基于密集连接卷积神经网络的道路车辆检测与识别算法
2022-04-12邓天民冒国韬周臻浩段志坚
邓天民,冒国韬,周臻浩,段志坚
(重庆交通大学交通运输学院,重庆 400074)
0 引言
近些年来,全球各地汽车保有量飞速增长,大量学者对自动驾驶领域展开了深入研究,目标检测成为了自动驾驶领域研究的一个重点。车辆作为目标检测任务中的重要对象之一,在自动驾驶领域有着非常重要的应用价值。随着计算机硬件水平的提升,基于卷积神经网络(Convolutional Neural Network,CNN)的目标检测方法凭借其强大的特征表达能力取得了惊人的成果[1]。Krizhevsky 等[2]提出的AlexNet 结构模型获得2012 年国际视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)的冠军,CNN 随即迎来了历史性的突破,掀起了对深度学习的研究热潮。
目前,基于深度学习的车辆检测识别方法主要分为两类:
一类是两阶段的目标检测算法,此类方法检测准确率和定位精度较高,但缺点是训练速度慢、实时性差,其中代表性的算法有R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]等。Nguyen[6]通过改进Faster R-CNN 算法的特征提取网络,引入上下文感知池化,提高了对小目标车辆和遮挡车辆的检测精度,但检测实时性还有待提升;杨薇等[7]提出了一种改进的Faster R-CNN 车辆实时检测算法,训练时采用多尺度策略,提高了模型泛化能力,但对于复杂环境下排列密集、遮挡严重的车辆检测效果较差。
另一类是一阶段的目标检测算法,这类方法不需要产生候选框,直接预测物体位置与类别,一次检测就能得到最终检测结果,其中代表性的算法有YOLO(You Only Look Once)系列算法[8-11]以及SSD(Single Shot MultiBox Detector)[12]等。Wang 等[13]提出了一种基于改进的YOLOv3-Tiny 的车辆检测方法,加入空间金字塔池化(Spatial Pyramid Pooling,SPP)模块,提高了模型特征提取能力,取得了较高的检测精度,但对于小尺度目标检测效果较差;赵文清等[14]提出了一种基于SSD 的反卷积和特征融合算法,降低了小目标的漏检率,但由于反卷积操作增大了运算复杂度,导致检测速度大幅降低。相较于两阶段的目标检测算法,一阶段的方法检测速度快、误检率低,但缺点是精度偏低、小目标检测效果较差以及对于复杂环境中的车辆检测较为困难。
本文针对上述道路车辆检测算法检测速度与检测精度相矛盾、小目标车辆漏检及复杂环境下检测困难的问题,提出一种基于密集连接网络的道路车辆检测算法。采用改进的密集连接残差网络结构,通过聚类算法对车辆数据集的边界框进行聚类,同时增大网络的检测尺度,并在特征融合阶段添加跳跃连接结构增强网络的特征信息融合,解决网络模型大、车辆检测精度不高和漏检的问题。
1 基于密集连接的主干特征提取网络
本文选用YOLOv4 框架进行改进,YOLOv4 模型的主干特征提取网络CSPDarknet53 是在Darknet53 网络[10]的5 组深度残差结构基础上分别添加跨阶段局部网络(Cross Stage Partial Network,CSPNet)[15]模块得到的,它将特征图的映射划分为两部分:一部分经过深度残差结构强化网络特征提取的能力;另一部分通过跨阶段层次结构与它们融合,在减少了计算量的同时可以保持准确性。对于道路车辆的检测识别,CSPDarknet53 网络中大量的运算参数会使车辆检测速度减慢,并且在数据集样本量较小时易导致过拟合。
1.1 密集连接模块
YOLOv4 模型在特征提取阶段采用5 组深度残差网络结构强化网络的特征提取,当网络层数加深时,解决梯度消失的问题。
图1 所示为YOLOv4 的残差模块结构,残差单元(Res unit)从残差网络(Residual Network,ResNet)[16]中借鉴而来,其核心的表达式为:

图1 残差模块结构Fig.1 Residual block structure

其中:xn表示n层的输出;Hn表示包括卷积、批归一化和激活函数组合在一起的非线性变换。
密集连接卷积网络(Dense Connected Convolutional Network,DenseNet)[17]具有密集型连接结构,如图2 所示。在DenseBlock 中,每个密集连接单元(Dense unit)层的输入都包含了较早层的输出,更好地利用了每一层的特征。
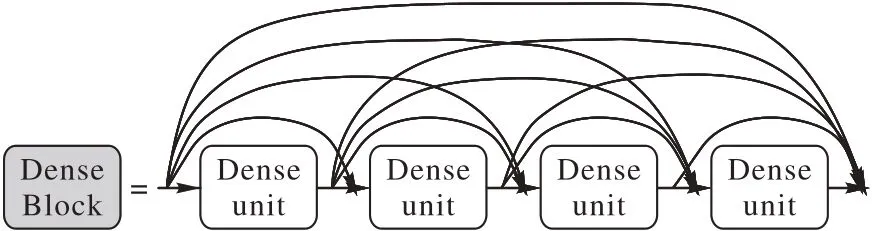
图2 DenseNet密集连接结构Fig.2 Dense connected structure of DenseNet
DenseNet 的核心表达式为:

其中:[x0,x1,…,xm-1]表示将0 到m-1 层输出的特征图进行并联粘接(concat)操作;xm表示m层的输出;Hm表示包括卷积、批归一化和激活函数组合在一起的非线性变换。
本文借鉴DenseNet 的密集连接结构,在原始的残差结构基础上提出具有更强特征提取能力的网络,称为DRNet(Dense Residual Network),如图3 所示。采用DRBlock 代替网络原有的ResBlock,通过残差组件单元进行特征提取,使网络训练更加容易,在每个残差组件之间采用密集连接方式,以加强特征复用,强化对浅层复杂度低的特征的利用。

图3 DRNet结构Fig.3 Structure of DRNet
1.2 跨层连接结构
根据CSP 模块结构与DRNet 结构的特点,设计以下两种不同的CSP 模块:CSPBlock-B 和CSPBlock-C,如图4 所示。
由图4(b)与图4(c)的对比可知,结构B 先将两个部分的特征进行并联粘接,之后再输入到1×1 卷积的过渡层,这样做可以使大量的梯度信息被重用,有利于网络的学习。结构C 则是先将部分的特征信息输入过渡层,然后再进行并联粘接操作,采用这种做法损失了部分梯度信息的重用,但由于1×1 卷积层输入维度小于结构B,使得运算复杂度降低。图4(a)为原始的跨阶段局部模块结构,可以看出,结构A 同时采用了上述两种结构中的过渡层,学习能力更强,但提高了运算复杂度。为提升模型的运算效率,本文选用结构B 作为新的跨阶段局部模块。

图4 三种不同的CSPBlockFig.4 Three types of CSPBlock
1.3 深度残差结构
综合考虑道路车辆检测的实时性需求与检测精度,采用6 组深度残差结构强化主干网络的特征提取能力。分别将6组深度残差结构中残差组件数量设置为1、2、3、3、3、2,提出一种运算复杂度相对较低、参数量相对较少的主干特征提取网络CSPDRNet53,网络模型结构如图5 所示。

图5 CSPDRNet53结构Fig.5 Structure of CSPDRNet53
相较于CSPDarknet53 中包含5 组深度残差结构以及1、2、8、8、4 个残差组件的较为复杂冗余且参数量过多的网络,CSPDRNet53 降低了算法的参数量和运算复杂程度,提升道路车辆检测识别效率,同时能一定程度上避免过拟合。
2 结合跳跃连接的多尺度特征融合网络
2.1 跳跃连接结构
YOLOv4 模型在多尺度特征融合阶段采用路径聚合网络(Path Aggregation Network,PANet)结构[18],如图6 所示。通过自上向下的特征融合,将高层的特征信息通过上采样的方式传递融合,对整个特征金字塔强语义特征进行增强,得到进行预测的特征图;通过自下向上的特征融合,用下采样的方式将低层的强定位特征传递上去。

图6 PANet结构Fig.6 Structure of PANet
PANet 结构中1、8 节点只存在一个输入边,没有不同特征信息的融合,因此删除对特征融合网络贡献较小的1、8 节点。除此之外,为使网络在不增加太多成本的情况下融合更多的特征信息,在输入特征图和输出特征图大小相同的两个节点之间添加跳跃连接结构,通过强化网络的特征信息融合,增强网络的表征能力,如图7 所示。
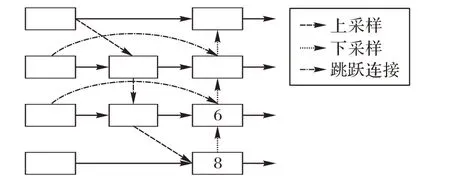
图7 引入跳跃连接结构的特征融合网络Fig.7 Feature fusion network introduced by skip connection structure
2.2 多尺度特征检测
在特征检测过程中,原模型通过8 倍、16 倍、32 倍下采样的特征图对目标进行检测。8 倍下采样特征图的下采样倍数低,特征感受野较小,适合检测小尺度的物体;32 倍下采样的特征图具有较大的特征感受野,适合检测大尺度物体。
为提高算法对小目标检测精度,本文将特征检测网络的3 尺度检测改进为4 尺度检测,将CSPDRNet53 主干特征提取网络中第3 个深度残差结构输出的104×104 特征图与3 次上采样后的特征图进行并联粘接处理得到第4 个特征检测尺度,并形成新的特征金字塔网络。4 尺度检测提高了对小目标车辆的检测精度,同时降低车辆的漏检率,改进后算法结构如图8 所示。
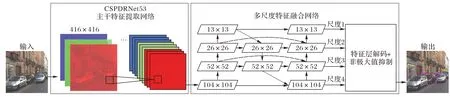
图8 提出的DR-YOLOv4算法结构Fig.8 Structure of proposed DR-YOLOv4 algorithm
3 先验框尺寸
YOLOv4 中先验框的尺寸是由COCO(Common Objects in COntext)数据集通过聚类得到,但考虑到COCO 数据集中包含的目标种类有80 类,检测目标的长宽比差别也较大,不适用于道路车辆检测。在道路车辆检测任务中目标车辆的长宽比是相对固定的值,不能直接使用模型原本的先验框尺寸,需对所用训练集中的标注框进行聚类并重新分配。本文选用K-Means++聚类[19]方法计算聚类,基本步骤如下:
1)从数据集中随机抽取一个点作为初始的聚类中心。
2)计算每个样本与已有的聚类中心之间最短距离D(x)。
4)重复步骤2)~3)选出所有的聚类中心。
5)用传统的K-Means 算法对选出的聚类中心聚类。
DR-YOLOv4 算法通过4 个特征检测尺度对车辆目标进行检测,为每个特征检测尺度分配3 个先验框,每个特征检测尺度中的每个单元格通过3 个先验框分别对3 个边界框进行预测,因此需要12 个先验框。利用K-Means++聚类算法对车辆数据集中标注框的长宽进行聚类。
根据聚类结果得出更新后的先验框大小分别为:(13,28)、(22,47)、(32,77)、(45,60)、(46,114)、(46,193)、(72,96)、(78,145)、(92,191)、(97,257)、(109,392)、(127,204)。相比YOLOv4 原本的先验框,根据车辆数据集聚类得到的先验框尺寸更符合训练集中道路车辆的长宽比,使用更新后的先验框对车辆数据集进行训练能够使得定位更加精确。
4 实验与结果分析
4.1 实验环境
本实验的硬件环境为Windows10 64 位操作系统,Intel Core i7-8700K CPU @ 4.30 GHz 处理器,16 GB 内存,NVIDA GTX 1080Ti 显卡,8 GB 显存。软件环境采用Darknet 深度学习框架[20],相较于其他深度学习框架,Darknet 具有安装速度快,易于安装的独特优势;整个框架完全由C 语言实现,不存在任何的依赖项;支持CPU 和GPU 计算,使用者可以根据硬件条件灵活切换;移植性非常好,Darknet 框架部署到机器本地非常简单。
4.2 实验数据集
选用KITTI 数据集[21]和BDD100K(Berkeley DeepDrive)数据集[22]中的图像作为本实验车辆检测模型的数据。KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,包含市区、乡村和高速公路等场景采集的真实图像数据;BDD100K 数据集由伯克利大学人工智能实验室发布,数据集涵盖了6 种不同天气、6 种不同场景以及白天、黄昏、夜晚三种时间阶段的复杂图片。数据集部分样本如图9所示。

图9 部分样本示意图Fig.9 Schematic diagram of partial samples
首先从KITTI 数据集的2D 目标检测数据集中选取7 481张图片作为基础实验数据集,其中6 000 张图片作为训练集,742 张图片作为验证集,739 张图片作为测试集。数据集共含 有Car、Van、Truck、Tram、Pedestrain、Person(sit-ting)、Cyclist、Misc 这8 个类别,将数据集按照VOC(Visual Object Classes)数据集的格式进行整理,并删除实验不需要数据的标签类别,仅保留实验所需的3 个类别:Car、Van、Truck,共计32 750 个标注信息。最后从BDD100K 数据集中挑选7 000张复杂环境图片作为扩展实验数据集,其中5 000 张图片作为训练集,1 000 张图片作为验证集,1 000 张图片作为测试集,保留实验所需的3 个类别:Car、Bus、Truck。
4.3 实验结果分析
4.3.1 特征提取网络实验
本文方法在特征提取网络进行三处改进,分别是密集连接模块、跨层连接结构及深度残差结构。为探究其对模型整体性能的影响,针对特征提取网络改进方案进行对比实验。
由表1 可知,融合密集连接网络后,导致模型运算量增加,检测速度有所下降,但同时增强了模型对浅层特征的复用,提升了一定的检测精度;在跨层连接结构改进后,由于损失了部分梯度信息复用,模型均值平均精度(mean Average Precision,mAP)降低了0.06 个百分点,检测速度有所提升;在对模型深度残差结构进行简化后,模型精度降低了0.97个百分点,检测速度上升了10.2 frame/s;最后,同时采用上述三种特征提取网络改进方案后,模型精度较原模型有所下降,检测速度达到了51.39 frame/s。

表1 不同特征提取网络对模型性能影响对比Tab.1 Influence comparison of different feature extraction networks on model performance
4.3.2 特征融合网络实验
在模型的特征融合网络,本文采用跳跃连接结构和多尺度特征检测两种方案对其进行改进。通过对两种方案的对比实验,验证其对模型性能的影响。
由表2 的改进方案对比实验可知,通过引入跳跃连接结构,强化了网络特征信息之间的融合,在提升精度的情况下,损失了一定的检测速度;在多尺度特征检测改进后,由于采用4 尺度进行检测,使得模型整体结构更为复杂,运算量增加,检测速度下降了5.85 frame/s,但采用4 尺度对车辆目标进行检测,有效降低了车辆漏检率,并提升了整体检测性能,检测精度提升了0.57 个百分点;在同时采用两种改进方案后,模型损失了一定的检测速度,但检测精度达到了98.09%。

表2 不同特征融合网络对模型性能影响对比Tab.2 Influence comparison of different feature fusion networks on model performance
4.3.3 先验框分配策略实验
原模型为每个特征检测尺度分配3 个先验框,以此适用于不同大小的检测目标。采用模型默认的先验框分配策略不一定适用于道路车辆数据集,因此需要对模型的先验框重新进行分配。本文在特征检测部分使用4 个特征检测尺度,其中13×13 特征图具有最大的感受野,适合检测大目标物体,分配最大的几个先验框;104×104 特征图分配最小的先验框;26×26 和52×52 特征图分配中等大小的先验框。为了验证先验框分配策略对模型性能的影响,针对不同特征检测尺度分配不同数量的先验框,探究最佳的分配方案。由于采用4 个特征检测尺度,因此将先验框总数控制为12。
由表3 的分配策略对比实验可知,不同先验框分配策略会对模型的性能有一定的影响,当为13×13 特征图分配4 个先验框时,模型的检测精度和检测速度均有所下降,这是因为训练集中大目标物体相对中小目标物体要更少,分配更多的先验框反而导致其他检测尺度训练难度增加;当13×13 特征图少分配1 个先验框,52×52 特征图多分配1 个先验框时,模型的检测精度与速度都达到最优,可见训练集中,中等偏小目标占比最大,大目标占比最小,合理地分配降低了模型的训练难度。根据实验结果,将聚类得到的12 个不同大小的先验框,分别按照2、3、4、3 的先验框分配策略,分配给4个特征检测尺度。先验框按照分配策略重新分配后结果为:将尺寸为(97,257)、(109,392)的先验框分配给13×13 特征图;(46,193)、(92,191)、(127,204)先验框分给26×26 特征图;(45,60)、(46,114)、(72,96)、(78,145)先验框分给52×52 特征图;(13,28)、(22,47)、(32,77)先验框分给104×104特征图。

表3 不同先验框分配策略对模型性能影响对比Tab.3 Influence comparison of different anchor allocation strategies on model performance
4.3.4 模型结构改进实验
为探究主干特征提取网络改进、特征融合网络改进以及先验框尺寸聚类与分配三种综合改进方案对模型整体性能的影响,构建8 组不同的实验方案对网络的检测精度和速度进行对比分析,实验结果如表4 所示。

表4 不同实验方案对模型性能影响分析Tab.4 Analysis of influence of different experimental schemes on model performance
由实验B 可知,在对特征提取网络进行简化后,模型mAP 下降了0.48 个百分点,检测速度较原始模型有所上升;实验C 对特征融合网络改进后,模型获得了98.09% 的mAP,Car 作为数据集中包含小目标最多的类别,检测精度比Van 和Truck 提升明显,检测速度则随着模型结构复杂化有一定降低;实验D 对模型的先验框进行维度聚类并重新分配后,模型检测精度提升了0.55 个百分点,检测速度也略有提升,不难看出先验框聚类及再分配可提升模型的检测性能;通过实验H 可知,同时使用三种改进方案时,在检测速度上比传统YOLOv4 高出2.33 frame/s,获得了48.05 frame/s 的检测速度,同时mAP 达到了98.21%,较原始模型提升了0.8个百分点,模型结构改进后在检测精度和速度上均有所提升。
通过以上改进实验可知,DR-YOLOv4 算法将先验框根据特征检测尺度由小到大按照2、3、4、3 个的策略进行分配;设计简化的跨阶段局部模块结构和6 组密集连接的深度残差结构,其中残差组件数量分别为1、2、3、3、3、2 个;在特征融合阶段引入跳跃连接结构并采用4 尺度检测。图10 所示为模型训练过程中的平均损失收敛曲线,当模型迭代次数达到14 000 时,学习率由初始的10-3下降到10-4;当模型迭代次数达到16 000 左右时,损失值在0.9 左右上下浮动,此时的学习率降低为10-5,并且在16 000 至18 000 次迭代过程中损失值无明显下降,平均损失收敛曲线趋近平稳。
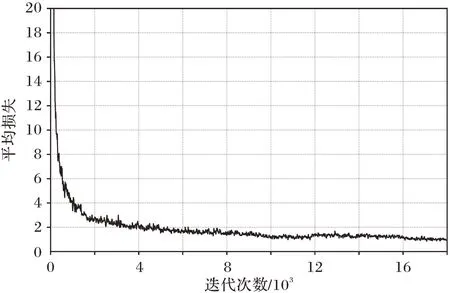
图10 本文算法平均损失收敛曲线Fig.10 Average loss convergence curve of proposed algorithm
表5 中显示了改进后模型与不同目标检测模型在KITTI数据集上的测试结果。DR-YOLOv4 算法在检测速度方面略逊色于SSD300,但仍以48.05 frame/s 的速度达到了实时检测的效果,并在检测精度方面以98.21%的mAP 优于其他的目标检测算法。

表5 不同目标检测模型在KITTI数据集上效果对比Tab.5 Comparison of effects of different target detection models on KITTI dataset
为进一步验证模型在复杂恶劣的环境中对车辆目标的检测效果,本文选取包含各种困难样本的BDD100K 数据集对模型进行训练和测试,由表6 的测试结果可以看出,改进后的模型在BDD100K 数据集上的检测精度与检测速度方面均优于原始模型。

表6 模型改进前后在BDD100K数据集上测试结果Tab.6 Test results on BDD100K dataset before and after model improvement
由图11 可以看出,本文算法在KITTI 数据集上的检测效果良好,在有遮挡及强光照的环境仍然具有很好的检测能力,可以精准地对车辆进行分类。在BDD100K 数据集的夜间环境中,存在遮挡、小目标及反光等因素干扰时,本文算法也能获得较好的检测效果,对道路车辆的检测具有良好的鲁棒性。

图11 部分检测结果示意图Fig.11 Partial schematic diagram of test results
5 结语
本文提出了一种基于密集连接网络的道路车辆检测算法DR-YOLOv4,采用改进的密集连接的残差结构和跨阶段局部模块结构及6 组深度残差块的主干网络;特征融合阶段通过采用多尺度特征检测和跳跃连接方式加强特征信息的融合;并对重新生成的先验框进行分配策略实验。实验结果表明,DR-YOLOv4 模型在KITTI 数据集上取得了98.21%的均值平均精度与48.05 frame/s 的检测速度,具有较好的检测精度和实时性,对小目标车辆的检测效果良好。最后为了验证模型在复杂环境中对车辆目标的检测性能,在BDD100K数据集上进行训练和测试,结果表明,改进后的模型对复杂环境下的车辆目标也具有良好的检测效果。
