基于深度强化学习的金融交易算法研究
2022-04-08祝玉坤邢春晓
许 杰,祝玉坤,邢春晓
1.清华大学 五道口金融学院,北京 100084
2.清华大学 北京信息科学与技术国家研究中心,北京 100084
如何获得经风险调整后的金融资产交易回报是现代金融关键研究热点之一。1964年,提出了资本资产定价模型(capital asset pricing model,CAPM),指出回报只与系统性风险有关,投资组合的目标为消除非系统性风险,成为金融市场交易重要基础理论。随后,1970年提出了有效市场假说理论,认为价格完全反映了所有市场公开信息,任何股票技术分析是无效的。然而许多实际市场交易现象并非遵守有效市场假说理论,出现了如羊群效应、股权溢价之迷等一系列金融异象。传统的金融交易方法主要基于价格预测方法,从影响证券价格变动的因子出发,分析研究证券市场的价格变动一般规律。但基于预测的方法存在以下挑战:(1)金融时间序列一般是非平衡数据且噪声大量存在,为了减少数据噪音和不确定性,通常手工抽取金融特征,难度较大且不全面。(2)变量因子间存在普遍的相关关系与多重共线性,导致权重参数估计失真。(3)由过去的时间序列生成的模型只能表明历史发生的事实,不能完会解释未来金融市场变化规律,模型样本外泛化能力弱。(4)在传统的预测方法中,当市场出现牛熊市转换、动量转换时,原有拟合模型可能不再匹配新数据。
近年来,人工智能呈爆发式发展,利用人工智能算法研究金融数据趋势与规律,建立金融交易策略越来越普遍,其中比较典型是深度学习(deep learning,DL)方法、强化学习[1-2](reinforcement learning,RL)方法。深度学习具有端到端的表示能力,具有强大特征提取能力和非线性函数拟合能力,可以部分消除复杂内部逻辑设计,提高数据来源多样性,主要应用于算法交易、风险管理、欺诈检测、投资组合管理等领域。然而,使用深度学习预测股票价格或趋势运动时,算法效果主要取决于预测准确度,容易出现过拟合现象,并且在存在交易成本的情况下,高预测准确度并不完全代表高最终收益率,未能捕捉到由于股票交易活动而引起的未来惩罚或奖励回报[2-3]。
强化学习与心理学中的行为主义相类似,事先未给定数据以及数据标签,具有探索-利用(explorationexploitation)特征。相比基于预测的方法,强化学习实现状态空间到动作空间映射转换,通过智能体与金融市场环境不断实时交互学习策略,从市场反馈中不断积累经验,在抑制风险的同时最大化累积回报,与人类认知与思考进程一致,被应用于股票自动化交易、资产组合配置、债权的定价与套期保值等领域。但传统强化学习方法存在感知状态与提取特征能力不足、状态空间与动作空间大小有限、不能捕捉前序时间序列特征等缺点。
融合了深度学习和强化学习的深度强化学习(deep reinforcement learning,DRL)在解决复杂序列决策问题上取得了显著的成功,深度强化学习集成了深度学习感知能力和强化学习决策能力[4-5]。DRL具备非凸性质,能够直接从高维原始数据中学习和控制策略,允许在一个整体中同时考虑价格预测和计算投资收益目标,扩大了策略函数的应用范围,提高了数据驱动自监督学习能力,交易成本、市场流动性、投资者的风险厌恶程度等重要制约因素可以被隐式表达,不需要另外建立新的总体投资收益函数模型,降低了模型建立与训练难度。主要应用领域有债权的定价和跨期套期保值、投资和组合配置、资产组合、资产负债管理等[6-12]。
基于以上讨论,本文中提出一种融合CNN与LSTM的端到端深度强化学习方法(CLDQN算法)寻找最佳交易策略,主要贡献如下:(1)将股票价格数据转换成对应的二维矩阵图,使用CNN模块抽取股票动态市场特征。(2)使用LSTM模块学习复杂的动态时间变化序列规律。(3)在动态股票市场中使用deep Q learning(DQN)方法获取累积回报并依此做出交易决策。(4)在真实股票数据集上的实验结果显示CLDQN显著优于其他基准算法,鲁棒性更好。
1 相关工作
使用深度学习方法预测股票价格主要有两类:一类是专注于提取时间序列规律,如RNN、GRU、LSTM等;一类是专注于融合不同数据,提取广泛的特征,如CNN、反卷积神经网络(deconvolutional neural network,DNN)等。下面分别介绍这两类算法。长短期记忆(long short-term memory,LSTM)应用于股票研究。LSTM是解决梯度消失一种特殊的循环神经网络,解决了RNN逻辑单元距离增加而出现的长期性依赖问题,被广泛地应用于时间序列数据并取得了显着的成果。Borovkova等[13]提出集成在线LSTM模型,将大量的技术性分析指标作为网络输入,根据每时段数据近期表现按贡献重要程度分别加权,以此处理非平稳高频股票市场数据,模型包括了两组不同规格的LSTM,第一层能够处理时间序列整体规律,第二层则针对具体特定特征。Cipiloglu等[14]提出LSTM模型学习股票月收盘价,介绍了5种不同资产组合构建策略,根据每个股票月度历史数据作为模型输入,预测每月的收盘价,产生了对成份股进行筛选或对成份股权重重新配置的不同聪明贝塔(smart Beta)变种,最终输出不同组合股票收益。Tiwari等[15]调研了LSTM在股票价格预测、指数建模、风险评估、收益回报的应用。Hiew等[16]使用金融情绪指数与LSTM融合预测股票收益,通过不同来源的情绪指数,如微博上关于不同股票的讨论,计算市场关注程度与情绪指数。也有使用LSTM与其他方法融合的方法,BAO等[17]将小波变换、堆栈式自编码器(SAEs)和LSTM相结合,首先对股票价格时间序列进行小波变换分解以消除噪声,接着应用SAEs生成深层高阶特征,输入至LSTM中预测第二天的收盘价,这种通过额外增加特征提取的方法在金融数据处理中比较常见。
卷积神经网络(convolutional neural network,CNN)应用于股票研究。CNN可以融合不同来源数据,浅层网络提取一些低级的局部特征,深层抽取更为复杂的全局特征,可用于交易价格预测、大盘趋势分类、资产投资组合等问题。Gudelek等[18]提出一种利用CNN预测交易型开放式指数基金(exchange traded fund,ETF)收益,首先在滑动窗口时间内生成不同ETF快照,使用卷积操作提取趋势指标以及基本面特征,包括RSI、SMA、MACD等特征,进而生成向量矩阵作为CNN的图形输入。为了考察不同市场之间的相关性,Hoseinzade等[19]使用2DCNN与3DCNN聚合对齐不同来源变量,包含S&P 500、纳斯达克、道琼斯NYSE,道琼斯DJI、罗素指数,模型由4部分组成,包括输入数据表示、日常数据特征提取、持续特征提取、预测部分。2DCNN使用单个市场与单个股票数据训练预测,3DCNN将所有可用的市场数据作为输入统一训练模型,这两种结构可提高3%~11%预测性能。Cai等[20]提出了一种融合CNN和LSTM框架,金融新闻和股票市场历史数据作为输入,构建了7个不同的预测模型分类器变种,组合成更强大的分类器。总体而言,CNN的优势在于特征提取平移不变性,不会破坏信号频谱,可并行处理不同时间节点数据。
区别于上述直接预测股票价格方法,基于强化学习方法将预测结果和投资动作结合在一起,直接以投资收益目标作为优化目标。强化学习价值函数可以具有不可微性质,因此可以较灵活地设计回报函数、增加数据来源与环境状态,模型泛化能力较好[21-22]。但当状态与动作连续时,动作价值表空间过大,导致查表状态(state)和动作(action)过于复杂,因而提出了使用神经网络拟合动作价值表方法[23]。Deng等[24]首次使用深度强化学习方法用于金融市场,深度学习部分自动感知动态市场条件,提取信息特征,强化学习模块与环境互动并做出交易决策,为进一步提高市场鲁棒性,引入模糊学习来减少输入数据不确定性,实证结果较好,此后基于该方法的文章大量出现。Zarkias等[6]使用一种价格追踪方法,通过将交易动作定义为包含市场噪音价格跟踪智能体,可密切跟踪价格,自动调整交易保证金,使用DDQN(double deep Q network)训练模型。Jeong等[25]针对交易数据不足的问题,提出迁移学习融合Q-learning处理高波动金融数据带来的过拟合问题,使用领域迁移方法将训练好的模型迁移到其他股票,逐步迭代减少搜索空间,该方法也可以应用到对冲策略、资产组合优化等场景。Carta等[26]提出了使用相同训练数据多次训练DQN集成方法,在不显著影响预期回报的情况下降低策略风险。Liu等[27]采用GRU与DQN结合方式,使用GRU抽取隐状态特征值与观察到的状态融合之后,共同做为强化学习状态表示内容。这种通过增加循环神经网络中间层的方式,降低了连续性时间序列噪音,使得DRL能获得较高稳定的输入特征,是一种处理噪音较好的解决思路。
2 基于CNN与LSTM的DQN方法
2.1 模型原理
强化学习过程可以使用马尔可夫决策过程(markov decision process,MDP)表示[21,28],通常将MDP定义为一个四元组(S,A,p,R),即(状态,动作,状态转移概率分布,回报)。强化学习算法主要步骤包括:(1)定义回报函数;(2)定义状态空间;(3)设计不同状态之间的转移概率分布表;(4)寻找最优化操作策略。本文关于金融强化学习的问题描述如下:
状态(state),是对金融市场环境的一种描述,代表投资者所能获取到的信息,状态设计需要满足两个条件:尽可能多包含影响因子信息;尽可能减少噪音因子信息。金融市场状态主要包括技术面、基本面、信息面。技术面包括交易量、价格最高点与最低点等;信息面包括市场外部信号、管理部门与上市公司等信息;基本面信息以股票内在价值为依据,包括公司经营分析、市场状况、行业地位分析等。
动作(action),是对智能体(agent)与环境实时交互可执行动作的描述,动作可分为连续型动作与离散型动作,包括三种动作,a∈{-1,0,1},分别代表证券卖出qt+1=q t+k,无操作,买入qt+1=q t+k,q t代表t时间股票份额,k∈Z(Z为整数集)。
策略(policy),π(s),状态空间到动作空间映射,表示在状态s下以一定的概率p(s,a)执行下一步动作a t,并转移到新的状态at+1。
回报(reward),r(s,a,s′),在智能体的动作下,从t时间开始到T时间结束,累积执行动作获得的回报值。在本文中,强化学习的最终目标是指定时间内累积折扣回报最高,学习过程是寻找使期望累积折现奖励R t最大化的策略π(s),形式化定义如下:
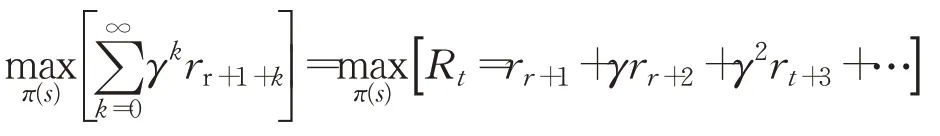
其中γ∈(0,1)是折扣因子,r t代表t时刻奖赏值。
评价策略π的期望使用状态值函数Vπ(s)表示,定义为。状态动作价值函数也称为Q函数,是对状态-动作对的评估,定义为Qπ(s,a)=,表示在状态s下根据策略π执行动作a获得累计期望价值。对一个指定的动作,如果其回报值大于其他所有动作的回报值,则称π为最优动作,表示为。最优状态动作价值函数Q*(s,a)通过贝尔曼方程求解[23],。实际上,Qlearning的目标是直接逼近最优状态-动作值函数,假定Q(s,a;θ)是参数为θ状态动作值的值函数,具体而言,对于第i+1状态下的状态-动作函数为Q i+1(s,a)=。此外,Q网络的迭代目标函数为是目标网络参数,通过迭代最小化损失函数L i(θi)学习参数,其中L i(θi)定义为
由于可行交易行为是一个离散集合,股票价格变化属于连续变化且没有边界,Q-learning中状态空间大小呈指数级增长,表格存储空间成本和贝尔曼迭代计算量过大,阻碍了Q-learning的发展。Mnih等[29]提出深度学习与强化学习结合的DQN网络,在Atari2006游戏中超过了人类的水平。DQN使用神经网络非线性近似表示值函数或策略,Q-learning表格替换成基于神经网络的Q-network[30-31],将深度学习与Q学习结合输出最优值。包含4个步骤:(1)初始化状态、环境、经验池、策略、神经网络等参数;(2)确定概率ε,将探索数据存入经验池;(3)根据采样规则从经验池取出数据训练,使用深度学习方法更新网络参数;(4)重新评估策略回报值,循环以上步骤直至收敛。
2.2 模型框架
本文提出的框架主要由三部分组成,如图1所示。(1)外部环境动态特征提取CNN部分。(2)时间序列规律分析LSTM部分。(3)交易动作决策部分。首先根据股票价格数据产生每支股票二维时序图,将单位时间内开盘价、最高价、最低价、收盘价组成蜡烛数据图,此外,新生成6组指数蜡烛数据图,包括上证指数、深证综合股票指数、上证50指数、沪深300指数、中证500指数、深证100指数。按照每28分钟价格波动曲线生成一个矩阵向量,行向量值为每分钟单位时间,t=k+1,k+2,…,k+28,列向量值为价格指数轨迹经过max-min方法调整后的价格浮动值,即矩阵T i∈R28×28,共7组向量矩阵,i∈(0,7),共同作为CNN输入[32]。
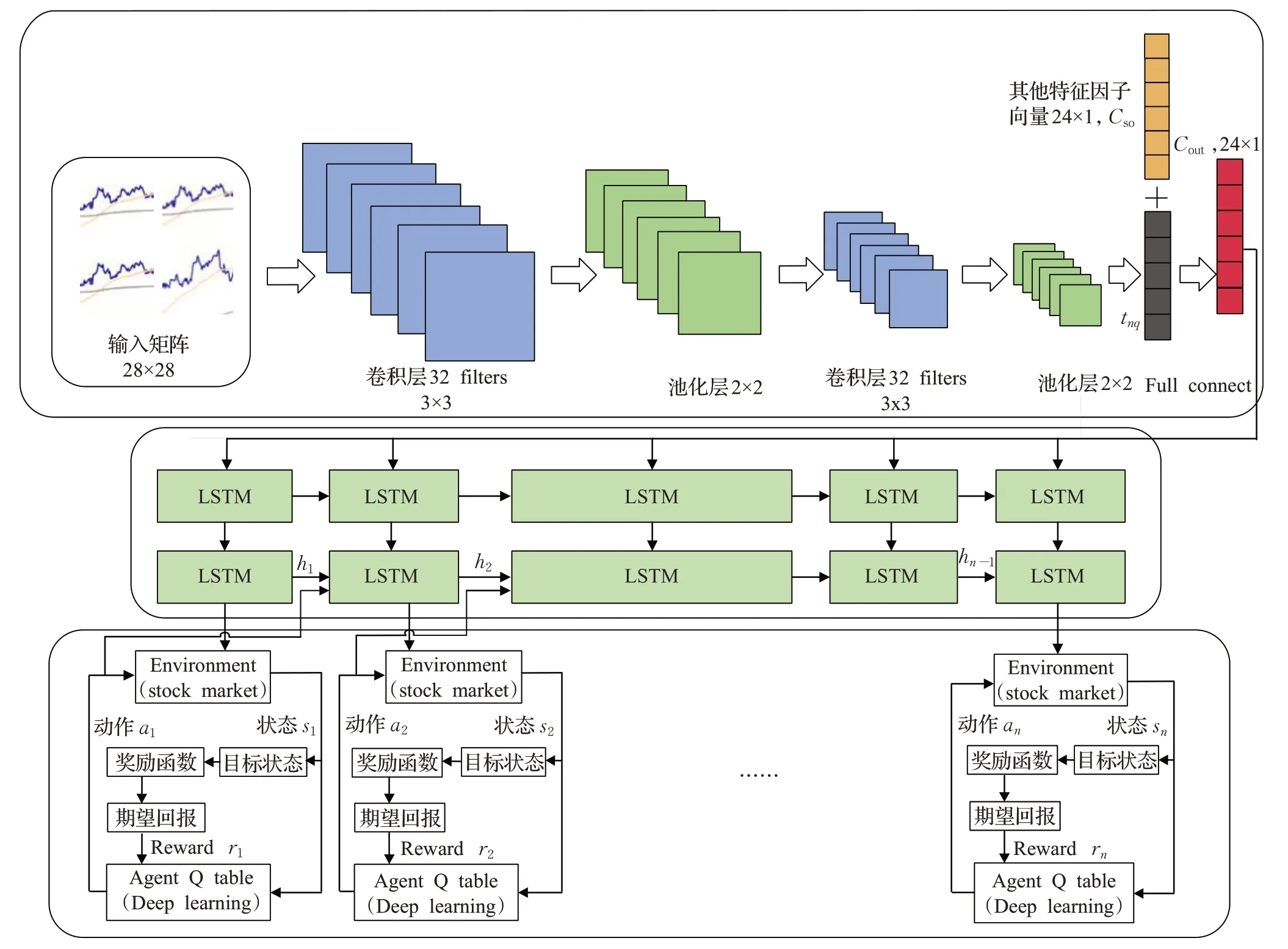
图1 CLDQN模型框架Fig.1 CLDQN model framework
此外,为了更充分挖掘股票价格信息,按照资产定价研究常用方法,将影响股票价格因子分为4类:流动性类因子、波动类因子、动量类因子、基本面因子。具体如下,流动性类因子:换手率、单日成交量;波动类因子:6个月波动率、9个月波动率、基于CAPM的过去30天特质波动率、基于Fama-French的过去30天特质波动率、平滑异同移动平均线(moving average convergence divergence,MACD)、移动平均线(moving average,MA)、过去30天日收益率标准差、30天内最大日度回报、随机指标KDJ、前1个月涨跌幅、前3个月涨跌幅、前6个月涨跌幅;动量类因子:相对强弱指数(relative strength index,RSI)、威廉指数(%R);基本面因子:账面市值、销售净利率、市盈率、市净率、股息率、净资产收益率、现金流资产比和资产回报率之差、非经常性损益比,共24种因子,每一类因子经数据归一化后,形成一个24维向量Cso。
减少原始数据中的不确定性是提高金融信号分析效果与算法鲁棒性的重要途径,CNN属于一种前馈式神经网络,具有局部感受野、权值共享特性,浅层卷积操作提取一些低级的局部特征,深层卷积操作提取潜在全局特征。卷积神经网络主要包括输入层、卷积层、激活层、池化层、损失函数层,卷积层与池化层交替成组出现,减少了特征维度,保证了卷积操作对位移、缩放和形放不变性。选取窗口大小为w∈Rk×k,步长为1的卷积过滤器作用在x i到x i+k-1的向量矩阵上,进行元素内积操作,元素积相加后得到新的空间特征,从窗口xi到x i+k-1得到特征为:
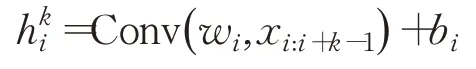
Conv是卷积操作,w i是权重参数,b i是偏置。将c个不同的过滤器分别作用矩阵上,可以得到输出c个卷积层矩阵t nq∈R(28-L+1)×(28-k+1)。池化层起二次提取特征的作用,通过降低二维图形分辨率降低特征维度,,fsub表示平均池化方式。最后一层池化层的输出与其他特征因子向量融合后(Cso,t nq),经过全连接层(fully connected layers,FC)输出Cout,作为LSTM的输入。LSTM具有抽取时间特征作用,通过遗忘门控制历史状态,第t层信号经输入门后仍可保留原有信息。本文LSTM结构定义如下:
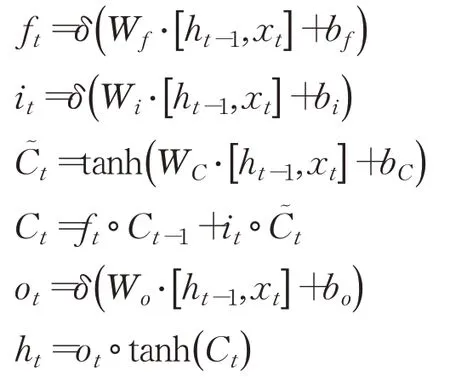
其中h t是LSTM单元的隐藏状态,表示来自前一个时间步长的信息,x t表示外部输入像信号,本文中为Cout,W f,Wi,Wc,Wo是对应门输入权重参数,f t选择忘记过去某些信息,i t记忆现在某些信息,C t将过去与现在信息合并,ot输出门输出,b f、b i、b c、b o是偏置,δ是非线性函数,符号“·”代表向量点乘,tanh是双曲正切函数,每个单元的相同门的输入参数共享。两层LSTM被证明效果一般较好,本文也采用两层LSTM架构[13]。
当智能体执行一个交易动作后,将获得股票市场返回的奖励Rt和状态ot,以及经LSTM处理后的前序ht,作为下一次神经元的输入,智能体动作可改写为at=μθ(h t,s t),Q函数可改写为
更新后的网络损失函数定义为:
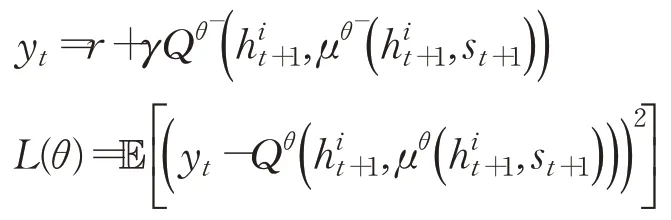
对损失函数求偏导:
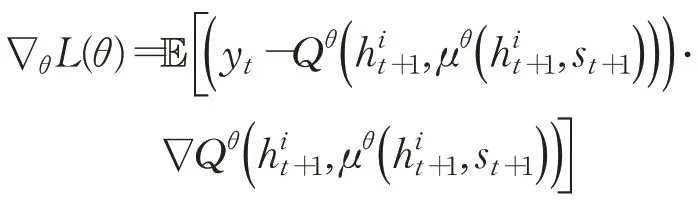
求解以使得损失函数最小,其中为t+1时刻LSTM输出,s t+1为t+1时刻环境状态,θi和是值函数Q的训练过程参数和目标网络参数,训练过程中间断更新。采用e-greedy贪婪策略,e-greedy是一个不确定性的策略,平衡了利用和探索部分,选取执行动作值函数最大部分为利用部分,仍存在一定概率寻找全局最优解为探索部分。采用经验回放(experience replay)方式随机抽取小批量样本训练,处理数据相关和非平稳分布引起的问题,增加样本多样本,防止程序陷入局部最优值,学习到的经验可以共享。
2.3 模型学习过程
Q-learning使用探索(exploration)和利用(exploitation)寻找新的最优策略。首先设定训练集窗口大小、验证集窗口大小、测试集窗口大小、经验池大小、折扣因子、学习率以及随机初始化神经网络权值θ和,初始化训练集状态、动作,以ε的概率从所有的动作中随机抽取一个执行动作A,记录即时回报R和转移到的新状态S,以1-ε概率使用神经网络决策获得下一步的动作,即令Q值最大的动作。在线处理得到的转移样本e t=(s t,at,r t,s t+1)存入经验池D中去除采样数据相关性。与传统的DQN经验池不相同,因为LSTM需要一次输入多个相关的时间步长,而不是随机采样的单个时间步长,需要对相当长的轨迹片段进行采样,用作向DQN提供状态s。经验池需要重新更改,(s,a,r,s′)~U(D)修改为
为了优化CNN网络,本文采用Adam优化算法求解损失函数优化极值,Adam是随机梯度下降算法的扩展式,通过计算一阶梯度加权平均和二阶梯度加权移动平均设计不同参数自适应性学习率。
从经验池中随机选取指定个数n的样本作为batches进行训练,Adam算法更新网络参数θ,通过N轮迭代后,将训练网络参数延迟赋值给目标网络参数,使目标网络与训练网络参数尽可能接近。
在各时间节点,有一个隐藏的假设,即各个时间点的状态是对环境的完整观察,但金融市场充满了大量噪音,使得状态s不能完全描述市场交易环境真实情况,为了增加探索行为,一个随机过程ξ~N( 0,σ2)噪声添加到环境网络,扰动后的动作更新为a t=μθ(h t,s t)+ξ。推进滑动窗口,重复以上过程,直到遍历完所有数据集。
CLDQN学习过程如下:
算法1CLDQN算法
初始化动作状态值Q函数参数θ,目标Q函数参数θ-,ε参数,经验池D大小,minibatch。
While循环数据集次数小于指定Ldo
Forepisode=1→Mdo:
初始化噪音随机过程N(0,σ2),更新参数θ和θ-,初始化超始状态s
fort=1→Tdo:
根据概率ε选择一个随机动作at,或根据argrmaxaQ*(h t,a;θ)值选择动作at
执行股票交易动作a t,获得奖励r t
将t时刻LSTM输出h t,at,cout融合后生成新的h t+1=LSTM(a t,cout,h t),将结果(h t,a t,r t,h t+1)存入D中
随机从D中随机取出minibatch个状态,设置y i

梯度下降更新θ,在损失函数(yi一Q(h t,a j;θ))2上执行对θ的梯度更新,每经过N步,更新目标网络参数
End for
End for
End while
目标网络更新如下:

τ表示学习速率。
正则化与Dropout,金融市场本质上是嘈杂的,深度学习具有强大的学习能力,为避免神经网络过拟合,使用Dropout正则化技术处理,Dropout在神经网络中以概率1-p舍弃部分神经元,在训练阶段降低神经网络规模,减少特征隐层节点间相互作用。
3 实验与与结果分析
3.1 实验平台与工具
本文采用Python3.4实现算法模型,Tensorflow函数模块开发深度学习网络。使用Python matplotlib 3.1库实现数据可视化,内存64 GB,CPU i7 4790,GPU GTX 1070,采用CUDA 9.0与CUDNN 7.1加速计算。交易成本设定交易金额的0.05%。mini-batch size等于512,初始学习率是0.01。
3.2 实验设置
实验数据来自wind终端,包括沪深市股票,特别选取4支股票:三一重工、格力电器、招商银行、紫光股份,主要原因有:(1)不同市值的股票受宏观市场的影响不同;(2)不同产业股票的周期性不同;(3)股民的关注度与股票价格具有相关关系,分别代表缓慢增长型、长期蓝筹型、稳定型、科技型公司。三一重工代表受宏观因素较深股票,格力电器、招商银行分别代表高市值股票,紫光股份代表科技成长型中小股票。对于股票中的断点,采用前序数据线性回归补全开盘价、收盘价、成交量等值。上证50指数代表大盘行情,流动性更强,蓝筹股与白马股占主要成份,沪深300为沪深股市市值最高的300支股票,对整体市场的影响力最大,属于大盘股股票,中证500指数代表沪深股市的中小盘股票,深证100指数代表多层次市场体系指数,为深市成交最活跃100支股票。使用2005年12月至2016年12月为训练数据,2017年1月至2020年1月为测试数据,采用数据标准化方法对经后复权后的交易数据进行数据标准化,如表1所示。为了进行比较,基准算法分别为LSTM模型、RRL算法[33]、决策树(decision tree);此外,CLDQN允许有两个变种:CLDQN-L代表CLDQN中去除CNN部分,CLDQN-C代表CLDQN去除LSTM部分,股票的特征输入采用特征向量直接作为LSTM的输入。使用4个不同的评价函数,即累计收益率(cumulative return,(末期资产-初期资产)/初期资产)、年化夏普比率(annual sharpe ratio,(收益率-无风险利率)/收益率波动)[34]、年收益标准差(annual standard deviation)、最大回撤率(maximum drawdown,max(1-账户当日价值/当日之前账户最高价值))等。

表1 实验数据特征Table 1 Experimental data characteristics
CLDQN各参数的设置如下:CNN filter为3×3,数量为32,步长为1,pool size为2×2,dropout设置为0.5。LSTM的input size为24,每层number of unit为128,所使用的激活函数为ReLU,Epochs=50,L=50。贝尔曼折扣因子0.9,经验回放池大小设置为100 000,贪心策略ε=0.9,终止值0.001。训练过程中采用off policy的方法,θ随深度学习梯度更新,目标只做周期性的拷贝更新,目标网络每100步更新一次。CNN、LSTM、DQN模块均使用Python和带有TensorFlow的Keras包实现。
3.3 实验结果
3.3.1 不同股票收益曲线
如图2为6种算法在4支不同股票数据下的收益曲线,图中纵坐标表示资产累计收益率,横坐标为样本外测试时间。从图中可以看出:
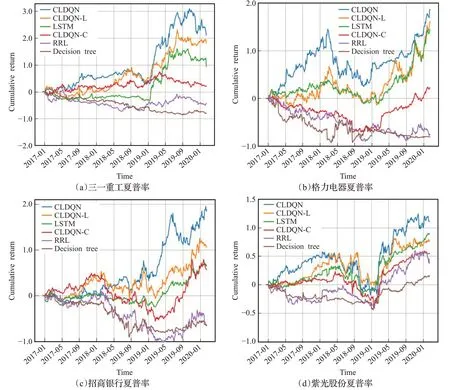
图2 股票累积收益率评测Fig.2 Stock cumulative return evaluation
(1)本文提出的CLDQN收益率曲线明显领先LSTM、RRL、决策树方法。在2018年,基准算法有一个比较大的跌幅,CLDQN算法收益则较为平衡。决策树的收效表现最低,LSTM算法处于居中位置。此外,对比CLDQN与CLDQN-L、CLDQN-C算法,同时考虑时间与变量交互特征的CLDQN效果比CLDQN-C算法最高约提高5.5倍左右(招商银行,2019-06),单支股票与整体市场的关联关系充分被捕捉,提高了算法精度。
(2)实验结果表明CLDQN-C算法一般,说明通过卷积抽取外部环境状态的方法对于算法性能增加影响有限。这是因为区别于图像特征提取,同一时间序列在同一时间上不会出现两个y轴像素,进一步地,取消了LSTM的CLDQN-C算法性能下降程度较高,说明LSTM可以发现隐藏在股票时间相关序列中历史价格规律,过去的历史数据影响因子可能会在未来股票市场变化中重现,有效地提高了模型收益能力。
(3)动量反转效应。通过对2018年股票的动量收益情况分析,可以发现市场整体环境对个股收益有着不同的影响,对于大盘股和小盘股的影响存在明显差异,小盘股对动量反转反应比大盘股更明显,紫光股份的动量效应比招商银行的动量效应更明显,市场处于上升阶段时CLDQN动量效应的表现优于熊市。
(4)从整体上看,净月平均收益(月平均收益-大盘月平均收益)在2017年、2018年、2019年逐年下降,可以认为算法在近期时间点表现优于远期时间点,可能的原因是由于训练集为2005年12月年至2016年12月,从经验回放池中的抽取的样本数据趋向于近期时期产生的数据,神经网络参数发生了迭代更新,当被应用于2019年时,由于距初始训练数据时间间隔变长,市场情况发生了变化,模型不再适应新的市场变化规律,导致CLDQN在距离训练数据时间较近的2017年效果优于远期2019年。
(5)决策树算法。从模型的逻辑上来看,决策树方法更符合价值投资理念,股票的基本特征,如市盈率、市净率、净资产收益率等指标对决策树影响更大,微观层面影响投资意愿,更倾向于长期投资,然而由于中国股市散户投资者多,交易频率高,风险承受能力较差,追涨杀跌现象严重,导致决策树算法效果不佳。
3.3.2 年化夏普率
如图3显示了不同的交易策略年化夏普率(描述资产收益对投资者所承担风险的补偿程度),年收益标准差(收益率的变动大小,描述股票投资的风险程度)、最大回撤率(描述投资者可能面临的最大亏损与抗风险能力)的评测结果,从图中可以发现以下规律:
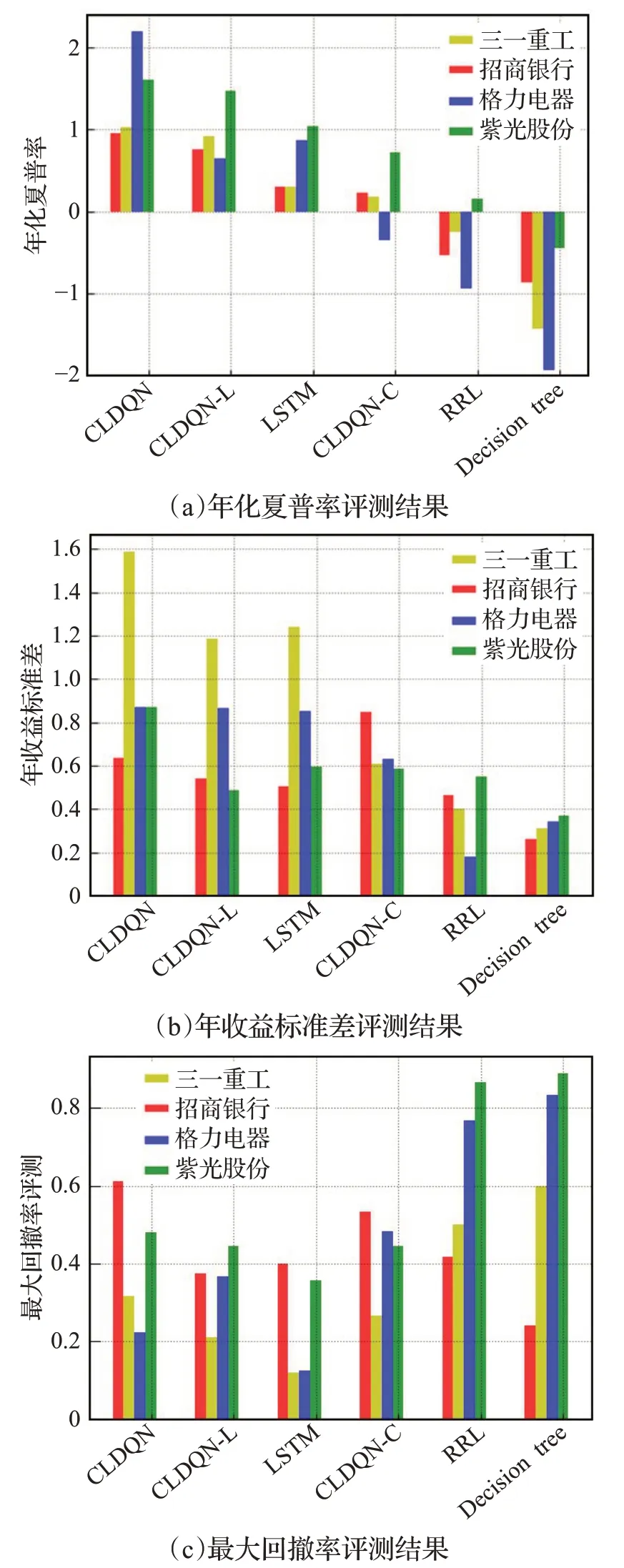
图3 年化夏普率、年收益标准差和最大回撤率评测Fig.3 Evaluation of annual sharp rate,annual return standard deviation and max dawndown
(1)本文提出的CLDQN算法整体上年化夏普率、最大回撤率都优于基准算法,CLDQN-C与LSTM算法的年收益标准差相近,可能原因在于LSTM对短期的时序数据规律敏感,能够快速捕捉到新变化的市场规律。决策树算法对动量因子的反应较为激烈,由于中国股市的透明性与不确定性比一般市场高,导致下一轮的回撤率更高。
(2)CNN作用。从图中可以看到,CNN模块对算法收益的重要性不如LSTM模块,但是CLDQN-C年收益标准差较低,说明CNN能够多角度融合不同来源影响因子,有效地稳定模型,提高鲁棒性。
(3)市值效应。紫光股份的最大回撤率最大,年化夏普率最低,原因在于紫光股份股票流动性较好,流动性与公司规模在截面上高度相关,对账面市值比的影响是长期的,市场对股票价格冲击大,公司规模与账面市值具有反向替代作用。
3.3.3 交易费用作用
影响股票投资收益主要有两部分,包括对行情规律的准确描述,以及交易成本对收益的影响。接下来讨论交易成本(ρ=0.000 5,0.001,0.001 5,0.002)对整体收益的影响。以CLDQN为例,结果如表2所示。
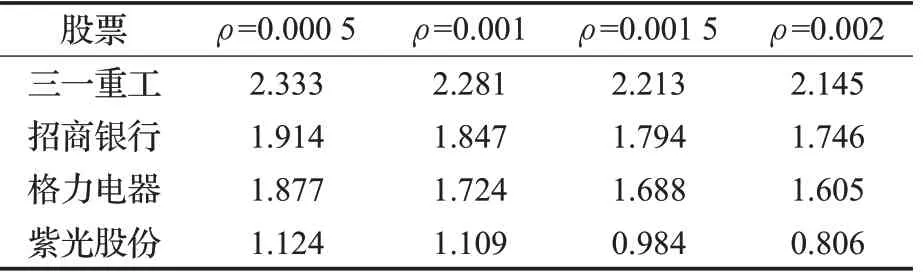
表2 交易成本对交易回报影响评测Table 2 Impact evaluation of transaction cost on return
从表中可以看出,随着交易成本增加,交易量明显减少,总回报收益逐步下降,在市场混乱时期,买卖双方的比例相对不平衡,降低交易成本会提高换手率,预期回报表现较好;当交易成本过高时,抑制金融市场过度投机,高流动性资产比低流动性资产所吸引的风险更高,市场波动性下降以减小市场风险,个体交易者的交易成本增加与价格下滑效应结合,总收益下降可以部分地由总交易成本过高来解释。此外,由于A股为散户型市场,交易费用提高不会降低风险资产流动性,总交易成本上升,因此从表中可以看出紫光股份的总收益的下降趋势最为明显。
3.3.4 证券指数对夏普率作用
为研究各证券指数对夏普率的影响,在产生蜡烛数据图阶段,依次剔除不同指数(包括上证50指数、沪深300指数、中证500指数、深证100指数)数据,此时CNN的输入只包含6组向量矩阵。实验结果如表3所示。
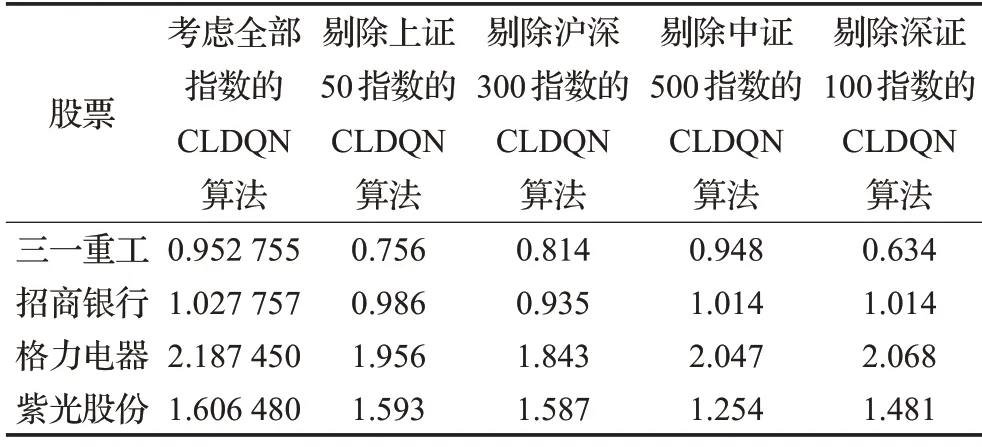
表3 证券指数对夏普率影响评测Table 3 Impact evaluation of stock index on sharp rate
从表中可以看出,不同指数对股票的夏普率影响程度不同,上证50指数对三一重工影响程度最高,其夏普率下降最快,沪深300指数对格力电器影响程度较高,中证500指数对紫光股份影响程度较高,说明外在消息面与投资者情绪产生的影响较大,深证100指数对三一重工影响较高。以上现象原因主要有两点:(1)深证100指数成分主要由交易活跃的股票组成,三一重工有相对较高成交量,因而所受影响最大。(2)对于市值较高的股票,如招商银行,股票趋势与大盘指数有较高关系,当市场变化剧烈时,高市值股承受的风险更高,夏普率下降明显。一般而言,个股的预测结果误差较大,夏普率较低,而大盘指数的预测精度一般较高,总体上的夏普率也更高。整体上,本文采取的多因子模型有较好的适性,夏普率更高,平均收益标准差更低,效果较好。
4 总结与展望
本文提出了一种融合了CNN与LSTM的深度强化学习股票策略交易算法CLDQN,深度强化学习算法性能很大程度上取决于所能表达的完整环境状态特征,CLDQN使用价格曲线、股指曲线、技术、信息、市场因子组成的向量作为CNN全局输入,利用LSTM寻找时间序列规律,引入随机噪音与模型训练正则化增加鲁棒性,降低模型过拟合,在真实数据集上比对了不同基准算法的累积收益率、年化夏普率、年收益标准差、最大回撤率,实证结果表明CLDQN算法的累积收益率更高,鲁棒性更好,扩展性强。
深度强化学习算法的基本逻辑与人类思维逻辑相似,代表了自动化交易最有可能的发展方向。未来工作可以从以下几个方面考虑:(1)大多数金融RL使用探索-利用模式,外界非常变性数据有重要价值,考虑引入行为金融学理论,将市场情绪与投资者情况纳入到影响因子中。(2)可解释性,投资者希望投资逻辑有明确的解释,以处理不断变化的市场状况,考虑加强认知科学对深度强化学习投资组合优化解释作用。(3)引入迁移算法应用到DRL中,以解决真实市场中的有效数据稀缺性问题。
