基于智能用电网络的负荷状态与类型在线辨识
2022-04-08郭治远李志勇邵洁黄婷周欢范帅何光宇
郭治远 ,李志勇 ,邵洁 ,黄婷,周欢 ,范帅,何光宇
(1.电力传输与功率变换控制教育部重点实验室(上海交通大学),上海市 200240;2.上海交通大学电子信息与电气工程学院,上海市 200240;3.国网上海浦东供电公司张江科学城能源服务中心,上海市 201210;4.国网上海市电力公司电力调度控制中心,上海市 200122)
0 引言
用电侧是智能电网的重要组成部分,包含多类电器设备,产生的数据量巨大。目前基于物联网技术将海量电器负荷聚合形成的智能用电网络已具备可观的产业规模。在此背景下,将负荷辨识技术和智能用电网络的主动控制手段结合起来,对内可促进需求侧安全、经济运行,对外可作为虚拟电厂参与电力系统调节,促进新能源消纳,有效推动国家“双碳”目标的实现。
智能用电网络是由智慧网关及其管辖的插座、开关等终端组成的用电侧管理系统[1],相关产业技术日趋成熟、市场规模巨大,目前智能控制产品市场已达200 亿元以上[2]。基于智能用电网络的负荷辨识能够提供监、管、控一体的闭环管理,是以直接控制负荷为手段的需求侧管理的先决条件[3],能够为违禁电器检测、故障自动诊断等应用提供信息基础[4],具有重要的研究价值。
目前,电器负荷的状态辨识暂无统一的定义,在非侵入式负荷监测领域,较常用的定义包括两类:1)将功率数据聚类产生的类别作为电器状态[5-6];2)视电器功率每1 W 为一档,每个档位为一个状态[7]。然而,这些定义常适用于能量分解,不能明确地反映电器实际的运行工况。在设备故障与健康监测研究中,电器状态则往往指电器的退化或健康状态[8],一般针对特定设备,缺乏通用性。其他关于电器状态的定义还有:光、声、电等信息反映出的电器具体动作状态[9];暂态层面家用负荷启动及关闭的数据形态[10]。以上定义均不能从易于量测的功率数据中挖掘电器的运行工况,为状态这一含义的扩展应用带来了局限性。
在负荷类型辨识方面,文献[11]采用Bagging、Boosting 等多种方法对办公环境下的插座负荷类型进行在线识别,文献[12]提取了功率、使用时间和地点等19 种特征,采用随机森林方法对插座类型进行识别,其插座负荷辨识采用了多分类视角,且特征提取选取了数据的统计特征,导致扩展性较差。在非侵入式负荷监测领域,文献[13]对高频场景下的负荷投切采用模拟退火方法进行特征提取并利用贝叶斯算法进行分类,文献[14]对低频数据使用多特征融合及隐马尔可夫模型(hidden Markov model,HMM)实现类型辨识及能量的分解,但采用的前向算法需依赖较长一段时间的跟踪。智能用电网络数据采集周期在秒级以上,而非侵入的方式在低频场景更多关注于负荷能量的正确分解,对类型的辨识难以同时兼顾实时性和准确率,同时可扩展性的讨论也相对较少。
鉴于此,本文提出改进分段算法并结合隐马尔可夫模型识别具有渐变特征的电器状态功率数据,实现识别状态与电器工况的对应;在低频数据场景实现接入2 min 即可准确辨识电器类型,并通过单分类视角,结合特殊工况的特征提取手段以及未知负荷的增量辨识方法加强算法的可扩展性。实证表明,所提方法对于负荷的类型和工况状态能够准确、快速地进行识别。
1 智能用电网络及其负荷辨识挑战
智能用电网络一般特指基于高级量测体系(advanced metering infrastructure,AMI)的用电侧能源管理系统,其典型网络拓扑可分为感知层、传输层、平台层与应用层,如图1 所示。其中,感知层包含了插座、开关、红外遥控等具备量测与控制功能的智能终端;传输层一般为网关或协调器,用于聚合底层各终端设备,并与平台和应用层进行交互。智能用电网络旨在为用户提供智能化的用电服务,以及对需求侧进行管理[15]。
智能用电网络通常以自趋优的节能或安全用电作为实施目标。自趋优控制的先决条件即为网关自主辨识所辖负荷类型和运行状态,继而基于评价模型来调节,该过程隐含了量测—辨识—控制—量测的闭环管理[16]。智慧网关先基于来自智能插座的负荷数据进行快速负荷类型和状态辨识,再结合辨识结果和运行数据对电器进行优化控制,最后通过反馈的电器运行数据进行下一次优化控制,这样循环直至满足停止条件。基于此,智能用电网络中的负荷辨识具有如下挑战:
1)以实现控制为目标:辨识的目标是为后续的负荷控制提供信息基础,因此需建立电器类型、接入插座和运行状态之间的强映射关系。
2)低频场景下的准确率要求:智能插座的采样频率通常不高,为1/60~1 Hz,需在低频的数据条件下保证负荷辨识准确率,避免错误的控制。
3)实时性要求:优化控制要求负荷类型和状态辨识具有高时效性,否则将失去控制的意义。
综上所述,在低频场景下,以智能电表数据为基础的非侵入式负荷辨识技术并不完全适用于智能用电网络的闭环管理控制体系,特别是在房间内有多台相同类型电器时无法明晰具体哪个电器需调控,这增加了智慧网关自趋优式控制的难度。因此,本文提出了适用于智能用电网络的电器负荷辨识方法及其技术架构。
2 电器级负荷的状态感知与类型辨识方法
2.1 基于事件的量测机制与负荷在线辨识流程
智能用电网络是以事件驱动方式进行量测数据上传的[16],即在智能插座内,当前量测结果与上一时间周期的量测结果产生一定变化后再进行上报,该方式实现了动态可变的精准数据采集和稳定实时通信。因此,量测到的电器功率具有连续性,需先从连续数据点中对电器的接入或断开进行检测,负荷辨识算法仅在电器接入时进行。
基于该方式,将电器的工作周期定义为:在插座无负荷时,产生了事件则认为电器已接入,当检测到功率持续接近0 一段时间时,认为电器工作已结束,插座进入无负荷状态,如此循环往复。基于该方法的负荷在线类型及状态辨识流程如图2 所示。
由图2 可知,在首次事件产生后,可对每个事件突变发生点进行负荷状态序列辨识和更新;在电器接入后的2 min,可结合已有状态序列进行电器类型识别。实际应用中一段数据的辨识过程如附录A 中图A1 所示。

图2 事件驱动量测机制下的负荷在线辨识流程Fig.2 Load monitoring method based on event-driven multi-agent measurement mechanism
2.2 电器状态的感知与建模
状态感知的目标是检测当前电器工作的运行工况,主要应用在电器故障自动诊断和不可中断工作环节的控制中。
2.2.1 电器工况的数据形态
电器工况的转变一般可由功率数据出现不同趋势和形态来表征,如附录图A1 和表A1 所示。常见电器工况的功率形态可分为以下2 种:1)平直片段,如图3(a)所示的阻抗型电器;2)曲线片段,如图3(b)、(c)所示的压缩机功率、正温度系数(positive temperature coefficient,PTC)热敏电阻元件加热启动时的非恒温工况[17],以及充电电池类电器恒压或涓流浮充工况[18]。
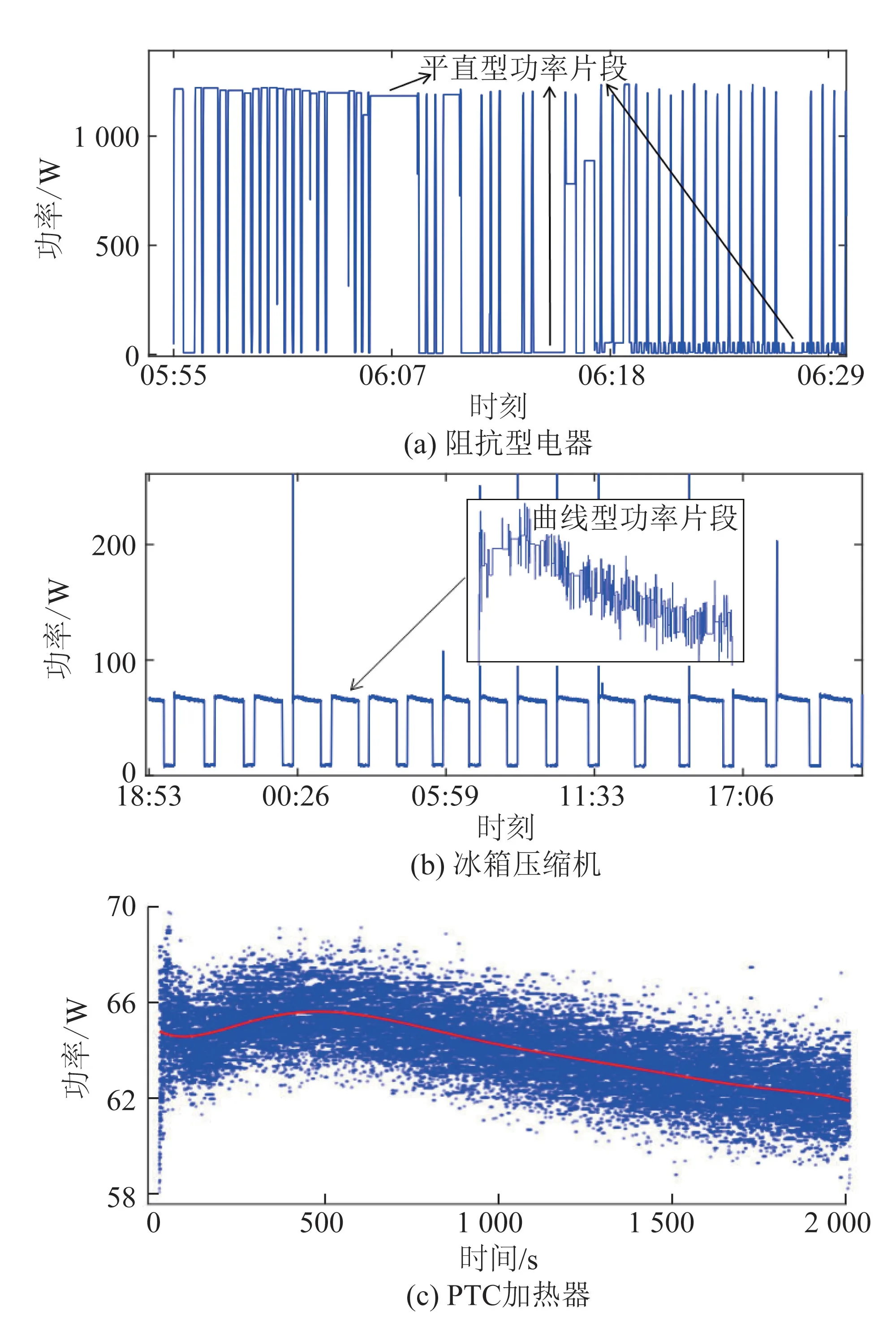
图3 电器功率数据形态Fig.3 Patterns of appliance power data
为此,可将实际电器的量测数据组合为不同形态功率片段序列。

式中:PMeasure为电器工作的量测曲线;为第i个功率片段。
2.2.2 基于改进CUSUM的分段算法电器的运行工况常基于双边累积和(cumulative sum,CUSUM)算法[19]进行判别,其通过累积统计量En判断是否发生分段,如式(2)所示:

式中:xn为第n个点的量测值;μ0为上一异变点到当前时刻的量测均值;β为可能存在的噪声水平或稳定阈值;或表示数据整体的分布向增大或减小偏移的累积量,当En大于某一阈值H时判断发生分段。
在该算法中,其弊端为难以划分具备相同趋势的数据段[20]。因此,本文做出如下改进:
1) 将累积量改为一阶均差值xn=fdiff[PMeasure(t)],旨在刻画累计的数据趋势。
2)增加稳定时间累积判据,在趋势累积判定异变点之外,当xn<β,累积时间Tn超过一定阈值,也视作异变点。
3)改进异变点判据,当且仅当以下条件均满足才视作产生异变点,式中sgn(·)为符号函数,x0为上一异变点的一阶均差值,TH为稳定时间阈值:
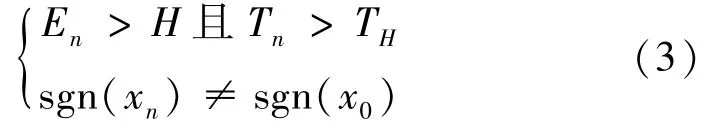
以上改进中,前两个改进点实现了将数据的增大、减小或平稳时间进行累积以判断异变点,改进点3)则避免了同一趋势下的数据因阈值变化而导致的错误分段。
2.2.3 基于k-medoids 聚类和隐马尔可夫模型的电器状态参数刻画
为实现电器工况的实时跟踪,需对分段后的功率片段进行对应状态的辨识。本文以隐马尔可夫过程刻画电器的状态变迁,其过程如下:首先,在训练阶段采用k-medoids 聚类方法对历史数据中的同一状态片段进行聚合;然后,基于频数统计法分别计算隐马尔可夫模型中的各参量;最后,在实时辨识阶段采用维特比算法进行状态序列的跟踪。类似方法已在较多文献中被提及[7],在此不过多赘述。
需要说明的是,对于HMM 模型参数中的观测输出概率,采用二元正态分布fGuassian-2d(·)进行计算,统计量为:与拟标准曲线间的动态时间规划距离fdtw(Pstandard,Pseg) 和持续时间Tseg,如式(4)所示。

式中:表示第t段状态;ot表示第t段观测,即分段得到的功率片段;si为电器模型中的第i个状态;Pseg为当前分段得到的功率片断,表示由该状态历史数据拟合得到的标准曲线,如图3(c)中红线所示。
2.3 基于单分类的负荷类型在线辨识
为充分考虑实际应用,类型辨识需具备较好的扩展性[21],具体体现在:
1)独立性:未知电器负荷不影响已有类型的识别效果,所提技术路线是通过单分类模型实现的。
2)泛化性:同类但不同品牌的电器同样能够识别,所提技术路线是通过结合电器特有工作环节实现的。
3)自动扩展性:接入的未知负荷能够自主创建新的标签,所提技术路线是通过提出扩展半径的增量支持向量数据描述(incremental support vector data description,ISVDD)算法实现的。
2.3.1 单分类模型
在未经特殊处理的有监督多分类模型中,输出结果必为某已知类。若接入新型电器负荷,则会产生误识别现象,不满足独立性要求。其原因在于一般的多分类算法默认样本标签属于训练集中的某一类,但该假设不适用于设备类型丰富的用户侧。
而在单分类模型中,单一电器模型仅判断输入样本是否为自身类别,顶层分类器中的各单分类模型结果互不影响,因此可以不为任何一类。新负荷分类正确则全部输出,否则辨识为未知电器,避免了误识别现象,可满足独立性要求。因此,本文采用单分类支持向量数据描述方法(support vector data description,SVDD)[22]来解决此问题。
2.3.2 特征选取
不同品牌的同类电器可能在功率范围上有所区别,且有时会具有不同的暂态特征。即便如此,同类电器却无法避免存在类似的运行工况,例如,冰箱必然具有压缩机工作这一工况。所以从这种特殊工况出发,采用方差较大[23]的算法选取宽松的范围,即可实现对不同品牌的同类电器辨识,解决泛化性要求。为此,本文提出基于特殊工况的特征选取方式,选取的特征如下:
1)特殊状态统计特性:功率均值μstate、功率持续时间Tstate以及平均均差,即在本状态Tstate持续时间内,累积功率的一阶均差xk的绝对值并求平均。对同类电器的特殊工况,利用HMM匹配后,提取此状态的统计特征作为分类属性。
2) 状态序列的观测概率-log[p(Pmeasure|:该特征表示对于某类电器的HMM 模型,产生当前量测数据的对数概率,这样既能反映每个状态是否得到正确匹配,又可验证状态彼此间的转移是否符合电器模型。
取2 min 长度的电饭煲量测数据,上述特征归一化后的分布如图4 所示。在选取典型研究[12]所述特征重要性最高、区分度最好的统计特征时,特征分布不仅存在与其他电器类别的交叠,而且品牌不同的2类电饭煲特征向量分离较远。而本文提出的特征中,在消除了与其他类别交叠的现象的同时电饭煲自身类别数据分布更加紧密。
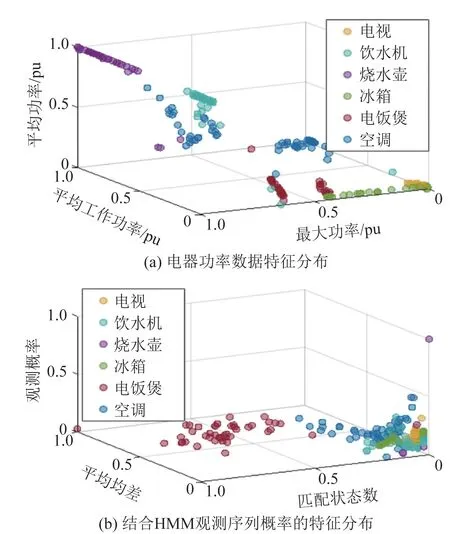
图4 电器功率数据特征分布对比Fig.4 Comparison of characteristic distribution of power data
2.3.3 扩展半径ISVDD 算法
新型电器负荷的扩展需要以增量的方式处理无标签数据,相关算法理论基础较少,为此提出启发式的扩展半径ISVDD 算法来实现对新接入的类别进行自动标注。对于未匹配到任何现有类别的负荷数据,采用如下所示的额外流程处理。
1)构建特征向量:取工作全过程的数据经CUSUM 算法分段后,以每段数据的功率均值、持续时间、最大最小值构建特征向量。

2)初始数据集建立:样本量较少时无法进行参数的训练,因此首先以范围选取的方式积累同类的初始数据集。

式中:yj为第j个伪标签;为预测标签;为实测特征向量;为标签j全部样本特征向量的中位数,取每个维度元素的1/10;εj为判别范围。
3)当积累数据量达到10 条,扩展半径ISVDD 算法开始运行,流程如图5 所示。

图5 扩展半径ISVDD 算法Fig.5 Incremental support vector data description with extended radius algorithm
图5 中,Xj表示伪标签类别j的全部样本,fISVDD(·) 表示通过增量SVDD 算法[24]计算得到新半径rt的函数,D() 表示SVDD 算法定义的输入样本的球心距离。半径的自动扩展主要通过参数C、ρ和δ实现。C为初始半径扩展超参数;ρ为小于1的衰减系数,用于控制半径收敛;δ为增量放大系数,用于发现距当前超球面较远的样本时进一步增大半径。
区别于常规SVDD 仅将落在超球面内的样本划分至自身类别,扩展半径ISVDD 算法中,对落在超球面附近的样本,也视为自身类别,即增加扩展半径以增大判定范围。同时,为避免其他类别与自身类别的样本由于密度相连现象导致的超球面无限扩展,在半径更新阶段利用小于1的衰减系数ρ来控制半径收敛。
3 实证分析
3.1 测试方法及测试环境
以实地部署的智能用电网络及在线辨识系统进行分析。插座采用 RN7211 芯片作为主芯片、CS5460C-ISZ 电能计量芯片作为采集芯片、CC2530 Zigbee 芯片作为通信模块;网关除Zigbee 模块外,采用Cortex-A7 作为CPU,并配置1 GB DDR3 作为内存,8 GB EMMC 作为存储设备,Mali400MP2 作为GPU,基于Linux 平台进行开发;服务器采用IBM System x3550 M3 服务器。
各插座接入电饭煲、冰箱、电视、烧水壶、饮水机、空调这几种电器进行功率测量及识别,如附录图A3所示,数据经过重采样后精度为1 Hz。部分数据如图6 所示,各实验中数据集的具体情况如附录表A1、A2 所示。

图6 本文建立的数据集Fig.6 The data set built in this paper
作为对照,选取了上述6 种不同品牌的电器进行对比,以笔记本电脑、打印机、电磁炉等附加电器的功率数据作为未知电器组成补充数据集。相关数据详见附录图A2 和附录表A3。
3.2 负荷状态辨识测试结果
采用滑动窗分段[25]和直接聚类[6]方法与所提改进CUSUM 分段方法分别作用于电热饭盒和电动汽车的电池,旨在验证所提状态划分算法的准确性,结果如图7 所示。
由图7 可知,所提改进CUSUM 方法对渐变特征的工作环节辨识效果显著好于聚类及滑动窗算法。在电热饭盒启动时,内部PTC 电阻温度不断升高,功率逐渐下降,恒温后功率保持恒定,滑动窗算法将升温和恒温阶段划分为了同一段,而聚类算法则将升温阶段划分为三段,改进CUSUM 算法做出了正确的划分。对于电动汽车的电池充电,其平直段为恒流充电,下降段为恒压充电,最后功率较低的平直段为涓流浮充,滑动窗算法混淆了恒流和恒压阶段,且将恒压部分分为两段,聚类算法对恒压阶段的检测存在较大延迟,且误分为两段,改进CUSUM 算法做出了正确划分。

图7 本文方法与滑动窗、聚类方法对比Fig.7 Comparison of segmentation results
进一步,以F1 值和平均绝对误差(mean-absolute error,MAE)作为量化指标,旨在说明准确性和实时性,2 个指标的计算方式如式(7)和式(9)所示。


式中:γF1为F1 值;TP为真正例,即实际为真且预测为真的样本数;FP为假正例,即实际为假而预测为真的样本数;FN为假反例,即实际为真而预测为假的样本数。F1 值越大分段效果越好[26]。

式中:CP为出现的分段点总数;P(i) -A(i)为预测分段点与实际分段点的间隔采样数。MAE 越小表示分段延迟越少。
用改进CUSUM 算法、滑动窗分段、直接聚类算法分别判定16 次电器运行的81 个分段点,F1 值和MAE 如表1 所示。
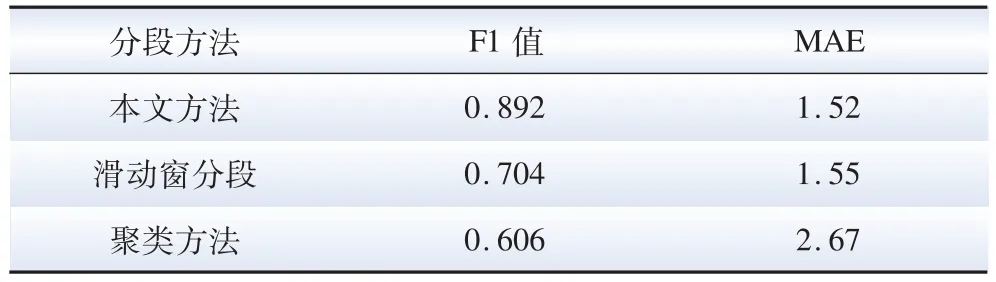
表1 分段效果对比Table 1 The result of segmentation
由表1 可知,所提的改进CUSUM 算法的F1 值高于其他两类算法,且检测延迟MAE 更小,表明在准确性和实时性上所提算法均优于滑动窗算法和聚类算法。其原因在于改进CUSUM 方法更符合以趋势反映工况变化的特点。
3.3 负荷类型识别效果
以基于功率统计量特征的k 近邻(k-nearest neighbor,KNN)和Bagging 方法[11]与所提的基于特殊工况特征的单分类算法进行对比。评价指标选取式(8)所示查准率P与查全率R,查全率反映对本类电器的识别效率,查准率反映对非本类电器数据能否有效过滤。
3.3.1 准确率分析
将原始数据集以3∶1的方式划分为训练集和测试集,基于特殊工况特征提取的单分类方法和基于统计特征的多分类方法查全率和查准率如表2 所示。

表2 训练集/测试集的类型识别结果Table 2 Type classification result of train/test set
从表2 可知,各方法均能达到较高准确率,故对算法的扩展性进行验证。
3.3.2 扩展性分析
1)独立性与泛化性。
扩展性体现在独立性和泛化性两方面。维持训练集不变,在测试集中,正类为同类但与训练集电器品牌不同的90 条数据,反类为44 条未知电器样本。查全率为正类误识别指标,反映泛化性要求;查准率为反类误识别指标,反映独立性要求,结果表3 所示。

表3 训练集/补充测试集的类型识别结果Table 3 Type classification result of train/extend test set
由表3 可知,所提基于状态和单分类的方法独立性和泛化性显著好于单纯利用统计特征且采用多分类模型的方法。对正类,识别冰箱、电视等功率随品牌变化的电器时,传统方法的查全率大幅下降,而所提的基于电器特殊工况特征方法更具普适性,查全率能维持较高水平;对于反类,多分类模型中大量未知样本被误识别,冰箱的查准率甚至低于20%,而单分类模型查准率受未知负荷的影响较小。
2)自动扩展性。
为验证本文所提扩展半径ISVDD 算法能够增量式地对未知电器进行分类,将表2 训练集中的电饭煲数据和反类数据打乱后依次输入算法进行训练。首先验证分类半径在长时间电饭煲数据的输入下能否有效收敛,其次分别考察新增数据后的查全率和查准率能否最终能达到理想的水平。计算查全率和查准率时,正类测试集为表2 电饭煲的测试集,反类测试集为表3的反类数据。实验结果如图8 所示。

图8 扩展半径ISVDD 算法结果Fig.8 Result of incremental support vector data description with extended radius algorithm
从图8 中半径变化规律可见,在新数据加入后,扩展半径ISVDD 算法一开始由于新增了距离较远的支持向量,超球面半径逐渐增加;后续更新中,由于超球面已覆盖较大范围,新数据大多出现在超球面内,ISVDD 算法半径不变[24],衰减系数ρ使半径逐步收敛。此特点意味着算法会先贪心式地寻找更多可能的同类数据,再收敛以避免无限扩展。
对于查准率和查全率的变化,由于特征向量考虑了CUSUM 分段后每一段功率的输入,对数据形态相似性的要求极高,因此反类数据不会误识别,查准率严格为100%。而对正类,经过增量式的扩展学习后,查全率能够达到90% 以上。鉴于扩展半径ISVDD 算法并未有先验的带标签数据输入,而是在第1 条电饭煲数据出现后自动进行同类数据的发现,因此能够随系统运行自动实现新类别数据集的扩展,使得智能用电网络中无标签的量测数据也能够发挥更大价值。
4 结论
具备电器级负荷控制功能的智能用电网络自趋优运行的前提是对负荷信息的感知。本文提出了扩展应用潜力较高的负荷状态与类型辨识算法,经实证分析有以下结论:
1)本文提出的改进CUSUM 方法的状态划分结果能够对应电器工况;而基于状态的SVDD 类型辨识算法以及扩展半径ISVDD 算法则具备较好的可扩展性。
2)以上辨识算法都具有实时、准确的特点,能够满足智能用电网络低频量测场景下自趋优控制的需要。
对智能用电网络的电器负荷数据的挖掘可结合类型和状态信息进一步扩展,如基于状态进行电器故障辨识、效用检测,基于负荷工作时间特性进行用户行为的刻画等,这些多元化信息的探索将是未来的研究方向。
附录A

图A1 实时识别过程及各步骤中间数据形式Fig.A1 Real-time identification process and intermediate data of each step
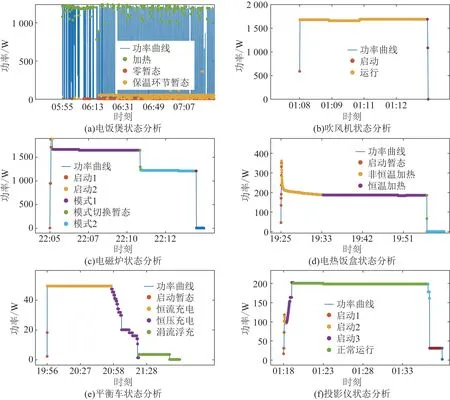
图A2 部分电器的状态分析结果Fig.A2 Analysis results of some electrical appliances states
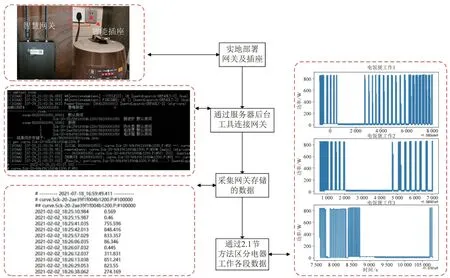
图A3 基于智能用电网络的数据收集过程Fig.A3 Data collection process based on Smart Electric Appliance Network
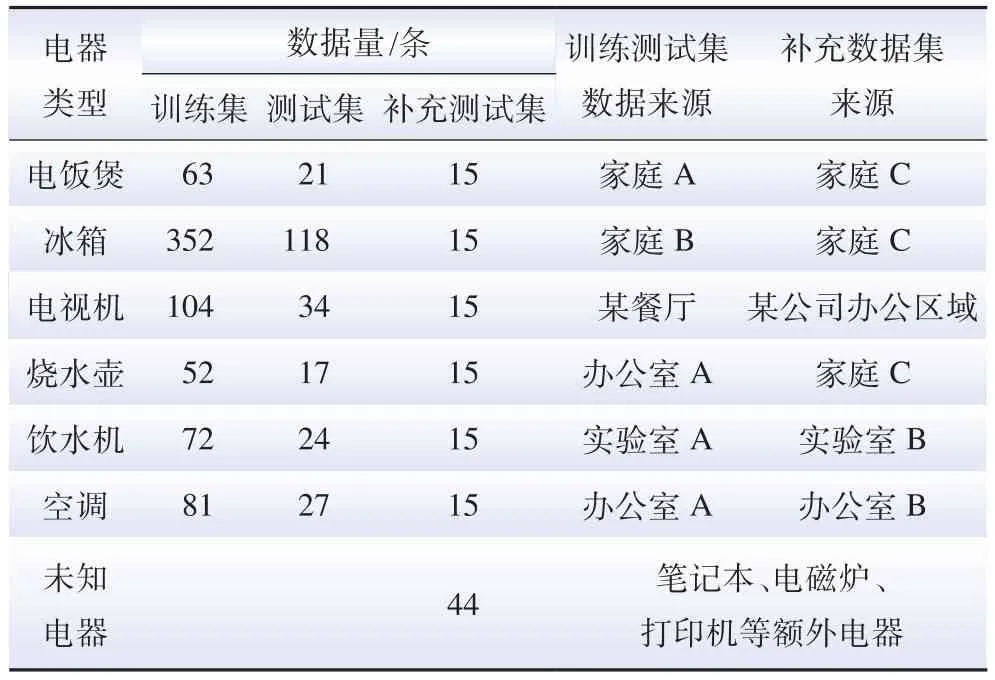
表A1 算法独立性与泛化性实验数据集构成Table A1 Data set for the experiment of algorithm independece and generalization

表A2 算法自动扩展性实验数据集构成Table A2 Data set for the experiment of algorithm outomatic scalability
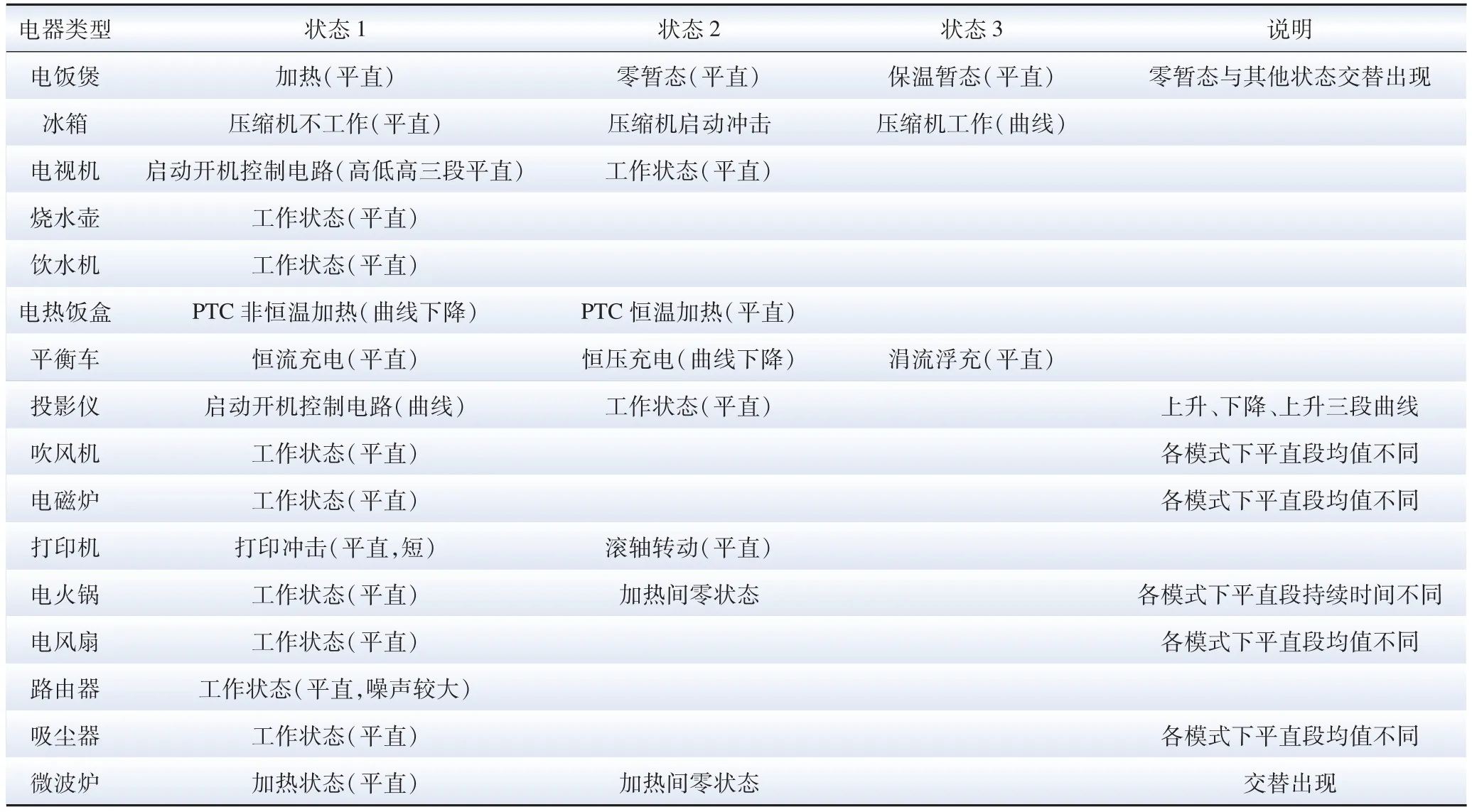
表A3 电器功率状态特征统计Table A3 State characteristic statistics of electrical appliances power
