基于GRU循环神经网络的云数据中心应用故障预测方法
2022-03-30胡小宁
胡小宁
(中国铁路信息科技集团有限公司,北京 100844)
中国国家铁路集团有限公司(简称:国铁集团)在2018年建成铁路主数据中心并投入使用。该中心支撑的应用超过350项,采用新一代云架构体系,容纳服务器设备数量达数万台。因此,对铁路主数据中心运维管理工作提出了更高的要求。铁路主数据中心运行与维护(简称:运维)管理工作是该中心各项业务应用平稳可靠、安全高效的重要支撑[1]。传统的应用故障监控方式只能在故障发生后,由运维人员根据故障现象逐层溯源排查,难以在短时间内精准定位故障,导致故障修复时间较长、影响范围和程度不能及时有效控制[2]。在云架构体系下,如果仍旧依靠传统的运维方式,将使运维成本大幅增加,但运维效果却难达预期,如果能提前预测未来可能发生的故障,运维人员就可在故障发生前进行定点排查,提前采取应对措施,避免故障发生后导致的损失,因此推动铁路主数据中心智能化运维已成为必然趋势[3],运维结合人工智能和深度学习技术,能有效提升云数据中心智能化水平和运维效率[4]。
近年来,不少学者针对数据中心故障预测技术进行了相关研究,如采用决策树算法和反向传播(BP,Back Propagation)神经网络进行故障预测[5];基于Adaboost算法的BP神经网络故障预测模型进行故障预测[6];基于加权中值的故障检测方法[7]。这些算法在一定程度上提高了模型预测的精确率,但从试验效果上看,还存在计算算力需求偏大、参数调整复杂、预测结果精确率难以满足实用性要求等问题。因此,有必要针对铁路主数据中心应用场景开展相关研究。
当前,铁路主数据中心对故障监控采取阈值检测报警机制,按CPU、内存、磁盘使用率等指标值是否超过预设的阈值进行预警,采取后报警机制。而该中心中应用种类繁多,固定阈值告警方式不能适用于全部应用。本文通过对应用的CPU、内存和磁盘监控数据进行研究,发现部分应用故障的出现并非突然发生,而是在状态恶化持续一段时间后才发生,此外,部分应用的同类故障多次出现时,其各类监控数据表现出一定的特征性和相关性。因此,本文提出一种改进的循环神经网络模型,通过特征工程和单层感知器(SLP,Single layer Perceptron)对应用故障进行预测,在报警阈值到达前发出预警信息,提前处理可能要发生的故障,避免因应用故障导致的损失,为运维人员提供更充裕的处理时间。
1 相关技术
1.1 特征工程
特征工程是根据要解决的业务问题,从原始数据中提取更多信息的过程,其目的是最大限度地从原始数据中提取特征,以供算法和模型使用。在机器学习的流程中,特征是数据和模型间的关键纽带,选取合适的特征可减轻模型构建难度,输出更高质量的模型[8-9],通常,特征工程包括特征构建、特征提取、特征选择3部分。
1.2 循环神经网络
神经网络具有良好的非线性拟合能力及较强的学习能力,为复杂应用场景提供了有效的理论基础。基于神经网络,既可通过设备故障特征诊断是否将会发生故障,也可通过学习来完善故障诊断知识库。目前,神经网络在设备故障领域的应用研究已成为热点[10-12]。
循环神经网络(RNN ,Recurrent Neural Network)作为深度学习的经典算法之一,可提取前后元素间的关联信息,多用来处理时序数据,被业界称为时序利器。在自然语言处理领域,RNN通过前后项间的时序信息理解文本含义,可实现机器翻译、阅读理解等[13]。在语音信号处理领域,也可通过RNN实现语音处理和语音识别
大规模云数据中心的监控数据按时间序列记录,这些数据在时间顺序上的变化能被循环神经网络捕捉并学习数据随时间变化的复杂非线性关系,从而实现故障预测[14]。
1.3 门控循环单元
在RNN模型的实际应用中,研究者发现,此类模型存在难以处理信息长期依赖(Long-Term Dependency)的缺陷,而基于门控循环单元(GRU ,Gated Recurrent Unit)和长短期记忆(LSTM ,Long Short Term Memory)的RNN模型可弥补此缺陷。GRU和LSTM原理类似,但GRU采用更少的参数,更快的模型训练速度,即可达到相近的训练效果[15]。基于GRU的RNN(简称:GRU网络)采用门控机制,其神经元基本结构[16]如图1所示。
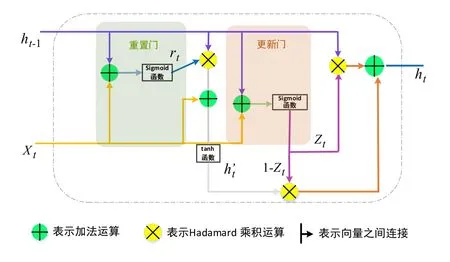
图1 GRU基本结构
从图1可看出,GRU由两个门构成,分别为重置门和更新门。GRU网络的数学公式如下:

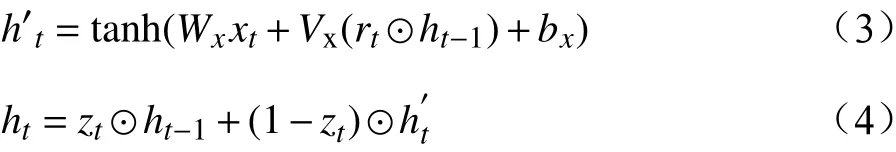
其中,zt表示t时刻的更新门;rt表示t时刻的重置门;xt表示t时刻输入向量;h′t表示中间隐层状态;Wx、Wz、Wr表示t时刻输入向量的权重矩阵,Vx、Vz、Vr表 示t−1时刻隐层状态的权重矩阵,bx、bz、br分别表示中间隐层、更新门、重置门t时刻的偏置项,这些权重矩阵和偏置项都是优化学习的参数,⊙ 表示点乘关系。
结合图1和公式(1)~(4)可知,相比LSTM网络,GRU网络减少一个输出控制,每个单元的输出是其时序传递的单元状态。GRU流程为:(1)从上一个时序单元输入一个ht-1,通过重置门后,与当前的输入xt结合;(2)经过tanh函数激活处理,形成一个新的中间隐层状态h′t;( 3)更新门控制h′t与ht-1以相应的比例进行重组,形成当前时刻的输出ht。
1.4 单层感知器
SLP是一种基于阈值传递函数的前馈网络,其神经元局部记忆的内容由一个权重向量组成,是人工神经网络中的基础类型,能处理二分类问题。单层感知器将输入向量与权重向量相乘求和,然后利用激活函数获得输出结果。
故障预测的结果为故障或非故障,是一个二分类问题,因Sigmoid函数可以将任一实数映射到(0,1)区间,可用来做二分类,故本文选择Sigmoid函数作为SLP的激活函数,并设定一个阈值,Sigmoid函数的输出值大于此阈值则标签为1,表示故障,否则标签为0,表示非故障。
2 应用故障预测
2.1 模型数据
本文使用云数据中心仿真环境中的应用进程(简称:进程)监控数据,对应用进行故障预测。该数据集的信息包括:
(1)在监控数据的时间跨度内,共有59类应用,2 013个进程,选取其中102个出现过故障的进程监控数据作为试验数据。
(2)监控数据包含应用所在服务器的CPU使用率、CPU等待I/O时间百分比、内存使用率、磁盘读写操作次数每秒(IOPS,Input/Output Operation Per Second)、进程的响应时间、网络连接数、CPU使用率、内存使用率,共8个特征。
(3)监控数据时间跨度为2020-07-01 00:00~2021-01-12 23:55,共28个星期,数据粒度为5 min。
通过对数据进行分析,发现每次应用发生故障前,在一段时间内,监控指标具有一定上升或下降趋势。本文对具备此类特征的进程监控数据进行建模和训练,构建基于GRU循环神经网络的云数据中心应用故障预测模型(简称:模型),将单个进程监控数据的前80%作为训练数据,剩余20%作为测试数据。
通过特征工程对原始监控数据进行预处理,包括数据的冗余清洗、特征提取、缺失值处理、无量纲化等,其中,特征值筛选采取嵌入法中基于惩罚项的特征选择和专家判断相结合的方法,对数据的无量纲化处理采用Z-score标准化方法,以时间序列x1,x2, ···,xn为例,n为特征值总数,Z-score标准化计算公式为:

则新序列的y1,y2,···,yn均值为0,标准差为1。
2.2 模型实现过程
模型实现过程如图2所示,其中,yt为判断故障标签;a为设定的故障阈值;w0~wn代表权重矩阵;代表t时刻n个特征的隐层状态(即网络层的输出);T代表训练数据时长;代表t时刻第n个特征的值。主要步骤如下。

图2 预测模型实现过程
(1)对监控数据中存在错误或缺失的数据进行特征工程处理,用此点相邻的部分点均值进行替换或补充,对磁盘IOPS、进程的响应时间、网络连接数等进行归一化处理。
(2)GRU网络输入的单个进程的8个特征数据为:CPU使用率(x1);内存使用率(x2);CPU等待I/O时间百分比(x3);CPU使用率(x4);内存使用率(x5);归一化后的网络连接数(x6);归一化后的响应时间(x7);归一化后的磁盘IOPS(x8)。
(3)利用选取的数据进行模型训练,根据模型测试的精确率进行参数调整及激活函数选定,从而确定GRU模型。
(4)使用和(3)相同的训练数据和测试数据,根据模型测试的精确率和覆盖率确定SLP的参数,训练出单个进程的SLP模型。
(5)利用(3)中训练得到的模型,预测单个进程未来一段时间的监控数据,通过(4)的SLP模型,得出单个进程发生故障的概率,并与此进程设定的阈值进行比较,判定进程是否故障。
2.3 参数设定
模型的训练调参阶段,通过对不同迭代次数(Epoch)和不同批处理(Batch_size)大小设定值的多次测试,确定当Epoch=20,Batch_size=2时,模型效果较好。基于该参数设定,某进程的CPU预测使用率和实际情况如图3所示。该进程CPU的预测使用率和真实使用率差值较小,趋势基本吻合,表明本文采用的方法对故障预测具有较高的精确性。

图3 某进程CPU使用率预测情况
3 结束语
针对铁路云数据中心应用运维管理中面临的故障复杂性和随机性问题,提出一种基于GRU循环神经网络和SLP相结合的应用故障预测方法。本方法可对服务器和应用进程的监控数据进行特征工程处理,从原始数据中提取必要特征供算法模型使用,能较快获得高精确率的预测数据,提高判定进程故障的精确率。通过试验数据和仿真分析结果,验证了本方法的实用性。
