傅里叶变换中红外光谱的牛奶品质无损检测分级
2022-04-02肖仕杰王巧华李春芳周增坡梁生超张淑君
肖仕杰,王巧华, 2*,李春芳,杜 超,周增坡,梁生超,张淑君*
1. 华中农业大学工学院,湖北 武汉 430070 2. 农业部长江中下游农业装备重点实验室,湖北 武汉 430070 3. 华中农业大学动物遗传育种与繁殖教育部实验室,湖北 武汉 430070 4. 河北省畜牧业协会,河北 石家庄 050000
引 言
牛奶富含蛋白质和脂肪。 乳蛋白中含多种人体必需的氨基酸。 乳脂能够提供能量和营养。 牛奶的品质决定牛奶的口感[1]和价格[2],直接关系到乳企的利润和发展。 相关数据表明,2014年—2019年,我国每年原料奶产量均在3 000万吨以上[3]。 随着生活水平的提高,消费者更加注重牛奶品质,因此市场上普遍出现“高蛋白”,“高乳脂”等特色牛奶。 此外,研究表明,牛奶中体细胞数的变化会直接影响乳蛋白和乳脂的含量[4]。 乳企在收购原料奶时会将其作为评价指标。
乳蛋白和乳脂含量,体细胞数的测定需要分开进行,使用不同的方法和仪器。 传统的化学分析方法技术成熟、准确率高,但是耗时长且污染环境。 若能找到一种方法同时对乳蛋白、乳脂含量和体细胞数直接进行检测并快速分级,将大大提高乳企的生产效率,节约生产成本。 利用中红外光谱法检测牛奶操作简单且快速无损,在国外被用于牛奶成分(如蛋白成分和脂肪酸)[5-7]的含量预测和奶牛营养、健康与生殖状况监控[8]。 在国内,中红外光谱在牛奶方面主要用于三聚氰胺和尿素等的掺假研究[9-10]。 牛奶体细胞的无损研究方面,崔传金等和吴海云等[11-12]利用电参数和化学计量学方法进行了含量预测和分类研究。 但是,关于牛奶体细胞的光谱无损检测鲜有报道。
利用傅里叶变换中红外光谱针对乳蛋白、乳脂和体细胞对牛奶进行分级研究。 通过对特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的光谱差异进行分析,利用无信息变量消除法(uninformative variable elimination,UVE)、竞争性自适应重加权算法(competitive adaptive reweighed sampling,CARS)与稳定性竞争性自适应重加权采样算法(stability competitive adaptive reweighted sampling,SCARS)筛选出能代表4种牛奶品质差异的特征变量,并基于朴素贝叶斯(NB)和随机森林(RF)模型构建了牛奶检测分级模型。
1 实验部分
1.1 样品
牛奶于2020年1月、3月至10月期间从河北省10个牧场获得,所有奶牛品种均为中国荷斯坦牛。 牛奶采集利用全自动挤奶设备,每份牛奶采集40 mL,分装到河北省奶牛生产性能测定(DHI)中心配置的全新专用取样瓶里并依次编号,为防止牛奶腐败变质,每个采样瓶里加入专用防腐剂布罗波尔3.2~3.4 μL并使其与牛奶充分混匀,及时放入专用冰箱冷藏保存。
1.2 仪器与设备
试验仪器与设备主要包括乳成分分析仪MilkoScanTM FT+(傅里叶变换中红外光谱仪,丹麦FOSS公司);体细胞检测仪FossomaticTM7(丹麦FOSS公司),电热恒温水浴锅。
1.3 方法
1.3.1 光谱采集、乳蛋白和乳脂含量及体细胞数检测
将牛奶分批放入42 ℃电热恒温水浴锅内预热15~20 min后摇晃均匀,使用MilkoScanTM FT+进行光谱采集以及蛋白质和脂肪的含量测定。 FossomaticTM7可视为自动荧光显微镜,物镜位于转盘上方,连续的牛奶液膜涂布在转盘周边,暴露在紫外光下,经吖啶橙染色的牛奶细胞荧光信号由光电倍增管检测并馈入放大系统,测得的脉冲被计数, 每个脉冲等于1 000个细胞·mL-1。
根据欧盟标准,脂肪的正常含量范围为1.5%~9%,蛋白质的正常含量范围为1%~7%,共筛选出5 121份牛奶。 各牧场的样本分布如表1所示。
1.3.2 分级标准
参考GB19301—2010《食品安全国家标准生乳》和TTDSTIA001—2019《生乳用途分级技术规范》对牛奶进行分级,分级标准如表2所示。
1.4 数据处理
1.4.1 光谱预处理方法
牛奶本身作为胶体,当光束穿过时,会产生丁达尔效应,即光的散射,仪器在运行过程中也会产生随机噪声,基线漂移等,对中红外光谱产生影响[8]。 本文采用6种算法对光谱进行预处理,包括标准正态变量变换(standard normal variable,SNV),多元散射校正(multiplicative scatter correction,MSC),一阶导数,二阶导数,一阶差分和二阶差分。
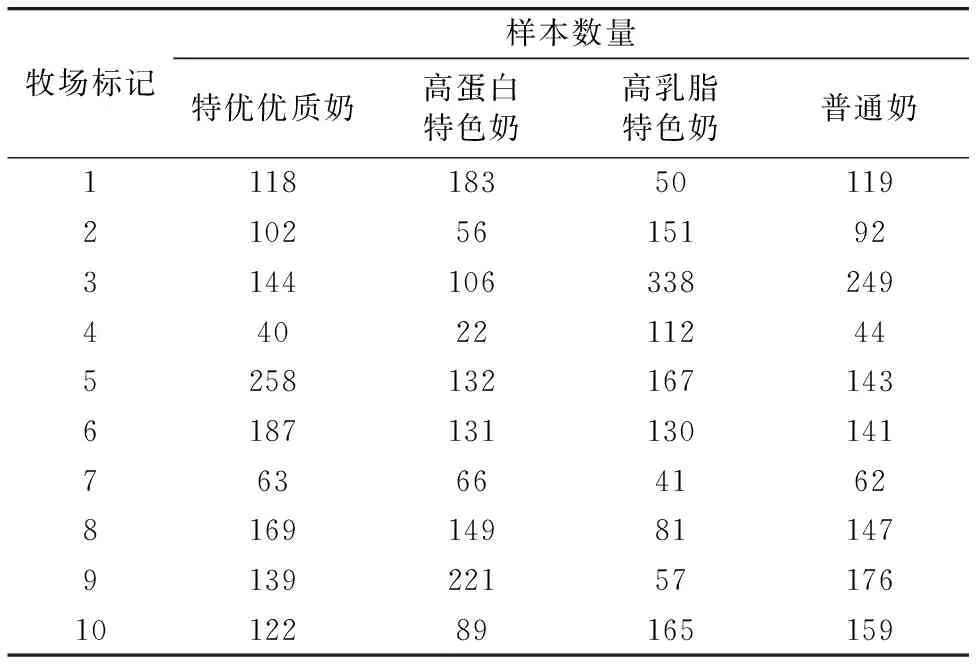
表1 各牧场的样本分布统计Table 1 Sample distribution statistics of each pasture

表2 分级标准Table 2 Standard of classification
1.4.2 特征变量选择
牛奶的原始光谱共有1060个波长,波长不同包含的信息不同,对模型的贡献率大小也不同,部分无信息变量对牛奶分级的中红外判别分析没有价值,反而容易降低模型的预测精度。 UVE,CARS和SCARS均以降低无信息变量为出发点,提取出能够代表4种牛奶差异的特征变量组合。
1.4.3 模型建立与性能评估
朴素贝叶斯(NB)[13]是一种以概率统计中的贝叶斯定理为理论基础的学习算法。 已知先验概率,并计算给定的待分级牛奶属于特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的条件概率,再计算后验概率,选择后验概率最高的类别作为牛奶的预测类别。
随机森林(RF)[14]的本质是一个多决策树(随机方法形成)的分类器。 当测试集中4种牛奶样本进入分类器时,实际上是由每棵决策树进行分类,选择分类结果最多的类别作为最终结果。
利用准确率作为模型的评价指标。 训练集准确率与测试集准确率越高并且两者越接近,表明模型的精度高,可靠性好。
全部数据处理均在MATLAB 2014b中进行。
2 结果与讨论
2.1 光谱分析
在中红外范围内对牛奶样品的采集区域为925~4 000 cm-1,由于3 680~4 000 cm-1区域对模型贡献率较低,因此,选择925~3 680 cm-1的光谱进行分析。 图1所示为特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的平均光谱,从图中可以看出,特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的平均光谱吸收曲线紧密重合,每条曲线的变化趋势相似,表明特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的成分大致相同,但同时它们的光谱吸光度也存在差异,这表明4种牛奶的化学成分含量存在差异,这就为我们建立牛奶品质分级模型提供了理论依据。
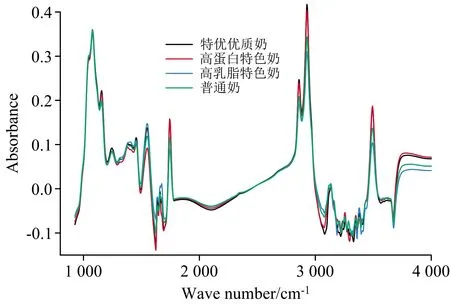
图1 特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的平均光谱
光谱中1 250,1 550和1 650 cm-1峰与蛋白质的吸收有关[15],1 774,2 856和2 928 cm-1峰与脂肪的吸收有关[10]。 此外,水的吸收峰与牛奶相似,会对牛奶的中红外吸收造成干扰。 1 597~1 712和3 024~3 680 cm-1区域由于水的吸收导致很低的信噪比[15-17],建模前先将这些区域去除。 最终取925~1 597和1 712~3 024 cm-1的敏感波段组合用于后续模型的建立。
2.2 样本集划分
样本总数为5 121,其中A级牛奶的样本数量为1 342,B级牛奶的样本数量为1 155,C级牛奶的样本数量为1 292,D级牛奶的样本数量为1 332,利用随机法RS按照7∶3的原则划分样本集。 划分后的训练集样本数量为3 587,其中,A级牛奶的样本数量为940,B级牛奶的样本数量为809,C级牛奶的样本数量为905,D级牛奶的样本数量为933;测试集中样本总数为1 534,其中,A级牛奶的样本数量为402,B级牛奶的样本数量为346,C级牛奶的样本数量为387,D级牛奶的样本数量为399。
2.3 光谱预处理
基于全光谱和预处理后的光谱数据,分别建立NB和RF模型,比较不同预处理对模型精度的影响,结果如表3。 对于NB模型,全光谱模型的训练集准确率与测试集准确率仅为84.50%和84.22%,与全光谱相比,所有预处理后的光谱数据建立的NB模型的训练集准确率与测试集准确率都有明显提升。 其中,二阶差分处理后的光谱建立的NB模型精度最佳,训练集准确率与测试集准确率为94.31%和92.11%。 对于RF模型,SNV和MSC的模型准确率低于全光谱模型,其余4种预处理方法建立的RF模型准确率得到提高。 二阶差分预处理后的光谱数据建立的RF模型精度最佳,训练集准确率和测试集准确率为99.86%和96.87%。 因此,无论是NB模型还是RF模型,均选择二阶差分预处理作为最佳的预处理方法,并用于后续的建模分析。

表3 采用不同预处理方法的全光谱预测模型Table 3 Full spectrum prediction model using different pre-processing methods
2.4 特征变量提取
2.4.1 UVE算法提取特征变量
UVE算法[18]的变量选择过程如图2所示,将阈值参数设为0.9,主成分数取20,建立PLS模型选择变量。 图中左侧曲线为牛奶的光谱变量矩阵,右侧为添加的与牛奶光谱变量数相同的随机噪声矩阵,两条水平虚线处的值分别为+95.57和-95.57,代表随机噪声的最大阈值,两线之间为被剔除的无用变量,水平线之外则为建模的牛奶特征变量。

图2 UVE消除算法筛选特征波长Fig.2 Screening characteristic wavelengths by UVE
2.4.2 CARS与SCARS算法提取特征变量
CARS算法基于“优胜劣汰”准则剔除不适应的波长变量。 SCARS算法延续了CARS的提取过程[19]。 由于两者的变量选择过程相似,仅以CARS为例对变量提取的过程进行分析。 如图3所示,将采样次数设为100,利用5折交叉验证,重采样率为0.8。 图3(a)表明,迭代次数增加的过程,被选取的特征变量数量在逐步减少。 此过程又可分为两个阶段,第一个阶段特征变量数呈指数衰减趋势,称为“粗选阶段”,第二个阶段特征变量数缓慢减少并趋于稳定,为“精选阶段”。 图3(b)为RMSECV的变化趋势。 当采样次数小于48,RMSECV变化不明显,大于48时,RMSECV缓慢增加,表明特征变量中可能包含了无用信息。 图3(c)中的竖线处对应迭代48次,可以取得最佳变量组合。
2.5 模型建立与比较
分别以UVE,CARS和SCARS提取的变量组合为自变量,以牛奶级别A, B, C, D (在模型中分别记作0, 1, 2, 3)作为因变量建立NB模型和RF模型,结果如表4。
对比NB模型可知,全光谱NB模型训练集准确率与测试集准确率分别为94.31%,92.11%,预测性能较好。 UVE,CARS和SCARS提取特征变量后建立的模型均优于全光谱模型,表明UVE,CARS和SCARS算法适用于牛奶的品质分级,可以简化模型,提高模型精度。 SCARS-NB模型的精度优于CARS-NB模型和UVE-NB模型,训练集准确率与测试集准确率为94.45%,93.94%。 CARS,SCARS提取的变量较少,为37,20,仅占全光谱变量的7.2%,3.9%。 UVE提取的变量数高达229个,占比达到44.6%,变量数远大于CARS,SCARS,导致模型运行速度慢,因此在UVE的基础上利用CARS,SCARS进行二次变量提取。 UVE-CARS和UVE-SCARS提取的变量数分别为30和37,仅占UVE变量数的13.1%和20.5%,变量数大大减少。 从UVE-CARS-NB与UVE-SCARS-NB的预测结果来看,两种二次特征变量结合方法均对UVE-NB进行了优化,且UVE-SCARS-NB要优于UVE-CARS-NB,训练集准确率与测试集准确率为94.68%,93.61%。 综合考虑,选择SCARS-NB模型作为牛奶品质分级的最优NB模型。
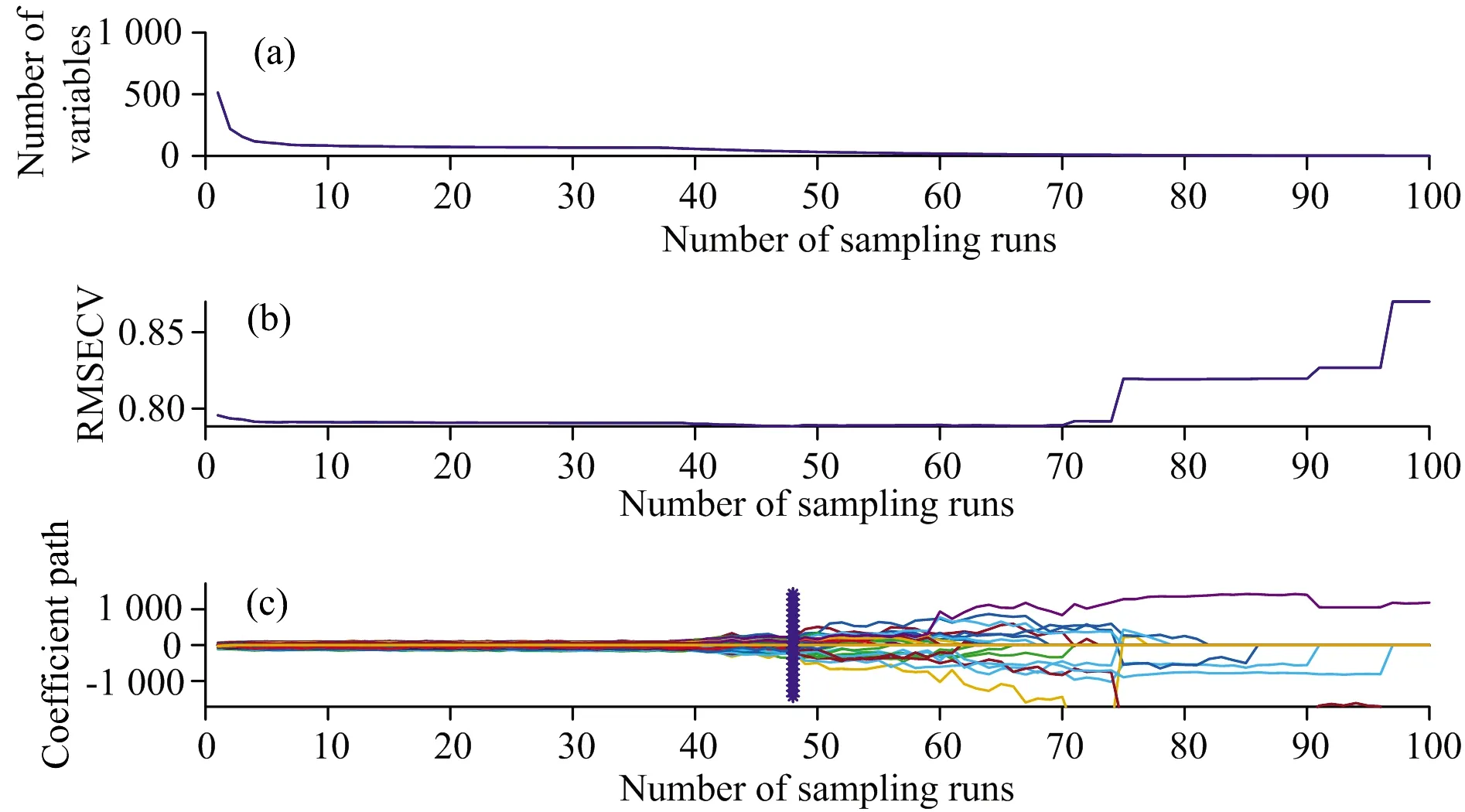
图3 (a)采样变量数; (b)RMSECV; (c)回归系数路径Fig.3 (a) Number of sampling variables; (b) RMSECV; (c) Regression coefficient path

表4 NB模型和RF模型的预测结果Table 4 Prediction results by NB and RF models
对比RF模型可知,全光谱RF测试集准确率为96.87%,模型的预测性能良好。 UVE,CARS和SCARS提取特征变量后建立的模型精度较全光谱模型均有不同程度的下降,但模型的测试集准确率均大于95.5%,表明基于特征变量的RF模型还是可行的,具有良好的精度。 其中UVE-RF的精度优于CARS-RF和SCARS-RF,测试集准确率为96.74%,与全光谱RF接近。 同样将UVE分别与CARS和SCARS相结合,进行二次特征变量提取并建立RF模型,但两种结合方法的模型精度较UVE-RF模型有所下降,这可能是因为CARS和SCARS在进一步剔除无用信息的同时将部分有用信息也剔除了。 其中,UVE-SCARS-RF的测试集准确率为96.48%,与全光谱RF较接近。
进一步对比全光谱RF,UVE-RF和UVE-SCARS-RF模型的预测性能。 与全光谱RF模型的测试集准确率相比,UVE-RF模型精度下降0.13%,UVE-SCARS-RF模型精度下降0.39%;对测试集的1 534份牛奶判别结果表明,UVE-RF仅比全光谱RF模型多误判2个,UVE-SCARS-RF比全光谱RF模型多误判6个。 但在运行时间上,对测试集的1 534份牛奶判别,全光谱RF模型的运行时间为59.28 s;UVE提取的特征变量数为全光谱变量的44.55%,运行时间为全光谱RF模型的44.74%;UVE-SCARS提取的特征变量数为全光谱的9.14%,运行时间仅为全光谱RF模型的10.22%。 综合考虑,最终选择UVE-SCARS-RF模型作为牛奶品质分级的最优RF模型。
2.6 最优模型的确定
对于NB模型,二阶差分-SCARS-NB模型取得最优效果,训练集准确率与测试集准确率分别为94.45%和93.94%,测试集中特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的预测准确率分别为97.26%,93.93%,93.02%和91.48%。 对于RF模型,二阶差分-UVE-SCARS -RF模型取得了最优效果,训练集准确率和测试集准确率为99.86%,96.48%,测试集中特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶的预测准确率分别为98.26%,97.40%,95.87%和94.49%。 二阶差分-UVE-SCARS-RF模型的训练集准确率与测试集准确率均高于SCARS-NB模型。 综合考虑精度和效率,最终选择二阶差分-UVE-SCARS-RF模型作为牛奶品质分级的最佳模型。
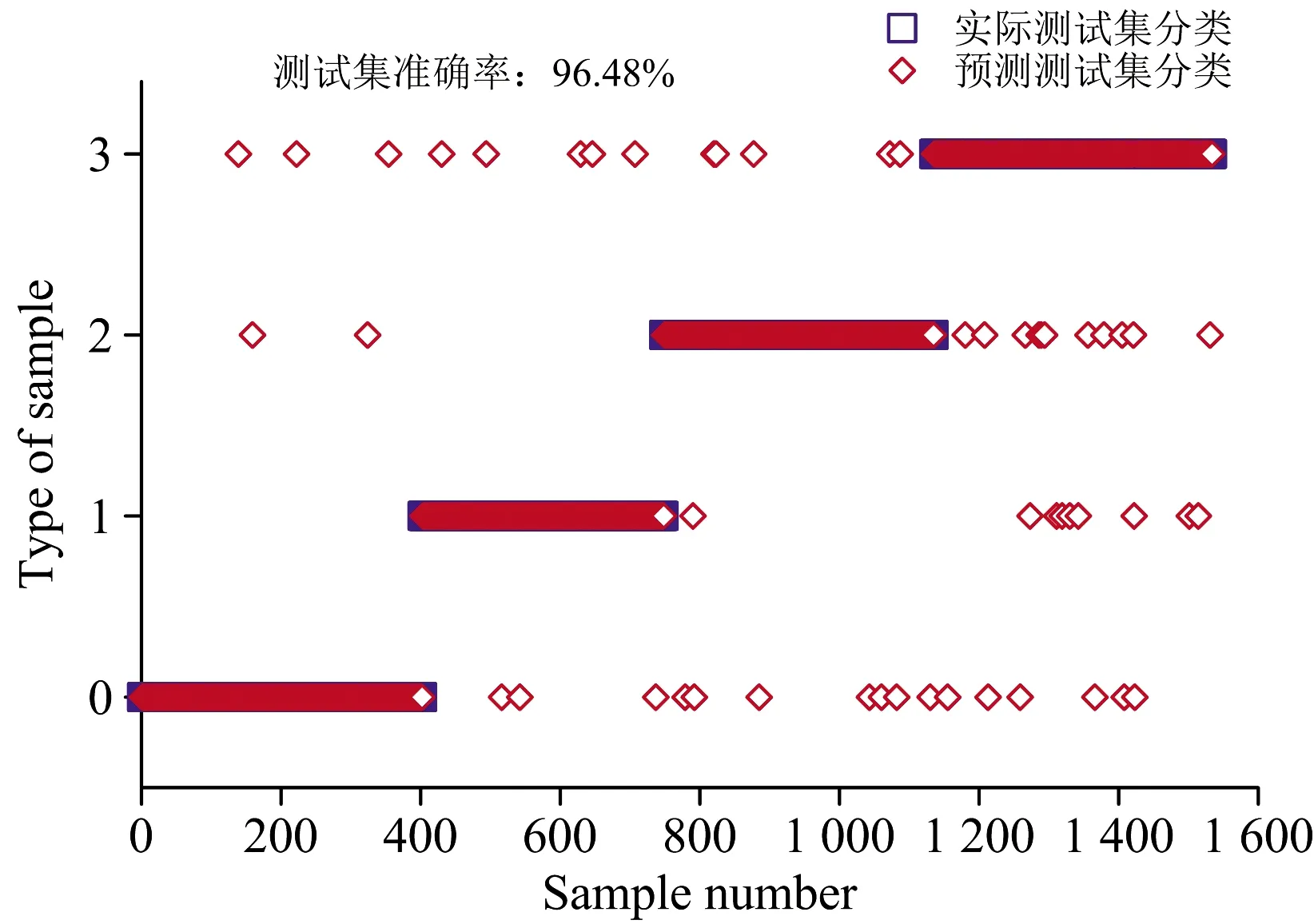
图4 基于二阶差分-UVE-SCARS-RF的分类模型Fig.4 Hierarchical model based on the secondorder difference-UVE-SCARS-RF
3 结 论
针对特优优质奶、高蛋白特色奶、高乳脂特色奶和普通奶建立了无损快速检测分级模型。 选择来自10个牧场的5 121份牛奶样本,保证了模型的通用性和可靠性。 主要结论如下:
(1)探讨了牛奶品质分级的最佳预处理算法,结果表明无论是NB模型还是RF模型,二阶差分均为最佳预处理方法,并将其用于后续的建模分析。
(2)探讨了UVE,CARS,SCARS,UVE-CARS和UVE-SCARS 5种特征提取算法对NB模型和RF模型性能的影响。 结果表明对于NB模型,SCARS为最佳特征提取算法,对于RF模型,最佳的特征提取算法为UVE-SCARS,但RF模型的精度优于NB模型。
(3)在实际生产中,效率也十分重要。 在测试集中,二阶差分-SCARS-NB模型的运行时间为5.53 s,二阶差分-UVE-SCARS-RF模型的运行时间为6.06 s。 综合考虑精度和效率,最终选择二阶差分-UVE-SCARS-RF模型作为牛奶品质分级的最佳模型。
