基于卷积神经网络的目标检测算法综述
2022-03-31余潇智杨静李兴超马文纹
余潇智 杨静 李兴超 马文纹
(1.西安理工大学 自动化与信息工程学院 陕西省西安市 710048)
(2.国网思极飞天(兰州)云数科技有限公司 甘肃省兰州市 730000)
(3.国网甘肃省电力公司超高压公司 甘肃省兰州市 730070)
(4.国网甘肃省电力公司酒泉供电公司 甘肃省酒泉市 735000)
目标检测是计算机视觉领域的一个重要分支,其任务是找出图像中若干特定的目标,并给出它们的类别和位置。近年来,目标检测算法一直是计算机视觉和图像处理领域的研究热门,一方面在于它是图像语义分割[1]、实例分割[2]等更复杂视觉任务处理的基础,另一方面是因为它在机器人导航、智能监控以及工业检测等诸多领域的巨大应用前景。
目标检测的发展可分为两个阶段,分别是基于人工提取特征的传统阶段和基于深度学习方法的新阶段。传统目标检测多采用滑动窗口结合手工提取特征的方法,最后结合专门的分类器进行分类。典型的算法有ViolaJones[3]、HOG[4]、DPM[5]等。其中,DPM 达到了传统检测算法的巅峰,连续获得Pascal VOC(The Pascal Visual Object Classes Challenge)挑战赛2007~2009年三年的检测冠军。它采用了将整体拆分检测的思想,并用到了包围框回归和上下文信息集成等方法,对目标检测领域的后续发展产生了深远的影响。但是,人工设计特征不仅工作量大、算法鲁棒性差,而且性能提升也遇到了瓶颈,在DPM 之后一直没有大的突破。直到2014年,R.Girshick 等人将CNN(Convolutional Neural Networks)[6]应用到目标检测当中,尝试使用卷积神经网络来提取特征,较传统方法一下将检测的平均精度提升了约30%,给检测效果带来了质的飞跃。这就是在目标检测领域有着里程碑意义的R-CNN[7],自此,目标检测与深度学习结合了起来,进入了新的发展阶段。自R-CNN 之后,又相继出现了SPP-Net[8]、Fast R-CNN[9]、Faster R-CNN[10]、R-FCN[11]以及YOLO[12]、SSD[13]等速度更快、效果更好的检测算法。本文将重点介绍基于卷积神经网络的目标检测算法。
1 CNN简述
卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络[14]。因卷积操作对特征提取的独特优势,使得它比传统的神经网络具有更好的学习能力。目前,卷积神经网络已成为深度学习的主流框架,并已被广泛应用于图像处理、自然语言处理和医疗诊断等多个领域。
1.1 CNN结构与特点
卷积神经网络其整体架构分为输入层、卷积层、池化层和全连接层。网络通过这些单元完成特征提取、非线性映射、下采样、转化输出以及最终构造目标函数并优化的基本过程。
卷积神经网络采用了三个基本概念:局部链接,共享权值和池化。局部连接和共享权值大大减少了参与卷积网络的参数,同时,它们能够有针对性的提取图像的空间特征,适应图像的平移不变性。而池化操作,一般跟在卷积层之后,用来简化从卷积层输出的信息,它也减少了神经元的个数。因此,相比于传统神经网络,卷积神经网络能够更好的提取图像的空间视觉特征,并且使用更少的连接和参数。这将使得模型得到更快的训练并有助于建立更深度的网络。
1.2 发展历史
1998年,Yann LeCun 提出LeNet[15]网络,用于解决手写数字识别的视觉任务,为卷积神经网络的发展奠定了基础。LeNet 在虽然在Mnist 数据集上表现的很好,但是在更大的真实场景的数据集上就力不从心了。直到2012年,Hinton和他的学生Alex Krizhevsky 提出了AlexNet[16],它比LeNet具有更深层的网络结
构并且有效的抑制了过拟合问题,此算法在当年ImageNet 大赛中以压倒性的优势战胜其它传统机器学习方法,拿到冠军,为卷积神经网络的发展确立了新的里程碑。2014年,VGGNet[17]网络在ILSVRC 比赛中获得定位项目冠军和分类项目亚军。VGGNet 是由牛津大学计算机视觉组合和Google DeepMind 公司研究员一起研发的深度卷积神经网络,它的最大特点在于使用多个小卷积核串联,增加了网络深度。同样在2014年的ILSVRC 比赛中,获得分类项目冠军的网络是GoogLeNet[18],它通过引入Inception 模块来增加网络宽度,同时通过引入1*1 的卷积层来压缩通道数量,降低计算量,从而进一步增加网络深度。2015年,微软研究院的Kaiming He 等人提出残差网络ResNet[19],并获得当年ILSVRC 比赛的冠军。ResNet 使用短路连接的方式缓解了深层网络梯度消失的困扰,并阻止了网络的失真与退化,因此将网络深度大幅的提高到152 层,这对于神经网络的发展可以说是革命性的。在这之后,人们又提出了残差网络的改进版本ResNetXt[20]、DenseNet[21]以及SENet[22]等更多的算法模型。
2 目标检测算法
传统的目标检测方法主要包括区域搜索、提取特征和目标分类三个部分。其中,区域搜索主要有滑动窗口和区域聚合两种方式,特征提取基于人工完成,目标分类则多用传统机器学习的方法完成。后来,随着深度学习逐渐崭露头角,卷积神经网络被引入到目标检测领域。与传统方法相比,它具有自动学习特征的能力,并且具有更强的特征表达能力和泛化性,因此逐步代替了基于人工的特征提取方式。
目前,基于卷积神经网络的目标检测分为两种方式,即两段检测方法和一段检测方法。两段检测是先给出预选区域,然后再针对区域进行分类与回归。而一段检测是在特征提取后直接进行分类与回归。下面分别介绍目标检测中的常用概念和两种检测方法中的若干经典算法。
2.1 基本概念
2.1.1 IOU 交并比
IOU(Intersection over Union)即交并比,就是两个框相交的面积除以两框相并的面积,计算方法如图1所示。在物体检测中,通过比较真实框和预测框的重叠面积可以判断检测精度。因此,IOU 作为在目标检测中对目标物体定位精度的标准。
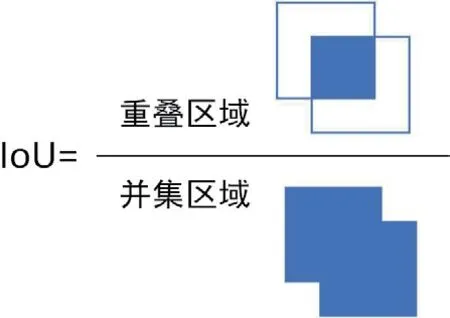
图1:交并比
2.1.2 精确率与召回率
其中,TP(True Positive)为正样本被预测正确的数量,FP(False Positive)为负样本被预测为正样本的数量。
其中,FN(False Negative)为正样本被错误预测为负样本的数量。
2.1.3 AP 与mAP 值
AP 与mAP(mean Average Precision)是目标检测算法中常用的评价指标,AP 是单个类别的平均精度,而mAP 是AP 值在所有类别下的均值。
AP 即为PR 曲线与坐标轴形成的面积,其中,r 代表着不同IoU 阈值下的召回率。
平均精确率均值(Mean Average Precision,mAP):
其中,N 为物体类别的数量,APn为第n 个类别的平均精确率。
2.2 两段检测方法
2.2.1 R-CNN 算法
R-CNN[7]是目标检测领域的里程碑,它的最大突破在于引入CNN 提取图像特征,将CNN 在分类任务上的优异表现迁移到检测任务上来,而在此之前,特征提取主要依赖人们的手工设计来完成。R-CNN 在VOC2012 上的mAP 值达到了53.3%,较传统模型提升了30%以上。算法首先使用Selective Search[23]对输入图像提取约2000 个候选框,再将候选框中的图像缩放至标准尺寸后送入CNN 进行特征提取,并得到特征向量,然后送入SVM[24]进行分类,最后线性回归得到目标位置并用非极大值抑制算法去掉多余检测框,流程如图2。R-CNN 的不足之处首先在于图像在进入卷积之前进行了截取或拉伸,破坏了图像的原本形态,影响识别效果,其次是对每个候选框的特征提取进行了大量重复的卷积运算,最后它的分类器训练和位置回归是独立进行的,从而导致它资源开销大且训练时间很长。
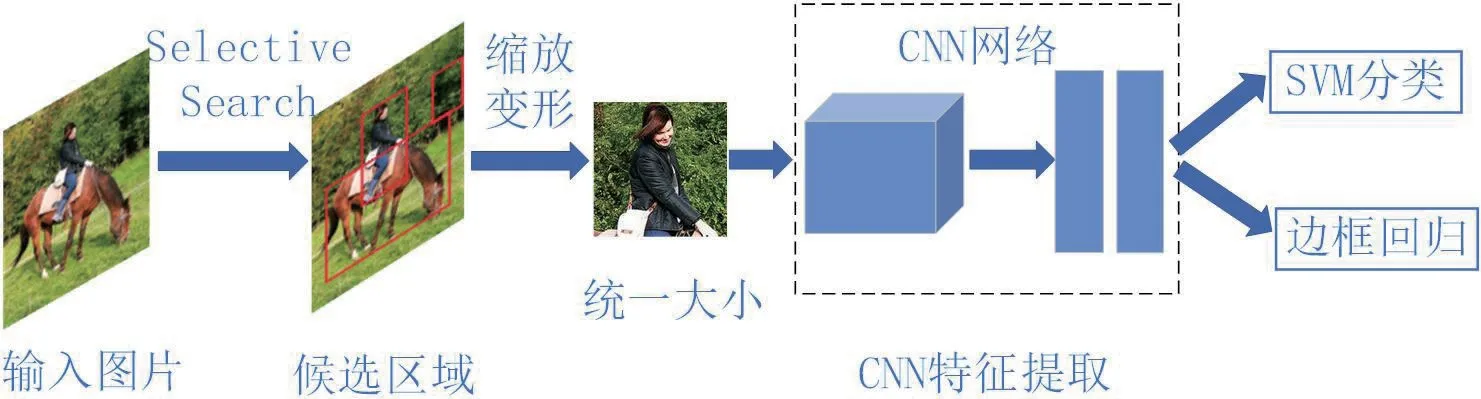
图2:R-CNN 流程
2.2.2 SPP-Net 算法
SPP-Net[8]解决了输入全连接层图像必须固定尺寸的问题。它引入了空间金字塔池化层 (Spatial pyramid pooling layer,SPP layer)[8]对特征图进行采样,SPP 层是对不同大小的区域划分成固定个数的单元格进行池化,这样无论输入图像的尺寸如何,经过SPP 层后,都能生成固定维度的特征向量,如图3所示。
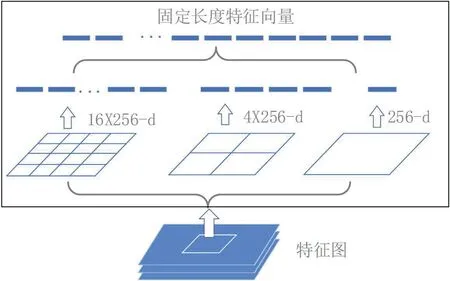
图3:空间金字塔池化
算法首先通过Selective Search 方法生成约2000 个候选框,并对整张图片送入CNN 卷积,提取出特征图。然后在特征图上对应找到每个候选框区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量,最后进行分类和回归,流程如图4。SPP 池化有效增强了尺寸鲁棒性,另一方面,算法只用CNN 处理一次,速度提升很大。在Pascal VOC 2007 数据集上,在准确度相当或更好的情况下,其处理测试图像的速度比R-CNN 快24 至102 倍。但是,它的分类和回归训练仍是独立的,并且也没有解决R-CNN 需要存储大量特征的问题。
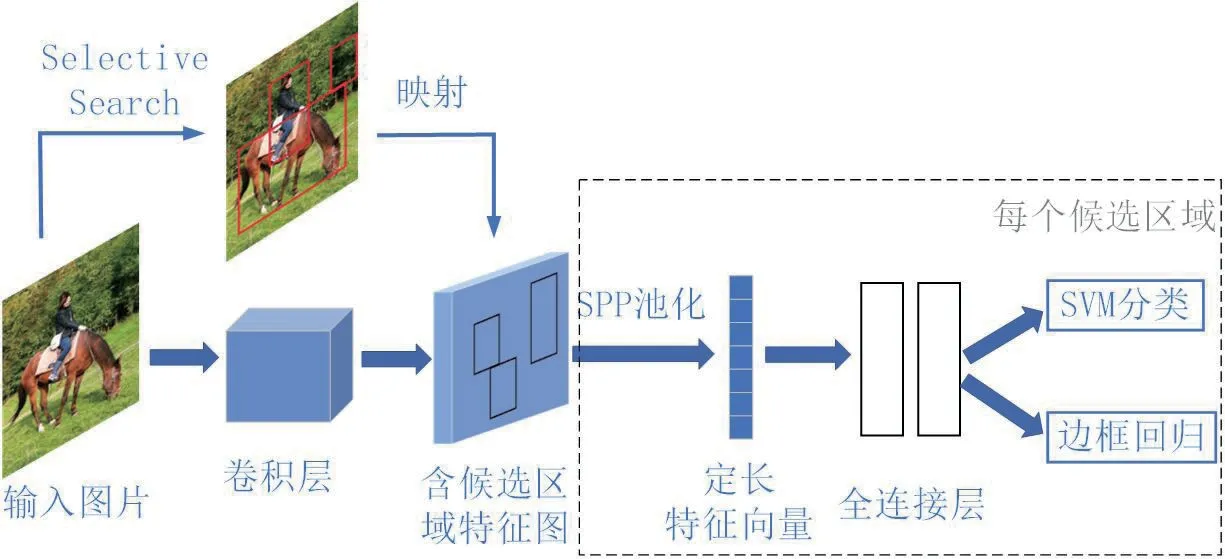
图4:SPP-Net 流程
2.2.3 Fast R-CNN 算法
Fast R-CNN[9]借鉴SPP-Net 模型,引入了ROI 池化层[9],将图像划分为均匀的网格,从而保证处理后的特征图具有相同的尺寸。它首先对图像进行卷积运算,然后将Selective Search 生成的候选框映射到卷积后的特征图上,基于此特征图的候选区域进行ROI 池化,生成固定尺寸的新特征图和特征向量,最后送入全连接层进行并行的分类与位置回归,流程如图5所示。Fast R-CNN 较前述网络最大的改变就是引入多任务损失函数(Multi-task loss),将分类与位置回归合并在一个阶段进行训练。另一方面,在网络训练时ROI 操作同样是共享了同一张图片的卷积特征。这使得网络训练和测试的速度都得到了显著的提高。用深度网络VGG-16[17]时,它比R-CNN 训练阶段快9 倍,测试阶段快213 倍,比于SPP-Net 训练阶段快3 倍,测试阶段快10 倍。但是,Selective Search 候选框的生成还是独立计算的,还不是完整的端到端系统。

图5:Fast R-CNN 流程
2.2.4 Faster R-CNN 算法
Faster R-CNN[10]引入了RPN(Region Proposal Network)[10]网络来取代之前独立的候选框生成算法,形成了真正意义上的端到端的神经网络模型。RPN 是区域推荐网络,它通过对特征图上生成的锚框进行预测,判断锚框是前景还是背景,同时,根据锚框和真实框的位置回归给出锚框的预测位置。Faster R-CNN 首先对输入图像进行卷积操作生成特征图,然后通过RPN 网络给出一系列候选区域,接着进入ROI 池化,最后进入全连接层进行物体分类和精确的位置回归,流程如图6所示。但是,Faster R-CNN 对于每个Rol 区域的分类和回归是单独计算的,并且子网络中的全连接层含有大量的参数,计算量也是很大的。另一方面,ROI 池化没有位置信息,也影响了定位精度。

图6:Faster R-CNN 流程
2.2.5 R-FCN 算法
R-FCN(Region-based Fully Convolutional Networks)[11]是基于区域的全卷积网络。它通过引入位置敏感得分图(position-sensitive score maps),向RoI 池化中加入了位置信息,较好的平衡了分类网络“平移不变性(translation invariance)” 和检测网络的“ 平移可变性(translation variance)”[25]之间的矛盾。同时,它去掉了全连接层,使用全卷积的网络结构,实现网络层的计算共享,从而大大减少了网络参数,提升了检测速度。简单来说,算法是在RPN 网络给出Rol 区域后,将每一个Rol 划分为K*K 的网格,然后分别对应到位置敏感得分图上进行池化,最终得到K*K*(C+1)维度(C+1 指C 个类别+1 个背景)的特征图用于分类。类似的,设计与分类并行的位置回归子网络,同样采用位置敏感得分池化的操作,得到K*K*4 维度(4 指4个位置值)的特征图,进行位置回归,流程如图7。R-FCN处理每张图的耗时为170ms,比Faster R-CNN 快2.5 ~20 倍。
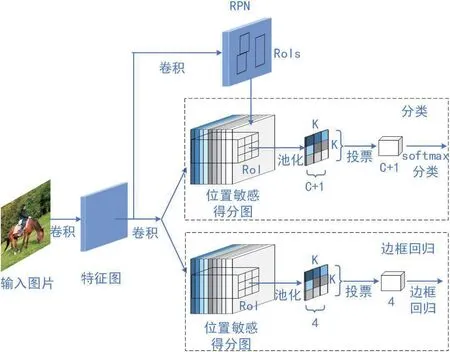
图7:R-FCN 流程
2.3 一段检测方法
2.3.1 YOLO v1
YOLO(You Only Look Once) v1[12]是重要的单阶段检测算法,它将整张图片作为输入,用卷积神经网络提取特征后直接进行分类与回归。算法首先通过卷积神经网络提取图像特征,再经过两个全连接层,然后输出7*7*30 尺度的特征图。在特征图中,7*7 是因为YOLO v1 将输入图像划分为7*7 个网格,每个网格对应特征图中的一个点。其中,每个网格对应的特征向量包括20 个对象的概率 + 2 个边框 * 4 个坐标 + 2 个边框的置信度。最终,算法根据这些参数分类与位置回归,其流程如图8。与两段算法相比,YOLO v1 的显著特点就是速度快。其次,由于YOLO 直接处理整张图像,因此,与提出候选区域算法相比,它的背景误检率更低。但是,由于YOLO v1 的一个子图像块中只能包含一个目标,因此,不适合小目标检测。而且,它的精度也比R-CNN系列算法低。
2.3.2 YOLO v2~v3
YOLO v2[26]针对v1 做了若干改进。首先就是使用了锚,YOLO v2 通过k-means 算法,在训练集中对锚的位置和形状进行聚类,以便更加符合对象中的样本尺寸。在YOLO v2中,预测框增加了,因此召回率也提高了。同时,由于每个锚都分别回归各自框的坐标和分类概率,它对密集小目标的检测能力也提升了。此外,YOLO v2 还增加了批次归一化、引入Darknet-19 的特征提取网络等做法。YOLO v3[27]主要加入了多尺度特征图的融合和残差网络结构,从而进一步提升了检测精度。
2.3.3 SSD 算法
SSD(Single Shot Multibox Detector)[13]是另一种重要的一段检测算法,它在VGGNet 的基础上增加了4 个小尺寸的卷积层,然后在6 个不同的特征图的每个位置上预设默认框(default box),类似于Faster R-CNN 的锚。算法利用小尺寸的卷积网络在特征图上滑窗,对于每个位置的每个锚,分别进行分类和边框回归,流程如图9。SSD 的优势在于采用多尺度特征图进行检测,不但提高了分类正确率,而且有效提升了对不同尺度目标的检测能力,尤其是对小目标检测的能力比YOLO 有了一定的提升。

图9:SSD 流程
2.3.4 RetinaNet
YOLO,SSD 等一段检测算法虽然明显提高了检测速度,但由于没有第一步预选框的初筛,导致真正的样本框占比极小,正负样本类别很不均衡。这也是一段检测算法精度普遍低于两段检测算法的一个重要原因。对此,Lin 等人提出了RetinaNet[28],算法的重点在于Focal Loss 函数,即在类别不平衡较大时,通过增加调节因子让损失函数更加关注难分样本,从而给予难分样本更多的优化。基于此,RetinaNet 框架被提出,用来验证Focal Loss 的效果。经验证,RetinaNet在COCO 数据集上的AP 值达到40.8%,其精度可以与两段检测方法媲美。但速度较YOLO 和SSD 有明显下降。
3 性能评价
评判算法优劣的一个重要方法就是在公开的数据集上进行评测,下面介绍目标检测领域比较有影响力的几个数据集以及各算法在部分数据集上的性能表现。
3.1 数据集
3.1.1 PASCAL VOC
PASCAL VOC(Visual Object Classes)挑战赛是计算机视觉领域早期的重要比赛之一,包括图像分类、目标检测、场景分割、事件检测等任务。目标检测常用的是VOC2007和VOC2012 数据集。其中,VOC2007 包括5000 张训练图像和1.2万个标注目标,VOC2012包括1.1万张训练图像和2.7万个标注目标。
3.1.2 ImageNet Imagenet 是一个大规模的带标签图像数据集。数据集有超过1400 万张图片和约2.2 万个类别。其中有超过百万张的图片有明确的类别标注和图像中物体位置的标注,也是适合的目标检测数据集。
3.1.3 MS-COCO
MS-COCO 数据集是微软团队发布的一个可以用来进行图像识别、分割和注释的数据集,其包括91 类目标和328,000 个图像。它的特点是图片大多数来源于生活中,背景更复杂,且含有的小目标更多,另一方面,它除了标注每个目标边框外,还标注了每个实例的分割信息。因此,COCO 逐渐成为目标检测的一个主流测评集。
3.1.4 Open Images
Open Images 来自于Google 团队,它包括900 万张图像和6000 多个分类。数据集的对象更加多样化,通常包含多个对象的复杂场景。同时,还提供了可视化的关系注释。较之前的数据集有更加丰富的信息。
3.2 性能对比
本文介绍的主要目标检测算法的性能对比如表1所示,表中的前5 行为两段检测算法,后6 行为一段检测算法。首先,这些算法推出的时间跨度较大,用于检测的数据集和测试环境不完全相同,文中所列文献数据尽量保证数据集和测试环境的统一,以减小硬件和外部环境带来的差异。通过表格可以看出,一是两段检测算法的检测速度明显慢于一段检测算法。二是就两类方法本身而言,随着算法的逐步改进和结构的不断优化,检测的效率和精准度总体趋势都在上升。第三,可以看到数据集对检测结果的巨大影响,例如YOLO v2 到v3,其mAP 值下降明显,正是因为COCO 数据集较PASCAL VOC 更加复杂,小目标更多。也可以看出复杂背景及小目标检测仍是目标检测所面临的挑战。
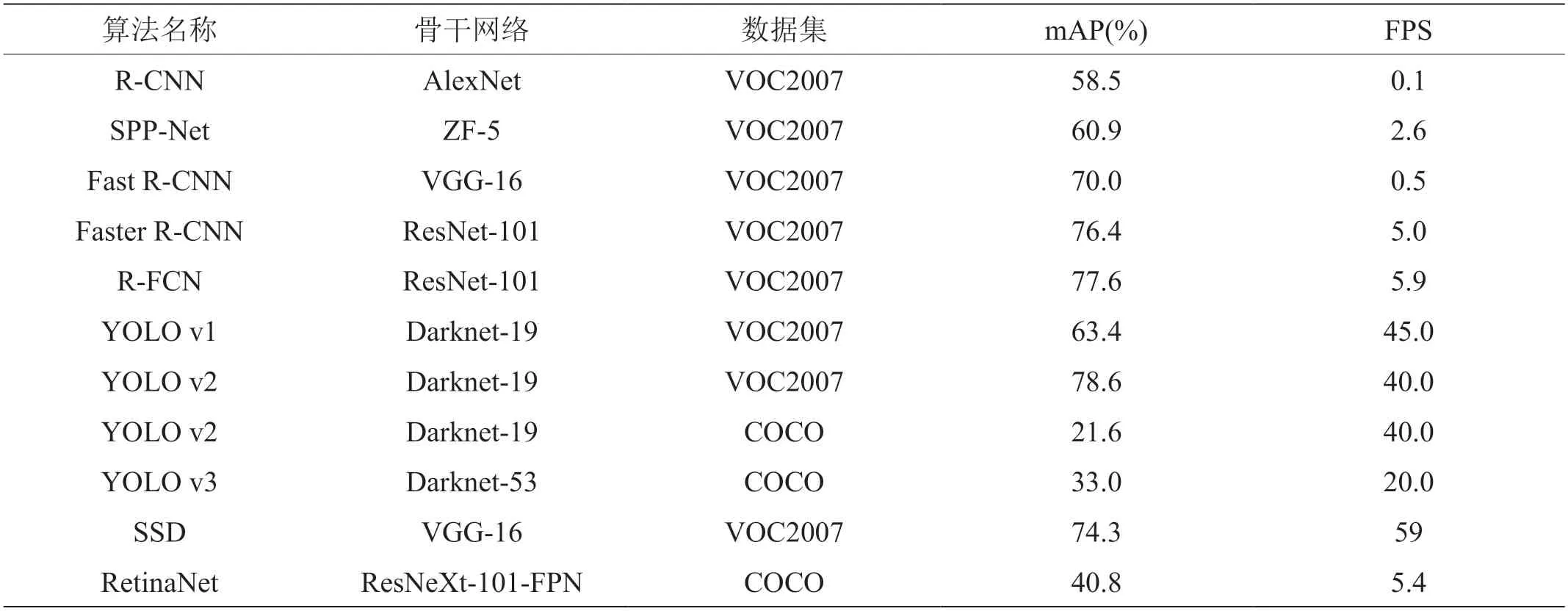
表1:主要目标检测算法性能对比
4 结论与展望
基于卷积神经网络的目标检测方法分为一段检测和两段检测。两段检测方法有预筛选的过程,精确度普遍较高,但检测速度较慢。一段检测将图像检测直接转化为回归问题,检测速度大大提升,但存在正负样本分布不均衡的问题,检测精度受到影响。不过,随着框架的演进,其精度也在不断提高。并且相较于两段检测应用范围更广,尤其是对于实时检测任务。
目前,基于深度学习的目标检测方法已是当前主流,各类算法层出不穷。一方面,用于特征提取的CNN 迅速发展,网络深度更深、准确度更高;另一方面,支撑模型训练的硬件设备性能更加强悍,这些都为目标检测的发展带来了很大的支撑。就目标检测本身而言,从一开始的多阶段训练,到最后融合为整个端到端的网络,从单一的特征提取到加入多特征融合,再到对图像全局和局部特征更好的融合处理,以及训练方式的不断优化等等,在多方面均取得了很大的进步,总体朝着检测速度更快,同时精度更高的方向不断演进。但是,目前对于复杂背景下的多尺度目标检测,密集小目标检测等仍有不足。同时,随着应用场景越来越复杂,如何在复杂环境下快速准确的判别目标,以及如何利用场景的语境信息和物体相互关系等,均是目标检测领域未来的研究方向。
