基于视觉的位姿计算技术在图书馆中的应用探索
2022-04-02牛悦 李辉
牛悦 李辉






摘 要 计算机视觉技术在产业升级中发挥了重要的作用,是建设下一代智慧图书馆的关键技术,而位姿计算技术是计算机视觉技术重要的研究应用方向。论文首次探索了基于视觉的位姿计算技术在图书馆中的应用,探讨了该技术对图书馆服务的重要意义,并且基于开源框架成功实现了基于视觉的位姿计算技术,将位姿计算系统实际部署在西北工业大学图书馆中。代表性场景的位姿计算结果表明,论文基于视觉的位姿计算技术方法,其位移精度在10厘米以内,角度精度在2度以内,定位平均耗时约为50毫秒,位姿精度和时间性能满足图书馆场景下定位的需求。论文是将计算机视觉技术用于构建智慧图书馆的一次有益尝试,也为其他相关技术在图书馆的落地实践提供了较好的借鉴作用。
关键词 六自由度;视觉定位;位姿计算;图书馆;计算机视觉
分类号 G250.7
DOI 10.16810/j.cnki.1672-514X.2022.03.008
Application of Vision-based Location and Pose Computation Method in Library
Niu Yue, Li Hui
Abstract Computer vision plays an important role and value in industrial upgrading, and are key technologies for constructing next-generation intelligent library. Vision-based 6dof location method is an important research and application direction of this filed. This work is the first time to explore applying vision-based location and pose calculation method in library scenario, and discuss the important value of the related applications. We implemented the vison-based location and pose calculation method based on some open source frameworks, and successfully deploy the location system in NWPU library. Representative scenarios show that transition and rotation accuracy of our vision-based location and pose calculation method are within 10 cm and 2 degree respectively, execution time of one calculation is about 50 ms, which can satisfy library requirements. This work is a valuable attempt of applying computer vision technology in intelligent library field, and has good reference function of practicing related technologies.
Keywords 6dof. Vision-based location. Location and pose calculation. Library. Computer vision.
0 引言
智慧图书馆已经成为当前图书馆应用研究的热点[1],其中将计算机视觉技术引入图书馆,促进智慧图书馆的发展,具有重要的研究和应用价值。
基于摄像头采集的图像数据,计算机视觉技术能显著提高智慧图书馆的自动化和智能化,由此,基于计算机视觉的智慧图书馆的相关领域得到了广泛应用。(1)人机交互领域。基于计算机视觉技术在视频处理技术,使读者和图书馆的交互从传统的鼠标和键盘扩展到了语音、图像、手势等多个维度。上海图书馆的“图小灵”应用相关的技术24小时给师生提供更为精细的咨询服务。(2)基于人脸的门禁和身份识别系统。人脸检测识别技术被大规模应用于图书馆门禁系统、借还书系统、签到系统等后,系统的安全性和效率都得到了极大的提升。(3)基于计算机视觉的图书识别辅助系统。应用计算机视觉技术对图书馆中的书籍进行管理能极大地促进智慧图书馆的建设。例如:使用文字识别对新图书自动录库,应用视觉技术对图书资源进行修补,都能够极大地提高相关工作的效率,降低人工干预的程度,达成智慧图书馆自动化、智能化建设的目标。
除了上述的应用,计算机视觉领域的一个重要分支——位姿计算技术,即采用计算机图像处理的方法实时地获取摄像头设备的位置和姿态,在图书馆的应用中并未被充分发掘和探讨。相对基于电磁波(例如GPS,Wifi和蓝牙等)的三自由度(仅有三维坐标)定位技术,视觉位姿计算技术有抗干扰、定位精度高、可以获取六个自由度(三维坐标+三个旋转角度)的优点。由于可以准确地获取限定设备位置和姿态的六维信息,基于视觉的位姿计算技术可以给图书馆带来除了位置服务外更多的智能应用,例如增强现实、机器人无人机导航等。为此本文将重点探讨基于视觉的位姿计算技术在构建智慧图书馆中的重要价值,并以位姿计算技术在西北工业大学图书馆的应用作为实例进行研究分析。
1 基于视觉的位姿计算技术在图書馆中的应用
基于视觉的位姿计算技术的定义为:通过分析摄像头获取的图像,计算得到摄像头的三维位置(x、y、z)和相对于x、y、z三个坐标轴的旋转信息,这六个变量可以唯一确定摄像头的位置和姿态,所以也叫六自由度定位。由于基于电磁波信号的定位原理是通过信号强度计算距离,然后使用三角定位,所以主流的定位方法,例如蓝牙、wifi、GPS等都只能获取到三个自由度(x、y、z)的信息,而没有另外三个自由度的姿态信息。没有姿态的信息,就无法得到无人机、用户手机等设备的朝向信息,从而导致很多的应用无法使用。此外,基于信号强度的电磁波定位方法在室内极易受遮挡物和多源反射的干扰,所以在室内大多数情况下无法正常使用。而基于视觉的位姿计算技术刚好可以克服上述基于电磁波定位的两个重要缺点,所以在很多领域具有重要的应用价值。
目前,基于视觉的位姿计算技术已经成功地在机器人导航[2]、无人机室内导航[3]和增强现实[4]领域得到了应用,例如苹果公司的ARKit、谷歌公司的ARCore等。而基于视觉的位姿计算技术在图书馆中也有很多具有重要价值的应用。主要包括以下几个方面。
(1)室内导航。通过基于视觉的位姿计算给读者提供图书馆路径规划。读者输入图书馆内想去的目的地,然后只要掏出手机拍摄当前场景的画面,就可以在手机图书馆地图上得到一条最优的路径,极大方便了读者在图书馆寻找目的地和相关设施。
(2)为读者推送信息服务。当读者到达图书馆的某个区域后,图书馆通过视觉算法获取其准确的位姿信息,可以给用户推送其可能感兴趣的信息和服务。例如阅览室里最热门的书籍,可快速给读者规划最优到达路径;或者最便利位置的自助借还机,可推送到达路径;也可以推送阅览室位置以及该室的重点服务内容等,让读者享受个性化的智能位置服务,提高图书馆信息服务的利用率。
(3)机器人自主配送。通过机器人自身携带的摄像头设备来获取其自身在三维世界中准确的位置和姿态信息,结合三维地图完成自主导航、配送等服务。例如,机器人自主配送代替现在繁重的基于人工的图书和资料配送服务,将工作人员解放出来;自主导航的清洁机器人还可以代替工作人员完成图书馆的清洁、消毒等工作,让人力应用在更加有意义的地方。另外,在2020年突发新冠肺炎疫情的背景下,机器人自主配送非常切合“非接触式服务”的需求,读者无需进入阅览室相关区域,只需将要还的书籍交由机器人,或者将要借图书的指令信息发给机器人,机器人便可代替读者完成全套自助借还书服务;还包括取查新报告、检索报告等,读者甚至不用进图书馆就可以获取到所需的资源,彻底切断接触可能导致细菌感染的风险。
(4)增强现实。通过对摄像头采集的场景图像进行处理,可計算用户设备实时的位姿信息,然后在真实的三维场景中渲染虚拟的物体对象,一起显示在用户的设备上,从而获得增强现实的能力。利用基于视觉定位的增强现实工具,可在图书馆真实场景中放置虚拟的信息公告栏,节约图书馆的成本,并响应“无纸化”图书馆的号召。还可以在图书馆大厅中放置栩栩如生的动态虚拟模型,让读者看到展示对象的所有动态细节,大大节省了空间。这种基于增强现实的教育展示方式易于模型的移动、更新和管理,极大节省了教育成本,提高了图书馆普及知识的效率。
(5)图书的虚拟介绍。当读者走进阅览室借阅图书的时候,每靠近一列书架,都可通过手机终端看到书架旁展示的虚拟书籍信息介绍,读者可以自行选择感兴趣的一类图书,也可以具体应用到某一本特定图书。这些信息的获取都非常快捷、准确,读者也同时拥有了很美妙的沉浸式用户借阅体验,从某种程度上来说必然会增加读者的进馆次数。
(6)活动展示应用。图书馆经常会举办各种种类丰富的活动,一些需要事物展示的活动,譬如外文原版书籍展示、图书馆老物件展示、建党和相关爱国主义文献展示等教育活动都可以取消实体展示,也不需要使用大屏幕,读者只需用自己的手机终端即可实时观看,不仅节省了大屏幕的购置成本和组织实物及展示的人力成本。
(7)读者寻求实时响应帮助。当读者在图书馆内发生意外时,可以通过基于视觉的位姿计算准确上报自己的位置并进行报警,使得图书馆工作人员可以在第一时间前往并处理,从而给读者提供更好的安全保障服务。
2 基于视觉的位姿计算技术在图书馆平台的建模流程
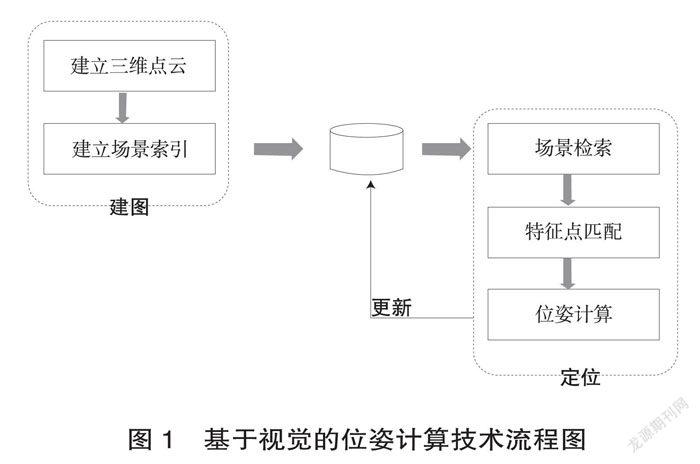
基于视觉的位姿计算技术主要包括建图和定位两大部分。其中,建图部分包括建立三维点云和场景索引两个步骤,建图生成的结果被存储在数据库中;定位部分包括场景检索、特征点匹配和位姿计算三个步骤,最后,定位的结果会动态地更新建图生成的数据库,保证数据库中的数据处在最新的状态。基于视觉的位姿计算技术整个流程如图1所示:
2.1 建图部分
这个部分对场景的图像进行处理,使用特征点描述子提取、图像索引等视觉技术,建立定位步骤需要使用的特征点和索引数据库。建图分为以下两个具体的步骤。
步骤一:建立三维点云。给定覆盖场景的图像集合,我们将使用多视几何[5]的方法来构建场景的三维点云。首先,选取两幅图像进行特征点和描述子的提取;然后计算两幅图像之间特征点的匹配关系;最后,根据匹配结果利用三角定位的原理计算出这些匹配的特征点的三维位置,形成三维点云。重复以上过程直到所有的图像都被处理,即可得到场景的三维点云。三维点云中包括点的三维坐标和点的描述子信息,这些信息在后面的位姿计算中将会被用到。
步骤二:建立场景索引。三维点云涵盖了整个场景的信息,为了方便地定位到某个具体的场景,我们需要对场景进行索引。即对某些领域的三维点云和描述子进行索引,将其转化成一个索引向量,例如:在图书馆的点云中,可以分别建立大厅、阅览室、自习室等不同局部场景的索引,便于后续的快速定位查找。经过上述两个步骤的处理,我们就得到了一个描述场景的三维点云和索引数据库。
2.2 定位部分
这个部分将利用建图部分得到的索引数据快速定位到相关的局部场景,然后使用特征点匹配得到从三维点到二维点的对应关系,最后使用三维、二维的对应关系计算得到位姿信息。定位部分分为以下三个具体的步骤。
步骤一:场景检索。给定一幅摄像头拍摄的查询图像,我们首先计算该图像的索引,然后使用该索引在数据库中进行查询,从而定位到最相关的局部场景索引。
步骤二:特征点匹配。我们搜集步骤一得到的局部场景的所有相关三维点和描述子信息,然后提取查询图像的特征点和描述子信息,最后再对上面两组描述子进行特征点匹配,得到匹配的特征点集合。
步骤三:位姿计算。通过上面的步骤,我们得到了一个3D-2D点的集合,即n个三维空间点坐标及其二维投影位置,它们符合下面的成像关系。
其中,(u、v)为成像平面的像素坐标,(X、Y、Z)为三维点的物理空间坐标,(fx、fy、cx、cy)为相机的焦距和中心坐标,称为内部参数;剩余部分表示相机的旋转和平移,称为外部参数,是我们要求解的部分。由于我们有很多的3D-2D点,所以可以建立多个上述的方程,然后采用优化的方法就可以计算出外部参数,即相机的位姿。
在每一次定位的过程中,要根据一定的策略,增加新出现的三维点,剔除一些多次定位没有被匹配上的特征点,来对三维点云进行更新,保证其反映场景最新的特征。
3 基于图书馆服务平台的嵌入视觉位姿结构
图书馆服务平台如图2所示,分为数据收集层、数据处理层、应用服务层、用户交互层四个层次。视觉位姿计算程序部署在数据处理层,该层从数据收集层获取图书馆内各种带摄像头的设备捕获的图像视频数据作为输入,然后使用相关的位姿计算方法对这些数据进行处理,实时获得对应设备的位置和姿态。这些位姿信息作为输出,传递给应用服务层中的相关应用程序,结合图书馆的其他信息给智慧图书馆提供室内导航、信息推送、机器人自主配送、增强现实、安全等服务。这些应用服务可以通过用户交互层被图书馆中的人员和机器访问。
4 基于视觉的位姿计算技术的具体实现
我们采用以下的具体方法来实现六自由度基于视觉的位姿计算方法。图像特征点和描述子采用SIFT[6]方法。SIFT特征是最主流的图像局部特征提取方法,具有尺度不变形和旋转不变形的优点,且对于光线、噪声、微视角改变的容忍度也相当高,所以该特征高度显著且容易提取,非常利于后续的图像匹配步骤。SIFT特征点提取、描述子计算采用OpenCV的编程接口进行实现,其相关代码如下所示,变量keypoint和descriptor为使用OpenCV的SIFT编程接口从图像image中提出的特征点和描述子。
sift = cv2.xfeatures2d.SIFT_create( contrast
Threshold = 0.04, edgeThreshold=10)
keypoint, descriptor=sift.detectAndCompute
(image,None)
三维点云的产生采用了colmap[7-8]开源框架,该开源框架是基于structure-from-motion多視几何方法对场景进行重建的。利用该框架的编程接口,输入场景的图像集合,可以得到场景的三维点云图。在重建的点云图中场景的很多重要物体可被很好地还原出来。在还原的过程中,需要建立图像所引。
图像索引的建立采用VLAD[9]算法。该算法通过聚类方法得到若干聚类中心,随后将所有特征与聚类中心的差值做累加,得到一个k行d列的矩阵,其中k是聚类中心个数,d是特征维数;最后将该矩阵扩展为一个(k*d)维的向量,归一化得到最终的索引向量。我们采用VLADLib(https://github.com/jorjasso/VLAD)开源库来实现VLAD索引向量的计算、存储和检索操作。图像描述子匹配采用OpenCV暴力匹配方法。为了提高匹配的准确性、避免相似点之间的误匹配,还可采用ratio test方法,即每次找到两个最匹配的点,并且要求这两组匹配之间的距离必须大于某个阈值。描述子匹配相关的代码如下所示。
bf = cv2.BFMatcher()
matches = bf.knnMatch(des, des_q,k=2)
#ratio test
thre_ratio = 0.75
good_matches = []
for m,n in matches:
if m.distance < thre_ratio*n.distance:
good_matches.append([m])
matches为应用OpenCV的BFMatcher方法得到的匹配集合,我们应用0.75的阈值,排除相近的匹配点后得到最终的匹配集合good_matches。
从3D-2D映射集合中计算相机位姿采用Opencv的solvePNP方法[10]。由于3D-2D集合中可能会存在错误的匹配点,所以在计算位姿时,我们采用随机一致性采样Ransac方法[11],其基本思想为:反复选择数据中的一组被假设为正确匹配的随机子集,直到最小的投影误差。Ransac方法最多可以处理50%的错误匹配点情况,其位姿计算的实现代码如下所示。
fx,fy,cx,cy = camera.params
camera_matrix = np.array([[fx,0,cx],[0,fy,
cy],[0,0,1]])
result = cv2.solvePnPRansac(np.
array(xyz),np.array(xy),camera_matrix,0)
rvec = result[1]
tvec = result[2]
inlier_ratio =len(result[3])/len(xyz)
其中,camera_matrix为相机的内部参数矩阵,xyz为三维点集合,xy为对应的二维点集合。cv2.solvePnPRansac为OpenCV采用Ransac的solvePNP方法。得到的结果中:rvec为旋转矩阵,tvec为三维位移坐标,inlier_ratio为正确的匹配点比例。
5 基于视觉的位姿计算技术在西北工业大学图书馆的实现
我们将上述六自由度的位姿计算系统部署在西北工业大学图书馆的服务器上,服务器配置为GTX1080ti的GPU、Ubuntu16.04的Linux系统。用户通过手机或者终端摄像头拍摄图像上传到服务器,服务器根据输入图像和基于场景的三维点云图,利用上述位姿估计方法计算得到六自由度的位姿,再返回给终端进行显示和后续处理。
5.1 西北工业大学友谊校园大厅场景位姿计算实验
图3为在西北工业大学友谊校区图书馆大厅场景下,基于视觉的位姿计算系统处理170幅图像后得到的位姿示意图。在图3中,每一個四面体的位置都表示当前相机拍摄此图像时的三维位移位置x、y、z,四面体的朝向则表示相机拍摄此图像时的三个姿态信息,从图3中可以看出,基于视觉的位姿计算系统还原了一条连续移动拍摄的位姿轨迹。
为了评估基于视觉的位姿计算技术的精度和时间性能,我们使用带激光雷达的ipad pro在图书馆大厅场景中的各个角度和位置收集了1000幅分辨率为1080p的图像。以激光雷达得到的图像位姿信息(毫米级的精度)作为真值,以单目摄像头收集的1000幅图像送入基于视觉的位姿计算系统进行处理后得到的位姿作为估计值,估计值和真值之间比较后的平均误差如表1所示。
其中,x、y、z为相机在坐标系中的三维位置,a、b、c为相机绕x、y、z三个坐标轴的旋转角度。可以看出,在图书馆大厅这个代表性场景下,相机位移的平均误差在10厘米以内,旋转角度的平均误差在2度内,基本上满足了六自由度定位定姿精度上的需求。
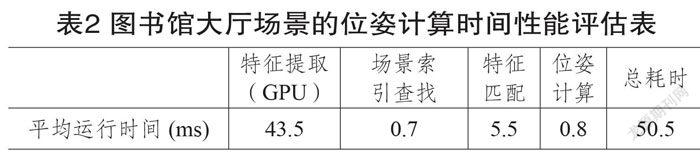
我们进一步评估了服务器对这1000幅1080p分辨率图像进行基于视觉的位姿计算的时间性能,其各个部分和综合的平均耗时如表2所示。
从表2中可以看出,整个过程中最耗时的操作为特征提取,即使在使用GPU的情况下,也需要30毫秒的时间。在图书馆大厅这个代表性场景下,基于视觉的位姿计算总平均耗时为50.5毫秒,约为20fps,基本上满足了实时性的需求。
5.2 在西北工业大学图书馆科普活动中的应用
上文已经陈述了基于视觉的位姿计算技术在西北工业大学图书馆技术部署的实验,并且论证了整个方案的技术可行性,本节将探讨基于视觉的位姿计算技术在西北工业大学图书馆开展科普活动的具体应用实例。
5.2.1 探月科普活动
为了庆祝嫦娥五号登月成功,西北工业大学图书馆使用基于视觉的位姿计算技术中的增强现实技术,将和探月相关的虚拟信息实时渲染在西北工业大学长安校区图书馆大厅中,开展探月科普活动。工作人员提前将相关的虚拟物体布置在图书馆大厅中,和大厅的场景信息进行绑定。当读者来到图书馆大厅打开手机、平板等设备的摄像头采集场景图像时,通过基于视觉的位姿计算技术即可获取读者设备的位置和姿态,并根据位姿信息实时将提前布设好的虚拟物体信息渲染在读者设备的屏幕上。在场景中分别展示了西北工业大学长安校区图书馆大厅中的嫦娥火箭发射前、发射中的场景以及太阳系等虚拟物体。这些虚拟物体栩栩如生,具备动态的细节效果,读者还可以通过设备和其进行交互。这种使用基于视觉的位姿计算和增强现实技术的科普活动给读者带来全新的沉浸式的体验,受到了广泛的好评。此外,利用基于视觉的位姿计算和增强现实技术进行科普展示活动时不需要实物模型,只需要使用手机等设备对虚拟物体进行简单的布设、移动和更新,极大地提高了布设的效率并节省了成本。图4为探月科普活动相关的部分场景图片。
5.2.2 绿色地球科普活动
探月科普活动起到了很好的宣传作用,于是西北工业大学图书馆后续又使用相同的基于视觉的位姿计算和增强现实技术开展了“绿色地球”科普活动,将树木布设在长安校区图书馆大厅,呼吁同学们一起保护绿色地球,相关的场景展示图片如图5所示。
通过使用基于视觉的位姿计算和增强现实技术,我们将几乎无法通过实物模型来布设的树木方便地布设到了图书馆大厅中,同时给学生真实而具有未来感的体验,提高了图书馆普及知识的效率。
参考文献
初景利,段美珍.智慧图书馆与智慧服务[J].图书馆建设,2018(4):85-90,95.
卢燚鑫.移动机器人视觉定位和路径规划若干问题研究[D].成都:西南交通大学,2019:56-63.
吕科,施泽南,李一鹏.微型无人机视觉定位与环境建模研究[J].电子科技大学学报,2017,46(3):543-548.
陈靖,王涌天,郭俊伟,等.基于特征识别的增强现实跟踪定位算法[J].中国科学:信息科学,2010, 40(11):1437-1449.
HARTLEY R,ZISSERMAN A.Multiple view geometry in computer vision[M].Cambridge university press,2003:36-51.
CHEUNG W,GHASSAN H.N-SIFT:n-dimensionalscale invariant feature transform[C].IEEE Transactionson Image Processing,2009,18(9):2012-2021.
SCHöNBERGER J L,JAN-MICHAEL F.Structure-from-motion revisited[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:4104-4113.
SCHöNBERGER J L, ENLIANG Z, JAN-MICHAEL F, et al. Pixelwise view selection for unstructured multi-view stereo[C]. European Conference on Computer Vision,2016: 501-518.
JéGOU H, MATTHIJS D,CORDELIA S,et al.Aggregating local descriptors into a compact image representation[C].IEEE computer society conference on computer vision and pattern recognition,2010: 3304-3311.
VINCENT L, FRANCESC M,PASCAL F,et al.Anaccurate o(n) solution to the pnp problem[J].Internationaljournal of computer vision,2009,81(2):155-166.
DERPANIS K G.Overview of the RANSAC algorithm[M].Image Rochester NY,2010,4(1):2-3.
