行效率得到大大提升。
(3)利用图数据库的优势,提出一种基本的子图(团)查找算法CliqueSearch 和一种基于参与实例验证的方法InstanceVerification 统计模式的参与实例。其中,为了减小搜索空间提高挖掘效率,设计了候选模式的粗过滤方法和表实例的细过滤方法以及实例的过滤与验证方法。挖掘算法本质上是迭代的过程,即由上一阶频繁模式生成下一阶的候选模式,并且生成的所有候选模式都遵循先验原理。
(4)为了方便比较,将挖掘频繁并置模式的经典算法Join-based 算法、Join-less 算法和最新提出的Fraction-Score 算法移植到了图数据库上,分别记为GDBJoinBased、GDBJoinLess和GDBFracScore。
(5)在真实数据集和模拟数据集上进行了广泛的实验评估,结果证明了提出的挖掘算法的正确性和有效性。
1 相关工作
Koperski和Han讨论了基于空间邻近关系的空间关联规则挖掘问题。这项工作挖掘与特定参考特征(例如癌症的发病率)相关联的空间特征子集。首先根据参考的实例计算出事务,然后使用先验算法求关联规则。Shekhar 和Huang提出了空间并置模式挖掘问题,并设计了Join-based 算法挖掘空间频繁并置模式。为了解决Join-based 连接操作开销大的问题,Yoo 等人提出了Partial-join 算法和Join-less算法。Partial-join 算法通过团划分模型物化空间邻近关系,基于团邻近直接得到表实例,并扫描数据集获得被团切断的频繁并置模式实例。该方法适合处理大部分空间邻近关系都在团分区内,而很少的空间邻近关系在团分区之间的数据集。Join-less 方法将空间邻近关系物化为星型邻居列表,然后表实例的生成使用实例查找的方式来代替连接操作。Wang等人提出了星型邻居存储结构CPI-tree,基于CPItree 所有表实例能够快速生成,但是随着输入的数据量变大,存储和递归搜索CPI-tree将是挑战性任务。
文献[1,14-16]采用基于MapReduce 的方法挖掘频繁并置模式,这些方法通过Hadoop 或者Spark 来搭建分布式并行计算平台,能高效地处理大数据,但是这些算法需要多个主机结点来向上扩展,带来的经济成本十分昂贵,并且它们的Reducer 结点存在着聚集同一频繁并置模式所有实例的瓶颈,时间和空间开销较大。Sainju 等人提出了一种基于网格的GPU 频繁并置模式挖掘算法,该算法当每个实例的邻居数在非常小的常数范围内或者当实例密集且分布不均匀时有较好性能,但是实例分布较为均匀时性能提升较小,且利用网格划分实例割断了一些重要的模式。
另外还有一些工作,Yoo 等人提出了极大频繁并置模式、闭频繁并置模式挖掘算法。Bao 等人提出了基于团的方法挖掘频繁并置模式,该方法不用查找模式的表实例,尤其在密集数据集上有更好的性能表现。Xiao 等人提出了一种基于密度的方法,该方法定义了密度比来描述邻近关系,并使用聚类技术来寻找频繁并置模式。Yao 等人提出了一种混合密度加权距离阈值的频繁并置模式挖掘算法,该算法考虑了密度加权和距离衰减效应,但是没有考虑实例的空间方位和网络效应的影响并且确定修正系数需要花费更多的计算时间。Chan 等人提出了一种新的支持度量方法度量并置模式的频繁性,称为Fraction-Score,它考虑了所有可能的行实例,同时避免了实例的重复计数的问题,但计算得到的候选模式支持度较小,当频繁度阈值设置不合理时,发现的模式数量少,容易丢失重要信息。文献[24-26]提出了挖掘局部或区域空间频繁并置模式,这些模式的实例通常位于整个空间的子区域中,这些方法考虑了并置模式的局部频繁性。文献[27]探索了负并置模式的向上包含性质,提出了极小负并置模式新概念。文献[28]利用统计学的方法估计表征区域密度的距离截断参数,省去了用户预先设定距离阈值的过程,有效提高了并置模式挖掘在未知区域上执行的自适应性。Liu 等人提出一种基于自然邻域的空间并置模式挖掘方法,该方法能在空间要素分布不均匀的场景中有效地发现并置模式。文献[30]提出主导特征并置模式的概念,揭示了空间特征间的主导关系,通过这种主导关系能挖掘更有价值的并置模式。
与上述空间频繁并置模式挖掘的研究相比,本文将输入的空间数据一次性物化为邻近关系图(neighborhood graph)存储在图数据库中,改变了传统将邻近关系存储在内存中的方法,设计了简洁而高效的基于图数据库的子图查找算法来挖掘频繁并置模式,并设计了有效的剪枝过滤方法。此外,传统的基于物化邻近关系查找表实例的方法(如Join-less算法),都可以通过本文构造邻近关系图的方法进行有效的移植。
2 基本概念及问题定义
2.1 空间频繁并置模式
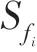
(空间并置模式)空间并置模式是一组空间特征的集合={,,…,f}∈,2 ≤≤。空间并置模式中特征的个数称为并置模式的阶,记为()=||。例如,({,,})=|{,,}|=3。
(空间并置模式实例)给定不同空间特征的实例集合={,,…,o}∈和空间并置模式。如果同时满足以下条件:包含了中所有实例的特征,中任意两个实例满足邻近关系,则称为的一个实例。空间并置模式实例也称为团(Clique)实例或行实例。所有的行实例的集合称为的表实例,记作_()。的表实例中,特征f∈对应不重叠的实例集合称为的参与实例,记作_()。
如图1 所示,={,,} 是一个并置模式,={.1,.1,.2}为的一个行实例,的表实例_()={{.2,.1,.2},{.4,.1,.1}}。_()={{.2,.4},{.1},{.1,.2}}。
(频繁并置模式)为了衡量并置模式的频繁性(有趣程度),在频繁并置模式挖掘中经常使用的度量方式是参与度(participation index,),然而的取值取决于参与率(participation ratio,)。

给定最小频繁性阈值_,如果()不小于_,即()≥_,则称为频繁并置模式。

(空间并置模式的反单调性)参与率和参与度随着并置模式阶的增大而单调递减。
参与率和参与度的反单调性证明可以参看文献[5]。
(空间并置模式实例的反单调性)并置模式的行实例数随着模式阶的增大而单调递减。
假设是空间并置模式的行实例,即满足邻近关系形成团,对于的任意子集′∈也满足邻近关系形成团,即的子集一定是子集对应的并置模式的行实例,反之不成立。因此并置模式的表实例条数随着模式的阶增大而单调递减。
2.2 问题定义
给定:
(1)空间特征集合={,,…,f}。

(3)空间邻近关系和频繁性阈值_。
约束:基于距离度量的邻近关系,具有对称性质。
挖掘结果:找到满足频繁性阈值的所有空间频繁并置模式。
目标:减少邻近关系的重复计算和对内存的大量占用,利用较少的时间正确并且完整地找到所有频繁并置模式。
3 相关算法
本章给出了基于图数据库的频繁并置模式挖掘框架及相关算法,包括邻近关系图的构造算法和两种频繁并置模式挖掘算法CliqueSearch和InstanceValidation。
3.1 挖掘框架
基于图数据库的挖掘框架如图2 所示,在第一次程序启动时,计算邻近关系并存储在图数据库中,然后基于构造好的邻近关系图挖掘频繁模式。在挖掘过程中,使用索引技术提高查询效率,进而提高挖掘算法效率。该框架的重点是减少邻近关系的重复计算,通过索引技术高效地搜索空间并置模式实例并进行有效的过滤,从而获得频繁并置模式。

图2 提出的挖掘框架Fig.2 Proposed mining framework
3.2 相关算法
(邻近关系图(neighborhood graph))邻近关系图=(,),其中中的每个结点都是中实例,中的每条边是中特征不同的结点对,并且=(o,o)为边的属性。
邻近关系图构造包括结点和边的创建,其中边创建利用线性扫描的方法,具体步骤如下:
结点的创建和插入。首先需要遍历空间实例集创建结点v并插入到中。例如,实例<,1,(x,y)>的结点表示为{:,:1,:(x,y)}。

构造邻近关系图

考虑图1 的空间数据分布,假设实例.1 的空间位置是(3,8),实例.1 的空间位置是(4,7),通过方法将这两个实例分别创建为结点{,1,<3,8 >}和结点{,1,(4,7)}并插入到结点集合中;方法创建结点之间的边,计算邻近距离=(.1,.1),创建.1 和.1 的边为<<,>,>。如图3 所示为一个邻近关系图,任意两个特征不同的结点之间都存在一条边。

图3 一个邻近关系图Fig.3 Neighborhood relationship graph
本文挖掘频繁并置模式的核心思想是按照模式的阶,从小到大地进行模式频繁性验证。假设特征实例集合是有序的,如按特征名称+实例编号的字典序升序排列。候选模式的生成是迭代的过程,1 阶频繁模式用特征集进行初始化,(>1)阶候选模式由其-1 阶均为频繁的模式生成(引理1)。模式表实例就是查找出邻近关系图中跟候选模式相关的满足邻近关系的所有团,然后根据定义4 来计算候选模式的频繁度。提出了两种算法计算候选模式的频繁度,分别是CliqueSearch 和InstanceValidation。
CliqueSearch 算法包括两个核心的步骤:查找与候选模式中特征相关的所有路径和路径检查。在路径查找步骤中使用索引技术提高查找效率,同时对查询到的路径进行过滤。过滤分为粗过滤和细过滤两个子步骤。在粗过滤步骤,如果候选模式的粗行实例的频繁度小于给定的阈值_,该候选模式一定不是频繁并置模式,将其剪枝;否则进入细过滤步骤,即判断路径中任意两个结点是否都满足邻近关系(任意两个结点之间都存在边),如果“是”保留该路径,否则将该路径剪枝。经过细过滤步骤后留下的路径一定都是并置模式的行实例。最后计算实际的频繁度,如果不小于给定的阈值,则该模式为频繁模式。
InstanceValidation 算法最大的优点是不用收集和存储候选模式的所有行实例,搜索空间小,中间操作步骤少。其核心思想就是根据中心实例的邻居集,判断该中心实例是否涉及到候选模式的一条行实例中,如果找到这样的一条行实例,就将该中心实例进行参与标记,并停止搜索其他涉及到该中心实例的行实例。判断中心实例是否涉及到模式的某条行实例,包括过滤和验证两个步骤。过滤步骤判断中心实例的邻居集是否包含了候选模式的所有特征,如果“是”则进行验证步骤,否则该候选模式一定不存在一条行实例涉及此中心实例,剪枝。验证步骤是搜索一条涉及到中心实例的行实例,即在中心实例的邻居集中找到一个任意两个实例都满足邻近关系的团,如果找到,标记中心实例为模式的参与实例。在完成模式中一个特征的所有实例的过滤和验证步骤后,计算该特征的参与率,如果小于给定阈值_,则停止模式中剩余特征的过滤和验证操作,并将该候选模式剪枝(根据定义3,候选模式中任意一个特征的参与率小于给定阈值,那么该候选一定是非频繁模式)。算法2 和算法3 分别给出了CliqueSearch 和InstanceValidation 算法的伪代码。
CliqueSearch

算法2 解释如下:
第3 行生成候选模式。根据参与度的定义可知,所有一阶模式都是频繁的。生成(>1)阶候选模式是通过-1 阶频繁模式集合中任意两个组合生成,如果组合生成的候选模式的阶数值为,则判断该模式的所有-1 阶子集是否都频繁,如果“是”保留该候选模式,否则舍弃。
第5 行根据候选模式到邻近关系图中查找出所有与候选模式特征相关的候选路径。首先需要根据候选模式构造出查询语句,如图4(c),存在候选模式{,,},路径查询 语句构造为“-[:<,>]--[:<,>]-”。查询图将返回与模式{,,}相关的所有满足邻近关系的路径。第7 行,如果模式为2 阶直接计算频繁度,判断其是否为频繁模式。
第9 行对候选表实例进行粗过滤,如果不满足最小频繁度阈值,则无需进行后续步骤的计算,将该模式剪枝;否则执行第10~12 行,候选路径细过滤,即判断路径中任意两个结点是否满足邻近关系,如果“否”,将该路径剪枝。路径细过滤步骤通过引入哈希表来检查(>1)阶行实例。哈希表中的每个元素是键值对结构的对象,键为-1 阶团,值为阶团中第个结点。在检查的过程中,首先对候选路径进行哈希转换,键为路径中前-2(>2)个结点,值为路径中后两个结点,判断值中的两个结点是否都能够在哈希表中查找到,如果不能找到或只能找到其中一个则将该候选团剪枝;如果两个结点都能够在哈希表中查找到,则检查它们之间边的距离是否不超过距离阈值,否则将其剪枝。这种检查过滤方法只需对邻近关系图查询一次。如图4(c)检查模式{,,} 的路径{.1,.1,.1} 和{.2,.1,.1} 是否构成团,首先进行哈希转换,对应的键值对分别是{:{.1},:{.1,.1}} 和{:{.2},:{.1,.1}},查找2 阶哈希表发现路径{.2,.1,.1} 的在({.2})中只出现.1,将其剪枝;而{.1,.1,.1}的在({.1})中均出现,因此检查.1 和.1的邻近关系,通过查询邻近关系图发现它们满足邻近关系,故保留为候选团。
脱离临床工作也是部分护理学博士研究生的入学动机。目前,在医院从事临床护理工作的护士工作负荷重、职业风险大、社会地位低、医护关系不平等[9],医院对护士人力资源的分级管理不完善[10],有的医院领导认为不管护士是什么学历,都应从临床一线做起[11],这使得护理学博士研究生担心到医院工作没有时间和精力进行科研,医院没有合适岗位能使他们兼顾临床护理工作和科研工作而埋没自己的专长,不能运用所学而对医院望而却步,从而青睐高校教师岗位。
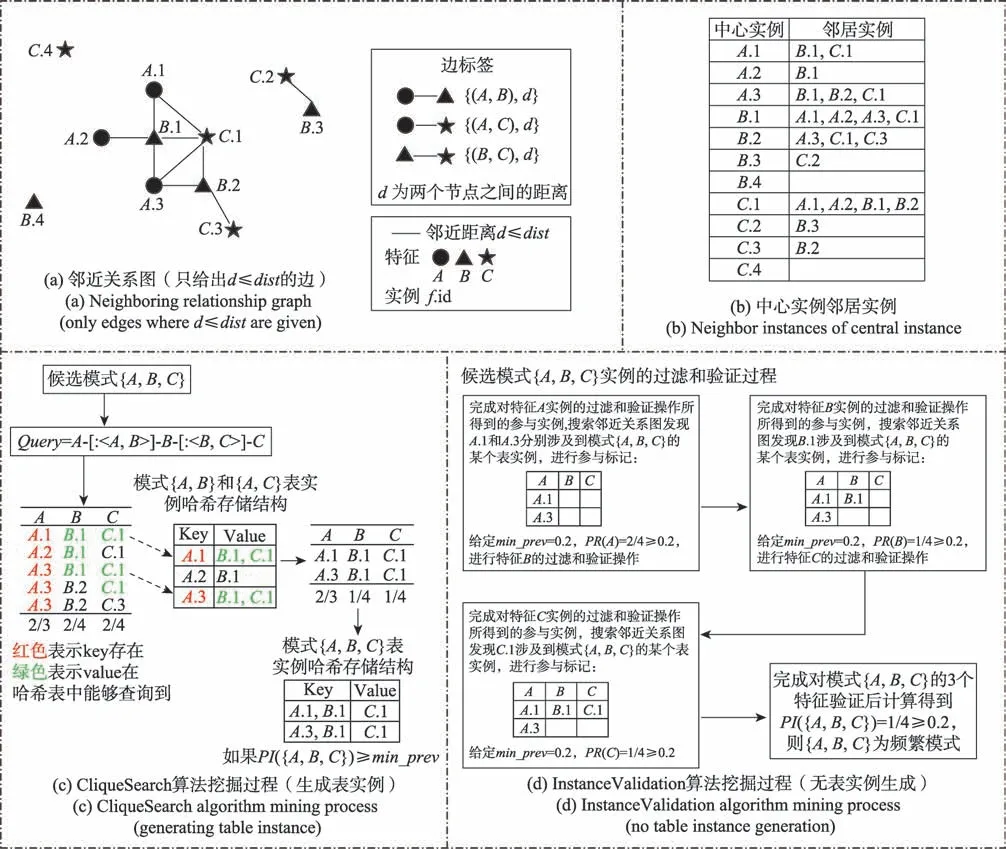
图4 基于图数据库的频繁并置模式挖掘过程示例Fig.4 Example of prevalent co-location pattern mining process based on graph database
第15~17 行,如果该并置模式频繁,则将其所有表实例转化为键值对保存到哈希表中,用于下一次的迭代检查。如{,,}为一个频繁模式,那么将其表实例转为键值对保存到3 阶的哈希表中,{{:{.1,.1},:{.1}},{:{.3,.1},:{.1}}}。
InstanceValidation


算法3 解释如下:
第3 行生成候选模式,方法同算法2 所述。第4~18 行判断候选模式是否为频繁模式。其中,第8~10行,判断特征每个实例是否涉及到候选模式的某个行实例中,如果存在一个行实例包含的实例,那么标记该实例为候选模式的一个参与实例。第9 行在实例的参与过滤与验证的步骤中可以采用空间特征查询法和枚举法。在本文中采用枚举法,因为枚举法能够确保完整地验证所有实例的参与情况并且实现简便。空间特征查询法的实现较为复杂,且空间特征查询是一个NP 问题,具有较大时间复杂度。在过滤阶段,首先判断模式的所有特征是否都在以实例为中心的邻居实例集中出现,如果“是”进行验证,否则进行下一个实例的过滤验证操作。如图4(d)所示,在进行候选模式{,,}的参与实例统计时,.1 的邻居实例集中同时包含了特征和,则进入该实例的验证步骤;同样的,.2 的邻居实例集中只包含特征,那么一定不存在{,,}的一个行实例涉及.2,调过实例验证阶段,直接进行.3 的过滤和验证。在验证阶段,搜索涉及该实例的一个行实例,如果搜索到这样的一个行实例,将实例标记为模式的一个参与实例,结束本次操作并进行下一个实例的过滤验证操作。如图4(d)中搜索到.1 涉及的一条行实例{.1,.1,.1},则对.1 进行参与标记。第11 行,完成模式中一个特征所有实例的过滤和验证操作后,计算该特征实例的参与率,如果小于给定阈值,则停止中其他特征的过滤和验证操作,并根据定义3 将剪枝。()不小于频繁阈值_,则进行特征的参与统计,否则将候选模式{,,}剪枝。采用实例验证的方法可以看出,在整个模式实例参与数的统计中没有行实例的存储并且不用计算所有的行实例,搜索空间小。
3.3 计算复杂度分析
(1)算法的时间复杂度分析。假设空间数据集有个实例,对应的空间特征集有个空间特征,每个特征f∈,1 ≤≤对应的实例最多有个,阶频繁并置模式最多有个,为实例o∈,1 ≤≤的特征,候选模式的候选实例个数最大为。中心实例o的邻居实例中每个特征的实例数最大为,其中≪。

表实例的收集通过候选模式查询邻近关系图数据库,每个候选模式粗表实例的收集需要的最大时间复杂度为(s),每个模式查询得到的粗行实例个数为,第一次过滤需要的时间为()。
对于算法2,引入哈希表来检查阶模式实例。检查一个阶候选团所需要的查询次数为一次哈希表和一次邻近关系图查询,总共需要两次查询,检查完一个模式的所有实例需要的操作次数为2×。频繁度的计算需要的执行次数为×+,其中特征实例的参与统计操作次数为×,完成模式中每个特征的参与率计算需要的操作次数为。有个阶候选模式完成频繁度计算,算法2 需要的最大执行次数是×[2+(×+)]。
对于算法3 在过滤步骤,完成对一个中心实例邻居的过滤需要的最大执行次数是(-1)×;在验证步骤,判断是否存在一条行实例包含中心实例,需要的最大搜索次数为l。完成一个候选模式的参与实例统计需要的最大执行次数为×[(-1)×+l] 。完成第阶频繁模式选择需要的最大执行次数为××[(-1)×+l]。
算法2 和算法3 经过次迭代的最大执行次数分别为××[2×+(×+)+s]和×××[(-1)×+l],因此最大时间复杂度分别为(××s) 和(×××l)且(××s)>(×××l)。
(2)算法的空间复杂度分析。算法1 构造的邻居图的空间复杂度为(||)≤()。每次迭代生成阶候选模式数量为=|C|,该步骤的空间复杂度为()。算法2 每个候选模式的最大行实例数为,每次迭代的哈希表最大空间占用为,因此算法2 的空间复杂度为(2×)。算法3 无表实例生成,每次保存的是每个特征的参与实例数,空间复杂度为(1)。
3.4 完整性和正确性分析
所提出的算法能完整和正确地发现空间频繁并置模式。
(1)完整性。完整性意味着算法能够发现所有的空间并置模式。下面分别证明算法1~算法3 的完整性。对于算法1,构造邻近关系图第一次线性扫描完成后,所有实例被构造为图的结点,没有实例丢失。构造出来的邻近关系图任意两个不同特征的实例结点之间都有一条边,在构造的过程中没有边丢失,因此构造出来的邻近关系图是完整的。对于算法2,第一步,生成候选模式的方法根据引理1 是正确的,没有+1 阶候选模式丢失。第二步,通过候选模式收集表实例和进行第一次过滤(粗过滤)是正确的,因为过滤掉的候选模式频繁度小于用户给定的最小频繁度阈值。第三步,定义2 和邻近关系确保了形成的模式实例是正确的,并且在团的检查中没有对候选模式实例误判而影响参与度的准确度。第四步,候选模式频繁度计算根据定义3 是正确的且被剪枝候选模式的真正频繁度小于用户给定的频繁阈值。对于算法3,统计一个模式的参与实例,分为过滤和验证两个步骤。在过滤步骤,判断每个中心实例邻居集所构成的团中是否包含了候选模式中所有的特征,根据定义1 和定义2 可知该步骤是正确的。在验证步骤,搜索一条包含中心实例的行实例,如果找到这样的行实例,则将中心实例标记为参与实例,在此过程中没有错误的标记模式参与实例,根据定义2 可证明该步骤的正确性。完成候选模式中一个特征的参与实例统计后,计算参与率根据定义3是正确的,同时利用剪枝来缩小搜索空间根据引理2 是正确的,因此没有频繁模式丢失和错误地选择非频繁模式。
(2)正确性。正确性意味着发现的所有空间并置模式都是频繁的。算法的正确性是通过过滤步骤和频繁度计算步骤来保证的。因为算法具有完整性,没有任何候选模式和候选模式实例的丢失,所计算的频繁度也是正确的,所以得到的频繁模式一定满足用户给定的频繁阈值。
4 实验与分析
首先,为了更好地进行算法的对比与分析,将已有的挖掘算法Fraction-Score、Join-based和Joinless移植到了图数据库上,分别记为GDBFracScore、GDBJoinbased 和GDBJoinless。然后,收集了真实数据集并进行数据清洗。最后,为了验证提出算法的效果和效率,分别在真实数据集和合成数据集上开展了不同维度的对比实验。此外,利用合成数据比较了基于图数据库和基于内存物化邻近关系对算法的执行时间和空间占用的影响。实验所用图数据库为Neo4j,所有算法都采用Java 语言实现,实验环境为Win10,Core i5 GPU、240 GB固态硬盘和16 GB内存。
4.1 实验数据集
实验数据集的相关信息如表1 所示。其中真实数据集1 是商业数据集,它是Yelp 数据集(https://www.yelp.com/dataset)的一部分。Yelp 数据集是一个公共数据集,包括美国许多城市的业务类别、属性和位置。真实数据集2 是北京植被数据,包括26 种植被类型(特征)和25 276株植被实例。真实数据集3是北京POI 数据,包括56 种POI 类型(特征)和207 198个POI(实例)。

表1 真实数据集说明Table 1 Description of real datasets
本文使用类似文献[3-4]中所提出的空间数据生成器来生成合成数据集。空间实例的分布密度和范围,由×的空间和决定,为空间边长。整个空间划分为×大小的网格,是邻近距离阈值。特征的密度由特征数决定。数据的分布满足泊松分布。表2 为合成数据生成器的几个重要参数说明。

表2 合成数据参数说明Table 2 Description of synthetic data parameters
4.2 真实数据集上的实验与分析
为了评估不同的参数设置对挖掘算法效率的影响,将本文提出算法CliqueSearch、InstanceValidation和基准算法GDBJoinbased、GDBJoinless、GDBFracScore分别在3 种真实数据集上进行实验。各个数据集的默认参数设置如表3 所示。

表3 真实数据集默认参数Table 3 Default parameters of real datasets
在3种真实数据集上,5种算法在不同距离阈值和不同频繁度阈值的运行时间如图5所示。当距离阈值增加,Join-based、Join-less和CliqueSearch算法的执行时间增加最明显;Fraction-Score方法和InstanceValidation算法的执行时间趋于稳定。提出的两个算法执行时间优于传统的方法和最新的技术,其中InstanceValidation算法的表现优于CliqueSearch。Fraction-Score 算法执行时间较Join-based 和Join-less 少,主要原因是所采用的频繁性度量方法不同,Fraction-Score 所用的度量方式先计算出每个特征对实例的贡献分数,然后通过特征分数累加的方式求并置模式的频繁度,不用收集表实例,因此时间开销较经典方法少。提出的方法挖掘出来的结果跟Join-based 和Join-less 方法一致,并且在时间开销上更少。同样地,由图5 可以看出,随着频繁度阈值的增加,执行时间都在减少。其中,在传统方法和最新技术的表现中,Fraction-Score 方法仍然优于Join-based 和Join-less 方法,这是因为Fraction-Score 方法的优化剪枝效率很高,每次减去的模式更多。提出的两个算法的表现仍然是最优的,因为在团的查找中,直接过滤了与模式无关的特征,只需检查团;而Join-less 方法在过滤与模式特征相关的实例时,需要遍历中心实例的所有星型邻居,然后利用组合的方法生成所有候选团,因此时间开销大。从表1 可知,真实数据集1 有80 个特征,属于特征密集型数据集,但实例密度较小。特征越密集,生成的2 阶候选模式越多,对于Join-based 方法,表实例的连接次数越多,时间开销增加。Join-less 和Fraction-Score 方法的过滤步骤能更快对非频繁候选模式剪枝,但是Fraction-Score 需要通过组合搜索判断候选模式是否存在一个实例,Join-less 方法要通过组合的方式收集表实例,比较耗时。提出的方法,基于图数据库查询团可以直接过滤非频繁模式,中间操作次数少,并且InstanceValidation 算法采用中心实例过滤与验证的方法不用存储表实例,直接对参与实例进行标记计数,因此时间开销更少。真实数据集3 实例数最多并且实例和特征密度较大。根据实验结果可以看出特征密集或者实例密集对Join-based方法都产生较大的影响,而Join-less 和CliqueSearch方式次之,Fraction-Score 和InstanceValidation 受到特征数量影响最小。如表4 所示,在3 个真实数据集上,根据默认参数对算法的时间效率加速比进行了计算。因为基准算法中GDBFracScore 算法的表现最优,所以提出的CliqueSearch 和InstanceValidation 仅与该算法的执行时间进行计算。从表中可以看出,算法2 的时间效率提升了至少7 倍,算法3 至少提升了11.5 倍,其中算法3 较算法2 执行时间效率至少提升了1.6 倍。综上,提出的两个算法在不同大小和分布的实际数据集上都表现出了良好的性能。
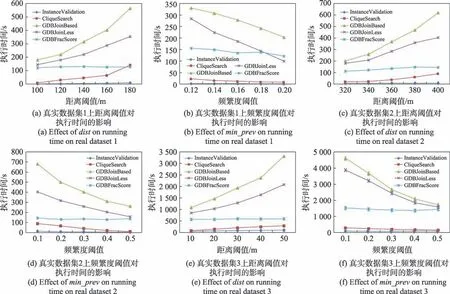
图5 真实数据集上不同参数对执行时间的影响Fig.5 Effect of different parameters on running time on real datasets

表4 提出算法与基准的执行时间和加速比Table 4 Execution time and speed-up ratio of proposed algorithm and benchmark
4.3 合成数据集上的实验与分析
为了研究实例数目对算法运行时间的影响,利用合成数据(合成数据集1~5)来进行实验,实例数量()分别取值2.4×10、2.8×10、3.2×10、3.6×10和4.0×10,数据分布空间大小为50 000×50 000,空间特征个数为40。5 种合成数据集的默认距离阈值设置为200 m,频繁度阈值设置为0.1。
如图6(a)所示,随着实例数增加,在相同的空间分布下,数据的密度变大,执行时间增加,提出的算法效率要远高于基准。因为随着实例数的增多,实例之间的邻近关系增多,形成的行实例增多,Joinbased 方法需要进行的表连接操作也增多,需要的时间开销也就越大。同样地,随着邻近关系的增加,Join-less 方法过滤得到的邻居就越多,组合生成表实例需要的时间就越长。Fraction-Score 方法搜索判定是否为模式实例的操作次数变多,时间开销增加。CliqueSearch 方法在表实例的查找中,没有连接操作也不用进行组合搜索操作,而InstanceValidation 方法不收集表实例,当实例数取值为4×10时,CliqueSearch算法的执行时间只需Fraction-Score 方法的28%,而InstanceValidation算法只需其16%,可以看出时间开销远小于基准,有更好的执行表现。图6(b)对本文所提的两个算法进行了比较,可以看出InstanceValidation算法的表现始终优于CliqueSearch。InstanceValidation算法采用实例过滤和验证的方法,统计一个候选模式的参与实例,不生成表实例,内存开销小。而CliqueSearch算法在选择频繁模式时,需要收集候选模式的所有表实例并且将-1阶频繁模式的每条实例转为键值对存储在哈希表中用于阶候选团(粗表实例)的检查,内存开销较大。当实例数增大到4×10时,CliqueSearch算法的内存使用为InstanceValidation算法的4.6 倍。
本小节通过实验比较不同特征数对算法运行时间的影响。数据的空间分布设置为50 000×50 000,实例个数设置为1×10,空间特征数分别取值为30、50、70、90、110。默认距离阈值为200 m,频繁阈值为0.2。
如图6(c)所示,当空间特征数为30 时,5 种算法之间有较大的执行时间差距,特征数增加到50 执行时间也增加,是因为特征数增多生成的候选模式增多,对于Join-based 方法,表的连接操作次数增多,因此时间增加;而对于Join-less 和Fraction-Score 方法,尽管没有大量的表实例的连接操作,但是组合搜索方法中组合操作的次数同样增多,执行时间增加。当空间特征数目增加到70、90 和110 时,尽管候选并置模式数目在增多,但算法的执行时间都在减少,因为在实例总数不变的情况下,随着特征数继续增加,每个特征对应的实例数在减少,因此模式的行实例数目也在减少。对于Join-less 方法,表实例的连接操作次数减少,收集到的表实例数也减少;而Fraction-Score 方法的组合操作次数减少,因此执行时间减少。同样地,提出的CliqueSearch 方法在特征数少的情况下,特征实例密集,收集到的模式实例更多,过滤需要的时间更多,因此需要的频繁模式计算耗时也多。特征实例稀疏时,收集到的模式实例更少,频繁模式计算耗时也在减少;InstanceValidation 方法,随着特征数目增加,时间开销有一定的增加但是受到的影响较小,整体表现趋于稳定。总体上,提出的算法在执行的时间效率表现上优于移植到图数据库上的经典算法和最新技术。
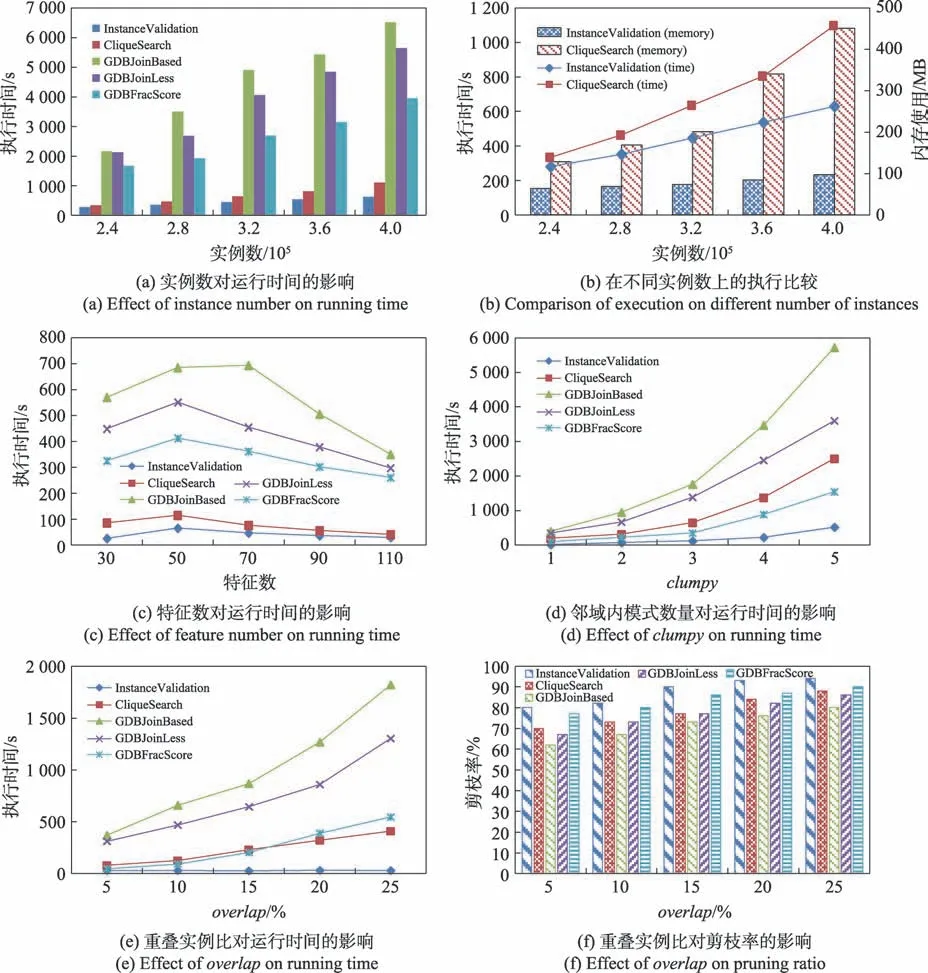
图6 合成数据集上不同参数对算法运行时间的影响Fig.6 Effect of different parameters on running time of algorithms on synthetic datasets
在本次实验中研究邻域内模式实例数量(参数的变化)对算法执行的影响。数据的空间分布设置为50 000×50 000,实例个数设置为9×10,空间特征数取值为30,距离阈值设置为200 m,频繁度阈值设置为0.2,参数的取值范围为1、2、3、4、5。
由图6(d)可以看出,随着取值增大,算法的执行时间都在增加,这是因为随着的增大,并置模式数量在增加。Join-based、Join-less 和CliqueSearch 方法收集表实例的中间操作次数增多;而Fraction-Score 方法计算模式分数评分需要的组合搜索操作次数同样增多,时间开销增加。对于InstanceValidation 方法,邻域内模式数量增多导致了中心实例需要执行的过滤与验证操作次数增加,从而时间开销增加,但它表现仍然是几种方法中表现最优的且具有一定的稳定性。
在合成数据上改变重叠实例比()的实验结果,如图6(e)所示。数据的空间分布设置为25 000×25 000,实例个数设置为5×10,空间特征数取值为30,距离阈值设置为800 m,频繁度阈值设置为0.2,取值设置为2,重叠实例比的取值范围为5、10、15、20、25。随着特征的重叠实例比增大,算法的执行时间都在增加。因为收集表实例的方法中间计算步骤增多,所以时间开销增加。例如一个中心实例周围是特征相同的几个实例,那么中心实例在表实例收集的过程中将被重复连接或者组合。在5 种方法中,实例的过滤和验证方法的表现最优并且更加稳定。算法的剪枝率实验结果如图6(f)所示。当重叠实例比增大,算法的剪枝率都在增加,其中本文提出的两种算法在剪枝率上有较好的表现,InstanceValidation算法剪枝率均高于80%,CliqueSearch算法保持在70%以上,并且提出的算法剪枝率都较基准高。因为随着重叠率的增加,重叠实例的特征参与率降低,候选模式的剪枝机会增大(剪枝率为非频繁模式总数与候选模式总数之比)。
4.4 基于图数据库和基于内存物化邻近关系的实验与分析
从真实数据集和合成数据集上的实验可以看出,Fraction-Score 在基准算法中的执行表现最优。因此本节在合成数据集上将提出的算法与Fraction-Score算法分别利用内存和图数据库物化邻近关系在执行时间和空间占用上进行比较。数据空间分布大小为40 000×40 000,实例个数为6×10,空间特征数为30。参与度阈值设置为0.3,和设置为1。距离阈值的变化范围是100 m、120 m、140 m、160 m、180 m。Fraction-Score方法利用图数据集库和内存物化邻近关系的执行时间比较如图7(a)所示。随着距离阈值增大执行时间都在增加,因为当距离阈值较小时,中心实例的邻近关系少,搜索空间小;当距离阈值变大时,邻近关系增多,搜索空间增大,时间开销增加。当距离阈值较小时,基于内存的方法执行时间少于基于图数据库的方法,但是当距离阈值变大时,基于内存的方法时间开销迅速增加且超过了移植到图数据库的方法,原因是基于内存方法计算邻近关系需要的时间开销增大,而移植到图数据库的方法只需要对邻近关系图进行查询而不用每次启动程序重新计算。提出的两种挖掘方法时间表现优于最新技术的两种实现方式。当距离阈值取值为180 m时,GDBFracScore、CliqueSearch 和InstanceValidation算法相对于MemFracScore 算法的时间效率提升倍数分别为2.2、3.6 和9.3。
算法执行的内存使用如图7(b)所示,随着距离阈值增大,CliqueSearch 和Fraction-Score 利用内存物化邻近关系方法的内存消耗都在增加,其中Fraction-Score 方法的内存消耗最多,因为Fraction-Score 方法随着距离阈值增加邻近关系增多,导致内存使用增加。CliqueSearch 方法的内存增加,因为查询到的模式实例数增多,即收集到的表实例增多。Fraction-Score 移植到图数据库上的方法的内存使用趋于稳定,因为邻近关系不用存储在内存中,需要存储的是每个空间特征对每个实例的评分,当实例数不变时内存使用大小趋于稳定。InstanceValidation 算法执行内存消耗最少并且随着距离阈值增加趋于稳定,因为不用收集和保存表实例。随着距离阈值增大,空间邻近关系增多,距离阈值取值为180 m 时,基于图数据库的方法较基于内存物化邻近关系的方法有着较明显的优势,GDBFracScore、CliqueSearch 和InstanceValidation算法与基于内存方式实现的Fraction-Score 算法内存占用比分别为1∶4.1、1∶1.7 和1∶6.6,其中InstanceValidation 的内存使用约为CliqueSearch的1/4。CliqueSearch 算法内存使用较GDBFracScore算法高,是因为前者保存表实例占用了大量的内存空间。综上,可以看出移植到图数据库上的方法在时间开销和内存使用上都有较好的表现。
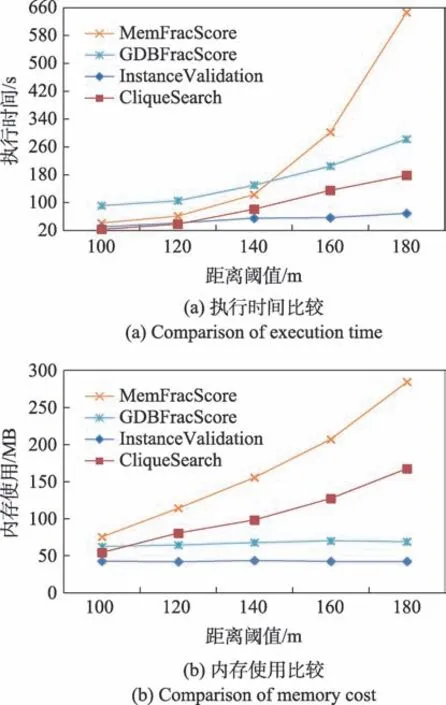
图7 图数据库和内存物化邻近关系的实验比较Fig.7 Experimental comparison between graph database and memory materialized neighbor relationship
5 结束语
空间频繁并置模式挖掘是发现一些先前未知的但是具有重要指导意义的空间知识的重要工具。传统方法能够对这些有着重要意义的模式进行挖掘,但当空间数据量较大时,存储空间邻近关系会占用大量的内存空间,带来内存不足的问题,并且查找表实例时间开销很大。图数据库是当前比较流行的一种非关系型数据库,能方便地以图的形式表示数据和关系,并且提供了管理高度连接的数据和复杂的数据库查询以及原生图形存储和处理的能力。空间实例之间存在着复杂的邻近关系,利用图数据库能够很好地把这些空间数据和它们对应的关系存储下来,然后挖掘空间频繁并置模式。根据图数据库的优点,利用图数据库来存储实例的邻近关系,即构造邻近关系图,减少了内存占用。移植到基于图数据库的经典的挖掘算法没有充分发挥图数据库的优势导致效率很低。因此,本文将传统表实例的生成方法转变为基于图数据库的团查找方法可以直接获得与候选模式相关的候选团,而不需要组合或连接操作来生成候选团,减少了时间开销。此外,本文还提出一种实例过滤和验证的无表实例收集的新方法,进一步提高了算法的时间效率和空间效率。最后,通过实验验证了所提算法的正确性、高效性和可扩展性。
在未来的工作中,计划进一步应用图数据库的特性,研究时空数据和带更多属性的数据的空间并置模式挖掘问题。此外,将进一步考虑在挖掘过程中融入应用领域的背景知识,研究基于知识图谱的空间并置模式挖掘技术。
