基于MongoDB的地震勘探数据管理系统的设计与实现
2022-04-06耿恒高徐传鹏彭蒙蒙彭苏萍何登科
许 娜, 耿恒高, 徐传鹏, 彭蒙蒙, 彭苏萍, 何登科
(中国矿业大学(北京)地球科学与测绘工程学院,煤炭资源与安全开采国家重点实验室,北京 100083)
0 引 言
地震勘探数据在地球物理勘探领域是资源勘探开发、资源评价与利用及相关决策制定的重要基础资料,其高效存取、处理和利用将直接影响石油、天然气和煤炭等能源勘探开发的经济效益。近几年,随着勘探技术的日益发展,万道以上的高密度地震勘探技术得到广泛应用,地震数据呈现爆炸式增长,数据规模可达PB、EB量级,地震勘探数据进入大数据时代。面对如此海量的数据,如何科学、有效地存取与管理地震大数据,提高地震数据的利用价值,是煤炭资源与安全开采重点实验室亟需解决的科学问题。另外,地球物理学专业学生如何学习和运用新信息技术来管理、处理海量的地震数据,也是新时期地球物理学专业教学中亟需解决的实践教学问题。
5G通信、云计算、大数据、人工智能、物联网等技术的发展,为海量的地震数据存储管理提供了一个契机[1]。这些新技术使通过无限的存储空间实现地震勘探大数据管理系统的高可用性和低维护成本成为可能,地震勘探数据已迈入“大数据”行列,对地震勘探行业产生深远的影响[2-4]。目前对于海量的地震勘探数据,缺少规范的在线存取和系统集中式管理,信息应用功能性不强,数据共享程度有待提高[5]。随着互联网Web技术的蓬勃发展,Web交互变得更加便捷,Web系统在数据治理方面得到重视,能够实现数据的网络管理和达到数据共享的功能[6]。这种独立于平台的使用方式越来越受到开发者和用户的青睐,国内能源院校、单位已经开始规划实验室信息管理系统[7-9]。系统开发人员已经逐渐将研究方式从C/S架构转向B/S架构,使用Web形式进行地学数据存储管理[10-12]。本文从重点实验室对地震勘探数据存取管理需求为出发点,总结勘探开发数据管理技术、地理信息系统技术以及油田、煤田系统架构设计等技术方法,将互联网主流开发技术应用到地震勘探数据存取管理,提出了基于MongoDB的地震勘探数据管理系统的设计与实现。同时为地球物理学专业的地震勘探和地球物理软件两大类课程提供了丰富的实践教学案例。
1 地震勘探数据管理系统研究现状
1.1 地震勘探数据存储需求分析
地球物理勘探作为地球科学中重要的研究手段,已经产生了海量的勘探数据。在各种勘探方法中,地震勘探技术是勘探石油、天然气和煤炭等能源最有效的方法,地震勘探过程中产生的数据被称为地震数据。地震勘探原理是利用人工激发地震波在地下地质体中传播后被地表检波器接收,通过处理检波器接收的地震信号,研究地下地质构造,寻找有用矿产资源的一种极重要的地球物理勘探方法,被广泛应用于石油、煤田、地热等能源探测。
随着科学技术的进步,各类物探传感器飞速发展,数据采集、传输技术得到了很大的提高,万道以上高密度地震勘探技术开始广泛应用于复杂的勘探对象,地震勘探已逐步向高密度、高精度发展,地震数据采集量迅速增长,总量达到了PB、EB级规模,呈现指数增长趋势[13-14]。据统计,2017年,每一炮的地震数据为32 000道,到了2020年,上升为64 000道,按照摩尔定律,每一炮的地震数据3年会翻一番[15]。如此海量的地震数据,传统的关系型数据库已经难以满足存储管理需求,需要探索出更加合适的存储管理方式。并且,当今市场上的大多数地震数据软件系统都定义了自己的内部格式,导致了数据存储方面的某些局限性,这对于构建统一的地震勘探数据管理系统带来了一定的挑战。因此,系统一方面需要满足多种数据格式快速存取和高效管理需求;另一方面还需满足数据量的不断增加,数据源应具备易扩展性。
1.2 地震勘探数据格式分析
地震数据格式是地震勘探过程中数据存储的一种特殊格式,地震数据格式较为复杂,通常以二进制形式存储。地震勘探道数据类型常见的分为:IBM浮点型、IEEE浮点型、16位整型、32位整型[16]。地震数据格式众多,野外数据采集仪器一般会有自己专门的数据组织形式,数据格式也各不相同,这些数据格式只针对软件本身,在其它软件中很难兼容管理。为了统一地震数据格式,国际勘探地球物理协会(Society ofExploration Geophysicists,SEG)制定了标准的地震数据记录格式——SEG格式。SEG格式有如下几种:SEGB格式、SEG-A格式、SEG-C格式、SEG-D格式、SEG-Y格式等[17]。随着地震勘探技术发展和软件系统的不断迭代,部分格式已经淘汰,目前业内使用最多的是SEG-Y格式。本文以SEG-Y格式为主要研究对象,SEG-Y格式又分为标准和非标准格式,区别在于是否含有3 600 Byte的文件头。标准的SEG-Y格式主要是由3部分组成,其结构如图1所示[18]。
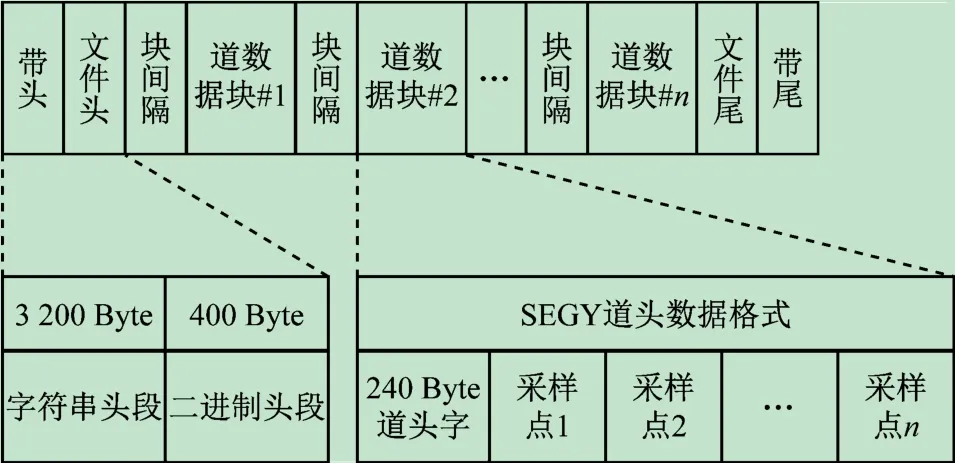
图1 SEG-Y数据格式示意图
由图1可以看出,第1部分是ASCII编码3 200 Byte EBCDIC文件头,存储在40条记录中,每条记录包括80 Byte,保存了数据整体性的描述信息,主要是记录了施工区域、施工单位和测量参数等信息。第2部分是文件头,共400 Byte,用二进制表示,记录了数据的具体信息。第3部分则是数据信息,记录了具体的地震数据,每一炮对应一道数据信息,每一道数据包括道头和道数据两部分信息,道头信息共240 Byte,使用二进制存放,记录了该道的具体位置信息,如采样点数、采样间隔、道集号、XLine号、InLine号以及坐标信息等。地震勘探数据通常以SEG-Y格式存储在工作站,如Alpha、Sun、IBM工作站。
1.3 地震勘探数据管理系统研究进展
地震勘探在采集、处理和解释等各个阶段产生了大量的地震数据,这些数据具有采集成本高、可用周期长、数据量大等特点。地震数据包含了大量的结构化数据、半结构化数据和非结构化数据。海量的地震数据需要科学有效的存取管理,地震勘探数据管理系统经历了如下几个阶段:人工管理阶段、文件系统管理阶段、数据库系统管理阶段、分布文件系统管理阶段等(见表1)。

表1 地震勘探数据管理系统发展阶段
2 系统数据源的选择
传统的关系型数据库由于存在扩展性有限、数据存取效率低、性能不足等缺陷,已无法满足当今地震数据面临的存取与管理需求,因此有必要探索一种新的数据源来提高地震数据管理系统的使用效率。而NoSQL数据库具有水平扩展容易、数据存储效率高和性能稳定等优点,可作为最佳数据源选择,目前已应用在地学各领域。本文分析NoSQL数据库和地震勘探数据管理系统特点与优势,以满足实验室对地震勘探数据高效存取与管理需求为出发点,选择合适的NoSQL数据库作为数据源。
2.1 NoSQL数据库分类对比
近年来,非关系型数据库(NoSQL)在数据库领域迅速发展,并且非关系型数据库(NoSQL)被认为比关系型数据库(SQL)更适合于海量数据的存储和管理[19-20]。NoSQL数据库使用分布式节点进行水平扩展,用户可以通过添加节点来动态提高数据库存储负载[21-22]。到目前为止,广泛使用的NoSQL数据库分为以下四大类[23-24](见表2)。

表2 非关系型数据库分类
本文系统主要基于Web页面实现地震勘探数据的高效、快速存取管理,分析上述NoSQL数据库的特点,最终采用Web端表现优异的文档型数据库典型代表MongoDB数据库作为系统开发的数据源。
2.2 MongoDB数据库
MongoDB是基于分布式文件系统的NoSQL开源数据库项目,它是一个高性能且可扩展的面向文档型存储模式的数据库[25]。它使用C++编程语言开发,使用类似于JSON类型的BSON(Binary JSON)松散式格式,可存储比较复杂的数据类型,可作为Web应用程序优秀的数据源。MongoDB提供了索引、聚合、分片和负载均衡等功能,支持大规模数据批处理,是一种介于关系型数据库和非关系型数据之间的数据库。MongoDB采用内存映射的内部管理机制,在进行数据管理操作时,MongoDB会把磁盘商队数据的所有操作转换为内存操作,其中所有关于内存的操作全部由操作系统来执行。MongoDB采用文档模型进行数据存储,与关系模型的存储方式不同,如图2所示。相比于关系模型,文档模型更适合作为Web开发的选择,主要基于以下几点:
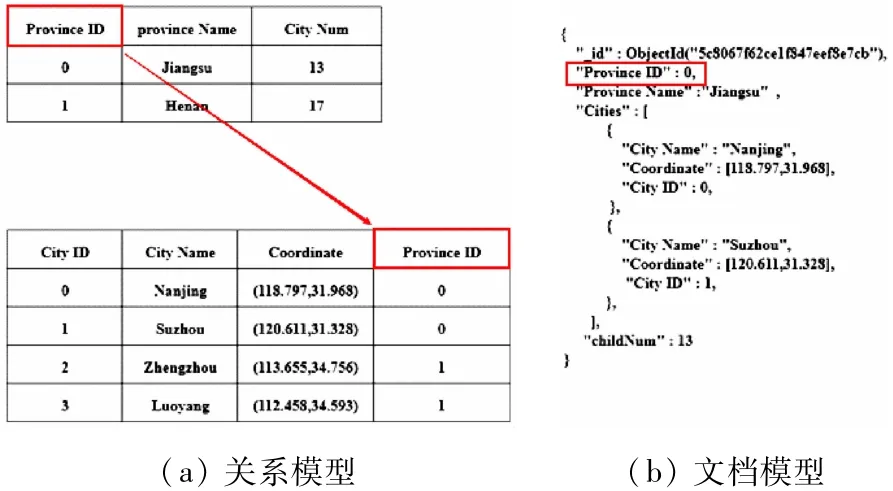
图2 关系模型与文档模型
(1)读写效率高。文档模型把数据信息存储在JSON中,查询数据时用很少的时间就可查询到磁头,相比于关系模型的二维表,在IO性能上有明显优势。
(2)可扩展能力强。由于多节点数据关联存在性能问题,因此关系型数据库很难做分布式。而文档模型不考虑关联,数据容易分库,水平扩展比较容易。
(3)动态模式。关系模型中二维表表示数据相对固定;文档模型数据结构灵活,每个文档可以存储不同结构的数据。
(4)模型自然。文档模型与对象模型十分类似,无需经过对象关系映射(ORM)双向转换,可直接用于内存和存储之间相互操作。
3 系统设计与实现
3.1 系统开发技术选型
(1)浏览器端开发技术。浏览器端(前端)开发主要采用HTML、CSS、JavaScript 3种基本语言。为了更好、更快速开发,系统在开发阶段采用了较为完善的前端框架。本文通过Node Package Manager(NPM)、Stack Overflow Survey、GitHub Stars统计数据来筛选出当前应用成熟和广泛的框架,比较当前几种主流的前端框架,最终选用Vue.js作为地震大数据管理系统的前端开发框架。
Vue.js是一个开源的轻量级前端JavaScript框架,采用自下而上的方式开发设计。Vue.js有著名的全家桶系列,包括了Vue-cli、Vue-router、Vuex、Axios等。Vue-cli称为脚手架,是官方开发的标准工具,通过Vue-cli可以快速构建系统的前端框架。Vue-router是Vue.js官方指定的路由管理器,实现数据的全局管理。Vuex是应用程序开发的状态管理模式,它将所有组件共享的变量存储在一个对象里,该对象放在顶层组件供其他组件使用。Axios是基于Promise的HTTP请求包,Vue.js使用Axios进行HTTP调用。Axios把请求封装起来,看起来像一个整体。Axios的API很丰富,除了常用的请求方法外,还提供了以下功能:①全局数据请求响应与拦截;②转换请求和响应数据;③取消请求;④自动转换为JSON数据;⑤客户端防止CSRF/XSRF攻击;⑥可以创建不同的实例,提供并发封装;⑦为复杂型场景提供灵活定义。有了这些模块,使得系统的前端开发能够快速的实现业务功能。
(2)服务器端开发技术。Python作为当今最流行的开发语言之一,得到广大编程爱好者的人员的使用。Python Web框架有许多,如Django、Flask、Tornado、Pylons、Web2py、Bottle等,目前最为流行的是Django和Flask,系统采用Django作为服务器端(后端)开发框架。Django是一个遵循MVC架构模式的Python Web网络框架,它包含了创建应用需要的几乎全部功能,可以快速开发安全和可维护的网站。Django只需要单独的安装包来安装,框架本身能够实现各种功能,可以不依靠其它的库来完成。它具有设计优秀、结构合理、性能出众、功能完善、要素齐全等特点,具体表现在Django提供了完善的帮助文档;在访问数据库时提供了丰富的组件功能;Django提供了灵活的URL映射,帮助快速编写接口;Template模板语言能够帮助编辑Web页面;提供了专门的后台管理系统;提供完整的错误信息提示帮助系统开发。Django采用MTV模式的框架基础,它将开发任务分为Model、Template、View三大部分,如图3所示。
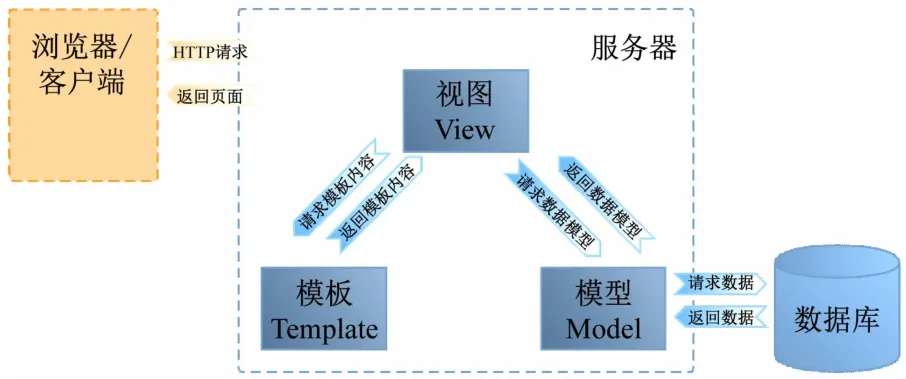
图3 Django MTV框架
MTV与MVC模式非常相似,它将开发工作分为3层,数据存取层(Model)实现业务对象明模型和数据库之间关系映射(ORM);表现层(Template)提供了语法模板展示信息页面;业务逻辑层(View)调用数据存取层和表现层,处理用户请求并返回响应。Django响应顺序如下:①Django收到浏览器HTTP请求;②通过URLconf查找对应的视图,进行URL路由分发;③视图接收到业务请求后查询数据,获取对应的页面;④视图函数处理完成给服务器返回HTTP响应;⑤服务器将响应发送给浏览器。
系统在后端开发中使用Python语言操作MongoDB时,使用PyMongo、MongoEngine、Djongo等模块,这些模块可以很好的操作MongoDB数据库。系统采用Django REST Framework(DRF)进行接口的编写,DRF是Django实现RESTful风格API框架,具有以下特点:具有清晰的API Web信息页面;Django ORM自动序列化;支持OAuth1和OAuth2授权;支持身份认证和权限控制;内置访问频率限制功能;丰富的定制层级;可扩展性,插件丰富,使用广泛,文档丰富等。
3.2 系统架构设计
软件系统最开始在大型机上运行,用户通过“哑终端”方式登录使用软件系统。随着个人电脑发展和应用,人们开始在电脑客户端(Client)使用软件系统,数据库运行在服务器端(Server),这种Client/Server模式简称C/S架构。随着Web技术的不断发展,系统开发逐步向浏览器端过渡,由于C/S架构需要更新每个客户端桌面应用程序才可以满足系统的更新,实现起来比较繁琐。因此新型的Browser/Server架构模式开始出现,简称B/S架构。在B/S架构中,用户访问浏览器获取Web页面,通过浏览器请求服务器,服务器端完成应用程序的业务请求和数据存储功能,这种方式具有极强的交互性。B/S架构系统更新十分便捷,只需服务器端进行升级部署,浏览器就可以轻松地使用新的应用,因此B/S架构迅速流行起来。本文研究的系统采用前后端分离的B/S分层架构开发模式,主要基于以下几点:
(1)分布性强。系统建立在广域网,不同的用户可以随时随地进行数据的查询、浏览等操作。在网络环境下,可以利用电脑、平板、手机等设备通过浏览器进行快速访问。
(2)扩展简单。通过增加网页和添加相关页面功能即可扩展系统业务。根据用户需求,可定制专门的功能模块,具有很好的灵活性和较强的耦合性。
(3)维护方便。通过更新修改对应的组件即可实现系统更新。只需开发者完成相应工作,用户无需任何操作。
(4)共享性强。通过网络可以实时地实现数据的共享,对数据进行存取管理。
(5)使用灵活。不仅可以应用于Windows平台,还可以应用于Unix/Linux等平台,在电脑、平板、手机等设备上都可以进行使用。
3.3 分布式存储集群搭建
(1)硬件环境配置。硬件配置需要考虑到数据库服务器的CPU、内存、硬盘配置等方面,信息如表3所示。

表3 硬件环境配置参数
(2)软件环境配置。对MongoDB数据库软件进行安装和相关参数的配置,如表4所示。MongoDB 4个节点部署在虚拟机Vmware Workstation中的CentOS7.2环境下。系统使用Virtualenv创建Python虚拟环境,保证软件环境的独立性和兼容性。

表4 系统软件信息
(3)系统测试环境。使用不同内核浏览器进行测试,包括:IE11、Chrome 80.0、Firefox 71.0、Safari 14.1等;对系统在电脑端、移动手机、平板等设备中的显示效果和功能进行测试。
(4)分布式存储集群搭建。地震大数据管理系统数据源采用MongoDB副本集与分片结合的方式搭建分布式集群,目前搭建4个节点,分别在CentOS_master、CentOS_slave1、CentOS_slave2、CentOS_slave3机器上进行部署,具体集群规划信息如表5所示。

表5 服务器规划
具体分片集群架构如图4所示,每台机器具体配置了相关信息。

图4 系统集群部署结构图
创建分布式集群相关目录。在四台虚拟机器CentOS_master、CentOS_slave1、CentOS_slave2、CentOS_slave3中分别配置对应文件目录,下面是每台机器的创建相关文件目录的具体操作步骤。例如在Master:192.168.55.110节点创建conf、mongos、config、shard1、shard3、shard4等相关目录的命令如下:


初始化副本集:rs.initiate(config),出现相关信息,如图5所示。
图5 初始化副本集
(6)配置分片副本集。在四台机器上分别进行相关信息配置,这里以shard1副本集为例。在3个节点master、slave1、slave2机器中/usr/local/mydb/conf/shard1.conf目录下进行如下相关信息配置:

初始化副本集配置,使用命令rs.initiate(config),出现如图6所示表示成功。
图6 初始化shard1副本集
(7)配置Mongos。先启动各节点配置服务器Configs,再启动分片服务器Shard,最后启动路由Mongos。分别在对应机器(master、slave1、slave2)/usr/local/mydb/conf/mongos.conf目录下添加如下内容:

查看集群状态:通过命令sh.status()查看信息如图7所示。
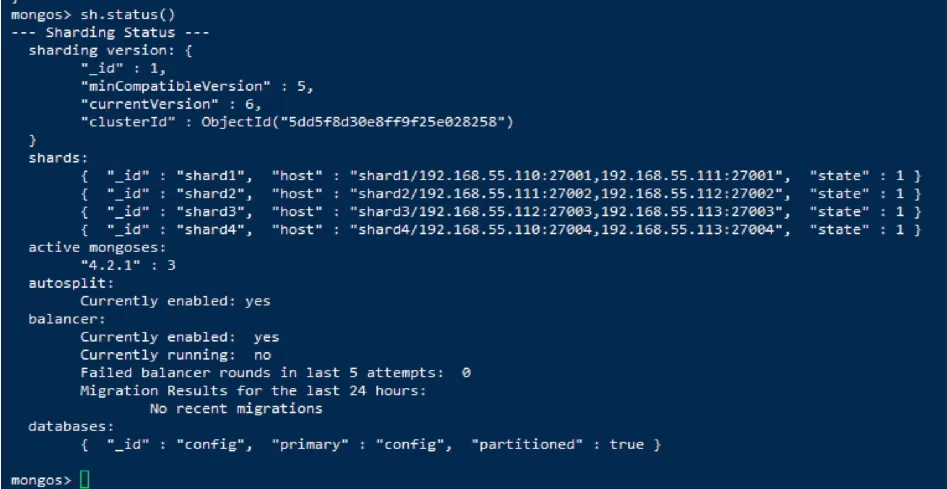
图7 分片集群状态
(9)分布式存储集群启动。启动所有节点配置服务器(节点master、slave1、slave2),启动命令如下:

成功启动分布式存储集群,集群连接测试如图8示。
3.4 分布式存储集群测试
(1)负载均衡测试。在一般情况下,数据在MongoDB数据存储会几乎均匀的分配到各个节点,但由于网络不稳定等原因,有可能会出现数据服务器宕机的情况。如果系统仅部署一台数据库服务器,会造成数据丢失,这显然是不合理的选择。针对上述可能出现的问题,系统采用MongoDB数据库副本集(Replica Set)的方式来实现数据的复和备份,即均衡负载特性。本文测试向搭建好的分布式集群中写入10万条数据进行测试,查看其数据分布情况,每个节点的数据分布结果见图9。

图9 分布式集群各节点数据信息
从图9中可以统计如下信息:

从统计信息中可以发现,10万条数据量在各个节点上维持在25 000条左右,系统搭建分布式集群在插入数据时可以达到负载均衡的效果。
(2)集群压力测试。利用Mongostat可以查看MongoDB的实时性能、QPS和连接数等信息。使用命令监测分片集群,如图10所示显示了插入数据时监控界面。启动命令如下:
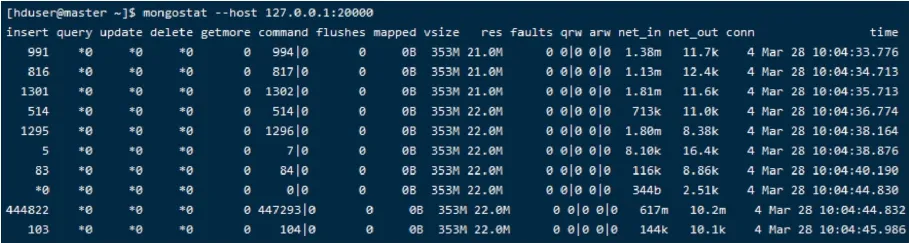
图10 分片集群mongostat监控界面
mongostat--host 192.168.55.110:20000
分片集群通过YCSB进行读写性能等压力测试,YCSB(Yahoo!Cloud Serving Benchmark)是一款开源的分布式性能测试工具,常用于测试NoSQL产品的读写性能。本文通过MongoDB自带的Mongostat监控配合YCSB进行测试,对系统集群进行读写测试。YCSB中workloads目录自带6种压力测试,信息见表6。

表6 YCSB场景对应关系
系统分别对workloads几种模式进行集群测试,这里100%读的场景为例,配置文件workloadc_mongo信息如下:


在集群中先进行数据加载,命令如下,查看系统生成相关信息如图11所示。

图11 YCSB加载测试数据信息
加载好数据,进行Run测试命令如下:

分别进行workloada、workloadb、workloadc、workloadd、workloade、workloadf等几种情况下测试,统计各种情况下的运行时间(Runtime)和吞吐量(Throughout),如图12所示。
通过图12可以清晰地发现,在运行100万条数据量情况下workloade情况下运行时间最长,每秒集群吞吐量最少,每秒仅仅达到约98条数据;workloadc情况选下运行运行时间最短,每秒的吞吐量大约为2 181条数据。通过测试对比这几种情况,发现MongoDB分布式集群在写数据的方面表现一般,但在读数据方面比写数据表现出色,比较适合系统开发中数据读多写少的特点。
3.5 数据的存储策略
中国矿业大学(北京)煤炭资源与安全开采国家重点实验室经过几十年的煤炭地震勘探,积累了海量的地震勘探数据,这些数据包括了结构化数据、半结构化数据和非结构化数据,这些宝贵的勘探数据的获取花费了大量的人力和财力,需要科学、规范的存储管理。地震勘探过程中产生的结构化数据包括了EXCEL、TXT、CSV等格式数据,这些结构化数据适合于建立索引和自动创建元数据。半结构化数据包括HTML、XML、JSON等格式和一些NoSQL数据库中的格式。非结构结构化数据包括文档、图片、音频、视频等格式的资料。
3.5.1 结构化数据存储
对于地震勘探数据中EXCEL、CSV、TXT等数据格式,可以转化为BSON格式进行存储。对于存储特定的空间信息的数据,系统采用GeoJSON编码格式。以存储地理坐标为例,系统可以采用引用式和嵌入式两种存储方式(见图13)。其他数据在数据存储中需要根据数据的存储要求采用合适的方式进行数据存储。系统支持相关数据的常见格式导出功能,满足需求。

图13 数据存储方式
3.5.2 非结构化数据存储
非结构化数据的存储,在关系型数据库中通常是采用存储数据的路径方式进行管理,本文研究的系统采用MongoDB内置的GridFS存储桶进行存取管理,这样存储方式可以将数据描述信息和GridFS中的数据源紧密的联系起来,在读取数据时都能够快速地定位到相关数据。如图14所示,地震SEG-Y文件数据存储在数据库中,地震数据信息表中filedata字段信息与GridFS中ID字段进行关联,地震数据信息表记录文件名、研究区域、单位信息、上传人员等描述信息,GridFS存储记录文件名、ID、数据大小、数据类型、上传时间等信息。
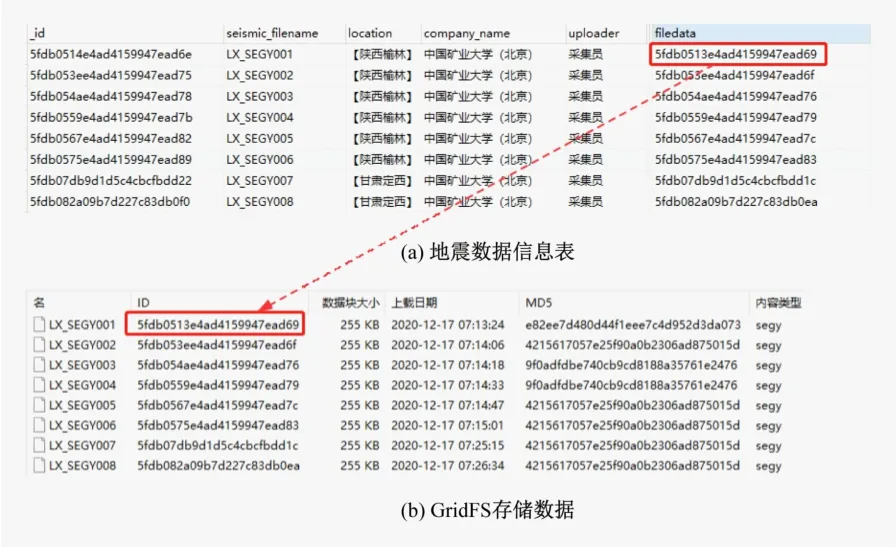
图14 地震勘探数据信息关联方式
3.6 功能页面的实现
系统前端使用Vue.js技术实现地震勘探数据管理的Web页面,采用响应式布局的方式适配手机、平板、笔记本等不同的访问设备,实现系统功能界面的友好显示。如图15所示,前者是在电脑端浏览器显示结果,后者是在移动手机端浏览器显示结果,系统能够实现响应式布局,界面显示友好。

图15 不同设备下系统界面显示测试页面
系统根据地震勘探业务需求实现相关功能界面,完成对地震勘探数据的存取管理和快速查询。其中包括了数据的上传、下载、浏览、添加、删除、修改、查询等基础功能,还实现了地震勘探数据典型的SEG-Y数据的数据解析查看功能,如图16所示。
图16 地震元数据管理页面
4 结 语
为了满足煤炭资源与安全开采国家重点实验室对地震勘探数据存取管理,同时为在地球物理学专业的教学中帮助学生掌握和运用新技术手段管理和处理海量地震勘探数据,设计和实现了地震勘探数据管理系统。针对地震勘探数据采集、处理及解释等各阶段数据需求,对地震勘探Web系统运行业务进行分析和设计,简要阐述了系统的开发技术、系统架构和底层数据源,探索一种基于MongoDB分布式存储集群作管理系统新的数据源,设计和实现了系统Web功能。
将NoSQL数据库技术应用到地震勘探领域是石油、煤炭等能源行业的发展趋势。为了满足实验室对海量地震勘探数据存储管理新需求,本文提出了基于MongoDB的地震勘探数据管理系统的设计与实现。该系统能够满足重点实验室海量地震勘探数据的存储管理需求,实现高效的地震数据管理,为数据处理、解释人员提供了很好的服务,也为地学的相关研究提供借鉴和参考。同时,为地震勘探基础课程和地球物理软件实践教学提供了丰富的案例,帮助学生理解和掌握新信息技术在海量地震勘探数据中的应用。
