基于向量数据库的智能媒资搜索研究
2022-04-01张浩
张 浩
(河南广播电视台,河南 郑州 450003)
0 引言
近年来,机器学习发展迅猛,深度学习作为机器学习的重要分支之一,引起了多行业的广泛关注。深度学习在文本、图像、视频等方面有着重要应用。在广播电视行业,为了提高对媒资内容的管理和分析能力,利用深度学习建立跨模态的媒资搜索引擎具有重要意义[1]。
目前文本内容的搜索方案已较为成熟,尽管图像数据相较于文本而言更加难以被组织和管理,但仍有很多以图搜图的成熟案例,如搜索引擎的以图搜图功能,电商网站的相似商品搜索,在档案管理中也存在一定的应用[2]。视频可以看作一组图像的集合,由于视频种类繁多且时间长短不一,传统的视频特征所占空间极大,所以很难高效地检索视频数据。借助深度学习强大的嵌入表示能力,可以将视频中的关键帧表示为特征向量,一方面大大减少了数据量,另一方面也为相似度的计算提供了便利,使视频搜索成为可能[3-4]。
通过深度学习可以提取文本、图像和视频的特征,将其表示为特征向量。而向量数据库就是用来存储、分析和检索向量的数据库[5]。深度学习和向量数据库是完成媒资内容搜索必不可少的组件。
1 向量数据库技术
向量数据库是用来存储、分析和检索向量的数据库。与传统关系数据库截然不同,向量数据库存储的数据量远远高于关系型数据库,并且主要的数据格式是向量,存储标量的情况很少。传统关系型数据库较多情况下是作为数据的归档,查询数据时,通常是精确查找,很少出现模糊匹配的情况。而向量数据库中的查询通常是向量之间距离的计算,查询出与输入条件最相似的数据行,是计算密集型的数据库。同时,向量数据库还有着高并发、低延时的设计要求。向量数据库具有存储量大、高并发与低延迟等特点,因此使用分布式向量数据库是必不可少的,并且分布式向量数据库应具有高扩展性、高可靠性。
目前,向量数据库技术仍处于发展阶段,常见的向量数据库有Milvus、Vearch、Proxima、ScaNN等。Milvus 主要用于存储、检索由神经网络和机器学习模型产出的海量向量数据,并提供多种相似度计算方式,还支持分布式部署、读写分离、横向扩展和动态扩容等功能,具有高可靠性、易于扩展和检索速度快等特点。
在构建媒资搜索平台过程中,使用神经网络模型将文本、图像和视频等非结构化数据表示为向量,存入向量数据库中。用户检索相关内容时,将用户的输入表示为特征向量,从数据库中查询,获取结果。平台架构如图1 所示。

图1 智能媒资搜索平台架构
2 文本搜索
传统的文本搜索分为建立索引和查询两个过程。倒排索引是搜索引擎速度快的一个核心原理,倒排索引[6]是一种键值对的结构,键是词汇,值是包含该词汇的文档集合。有了倒排索引,查询时就无需遍历所有的文档,通过查询索引定位包含该词的文档集合,可以过滤掉大量的文档。目前常见的全文搜索引擎有Solr、Elastic Search 等,通过使用这些全文搜索引擎,可以容易地构建基于词频的文本搜索服务。
BERT 是由Google AI 研究院提出的一种预训练模型[7]。基于BERT 可以获取文本的向量表示,其向量表示包含了深层的语义信息。基于向量表示,可以完成语义相似度计算、语义搜索、聚类、翻译等任务。语义级别的搜索可以通过理解查询内容提高搜索的准确性,同时语义搜索还可以查找同义词等深层信息,这与传统的搜索引擎存在本质的区别。
基于语义的内容搜索引擎与传统的搜索引擎在构建检索库时的基本流程是相同的,其区别重点在于索引库的构建方式。传统搜索引擎根据文本词汇构建倒排索引,而基于语义的内容搜索引擎构建的是整个文本的嵌入表示,与根据词汇构建的索引相比,保留了更多的语义信息。图2 展示了基于语义的搜索引擎构建过程。

图2 基于语义的搜索引擎构建过程
3 图像搜索
随着计算机算力的不断提升,图像等非结构化数据的搜索成为可能。Google、百度等公司已经提供了面向用户的图像搜索服务,许多电商平台也通过使用图像搜索功能,为消费者提供更便捷的购物体验。广播电视行业存在海量的图像媒资数据,构建内部的图像检索服务,可以根据图像快速查找相关内容,从而方便用户管理和查询图像媒资数据。
最早关于图像搜索的研究是通过构建特征工程来实现的。2012 年,Alex 等人提出的AlexNet网络模型[8],以远超第二名的方式刷新了ImageNet大赛的成绩,并且通过使用模型的最后一个隐藏层输出的向量,在测试集中与其他图像的向量计算欧氏距离,发现模型可以很好地表示图像的语义信息。使用机器学习模型将图像嵌入到高维向量中,通过计算向量的距离衡量图像间的相关性,与特征工程相比节省了大量资源,并且取得的效果更好。
为了获取表现较好的图像嵌入表示,需要使用大量的图像数据训练模型。然而,训练的代价是非常昂贵的。为了解决这一问题,有学者提出了迁移学习。迁移学习的思想是,如果模型是基于充足且大量的通用数据集训练的,那么该模型可以作为一个通用的模型,可以使用其直接获取图像的向量表示,而不需要从零开始训练新的模型。
4 视频搜索
视频搜索与图像和文本相比更加复杂。视频可以视作一系列图像的集合,并且增加了声音信息。与图像数据相比,视频一般每秒播放24 帧图像或者更多,其数据的量级远远高于图像。而视频中包含大量的冗余信息,通过提取视频中关键帧的方法可以大量减少冗余数据,但仍会产生大量的数据。
视频不仅仅包含图像数据,声音也是视频的重要组成部分之一。因此在对视频数据建立索引时,要同时考虑图像和声音。视频中的图像数据向量化表示可以采用图像搜索中的技术,声音数据可以使用在音频数据集上的预训练模型,将视频中的关键帧前后的声音信息作为输入,获取声音信息的向量化表示[9]。
进行视频搜索时,首先从待搜索视频中抽取出关键帧与声音信息并表示成向量信息,然后分别从向量数据库中搜索,对搜索结果按命中率排序,将命中次数排序并返回结果。图3 展示了音视频数据索引建立的过程。
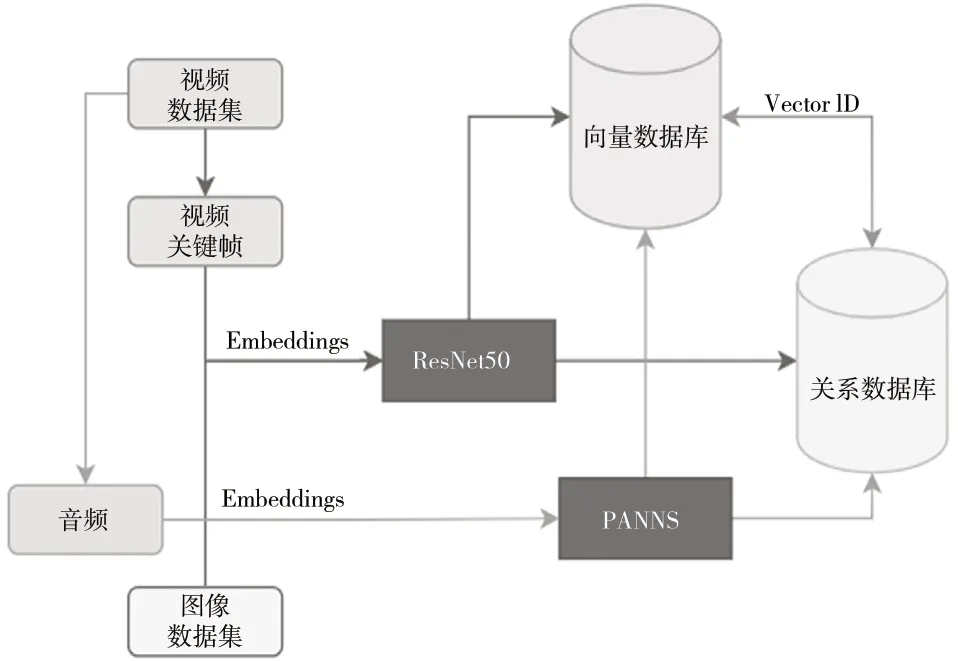
图3 音视频数据索引建立过程
5 单模态与跨模态搜索
每种信息存在的形式都可以称为一种模态,例如本文中的文本、图像和视频信息,都是一种模态。通过文本搜索文本、图像搜索图像和视频搜索视频,都是在单独的模态中的行为。单模态的表示学习存在较多的限制,而跨模态表示学习可以利用各个模态互补,提出模态间冗余的部分,从而学习到更好的特征表示。目前的主要研究方向为协同表示和联合表示,协同表示是将跨模态数据映射到各自的向量空间中,但相互之间存在相关性约束;联合表示是将跨模态信息映射到同一向量空间。
随着跨模态数据不断增多,跨模态的表示学习受到了学者的广泛关注。研究者在机器视觉和自然语言处理等领域取得了一系列的成果,提出了一系列的以深度学习为基础的跨模态表示学习方法,极大地促进了跨模态学习的发展[10]。利用跨模态表示学习的特征可以进行跨模态的搜索,如通过文本搜索图像、通过音频搜索视频等。而跨模态的表示学习需要大量的数据做支撑,例如在构建文本、图像和音频的跨模态表示时,需要大量的<文本、图像、音频>格式的数据集。如何构建有效的数据集是跨模态表示学习的重要挑战之一。
6 结语
随着深度神经网络的发展,单一模态的表示学习已经相对逐渐成熟,跨模态的深度学习逐渐成为研究热点。跨模态学习通过利用不同模态之间信息,弥补了单模态学习的不足之处。跨模态融合学习的用途非常广泛,例如跨模态检索为媒资内容的管理提供了有效的方案,满足了用户普遍的检索需求。多模态学习相比于单模态具有极大优势,在将来多模态学习的应用将会更加广泛。
