DAST开发技术设计与分析
2022-04-09王宁周云才
王宁 周云才

摘要:DAST作为自动化安全测试工具,是目前应用最广发、使用最简单的一种web应用安全测试方法,评价其优劣的重要一点就是发现漏洞的能力,而发现漏洞的前提是DAST前期爬虫能爬取到的web资源多少,爬取页面的能力越强,爬取到的资源越多,可发现漏洞的概率也将会大大提升。文章将从任务模块、扫描模块和爬虫模块三大核心模块出发,讲解DAST的实现原理、系统架构、核心处理机制,同时介绍了开发过程中碰到的问题和解决思路。
关键词:动态应用程序安全测试;黑盒测试;动态爬虫; 扫描引擎; 漏洞扫描
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)06-0065-03
开放科学(资源服务)标识码(OSID):
1 概述
DAST全称为动态 web 应用程序安全测试,是一种基于黑盒式安全测试的技术,是目前国内应用最普遍、使用最简单的一种动态 web 应用安全测试的方法,安全工程师常见的测试工具有诸如AWVS、AppScan 等,这些都是基于DAST原理的测试产品[1],DAST作为自动化安全测试工具,评价其优劣的重要一点就是发现漏洞的能力,而发现漏洞的前提是DAST前期爬虫能爬取到的web资源多少,爬取页面的能力越强,爬取到的资源越多,可发现漏洞的概率也将会大大提升,随着互联网的开放性和自由性使得黑客更容易获取到敏感信息,造成网络安全问题的发生[2]。
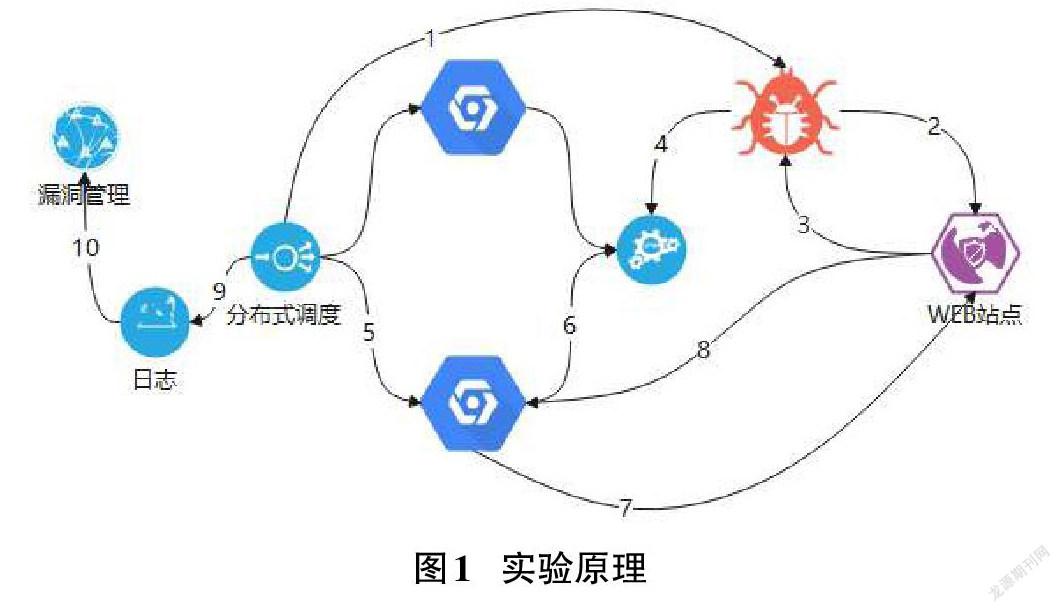
2 DAST实验原理
2.1 主要过程
通过爬虫搜索来搜寻整个web的应用架构,发现一个被检索web 应用程序包含了多少个目录,多少个网站,页面中所有元素都为参数;根据爬取的结果,对已经发现的网站页面和参数重新根据规则内容组装网站的结构,发送一个修改后的HTTP Request 进行了袭击尝试;通过对Response返回内容的准确性进行了分析和判断,来验证其中是否有安全漏洞。
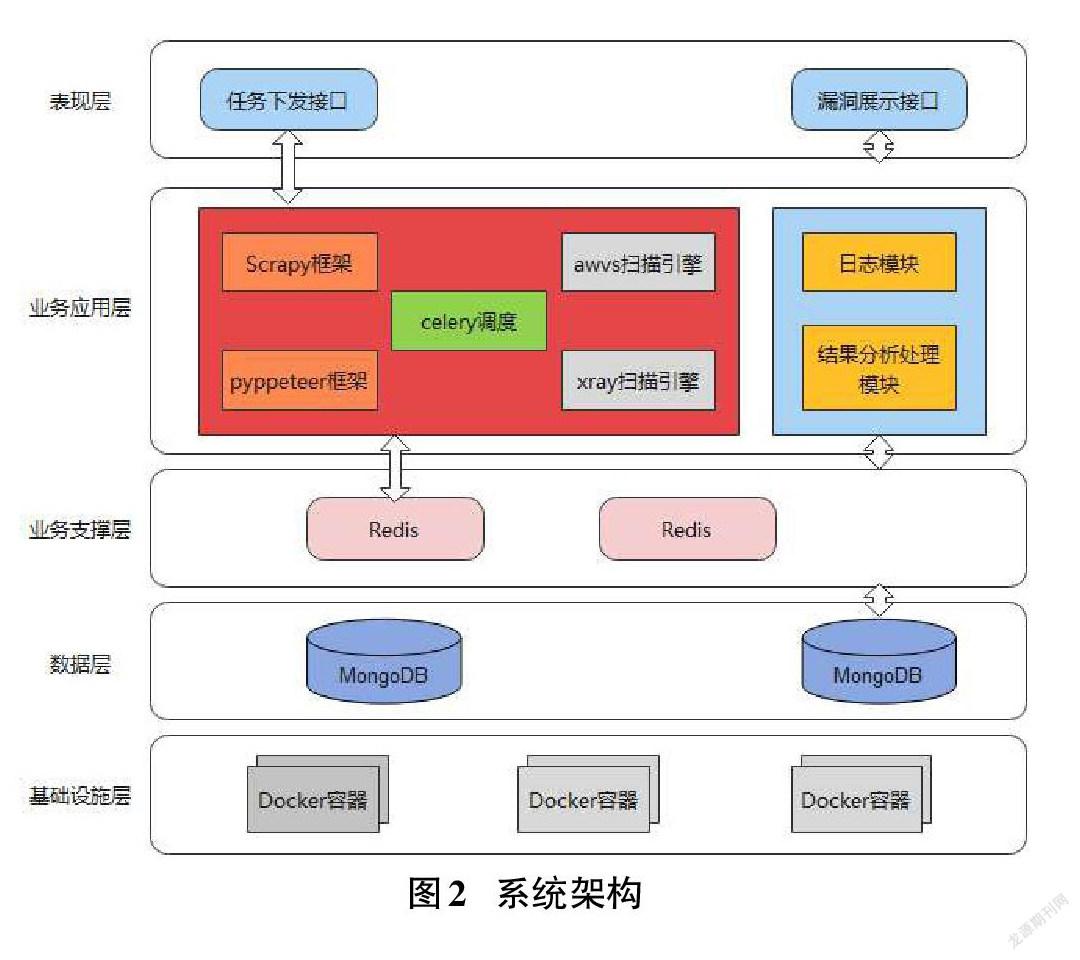
2.2 系统架构
任务下发接口:在bs2系统中填写相应待测域名及必要信息点击下发或通过API接口提交。
漏洞展示接口:测试完成后相应漏洞信息会在bs2中详细展示或通过API接口获取结果详情。
Celery任务调度:Celery架构主要由消息中间件(message broker)、任务实时执行消息单元(worker)和对每个任务消息进行实时执行的消息结果(task result store)等部分共同结合组成,可以大量处理实时异步信息。
Scrapy:Scrapy是一个快速的高级web crawling和web scraping框架,用于抓取网站并从其页面中提取结构化数据。
Pyppeteer:Pyppeteer是Puppeteer的Python版本,Puppeteer语言是 google 基于 node. js 进行开发的一个软件,可以通过Chrome浏览器的API以JavaScript代码对Chrome进行简单操作,用于爬虫来完成对Web 程序的数据爬取和 Web应用程序的自动检索测试。其API极其完善,功能非常强大。
awvs、xray扫描引擎:目前主流知名的web漏洞扫描器[3]。
Docker容器[4]:是一个基于开源软件应用程序的软件容器开发引擎,完全采用开源沙盒架构机制,相互之间没有任何接口。不依赖任何语言、框架包括系统。
3 核心模块
3.1 任务调度模块
本项目将Celery分布式系统作为一个整体性的任务调度,它作为分布式任务团队的异步处理框架,能够使得任务的执行过程完全独立于主程序,甚至能够分配给别人去运行。Redis为Celery的broker,主动扫描、被动扫描、爬虫、信息收集共4个节点的任务执行单位 worker 并发运行在Celery節点中,MangoDB为节点的任务执行结果存储 task result store。周期地获取url,从url相关的附属信息中判断该url即将进行的任务状态,并根据任务状态分配进行相应的动作,若没有新的扫描url则等待。对于一些爬虫引擎的分布式调度阶段可能遇到的问题,在具体看到单个 browser 如何来管理自己所对应 tab 的时候,因为Chromium的启动和关闭成本非常大,远远超过了标签网页 tab 的启动和关闭,而且只有让 browser 长时间驻留,才可将Chromium服务化,为了达到这个目的,在执行时,会涉及browser对tab动态管理的情况,本文主要采用的方法是 Pyppeteer,因为CDP中所有相关的操作均为异步,那么 browser 对 tab 的各种动态加权或者增减其实也就是等价于协工程任务的动态性增减。
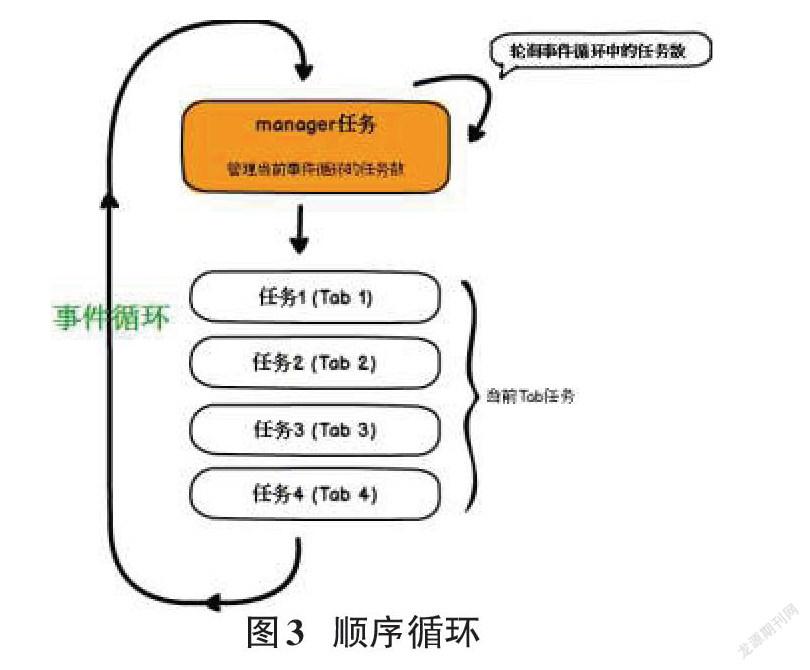
对于这个问题目前的解决方案为:首先,要控制单个的browser能同时处理的tab页面的阈值,因为单个browser其实是一个处理进程,而且在设置的最大tab数的数量过多时,会导致维持多个websocket的连接,当使用者的单个处理进程逻辑较复杂,单个处理进程的CPU占用就很有可能会达到一定的占用极限,相关的处理任务也可能会被直接阻塞,效率就可能会开始有所谓的下降,某些tab页面甚至会由于超时自动关闭退出。所以单个的browser能同时处理的tab页面必须控制到一个固定的阈值,这个阈值需要依靠CPU的占用情况及具体性能来决定。实现这种设计方法的主要目标之一就是通过自动创建一个新的事件任务循环,判断当前的多个事件任务循环过程中的事件任务执行次数与最大任务阈值之间的最大差值,往其中一个循环新增的事件任务执行次数增加即可。同时,因为我们可能开启了一个事件处理循环后对一个主运行进程的事件阻塞,我们可能需要自行监控一个特定时间点,该循环的事件运行也必须保证它本身是异步的,我们可能需要自行创建一个从它自己所在的一个事件处理循环中发出去向自己和它所在这个地区的异步事件并在循环中自行添加一个异步任务,图3中所显示的事件就是上文提到的运行顺序和事件循环中的运行样式截图。
3.2 扫描引擎模块
本項目使用的是开源的awvs、xray两款主流漏扫来配合实现相关的扫描功能[5]。任务下发处提供主动扫描、被动扫描两种方式,被动扫描的话是通过xray本身以被动方式运行,返回给前端代理的ip+port,此方式是便于安全人员自己使用及业务开发人员开发过程中自我进行相应安全检测,xray独立运行,结果会返回到前端展示。
主动扫描是以AWVS为主,AWVS轮询检测到扫描请求时,会创建新的扫描任务,同时将流量代理到xray的设置模式,与xray进行同步扫描,结果处理模块会等待两个扫描器全部完成扫描后对结果进行格式统一、去重等处理,最后完成入库,由前端进行漏洞展示。
3.3 爬虫模块
爬虫的整个模块作为Celery中的一个worker单元,以Scrapy框架为核心[6],通过Scrapy本身的spiders、engine、downloader等中间件来实现整个的爬虫,而单靠scrapy无法实现复杂的动态爬虫,所以在原有的下载器中间件管理器列表中加入了Pyppeteer来辅助实现动态爬虫。
首先可以通过调用start_requests()接收前端下发任务信息的数据库,从而获取相应信息生成第一个初始请求URL,并且指定一个parse方法的回调函数;在parse方法的回调函数中,解析响应出的内容并返回对象,在这些请求中还会包含一个回调事件处理这些响应;Scrapy Engine在其中作为引擎,负责其他所有中间件的信号、通讯、数据的传递等,生成的requests通过它发送给Downloader下载器去请求下载资源[7];在Downloader下载器中有下载处理器和下载器中间件管理器,其中下载处理器对所有引擎发送过来的requests进行处理,下载器中间件管理器会按照上图顺序自上而下处理,在最下方添加了Pyppeteer用来处理网页中的事件,引擎将获取到的Response交给Spider来处理,并获取Spider解析后的request;只要有新的request,Scrapy的Engine与Scheduler模块就会重复运转,直到任务队列中没有新增为止。
整个的爬虫模块中最为重要的一个是处理动态爬虫的部分。动态爬虫作为漏洞扫描的前提,对于web漏洞发现有至关重要的作用,先于攻击者发现脆弱业务的接口将让安全人员掌握先机。即使你有再好的payload,如果连入口都发现不了,后续的一切都无法进行。
随着静态网站服务前端设计框架的广泛使用越来越多,网页内容对于网页爬虫也可能变得越来越不友好,在不断地考虑如何重新进行网站服务端网页渲染时,vue等前端框架可能会直接让一些静态网页爬虫完全的消失效[8]。在puppeteer和Chromium项目经历了不断迭代后,新增了很多关键功能,Headless模式现在已经能大致胜任扫描器爬虫的任务。所以我们果断选择了py.ppeteer(采用python实现的puppeteer非官方版本)来实现动态爬虫功能。 爬虫在爬取页面时,可能会被意外导航请求中断,造成漏抓。所以除了和本页面相同url的导航请求外,其余导航请求都应该被取消。避免造成漏抓,面对重定向需要根据具体情况来区别对待。
静态爬虫(如Scrapy等)通过解析form节点手动建立POST请求的方式,在现在已经稍稍落伍。当前互联网的前端处理逻辑越来越复杂,复杂的JS逻辑处理充斥在页面执行各个部分(如填写表单、发出POST请求等),最后的请求内容格式和静态构造差别巨大,总的来说,静态爬虫无法满足大部分爬取需求,所以爬虫必须模拟正常的表单填写以及点击提交操作,从而让JS发出正确格式的请求,这样才可以做到准确爬取。
表单的提交也有一些重要问题需要特别注意,如果直接点击一个form这个表单的提交按钮,那么就可能会直接导致当前的表单页面重载,使用者可能不完全希望当前的表单页面被重载,为避免这种情况,在hook前端导航请求之外,还需一个target属性设置在form节点,指向一个隐藏的iframe,若想成功提交表单,还得正确触发表单的submit操作。另外,不是所有的前端内容都有规范的表单格式,或许有一些form连个button都没有,所以为了保险起见,只能尽可能地多尝试几种方法。
4 总结
4.1 目前DAST的优劣势
DAST的主要优势为:DAST可发现绝大多数常规的安全漏洞;DAST平台可以解决大量L1、L2级域名系统无法人工安全渗透测试问题;DAST提供被动扫描功能,可方便业务开发人员自我进行安全检测。
DAST的主要劣势为:DAST的主要测试对象为http/https的web应用程序,但是对于IOS/Android上的App无能为力;DAST无法定位漏洞的具体代码位置和分析漏洞产生的原因,仅能定位漏洞URL;DAST太过依赖自身漏扫功能,不能发现其他类型的安全漏洞;DAST运行需要发送漏洞攻击包来进行安全测试,该方法会对业务测试造成一定的影响以及产生一些脏数据。
4.2 结束语
通过此篇文章,大致讲解了DAST扫描的实现原理、系统架构、核心处理机制,对其中涉及的关键算法步骤都做了详细分析,同时介绍了开发过程中碰到的问题和解决思路,希望能给阅读者一些知识上的收获。
参考文献:
[1] 刘杰,葛晓玢.基于网络爬虫的Web漏洞扫描研究[J].黑河学院学报,2017,8(12):211-212.
[2] 王小君.网络信息安全防范与Web数据挖掘系统的设计与研究[J].电子设计工程,2018,26(12):83-87.
[3] 牛咏梅.面向Web应用的漏洞扫描器的设计与实现[J].南阳理工学院学报,2018,10(6):66-69.
[4] 董昕,郭勇,王杰.基于DevOps能力模型的持续集成方法[J].计算机工程与设计,2018,39(7):1930-1937.
[5] 陆静.10种漏洞扫描工具[J].计算机与网络,2020,46(15):30-31.
[6] 方奇洲.基于Docker集群的分布式爬虫系统的设计与实现[D].武汉:武汉邮电科学研究院,2020.
[7] 杜鹏辉,仇继扬,彭书涛,等.基于Scrapy的网络爬虫的设计与实现[J].电子设计工程,2019,27(22):120-123,132.
[8] 徐鹏涛.基于Vue的前端开发框架的设计与实现[D].济南:山东大学,2020.
【通联编辑:梁书】
