基于单层神经网络的流程相似性的研究
2022-04-08蔡启明许宸豪
蔡启明,张 磊,许宸豪
南京航空航天大学 经济与管理学院,南京 211106
业务流程管理在企业走向数字化、信息化的过程中扮演着重要的作用,能够显著地提高公司的效率,其应用场景包括员工培训、工作资料传递、项目归档等,但是广泛的使用造成了业务流程模型数量的庞大,给企业的有效利用带来挑战。为了对现有流程更好的使用、分析、管理,公共组织或者大型企业开始建立流程仓库,中国移动建立了一个超过40 000的业务流程仓库;荷兰政府保存有600个流程;德国政府尝试建立能访问和保存公共管理流程模型的平台。
而仅仅建立流程库无法满足当今快速变化的市场需求,为了更好地描述业务工作,迅速地构建业务流程模型是企业实现业务流程管理的先决条件。传统的流程建模方式完全仰赖建模人员自身的业务水平,需要建模人员具备丰富的领域知识、熟悉业务流程的执行过程,以及应对突发状况的能力,使得人工建模需要耗费企业大量的人力物力。若能为建模人员推荐现有流程库内的相似流程,在已有流程的基础上进行修改将大幅缩短建模周期,减少重复性工作,目前主流的业务流程推荐技术都是基于流程相似性的思想。
1 相关工作
近年来流程相似度计算的相关研究已经取得了较好的成果,现有的方法可以归为三类:
(1)基于文本内容的流程相似性研究。该方法面向节点的文本内容,包括语义相似性、字符串编辑距离等。Akkiraju等人[1]基于SAP标准化流程集,从流程与节点内容的角度使用文本内容相似性衡量业务流程的相似性。该方法忽略流程图结构的影响,面对相同的任务采用不同的图结构却使用同样的文本内容时,该方法的可信度将无法保证[2]。
(2)基于流程图结构的流程相似性研究。针对该方法的研究较多,Deb等人[3]提出基于服务质量的业务流程设计方法,该方法对服务质量定量、定性,得到较好的业务流程模型的路径。Fellmann等人[4]提出了过程建模推荐系统,对各过程逐个分析,完成流程建模工作。曹斌等人[5]从业务流程资源库入手,运用图挖掘方法对流程模式提取,基于近距离最大子图优先的流程匹配策略对参考流程与流程模式的相似性进行判断。Huang等人[6]提出了一种基于业务流程图结构的两阶段流程搜索方法。基于图结构的相似度计算方法准确度较高,但是由于在对流程图结构处理过程中会造成语义信息的丢失,以致于对流程行为之间的关系辨识能力较低。
(3)基于流程行为的流程相似性研究。该方法借助于流程的图结构,梳理节点之间的逻辑关系得到节点执行序列,从而获得行为信息。Takeru等人[7]提出一种基于点过程模型框架,并以数据驱动的方式构建其模型,将在线活动回归模型拟合到实验数据完成流程建模。Jalali等人[8]提出一种混合的业务流程建模方法,它基于声明性规则来处理必要的跨领域关注点和命令性业务流程模型。
上述针对三类方法的研究中,基于文本内容的流程相似性忽略图结构的影响,可信度较低;基于图结构的相似性准确度较高,相关的研究较多,但是存在语义信息丢失的情况;而基于流程行为的相似性计算方法更贴近现实过程中流程运行的真实情况,参考意义较高。所以本文从流程行为的角度出发,从流程系统记录的日志数据中挖掘节点之间的行为信息,通过使用神经网络模型对日志数据进行训练,获得每个节点的向量表达,进而描述整个业务流程结构,计算业务流程间的相似性。
2 基本概念
本章将介绍本文中出现的相关概念,以便于更好地理解本文使用的方法。
业务流程是一组将输入转化为有价值的输出的流程节点的有序集合。业务流程的表示方法有很多,包括WF-net、C-net、Process Tree等[9],本文仅介绍Petri网。
定义1(Petri网)一个Petri网是一个三元组(P,T,F),其中:
(1)P表示一个有限的库所集;
(2)T是一个有限的变迁集(P⋂T=φ);
(3)F=(P×T)⋂(T×P)是弧的集合。
Petri网中的库所通常表示资源、条件,变迁则表示事件、活动、行为,如图1所示,是一个包含5个库所,6个变迁的流程模型。
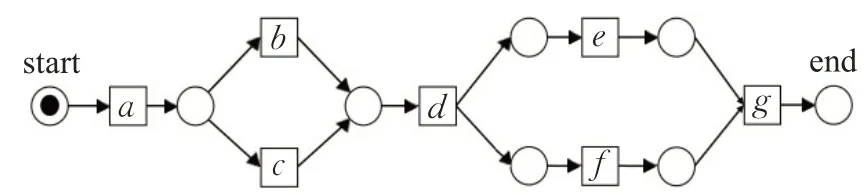
图1 用Petri网表示的流程模型Fig.1 Process model represented by Petri net
Petri网的基本结构有4个[10]。顺序结构:模型内的行为有严格的执行顺序,存在明显的依赖关系,如图2所示;选择结构:模型内的行为具有排他性,不同的条件激发不同的行为,如图3所示;并行结构:模型内的行为具有并行关系,在激发条件下可以并发执行,如图4所示;循环结构:模型内的特定行为在一定条件下多次执行,如图5所示。
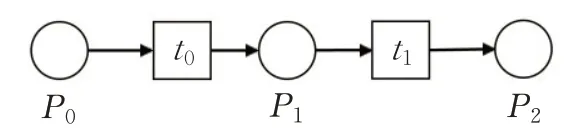
图2 顺序结构Fig.2 Sequence structure

图3 选择结构Fig.3 Select structure
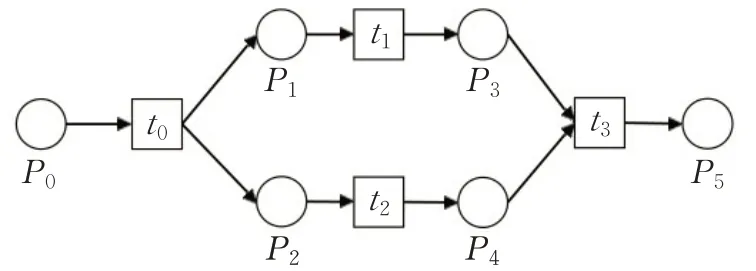
图4 并行结构Fig.4 Parallel structure
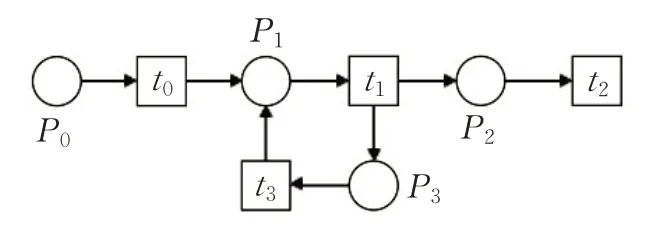
图5 循环结构Fig.5 Cyclic structure
定义2(独立路径)流程模型的独立路径是指从开始节点到结束节点的多次执行中,每次至少有一个任务节点是未被执行过的,即一条独立路径至少包含一条在其他独立路径中未有的边[11-12]。
以图1中的流程图为例,其独立路径包括“a--b--d--e--f--g”“a--c--d--e--f--g”。
定义3(前驱节点集,后继节点集)在一个Petri网(P,T,F)中,两个节点n,m∈T之间存在路径,当且仅当存在一系列节点n1,n2,…,n k∈N使得n1=n,n k=m,并且对i∈1,2,…,k-1均有(n i,ni+1)∈F成立,记作n⇒m。定义n的前驱节点集为{m|m⇒n};n的后继节点集为{m|n⇒m}。
定义4(日志)[13]设T是活动的有限集合,ε∈T∗为一条活动序列,L∈B(T∗)是一个流程执行日志,其中T∗表示集合T的Kleene闭包。
以图1中Petri网表示的业务流程为例,T={a,b,c,d,e,f,g},L=[<a,b,d,e,f,g>3,<a,c,d,e,f,g>2]是一个包含5个实例的执行日志。
日志是系统对业务流程运行过程的客观记录,即工作流程系统运行时留下的轨迹,包含流程、组织、资源、成本、时间、参与者等流程运行状况信息。在事件日志中,一个实例是业务流程的一次执行过程,一个业务流程可以包含多个实例,而每个实例由多个有序的节点组成[14]。以图1所表示的业务流程为例,其部分运行日志见表1。本文仅关注业务流程运行过程中的行为,因此,对日志进行简化,简化结果见表2。
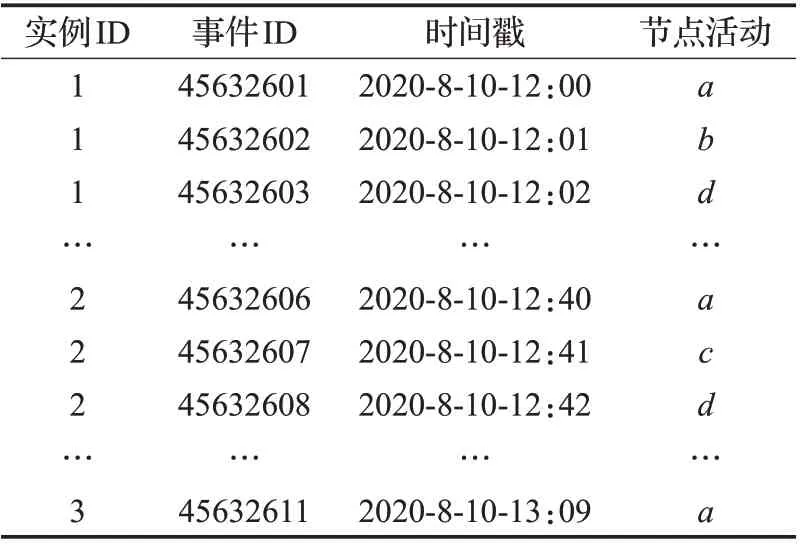
表1 图1流程的部分日志Table 1 Part log of process in Fig.1

表2 图1流程的日志简化形式Table 2 Simplified form of log in Fig.1
定义5(依赖关系)[15]设L为流程日志,T为日志L中所有任务的集合,∃t1·t2∈T,在日志L中,任务t1的紧后任务t2执行的次数记为 ||t1>L t2,L(σ)为轨迹σ在日志L中出现的次数,其中:
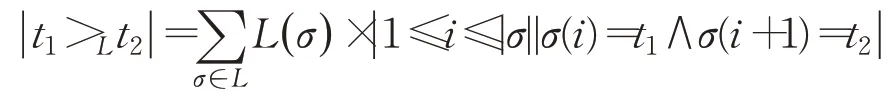
|t1⇒L t2|是t1和t2的依赖关系值,其计算公式为(1):

3 流程相似度的计算方法
相似度是对两个事物的相似性的量化指标,可以通过计算事物的特征之间的距离来衡量。如果距离小,那么相似度大;如果距离大,那么相似度小。比如两种水果,将从颜色、大小、维生素含量等特征进行考虑。针对相似度度量的方式包括:欧式距离(Euclidean distance)、曼哈顿距离(Manhattan distance)、切比雪夫距离(Chebyshev distance)、闵可夫斯基距离(Minkowski distance)、汉明距离(Hamming distance)、余弦相似度(Cosine similarity)、皮尔森相关系数(Pearson correlation coefficient)、杰卡德相似系数(Jaccard similarity coefficient)及杰卡德距离(Jaccard distance)。
本文将业务流程进行向量表达,选择余弦相似度来衡量流程之间的相似度,余弦值越大,代表向量之间的夹角越小,即相似度越高。本章将介绍业务流程的向量化表示方法,以及相似性计算公式。
3.1 基于行为的业务流程体系
流程相似性包括流程结构的相似性与流程语义的相似性,根据第2章中的定义2中可知,业务流程的结构包含顺序、选择、并行、循环4种,同时在每一个节点中都包含有行为信息,以致流程间相似性的量化较为复杂。为了简化相似度量化的复杂性,本文提出了基于行为的业务流程体系。
基于行为的业务流程体系包括三部分:业务流程、独立路径与流程节点。流程节点是行为表现的最小单位,是构成语义信息的最小组成部分,如图6所示,流程B中包含a,b,c,d,e,f,g等7个节点;独立路径由多个流程节点有序组合形成,节点的行为构成该条独立路径的语义信息,具有唯一性,该流程的独立路径包括两条:<a,b,d,e,f,g>与<a,c,d,e,f,g>;业务流程面向具体的业务工作,是节点的有序组合,由于业务流程结构的多样性使得节点行为组合构成了业务流程的语义信息,具有多样性。
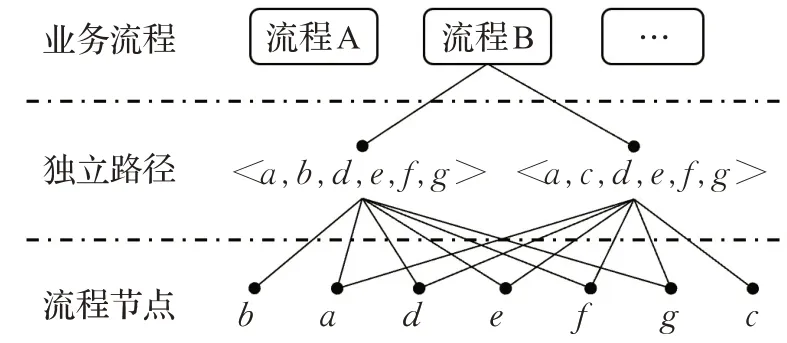
图6 基于行为的业务流程体系Fig.6 Behavior-based business process system
根据对独立路径的定义,从开始节点到结束节点的多次执行过程中,每次执行至少有一个节点是其未被执行过的,由于流程的执行过程依赖其固有结构,所以独立路径中不仅包含流程的部分语义信息,还包含流程的部分结构属性。据此可以得出结论:业务流程中所有独立路径的集合可以表达流程的完整语义信息。
3.2 业务流程的向量表达
本文采用独热编码对流程节点进行向量化表达。独热编码也称一位有效编码,使用V位状态寄存器来对V个状态进行编码,每个状态都有独立的寄存器位,任意时刻有且只有一位有效。例如:针对图6中的流程B,流程库内的节点集T={a,b,c,d,e,f,g},则V=7,那么a表示为向量(1,0,0,0,0,0,0),b表示为向量(0,1,0,0,0,0,0),依此类推。
独立路径的语义信息由节点行为构成,本文将节点向量相加表示独立路径的向量。针对任意一条包含n个节点的独立路径,第i个节点的向量为t i(i=1,2,…,n),该独立路径的向量为
业务流程结构上是流程节点的集合,语义信息是由独立路径构成,本文采用加权平均的方式将独立路径的向量组合表达为流程向量。以包含m条独立路径的流程为例,第j条独立路径的向量为r j(j=1,2,…,m),N j为日志数据中第j条独立路径的执行次数,N为实例ID数,该流程的向量为
因此,两个流程process1与process2之间的相似度计算公式为:

当节点集合较多的时候,独热编码的方式将增大向量的稀疏性,对相似度的计算造成误差,为了解决这个问题,需要将节点向量映射到低维连续空间中表示。
3.3 基于神经网络模型的节点向量映射
本节根据节点之间的依赖关系建立节点之间的函数关系,将记载业务流程行为轨迹的日志数据导入神经网络模型进行训练,将节点向量映射到低维空间中。
节点组合构成了独立路径的唯一性,根据第2章定义6可知,节点之间存在着依赖关系,本质是行为之间存在着依赖关系,节点作为行为表现的最小单位,其前驱节点集的共同作用导致了该节点的执行,因此针对路径σ,其n个节点的向量为:t1,t2,…,t n,对于任意节点向量t x:

同时其后继节点集的执行依赖于该节点的执行,即:

将两个函数关系进行组合,α与β是两个常数
(α+β=1):
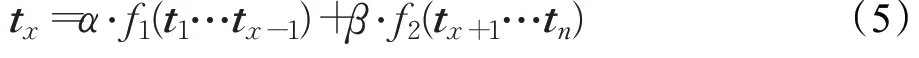
那么存在常数γ:

据此,构建包含输入层、映射层、输出层的神经网络模型,如图7所示,因此在该路径轨迹σ中,将t1,t2,…,t x-1,t x+1,t x+2,…,t n作为模型的输入,流程库内节点个数为V,整个计算过程如下:
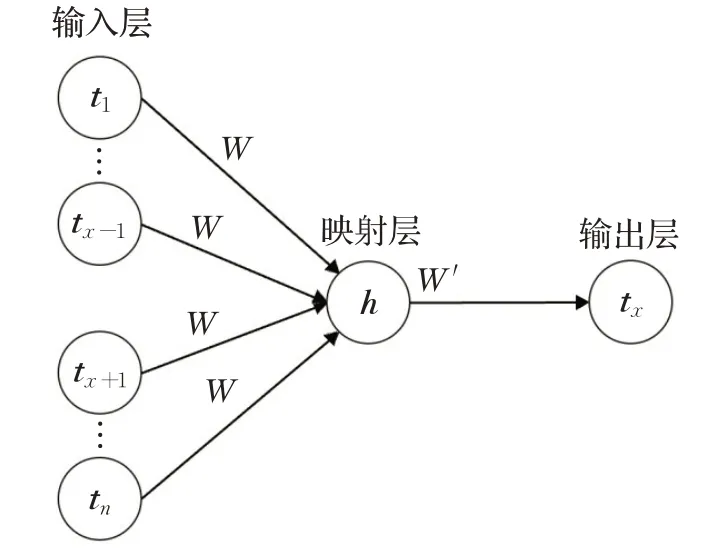
图7 单层神经网络模型Fig.7 Single layer neural network model
步骤1采用独热编码初始化节点向量。路径中节点的向量为:t1,t2,…,t n,每个向量长度为V。
步骤2输入层与映射层之间的权重矩阵为W(H×V),其中H为映射层向量的长度,且H<V,那么映射层的向量h为:
步骤3映射层与输出层之间的权重矩阵为W′(V×H)(矩阵W与矩阵W′无关),与向量h相乘为:
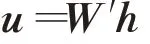
u长度为V:
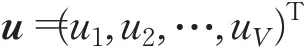
通过softmax函数,节点t在路径轨迹σ(t)中执行的概率为:
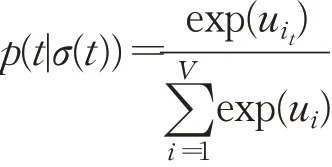
其中i t为节点t在流程库内得索引。
步骤4更新权重矩阵。训练过程的目标是获得节点t x的概率最大,那么损失函数E为:

将损失函数对ui求偏导,即为预测节点为流程库中第i个节点的概率值与待预测节点向量中的第i个分量的差值e i:
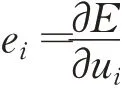
损失函数E对权重矩阵W′中第i行,第j列的权重w'ij求偏导:
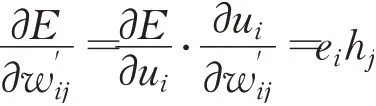
其中h j为向量h的第j个分量,的更新公式为:

其中,η>0为学习率。
损失函数E对h j求偏导:

EH表示流程库内所有节点的输出向量与预测误差的和。损失函数E对权重矩阵W第j行,第k列的权重w jk求偏导,经过整理得到w jk的更新公式:

在训练完成之后,将每个节点向量与训练好的参数矩阵W相乘,得到节点在映射层的低维连续向量,在此基础上,计算业务流程的向量形式,按照公式(2)计算流程之间的相似性,本文在第4章给出了实验分析与相关的应用。
4 实验分析
本章将对本文提出的流程相似性的度量方法进行实验验证。首先简要描述进行实验的环境配置,其次介绍实验数据集、实验的方法以及相关的评价标准,最后分析实验结果并给出该方法在流程推荐领域的应用。
4.1 实验环境
实验环境包括硬件配置与硬件环境两部分:
(1)硬件部分。处理器:AMD Ryzen 5-3550H,主频2.1 GHz,内存:16 GB。
(2)软件部分。操作系统:Windows10家庭版,64位操作系统;算法描述语言:Python3.7.4;算法依赖包括:numpy、pandas、matplotlib。
4.2 实验数据与方法
经过查阅相关文献,本文选择了周长红等人[16]在研究过程中分享到GitHub上的数据进行实验验证。该数据集包括有业务流程以及对应的流程日志,以一个真实的保险理财申请流程P0为基础,如图8所示,采用多种方式构造了13个流程的变体,见表3。13个流程的日志数据由日志生成工具(PLG)生成。

图8 原始流程P0Fig.8 Original process P0

表3 变体流程信息Table 3 Variant processes information
本文按照所提出的方法对P1~P13流程的日志数据进行训练,获得节点的低维连续向量形式,结合各流程独立路径在日志数据出现的频率计算出业务流程的向量形式,根据公式(2)计算P1~P13与P0之间的相似度,进行排序,与周长红等人[16]给出的基准排序进行比较。
4.3 实验结果分析
为了直观地展示所提出算法的准确率,实验选取文献[16]提出的weight business process graph(WBPG)算法、文献[17]提出的matrix distance similarity(MDS)算法、文献[18]提出的graph edit distance(GED)算法与本文的算法进行比较,计算13个变体流程与P0的相似度,结果如表4所示。
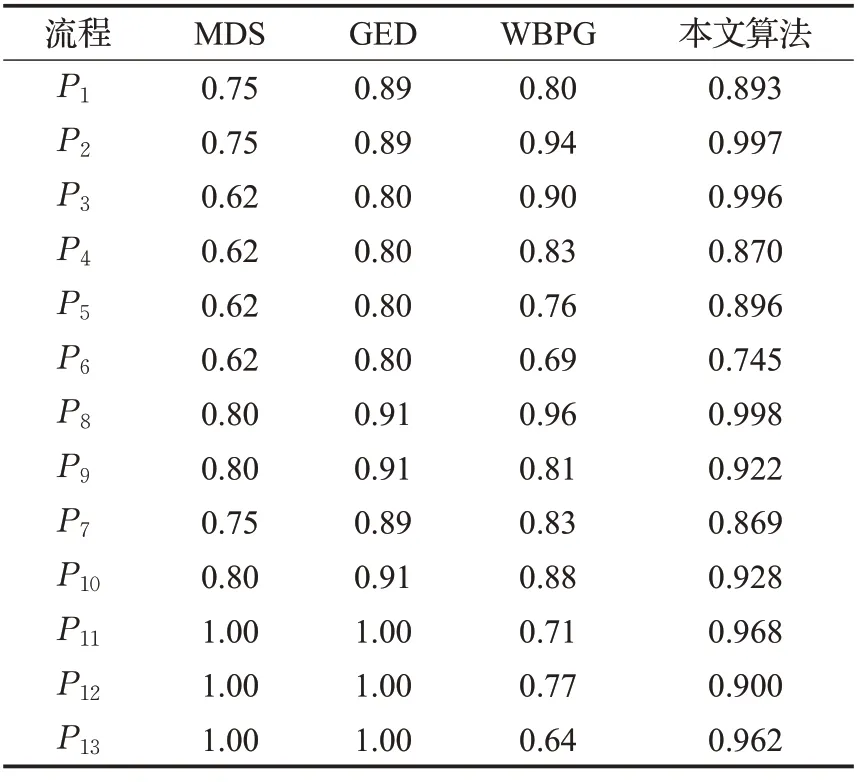
表4 不同算法的实验结果Table 4 Experimental results of different algorithms
由于每种算法采用的相似度计算方法不同,导致结果也不相同,所以按照各算法的相似度值大小对13个变体流程排序,周长红等人[16]公开的成功中也给出了15位领域专家按照P1~P13与P0之间相似性大小的排序结果,以及对应流程变体的权重,将该排序结果作为标准排序,得到如表5所示的排序结果。

表5 相似度排序结果Table 5 Results of similarity ranking
本文选择归一化折损累计增益(normalized discount cumulative gain,NDCG)对算法的准确率进行评估。NDCG是一种常用的评价排序、搜索算法的方法,其计算公式如下:

式中,DCG n表示某给定业务流程模型与n个相关流程的折损累计增益;r(n)表示排在第n个位置的流程的权重,即计算出的排序结果的DCG值;IDCGn表示标准排序内流程与n个相关流程的理想折损累计增益,即排序的理想情况下的DCG值(IDCG)。由公式(7)和(8)可知,算法的排序准确率越高,DCG与IDCG越接近,NDCG越大。
经计算,标准排序的IDCG为4.167,根据表5内各个算法的排序结果,计算对应的DCG值,进而得到NDCG值,计算结果如表6所示。
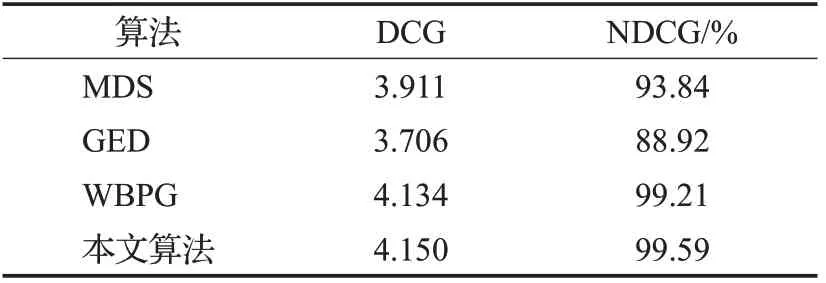
表6 不同算法排序结果的DCG与NDCGTable 6 Results of DCG and NDCG of different algorithms ranking
本文算法计算出相似度最高的5个流程与标准排序相同,比其余3种算法都更由优势,基于流程相似性思想的流程建模推荐技术尤其关注排序排名较高的流程,而归一化折损累计增益的计算公式也决定了该评价方法更关注排名靠前的结果。由表6可以看出,本文方法相对于其他3种方法准确率更高。
4.4 实际应用
传统的流程建模方式完全仰赖建模人员自身的业务水平,需要建模人员具备丰富的领域知识、熟悉业务流程的执行过程,以及应对突发状况的能力,使得人工建模需要耗费企业大量的人力物力。因此,基于已有流程辅助的半自动化流程建模方法受到广泛的青睐,流程推荐是针对当前的业务流程片段,通过对已有业务流程的分析,为建模人员推荐后续可能执行的业务活动。当前主流的流程推荐方法都是基于流程相似性的思想,该类方法通过计算待推荐流程片段与已有流程的相似性,将相似性较高的流程推荐给建模人员,但是该方法当面对独立路径较多的业务流程时无法保证推荐的准确率。
鉴于上述原因,本节构建基于本文所提方法的流程建模系统,如图9所示。将相似性的计算从业务流程层次转向独立路径,获取待推荐系统的独立路径,与现有流程的独立路径进行相似度比较,相较于基于流程相似性的方法,准确率更高,灵活性更强。该系统包含3个主要模块。
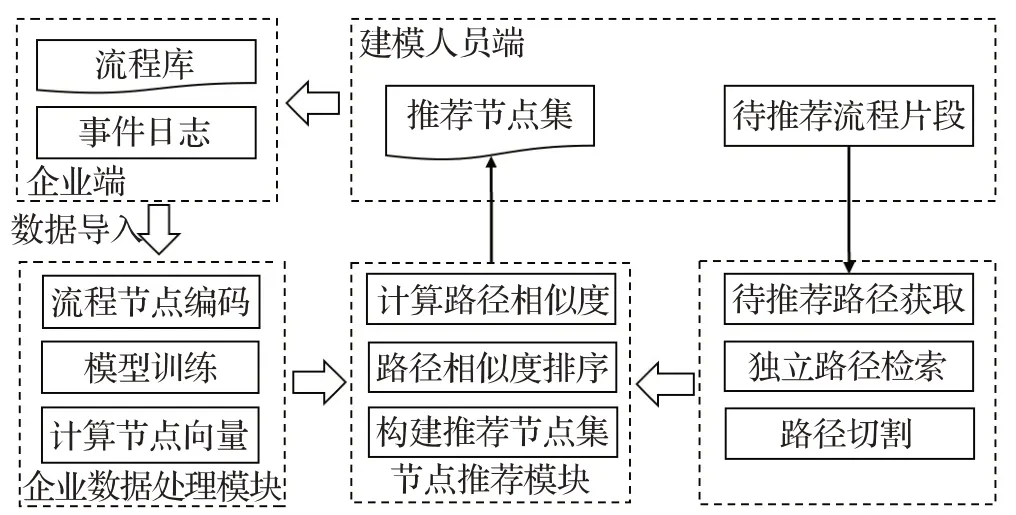
图9 流程建模推荐系统Fig.9 Process modeling recommendation system
(1)企业数据处理模块。该模块的详细过程见3.3节,此处仅简要说明。该阶段分为3个步骤:
步骤1流程节点编码。采用独热编码初始化流程库内节点的向量。
步骤2模型训练阶段。构建神经网络模型,以日志数据中的流程轨迹为训练集,训练模型。
步骤3计算节点向量。将训练好的模型中输入层与映射层的权重矩阵与初始化向量相乘获得低维连续的节点向量。
(2)待推荐流程处理模块。本阶段的工作包括3个步骤:
步骤1获取待推荐流程片段的所有独立路径。设流程片段中包括z个待推荐路径:σre1,σre2,…,σrez。
步骤2独立路径检索。待推荐路径σrei(i=1,2,…,z)的末端节点为σrei[end],在流程库内搜索包含节点σrei[end]的独立路径。
步骤3独立路径切割。以待推荐路径σre i为例,设包含节点σr ei[end]的独立路径有y个:σ1,σ2,…,σy,对y个独立路径进行切割,如将独立路径σk(k=1,2,…,y)切割,仅保留从开始节点到节点σrei[end]的路径,即σk[1:jσk,σrei[end]],其中jσk,σrei[end](k=1,2,…,y)为独立路径σk中节点σrei[end]的索引。
(3)节点推荐阶段。该阶段分为3个步骤:
步骤1计算路径相似度。计算第i条待推荐路径σrei与流程库中包含其末端节点σre i[end]的第k条经切割后的路径σk[1:jσk,σrei[end]]之间的余弦相似度,记为similarity<σrei,σk[1:jσk,σrez[end]]>。
步骤2对路径间相似度的计算结果从大到小排序。
步骤3构建推荐节点集合。根据排序结果,与待推荐路径σrei相似度最高的路径为σtar[1:jσtar,σrei[end]],那么对应未切割的独立路径为σtar,则待推荐路径σrei的推荐节点即为该路径中待推荐路径末端节点的下一个节点σtar[jσtar,σrei[end]+1]。
计算出每一个待推荐路径的节点后构成集合推荐给建模人员,建模人员在完成新流程后输入流程库内。
5 结论
针对流程相似性的研究多集中于流程图结构,却忽略了流程语义的相似性,本文从业务流程实际执行过程的角度出发,构建基于行为的流程体系,将流程的复杂结构转化为独立路径,同时包含流程的行为属性,最后将独立路径分解为流程节点。采用独热编码表示节点的初始向量,构建神经网络模型对节点向量的训练,获得低维连续的向量,进而表示流程向量,通过向量间的余弦相似度表示流程间的相似程度,通过实验计算该方法的准确率达到99.59%。
本文尝试将人工智能技术应用到流程相似性的度量中,取得了较好的准确率,并且给出了在流程推荐领域的应用形式。但是本文存在一定局限性:该方法对日志数据量要求较大,当数据量较少时,无法保证其准确性;其次,应用在流程节点推荐领域时,如果建模人员输入的流程片段中存在流程仓库没有的节点,会导致该方法推荐的准确率无法保证。所以,后续工作将着重针对这两方面进行研究。
