有监督实体关系联合抽取方法研究综述
2022-04-13张少伟陈子睿徐大为贾勇哲
张少伟,王 鑫,2+,陈子睿,王 林,徐大为,贾勇哲,
1.天津大学 智能与计算学部,天津300350
2.天津市认知计算与应用重点实验室,天津300350
3.天津泰凡科技有限公司,天津300457
随着大数据时代的到来,人们日常生活中会产生海量的数据,比如新闻报道、博客、论坛、研究文献以及社交媒体评论等,数据的领域交叉现象突出,有价值的信息往往隐藏在大量数据中。信息抽取(information extraction,IE)的目的在于快速高效地从大量数据中抽取有价值的信息。实体关系联合抽取作为信息抽取的核心任务,近年来受到学术界和工业界的广泛关注,实体关系联合抽取通过对文本信息建模,来自动识别实体、实体类型以及实体之间特定的关系类型,为知识图谱构建、智能问答和语义搜索等下游任务提供基础支持。
传统的流水线方法将实体关系联合抽取分解成命名实体识别和关系抽取两个独立的子任务,流水线方法先执行命名实体识别任务,再根据命名实体识别的结果完成关系抽取任务,两个子任务使用的模型相互独立,可分别在不同的训练集上训练。传统的流水线方法通常会引发以下三个问题:(1)误差传播。命名实体识别子任务产生的误差,在关系抽取子任务中无法得到纠正,影响关系抽取的结果质量。(2)子任务间缺少交互。流水线方法忽略了命名实体识别和关系抽取两个子任务间的关系,两个子任务之间缺少交互,使得子任务的信息没有被充分利用。比如实体类型和关系类型之间应存在某种隐含关系,在识别实体类型的过程中,关系类型会起到一定作用,对于识别关系类型的过程同样如此。(3)产生冗余信息。命名实体识别子任务获得的实体,实体之间并非都存在某种关系,不存在关系的实体作为冗余信息传递到关系抽取子任务中,提高了错误率。因此,实体关系联合抽取逐渐受到重视。
本文主要研究有监督实体关系联合抽取,文中也称为联合抽取。联合抽取通过建立统一的模型,使不同的子任务彼此交互,充分利用子任务中的信息,进一步提升模型的性能。然而,在实际应用中,联合抽取模型会面临以下几个挑战:
(1)实体嵌套:现实生活中,存在一个实体嵌套另一个实体的情况,同一个词可能属于不同的实体,比如“天津大学”是一所大学,同时“天津”也是一个地点。联合抽取模型需要融入更丰富的上下文语义信息才能识别当前实体类型,大量实体嵌套的情况增加了联合抽取的难度。
(2)关系重叠:同一句子中可以存在不同的关系类型,相同的实体之间可以存在多种关系类型,不同关系之间也可能包含一些隐藏信息。比如“北京是中国的首都”,“中国”和“北京”之间存在“包含”和“首都”两种关系类型。联合抽取模型需要设计不同的抽取策略或复杂的标注方案才能解决此类问题。
(3)数据噪音:日常生活产生的海量数据通常存在大量数据噪音,尤其是网页、社交平台和媒体评论等环境产生的数据,存在许多特殊符号和不标准表达等类型的噪音。包含数据噪音的数据难以被充分利用,也增大了联合抽取获取有效数据的难度。
(4)模型的平衡性:联合抽取的难点是增强子任务间的交互性。简单的交互难以充分利用子任务的重要信息,降低抽取结果的准确性;复杂的交互会对子任务进行限制,使得子任务抽取的特征不具备丰富性。联合抽取需要在子任务特征的丰富性和子任务的交互性间做权衡,以达到最佳抽取效果。
联合抽取的相关工作如下:文献[14]是基于深度学习的命名实体识别和关系抽取的介绍,但对基于深度学习的联合抽取方法介绍较少;文献[15]对命名实体识别和关系抽取做了系统全面的介绍,但未侧重于联合抽取的方法;文献[16-17]着重于研究关系抽取的各种方法,对联合抽取的方法描述较少;文献[18]综述了基于深度学习的关系抽取方法,并未介绍联合抽取方法;文献[19]侧重于基于机器学习的各种关系抽取方法,对联合抽取方法的介绍较为简单;文献[20]与本文的工作接近,但在描述基于神经网络的联合抽取方法时没有进行细致的分类。本文则针对有监督实体关系联合抽取方法做出了较为详细的分类和介绍。整体框架如图1 所示。

图1 联合抽取方法分类Fig.1 Classification of joint extraction methods
本文目的在于对有监督实体关系联合抽取的最新研究进展提供全面深入的研究综述。具体而言,本文的贡献在于:
(1)根据特征的不同提取方式,对联合抽取进行了细致的分类,并详细阐述了不同类型下联合抽取方法的特点。
(2)介绍了联合抽取常用的数据集及评价指标,在不同数据集上比较了各个方法间的性能差异并进行分析。
(3)基于最新的研究进展,总结联合抽取面临的多种挑战性问题,指出未来的主要研究方向。
1 预备知识
本章给出实体关系联合抽取需要的预备知识。



当前主流的联合抽取方法主要基于各类神经网络模型,以下介绍联合抽取常用的神经网络模型。
循环神经网络:循环神经网络擅长处理带有时序信息的序列,其在每个时刻都更新自己的“记忆”,难以解决长期依赖与梯度消失的问题。长短时记忆网络(long short-term memory,LSTM)于1997 年被提出,是循环神经网络的一种变体。LSTM 用特定的学习机制来聚焦并更新信息,能够解决长期依赖和梯度消失问题。门控循环单元(gated recurrent unit,GRU)对LSTM进行改进,使用更少的门提升了计算效率。
图卷积网络(graph convolutional network,GCN):研究者们将诸如卷积神经网络等传统神经网络结构扩展到图数据中,使用卷积层提取图中节点的特征信息,将当前节点的特征传递至相邻节点,通过叠加GCN 层学习到图中的节点表示。GCN 的输入是一个图,图通常由×的节点嵌入矩阵和×的图结构表征矩阵(如邻接矩阵)来表示,最终输出×的矩阵,表示每个节点的特征信息。
预训练模型:预训练模型是已经在大量数据集上训练并保存的网络模型。对于具体的任务,可以在预训练模型上微调,实验也证明预训练方法是有效的。在自然语言处理(natural language processing,NLP)领域,预训练模型BERT(bidirectional encoder representations from transformers)展现了优秀的性能。BERT 是一种基于Transformer的多层双向语言表征模型,由个相同的Transformer块叠加而成,通过点积注意力的方法更深层次地学习到单词的特征信息。
表1 给出了联合抽取常用符号描述。

表1 常用符号描述Table 1 List of notations
2 基于特征工程的联合抽取
特征工程是将原始数据转化为表达问题本质特征的方法,将特征工程获得的特征运用到模型中可以提高模型性能。基于特征工程的联合抽取,需要根据数据特点设计特征,当满足特征函数的条件时,该特征函数会被触发。基于特征工程的联合抽取主要有以下四种方法:整数线性规划、卡片金字塔解析、概率图模型和结构化预测。
2.1 整数线性规划
线性规划(linear programming,LP)是运筹学中应用广泛且较为成熟的一个重要分支,目的是在有限资源和若干约束下,求解得到某个目标函数最大值或最小值的最优策略,其中约束条件和目标函数均为线性函数。线性规划的形式化表达如下:

式(1)表示需要优化的函数,式(2)表示若干线性约束。Roth 等首次使用整数线性规划的方法实现联合抽取。其使用随机离散变量表示局部实体识别和关系抽取的结果,目的是在先验信息、关系和实体类型等多个约束条件下求得全局最优分配策略。该模型的目标函数由两部分构成:(1)标注分配损失,表示局部分类器预测的标注与实际值偏离的情况。(2)约束损失,表示破坏给定约束条件需要付出的代价。文献[30]通过添加变量的整数约束将线性规划转换成整数线性规划,用线性松弛法、分支定界法和割平面法等求解最优分配策略。
Yang 等将整数线性规划的方法应用到细粒度的观点抽取,抽取观点、观点相关实体和观点与实体间的关系。文献[31]的实验数据中只存在“IS-FROM”和“IS-ABOUT”两种关系类型,观点和观点相关实体的识别被当作序列标注任务,用条件随机场(conditional random field,CRF)学习序列标注的概率;观点与实体间的关系抽取被当作分类任务,定义势函数表示候选观点相关实体与其参数的关系信息。另外,文献[31]根据数据信息定义了大量的特征,包括词性特征、短语类型特征和依赖路径特征等。对于观点标注的唯一性、不重叠性和实体关系一致性等都采用线性公式进行约束。
整数线性规划是一个获得全局最优解的有效方法。整数线性规划的方法应用到联合抽取中,大量的线性公式可以表示各种类型的约束条件,使得联合抽取的设计更具备通用性和灵活性。
2.2 卡片金字塔解析
整数线性规划方法根据多个独立局部分类器的结果计算全局最优解以实现联合抽取,但局部分类器之间没有交互。卡片金字塔解析方法则用图结构编码句子中实体信息和关系类型信息,局部分类器彼此交互,提升了联合抽取的性能。
Kate 等将联合抽取转换成图节点标注的问题,图的结构类似金字塔,因此称为卡片金字塔模型,如图2 所示。这种类似树的图结构在最高层有一个根节点,中间层是内部节点,底层是叶子节点,句子中的实体对应叶子节点,叶子节点标注为实体类型。图的层数和叶子节点数相等,从图的底层到顶层,每次减少一个节点。除去最底层节点,每一层的节点表示与节点相关的最左和最右两个叶子节点之间可能存在的关系。文献[33]的两个局部分类器为实体识别分类器和关系抽取分类器,都采用支持向量机(support vector machines,SVM)进行训练,根据局部分类器的结果构造卡片金字塔图。文献[33]采用动态规划和集束搜索的方法设计解析算法,该方法主要由实体生成和关系生成两部分组成,根据卡片金字塔的结构特点,分别产生叶子节点的实体信息和非叶子节点的关系信息。最终图的节点都被标注,实现了联合抽取。
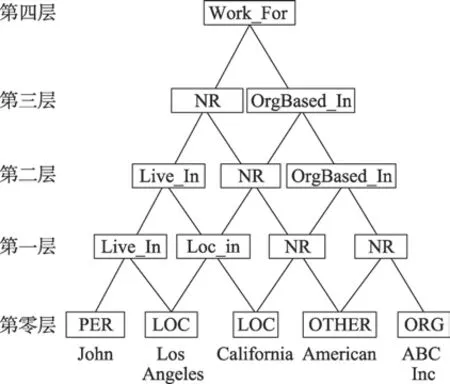
图2 卡片金字塔模型Fig.2 Card pyramid model
2.3 概率图模型
概率图模型使用图结构表示概率分布。由无向图=(,)表示联合概率分布(),即在图中,节点∈表示一个随机变量Y,边∈表示随机变量之间的依赖关系。
Yu 等设计了任意图结构的联合判别概率模型来同时优化联合抽取所有相关子任务,在一个实体信息已知的条件下预测该实体与另一个实体间的关系。其将实体信息和关系类型信息联合建模,整个模型由三部分构成:半马尔可夫链层、势函数层和全连通图层。该模型通过改进传统的CRF 获得无向图的最大条件概率,并设计新的推理方法获得实体关系的最大后验概率,完成联合抽取。
Singh 等则对命名实体识别、关系抽取和共指三个子任务统一建模,根据三个子任务的联合概率表示三个子任务间的依赖关系。具体而言,将三个子任务的变量和因子组合构成图模型,因子通常被定义为特征函数和模型参数的对数线性组合,图中随机变量的概率分布可由因子表示,如图3 所示。图中表示给定的实体变量,下标表示不同的实体,、、分别表示标注变量、共指变量和关系变量,下标作为参数对应不同实体信息,Ψ、Ψ、Ψ分别表示标注因子、共指因子和关系因子,括号中的数字代表不同的实体信息。由于模型中包含大量变量,该方法采用扩展的置信度传播算法进行推理,最终获得实体类型和实体间的关系。

图3 文献[37]的概率图模型Fig.3 Probability graph model of Ref.[37]
用概率图模型实现联合抽取的优点是可以将大量随机变量表示为一系列概率分布,这些概率分布根据基础图进行因式分解,能够捕获变量间的依赖信息。
2.4 结构化预测
传统的机器学习方法,主要面向回归问题和分类问题,输出分别是一个标量和一个类别。对于结构化预测,任务的输出是一个序列、图或树等结构类型,结构中包含语义信息和逻辑信息。
Li等采用结构化预测的方法,将句子中的实体类型信息和关系类型信息存储在图中,图的节点表示实体信息,弧表示实体间的关系信息。文献[38]通过集束搜索进行结构化预测,即对于第个单词,维持个最好的局部结构。其目的是在给定特征和约束条件下预测句子的隐藏结构,形式化表达如下:

其中,表示输入句子,′表示候选结构,(,′)表示整个句子的特征向量。文献[38]采用特征向量和特征权重的内积来表示候选结构的分数,并使用基于半马尔可夫链的分段解码器。由于输出结构中包含实体和关系的信息,该方法通过设计全局特征以约束图结构,最终选择分数最高的结构^ 作为输出。
Miwa 等则用简单的表结构来表示实体类型和关系类型。表的对角线表示实体类型,表格的下三角元素表示实体间的关系类型。文献[39]采用BILOU(begin、inside、last、outside、unit)标注方法,每个实体标注代表实体的类型和每个单词在实体中的位置,如单词Steven 和Jobs 的标注分别为B-PER 和L-PER,分别表示“人”类型实体的起始单词和末尾单词。如图4 所示,由于输入句子构成的表格具有对称性,该方法只使用了表格的下三角部分,根据不同的顺序(如顺序和逆序读取句子)将表格转换成序列;用特征函数与特征权重的内积表示候选结构的分数,选取分数最高的结构作为模型的输出来实现联合抽取。

图4 文献[39]的表格标注方法Fig.4 Table annotation method of Ref.[39]
表2 是对基于特征工程的联合抽取方法的小结,整数线性规划方法可以灵活地表达各种约束条件,但子任务间的交互性较低;卡片金字塔模型、概率图模型和结构化预测皆采用图或表结构来增强子任务间的交互性,但所采用的解析方法不同,计算复杂度增高。卡片金字塔模型设计了相应的卡片金字塔解析算法,概率图模型对一系列概率分布进行解析,结构化预测则评估不同候选结构的分数来选取最优结构。

表2 基于特征工程的联合抽取方法总结Table 2 Summary of joint extraction methods based on feature engineering
3 基于神经网络的联合抽取
基于特征工程的联合抽取在获取特征的过程中严重依赖NLP 工具,需要大量人力和专业领域知识,且存在误差传播的问题,最终影响联合抽取的结果。由于神经网络具有优异的特征学习能力,神经网络的方法被逐渐应用到联合抽取中。
如图5 所示,基于神经网络的联合抽取模型通常由三部分构成:(1)词嵌入层。词嵌入层将输入句子中的单词w嵌入到一个向量空间,向量中融入单词信息、字符信息和其他特征信息。(2)序列编码层。序列编码层叠加在词嵌入层上,将词嵌入层获得的向量进一步编码,使得单词w对应的向量融入上下文信息。(3)解码器层。基于联合解码的联合抽取模型在序列编码层上叠加统一的解码器,直接解码序列编码层得到联合抽取的结果;基于共享参数的联合抽取模型在序列编码层上叠加不同的解码器,根据不同的子任务解码序列信息,解码器间通过共享序列编码层进行信息交互。

图5 基于神经网络的联合抽取Fig.5 Joint extraction based on neural network
3.1 基于共享参数的联合抽取模型

实体对映射到关系将联合抽取分解成两个子任务:命名实体识别和关系抽取。目前,两个子任务都有较为成熟的处理方法。
SPTree首次采用神经网络的方法实现联合抽取。如图6 所示,SPTree 由三个表示层组成:词嵌入层、序列层和依赖层。最底层的词嵌入层将单词和单词词性转换成嵌入向量。序列层则由双向LSTM和两层前馈神经网络构成,序列层的输出为单词的BILOU 标注,通过标注信息实现命名实体识别子任务。SPTree 采用序列标注方案时融入了实体间的依赖信息,通过利用上一个单词的标注信息预测下一个单词的BILOU 标注。

图6 基于依赖树的联合抽取模型Fig.6 Joint extraction model based on dependency tree
将命名实体识别子任务识别的实体进行关系抽取,由模型的依赖层实现。SPTree的依赖层采用双向树结构的LSTM(由上到下和由下到上),使得每个节点融入该节点到根节点和叶子节点的信息。树结构LSTM的设计方法有利于关系抽取,在依赖树中找到两个目标实体的最小公共节点,即两实体间的最短路径,该方法在Xu等关系分类的实验中被证明是有效的。
SPTree 的联合抽取过程中,由于依赖层叠加在序列层上,命名实体识别和关系分类两个子任务可以共享序列层和词嵌入层的信息,两个子任务同时进行训练并在整个模型解码完成后,通过反向传播算法更新共享参数来实现信息交互。
在后续的研究中,各类模型主要从两方面提升联合抽取的性能:(1)提升命名实体识别和关系抽取的准确性;(2)增加两个子任务间的交互性。

另外,现实世界中的实体通常基于跨度进行标记,对跨度建模能够直接抽取实体的特征信息,在设计上容易解决实体嵌套的问题。
Dixit 等在双向LSTM 上使用注意力机制获取所有可能的跨度;Luan 等在假设空间上进行集束搜索,评估跨度的类型信息和跨度间的关系信息;在后续的改进版本中,DyGIE通过构造动态跨度图来进一步丰富跨度信息;文献[52-54]则通过预训练语言模型BERT和注意力机制,提升了抽取跨度的准确性。
为了增强两个子任务间的交互性,Gupta 等将联合抽取转换为表格填充任务;Zhang 等在文献[55]上进一步改进,采用LSTM 进行特征抽取;RIN(recurrent interaction network)采用双向LSTM 学习共享参数层的动态交互信息;Feng 等则采用强化学习的方式增强子任务间的交互;Sun 等设计最小化风险的全局损失函数进行联合训练;在后续的改进版本中,Sun 等将实体类型和关系类型构造成二分图,用GCN 进行联合推理。
联合抽取模型需要权衡子任务的准确性和交互性,在抽取句子的特征信息时通常采用双向LSTM 或预训练语言模型,不同的子任务会设计相应的子模型。上述相关文献的模型架构及描述总结如表3所示。

表3 实体对映射到关系模型总结Table 3 Summary of mapping entity pairs to relationship models
头实体映射到关系、尾实体的联合抽取策略可以用式(4)中的条件概率来表示:

这种策略将联合抽取分解成两步,先抽取头实体,再根据头实体抽取相应的关系类型和尾实体。一个直观的解释是:模型如果不能准确地抽取头实体,那么模型抽取的关系类型和尾实体的置信度同样较低。
Katiyar 等在识别实体的过程中采用BILOU 序列标注的方法,识别出实体后,使用指针网络的方法(注意力模型的一种改进),根据关系类型识别出另一个实体。文献[62]的序列编码层采用多层双向LSTM,在序列编码层上叠加一层从左到右的LSTM层和前馈神经网络进行解码。识别当前实体的过程主要由式(5)和式(6)实现:



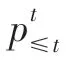
为了抽取句子中的多个关系类型,Bekoulis 等采用多头选择机制,在后续的改进版本中,Bekoulis等在词嵌入向量中添加一个最坏情况扰动项产生对抗样本,通过对抗学习提升了联合抽取模型的鲁棒性;ETL-Span采用序列标注的方法实现了该分解策略;CasRel将关系类型当作一种头实体映射到尾实体的函数,根据函数f()→设计头实体触发器和特定关系的尾实体触发器;TPLinker设计了一种新颖的握手标注方案,将长度为的句子转换成长度为(+)/2 的序列后进行编码,解决了曝光偏差的问题。
Li等和Zhao 等则采用机器阅读理解的方法,将先验信息融入到问题中,在问题和句子的交互中捕捉语义信息,提高了模型的准确性。文献[68]根据头实体用模板生成的方法获得关系类型和尾实体的问题,并采用机器阅读理解的方法抽取句子中对应的尾实体。文献[69]对同一个实体类型,设计了不同角度的多个相关问题,融入更多先验信息。在问题生成过程中,过滤无关关系类型,选择相关关系类型生成问题,并采用答案集成策略选取最优答案。
一般而言,句子中存在的关系类型是由上下文信息而不是实体信息触发。比如句子中若有类似“was born in”的信息,那么可以判断出存在“Place_Of_Birth”的关系类型。关系映射到头实体、尾实体的联合抽取方法便是基于这种现象,先识别出关系,将关系作为先验信息抽取实体,使模型更关注于该关系相关的语义信息,减少冗余的抽取操作。另外,句子中关系类型的数量通常少于实体数量,关系映射到头实体、尾实体的联合抽取方法也降低了计算复杂度,提高了联合抽取的效率。
HRL(hierarchical reinforcement learning)将实体当作特定关系类型的参数,并设计分层的强化学习框架完成联合抽取。强化学习会给出智能体每个状态下应该采取的行动,使得智能体从环境中获得的奖励最大。如图7 所示,高层级的强化学习被用于关系抽取,在这一层级,智能体顺序扫描句子,当中有足够的语义信息时,如一些动词短语“die of”,名词短语“his father”,或介词“from”等,智能体将会预测出相应的关系类型,并发布一个子任务,即低层级的强化学习,用于识别当前关系类型对应的实体对,当子任务完成后,智能体继续扫描剩余的部分。

图7 分层级的强化学习框架Fig.7 Hierarchical reinforcement learning framework
具体而言,高层级和低层级的强化学习都采用双向LSTM 编码得到每个单词的特征向量。高层级的强化学习将单词的特征向量、关系类型的嵌入向量和上一时刻的状态信息向量拼接后,通过前馈神经网络获得当前的状态信息向量,采用随机策略预测当前句子包含的关系类型。高层级的强化学习同时设置奖励函数,当句子不存在模型预测得到的关系类型时,函数值为-1;当模型预测得到关系类型为空时,函数值为0;当句子存在模型预测得到的关系类型时,函数值为1,此时会触发低层级的实体识别。低层级的强化学习采用序列标注的方法,根据预测标注与序列标准标注之间的偏差设计奖励函数。
高层级的关系抽取和低层级的实体识别通过状态信息向量和奖励函数实现交互。在执行低层级的实体识别时,高层级的关系抽取传递相关的关系信息,低层级的实体识别会通过奖励机制,将实体识别的情况反馈给高层级,使得句子中的多个关系三元组被有序地抽取。
Zhou 等通过在双向LSTM 上叠加卷积神经网络提升了关系抽取的准确性,并采用单向LSTM 解码当前关系类型对应的实体对;RSAN(relation-specific attention network)根据不同的关系类型,用关系敏感的注意力方法获得句子的不同特征信息,通过门机制降低了无关关系类型对实体识别的影响;Wang等认为统一编码器在编码实体信息和关系类型信息时,得到的特征信息可能是冲突的、不明确的。Wang 设计了两种不同的编码器:序列编码器和表编码器。两个编码器分别用于编码实体信息和关系类型信息,其内部彼此交互。表编码器将特征信息传递给序列编码器,并预测出关系类型;序列编码器根据特征信息和序列编码信息,通过前馈神经网络预测出实体信息。
基于共享参数的联合抽取模型总结如表4 所示。实体对映射到关系的联合抽取模型,两个子任务的实现方法较为成熟,通过共享参数的方法容易实现联合抽取,但联合抽取过程中会产生不存在关系的冗余实体对,难以有效解决关系重叠的问题;头实体映射到关系、尾实体的方法能够有效解决关系重叠的问题,增强了实体类型信息和关系类型信息的交互,但模型设计相对复杂;关系映射到头实体、尾实体的方法减少了冗余信息的抽取,能够解决关系重叠的问题,但识别候选关系类型的难度较大,模型设计相对复杂。

表4 共享参数模型总结Table 4 Summary of shared parameter model
3.2 基于联合解码的联合抽取模型
基于共享参数的联合抽取模型,每个子任务拥有独立的解码器,通过共享参数的方法实现信息交互,子任务间的交互性并不强。为了增强不同子任务之间的交互性,基于联合解码的联合抽取模型被相继提出。基于联合解码的联合抽取模型通常在序列编码层上叠加统一解码器,直接解码得到关系三元组信息。主要存在两种方法:(1)序列标注方法,将联合抽取转换成序列标注进行解码;(2)Sequenceto-Sequence,采用Sequence-to-Sequence 方法生成关系三元组。
对于命名实体识别任务,通常采用序列标注的方法实现,模型通过预测每个单词的BLOU 标注来识别实体。用序列标注实现联合抽取的优点是方法成熟,实现简单;难点是需要设计统一的标注方案,在标注中融入实体类型信息和关系类型信息。


图8 序列标注方案Fig.8 Sequence annotation scheme
NovingTagging 设计的标注方案在将实体信息和关系类型信息相结合时,并没有融入实体类型信息。由于每个单词只能有一个标注,NovingTagging不能解决关系重叠和实体嵌套的问题。
Dai 等在标注方案上进一步改进,将长度为的句子根据每个单词的位置进行次不同标注,使得每个单词可被多次标注。在解码过程中,文献[75]采用基于位置的注意力方法和CRF 得到个不同的序列标注,解决了关系重叠的问题。
Sequence-to-Sequence方法最初被应用于机器翻译,基于Sequence-to-Sequence 的模型主要由两个分别被称为编码器和解码器的循环神经网络构成,编码器将任意长度的输入序列转换成固定长度的语义向量,解码器将语义向量转换成另一个输出序列。
Zeng 等采用Sequence-to-Sequence 的方法设计了模型CopyRE,同时引入了复制机制。联合抽取过程类似机器翻译,解码器依次产生关系类型、头实体和尾实体。文献[78]首次将关系重叠类型进行分类,如表5 所示,将关系类型分为三种:(1)Normal关系类型,关系三元组的实体没有重叠;(2)SEO(single entity overlap)关系类型,关系三元组的实体对中有一个实体与另一个关系三元组的实体重叠,但两个关系三元组的实体对不重叠;(3)EPO(entity pair overlap)关系类型,一个实体对之间存在多种关系。

表5 关系类型分类示例Table 5 Example of relationship type classification
联合抽取模型普遍容易解决Normal 类型,Copy-RE 能够解决EPO 类型和SEO 类型。如图9 所示,CopyRE 的编码器采用双向循环神经网络,句子经过词嵌入层后传入双向循环神经网络,双向循环神经网络最终的隐藏状态向量拼接得到语义向量,编码过程中用注意力方法获取注意力向量。解码器采用单向循环神经网络,和输入解码器后获得当前时刻的输出向量,输出向量通过前馈神经网络获得关系类型,关系类型的嵌入向量和注意力向量作为下一时刻+1 的输入,+1 时刻的输出向量通过前馈神经网络后采用复制机制从原句子中复制头实体,头实体的嵌入向量和注意力向量在+2 时刻用相同的方法复制得到尾实体。最终依次产生句子中的所有关系三元组,实现联合抽取。在解码过程中,一个实体可以被多次复制,解决了关系重叠的问题。
在后续的研究中,CopyRL提出句子中的多个三元组之间应该存在顺序关系,并采用了强化学习方法;由于CopyRE 只能复制实体的最后一个单词,难以处理一个实体包含多个单词的情况。文献[81]提出了一种多任务学习模型CopyMTL,CopyMTL 在CopyRE 基础上添加了一个序列标注模块用于实体识别。序列标注得到的实体和复制机制得到的实体进行校对,使得CopyMTL 能够准确识别实体。上述三个模型间的对比如图9 所示。HDP(hybrid dual pointer network)编码器中采用了Transformer,解码器为从左到右的单向LSTM,提升了特征抽取能力;Nayak 等设计了两种新颖的方案来表示三元组,根据两个方案分别设计了不同的解码器,即基于单词的解码器Wdec 和基于指针网络的解码器PNDec,提高了关系三元组之间的交互;SPN(set prediction network)认为句子中的关系三元组应该是无序的,自回归解码器将无序的关系三元组有序生成,增加了模型的负担,因此SPN 采用基于Transformer 的非自回归解码器,并设计基于集合的二分匹配损失函数,一次性产生包含所有关系三元组的集合。
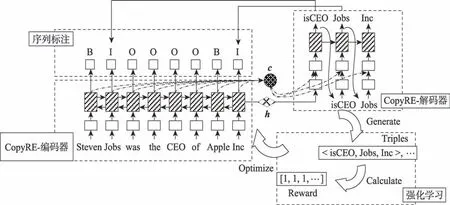
图9 Sequence-to-Sequence 模型对比Fig.9 Sequence-to-Sequence model comparison
基于联合解码的联合抽取模型主要有序列标注和Sequence-to-Sequence 两种方法。序列标注的方法容易实现联合抽取,但真实数据间的关系通常比较复杂,在解决实体嵌套、关系重叠等具体问题时,序列标注的方法需要设计复杂的标注方案,增加了联合抽取的难度;Sequence-to-Sequence 的方法能有效解决关系重叠的问题,但当句子长度较长时,提升了构造具有丰富语义特征向量的难度。
表6 是基于神经网络的联合抽取方法总结。基于共享参数的联合抽取模型将联合抽取分解为不同的子任务,通过构造丰富的子任务特征信息来提升子任务模型的准确性,但子任务间的交互性相对较低;基于联合解码的联合抽取模型使得实体信息和关系信息充分交互,但需要设计相对复杂的解码方法。

表6 基于神经网络的联合抽取模型Table 6 Joint extraction model based on neural network
4 数据集
本章主要介绍联合抽取的常用数据集,主要分为人工标注的数据集和采用NLP 获取的数据集,这两类数据集都被作为有监督数据集进行处理。
4.1 人工标注数据集
人工标注的数据集需要标注员对文本数据进行标注,耗费成本大,整体效率低下,但数据质量高,噪音少,有公认的评价方式,这类数据集的规模通常也较小。
ACE(automatic content extraction)的研究目标是从自然语言数据中自动抽取实体、实体相关事件和实体间的关系类型,其数据来源除英语外还包括阿拉伯语和汉语等。ACE 预先定义了实体间的关系类型,ACE 的任务是识别实体间是否存在语义关系,并进一步判断该语义关系属于哪一种预定义的关系类型。ACE 提供了相应的标注数据集ACE2004 和ACE2005。ACE2004 数据集的实体和关系类型如表7所示,ACE2005保留了ACE2004中的PER-SOC(person-social)、ART(agent-artifact)和GPE-AFF(geopolitical entity affiliation)关系类型,将PHYS(physical)关系类型分为PHYS 和Part-Whole 类型,移除了DISC(discourse)类型,将EMP-ORG(employment-organization)和PER/ORG-AFF(person/organization-affiliation)合并成EMP-ORG。

表7 ACE2004 数据集Table 7 ACE2004 dataset
SemEval(semantic evaluation)会议在自然语言领域受到广泛关注。SemEval-2010 Task 8 侧重于识别名词对之间的语义关系,目的是比较不同关系抽取方法的性能差异,并对未来的研究提供标准的评测方法。SemEval选择9种关系类型:CE(causeeffect)、IA(instrument-agency)、PP(product-producer)、CC(content-container)、EO(entity-origin)、ED(entitydestination)、CW(component-whole)、MC(membercollection)和MT(message-topic),覆盖范围较为广泛。SemEval 提供了8 000 个训练样本和2 717 个测试样本,每个样本存在的关系类型都被标注,但没有标注实体的类型信息。
CoNLL04 数据集提供了1 437 个至少存在一个关系的句子,句子中的实体和关系类型都进行了标注。CoNLL04 数据集包含5 336 个实体,19 048 个实体对(二元关系),存在4 种实体类型和6 种关系类型,具体细节如表8 所示。

表8 CoNLL04 数据集Table 8 CoNLL04 dataset
ADE(adverse drug events)数据集中存在两种实体类型:Drug 和Disease。任务的目的是抽取句子中的Drug 类型实体和Disease 类型实体,并确定Drug 和Disease 的关联性。ADE 数据集来自于1 644 个PubMed 的摘要信息,从摘要中选取至少存在一组实体类型为Drug-Disease 且关系类型为ADE 的句子,ADE 数据集共6 821条,包含10 652个实体以及6 682个关联。
4.2 NLP 获取数据集
通过NLP 获取的数据集,规模较大,迁移性较好,但质量相比人工标注数据集较低。主要有NYT(New York Times)数据集和WebNLG(Web natural language generation)数据集,分别采用远程监督和自然语言生成的方法获取。远程监督将大量语料数据与现有数据库中的关系进行对齐,通过成熟的NLP 工具进行实体标注;自然语言生成方法是从标准数据库中获取关系三元组信息,用自然语言生成技术构造大量包含该关系三元组的句子。
NYT 数据集通过远程监督的方法获得,采集了1987 年到2007 年的纽约时报新闻文章数据共24.9万条,将获得的数据与Freebase 对齐,构造出了118万条句子。过滤出部分噪音数据后,剩余66 195 个句子样本,通常随机选择出5 000 条样本作为测试集,5 000 条样本作为验证集,剩余的56 195 条样本作为训练集,共包含3 种实体类型和24 种关系类型。
WebNLG 通过从DBpedia 中抽取一组三元组并采用自然语言生成方法获得所构造的句子。该数据集共有5 519 条训练集和703 条验证集,包含246 种关系,每个样本由一组三元组和一条标准句子构成,标准句子包含样本中的所有三元组,实验时,研究人员通常会过滤不包含实体的标准句子。
以上数据集的相关信息总结如表9 所示。

表9 实体关系抽取数据集总结Table 9 Summary of entity and relation extraction datasets
5 评测标准及实验
评测标准通常采用精确率()、召回率()和1 值3 个指标。根据机器预测结果和真实情况可划分为真正类(true positive,TP)、假正类(false positive,FP)、真负类(true negative,TN)、假负类(false negative,FN)4 种情况,其构成的混淆矩阵如表10 所示。

表10 混淆矩阵Table 10 Confusion matrix
精确率和召回率的定义公式分别为:

精确率和召回率是一对矛盾的度量,一般来说,精确度较高时,召回率往往偏低;召回率高时,精确率往往偏低。1 值则是基于精确率和召回率的调和平均值,计算公式如下:

由于数据集的不同,实体关系联合抽取的评测方式也有所不同。在NYT 和WebNLG 数据集上,以模型最终抽取的三元组作为评测依据,通常认为三元组中的实体及关系类型都正确时为TP。不同模型在NYT 和WebNLG 数据集上的实验结果如图10、图11 所示。
从图10、图11中可以看出,NovelTagging在NYT 和WebNLG 数据集上的评测1 值相对较低,其采用序列标注的方法实现联合抽取,将实体信息和关系类型信息都存储到统一的标注中,使得标注方案设计复杂,解码器需要直接解码实体和关系类型信息,增大了解码难度。

图10 NYT 数据集上的评测结果Fig.10 Evaluation results on NYT dataset

图11 WebNLG 数据集上的评测结果Fig.11 Evaluation results on WebNLG dataset
Sequence-to-Sequence 方法容易解决关系重叠的问题,例如文献[78]提出的模型CopyRE-One和Copy-RE-Mul,其评测结果优于序列标注模型,但两个模型获得相对较低的1 值。原因是双向LSTM 难以准确识别边界较长的实体信息,尤其是在包含大量边界较长实体的WebNLG 数据集上,CopyRE-One、Copy-RE-Mul 的评测1 值低于其在NYT 数据集上的1值。而SPN模型在NYT 和WebNLG 数据集上都取得了最佳的1 值,分别为92.5%和93.4%,主要有3个原因:(1)Sequence-to-Sequence 方法适合解决关系重叠的问题;(2)采用BERT 编码器、Transformer 架构的解码器,提升模型识别实体边界的准确性,Transformer 解码也使得运行效率有所提高;(3)解码器采用非自回归的方式直接解码得到关系三元组集合,不注重关系三元组的顺序,减轻了解码器负担。
采用实体对映射到关系的方法实现联合抽取的模型,主要难点是解决关系重叠的问题。如文献[47],为了有效解决关系重叠的问题,设计了复杂的注意力机制。另外,RIN模型在两个数据集上的评测1 值也相对较高,RIN 以GRU 为主,但RIN 额外添加了双向LSTM用于命名实体识别和关系抽取两个子任务的交互,从实验结果可以看到这种方法是有效的。
在NYT 和WebNLG 数据集中含有大量EPO、SPO 等关系重叠类型的数据,使得大多数联合抽取模型在这两个数据集上的评测1 值略低。对于采用头实体映射到关系、尾实体方法和采用关系映射到头实体、尾实体方法实现联合抽取的模型,如CasRel和RSAN,这类模型在NYT 和WebNLG 数据集上的评测1 值均较高。主要原因是这类模型采用分解策略有效解决了关系重叠问题,实验结果也佐证了这一判断。另外,在两个数据集上评测1 值相对较高的SPN、ETL-Span和TPLinker等模型,这些模型的编码器均采用了预训练语言模型BERT,进一步说明了预训练语言模型的有效性。
对于人工标注的数据集,实体类型和关系类型的标注质量较高,评测通常有两方面:命名实体识别的1 值,实体的边界和类型都正确则视为TP;关系抽取的1 值,关系类型正确并且与之相关的两个实体边界及类型都正确则视为TP。有的模型在关系抽取评测时并没有考虑到两个实体的类型,如表11 中右上角带“*”的评测结果。在不同数据集上不同模型的评测结果如表11 所示。
从表11 中可以看到,基于特征工程的联合抽取方法Li和Miwa在不同数据集上识别实体和抽取关系的评测1 值相对较低,原因是特征工程需要设计大量特征函数,通过特征工程获得的特征准确度较低。SPTree、Bekoulis和Bekoulis都是基于神经网络的联合抽取模型,在不同数据集上的评测1值相近,评测1 值略高于基于特征工程的模型。这3 个模型都是以双向LSTM 为主要架构,特征提取的能力低于基于Transformer的模型,使得这3 个模型的1 值处于相对较低的水平。Sun和Sun模型在ACE2005 数据集上的关系抽取评测1 值相比SPTree进一步提升,这两个模型分别采用最小化风险训练的方法和构造实体关系二分图的方法,加强命名实体识别和关系抽取两个子任务间的交互,评测结果也说明加强不同子任务之间的交互性能够提升整体的抽取效果。

表11 有监督数据集上评测结果Table 11 Evaluation results on supervised datasets %
采用机器阅读理解方法的模型,如Li和Zhao在ACE2005 数据集上的评测1 值处于相对中等的水平。机器阅读理解的方法,在问题中融入重要的先验信息,并以问答的形式更好地捕捉到问题和文章之间的交互信息,提升联合抽取的性能,但这类方法需要根据识别的实体设计合适的问题。
基于跨度的模型,如文献[49-54]在不同数据集上的评测1 值处于相对较高的水平,尤其是命名实体识别的评测1 值,进一步证明了直接在跨度上建模能有效解决实体嵌套的问题。其中SPAN模型在数据集上的评测1 值最高,原因在于其用多头注意力抽取丰富的跨度表征信息和上下文表征信息。另外,这些模型在特征抽取上均采用预训练语言模型BERT,具备更强的特征抽取能力。Wang改进了Transformer,设计了两种不同的编码器分别编码实体信息和关系信息,实验的评测1 值处于较高的水平。
6 未来研究方向
本文介绍了有监督实体关系联合抽取的各种方法以及相关理论,并进行了实验对比,在常用数据集上进行的实验表明,实体关系联合抽取方法取得了一定的进步,然而现存的联合抽取理论和技术尚有许多局限性,仍面临着许多技术难题和挑战。接下来的研究重点包括以下内容。
(1)篇章级别的实体关系联合抽取
本文介绍的模型大多是基于句子级别的联合抽取,面临的挑战主要是实体嵌套和关系重叠,可以通过设计特殊标注方案或调整抽取顺序的策略解决。而篇章级别的数据处理较为复杂,目前的预训练语言模型如BERT,其输入有最大长度限制。如何在较长篇幅的数据下进行模型训练,如何处理不同句子间的关系信息、不同关系间的关系信息,多个实体共指等复杂情况仍有待解决。另外,对于一些隐藏的关系类型,并不能通过简单的抽取得到,需要进一步根据上下文的信息推理获得。显然将篇章级别的抽取看作一系列单句子抽取的组合是不合理的,如何设计一个行之有效的方案依然亟待解决。
(2)融入多样信息的实体关系联合抽取
本文介绍的模型抽取的三元组大多是静态的,输入句子经过序列编码器后得到的词向量融入了上下文的语义信息,模型主要关注实体信息和预先定义的关系类型信息,而在抽取带有时序信息的实体和实体间的关系时,实体和实体间的关系可能都在动态更新,如何在词向量中有效嵌入时序信息仍有待研究。此外,当句子中包含事件信息时,如事件之间存在因果关系,事件的发展会影响实体和实体间的关系,模型需要同时考虑不同的事件信息以提高联合抽取的准确性。因此,在实体关系联合抽取模型中如何有效融入时序、事件等多样信息是非常有意义的研究课题。
(3)面向中文的实体关系联合抽取
目前面向中文的实体关系联合抽取的研究仍然落后于英文,主要有两个原因:①数据集的缺乏。有监督的中文数据集相对较少,目前存在的中文数据集大多基于特定领域,如金融、医药等,且数据集的规模通常较小。开放领域的有监督中文数据集则更为稀少,缺少公认的评测基准和指标。②中文的复杂多义性。首先,中文没有明确的单元边界,不像英文能够使用空格符对词进行分割,中文也没有明显的词性变换等特征,容易造成边界歧义。其次,中文中一词多义现象普遍,同一词在不同语境下所表达的意思不一致,且一种语义存在多种不同的表达,句式灵活多变。另外,随着互联网的快速发展,词语不断具有新的含义,进一步增强了联合抽取的难度。在设计面向中文的联合抽取模型时需要着重考虑中文的特殊性,因此,面向中文的实体关系联合抽取是一个非常重要的研究方向。
(4)提升实体关系联合抽取的可解释性
当前主流的实体关系联合抽取模型主要基于神经网络,在特征抽取上更优于传统的特征工程方法,减少了人工抽取特征的工作量,但基于神经网络的方法面临着一个棘手的问题——可解释性差。联合抽取模型的性能通常由实验进行验证,但是如果无法理解学习到的特征表示具有何种可解释的含义时,则无法深刻理解模型本身的应用限制。尤其目前模型趋向于复杂化,如何选择网络层数、模型参数大小、模型架构、优化算法以及激活函数等,通常是基于具体实验的效果,并未理解其真实含义,对于联合抽取结果的可解释性不强。如何提升实体关系联合抽取模型的可解释性仍然需要进一步研究。
7 总结
实体关系联合抽取能够从文本中自动识别实体、实体类型以及关系类型,是信息抽取中的核心任务,积极推动了知识图谱构建、智能问答和语义搜索等领域的发展,具有广阔的应用前景。本文对有监督实体关系联合抽取方法进行综述,介绍了四种基于特征工程的联合抽取方法;对于基于神经网络的联合抽取模型,描述了三种基于共享参数的方法和两种基于联合解码的方法;以图表的形式对比了不同模型的优缺点,并对联合抽取常用的七个数据集进行了介绍;在不同数据集上比较了各种方法间的性能差异并进行分析;最后展望了实体关系联合抽取的未来研究方向。
