互联网数据挖掘与分析平台设计与实现
2022-04-11李翔坤

摘 要:面对移动互联网中庞大的数据量,如何进行挖掘和可视化的分析是当前大数据研究的一个热点。本文搭建了一个互联网数据挖掘与分析平台,首先采用基于Scrapy框架搭建的爬虫系统从互联网络爬取了大量新闻数据与招聘数据,通过Sphinx和CoreSeek经过googlediffmatchpatch算法去重,最后利用R语言对这些数据进行可视化分析,从而为制定决策提供更好的依据。
关键词:互联网数据;R语言;Scrapy;可视化分析
随着社会信息化程度的不断提高,作为信息化的产物目前各种APP和网站层出不穷,然而每一款优秀的APP或者网站其后台必然存在庞大的数据量。如果能够对这些数据进行很好的挖掘与分析以及将其可视化,帮助决策者更好地掌握自己的产品和客户的动向,这毫无疑问会提升其产品在市场竞争上的生命力。因此数据挖掘和数据可视化分析一直是数据分析方向的一个研究热点。R语言作为数据分析的工具,已经被越来越多地用在数据的可视化分析中。由于R语言是开源的,R的扩展包非常庞大又功能齐全,在这些丰富的扩展包的帮助下,让数据的可视化分析变得简单易行。因此,本文从互联网爬下来的大量数据的分析与可视化采用R语言来实现。
1 数据的获取
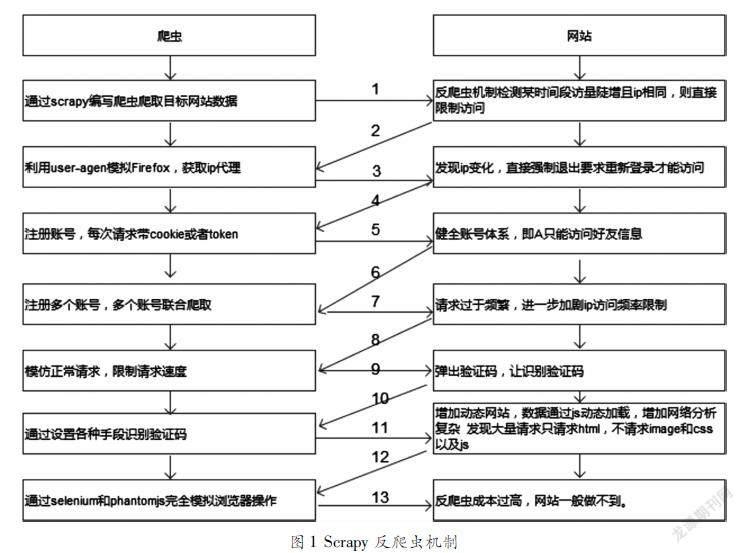
在做数据分析与可视化工作时为了更加准确地说明问题,往往是需要大量实时可靠的数据作为基础的,数据获取是进行数据分析与可视化的第一个阻碍,尤其是像新闻和招聘这类数据,单纯靠手工收集获取难度巨大,这时可行的办法是搭建爬虫系统来自动爬取实时的互联网数据,作为数据分析与可视化的基础。然而现在网站大多都存在反爬虫机制,Scrapy框架编写的爬虫系统在对互联网网站数据进行爬取时,针对目前网站常用的反爬机制会采取一些措施。它的工作流程如图1所示。因此本文选取Scrapy爬虫系统进行爬取新闻数据和招聘数据。
2 除去重复数据
爬虫是通过URL来定位资源的位置进行数据爬取的,这就会导致一些问题的出现,当然这些问题本身也是不可避免的,因为不同的URL对应的数据可能存在高度的相似性,尤其像新聞信息这样的数据。为了保证后期数据可视化时效果的合理性与科学性,必须在数据进行可视化之前对爬取的数据去除冗余。本文采取的做法是,在对新爬取的数据进行入库之前,需要拿新爬取的数据与数据库中已存在的数据进行文本差异性比较,如果在比较时发现两条数据差异性比较小则删除新爬取的数据禁止其入库,从而避免数据冗余。
本文采用googlediffmatchpatch算法对数据进行差异性鉴定,不是直接用一条数据的全部内容参与差异性分析,而是在比较之前对数据进行关键词提取,如利用Pathon中文分词组件Jieba分词,找出最能代表某条数据的全部关键词,通过比较两条数据的关键词的差异性来间接地确定两条数据的差异性,从而提高了鉴定的效率。
googlediffmatchpatch算法的思想:使用两条待比较的数据其中的一条为模板,把作为模板的一条进行复原,统计出复原的步数,再计算出复原成模板最坏情况下的步数,用最坏情况下复原成模板的步数减去实际复原所用的步数,再除以最坏情况下的步数即为两个带比较文本的相似度。每个步骤只能做“保持不变”“插入”或者“删除”操作。
3 数据的可视化分析
完成了数据的获取以及对获取的数据进行挖掘与分析工作之后,就可以进一步对数据进行可视化分析。可视化的分析结果能够显著地为决策者提供一定的支持。之前爬取的数据已保存在MySQL数据库中,所以在利用RStudio工具对数据库中的数据进行分析之前,需要先设置数据源然后利用R语言中的RODBC包提供的相关接口与MySQL数据库建立连接。最后就是根据要达到的可视化目标,编写相应逻辑的SQL语句来获取数据库中的数据,之后利用R语言丰富的扩展包所提供的相关函数,把获取的数据转化成R语言可视化所要求的数据格式便于可视化分析,至此完成对数据可视化分析的工作。
本文主要采用R语言词云图对新闻进行了可视化分析,利用饼图、条形图和绘制地图等方式对招聘信息进行了可视化分析。
3.1 新闻数据词云图
图2采用词云的方式对爬取的所有新闻数据共同提到的关键词汇进行可视化,当鼠标移动到相应的词汇时,将会显示该词汇一共被提及的次数。本文利用wordcloud2这样一款用于从文本生成词云图而提供的工具包进行词云的生成。
3.2 招聘数据城市分布图
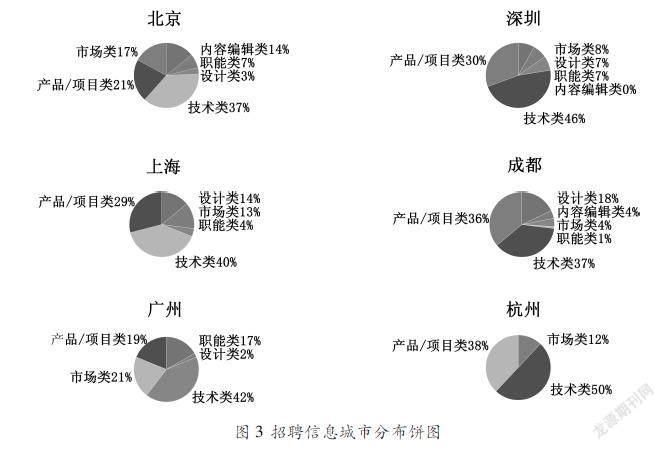
图3采用饼图的形式,展示了数据库中招聘岗位数量最多的前六位城市的各类岗位的分布情况。利用R语言提取数据和绘制饼图的代码如下所示:
library(RODBC)
par(mfrow=c(3,2))
myconn=odbcConnect("MySQLODBC","root","")
works<sqlQuery(myconn,"select catalog, count(recruitNumber) as recruits from newsanalysis_tencent where workLocation='北京' group by catalog order by recruits")
city<works['catalog']
recruits<works['recruits']
recruits<as.matrix(recruits)
recruits<as.numeric(recruits)
city<works['catalog']
city<as.character(unlist(city['catalog']))#將数据框类型转换为字符型
pct<round(recruits/sum(recruits)*100)
lbls2<paste(city," ",pct,"%",sep="")
pie(recruits,labels=lbls2,col=rainbow(length(lbls2)),radius=1.1,main="北京")
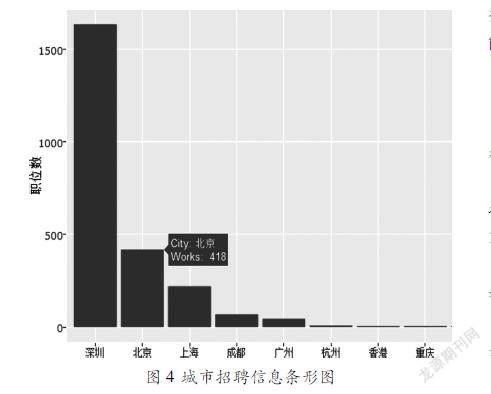
图4采用条形图的形式对数据库中每个城市招聘职位总数进行可视化。当鼠标移动到对应城市的条形图上时会自动显示该城市目前的招聘职位总数。利用R语言提取数据和绘制条形图的代码如下所示:
library(RODBC)
library(ggplot2)
library(plotly)
library(dplyr)
myconn=odbcConnect("MySQLODBC","root","")
city<sqlQuery(myconn,"select distinct workLocation from newsanalysis_tencent order by workLocation")
count<sqlQuery(myconn,"select count(recruitNumber) as count from newsanalysis_tencent group by workLocation order by workLocation")
city<cbind(city,count)
city$workLocation<reorder(city$workLocation,city$count,function(x){mean(x)})
city<arrange(city,desc(count))
#取前8名
City<city$workLocation[1∶8]
Works<city$count[1∶10]
p<ggplot(data=city[1∶10,],aes(City,Works))+geom_bar(fill='red',stat="identity")+labs(x="城市",y="职位数",title="各地方岗位数量")
p<ggplotly(p,width=672,height=480)
本文基于R语言对比较有代表性的新闻数据和招聘数据进行了可视化分析,并对分析过程中需要注意的重要流程做了详细的分析与说明。用R语言代码演示了新闻数据对应的云图以及招聘数据对应的饼图、条形图、城市分布图的完整绘制过程。R语言是既能处理海量数据,又能提供几乎整个统计领域的所有前沿算法的强大的数据可视化工具,下一步将对爬取的互联网数据进行更深入的挖掘,并采用R语言构建一个数据分析和可视化的平台,能进行更强大的数据挖掘分析和可视化能力。
参考文献:
[1]刘璐,等.基于topk显露模式的商品对比评论分析[J].计算机应用,2015,35(10):27272732.
[2]孟诗琼,孟诗瑶,尹志.基于R语言的汽车消费数据挖掘及可视化方法[J].宁波工程学院学报,2015,27(4):1723.
[3]杨霞,吴东伟.R语言在大数据处理中的应用[J].科技资讯,2013(23):1920.
[4]刘培宁,韩笑,杨福兴.基于R语言的Net CDF文件分析和可视化应用[J].气象科技,2014,42(4):629634.
[5]孙歆,戴桦,孔晓昀,赵明明.基于Scrapy的工业漏洞爬虫设计[J].信息安全与技术,2017.8(1):6671.
作者简介:李翔坤(1978— ),女,汉族,辽宁营口人,硕士,副教授,研究方向:数据存储、数据挖掘及应用。
