群落尺度植被水土保持功能评价模型的构建
——以大别山北麓安徽省金寨县为例
2022-04-02张洪达赵传普戴玉婷杨绮梦頔
张洪达, 赵传普, 戴玉婷, 袁 利, 杨绮梦頔, 吴 傲, 刘 霞
(1.南京林业大学 南方现代林业协同创新中心, 江苏省水土保持与生态修复重点实验室,江苏 南京 210037; 2.水利部 淮河水利委员会 淮河流域水土保持监测中心站, 安徽 蚌埠 233001)
植被是防止水土流失、维持生态平衡、改善生态环境的重要因素[1],具有涵养水源、保持水土、防风固沙等作用[2]。植被作为影响水土流失的一个重要因子受到人们的广泛关注[3-4],而研究植被水土保持功能对生态保护、减少地表径流及土壤流失等研究具有重要意义。
长期以来,植被水土保持功能评价主要以植被覆盖度单一指标为主,在植被覆盖度与土壤流失量定量关系研究中[5],植被覆盖度与土壤流失量之间相关性显著,但尚未形成统一的定量关系[6]。此外,在相同覆盖度下,不同植被类型、结构的水土保持功能存在明显差异。因此,采用单一指标评价其结果存在一定的局限。随着植被水土保持机理研究的深入,近来许多学者提出了包含植被垂直结构(层次)、植被类型、枯枝落叶层、根系层等[7]多指标体系的综合评价方法,可较全面的反映植被特性。但因受地理区域、自然条件差异影响,确定的最优水土保持植被类型、植被结构、群落组成都不相同。到目前为止,尚未能形成一个公认统一的指标体系,综合性的评价指标研究还停留在小尺度的定点观测上,未能满足于生产实践的需要[8-11]。
大别山区为中国中部地区的重要生态功能区和淮河上游地区生态屏障。随着区域经济社会发展,该区水土流失问题日益严峻,其植被水土保持功能状况及其评价成为研究热点。本文以大别山区北麓金寨县为研究区,以森林、灌草植被为研究对象,探索面向群落尺度的植被水土保持功能评价模型构建方法,以期为大别山区植被水土保持生态建设提供参考依据。
1 研究区概况
研究区位于鄂豫皖3省交界的大别山主脉北麓安徽省金寨县(115°22′—116°11′E,31°06′—31°48′N),总面积3 814 km2。地势南高北低,以斜坡(8°~15°)、陡坡(15°~25°)为主。属北亚热带湿润季风气候区,多年平均降雨量1 389.6 mm,多年平均气温15~16.3 ℃。岩石主要为花岗岩和花岗片麻岩,土壤主要是粗骨土、黄棕壤、山地棕壤、紫色土等。研究区森林覆盖率达74.1%。防护林主要树种有马尾松(Pinusmassoniana)、麻栎(Quercusacutissima)、青冈栎(Cyclobalanopsisglauca)、化香(Platycaryastrobilacea);用材林主要树种有杉木(Cunninghamialanceolata)、毛竹(Phyllostachysedulis);经济林主要树种有板栗(Castaneamollissima)、山核桃(Caryacathayensis)、油茶(Camelliaoleifera)、茶(Camelliasinensis)等。
2 材料与方法
2.1 数据获取
2.1.1 数据来源 金寨县森林资源2类调查图斑数据和森林资源分布图(1∶30万,2018年)由林业部门提供,SRTM分辨率30 m数字高程模型来源于地理空间数据云。文献数据源来自于2020年中国学术期刊网络数据库,检索相关研究文献并分析研究热点,统计高频词频次。
2.1.2 野外调查 基于森林资源分布图,植被类型分为防护林、用材林、经济林、灌草4个组,在考虑代表性、易获取性及空间分布均匀等原则基础上,按照植被类型采用分层抽样方法确定野外调查样区。在每组优势树种中按图斑数量随机抽取1%,研究区整体抽样比例为0.67%,结合坡度、坡向、高程等确保在各等级均有分布。 确定地面调查样区120个、多光谱无人机调查样区100个,于2019年8月开展野外实地调查。调查样区选择结果见表1,其空间分布见图1。

图1 大别山北麓安徽省金寨县调查样区分布

表1 野外调查样区统计
野外调查包括地面调查和无人机调查。其中,地面调查样方设置为乔木层(30 m×30 m)、灌木层(5 m×5 m)、草本层(1 m×1 m)地被层(1 m×1 m)。郁闭度、盖度及叶面积指数测量采用五点测量法,即以样区4个角点和中心点为测定位置,多次测量求平均值;采用植被覆盖度动态测量系统测量郁闭度、盖度;叶面积指数仪(型号:LAI-2 000)测量叶面积指数。
无人机调查借助无人机(型号:大疆m600-pro)搭载多光谱传感器(型号:MicaSense RedEdge-M)获取植被覆盖度信息。航线规划不低于75%的航向、旁向重复度,飞行相对高度为200 m,主航向重叠率设置80%,范围500 m×500 m。
2.2 研究方法
2.2.1 植被水土保持功能指标筛选
(1) 文献计量法。采用CNKI网5.3.R4数据分析模块,对涉及植被水土保持功能关键词进行统计,通过有效挖掘和分析比较实现指标预选[12]。
(2) 专家咨询法。选取从事水土保持功能相关研究的教学与科研人员、已发表类似文章且有较高引用率的研究人员、以及研究区具有高级技术职称的水土保持生产实践工作者对预选指标进一步分析与遴选[13]。
2.2.2 指标变量筛选方法
(1) 随机森林。随机森林方法在对数据进行分类的同时,可以给出各个指标变量在分类中的重要性评分,依据该评分可以对指标变量进行排序来判断指标变量在分类中起到的作用大小,并筛选出相对重要的指标变量[14-15]。
(2) 决策树。决策树以树状结构表现,叶子结点代表一个结论,内部结点描述一个属性,是从上到下一条路径来确定的分类规则[15]。通过构建决策树规则帮助了解各指标变量的贡献大小、方向,指标变量间的关系更加易懂。
2.2.3 土壤流失评价方法 结合野外调查实测数据,基于CSLE模型计算调查样区土壤流失量。公式如下[16]:
A=R·K·L·S·B·E·T
(1)
式中:A为年单位面积的土壤流失量〔t/(hm2·a)〕;R为降雨侵蚀力因子〔MJ·mm/(hm2·h·a)〕;K为土壤可蚀性因子〔t·hm2·h/(hm2·MJ·mm)〕;L为坡长因子(无量纲);S为坡度因子(无量纲);B为生物措施因子(无量纲);E为工程措施因子(无量纲);T为耕作措施因子(无量纲);各因子采用年度水土流失动态监测成果。
2.2.4 植被水土保持功能评价模型 基于随机森林重要性排序指标同土壤流失量建立回归关系。多元线性回归模型可以表示为[17]:
A=β0+β1X1+β2X2+,…,+biXi+ui
(2)
式中:A为模型因变量,即土壤侵蚀模数。X1,X2,…,Xi为解释变量,即郁闭度、盖度、坡度、枯落物厚度等;β0,β1,…,βi为模型回归系数,即被估计量;ui随机误差项。
3 结果与分析
3.1 植被水土保持功能评价指标筛选
3.1.1 基于文献计量学的评价指标预选 以植被水土保持功能、植被水土保持效应、植被水土保持功能评价等作为主题词,对1980—2020年文献进行检索,共检索相关文献2 916篇。通过进一步甄别,筛选出中国国内与本研究相关度较高的198篇文献进行分析。
基于词频分析法,对植被水土保持功能及评价的相关文献进行分析,并对关键词进行词频统计(表2)。在植被水土保持功能研究中核心关键词是枯落物层、林分结构和植被类型等。词频统计结果可归纳为3大类72项指标,即:功能表征指标(如非毛管孔隙度、土壤最大持水量、林冠截留、地表径流、土壤抗冲性、毛管孔隙度等)、功能影响指标(群落类型、结构、数量特征、枯落物层、植被类型、土壤层/根系层等)、地形因子指标(坡度、坡位等)。

表2 植被水土保持功能研究关键词统计
3.1.2 基于专家咨询的评价指标初选 专家组由3方面人员组成:①从事水土保持与荒漠化防治教学与科研任务的人员;②长期从事水土保持工作,且有5 a以上工作经验的并取得高级技术职称的一线工作者;③已发表了类似文章的且有较高引用率的研究人员。确定了30名在植被水土保持功能研究及评价领域较为熟悉的专家。
基于文献计量学指标预选结果,对每一项指标通过“A(极重要),B(重要),C(一般),D(不重要)”4个选项来咨询,保留均值X≥3且变异系数CV≤0.25的指标[13],确定了植被水土保持功能初选指标集。以植被水土保持功能为评价的总体目标,指标体系包括自然因素和人为因素两大类。构建了3层指标体系,其中一级指标4项,二级指标7项,三级指标30项。植被水土保持功能初选指标详见表3。
3.2 基于决策树的植被水土保持功能评价模型构建
3.2.1 基于决策树的指标相关关系分析 为进一步分析各特征指标的作用规律,利用指标决策树分类回归模型通过一些显著指标进行量化。根据生成的复杂度参数与交叉验证误差(图2),查找其最优的切分变量和最理想的分割节点,目的是将决策树大小控制在一个理想的范围内。可知决策树最优分割为4个节点时误差达最小。
由图2及图3a可知,决策树各节点对应的指标特征同下文的指标重要性特征规律基本一致。其中,在决策树中坡度是一项具有全局性的重要变量指标,阈值9.5°时决策树分成了左、右两类。为了更好的分析坡度指标对侵蚀量的影响,绘制了坡度与侵蚀量的散点图(图3b),由图3b可知,在10°临界坡度处土壤侵蚀模数分布特征存在显著差异,在<10°范围呈现明显“聚集性”分布特征;在>10°范围呈正相关关系。

图2 复杂度参数与交叉验证误差
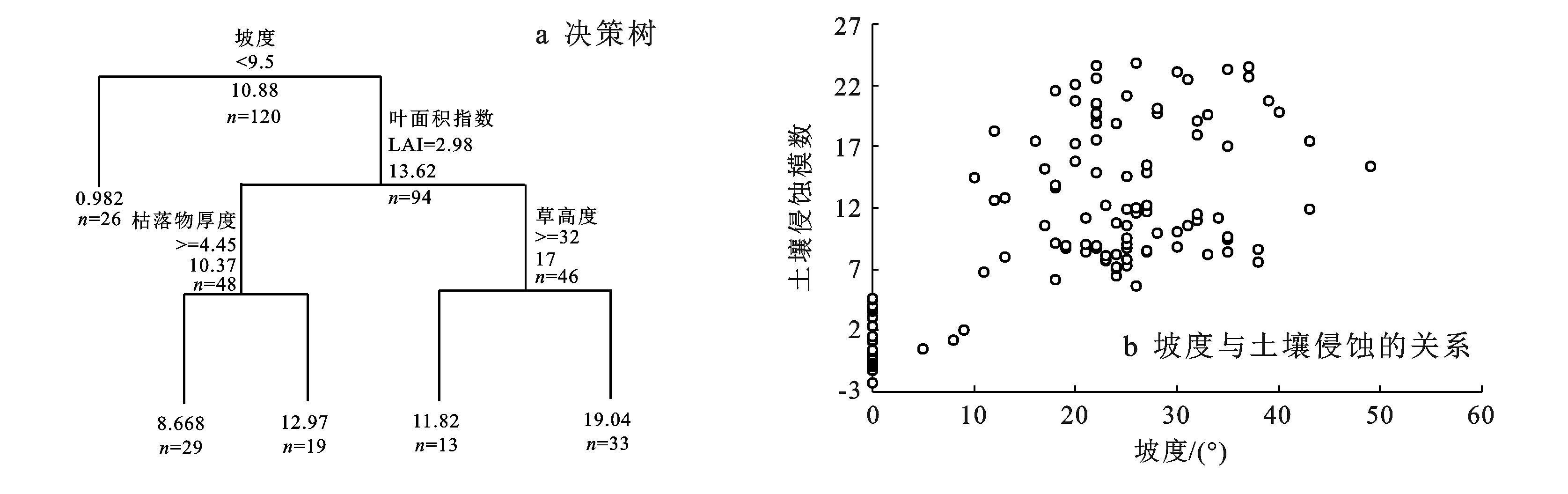
图3 植被水土保持功能决策树、坡度与土壤侵蚀关系
综合上述指标变量间决策树关系分析,较清晰的展示出了指标同土壤流失量相互关系,基于此在群落尺度植被水土保持功能评价模型构建。根据坡度关键变量特征10°坡度为临界值,以<10°坡度和≥10°坡度划分成两部分,将野外调查实测值分别进行局部回归建模。
3.2.2 局部回归 基于上述分析按10°坡度为临界点将野外调查点实测值分成两部分,将指标引入多元回归方程,然后根据分析结果剔除统计学意义不显著的变量,直至所构建的回归方程中不再有可剔除变量。经多元逐步回归,当坡度<10°时构建方程包括草盖度、枯落物厚度为极显著(p<0.001),乔木郁闭度、乔木密度为较显著(p<0.01),灌木高、乔木胸径为显著(p<0.05)共6项指标,模型决定系数R2为0.74;当坡度≥10°构建方程包括草盖度、灌木盖度及枯落物厚度为极显著(p<0.001),乔冠层厚度较显著(p<0.01),坡度、乔胸径为显著(p<0.05)6项指标,模型决定系R2为0.64。局部回归模型详细参数见表4。

表4 水土保持功能评价局部回归模型参数
3.3 基于随机森林的植被水土保持功能评价模型构建
3.3.1 基于随机森林的指标重要性排序 基于R语言随机森林,将植被类型、群落结构、地形等因素所选取的30项初选指标的实测值为自变量,与对应点位土壤流失量为因变量进行随机森林回归。本文采用随机森林重要性评价进行指标分析,分析指标重要性及影响规律,可以为植被水土保持功能评价提供重要指导[18]。
随机森林中涉及ntree和mtry两个参数,即决策树颗数和节点分裂的次数。通常在ntree增加时,模型预测精度不能提高的情况下,ntree设定应尽可能小,mtry设定为变量个数的1/3。此外随机森林算法对样本数据的量纲和单位不敏感,故运算时无需对样本数据进行归一化处理[10]。以初选30项指标建立训练集获取最优试算参数,可知,随机森林模型参数为特征数10决策树为500棵时,误差趋于稳定且达到最小。决策树数量与误差关系图4。
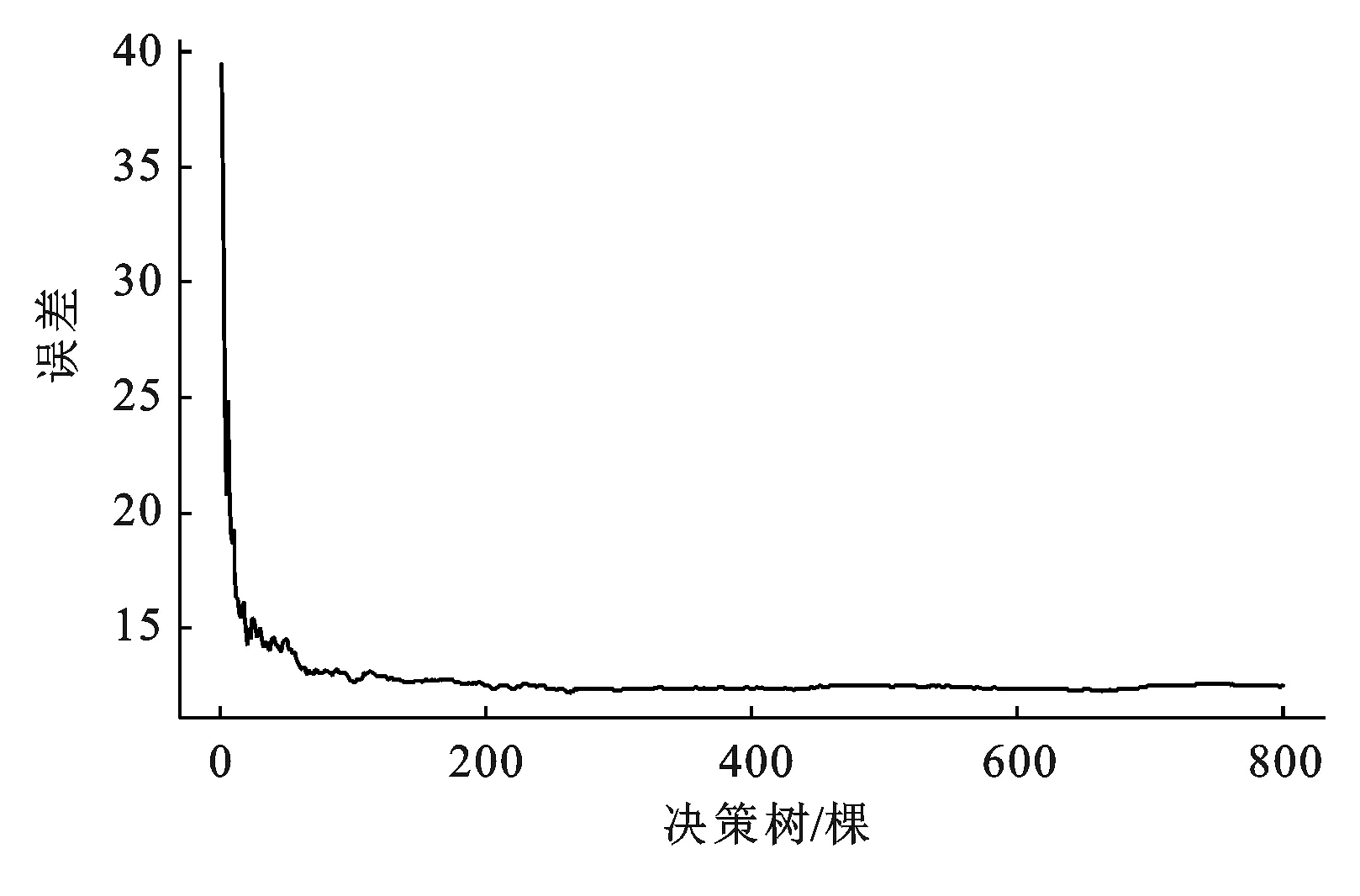
图4 决策树数量与误差关系
由图5指标重要性排序结果可看出,影响水土保持功能的主要指标是坡度、坡位,其次是枯落物厚度、叶面积指数,而道路距离、村庄距离影响最小。如图5所示,水土保持功能评价模型指标重要性排序为:坡度>坡位>枯落物厚度>,…,>村庄距离。由图5可知,坡度、坡位、枯落物厚度、叶面积指数等排序前12个指标(%IncMSE>3.2),对模型的整体贡献度超70%,在植被水土保持功能评价模型构建时可以前12项指标进行回归建模。
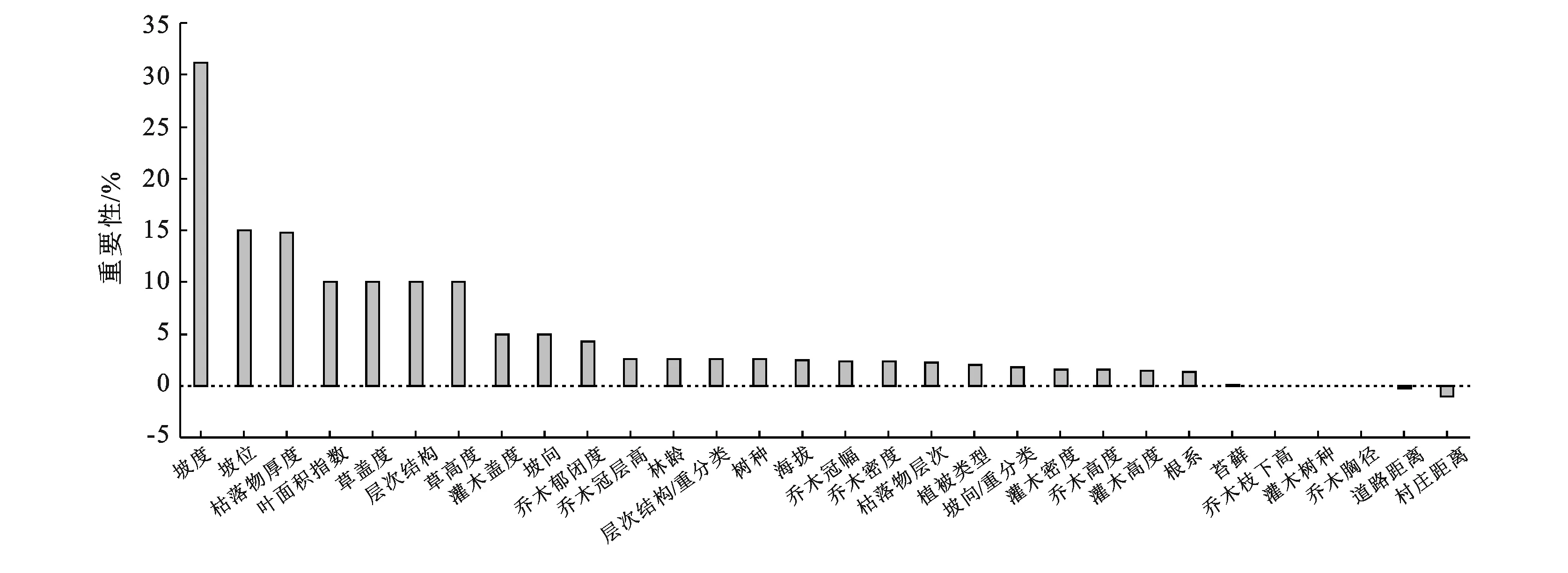
图5 水土保持功能评价模型评价指标重要性排序
3.3.2 全局回归 将野外调查点实测值作为一个整体,以指标重要性排序的前12项与土壤侵蚀模数建立回归关系,并进行逐步回归根据回归结果剔除统计学意义不显著的变量,直至所构建的回归方程中不再有可剔除变量。表5结果显示最终显著性水平高的指标有5项,其中,坡度、草盖度和枯落物厚度显著性为极显著(p<0.001),林龄、灌木盖度为显著(p<0.05),模型决定系数R2为0.71。全局回归模型详细参数见表5。
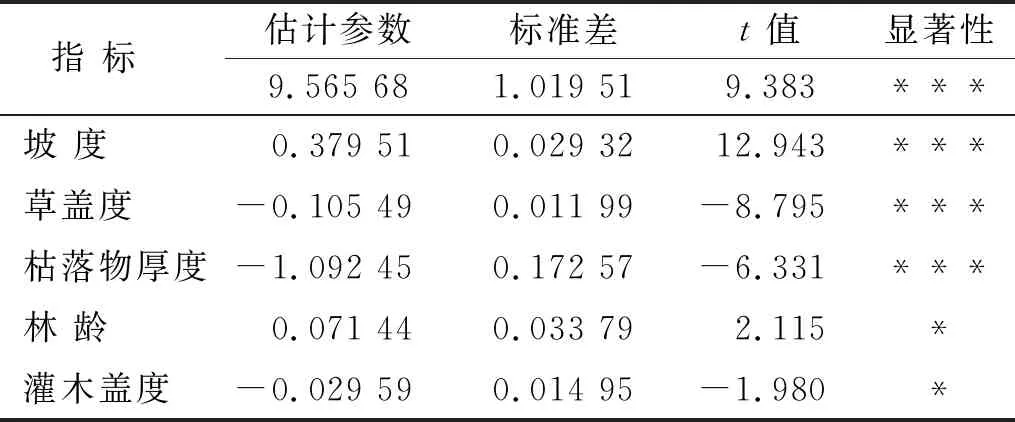
表5 水土保持功能评价全局回归模型参数
综上对比两种建模回归结果来看,其全局回归效果(R2为0.71)较局部回归(R2均值为0.69)更优,可见,坡度在植被水土保持功能中并非其关键变量。因此,选取全局回归5项指标作为评价,从群落尺度评价植被水土保持功能更简便、高效。
3.4 植被水土保持功能评价结果验证
采用前文研究的群落尺度植被水土保持功能评价全局回归模型,对研究区植被类型进行评价。根据评价结果将植被水土保持功能划分为5个等级:优(>0.8),良(0.6~0.8),中(0.4~0.6),差(0.2~0.4),极差(<0.2)。由表6各植被类型水土保持功能评价结果均值可知,研究区植被水土保持功能为防护林(0.705)>用材林(0.529)>经济林(0.513)>灌草(0.457)。

表6 金寨县群落尺度植被水土保持功能评价结果
4 讨论与结论
(1) 水土保持功能评价研究,主要有单一指标评价、多指标综合评价两类[5]。众多研究表明植被水土保持功能是多个结构层次共同作用的结果,综合指标评价优于单一指标评价。多指标综合评价将植被划分为多个层次(群落组成、垂直结构等),强调枯落物层的作用,多以枯落物的盖度、厚度及持水量等做为重要指标[19]。在群落尺度水土保持功能研究中黄进等[20]利用林冠截留率、灌草层盖度、枯落物盖度等8个指标,采用加权综合法对浙江省生态公益林的水土保持功能进行评价。张锐[21]选取了植被、枯枝落叶、土壤、地形4个准则层的19个评价指标,以综合评价理想点法比较了5种类型人工林地的水土保持功能。以上均对森林的水土保持功能做出合乎实际的科学评价,指标体系也能较为全面地反映植物特性。本文与同类研究对比来看指标间存在一定差异,其主要原因是研究区地理位置、立地条件、植被类型及分布差异所致。
(2) 植被水土保持功能评价指标体系构建。本文基于已有研究通过“预选—初选—复选”分层逐级聚焦构建。“预选”是以文献计量法对已发表文献的研究热点及方向进行词频统计分析共选取了72项指标;其后利用专家咨询法打分评判方式选取包括植被类型、结构层次等“初选”指标30项,以野外调查获取现场实测值;最后以随机森林机器学习方法将初选指标重要性量化排序结合数学建模逐步回归的方式,构建了群落尺度的指标评价体系包括坡度、林龄、灌木盖度、草盖度、枯落物厚度5项R2为0.71。本文利用随机森林机器学习算法与多元线性回归法结合建立植被水土保持功能评价模型,相较于已有研究所采用的层次分析、主成分分析法[22-23],在处理高维复杂数据时,随机森林算法表现更稳健、是精度和效率均较高的算法,而且结果也更易于解释。线性回归对于功能的综合性、整体性能有较好的体现,此方法在群落尺度水土保持功能评价应用可操作性强更易于掌握。
(3) 研究区植被水土保持功能评价结果为:防护林(0.705)>用材林>(0.529)经济林(0.513)>灌草(0.457)。评价结果与前人研究基本一致呈现出:林>灌>草的规律,植被具有成层现象,天然植被相较于人工植被所发挥的水土保持功能更强[24]。
