基于自然语言处理的产业链知识图谱构建
2022-04-07毛瑞彬李爱文周倚文潘斌强
毛瑞彬,朱 菁,李爱文,周倚文,潘斌强,岳 琳
(1.武汉大学信息资源研究中心,武汉 430072;2.深圳证券信息有限公司,深圳 518022;3.天津大学管理与经济学部,天津 300110)
1 引 言
产业链作为一个产业经济学的概念,指各个产业部门之间以产品或服务为纽带,基于一定的技术经济关联,形成的具有价值增值功能的链网式关联关系形态[1]。随着全球化的发展,产业链对国民经济的影响无处不在。国家产业结构持续优化升级,广东省积极推动区域产业升级转型[2],中部[3]和西部[4]省份承接东部转移产业。在投资领域,股票市场基于产业链建立投资组合[5],传媒类上市企业通过投资寻求全产业链经营[6]。金融产业中的P2P网贷[7]、商业银行[8]的风险影响着国家金融稳定。因此,产业链研究在投融资、金融监管和区域产业规划等领域有重要意义。
目前,产业链研究报告主要由券商、研究所和咨询机构的行业研究人员人工编写,其主要形式是文本,不利于进行自动检索、分析和计算。从形态特征来看,产业链是典型的网络结构,因此使用知识图谱对产业链信息进行组织和存储,是较为可行的解决方案。从相关研究来看,①大多面向单一产业的知识图谱构建或面向产业竞争情报服务的框架和模型,没有把产业链和知识图谱有机地结合起来;②行业关系和数据都蕴含在研究报告、上市公司公告和互联网新闻等海量的文本中,传统的构建和融合方法无法有效解决行业名称融合中未登录词的挑战问题;③缺乏统一的产业链本体库。以上对于产业链知识图谱的构建提出了较大挑战。
本文面向产业链在现代经济活动中的应用,针对金融领域文本特点,提出基于领域语言模型的知识抽取方法,进行产业链知识图谱构建,其主要创新点有:①首次提出了产业链本体库,为产业链知识图谱的构建提供了良好的基础;②基于领域语言模型的实体和关系联合抽取,有效地解决复杂金融文本的知识抽取难题;③结合无监督共现词语发现算法和领域语言模型,较好地实现了知识融合。
2 研究现状
2.1 产业链分析方法
目前国内外研究者一般通过分析专利[9]、专利组合[10]、论文等构建技术链[11]和创新链[12]分析企业合作竞争情况,构建产业竞争情报分析框架[13],分析上下游行业企业的竞争能力。这些方法的数据源是专利和论文,获取较为方便,格式统一,分析起来较为便捷。但也存在缺点:一是受专利和论文领域限制,覆盖的主体类别较少;二是由于专利和论文中并不存在上下游关系,难以实现自动化构建。
在分析模型上,迈克尔·波特[14]提出了影响产业吸引力以及现有企业竞争战略决策的五力模型。基于SCP(structure-conduct-performance)范式构建产业竞争分析模型[15]提出了市场结构、市场行为和市场绩效三个层面的刻画方法。双钻石模型[16]在波特钻石模型原有六大要素的基础上增加了“区域文化”和“外来投资”两大要素。这些模型和方法需要采集市场产量、销量、价格、利润等数据,主要针对特定的行业或企业,如果推广到构建包含所有国民经济行业的全产业链,实施难度和成本都比较高。
2.2 知识图谱构建方法
知识图谱是通过网络表示数据,网络中的节点和边代表着实体和关系。目前,英文维基百科知识图谱主要有Freebase[17]、DBpedia[18]、YAGO[19],中文维基百科知识图谱有Zhishi.me[20]、CN-DBpedia[21]、PKUBase等。谷歌、微软、百度等厂商建立了面向搜索引擎的知识图谱。国内企查查、天眼查、启信宝、BBD数联铭品等科技企业以工商数据为基础构建商业领域知识图谱,包括供应商、客户、诉讼等信息,提供企业关联关系查询和计算等功能,这些商业领域知识图谱关注企业之间的关系,产业链则是从宏观到微观,关注产业的规模和发展以及企业之间的竞争与协同。目前,专门针对产业链的知识图谱系统性构建方面的研究还较少,现有研究大多针对单一产业,如气象农业[22]、商业[23]、教育[24]等。
因为领域知识图谱需要定义特定的数据结构,首先要进行本体构建[25],一般可以采用自上向下和自下向上两种方式[26]。本体构建需要考虑知识图谱的存储模型,存储一般有RDFs(resource description framework schema)和属性图两种模式,RDFs模式使用三元组形式,一般应用于本体复杂而实例较少的情况,如医药行业[27];而属性图较RDFs更加灵活,结点和关系支持多属性描述,能够有效节约结点数量,一般应用于实例数据量较多的情况,如金融领域[28]。
金融领域中文本数据占比较大,需要从文本中进行知识获取和知识融合[29]。知识获取主要指实体和关系抽取,国内外研究较多,如Bekoulis等[30]提出的多头选择模型、Chi等[31]提出的基于句子模型和多层注意力的方法,以及Zhou等[32]提出的强化学习的方法,这些都是基于双向长短时记忆网络(bidirectional long short-term memory,Bi-LSTM)的,无法根据任务进行动态优化。知识融合主要是对同义词的指向进行识别,其方法主要有聚类[33]、分类[34]和相似度[35]等,也可以根据已有的知识图谱进行嵌入学习和预测[36],这些方法大多针对维基百科类文本的处理,难以适应实体和关系复杂的金融领域。另外,传统的算法模型的通用性较差,其构建难度和成本也居高难下。
3 构建流程与方法
3.1 系统框架
产业链知识图谱的系统框架分为四层,如图1所示。第一层是数据源层,主要是产业链知识图谱的数据源头,包括研究报告、互联网新闻、上市公司披露文本等。这些文本数据包含大量行业实体、关系和元素数据。由于文本来源于不同的机构,如上市公司、研究机构和新闻媒体,因此它们对产业、行业和公司的理解和表达方式也不尽相同,对知识图谱的构建是个较大的挑战。
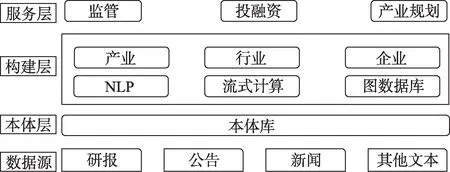
图1 产业链知识图谱的系统框架
第二层是本体层,这一层是产业链知识图谱的骨骼框架,是图谱的元数据。知识图谱一般包括本体和实例,产业链知识图谱也一样。虽然已经有很多学者提出自动构建本体库,但国民经济行业涉及范围广阔,使用专家模式具有更好的目标性,这也是本文采用的方式。本文在《国民经济行业分类》(GB/T 4754-2017)①http://www.stats.gov.cn/tjsj/tjbz/、《全国投入产出表》②http://www.stats.gov.cn/ztjc/tjzdgg/trccxh/zlxz/trccb/、GICS(Global Industry Classification Standard,全球行业分类系统)③https://www.msci.com/gics的基础上构建本体库。
第三层是构建层,在本体库的基础上,通过自然语言处理技术,从新闻报道、研究报告和上市公司公告文本中识别行业、上下游、典型公司和要素等实体数据,将识别的实体进行实时融合关联存储到图数据库中,这些数据作为本体库的实例化数据,本体和实例一起形成产业链知识图谱。基于流式计算,能够将各处理模块集成起来,实现管道式处理流程,针对每天新增的金融文本数据,进行自动化的处理和增量的持续构建。
第四层是服务层。通过产业链知识图谱,可以发现企业所在行业的发展趋势和行业规模,发现企业的风险和价值,面向证券监管、投融资和产业规划等实际应用场景提供服务。
3.2 构建流程
采用自上而下的方式,从海量的文本数据中构建产业链知识图谱,分为本体构建、自动构建和人工审核三个阶段,如图2所示。①http://www.stats.gov.cn/tjsj/tjbz/本体构建:产业链本体本质上是国民经济行业及行业属性的集合,需要专家进行总结和抽象,除了经济领域的专有知识外,还包括一些常识性知识,通过学习的方法构建,难度较大,成本较高,因此本文选择人工进行本体构建。②http://www.stats.gov.cn/ztjc/tjzdgg/trccxh/zlxz/trccb/自动构建:新闻报道、研究报告和上市公司公告文本大多以PDF和HTML形式存在,需要先统一转换为下游方便处理的文本格式。对文本进行预处理,把文本段落按照产业链要素类别进行分类,根据不同类别,进行实体和关系识别,最后进行知识融合。③https://www.msci.com/gics人工审核:通过自然语言处理技术识别的行业、上下游、同义词和要素等存在一定错误率,直接服务于投融资和监管仍存在一定差距,经过专家审核,不仅能够提升系统可用性,还可以通过改进语料库提升模型准确率。

图2 产业链知识图谱构建流程
3.3 本体构建
产业链本体主要考虑产业链上中下游细分行业及要素。以GICS为基础,将GICS四级分类体系扩展至五级,细化行业分类颗粒度。在分类体系扩展时主要遵循两个原则:①是否有上市公司以该细分行业作为主营业务;②该新增细分行业的市场规模是否足够大,是否具有投资价值。当细分行业满足任一条件时,即可新增细分行业。产业链要素是指以行业研究视角确定的、对产业链投资具有重要参考价值的数据,主要包括特定细分行业的行业定义、竞争格局、历史与趋势、行业规模等。行业数据的来源包括上市公司的招股说明书及定期报告、第三方机构公开发布的研究报告、重点行业网站发布的新闻舆情等。行业数据的选取注重时效性与权威性。典型公司是指特定细分行业内的龙头企业、海内外上市公司以及新三板挂牌企业;并且根据已有数据基础,将非上市典型公司根据公司规模、发展情况分为高新技术企业、路演企业和园区分层企业等;对数据较为完善的上市典型公司,则提供包括公司估值分析、企业经营状况分析等在内的结构化数据,帮助用户了解市场整体竞争态势。这部分数据属于结构化数据,获取和整合的方法与文本存在一定差异,本文构建的方法聚焦文本信息,因此下文不再赘述。产业链知识图谱本体库框架如图3所示。
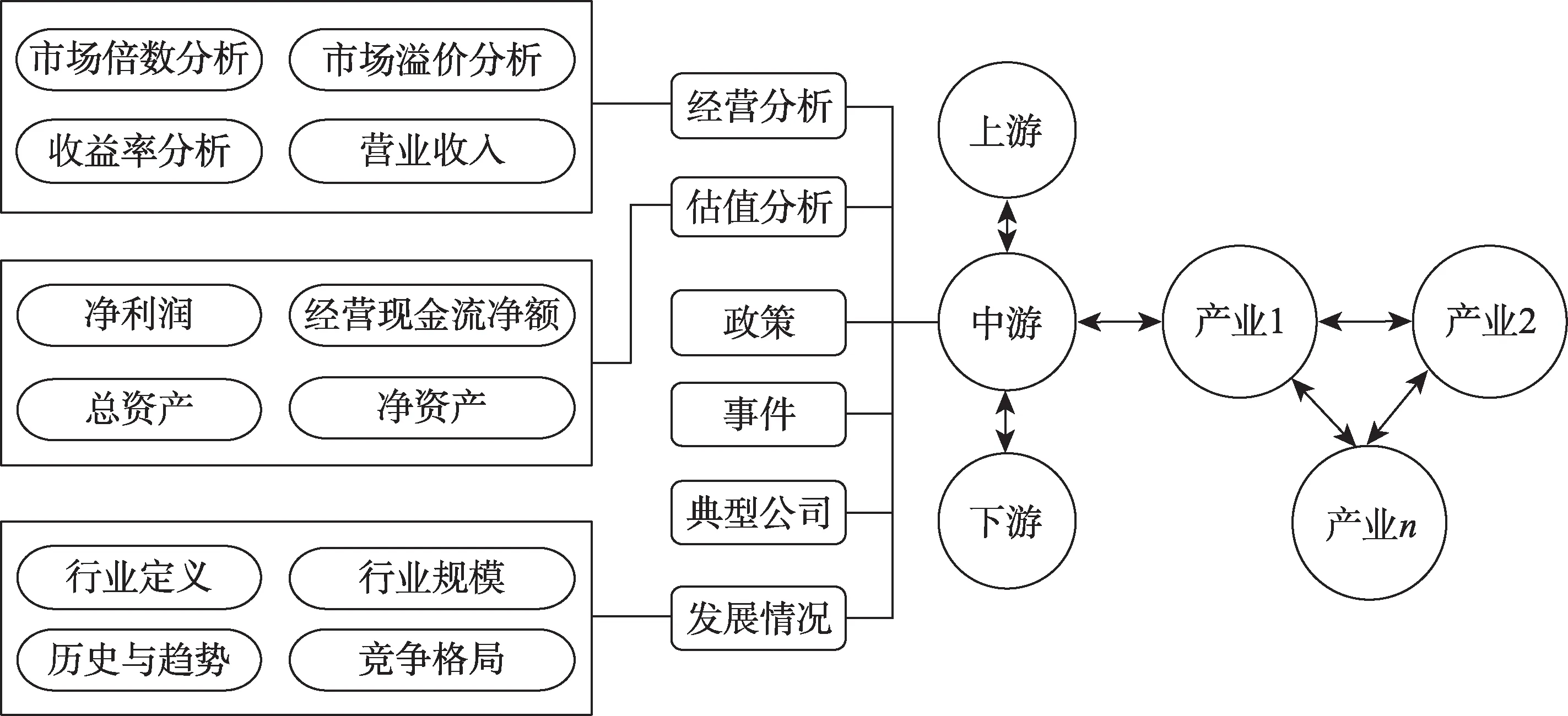
图3 本体框架
在本体框架中,核心类主要有产业、行业和企业(典型公司)。企业集合组成行业,行业集合组成产业。产业和产业之间存在上下游关系,如资源产业是制造产业的上游。一个产业由多个协同分工的行业组成,如制造行业,有生产零件的行业,也有集成组装的行业,这些行业也组成了上下游关系。行业包括经营分析、估值分析、政策、事件、典型公司和发展情况等属性,这些属性共同刻画了行业的规模和发展趋势等特征。其中企业包含了该行业所有企业,企业的属性包括工商、新闻、专利、文书,企业之间也存在上下游、诉讼、竞争、合作等关系。
4 面向产业链知识图谱构建的自然语言处理
产业链知识图谱的数据源主要包括行业研究报告、上市公司公告和互联网新闻等金融领域文本,金融领域含有大量的实体和专有名词,为提高模型算法的通用性,实现语义迁移能力,本文提出基于领域语言模型的知识分类、抽取和融合算法。
4.1 领域语言模型
传统语言模型是单向的,这使得在模型的预训练中可以使用的架构类型很有限,制约了预训练表示的能力。BERT(bidirectional encoder representation from transformers)模型[37]采用Transformer编码器作为模型的主体结构,完全基于多头注意力机制(Multi-Head Attention)实现语言建模。Self-Attention的Q(query)、K(key)和V(value)三个矩阵均来自同一输入,先计算Q与K之间的乘积,再除以尺度标度dk;其中dk为一个query和key向量的维度,利用Softmax操作将其结果归一化为概率分布,再乘以矩阵V就得到权重求和的表示。Multi-Head将一个词的向量切分成h个维度分别计算自注意力(Self-Attention)进行拼接,各维度的注意力计算参数并不共享。这样每一维空间都可以学到不同的特征,利用这些特征来调整每个词的重要程度就可以获得每个词新的表征。

谷歌的中文BERT Base语言模型是基于中文维基百科语料进行训练的,金融领域文本语言表现出了与维基百科不一样的特点,如大量使用短句、短句零指代或指代歧义等现象较为严重。此外证券领域的要素描述一般由时间、主体和具体值组成,与维基百科也存在一定区别。为了有效地对金融领域语言特征进行建模,有必要训练金融领域语言模型。
本文在中文维基百科语料的基础上增加了金融领域语料,包含公告、研究报告以及领域新闻,训练了证券领域语言模型,将语言模型封装成服务,为下游的分类、实体和关系的识别以及融合等多种任务提供支持,在给定的证券领域语料上,较使用谷歌BERT Base,本文方法的性能有一定提升。表1是在证券领域文本上分别使用BERT Base和本文的预训练领域语言模型在分类和实体识别任务上的性能对比。

表1 使用BERT Base和领域语言模型在分类与实体识别任务上的性能对比
4.2 文本分类
行业研究报告等文本大多具有篇章结构,每个篇章包含多个章节和段落,描述多个主题,如果不加区分地进行知识抽取,会对抽取模型形成较大挑战。因此,在进行知识抽取前,应该进行要素文本分类,然后根据不同类别进行抽取,提升抽取性能。
传统文本分类的特征工程工作量较大,利用BERT预训练语言模型微调做分类任务,能够减少特征工程的复杂性。将分类文本分割成字列表或词列表,在列表首尾加上对应的符号[CLS]和[SEP],获得字列表在词汇表对应的ID,进而可以获取对应的字向量表示;同理,可获得字对应的句子向量表示和位置向量表示。将字向量表示、句子向量表示、位置向量表示对应元素相加作为输入,经过BERT深层神经网络后,再使用Softmax或Sigmoid进行分类,最终输出向量的维度为分类数,向量中的每个元素代表每个下标对应类别的概率值,选概率值最大的下标对应的类别作为最终的分类结果。
4.3 知识抽取
产业链相关文本中除了大量行业名称实体和企业名称实体,还包含了事件、行业规模和上下游等复杂的实体关系集合,这些实体关系不是简单的上下连接,而是需要根据上下文进行复杂的逻辑判断,一个实体可能会跟多个其他实体产生联系。例如,“我国商用清洁市场从2009年以来经历了爆发式增长,从2009年的166.2亿元猛增长到2010年的600亿元,从2010年的600亿元增长到2012年的近885.6元”,该句中蕴含着<‘我国’,‘商用清洁’,‘2009’,‘166.2亿元’><‘我国’,‘商用清洁’,‘2010’,‘600亿元’>以及<‘我国’,‘商用清洁’,‘2012’,‘885.6亿元’>三个四元组,其中“我国”以及“商用清洁”与4个时间实体都有关系,每个时间实体又与金额实体一一对应。
针对行业规模抽取场景,我们优先选择了联合模型去处理,借鉴Multi-Head Selection方法,考虑到金融业务领域词语的专业性以及预训练语言模型的优势,本文设计了基于BERT和领域知识的多头选择算法,进行领域实体关系联合抽取,如图4所示。模型包括以下结构:Pre-training层、Fine-tuning层、NER层和Relation层。下文将对输入到输出所涉及的结构进行一一解析。
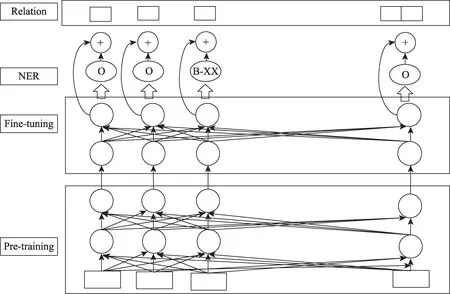
图4 基于BERT的Multi-Head Selection实体关系联合抽取模型
Pre-training层和Fine-tuning层:使用上述领域语言模型,获取输入文本的token向量表示,把token的向量表示输入BERT模型进行调优。
NER层:对微调层token输出计算NER每个标签的得分,对预测标签序列线性链CRF得分进行优化,使得预测的标签序列正确概率最大,
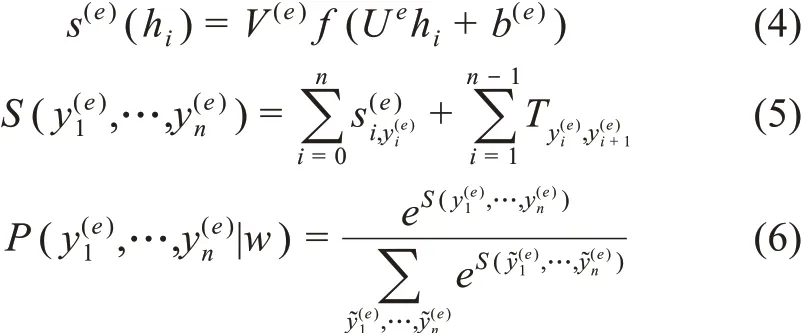
Relation层:初始化实体标签向量矩阵,获取每个token预测标签所对应的向量,把输入tokeni的上下文表示以及实体标签向量拼接后组成的zi,与其他词tokeni的zi单独计算所有关系类别k的得分,确定它的最可能的头实体以及关系。实体标签向量在模型训练过程中进行学习和更新。

针对实体和关系,每个词语的模型输出有两部分:实体标签和关系元组集合。以上文中的句子为例,实体标签采用BIO形式,“商用清洁”属于行业,其标签为“商用/B-industry清洁/I-industry”,头实体以及关系的元组集合采用关系标签+关系位置的形式,例如,“商用清洁”的市场规模数据分别对应“166.2亿元”“600亿”和“885.6亿”,其关系标注为{['rela','rela','rela','rela'],[22,29,35,42]}。为了消除实体冗余关系,在多个实体中最后一个词才能作为另一个实体的头部,比如,上述关系中,并不是所有实体连在一起,我们只连接“清洁”和“元”。如果不存在关系,那么标签为N。标注情况如图5所示。
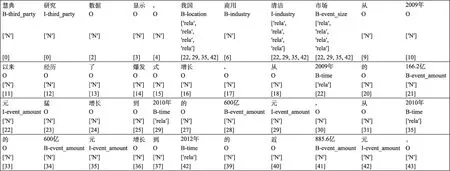
图5 实体关系联合标注
4.4 知识融合
在金融文本中,由于缺乏统一标准,以及人们对于产业认识的差异,同一产业、行业和产品存在较多不同的说法,对知识图谱的构建造成了一定的困难。如何识别同一产业、行业和产品的同义表达并融合,是属于知识图谱中的知识融合任务。本文把行业识别和融合转换为行业同义词的识别和计算。
为了解决未登录词问题,我们提出了结合字节对编码(byte pair encoding,BPE)[38]和领域语言模型的方法进行同义词识别,以下简称为BPE-BERT模型。BPE是一种简单的数据压缩技术,它迭代地将序列中最频繁的字符对合并为字符序列或者合并为词,其训练过程不需要监督。这种方法能够很好地解决字典和分词的局限性问题,还能够融入语境知识。BPE-BERT混合识别模型由BPE和BERT语言模型两部分构成。通过BPE对文本进行分词后,将词汇输入预训练好的BERT语言模型,得到其表示向量,最终使用斯皮尔曼秩相关系数(Spearman's rank correlation coefficient)[39]计算词汇之间的相似度。
5 实验与结果
5.1 实验过程
5.1.1 文本预处理
本文选择2018年和2019年的研究报告共83549篇,应用基于篇章的金融文本分析方法进行处理,抽取目录、段落和表格,过滤段落中一些不需要的信息,如目录、页眉等,并使用SimHash去重,最终获得2840666个段落。
金融文本中,行业名称大多是名词,在上下文语境中,一般作为主语、并列主语或宾语成分,其前后存在一些助词。为提升准确率,需要把这些停用词用空格替换,如“和”“的”等,并将所有数字置0处理,这样做可以减少不同数字对语义产生的影响。语料预处理后共2.2 G。
5.1.2 要素文本分类
按照产业链本体中对产业链要素的制定,产业链要素主要包括:定义(1)、描述(2)、政策(3)、事件(4)、行业规模(5)、历史与趋势(6)、竞争格局(7);通过人工进行分类语料标注,每个类别10000条;有些文本不属于上述7类,所以我们增加了10000条负样本,并设置为第0类。随机按照8∶1∶1将这份数据划分为训练集、开发集和测试集。利用以上语料进行微调和训练,在验证集上的评估结果如表2所示。
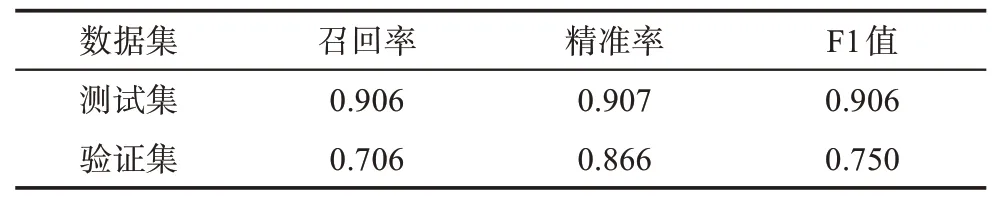
表2 要素文本分类模型性能
5.1.3 典型公司识别
本文把行业典型公司识别转化为公司简介与行业的多分类任务进行解决。先将上市公司和三板挂牌企业通过主营业务和行业分类进行映射,共1.5万余条语料;再基于这些种子语料,通过文本相似度计算对种子语料进行扩展,共获得10万条语料。
基于第4.2节文本分类算法对行业多分类问题进行建模,考虑到行业数量较多,以及10万条语料的分布不均衡,针对没有语料或语料较少的行业,除了增加新的语料外,还通过子句的随机组合生成新的句子进行增强。另外,使用下采样和修正类别权重对模型进行优化,通过训练和测试,把多分类中置信度高于75%的类别作为最终公司所属行业,置信度参数可以在迭代和优化中进行修正,以最大限度提高分类准确率。随机按照8∶1∶1将这份数据划分为训练集、开发集和测试集。在测试集上的评估结果如表3所示。
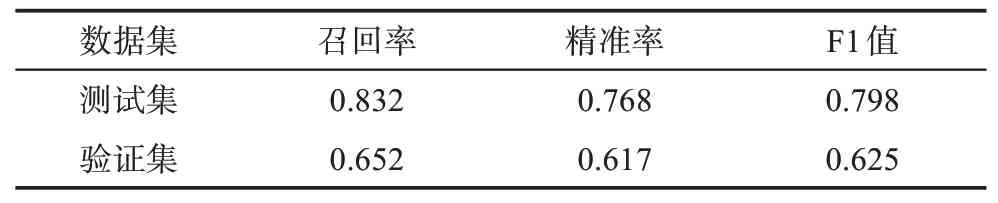
表3 典型公司识别分类模型性能
5.1.4 行业上下游识别
行业上下游一般包含在金融文本对于行业的解释性语句里。上下游识别主要是从金融文本中识别行业名称并判断行业名称之间的上下游关系,例如,“医药CMO的上游行业为精细化工行业,其提供的基础化学原料经过分类加工后可形成专用医药原料”中明确指出,精细化工是医药CMO行业的上游,而“芯片是生产手机的原材料”则通过说明芯片是手机的原材料,来说明芯片行业是手机行业的原材料。根据文本特点,本文把上下游关系分为四类,分别是上游、下游、包含和unknown;其中,包含关系属于同一行业的细分领域,unknown则指两个行业没有上下游或包含关系。本文使用第4.3节中的实体和关系联合抽取模型完成行业上下游识别任务,并与性能较好的方法进行对比。通过制定规则和人工校正,总共积累了近2万条语料,对语料进行均衡,对比情况如表4所示。

表4 行业上下游模型性能对比
从表4来看,联合抽取模型性能较其他模型更好,F1值达到了0.812。表5给出了在联合抽取模型下,行业上下游实体和关系识别的精准率、召回率和F1值。由表5可见,行业名称识别的召回率为74.2%,观察来看,行业上下游在文本中的重复率较高,相同行业的上下游描述语句多次出现在不同的研究报告中。因此,本文模型可以牺牲召回率进而提升精准率,保证大部分上下游文本中的实体能够被准确识别。

表5 行业上下游实体及关系识别模型性能
5.1.5 行业要素结构化
行业要素结构化的典型应用是行业规模的识别,行业规模的描述包含了较多信息,主要包括细分产品的占比、龙头公司的占比以及行业规模的历史和未来研判,是分析判断一个行业成熟度和潜力的关键数据。如何自动化地从行业研究报告中提取出细分行业所对应的市场规模信息,关键在于从非结构化文本中挖掘行业实体及其对应的规模。本文使用第4.3节中的实体和关系联合抽取模型对行业要素进行结构化,性能超过其他方法的联合抽取模型。实验效果如表6所示。
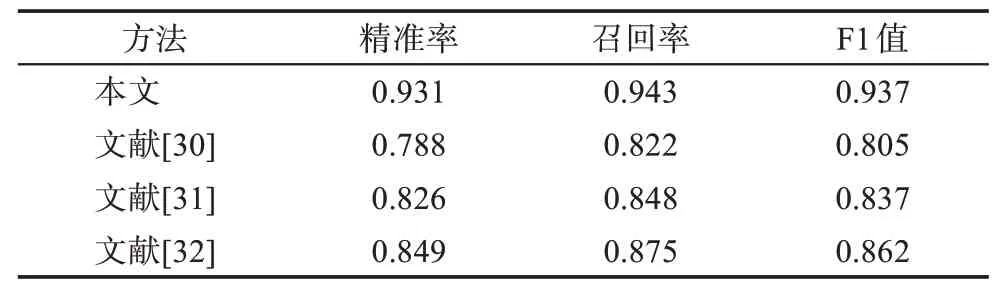
表6 行业要素结构化模型性能对比
表7给出了在联合抽取模型下,行业规模实体和关系识别的精准率、召回率和F1值。与行业上下游识别不一样,上下游中实体类别单一,都是行业名称,而行业规模实体较多,主要包括金额、数量、行业、地点、时间等7种实体,而关系较上下游少,只有二分类。从性能上来看,行业规模中的行业名称识别的整体性能较上下游中的行业名称识别更高,其主要原因在于,行业规模语句中包含的行业名称实体较少,密度较低,有较多的上下文语义特征可以区分;而行业上下游的实体密度过高,且句子较短,语义特征较少。

表7 行业规模实体及关系识别模型性能
我们对71528条行业规模文本进行了行业要素结构化处理,共获得了33118条完整的行业规模机构化数据。表8展示的是从文本中抽取的糖尿病诊疗产业中的GLP-1受体激动剂利拉鲁肽的行业规模。产业链本体中的融资事件要素和行业规模较为类似,也可以通过这种方法进行抽取,不再赘述。

表8 利拉鲁肽行业规模抽取示例
5.1.6 行业同义词融合
在本文业务场景中,有些行业关键词是两个词的组合,使用中文分词对其进行分词,容易导致切分粒度过小,如“地球同步轨道卫星”是一个完整的行业名称,很容易分成“地球/同步/轨道/卫星”,从而降低了整个系统的可用性。在解决实体名称融合前,首先要能够有效地识别行业关键词,使用BPE方法能够有效解决这个问题。基于BERT语言模型,对分词结果和领域关键词进行相似度比较,能够较好地识别同义词,详情如表9所示。“赖脯胰岛素”是重组人胰岛素类似物,系统准确地识别了“赖谷胰岛素”“预混赖脯胰岛素”“德谷胰岛素”“门冬胰岛素”等重组人胰岛素类似物。

表9 同义词识别样例
5.2 案例分析
在本体库的基础上,通过文本分类、知识抽取和融合,产业链知识图谱的构建已经完成,产业链上中下游、行业文本分类、要素结构化、行业同义词融合以及典型公司等各个产业链要素均实现了较高程度的自动化。目前,产业链研究系统已完成重点行业产业链78个,覆盖各级细分行业超过7600个。
5.2.1 产业链查询
产业链知识图谱基于图数据库,能够解决报告式产业链无法关联和检索的问题。系统提供产业链关键字、行业关键字、企业关键字等多种检索方式对产业、行业和企业进行检索,用户可以选择产业链知识图谱系统进行查看,还可以对图谱中某个具体的行业进行下钻分析,浏览该行业的要素数据,包括典型公司、行业规模、竞争格局、发展历史与趋势、行业壁垒等要素数据;进一步地,可以查看该行业上市公司情况,分析该行业的成熟度。图6展示了糖尿病诊疗产业的概况。根据系统展示,糖尿病诊疗产业链上游行业包括原料药、制药装备和医药研发制造外包等,中游为西药降糖药、胰岛素、新靶点药物、血糖监测系统等,下游为医疗服务,包括药品推广、流通和销售。
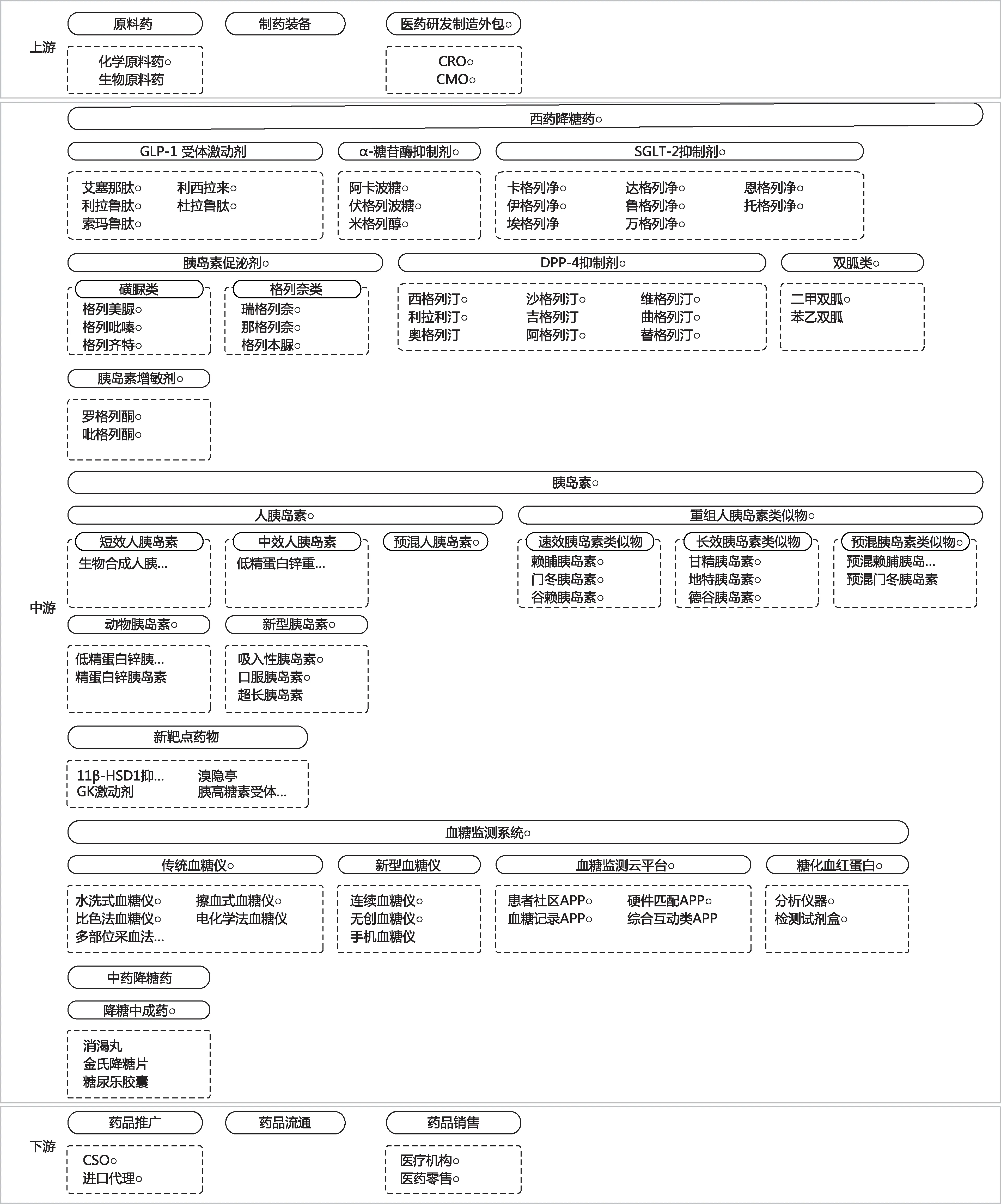
图6 糖尿病诊疗产业链图谱部分示例
5.2.2 投融资
产业链知识图谱把产业链要素、行业规模和典型公司等都集成在图谱里,方便用户分析计算,应用在投资领域,可以辅助筛选赛道和投资标的,解决传统研究报告不能关联分析的问题。从图7的利拉鲁肽行业规模数据可以看到,利拉鲁肽在全球的销售额以14.9%的年复合增长率上升,受制于国内生产技术能力,整个GLP-1受体激动剂在我国2017年的销售规模仅为0.5亿美元左右,预计未来全球销售规模将超过100亿美元,这意味着其应用潜力巨大。我们查看GLP-1受体激动剂或利拉鲁肽行业的典型公司,能够发现有一家生物科技公司在多肽类药物生产上积累了较多的核心专利,具备一定的药物研究和生产能力,是潜在的投资标的。可以将该公司与同行业中的典型公司进行对比,如知识产权、司法文书、舆情数据、股东和高管;进一步地,如果掌握了该公司的财务数据,还可以将该公司置于上市公司群体中,分析该公司与上市公司在经营和估值方面的排位情况。

图7 产业链知识图谱中以利拉鲁肽为例的行业要素可视化展示
5.2.3 证券监管
证券监管领域的应用中,上市发行审核是重要场景。基于产业链知识图谱细分行业和典型公司,可以从拟上市公司的关联关系、行业规模、业务前景、竞争趋势和可比公司等多个角度与招股说明书的内容进行对比分析,挖掘拟上市公司风险。如表10所示,某拟上市公司招股说明书中披露的毛利率为45%,与其披露的同行业可比公司平均毛利率39%相比稍高,但与产业链知识图谱中典型公司的平均毛利率31%相比,高出了50%,需要说明其合理性;且有一个重要的可比公司“碧水源”没有出现在招股说明书中,因此,可比公司的完整性不足。上述通过产业链知识图谱发现的问题在后续公开的问询函中得到了印证。这样,通过产业链知识图谱中产业要素数据的对比,能够验证招股书中相关的内容,辅助审核人员进行问询。类似地,针对上市公司持续监管,可以从上市公司的关联关系、主营业务等多个角度与上市公司年报和并购重组公告进行对比分析;通过产业链和区域优势的分析,能够为区域经济整合和发展提供情报数据。

表10 基于细分行业和典型公司辅助上市发行审核示例
6 总 结
本文从产业链在现代经济活动中的应用角度出发,对产业链知识图谱的构建方法进行了研究,创新性提出了产业链知识本体,基于领域语言模型,实现知识分类、抽取、融合等知识图谱构建模型和流程,能够有效解决金融领域复杂文本的处理,成功地构建了产业链知识图谱。针对投融资、证券监管和产业规划等重要应用场景,结合场景需求和知识图谱功能进行应用示例分析,证明本文提出的构建方法和系统有较好的可用性和有效性。
关于产业链知识图谱,目前仍存在一些有待深入研究的问题:①从整个构建流程来看,本体构建的专家工作量较大,遇到新的产业和新的行业,仍然需要人工干预,如何让机器学习人工本体构建的模式并迁移到其他产业和行业的本体构建上是下一步值得研究的工作;②虽然领域语言模型能够有效区分细分行业的差异,但仍然需要人工进行修正,如何识别细分行业中字、词、句子、段落等多层次的差异,应该是解决这个问题的关键;③如何将企业图谱融入进来,甚至包括二级市场的实体、关系和事件,将是个更具有挑战性的课题。
