基于Openpose改进的苹果生长方向检测*
2022-04-03李会宾刘怀洋王文昊刘万福
李会宾,史 云※,刘怀洋,王文昊,刘万福,杨 鹏,3
(1. 中国农业科学院农业资源与农业区划研究所,北京 100081;2. 苏州大学机电工程学院,江苏苏州 215100;3. 河海大学地球科学与工程学院,江苏南京 211100)
0 引言
采摘姿态的确定是水果采摘机器人采摘过程中的一个重要环节。通常情况下,人在抓取某一物体时,首先通过视觉感知物体的形状、位置和放置的姿态等信息,再依据自身位置和抓取习惯选择较为方便和可靠的抓取方式。与之类似,为实现无损采摘作业,需要视觉系统快速从复杂的果园环境中定位出水果抓取点和该果实的生长方向,这样有助于实现仿生式果实采摘,降低采摘过程中对果实和树枝的损伤。
目前,由于生长姿态通常难以通过视觉识别系统轻易获取。因此,在大部分采摘机器人和视觉识别的现有研究中,一般只考虑了果实目标的位置信息,而对于果柄姿态信息考虑较少。张高阳根据苹果尾部花萼区域是否可见分析了基于机器视觉的果实姿态信息测量方法,详细研究了果实姿态信息的粒子滤波估计[1]。宋怡焕等使用灰度共生矩阵和小波变换对苹果的果梗和果萼进行纹理分析,确定果轴方向[2]。Bac 等开发的甜椒采摘机器人,通过双目相机确定果实位置,在甜椒预采摘点通过单目相机获取果柄方位信息,从而确定甜椒生长方向[3]。云双等对位于传送带上的柚子姿态进行了研究,通过搭建双目视觉测量系统拍摄水果图像,通过提取位置点与花萼点作为姿态定位特征点,然后求解水果空间几何参数[4]。赵文旻等对苹果形状特征进行了细致的分析与分类,提出了判定苹果姿态的方法,通过边缘点与形心点的距离判断花萼点,从而确定果轴方向[5]。以上4种方法必须保证花萼点或者果梗点的可见性,否则会导致果实姿态检测失败。新西兰工业研究所的Penman等采用蓝色条形光源的方法,通过对苹果表面纹路分析,确定果轴方向[6]。Zhang等同样从光源入手采用红外光照射的方法,获取苹果表面纹理信息,识别苹果果萼与果梗位置[7]。但是Penman和Zhang的方法需要特定辅助光源设备,会增加了系统的复杂度。Zhang等利用苹果轮廓中果梗以及花萼处存在凹陷的轮廓特征,运用近红外线阵结构光来实现苹果轮廓的3D重建技术,通过比对重建轮廓与标准球体的差异确定出果梗/花萼的位置[8],但是这种方法在受到叶子和树枝遮挡的情况下,会造成定向失败。Yu等对YOLO网络进行了改进[9],通过在锚点上增加一个旋转角实现检测框的旋转角度,从而提高草莓采摘点的定位精度,但是该方法不太适用于圆形水果。
综上所述,目前基于视觉对水果姿态估计虽然取得了一定成果,但是还依然存在一定的局限性,如必须保证果萼点和果梗点的可见性,需要特殊光源,或者果实表面不能被遮挡,只有在这些条件下才能实现果实生长姿态的检测。文章基于上述问题,提出一种基于改进Openpose 模型的果实姿态估计方法[10],在Openpose 模型的基础上,基于ShuffleNet V2[11]和坐标注意力机制[12]实现主干网络的替换,并且基于果实的关键点数量重新设计了局部亲和域的连接方法。最终改进后的模型仅使用RGB果实图像,就能准确地获取果园场景下目标果实的生长方向,也不会受到果实表面遮挡的影响。
1 研究数据
1.1 苹果生长方向数据标注
苹果数据采集时间为2022年9月,采集地位于陕西省杨陵,拍摄传感器为RealSense D455,获取的图像分辨率为1 280×720,本次采集了顺光、逆光、侧光和暗光4种光照情况下的图像,避免光照强度不同对图像识别的鲁棒性造成影响,一共采集图像2 000张。该文将无遮挡类果实(N类)和仅有叶子遮挡果实(L类)作为采摘目标,所以仅标注这两类图像。标注结果如图1 所示,标注原则如下:①L 类苹果可见度要大于等于50%;②标注好苹果的生长方向,即通过连线苹果的果柄点和果萼点实现标注,无法观察到苹果的果柄点和果萼点时,通过人为经验判断出果萼点的位置进行连线标注,且顺序不可颠倒,标注完成后会生成结果为pose的两点数据。③由于果园里有大量的果树,为了重点标注出近距离能够采摘到的苹果位置,该文中只标注出了当前果树上的苹果,图像背景会存在一些像素占比较少的小苹果,文中不再进行标注[13]。

图1 使用Labelme对图像进行标注Fig.1 Use Labelme to label images
1.2 数据格式转换及统计
由于Labelme软件标注图像得到的是json文件。Openpose在做训练实验的时候,需要用到的是果实方向关键点在切片图中的坐标和原果实切片图,如图2所示,最左侧为原图像,第二列为N和L类苹果的切片图,第三列为一列数字包含了3类内容,前两位数字代表了苹果的果柄点在切片图中的坐标,后两位数字代表了苹果的果萼点在切片图中的坐标,关键点的坐标类型通过文本格式保存。图像标注后,其中N类总计8 671幅图像,L类11 813幅图像,按照7∶3来切分为训练集和测试集,将N类中2 601幅图像作为测试集,6 070幅图像作为训练集,L类中3 544幅图像作为测试集,8 269幅图像作为训练集。所有测试、训练集的详细信息如表1所示。

图2 N和L类的数据格式转换Fig.2 Data format conversion of N and L classes

表1 测试集与训练集信息Table 1 Information of test dataset and training dataset
为了增加图像训练集,更好地提取各种光照状态下图像的特征,避免模型在训练过程中的过拟合现象[14]。该文对训练图像进行了数据扩增处理。由于图像采集时光照条件较为复杂,为了提高训练模型的泛化能力,对原切片图像进行了亮度增强及减弱、对比增强及减弱和模糊化5种图像增强处理。同时在数据采集过程中,会存在相机抖动造成图像模糊的情况,所以增加了模糊化的增强处理。为了使得图像扩增后,原标注仍然有效,该文中,将图像的亮度、对比度在原图的50%以内进行随机变化。图像模糊化采用中值滤波的方式。图像增广后的结果如图3所示,其中图3a是原图像,其它5 种图像增强的结果如图3b~f 所示。图像增强后共获得71 695 幅图像作为训练集,其中N 类为30 350幅图像,L类为41 345幅图像。

图3 数据集增广结果。a.N类图。b.亮度增强的N类。c.亮度减弱的N类。d.模糊的N类。e.对比度增强的N类。f.对比度减弱N类。h.L类原图。i.亮度增强的L类。j.亮度减弱的L类。k.模糊的L类。l.对比度增强的L类。m.对比度减弱的N类。Fig.3 Dataset augmentation results
2 研究方法
2.1 Openpose框架结构及改进
Openpose 框架由CMU 实验室研究学者开发,该模型的提出有效对人体的面部、手部、足部的关节点进行检测,同时即使在部分遮挡的情况下,也能实现对人体姿态的估计[15]。该方法总体流程如图4所示。图4表现了该模型首先使用了VGG19[16]特征提取器作为骨干网络获取输入图像的特征,接着将特征图作为多阶段输入,每个阶段主要实现对上阶段特征的修正和逐渐优化。每一个阶段分为两部分,分支1Branch1)是关键点热力图计算模块,用于关键点定位;分支2Branch2)是局部亲和域检测模块,用于寻找关键点之间的联系,辅助连接所有检测到的关键点。Openpose 架构大体结构共分为6 个阶段,但是,针对单个苹果类的目标,过多阶段数会耗费更多计算资源,造成计算冗余,对模型最终精度提升的帮助将逐渐减小。

图4 Openpose网络模型Fig.4 Openpose network model
在Openpose 中包含了两个分支,其中上方区域用来预测目标部位置信图S,ρ 代表用来检测置信度S 的网络模型,F 代表VGG-19 提取的特征,t 代表网络所处的阶段。图中下方区域用来预测目标各个局部的部分亲和力字段(Part Affinity Fields,PAF)L,φ 是用来检测目标部分亲和力字段L 的网络模型。每对S 和L 回归一次系统完成一次迭代,迭代之后将新特征S、L 和原输入连接一起,按照迭代机制作为下阶段的预测输入。该机制能够在不增加计算量的基础上,对预测结果多次进行优化修正,可以让模型学习更多的特征信息,提高检测精度。连续迭代t∈(1,...,n)次,形成Openpose推理结构。在获得预测结果后,需要计算每个阶段的损失函数,第t 阶段时候的损失函数为:
式(1)(2)中,代表真实标注关键点置信度图;L*c代表真实标注亲和力大小;W(P)是二值掩码函数,取值为0或1,该掩码用于避免在训练期间惩罚真正的正向预测。整体的损失函数为:
为了使得Openpose 模型能够在单个苹果关键点检测上更好的发挥自身性能,该文结合单个苹果的自身特点对模型进行了进一步改进。多张单个苹果的标注结果如图5所示,可以看出每个苹果的二维生长方向通过果柄点和果萼点表示,且果柄点均在果萼点之上。基于该先验知识,由此可推段出模型的局部亲和力检测模块的作用会发生下降,可以规定苹果生长方向是从果柄点指向果萼点,亮点具有默认的亲和力。基于此,对Openpose 模型去除了部分亲和力计算分支,这样可以大大减少模型的计算量。

图5 多张单个苹果生长方向标注情况Fig.5 Growth direction labels of multiple individual apple
另外针对Openpose主干层采用VGG19作为主干网络。VGG19网络虽然成熟且训练效果较好,但网络结构较为冗余,复杂的层级使用的是普通的直筒式相连,这会随着网络层数的不断加深带来负面影响。由于采集的各类苹果数据均处于多种光照条件下,所以需要升级模型主干的架构,进一步提升主干特征提取的性能。因此该文提出使用改进的ShuffleNet V2-CA 作为VGG19 的替代,使得Openpose 架构更加灵活高效。改进的Openpose 结构如图6 所示,接下来将对Openpose 框架中重要组成部分VGG19 的改进、PAF的阶段修改部分进行原理阐述。
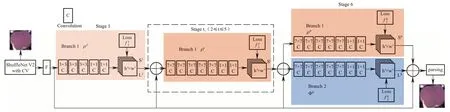
图6 改进后的Openpose网络模型Fig.6 Improved Openpose network model
2.2 ShuffleNet V2和CA的原理和结构
该文首先采用ShuffleNet V2和CA注意力机制的融合作为Openpose的主干网络,进而替代VGG19的特征提取方式,两者相结合实现多尺度的特征提取。两种ShuffleNet V2的基本模块设计情况如图7所示。如图7a所示,在ShuffleNet V2单元1中,首先对输入的特征进行通道划分,分成了左右分支,左右分支的通道数相同。左边分支的特征不进行计算;右边分支会经过两个1×1 卷积和一个3×3 深度可分离卷积,3 个卷积的步长均为1,并且使用相同的输入通道数和输出通道数。当右侧的卷积完成后,左右分支会进行连接操作进行特征融合,主要体现为通道数相加,最后通过通道混合,实现了不同组间的信息交流,使得通道充分融合。如图7b所示,在ShuffleNet V2单元2中,首先不会对特征的通道进行划分,而是直接将特征图输入到两个分支中。两个分支使用的步长不同于单元1,主要是使用步长为2的3×3深度卷积,实现对上一层级的特征图进行尺寸降维,从而起到减少网络计算量的作用。接着,两个分支经过BN层和ReLU层进行计算后,输出特征后进行特征连接操作,通道数相加后变为原输入的2倍,该操作增加了网络通道的宽度,并且起到了在不显著增加FLOPs的情况下,增加了通道的数量,使网络提取特征能力更强。最后,通过通道混合实现了不同组间的信息交流。ShuffleNet V2 模型目前发挥了较好的性能,超越了同级别的MobileNet V2、Xception和ShuffleNet V1等模型。主要由于以下原因:①计算过程中,相同的输入输出通道可以使得内存访问成本最小;②分组卷积有助于降低模快的计算复杂度,但分组数不宜太多。

图7 ShuffleNet V2单元。a.ShuffleNet V2单元1,b.ShuffleNet V2单元2Fig.7 ShuffleNet V2 unit
ShuffleNet V2 通过轻量化的手段对深层语义特征进行了提取,但是容易丢失图像中苹果的细节,从而不利于进行关键点检测。为了增加模型对细节特征的捕获能力,解决 ShuffleNet V2 的对苹果细节特征提取能力弱的问题,于是将坐标注意力机制Coordinate Attention,CA)引入到ShuffleNet V2中。CA注意力模块结构如图8所示,其中X Avg Pool和Y Avg Pool是沿着x轴和y轴做池化操作,分别提取宽度和高度上的特征信息,连接操作是聚合x 轴和y 轴上的特征信息,接着做卷积能够获得远程依赖关系,然后进行归一化,使用ReLU激活函数,此时能够得到每个维度的全局信息,之后做沿着宽度和高度进行分割操作,分别进行Conv和ReLU激活,最后进行重新加权Re-weight)操作,从而完成了一个基于空间维度的注意力机制。该文提出的ShuffleNetV2-CA 两个基本单元以ShuffleNet V2单元结构为基础进行改进,加入高效通道CA注意力模块,如图9所示。该模块只涉及少量参数,适当的跨通道进行信息交互,可以在保持网络轻量化的同时也能带来明显的性能增益,并显著降低模型的复杂度。

图8 CA注意力模块Fig.8 CA attention module

图9 ShuffleNet V2-CA 模块单元Fig.9 ShuffleNet V2-CA model unit
ShuffleNet V2主干网络结构如图10所示,输入切图大小为3×224×224,然后连续使用2个由 ShuffleNet V2-CA单元2和ShuffleNetV2-CA单元1组成的模块层,两个模块层中单元2与单元1的数量分别为1:3和1:7。为更好融合通道注意力不使用最大池化层,而使用计算量小的通道数为24,卷积核大小为3×3,步长为2的深度分离卷积,提出特征更丰富。

图10 ShuffleNet V2-CA主干网络Fig.10 ShuffleNet V2-CA backbone network
2.3 全PAF修剪
局部亲和域是由一组流场组成的表示,这些流场能够对可变数量的目标关键点之间的非结构化成对关系进行编码,用来描述关键点在骨架结构中的走向。Openpose可以有效地从PAF中获得成对分数,而无需额外的增加训练步骤。PAF就是对有联系的关键点进行标注,是身体每对关键点的2D向量,同时保留了关键点区域之间的位置信息和方向信息。在Openpose 模型中,存在6 组热力图关键点定位模块和6 组PAF 模块,这种模式主要针对多目标下的多个关键点情况而设计,并不完全适用于单苹果下的两个关键点的模式,主要是因为在6组PAF 模块内逐步提取两个关键点之间的关系时,会出现冗余计算。于是为了减少不必要的计算消耗,该文中对全部PAF模块进行了修改工作。该文中去除了前5个PAF模块,保留了1个PAF模块,这个过程中大大的降低了原PAF模块的计算消耗,但也能够维持了苹果两个关键点之间的关联,全PAF修剪后如图11所示。

图11 全部PAF模块修剪后的结果Fig.11 All PAF module trimmed results
2.4 模型评价指标
该文采用模型评价指标分别是关键点相似度OKS,Object Keypoint Similarity)[17],计算得到的平均精度AP,Average Precision)、平均精度均值mAP,mean Average Precision)。mAP 为时获取的T 个AP 的均值,T 取值为100.50,0.55,…,0.90,0.95),AP50 为T 是0.5 时的平均精度,AP75 是T 为0.75 时的平均精度,mAP-S 为小尺寸苹果的平均精度均值,mAP-B为大尺寸苹果平均精度均值,OKS、AP、mAP的计算公式为:
式(4)(5)(6)中,p表示在图像中某个苹果,pi表示某个苹果的第i个关键点,d2(pi)表示当前检测的一组关键点中序号为i的关键点与标签关键点坐标的欧式距离,表示这个关键点的可见性,该文中关键点均可见,则表示标签的尺度因子,w和h为图像的宽和高,σi表示关键点pi的归一化因子,δ(*)表示如果条件*成立,P为测试集中图像的个数。
3 结果分析
3.1 改进的Openpose训练
在完成Openpose改进框架搭建后,需要训练出合适的模型用于实现对苹果生长方向的检测。该文将改进后的Openpose框架在Pytorch平台上进行训练,训练平台的硬件配置包括英特尔至强CPU E5-2678,8GB 内存和1 块英伟达型号为3050 的GPU。在网络模型参数初始化设置中,设置动态衰减参数取值0.89,权重系数decay取值0.000 5,初始学习率设置为0.001,另外学习率会根据迭代的次数而逐渐下降,批次大小设置为8,最大迭代次数设置为200,当训练过程中,当迭代过程中损失逐步下降到稳定的阶段就停止训练。这200次的训练误差图如图12所示,训练损失率变化如图13所示。从图12中可以看出,在迭代到175次时,训练误差总体上在逐步减小并趋于平缓,这说明模型在逐步收敛。如图13所示,在模型训练过程中,学习率一直在不断的减小,促使模型收敛到全局最优处。

图12 改进的Openpose训练误差Fig.12 Improved Openpose training error

图13 改进的Openpose在训练过程中学习率变化Fig.13 Learning rate changes in the training process of improved Openpose
3.2 改进后的Openpose对苹果生长方向检测的影响
改进后的Openpose模型对苹果生长方向的检测结果如图14所示,我们发现改进后的Openpose模型对苹果生长方向的检测效果较好。图14a~e中属于N类,图14f~j中属于L类。两类苹果的表面存在光照不均、完整度不一、亮块、阴影等情况。同时在L类切片图像中,苹果存在枝叶遮挡和背景复杂等情况。图14k~o属于N类和L类在低光照情况下的情况。首先对于N 类,我们发现图14a~e中属于方向不一的苹果,图14b存在果萼点和果柄关键点都无法直接可见的情况,图14a~e存在果柄点无法被直接可见的情况,但不可见的关键点的位置均被改进的Openpose模型所识别,说明了改进后的Openpose算法对不可见的关键点具有较好的预测评估效果。图14f~j中的苹果表面上会有不同程度不同位置树叶的遮挡,主要表现为在多种光照条件下,这些苹果的果柄位置、侧边等位置会存在树叶遮挡的情况,会改变苹果的表面形态特征,如图14f和图14i所示。但是基于改进版的Openpose 模型针对无规律树叶遮挡类苹果的情况,也实现了生长方向的精准检测,说明改进后的模型对存在树叶类遮挡情况下的检测效果有较强的鲁棒性。如图14k~o所示,这5张切图中的苹果均是在光照强度较弱的情况下进行采集的,表现是苹果表面亮度低,对比度差,色彩失真,但是苹果的完整度较高,从检测结果中发现,这5张切图中苹果生长方向检测效果较好,可见改进版的Openpose模型针对场景中存在的低光照的情况下,也能够完成苹果生长方向的检测。
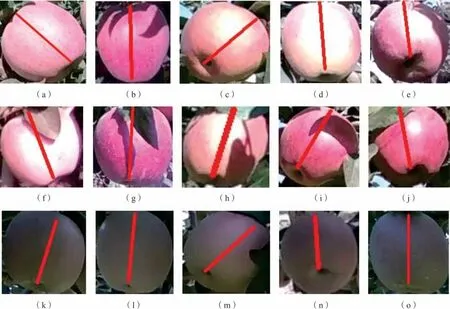
图14 改进的Openpose网络模型对苹果方向检测结果。图a到e是强光照下的N类检测结果,图f到j是强光照下的L类检测结果,图k到o是低光照下L和N类的检测结果Fig.14 Apple direction results with improved Openpose network model
梯度加权类激活映射Grad-CAM)[18]利用网络反向传播的梯度计算出特征图的每一个通道权重从而得到热力图。在该文使用Grad-CAM 对Openpose 模型进行可视化,主要是验证模型是否实现了对图像中的重要特征区域的定位情况,实现对模型检测关键点检测过程的可视化解释。在Grad-CAM 可视化图中深黄色区域代表该处的图像特征是模型进行正确分类的重要依据,这些重要信息主要位于苹果的果柄、果萼位置以及两部分的中间连接处,这些区域颜色较亮,证明该位置处的特征对苹果关键点的检测作用大。图14中包含了2组热力图检测结果,分别是图15a~e和f~j每一组包含了5张图像,分别是苹果切片原图、果柄处热力图、果萼处热力图可视化、关键点连接向量场可视化以及最后的检测结果。其中图15a~e 属于L 类热力图检测结果,图15f~j 属于N 类热力图检测结果。以图15a~e所代表的L类为例,苹果在图15b和图15c中的激活区域位于靠近果柄部分和果萼部分的关键点周边区域,图15d展示了两个热力图区域之间的连接向量场,在图14e中实现了两个关键点的关联。综上所述,从Grad-CAM 可视化图可以清楚地看出,改进后的Openpose模型能够准确实现苹果果萼和果柄处两个关键点的定位以及关键点连接向量场的检测,证明了改进模型在单个苹果目标关键点检测的有效性。

图15 苹果生长方向检测可视化解释。图a和f是原图,图b和g为果柄处关键点热力图,图c和h为果萼处关键点热力图,图d和i是苹果关键点连接向量场热力图,图e和j为原图苹果生长方向检测结果Fig.15 Visual interpretation of apple growth irection detection
为了定性观察到Openpose 模型改进前后的性能提升情况,该文对部分N类和L类图像开展了关键点检测结果的对比工作,如图16所示。其中图16a~c和g~i属于N类关键点检测结果对比图,图16d~f和j~l属于L类图像关键点检测结果对比图。在每组3张图像中,第一列图像为Openpose模型检测的结果,第二列图像为人工标定的真值,第三列图像是改进后Openpose模型检测的结果。在图16a~c和g~i这组对比图中,可以观察到Openpose模型对这类模糊的苹果检测时,关键点的特征位置定位会出现随机性偏差,但是改进后的模型对苹果方向的检测效果较好。在图16d~f 这组对比图中,可以观察到Openpose模型对这类叶遮挡的苹果检测时,果萼部分的检测由于受到了树叶的影响,造成果萼部的关键点检测结果落到了错误位置,但是改进后的模型能够避开这一影响,实现对受遮挡苹果方向的较好检测。在图16j~l这组图像中,可以观察到Openpose 模型对这组图像的关键点检测时,苹果的关键点均被检测出来,但是其准确性较低,明显和真值存在差异,而改进后的模型的对这个苹果的关键点检测结果较好。综上所述,该文改进版的Openpose苹果生长方向检测模型,对存在光线干扰、树叶干扰等自然情况下,仍能够有效地对苹果生长方向进行检测,且性能更优。

图16 Openpose改进前后模型对苹果方向检测效果图。图a和g是基于Openpose的N类的生长方向检测,b和h为人工标注图a和g的真值,c和i为基于改进版Openpose的N类苹果的生长方向检测,图d和j是基于Openpose的L类的生长方向检测,图e和k为d和j的真值,图f和l为基于改进版Openpose的N类苹果的生长方向检测。Fig.16 Comparison of apple direction detection performance between improved Openpose and original Openpose
为了验证改进前后Openpose模型的性能变化和不同框架对苹果方向的检测性能,本次试验将改进的Openpose 框架与Openpose 框架、AlphaPose[19]框架和级联金字塔网络Cascaded Pyramid Network,CFN)[20]框架相比较。为了保证对比试验的公平性,所有模型都使用同一套数据集进行训练,参数保持模型原有的默认参数,最后采用相同测试集对各个模型进行测试,测试结果如表2所示。

表2 不同模型对苹果生长方向检测的测试结果Table 2 Test results of apple growth direction detection by different models
从表中可以看出,改进后的Openpose框架在对测试集的关键点检测方面,在各指标上,全面超过Openpose 框架,表中的Ts)代表处理所有测试集合中每个图的平均速度,单位为秒。改进后的Openpose的运行速度是改进前的6.56倍,从mAP、mAP-s、mAP-b、AP50、AP75 这些参数中,分别增长9.18%,8.50%,11.56%,1.67%,6.35%,证明了改进方法中取出多余的PAF 模块,引入轻量化的主干模型对Openpose 的性能提升显著。AlphaPose和CFA的性能上也明显优于Openpose模型,但是对于改进后的Openpose来说,以上两种算法的各项指标均被超越,由此证明了该文算法的优越性。综上所述,改进的Openpose算法根据苹果的特点在Openpose框架进行了针对性的模型修改,使得模型的关键点计算和关联方式与单个苹果的关键点数量的检测相适应,并大幅加快了模型运行的时间,也进一步提高了苹果关键点检测的精度。
4 结论与讨论
该文针对苹果智能化采摘中苹果生长方向检测精度不高、易受遮挡影响的问题,提出了基于Openpose的改进版苹果生长方向检测算法。该文对Openpose框架进行了2项主要改进:①提出通过ShuffleNet V2 和CA 注意力机制相融合的方式替换原VGG19 结构,降低主干的参数量,并提升模型主干在多种光照条件下对苹果特征的检测能力;②结合单个苹果的自身关键点的特征对该模型去除部分PAF分支的改进,这样可以大大减少模型的计算量,提高模型的计算效率。改进后的Openpose模型在各个指标上,全面超过了原模型,其运行速度是改进前的6.56 倍,对于mAP、mAP-s、mAP-b、AP50 和AP75 这些参数,分别增长9.18%、8.50%、11.56%、1.67% 和6.35%,证明了改进方法对Openpose 的性能提升显著。与AlphaPose 和CFA 算法相比,改进后Openpose 的性能也达到了最优,由此证明了该文算法的优越性。
