MKIF模型风电机组健康劣化监测及预警
2022-04-06刘博嵩
刘博嵩,郭 鹏,雷 萌
(华北电力大学 控制与计算机工程学院,北京 102206)
0 引言
近年来,风力发电规模在我国迅速增长[1]。风电机组 SCADA运行数据可以用来评估机组发电性能和健康状态[2-4]。建立风电机组健康劣化监测系统,实时分析 SCADA运行数据,及时发现风电机组健康劣化,对保障机组安全、提高发电量有重要意义。
风电机组运行状态随风速时变,其异常数据类型复杂,所以对风电机组进行健康劣化监测具有一定难度。文献[5]采用随机森林的袋外估计进行特征选择,使用XGBoost算法搭建风电机组故障分类模型,取得了较好的效果。文献[6]使用深度全连接神经网络构建分类模型,以判断叶片结冰状态;但由于风电机组故障类型繁多,不同故障的数据特征各不相同,所以模型训练集很难包含所有种类故障数据的全部特征。因此,使用分类模型对机组健康状态进行监测具有一定缺陷。文献[7]利用机组正常运行数据建立了马氏(Mahalanobis)参考空间,通过比较模型预测值与参考空间的相对关系来监测机组运行情况。此方法只能判断单个运行数据的异常状态,未引入时间尺度对风电机组健康劣化情况进行整体判断。文献[8]采用偏最小二乘法建立功率曲线模型,应用模糊综合评价指数对机组每日发电性能进行评价;但其以“日”为单位的发电性能评价实时性较差。文献[9]分别采用线性和威布尔分布模型建立了风电机组功率曲线模型,在监测阶段采用控制图和残差分析方法对发电性能异常进行检测;但使用该方法需大量异常数据才能使线性或威布尔分布指标产生明显异常变化,实时性一般。文献[10]采用高斯过程监督学习建立多变量功率曲线模型,使用序贯概率比检验(SPRT)分析模型预测残差,并对发电性能劣化进行监测预警。文献[11]采用两步法对风电机组发电性能进行监测:第一步,针对风电机组历史数据采用极限学习机建立发电性能基准模型并对待监测数据进行功率预测。第二步,使用风速与预测功率2变量建立Copula相关模型,采用Copula模型参数作为衡量发电性能的指标。文献[10,11]所述方法受风电机组数据质量影响较大,实际应用时需设计前置算法对原始 SCADA数据中的正常数据进行提取。
文献[12]对比了 4种异常值检测算法对风电机组数据的识别效果。实验表明,相比于其他算法,孤立森林算法具有更高的精度。孤立森林算法可以判断每一数据点的孤立情况,无需前置算法即可实现风电机组正常数据提取并判断实时运行数据的健康劣化程度。但是,文中孤立森林算法对高密度异常数据识别的效率还有待提高。为解决此问题,本文设计一种基于孤立森林的MKIF算法,并将其与滑动窗口算法相结合,建立MKIF健康劣化监测预警模型,实现风电机组实时工作状态评估。
1 数据分布特征及监测预警模型
1.1 运行数据分布特征
本文的实验机组为某风电场编号为 E17的1.5 MW变桨变速机组。机组SCADA系统以10 min为间隔,记录重要传感器测量数据。运行数据中,风速-功率特征最能反映机组的工作状态。将每一条运行数据中的风速和功率构成一个数据对,于是形成风速-功率坐标系下的一个功率散点。E17机组2019年1月至4月共产生16 335条运行数据,功率散点分布情况如图1所示。

图1 E17机组数据分布情况Fig. 1 Data distribution of E17 unit
风电机组功率散点分布特征如下:
(1)风电机组正常运行数据散点密集分布,构成“功率主带”。额定风速以下,机组处于最大风能追踪阶段,风速和功率特征呈现三次方关系。在额定风速以上,机组调节桨距角大小控制输出功率在额定值附近变化。功率主带呈现水平分布。在实际应用中,可以直接将输出功率大于等于额定功率的数据标记为正常值。
(2)异常功率点类型。①底部堆积数据。风电机组停机检修或风速低于切入风速时,机组理论输出功率为零。如果数据表现为“大量异常数据围绕功率零值附近密集分布”,可将其直接去除。②欠发异常数据:风电机组老化、叶片受损、叶片结冰等问题会造成机组发电性能劣化,产生欠发异常数据。与功率主带中正常数据相比,欠发异常点在同风速下发出的有功功率明显偏小,分布在功率主带右侧。③限负荷异常数据:当机组因电网调度需求人为限功率或因部分部件温度异常自动限功率时,风电机组会提前变桨,并将实发有功功率限制在一个较低的设定值附近。限负荷异常数据位于功率主带右侧,呈水平分布,通常密度较高且桨距角不为零。④传感器故障异常数据:持续的传感器故障会产生大量密集分布的异常点。风速计异常数据密度较高,且数据中桨距角变量与正常数据无异、异常特征不明显,识别难度较大。
1.2 MKIF健康劣化监测预警模型
MKIF风电机组健康劣化监测预警模型如图2所示,分为建立健康基准模型和在线健康评估2部分。

图2 MKIF风电机组健康劣化监测预警模型Fig. 2 MKIF wind turbine health deterioration monitoring and early warning model
(1)建立健康基准模型:考虑功率散点的总体分布特性,设计一种基于孤立森林的MKIF算法。该算法使用小批量K均值聚类确定MKIF搜索树分裂节点的数量和位置,并定义MKIF异常得分以判断数据的异常程度。MKIF算法不需对原始数据进行区间划分,可以通过综合距离和密度特征,依照功率散点的总体分布形状识别出全局稀疏点,进而提取出风电机组功率主带并生成拒绝阈值。功率主带和拒绝阈值构成了风电机组健康基准模型。
(2)在线健康评估:在监测阶段,使用MKIF算法将实时待监测数据与功率主带数据相比较,使用MKIF异常得分评判每一条实时数据偏离功率主带的程度。当实时数据异常得分大于基准模型拒绝阈值时,认定该数据为健康劣化数据。同时为了避免如偶发传感器故障、通讯异常、启停机等产生的偶发异常数据造成的误报警,引入滑动窗口算法监测时间序列数据的健康劣化率。当窗口内数据健康劣化率大于设定阈值时,发出风电机组健康劣化预警。
2 监测预警模型建立
2.1 传统孤立森林算法原理
孤立森林(isolation forest)算法可以提取出风电机组功率主带数据作为健康基准,并以得分的形式量化每一数据点偏离功率主带的程度。
异常值检测主要分为2步,即使用原始数据构建二叉搜索树(孤立树,iTree)和异常得分计算。算法的核心在于构建孤立树。
孤立树的构建过程如下:给定一个数据集D={d1,d2,···,dn},随机选择D中数据的一个属性H和它的分裂临界点r。使用临界点r将数据集D划分为左子树和右子树2部分。以此方法构造孤立树,直到每一子树中只剩下一条数据或树达到最大深度。
孤立森林算法通过随机采样提取D的子集来保证孤立树的多样性。一定数量的孤立树便可组成孤立森林。
对于每一个数据点di,遍历每一颗孤立树,di的总体异常得分为:


式中:t为树的数量;M为树T的深度;k为出口节点包含数据的个数;c(ψ)为二叉搜索树失败查询的平均路径长度,由式(3)及式(4)给出。
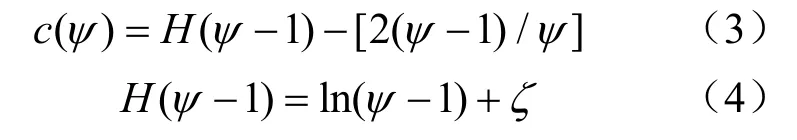
式中:H(ψ-1)为调和数,其中ψ为采样规模;ζ为欧拉常数,取值约为0.577 216。
数据异常得分S(di,ψ)越高,其为异常值的可能性越大。当所有数据的异常得分均约为0.5时,认为数据集D中没有明显异常值。
2.2 MKIF算法原理
传统孤立森林算法中的孤立树是使用二叉树的结构构建的,且其分裂临界点r是随机选择的。由于原始数据具有多样性,二叉树结构无法很好地表征原始数据分布情况,且其引入的随机因素可能会造成算法精度低、稳定性差。
针对这些问题,文献[13,14]提出使用聚类的概念来扩充树,使孤立树脱离经典的二叉搜索树结构。文中使用了肘部法则来判断最佳聚类个数。但是,用肘部法则对聚类效果进行评价时仅能考虑簇内和方差(SSE),未能针对簇间距离进行评判;文献[13]中定义的数据异常得分取值范围不固定且普遍为负值,无法直观地从异常得分来准确判断一个样本的孤立程度。
为克服以上缺点,本文设计了基于孤立森林的MKIF算法:将小批量K均值引入孤立森林搜索树的划分过程中。
MKIF使用聚类算法确定孤立树分裂节点的数量和位置,在构造孤立树的过程中调用聚类算法的次数极高;所以,聚类算法的时间复杂度大大影响了MKIF算法的运行效率。小批量K均值聚类使用部分数据来更新模型参数,其收敛速度比K均值算法更快[15];但小批量K均值算法同样需要事先确定K的个数。本文使用轮廓系数(silhouette coefficient)来解决这个问题。
对于数据集中样本di,假设样本di被聚类到簇A,其轮廓系数si定义为:
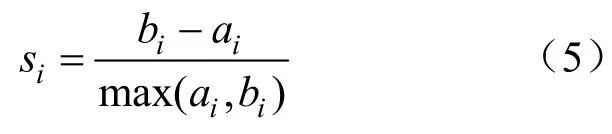
式中:ai为样本di与同一类别中所有其他点之间的平均距离,以体现凝聚度;bi为样本di与下一个距离最近的簇中的所有其他点之间的平均距离,以体现分离度。
样本di的轮廓系数si的取值范围为[-1,1]。轮廓系数越大,样本越适合所在簇,聚类效果越好。
本文采用轮廓系数来监督小批量K均值聚类,可以在保障聚类效果的基础上降低聚类时间复杂度,非常适合风电机组这样的大规模数据的分析处理。
MKIF算法孤立树的构建流程如如下:在数据集D中随机选择一个特征H,并将D划分为C个子树。根据文献[13]给出的经验,子树的个数从2~4中选取。使用小批量K均值算法在不同子树个数(K个数)情况下分别对数据集D的特征H进行聚类,并计算对应子树个数的轮廓系数。选取轮廓系数最大的作为最终的子树个数,并记下此时聚类中心和聚类边界的位置。如此构造孤立树,直到每一子树中只剩下一条数据或树达到最大深度。
MKIF算法异常得分定义如下:
对于数据点di,在第j次划分子树时产生的异常得分值为:
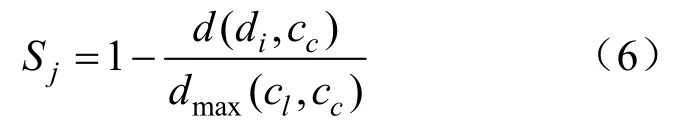
式中:d(di,cc)为di到cc的欧氏距离;dmax(cl,cc)为cc到cl的最大距离;cc为样本di所属类的中心;cl为di所属类的边界。
数据点di的最终异常得分为:

式中:N为树的最大深度;t为搜索树的数量;M为第T颗搜索树划分子树的次数。
样本点MKIF得分的取值范围为S(di)∈[0,N]。MKIF异常得分越高,则说明树的平均深度越高、样本点与聚类中心的平均距离越远,样本点的孤立程度越高。
在用MKIF算法建立风电机组健康基准模型时,首先按本节所述方法构建孤立树,并计算每一数据点的异常得分;然后根据预先设定的置信度B(本文选择90%和80%),选择异常得分较低的B数据作为正常数据组成功率主带,并取功率主带中最大的异常得分值作为拒绝阈值。功率主带和MKIF拒绝阈值即构成了风电机组健康基准模型,可作为判断风电机组健康状态的标尺。
为了更加直观地展示出MKIF算法的优势,使用传统孤立森林算法和 MKIF算法对一组随机生成的二维数据进行分析。图3示出了对于一个位于边界的红色方形目标点,2算法对笛卡尔坐标系的划分过程以及生成的树结构。①传统孤立森林算法随机选取分裂节点,交替对数据集的横纵坐标进行划分,最终产生的孤立树深度为9。其二叉树的结构与样本分布情况关联性不高,相似样本数据往往会被划分到不同子叶。该算法异常得分值与孤立树深度密切相关,对分割点的位置非常敏感,不确定性强。②MKIF算法孤立树分割点的数量和位置均由聚类算法得出,稳定性强。在实际应用中使用少量孤立树组成孤立森林即可获得较好的异常值和新奇值检测效果。最终产生的孤立树深度为4,远低于传统算法,运算时间大幅缩短。图3中MKIF孤立树的结构能很好地表征样本分布情况。

图3 孤立树构建示意图Fig. 3 Schematic diagram of isolation tree construction
2.3 滑动窗口MKIF劣化监测原理
在劣化监测阶段,对每一个新的监测数据,MKIF算法实时计算其在孤立树中的位置及异常得分,进而实现对比分析监测数据与功率主带健康基准模型的位置关系。当监测数据异常得分大于基准模型拒绝阈值时,认定该数据为健康劣化数据。
风电机组运行过程中,随机、偶发传感器故障、信号噪声、启停机过渡过程等会产生偶发劣化数据。为发现风电机组系统持续的健康问题,减少误报警率并保证健康监测的实时性,采用滑动窗口对时间序列运行数据进行劣化监测。设滑动窗口内监测数据的个数为Nwin,滑动窗口内监测数据更新个数为Nupd,如图4所示。
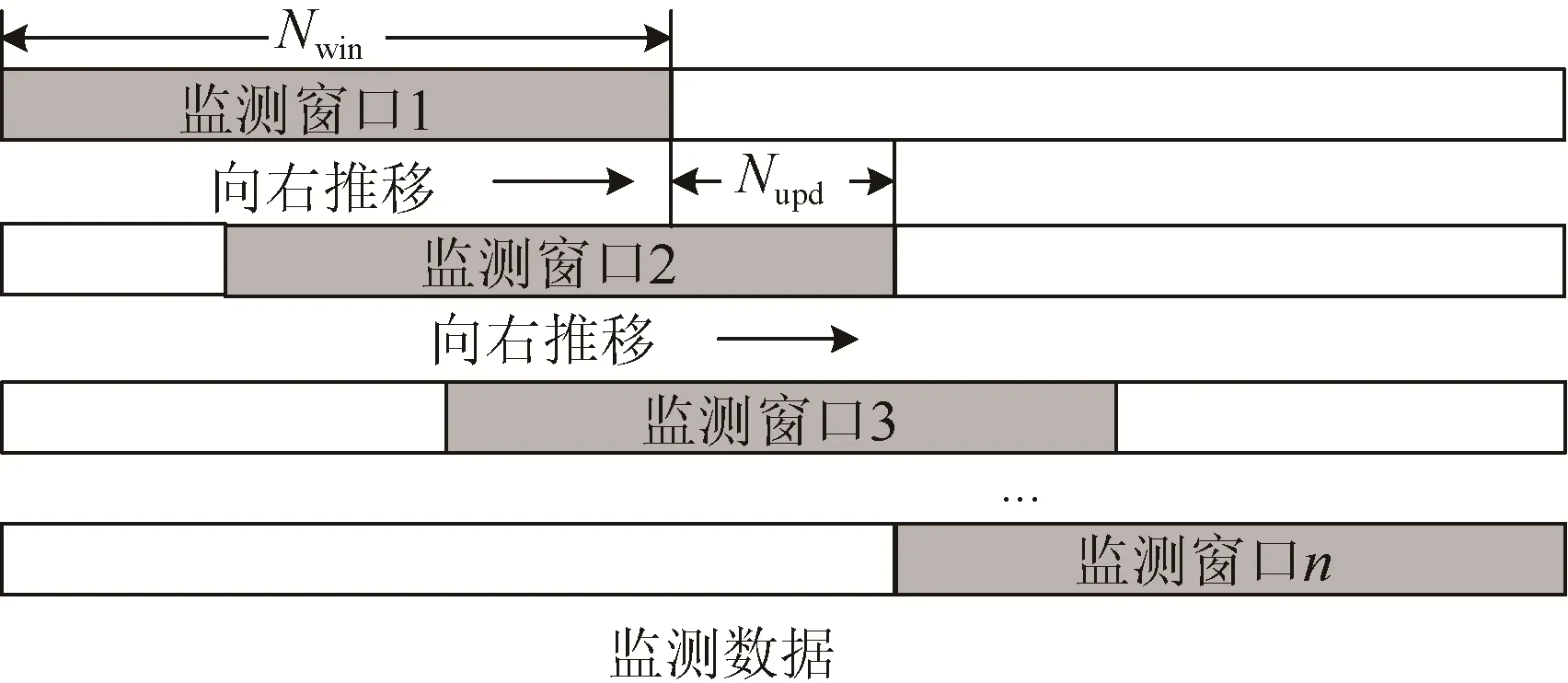
图4 滑动窗口算法原理Fig. 4 Principle of sliding window algorithm
对滑动窗口内的每个监测数据采用拒绝阈值进行劣化判别。定义窗口内运行数据劣化率为:

式中:Ndeg为窗口内劣化数据个数。
设定风电机组健康劣化报警阈值为Valm。当滑动窗口内劣化率高于报警阈值时,即Rdeg>Valm时,发出风电机组劣化预警。预警时刻为该滑动窗口内最后一个监测数据对应的时间。
3 实例分析
3.1 风电机组健康基准模型实例
为检验本文设计的MKIF算法在建立风电机组健康基准模型方面的效果,将E17机组2019年1月至4月的运行数据送入传统孤立森林和MKIF算法进行识别。首先,将功率小于零的运行数据直接剔除,并将高于额定功率的数据标记为正常值。同时,为了更加准确地分离出限功率异常数据,将每条运行数据中的风速、功率、桨距角 3个特征作为传统孤立森林和MKIF算法的输入,功率主带提取结果如图5所示。
图5(a)为用孤立森林算法识别异常数据提取功率主带建立健康基准模型的结果。图中的限功率和风速计异常数据点密度高,在二叉搜索树中具有较高的平均深度,被识别为正常值。
由图 5(b)可知:MKIF的搜索树结构可以更好地表达出数据分布情况。在异常得分数据中引入了点到聚类中心的距离,降低了算法对密度的敏感程度,将远离功率主带的分布密度高的限功率和风速计异常数据点准确识别为异常,准确提取出功率主带作为健康基准。

图5 MKIF算法功率主带提取结果Fig. 5 Power main band extraction result of MKIF
图5(c)所示为置信度B=80%时,MKIF算法功率主带提取效果。可以看出,置信度取值对功率主带提取效果影响较小。当置信度较低时,算法会将大量零功率附近的数据点识别为异常。实际应用中,可适当设置一个较小的置信度(如85%)以提高算法的适用性。
考虑到用传统孤立森林算法建立的基准模型精度较低且包含大量异常数据,不能满足劣化监测的需求,故本文仅使用MKIF健康基准模型对风电机组健康劣化情况进行监测预警。
3.2 健康劣化预警实例
针对E17机组,在提取出功率主带并建立风电机组健康基准模型之后(B=90%),将5月9日0:00时开始的120条运行数据作为监测数据执行健康劣化预警,其中的劣化数据分布情况如图 6所示,均位于功率主带右侧。

图6 劣化数据分布情况Fig. 6 Deterioration data distribution
实验机组运行数据采样间隔为10 min。由于采样间隔较长,为提高检测的实时性,设置滑动窗口内监测数据的个数Nwin为18个(3 h),窗口更新数据个数Nupd为3个(0.5 h),劣化报警阈值Valm=30%。图7为5月9日0:00时开始的各滑动窗口劣化率变化趋势。图8为第12、14、19和第25个滑动窗口监测运行数据与健康基准模型的对比图。
在图7中,实验机组从第12个滑动窗口开始出现健康劣化。在第14个滑动窗口劣化率达到38.9%,超过报警阈值Valm=30%,即在第60个监测数据,也即9日10:00时,发出风电机组劣化预警,距离首次出现健康劣化数据的第12个滑动窗口仅滞后6个数据点约1 h。若SCADA系统的数据采集间隔更短,则本劣化预警模型的实时性更强。

图7 滑动窗口健康劣化监测Fig. 7 Degradation monitoring in sliding windows

图8 滑动窗口内数据分布情况Fig. 8 Data distribution in sliding windows
将风电机组健康劣化数据各参数与功率主带中正常数据的各个参数进行比对分析,能够确定机组健康劣化的原因。如图9所示,5月9日健康劣化数据的齿轮箱油温均超过70 ℃,明显高于同工况下功率主带数据的齿轮箱油温:推断为此时实验机组齿轮箱运行异常,齿轮箱油温超过设定报警值导致机组被迫在额定风速以下提前变桨限制机组出力,进而使风电机组出现健康劣化。

图9 齿轮箱油温劣化数据Fig. 9 Gearbox oil temperature of deterioration data
为验证本文劣化报警阈值设置的合理性,使用MKIF风电机组健康劣化预警模型对E17机组2019年10月运行状态进行长期监测,结果如图10所示。图中,10月9日15时左右,风电机组产生了4组偶发异常数据,导致机组健康劣化率增加到22%。MKIF健康劣化监测预警模型在10月12日10时与10月28日16时2次报警。查阅机组运行日志:风电机组在10月13日02时与10月29日20时2次故障停机,其余时间工作正常。机组运行情况与模型监测预警结果相符。因此,本文将劣化报警阈值Valm设置为30%,这样即可在保证灵敏度的基础上降低偶发异常数据对劣化监测的影响,使模型具有较好的预警效果。
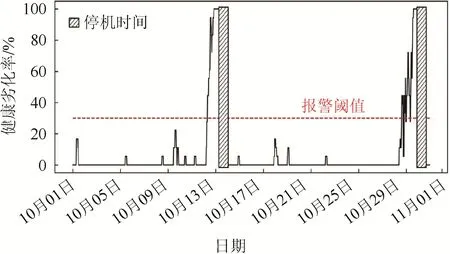
图10 健康劣化长期监测结果Fig. 10 Results of long-term monitoring of health deterioration
4 结论
提出了基于孤立森林的MKIF算法:应用小批量K均值聚类自适应确定MKIF搜索树的结构,并采用异常得分从全局的角度判断每一数据点的孤立程度。使用MKIF算法提取出高质量的风电机组功率主带作为健康基准,以标识单个数据的运行状态。引入滑动窗口算法判断时间序列数据的健康劣化率,确定机组健康劣化时段。针对不同故障类型,比对正常数据与劣化数据参数,分析健康劣化原因。
实例验证表明,MKIF算法具有更高的建模精度,算法提取出的功率主带数据能够更好地表征风电机组正常工作状态。构造的风电机组健康劣化监测模型能够实时监测机组工作状态,并准确识别出实验机组齿轮箱异常。
