数据匮乏场景下的商业建筑能耗预测方法
2022-03-31章挺飞
刘 杭,罗 恒,章挺飞
(苏州科技大学 电子与信息工程学院,江苏 苏州 215009;江苏省建筑智慧节能重点实验室,江苏 苏州 215009)
在商业建筑节能工作中,普遍会遇到数据匮乏的场景,它会直接影响能耗预测准确度,进而影响能源使用效率,增加商业能源使用成本[1-3]。如新兴产业中,新建或改建扩建的商业建筑项目,会出现短期能耗数据匮乏的情形[4]。同时,部分能源管理系统的不完善,也会导致能耗数据采集的大量缺失,以至于无法实施可靠性预测[5-6]。
近年来,国内外专业学者在商业建筑能耗预测的数据匮乏场景的探索上涉及很少,大多研究集中在传统场景下的传统机器学习和深度学习方法[7-8]。前者适应力强,能够快速开发,主要有支持向量机(Support Vector Machines,SVM)[9-12]、BP(Back Propagation)神经网络[13-15]、K近邻(K-Nearest Neighbor,KNN)[16]和极端梯度提升(Extreme Gradient Boosting,XGBoost)[17]等,但同时存在模型过分依赖特征、容错率小等弊端。后者学习能力强,如长短期记忆网络(Long Short-Term Memory,LSTM)对能耗序列预测呈现一定的优势[18],其特有的门控单元的记忆功能,能够捕捉时间序列项之间的依赖关系,具有优秀的预测能力,门控循环单元(Gated Recurrent Unit,GRU)则优化了LSTM结构,收敛较快,能够有效处理复杂的能耗数据[19],但计算量很大,在数据匮乏时会影响预测结果。因此在这一场景下,可以使用数据增强方法扩充数据,其中生成对抗网络(Generative Adversarial Networks,GAN)是近年来深度学习领域数据增强的重要方法,它通过生成高质量的训练样本补充并扩展真实数据[20],如文献[21-23]分别应用GAN实现不平衡数据、图像和序列数据的数据增强用以提升准确度预测。
针对数据匮乏场景下的商业建筑能耗预测,提出了一种基于GAN-GRU组合模型的预测方法。文中针对GRU特有的时间序列记忆敏感性,设计生成对抗网络框架结构,生成具有时间关键点的平行信息数据并进行扩充,并利用GRU实现复合数据的预测分析,同时与K近邻(K-Nearest Neighbor,KNN)、梯度提升树(Gradient Boosting Decision Tree,GBDT)和岭回归(Ridge)等传统算法对比,最终结合方差-协方差预测结果的权重复合思想,提升预测结果的准确性、鲁棒性和泛化能力。该研究对于新兴产业数据匮乏场景下的商业建筑节能具有重大意义。
1 理论与模型构建
1.1 生成对抗网络
GAN是2014年提出的一种生成模型方法,它吸收了对抗博弈的思想,其通过内部的两种模型结构引导生成数据。网络模型主要有两部分构成:判别模型D和生成模型G。生成模型主要目的是尽可能生成接近真实数据的假数据,判别模型则捕获生成数据来自真实训练数据的概率,这种生成对抗的原理使得生成的数据更加准确[20]。生成对抗网络的主要网络结构如图1所示。
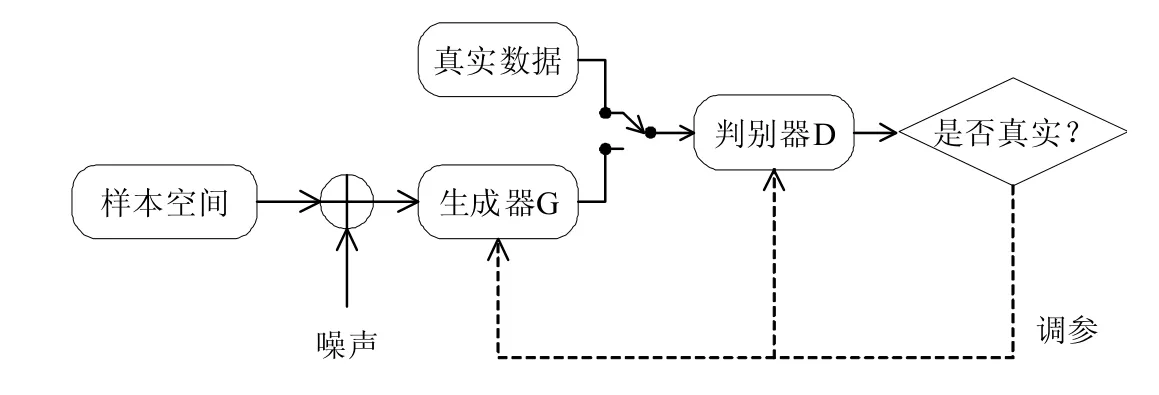
图1 生成对抗网络模型
为了尽可能寻求两种内部结构的平衡,需要在生成数据过程中不断迭代优化,生成器被训练用于最小化值函数,而判别器则希望最大化这一目标,两者采用二人零和博弈策略。在上述最大最小优化过程中,主要的优化目标函数为
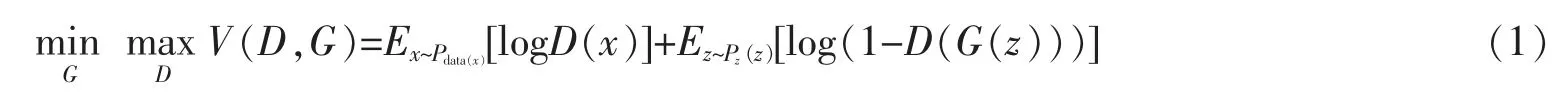
其中,x表示真实能耗序列数据,z代表输入G网络的噪声,G(z)代表G网络的生成数据,D(x)代表输入数据属于真实序列数据概率的判断估计,Pdata(x)代表原始序列数x的分布,P(z)代表输入噪声变量的先验值,E代表求解期望值。
1.2 生成对抗网络设计
GAN的网格模型不需要庞大的计算方法,通过两种逼近函数的网络,使生成模型和判别模型不断逼近真实状态以获取最优的网络参数,当判别模型D趋于稳定,生成器G可获取最终稳定模式下不同网络状态为
1.2.1 生成器
生成器由编码器和解码器组成,针对时间序列信息,GRU用来捕获时间步信息,获取前一时刻数据特征记忆并传递给下一单元信息。

其中,FCR表示全连接层,使用ReLu激活函数,Wen与Wencoder表示网络迭代过程中参数矩阵表示为t时刻的数据输入。则分别表示中间状态,使用门控循环单元(GRU)捕获时间记忆信息,实现网络参数快速收敛。设置随机噪声为高斯噪声的方式,并将其送到解码器中,再使用多层感知器(MLP)生成平行数据。

1.2.2 判别器
设计判别模型为

其中,Cit表示来自t时刻原始数据和生成平行数据输入,Y^表示生成器分类结果,Wgru与Wmlp表示偏差矩阵。
1.2.3 损失函数
对于序列生成数据,选择常用的均方误差(MSE)作为网络回归迭代过程中的损失函数

1.3 对比结构及组合设计
为了体现上述GAN结构设计的优势,设计了实验的四个流程,如图2所示。
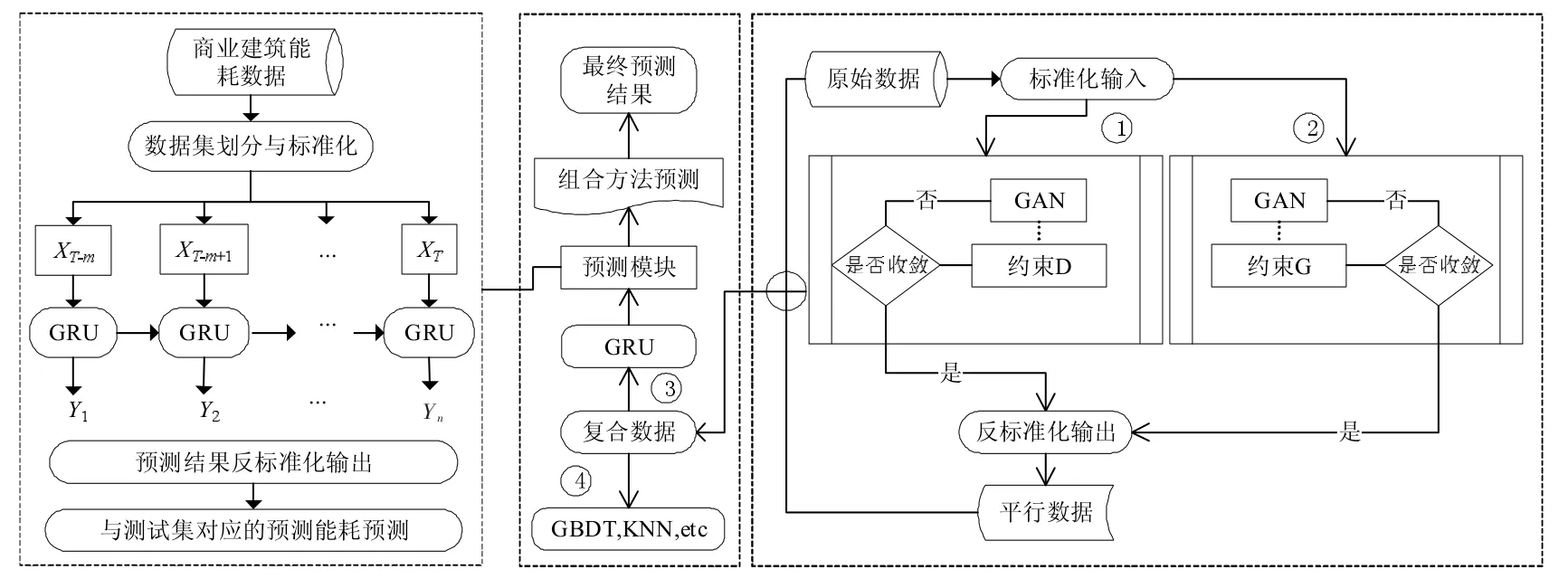
图2 实验设计流程
在流程1中,约束判别模型D不变

其中,生成结构保持不变,记为G-GRU,或将第1.2.1节中公式更换为以下三个公式,分别记为G-LSTM、G-RNN和G-Bi-LSTM。

其中,RNN为循环神经网络单元,Bi-LSTM为双向长短期记忆网络。流程2则在流程1的基础上,约束G,即保持第1.2.1节生成器结构不变。其中,判别模型保持不变,记为D-GRU,或将公式更改为以下三个公式,分别记为D-LSTM、D-RNN与D-Bi-LSTM。在流程3中,使用GRU为主预测算法。在流程4中,使用对比的复合数据预测方法为:GBDT(梯度提升树)、KNN(K-近邻算法)、Ridge(岭回归)和RF(随机森林)。

虽然GAN能稳定生成平行数据信息,但无法保证不同平行数据的关联性,因此不具备预测鲁棒性,文中使用组合预测的方式,利用多次GAN-GRU的预测结果,计算每种结果的权重。方差-协方差法能找到最优的权重组合,提高短期能耗预测的鲁棒性和准确度。每种预测结果的方差计算为

其中,n为训练集数目,e1,e2,…,en分别表示n条数据的绝对百分比误差,e¯为e1,e2,…,en的均值。文中以日能耗预测组合为例,定义第m天日能耗序列预测值ym={ym1,ym2,…,ymn},ymn表示第n种的训练。第m+1天的第n种的预测结果权重为wmn=1/[vmn(1/vm1+1/vm2+…+1/vmn)],最终的第m+1天预测结果组合为
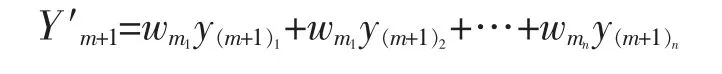
2 实验与结果分析
2.1 数据说明
文中选取了上海正大广场大型商业建筑2018年度的能耗序列数据。经过预处理,使时间间隔标准化为1 h,其日期准确范围为2018年1月1日—2018年12月31日,共有8 760条数据。定义三种数据集结构分别为:原始序列数据集、平行序列数据集和复合序列数据集。将原始序列中第1-L1天序列段定义为

其中,t表示天数,n表示一天样本数,L1表示原始序列的样本天数。
定义GAN生成的平行数据结构为

其中,t表示天数,n表示一天样本数,L2表示生成的样本天数。
定义复合后的数据结构为

其中,L=L1+L2。
模拟数据匮乏场景:该商业建筑仅有一个月的历史能耗数据,需要预测下个月能耗数据。为了方便训练,统一每个月数据量为672条,即每月取前28 d的数据量。使用上海正大广场2018年度数据为训练和预测数据,总数据集定义为{seq1,seq2,…,seq11,seq12},表示第1-12月份的每月数据集序列。根据模拟数据匮乏场景,设计11组数据匮乏场景下的数据集的结构为{{seq1,seq2},{seq2,seq3},…,{seq11,seq12}}。
2.2 预测指标
选取指标函数平均绝对误差(MAE)、均方根误差(RMSE)和相对误差(CV-RMSE)作为评估指标,三种指标的表达式分别为
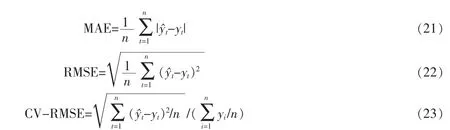
其中,y^t表示预测数据,yt表示原始数据。
2.3 平行数据实验结果与分析
为了比较第1.2节中设计的生成对抗网络结构性能,使用10组数据匮乏场景能耗数据集为{{seq1,seq2},{seq2,seq3},…,{seq10,seq11}}。其中,每组的前一个月数据用于训练并拆分训练集和验证集的比例为6:1,每组的后一个月数据用于预测。每次实验迭代次数设置为4 000次,需保证生成模型和判别模型的loss趋于稳定且收敛,在实验过程中偶尔出现loss波动明显,即需要重新迭代。每组生成的平行数据则设置为GRU预测的训练集,并拆分训练集和验证集的比例为6∶1,使用GRU算法在预测集上测试。图3为10组数据集的生成平行数据使用GRU训练并预测后的指标误差。其中,D-GRU模式在10组数据集上MAE、RMSE和CV-RMSE上的指标都相对较小,且最终的误差均值最低,说明GRU更易收敛,所提模型生成数据性能更接近真实数据,且符合预测需求。
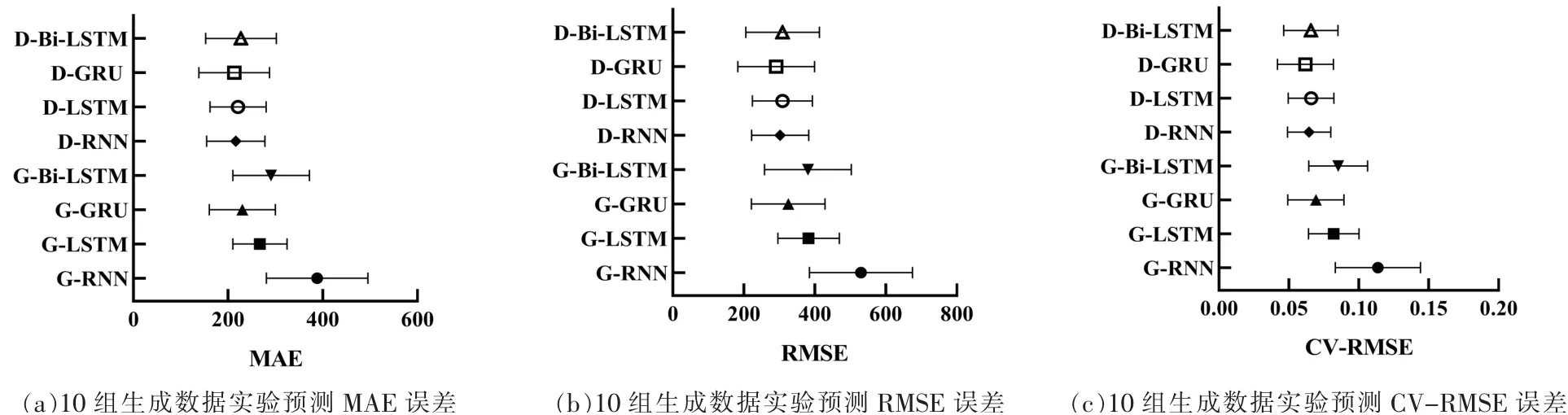
图3 10次生成数据实验的预测指标对比
2.4 复合数据实验结果与分析
在生成平行数据后,将每月原始数据与平行数据按照公式进行数据复合,由此分类成三种数据集:平行数据、原始数据、复合数据。在第2.3节的基础上,继续使用GRU作原始数据与复合数据的预测性能分析。在同样的10类数据集下,复合数据集的总体指标均值较低,与原始数据集三类指标相比,分别提升了13.6%,15.5%和12.01%,见表1。这表明数据复合后,能提高短期能耗的预测性能。

表1 两类数据集预测性能对比
2.5 组合预测实验结果与分析
将2.4节的复合数据同时使用GRU与KNN、GBDT、Ridge、RF四类传统机器学习方法预测对比。10类数据集的预测误差箱型图,如图4所示。

图4 10组预测方法的预测指标对比
由图4可以观察到传统的机器学习方法存在误差较大的情况,这是由于传统模型简单并且只适用于快速开发的情况。总体性能而言,文中所提GAN-GRU模型方法,误差收敛快,准确度高,能适应大部分小数据下商业建筑数据序列预测。值得注意的是,对于特征复杂和无规律的数据集,则不适用文中模型结构,因为复杂特征会直接影响模型准确度,且不规律数据集不具备代表性,无法生成适当的平行数据。
由于生成对抗网络每次生成数据不同,且存在部分偏差,为了提高预测的鲁棒性,使用第1.3节所述每日预测组合预测模式,采用{seq11,seq12}数据集,开展10次平行数据实验,生成10次商业建筑2018年第11月份不同的数据结构,并使用GAN-GRU组合模型预测商业广场2018年度第12月份数据。
图5为原始数据、平行数据和复合数据的组合模式针对上海正大广场第12月份预测结果的24 h窗口均值的拟合曲线。可以看出最终融入方差-协方差思想的组合预测实验结果最贴近真实数据,相比原始数据预测的MAE、RMSE和CV-RMSE指标分别提升了16.9%、16.7%和18.6%。
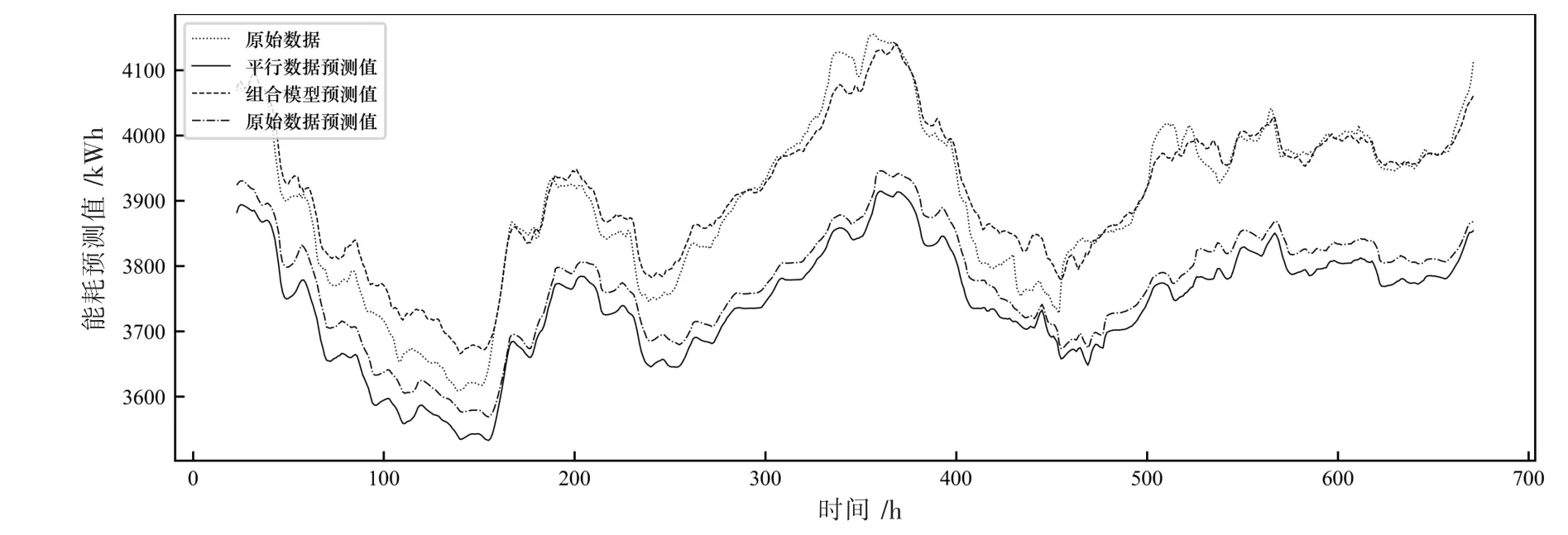
图5 正大广场12月份24 h窗口能耗预测结果
图6为组合实验的预测指标分布图,hybrid表示融入方差-协方差思想的组合模型的实验结果,其10次实验中的误差指标上下波动,且存在误差较大的情况,证明前面所述的生成数据预测的不稳定性,最终的复合模式则使其保持在一种相对稳定且较优的预测状态,验证了理论的实用性并具备一定的推广性。
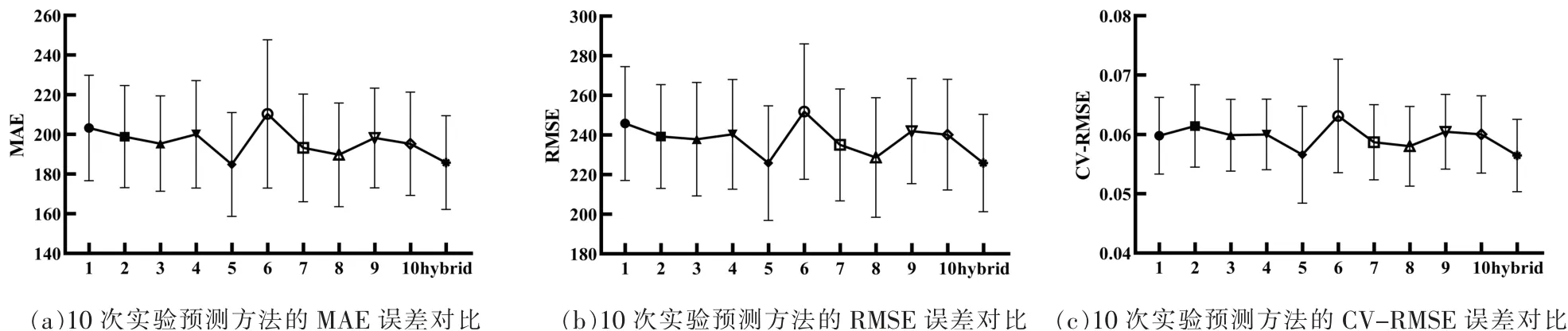
图6 复合模型的三类实验指标对比
图7为实验中不同预测结果计算的权重,预测性能决定组合权重,预测指标较差的模型,下一日则分配较低的权重,反之,则分配较高的权重。最终的实验结果表明文中方法大幅度提升了数据匮乏场景下商业建筑能耗短期预测性能,并且具备一定的预测鲁棒性。

图7 复合模型实验权重分布
3 结语
针对数据匮乏场景下商业建筑能耗预测问题,提出了一种基于GAN-GRU的商业建筑能耗短期预测组合模型。通过不同约束条件下的GAN结构生成平行数据,在GRU预测分析下,采用适用度最高的结构的平行数据与原始数据关联,以生成的复合数据作为训练数据,并将其通过GRU预测的结果结合方差-协方差权重组合模式得到最终的预测结果。实验结果表明,这种组合模型预测能力远高于传统模型,对数据匮乏场景下的商业建筑节能具有要意义。
