基于Kaldi 的智能语音识别在物联网中的应用研究
2022-04-01廖盛澨
廖盛澨,曾 俊,徐 崇
(江西应用技术职业学院,江西 赣州 341000)
0 引言
智能语音识别技术(Automatic Speech Recognition,ASR)是以人类语音为输入的新型交互技术。通过智能语音识别技术,人类可以与机器进行“交流”,机器能够听懂人类的语言,并且能够反馈结果给人类。智能语音识别系统主要由语音的采集与识别、语义的理解以及语音的合成组成。实际上,人们在20 世纪50 年代就开始研究智能语音识别技术,时至今日,语音识别技术已经取得突破性的进展。智能语音识别是实现人机智能交互最好的入口,也是完全机器翻译和自然语言理解的基础。特别是近年来,大数据和云计算时代的到来,加上深度神经网络技术的进步,语音识别系统的性能获得了显著的提升。语音识别技术也逐步走向实用化和产品化,智能语音识别技术在物联网产品中也得到更广泛的应用。从各种离线物联网(Internet of Things,IoT)设备,再到各种公共服务和智慧政务等场合的应用,智能语音识别技术正在逐步影响人们的生活。
目前常用的语音识别工具有CMU Sphinx、HTK、Julius、ISIP 及Kaldi。其中,Kaldi 是由Dan Povey 博士和BUT 大学合作开发的一套完整的语音识别套件[1]。Kaldi 的文档覆盖全面,代码灵活易于扩展。作为一个开源项目,Kaldi 的社区比较活跃,版本稳定。而且,Kaldi 同时包括了语音识别解决方案中的语音和深度学习方法。Kaldi 智能语音识别算法主要由C++编程语言实现,作为一个跨平台的相对轻量级的智能语音识别算法,比较适合移植到嵌入式领域中。
1 智能语音识别技术原理
语音识别原理比较复杂,主要分为前端处理和后端处理两部分,系统结构如图1 所示。其中,前端处理是对麦克风采集的音频数据做处理,主要过程可分为端点检测、降噪及语音特征提取;后端处理主要是对音频数据与声学模型、语言模型进行匹配,以及对音频数据的解码。

图1 语音识别系统结构框图
端点检测也叫语音活动检测(Voice Activity Detection,VAD),它的目的是从带有噪声的语音中准确地定位出语音的开始点和结束点,去掉静音的部分,降低对后续步骤造成的干扰[2]。
降噪又称噪声抑制(Noise Reduction),麦克风采集到的音频通常会有一定的噪音,如果噪声较大,会对语音识别产生较大的影响,比如影响语音识别率,导致端点检测灵敏度下降等。所以,噪声抑制在语音的前端处理中显得尤为重要。
特征提取是将预处理之后的语音的特征值提取出来,由于语音波形在时域上的表述能力很弱,需要将语音做波形转换。常见的一种变换方法为MFCC 特征值提取。
声学模型、语言模型和解码器是语音识别系统最重要也是最复杂的部分。声学模型主要用来构建输入语音和输出声学单元之间的概率映射关系;语言模型用来描述不同字词之间的概率搭配关系;解码器负责结合声学单元概率数值和语言模型在不同搭配上的打分进行筛选,最终得到最可能的识别结果[3]。
2 Kaldi 语音识别套件
Kaldi 是当前最流行的开源语音识别工具(Toolkit),它使用有限加权状态转换机(Weighted Finite State Transducers,WFST)来实现解码算法。Kaldi 的主要代码由C++语言编写,在此基础上使用bash 和python 脚本做了一些工具,比较适合移植到嵌入式设备当中。此外,Kaldi 开源社区相对于其他开源社区更加活跃,可以更高效地得到技术反馈。因此,Kaldi 是物联网应用的较好选择。
Kaldi 的框架如图2 所示,最上面是外部的工具,包括线性代数库BLAS/LAPACK 和OpenFst。中间是Kaldi 的库,包括HMM 和GMM 等代码,接下来是可执行程序,最下面则是一组脚本,用于实现语音识别的不同步骤(比如特征提取、训练单因子模型等)。
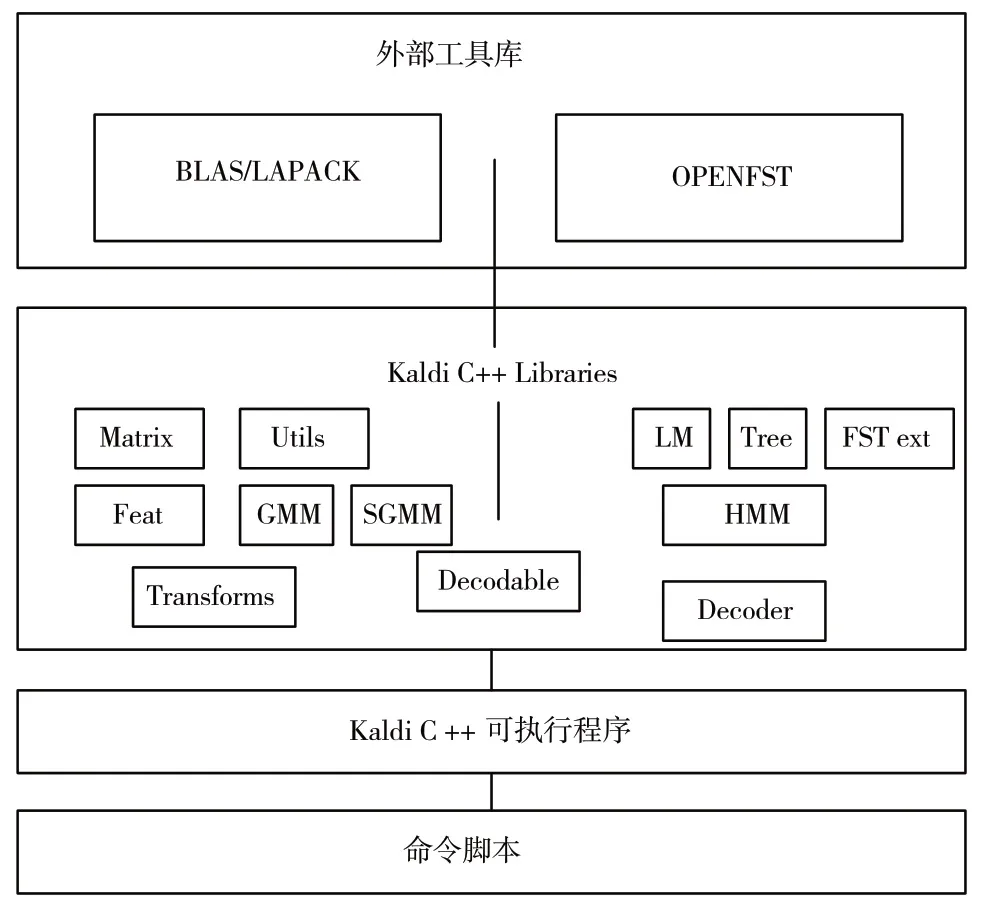
图2 Kaldi 框架图
以前常用的声学模型是GMM-HMM 模型,由于建模能力有限,无法准确地表征语音内部复杂的结构,因此识别率低。Kaldi 支持DNN-HMM 声学模型。相比于GMM-HMM 模型,DNN-HMM 模型加入了深度学习模型,不需要假设声学特征所服从的分布,所使用的特征是FBank,这个特征保持着相关性。为了充分利用上下文的信息,深度神经网络(Deep Neural Networks,DNN)采用连续的拼接帧作为输入[4]。本文采用DNN-HMM 模型,在服务器中训练好之后,将DNN-HMM 模型移植到G1 平台中。
3 基于G1 和Kaldi 的物联网应用
本文采用煊扬G1 的嵌入式处理器作为硬件平台。G1 是轻型AIoT 双核芯片,内置了一颗音频编解码器,是作为离线语音识别平台的较好选择。语音识别模型需要在服务器中训练好之后移植到G1平台中。基于G1 的语音识别框架如图3 所示。

图3 基于G1 芯片的智能语音识别框架图
在实现中,将CPU Core0 主要用做麦克风数据的采集和音频数据的前处理,CPU Core1 运行Kaldi 语音识别套件。CPU Core0 处理完的数据是PMD 数字音频信号。将该信号送给音频Decoder,然后将解码后的音频信号传给CPU Core1。CPU Core1 将运行Kaldi 语音识别算法,得到最终的识别结果。
基于G1 芯片的智能语音识别平台实物如图4 所示。本文将采用风扇作为控制对象,G1 芯片将识别后的结果发送给控制风扇的微控制单元(Micro Control Unit,MCU),从而达到利用语音控制风扇的目的。

图4 基于G1 芯片的智能语音识别平台实物
4 测试结果
在G1 平台上完成Kaldi 整套工具移植后,需要对系统进行测试。本文总共测试8 条命令,第一条命令为唤醒词,如表1 所示。由于唤醒词的识别率最能影响客户体验,因此针对唤醒词在Kaldi 中做了客制化,用来提升唤醒词的识别率。

表1 测试命令表
本文的测试方法是:先用PC 录音工具录取10个人的语料,然后用PC 播放器反复播放语料,来测试继承了Kaldi 套件的G1 平台的语音识别效果。通过抓取G1 平台串口打印的信息,可以计算总共识别成功的次数,从而计算出识别率。由于声音的大小直接影响到识别率,本实验在PC 中设置了三种不同的声音大小,分别为30 dB、50 dB、70 dB。唤醒词每种声音大小测试2 000 次,其他命令各测试1 000 次。
测试结果如表2 所示。可以看出,唤醒词的识别率在92.4%以上,其他7 条命令的识别率大多在85%以上。命令识别率偏低的原因主要是当时风扇正在工作,从麦克风采集的语音数据具有较大噪音。G1 作为轻型的物联网芯片,搭载Kaldi 语音识别框架,选择风扇作为控制对象,识别率能够达到85%以上。

表2 Kaldi 智能识别算法识别率
5 结语
本设计通过对开源智能语音识别套件Kaldi 的研究,将Kaldi 移植到煊扬G1 语音芯片中,将风扇作为语音控制对象,实现了智能语音离线识别。经过系统测试,语音识别率在85%以上,证明可以满足日常物联网产品需求。
随着物联网芯片性能的逐步加强和5G 通信技术的普及,加上大数据技术和云计算技术的逐渐成熟,在线智能语音识别运用在物联网中将会成为主流[5],识别率和识别速度将得到很大提升。如何将智能语音识别技术和云计算、大数据技术融合运用,将会是今后的研究方向。
