基于领域主题的学科交叉特征识别方法研究
2022-03-30陈琼朱庆华闵华刘周颖
陈琼 朱庆华 闵华 刘周颖










作者简介:陈琼(1998-),女,硕士,研究方向:网络信息资源管理。朱庆华(1963-),男,教授,博士生导师,研究方向:网络信息资源管理,用户信息行为。闵华(1969-),女,副教授,研究方向:语义网、健康信息学。 刘周颖(1994-),女,博士研究生,研究方向:网络信息资源管理、社会化媒体。
摘 要:[目的/意义]为了更加精准地探究学科交叉规律,本研究构建一个基于领域主题的学科交叉特征识别框架以识别学科交叉主题、交叉态势以及交叉结构。[方法/过程]对WOS数据库中医学信息学领域2000—2020年发表的45 546篇文献进行实证研究,首先基于LDA主题模型划分领域主题,然后引入Div指标分析比较学科交叉态势,最后构建学科共现网络并结合中介中心性分析学科边缘—核心子群结构。[结果/结论]本研究共划分9个子主题,分别为心脏信号传感系统、电子健康技术、电子病历系统、健康app和使用行为、医疗护理电子系统、随机治疗实验、图像分割和聚类、基于机器学习的特征识别以及癌症治疗风险评估,其中前5个主题的学科交叉程度在近5年呈现波动上升的趋势;学科结构方面,交叉程度较深的主题大多以工程学和计算机科学为核心学科。本研究有助于科研管理部门以及科研人员制定相关政策、优化资源配置、识别学科前沿等。[局限]由于早期期刊文献引文信息不全面,一定程度上会影响学科交叉程度计算的精确度。
关键词:学科交叉;领域主题;LDA模型;特征;识别;医学信息学
DOI:10.3969/j.issn.1008-0821.2022.04.002
〔中圖分类号〕G201 〔文献标识码〕A 〔文章编号〕1008-0821(2022)04-0011-14
Abstract:[Purpose/Signficance]In order to explore the interdisciplinary rule more accurately,the study constructs a framework to recognize the interdisciplinary features based on domain topics,which helps to identify interdisciplinary topics,interdisciplinary situation and interdisciplinary structure.[Method/Process]45546 articles in the field of medical informatics in WOS database from 2000—2020 were used for empirical research.Firstly,domain topics were divided based on LDA topic model.Then,Div index was introduced to compare and analyze the interdisciplinary situation.Finally,the disciplinary edge-core subgroup structure was analysed based on co-occurrence network and betweeness centrality.[Result/Conclusion]There are nine sub topics divided,including heart signal sensing system,electronic health technology,electronic medical record system,health app and use behavior,medical care electronic system,randomized treatment experiment,image segmentation and clustering,feature recognition based on machine learning,and cancer treatment risk assessment.Among them,the interdisciplinary degree of the first five subjects shows a fluctuating upward trend in recent five years;In terms of discipline structure,engineering and computer science are the core subjects with deep interdisciplinary degree.This study is helpful for scientific research administrations and researchers to formulate relevant policies,optimize resource allocation,and identify the frontier of disciplines.[Limitations]Due to the incomplete citation information of early journals,the accuracy of interdisciplinary degree calculation would be affected to a certain extent.
Key words:interdisciplinary;domain topic;features;recognize;LDA models;medical informatics
随着大科学时代的到来,“交叉”已经成为现今科学发展的关键词。自20世纪中后期,学科间的交叉融合活动越来越频繁,不断碰撞衍生出新的学科,形成错综复杂的学科网络。目前,在5 500多个较为成熟的学科领域中,有近一半的学科具有交叉融合的特征[1],例如生物化学、人工智能、生态经济学等。
学科间的交叉融合既是知识发展、技术创新的重要源泉,也是人类社会实践的迫切需求。一方面,学科交叉点往往可能就是新的科学生长点、新的科学前沿,最有可能产生重大的科学突破,使科学发生革命性的变化[2],如DNA双螺旋结构、人类基因组测序、载人空间飞行等重大科研成就都是学科间合作的成果;另一方面,人类社会中许多复杂重大的问题已经无法在单一学科的研究范式和思维模式下解决,多学科交叉合作大势所趋。学界与产业界积极呼吁不同学科领域间的知识共享和协作,交叉科学研究(Interdisciplinary Research,IDR)应运而生。
在此背景下,教育部、财政部和国家发改委提出“双一流”高校要积极创新学科组织模式,促进基础学科之间的交叉融合,组建学科联盟,搭建学科交流平台[3]。北京大学、南方科技大学、北京理工大学等多所高校先后成立前沿交叉科学研究院,致力打造一流的多学科交叉融合学术发展平台。2019年,国家自然科学基金申请中增设了“共性导向、交叉融通”类科学问题属性[4],鼓励发展具有学科交叉背景的研究项目。2020年11月,国家自然科学基金委员会正式成立交叉科学部,负责统筹国家自然科学基金交叉科学领域整体资助等工作[5],进一步推动学科间交流、打破学科壁垒、促进学科创新。学科设置方面,2021年教育部宣布“交叉學科”成为第14个学科门类[6],强调经济社会发展对高层次复合型人才的迫切需求,学科交叉深度融合势不可挡。
目前,学科交叉活动已经广泛深入到各个研究领域,大数据背景下学科交叉方式朝着多样化、大跨度和深层次的方向发展。识别学科交叉特征,即探索学科间的交叉规律,宏观上是学科交叉的形成和发展态势,从国家、机构等维度对未来学科发展趋势进行把控;微观上则是从主题粒度甚至是篇章粒度识别学科交叉点,探索学科重点发展方向。探索学科间的交叉规律、认识学科交叉知识形成和发展过程、识别学科交叉点对于交叉科学研究有着重要的意义。科学计量视角下的交叉科学研究多属于信息科学和图书馆学领域,近年来成为图书情报领域十分重要的研究方向[7],主要包括交叉科学测度指标、交叉科学研究评价、交叉科学可视化研究等方面。目前,图书情报领域的交叉科学研究主要存在以下几个问题:研究维度上,主要侧重于关注学科交叉的演化态势,从整体学科的层面探究学科交叉结构变化以及国家机构特征,而基于微观层面的交叉特征研究还较少[7];数据来源上,现有学科交叉主题研究中涉及的数据量较小,不利于识别真正的学科增长点;研究方法上,已有研究以关键词分析和单一的测度指标为主,在交叉特征识别上不够准确;研究内容上,交叉主题的研究还不够深入,缺乏进一步对主题进行交叉态势分析。因此,本研究提出基于领域主题的学科交叉特征识别的研究方法,结合LDA主题模型、社会网络分析、引文分析等研究方法,在引文内容的基础上构建基于领域主题的学科交叉特征识别研究框架,并以医学信息学领域为例,识别学科交叉主题、交叉态势以及交叉结构。
1 国内外研究现状
1.1 学科交叉测度指标
学科交叉测度指标可以分为两大类——多样性指标和凝聚性指标[7],前者主要是从学科的丰富性、平衡性和差异性衡量学科交叉程度,后者则是基于社会网络分析的方法衡量学科交叉融合的紧密程度。已有研究中所使用的学科交叉测度指标如表1所示。
虽然研究人员意识到学科交叉测度难以利用单一的标准进行客观的评价,需要尝试融合多指标进行研究,但现有研究中多指标融合倾向在同一维度内进行,少有研究考虑结合多样性和凝聚性不同维度的指标进行研究。少数的综合性指标,如全局Φ指标的使用较少[19],科学性也有待进一步考证。另外,现有的学科交叉测度指标更多是用于宏观层面学科交叉演化过程,但在微观主题的研究中,尤其是不同主题交叉程度的比较上,可行性和有效性尚未得到充分的验证。因此,本研究试图引入新的学科交叉测度指标,并基于多维指标构建基于领域主题的学科交叉特征识别的研究框架,为学科交叉特征研究提供新的思路。
1.2 学科交叉主题识别
学科交叉主题主要是指学科交叉程度较强的研究主题,学科交叉主题往往可能是研究前沿或知识生长点,因此,识别学科交叉主题是交叉科学研究中的一个关键问题。现有学科交叉研究中主要是从宏观层面分析学科交叉态势,针对微观层面下学科交叉主题的识别和态势分析还较少。已有研究中主要是基于关键词、引文分析以及文本挖掘3个视角进行学科交叉主题的识别。
1)基于关键词的学科交叉主题识别
关键词是知识组成的基本单元,是反映文献主题并进行学科知识分析的最直接、便捷的方式。通过分析学科间关键词的交叉情况,不仅能够快速了解学科交叉的发展,而且可以提取具体的交叉内容[20]。闵超等基于关键词共现进行聚类分析提取研究主题,并引入战略坐标图探讨了学科交叉研究主题的内在联系和发展脉络[21]。李长玲等基于关键词围绕学科交叉主题进行一系列相关的研究,先后通过重叠社群网络的可视化分析、关键词共现矩阵以及时序关键词聚类分析等方法识别交叉主题[22-24]。杜德慧等对跨学科参考文献的关键词进行分析,构建学科相关新颖性指数,计算跨学科引文关键词与目标学科的新颖且相关程度,识别与目标学科具有较大合作潜力的跨学科知识[25]。Xu H等提出TI指标来挖掘学科交叉主题,并以图书情报学为例验证TI值和Bet值能够很好地识别外部学科和内部主题的交集[26]。Dong K等综合共现网络分析、高TI术语分析和突发监测等研究方法,从多维角度识别图书情报学领域的学科交叉主题,以期获得更为全面和准确的结果[27]。整体来看,关键词共现网络是现有学科交叉主题研究中较为常用的研究方法,在此基础上结合社会网络分析、时序分析、聚类分析、多维尺度分析等方法展开研究。
2)基于引文分析的学科交叉主题识别
引文分析通常是指基于文献间的引用关系,包括纵向继承的引用/被引关系、横向联系的共引/共被引关系来构建相应的引文网络。基于学科的引文网络可以识别学科结构、主题子群、核心节点、桥梁节点等关键知识节点,并结合测度指标来识别学科交叉主题。除了文献间的引用关系,不同学科间互引网络的共同研究内容也可以代表跨学科交叉研究主题[28]。因此,引文分析方法也可用于学科交叉主题识别的研究。Chi R等基于共被引网络分析,进行探索性网络分析和内容分析,识别研究主题的发展以及相互之间的关系[29]。Rafols I等以生物纳米科学领域为例,构建文献耦合网络,结合多样性和连贯性分析学科交叉主题的出现和扩散[16]。章成志等从引文内容的视角分析学科交叉类别、检测多学科交叉现象,对改进传统的学科多样性测度具有重要参考价值[43-44]。相较于文献计量学的其他研究领域,引文分析在学科交叉主题识别中应用较少,主要原因可能是引文分析具有一定滞后性,无法及时准确地识别新兴的学科生长点。
3)基于文本挖掘的学科交叉主题识别
随着文本挖掘技术的兴起,研究人员开始关注文本挖掘算法在学科交叉知识发现上的应用,综合考虑语法、语义信息的运用。商宪丽基于多模主题网络,构建学科—对象—方法三模网络,识别交叉学科知识组合模式[30]。韩正琪等使用Rao-Stirling指标筛选学科交叉文献,再基于LDA主题模型识别学科交叉主题[31]。张斌结合LDA模型和桑基图,对管理信息系统学科及相关的基础学科进行主题划分,并对主题词进行共现分析学科之间的关系[32]。Raimbault J将语义分析与引文网络相结合,构建地理学领域的大规模数据集揭示学科交叉主题[33]。基于文本挖掘的学科交叉知识发现将成为未来交叉科学研究的趋势,在数据来源、数据规模、识别准确性等方面存在更为广阔的应用空间。
2 研究设计
LDA主题模型是一种文档主题生成模型,该模型算法基于概率主题分布的方法进行文本语义分析并从中抽取出有价值的潜在主题信息[34]。LDA主题模型假设存在一组潜在的主题,每个主题由不同出现概率的主题词组成,每篇文章也是由不同主题根据不同概率所组合而成[35]。LDA主题模型在大规模语料识别和潜在隐藏主题发现上存在一定的优势,例如一个主题词可以出现在多个主题中,基于摘要或全文而不仅仅是关键词等,一定程度上弥补了关键词分析和引文分析方法的不足,能够实现内容主题层面的文献数据分析和影响力评价。因此,本研究采用LDA主题模型对医学信息学领域主题进行划分。
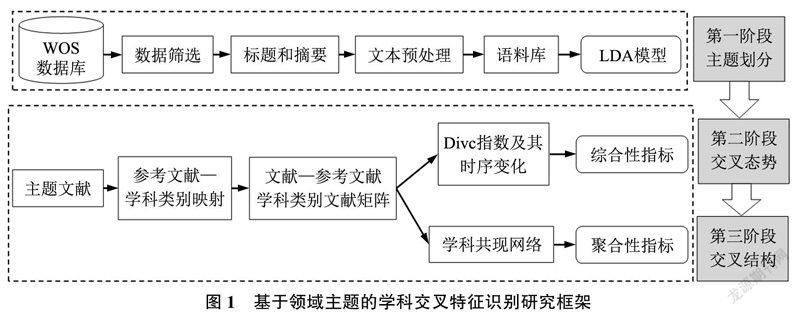
针对前人研究的不足,本研究提出基于领域主题的学科交叉特征识别研究框架,主要分为3个阶段,如图1所示。首先,从WOS数据库筛选文献,进行数据清洗并构建语料库,利用LDA对医学信息学领域进行主题划分。然后,使用引文分析方法构建文献—参考文献学科类别文献矩阵,利用Div等学科交叉多样性指标对各主题的学科交叉程度进行探测,利用时序性分析方法对各个领域主题的学科交叉态势和未来发展进行展望。最后,使用Gephi软件绘制各领域主题的学科共现网络,使用Louvain聚类算法进行学科子群的分类,基于中介中心性等凝聚性指标识别核心学科子群和边缘学科子群,探索各领域主题的学科交叉结构。
2.1 数据来源与处理
医学信息学是聚焦于对医学信息的处理、实践与教育的一门交叉学科,它所涉及的学科范围较广,学科交叉程度较高,且交叉对象较为复杂,学科前沿与学科交叉主题的关系更为密切,因此了解不同领域主题下的学科交叉特征更有利于相关从业人员、研究者更好地把握研究动态、选择研究方向并进行有效的资源配置。本研究以医学信息学领域英文文献为研究对象,选择Web of Science(WOS)核心数据集作为来源数据库,设定学科类别为医学信息学,即“WC=medical informatics”为检索式进行检索,设定文献类型为论文(Article),检索年限为2000—2020年,实施检索得到45 546条数据。从WOS下载所有相关文献的全记录信息,包括论文检索号、标题、摘要、关键词、参考文献、作者、来源期刊等信息。为了对医学信息学领域中具有一定代表性的研究性文献进行学科交叉性研究,笔者对文献进行自动筛选。首先剔除没有摘要、参考文献不完整或参考文献数量较少的文献,共3 350篇;然后笔者又删去被引次数为0和1的文献,共7 653篇。通过筛选,最终确定34 543篇文献题录数据作为研究数据集。
目前,构建文本语料库的形式包括关键词、摘要、标题+摘要、关键词+摘要等。传统的共词分词方法多使用关键词作为语料,而在主题模型的实践中,许多研究选择的是摘要、标题+摘要的形式,相较于关键词,摘要和标题融合下所提取的主题准确度较高、语义信息混乱程度较低且主题粒度较细[40]。因此,本研究通过抽取文献题录数据中的标题和摘要,并将这两个字段合并作为文献内容字段,经过一系列数据预处理操作生成文本语料。数据预处理主要分为3个步骤:第一步,对文本内容进行分词;第二步,去除停用词,本研究使用的停用词表除一般的英文停用词表外,还融入了冯佳针对医学信息学文本选取的停用词表[40],在剔除停用词的基础上过滤掉文本中的标点符号、语气助词、副词、介词等没有实际含义的词汇;第三步,通过Python语言中的Porter Stemmer包进行词形归并和词根提取,最终生成包含65 477个词汇的语料库。
2.2 Div交叉测度指标
Stirling A认为,学科交叉多样性测度主要包括3个特征:丰富性(Variety)、平衡性(Balance)和差异性(Disparity)[36]。为了能够更加清晰地描绘学科交叉特征,学者们通常将这3种特征融合在一起,如广泛使用的学科交叉测度指标Rao-Stirling[12]。Rao-Stirling指标使用辛普森指数(Simpson Index)将丰富性和平衡性结合在一起,然后再融入代表差异性的学科相似度。研究人员开始意识到Rao-Stirling指标并不够准确,利用辛普森指数來替代丰富性和平衡性可能会影响这两个指标在最终结果中的权重,平衡性通常在计算过程中被弱化了甚至根本不存在[37]。因此,Leydesdorff L等提出将多样性、平衡性以及差异性独立开来再互相融合的测度指标Div交叉测度指标[38],该指标被初步运用在期刊层面的学科交叉测度。并且实证研究发现,相较于Rao-Stirling指标,它能够更加准确全面地反映学科交叉特征。本研究借鉴这一思想,将其运用于领域主题的学科交叉测度并试图验证该指标的可行性。Div计算公式如下所示:
n表示该主题所属的学科数量,N表示学科总数量,Re_Variety表示相对多样性;Gini_Co即基尼系数,用于衡量平衡性,xi表示学科i出现的次数,基尼系数越大说明该主题文献的学科分布越不平衡,因此,1-Gini_Co可以体现该主题的平衡性;dij表示学科间的距离,本文采用余弦相似度来表示学科间的距离。
2.3 学科边缘—核心子群分析
本研究将基于学科共现网络进行学科交叉结构
的分析,识别学科边缘—核心子群。通过Louvain聚类算法对学科共现网络进行聚类分析,划分学科子群。Louvain聚类算法是一个包含两阶段的反复迭代过程[39],它在计算时间和准确性上都有良好的表现。目前,它已经广泛用于知识科学分析,著名知识图谱软件Gephi与Pajek都是基于此算法对网络进行社团划分;另外,它基于模块度的自我优化过程不需要提前确立聚类的数量,可以避免由于主观设立聚类数量而带来的误差。根据Blondel V D等的研究,该算法的有效性在于模块度的增加ΔQ是可以通过将孤立节点不断合并入其他的社区得到的[39],其计算公式如下:
在划分学科子群的基础上,再结合中介中心性指标识别核心学科、边缘学科、核心学科子群以及边缘学科子群。中介中心性的计算方式如表1所示,在学科共现网络中,中介中心性较强的学科可以划分为核心学科,包含较多核心学科的学科子群可以划分为核心学科子群。
3 基于LDA主题模型的领域主题划分
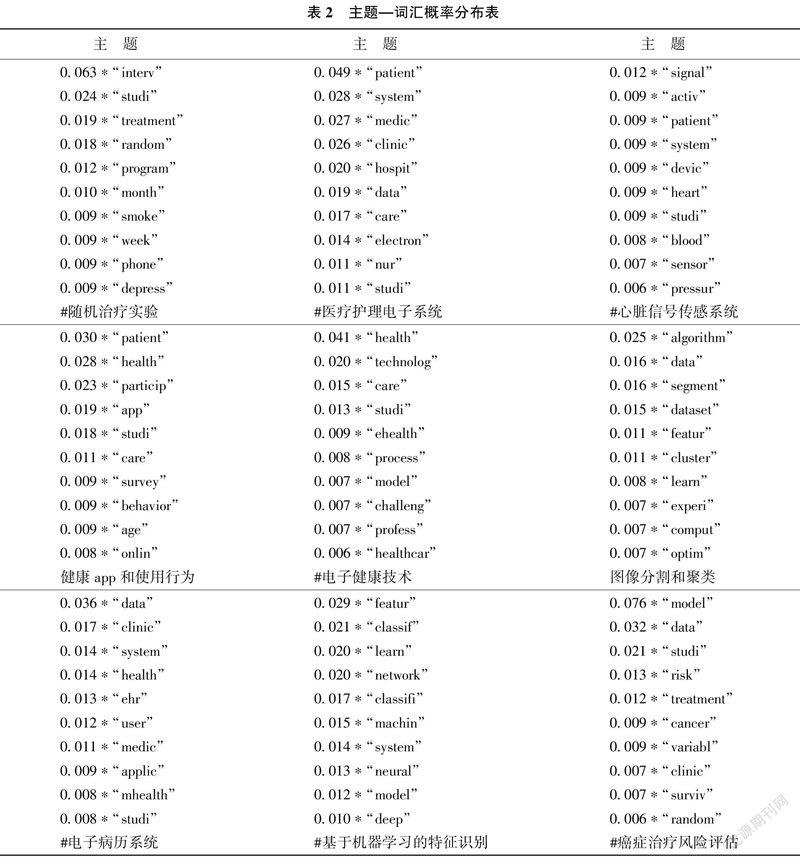
本研究采用LDA主题模型抽取医学信息学领域潜在的主题分布,其中划分的主题数量K是决定LDA主题模型质量的关键参数。困惑度是对概率模型预测样本的量化评估,能够作为评估LDA主题模型的量化指标,以帮助确定最有的K值[45]。初步设定选取20以内的主题数量,设定K值从1开始取值,步长为1,进行反复运算,并绘制困惑度的变化曲线,如图2所示。如图中曲线所示,当K值为9时,模型的困惑度处于极小值,且K值随后波动开始明显变小,因此,本文确定最终的主题数量K为9个。随后对语料库进行LDA主题建模,主题抽取结果如表2所示。本研究列举每个主题下概率最高的10个词汇,以描绘各主题内容。
最后,需要根据提取的主题进行文献的分类,Mann G S等认为,如果一篇文献中超过10%的概率是由某一主题生成的,则认为这篇文献属于该主题,基于次构建文献和主题之间的映射,将一个主题和一组文献构建关系[41]。因此,本文设定0.1的阈值,即如果一篇文献由某一主题生成的概率不小于0.1,则认为这篇文献属于该主题。
4 数据分析
4.1 基于多样性维度的学科交叉态势分析
本研究基于引文分析进行学科交叉主题的识别。对初始数据源中的参考文献进行学科分类,需要将参考文献依据其期刊简称映射到相应的学科上。首先,从JCR下载1997—2019年的期刊简称和期刊全称对照表,基于该表将参考文献所属的期刊简称转化为全称;然后在WOS Group网站下载2020年更新的期刊—学科类别映射表,基于此表可以将转换为全称的期刊名称投射到其所属的WOS学科类目中。但是,仅仅依靠上述方法无法将一部分已经被JCR剔除、停止出版以及书写不规范的期刊和会议简称进行转换,因此,本研究还利用爬虫技术,将这部分期刊和会议简称通过WOS的期刊名称检索功能,爬取其所属的相应的WOS学科类目。得到初始数据源中发表在被WOS收录的期刊上的、有期刊—学科映射关系的有效数据为864 970条。统计每个学科类目下的文献数量用于进行医学信息学学科交叉性分析,考虑到JCR中部分期刊被归属到多个学科类目,发表在这些期刊上的文献在其所对应的所有学科分类上均有计数,表3为参考文献—学科类别映射表。
基于Python构建医学信息学领域文献引文学科分布矩阵,本研究利用R语言编写程序语言,利用Chavarro D等所构建的WOS学科类别相似矩阵[42],计算医学信息学领域各主题的相对多样性、基尼指数、信息熵、差异性、Rao-Stirling指数和Div指数,表4为计算结果。经计算,Div指数和Rao-Stirling指数的相关性系数为0.96(p<0.001),因此,Div指数可以有效刻画领域主题的学科交叉程度。如表4所示,主题3(心脏信号传感系统)、主题8(基于机器学习的特征识别)、主题6(图像分割和聚类)以及主题5(电子健康技术)的学科交叉程度较高,可被视为医学信息学领域的学科交叉主题。
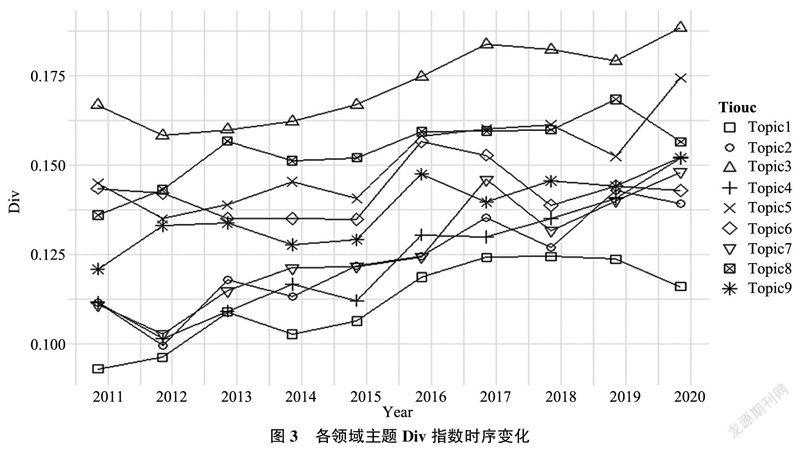
针对各个主题近10年(2010—2019)的文献,计算每一年的学科交叉测度指标Div以研究学科交叉发展态势,结果如图3所示。总体来看,医学信息学的学科交叉程度呈随时间上升的趋势,但具体来看,不同主题的上升窗口期不尽相同。主题3(心脏信号传感系统)、主题5(电子健康技术)、主题7(电子病历系统)、主题4(健康App和使用行为)、主题2(医疗护理电子系统)的学科交叉程度在近5年呈现波动上升的趋势,而同时段主题1(随机治疗实验)、主题9(癌症治疗风险评估)、主题8(基于机器学习的特征识别)、主题6(图像分割和聚类)的学科交叉程度都已经趋向平缓。学科交叉程度的不断增长表明该主题受到研究学者的广泛关注,更多研究领域被引入,推动该主题进一步发展,是潜在的学科热点和前沿主题;而当学科交叉程度趋向平缓,说明该主题的研究逐渐成熟,选择的跨学科合作对象种类和研究路径趋于稳定,形成了较为完善的研究体系。
4.2 基于凝聚性维度的学科交叉结构分析
基于各个主题的文献—参考文献学科类别矩阵,将其转换为学科共现矩阵,计算两两学科在同一文献中同时出现的次数,然后將矩阵导入Gephi软件进行绘图,利用Louvain聚类算法进行聚类分析,划分为不同的学科群体。为了更加清晰地展示聚类结果以及该主题下的核心学科,本研究根据边的权重以及节点的加权度,过滤掉权重较低的节点和边,同时依据中介中心性大小设定节点大小绘制学科共现网络,主题进行学科群体划分的结果如图4~图12所示,然后再通过计算各个节点的中介中心性评价各个学科在该主题的影响程度,表5~表13展示了每个主题的中介中心性TOP5的学科信息。
1)主题1:随机治疗实验
学科群体①——以公共卫生、环境卫生与职业卫生、医学信息学、卫生保健及服务等医学学科为主;学科群体②——以计算机信息系统、计算机交叉科学等计算机学科为主;学科群体③——以精神病学、心理学、儿科等学科为主。虽然学科群体①包含的学科数量是最少的(21.7%),但是从图4可以看出学科群体①所包含的核心学科是最多的,是该主题的核心学科子群,相较而言,学科群体②(49.06%)和学科群体③(29.25%)所包含的学科数量较多,其中的核心学科数量却较少,是该主题的边缘学科子群。该主题的学科交叉程度较弱,个别核心学科控制了整个学科群体中学科之间的交流。
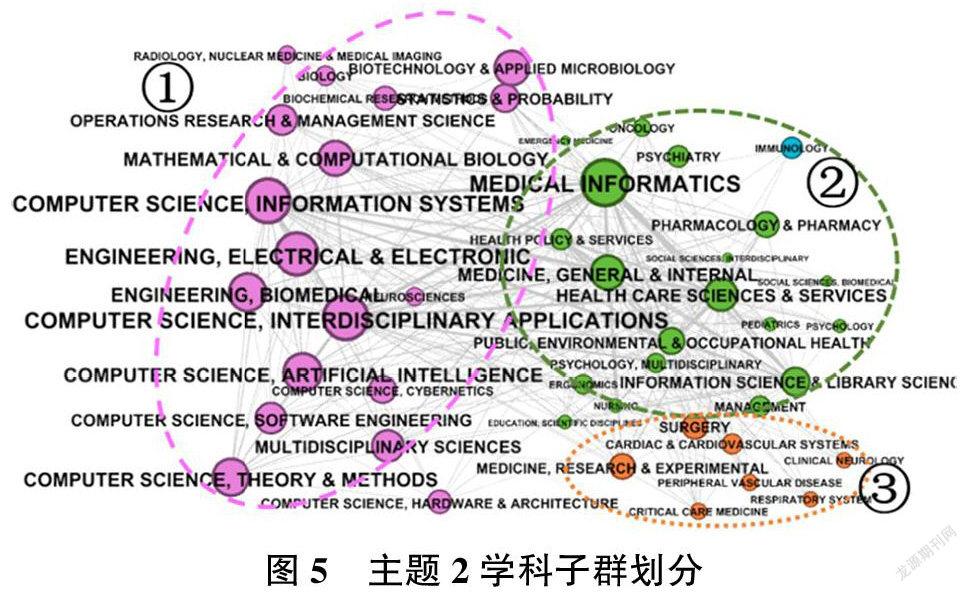
2)主题2:医疗护理电子系统
主题2可以划分为3个学科群体,分别为学科群体①——以计算机交叉科学、计算机信息系统、电子电气学等与计算机科学和工程学相关的学科组成;学科群体②——以医学信息学、健康护理学等医学相关学科组成;学科群体③——以医学研究与实验、外科学等相关学科组成。学科群体①和学科群体②都属于本主题的核心学科子群,存在重大影响力的学科很多,节点间的联系也更为紧密,交叉学科程度和丰富度都很明显,尤其是学科群体①和②之间的联系非常紧密,这体现出医疗护理电子系统主题下学者们主要利用计算机和工程学技术来解决医学信息学的相关问题。
3)主题3:心脏信号传感系统
主题3可以划分为:学科群体①——以计算机交叉科学、数学与计算生物学、电子与电气等计算机科学与工程学相关学科组成;学科群体②——以普内科、神经学、心脏和心脏系统学等学科组成;学科群体③——多学科交叉科学和医学实验与研究等学科组成。整体上看,每个学科群体中都存在中介中心性很强的学科,相较而言,学科群体①包含的核心学科数量最多,体现了该主题中计算机科学和工程学的重要地位。同时,该主题中多学科交叉科学也处在很重要的位置,体现了该主题多学科融合性。与其他主题不同的是,该主题下各学科中介中心性值没有特别高的,排名前5的学科的中介中心度都比较均衡,这体现了“心脏信号传感系统”主题中学科互相融合、互相衍生的特征。
4)主题4:健康App和使用行为
可以分为3个学科群体,学科群体①——以健康服务、健康政策以及公共健康等为主;学科群体②——主要包括外科、神经科学;学科群体③——以计算机信息系统和交叉学科为主。学科群体①为核心学科子群,节点的内外部连线都非常丰富,而学科群体②和学科群体③的内部连接较少,大多是依附于学科群体①。另外,该主题中介中心性排名前5的学科都属于医学大类,这体现了该主题下对其他非医学类学科的融合较弱。
5)主题5:电子健康技术
学科子群①和学科子群②为核心学科,学科子群①中除了医学信息学、卫生护理和服务等医学学科,还融入了管理学、运筹管理科学、商业等社会学相关学科;学科子群②以工程学学科和计算机学科为主。学科子群①和学科子群②之间交流十分紧密,体现了该主题学科合作紧密,学科应用广泛的特征。
6)主题6:图像分割和聚类
学科子群①——以计算机信息系统、计算机交叉学科、电子电气工程、生物工程等工程计算机学科为主;学科子群②——以医学信息学、普内科等医学相关学科為主;学科子群③——以生物化学、生物工程等生物学相关学科为主。每个学科子群都有影响程度较大的学科子群,整体而言,核心学科数量较多,分布较为均匀,学科交叉结构比较丰富。
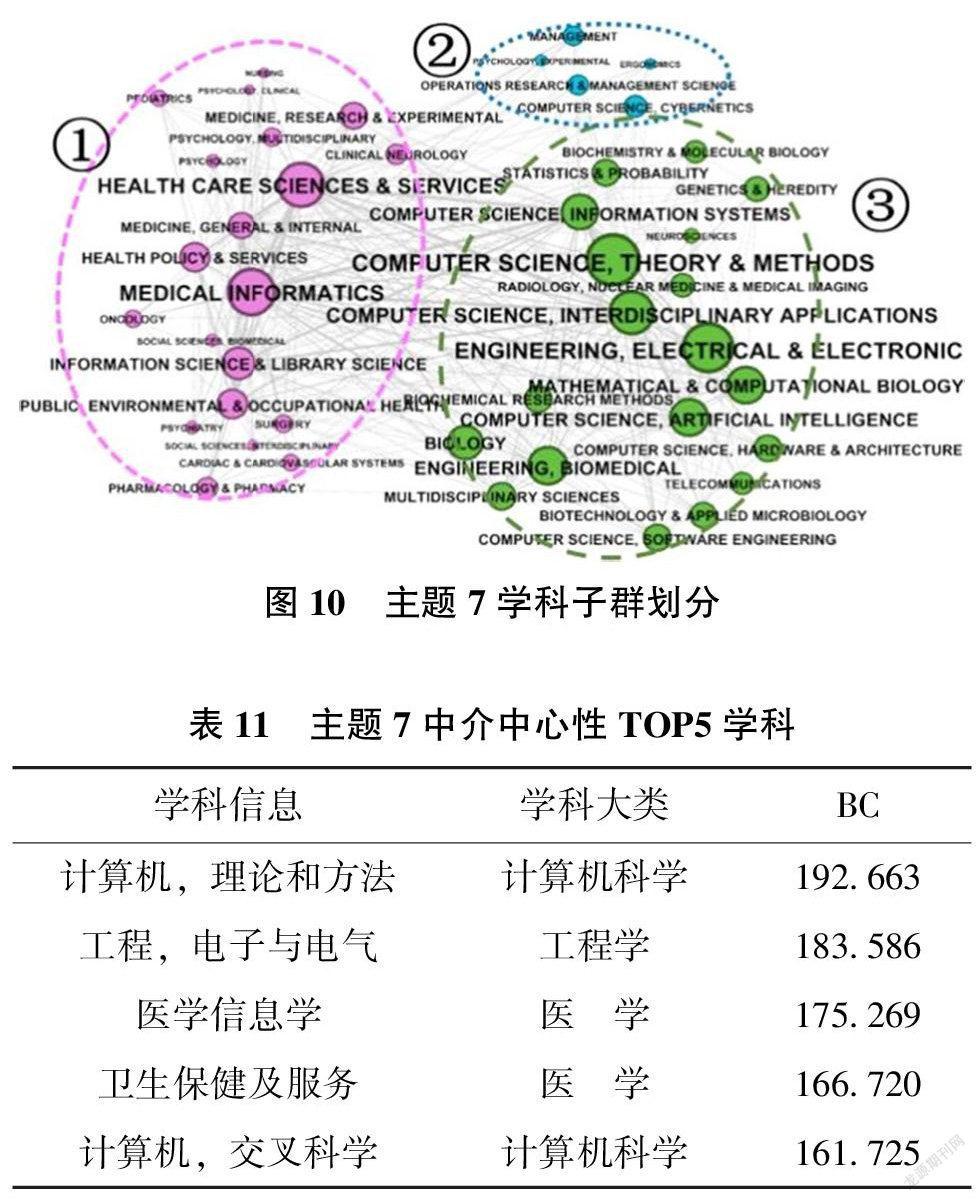
7)主题7:电子病历系统
学科子群①——以医学信息学、卫生护理和服务等学科为主,另外,图书情报学科也处在核心学科的位置;学科子群②——边缘学科子群,主要以管理学为主;学科子群③——核心学科数量最多,主要是计算机科学和工程学相关学科。该主题下计算机学科和工程类学科的影响显著,尤其是与计算机科学相关的理论和方法在该主题的相关研究中被广泛使用。
8)主题8:基于机器学习的特征识别
学科子群①——以计算机科学和工程学相关学科为主,还包括一些计算机和医学生物学的交叉学科,是数量最多、影响最大的学科子群;学科子群②——主要包括普内科等医学学科;学科子群③——主要是生物学相关的交叉学科;学科子群④——则是以神经科学为主。该主题主要是以计算机学科和工程学学科知识为主导,研究其在各种医学、生物学领域的作用。
9)主题9:癌症治疗风险评估
学科子群①——以医学信息学、统计学与概率论、生物学为主;学科子群②——以计算机交叉科学、交叉科学、生物工程等学科为主;学科子群③——以普内科、卫生护理和服务以及健康政策和服务相关学科有关。该主题相关研究还是以医学学科为主,各学科子群中都存在医学、生物学相关的学科。
5 结 语
随着科学研究逐渐转向基于数据密集型的第四范式,学术研究的知识发现模式也在不断革新,越尖端、前沿的研究越需要突破单一学科的限制,多学科交叉的研究范式受到学者们的广泛关注。学科合作与交流有助于拓宽现有的学科研究边界,提出创新性的研究问题,提供更多元的理论基础和视角。
本研究在梳理前人研究的基础上,提出基于领域主题的学科交叉特征识别方法。研究维度上,目前图书情报领域的交叉科学研究主要侧重于关注学科交叉的演化态势,而基于微观层面的交叉特征研究还较少[7],本研究着眼于学科交叉研究的微观层面,补充相关研究的空白;数据来源上,现有学科交叉主题研究中涉及的数据量较小,不利于识别真正的学科增长点,本研究获取的数据量相较而言较为全面、翔实,能够提供有利的数据支撑;研究方法上,综合考虑学科交叉测度的多样性和凝聚性维度,分为学科交叉态势分析和学科交叉结构两阶段,能够更加全面地识别学科交叉特征,弥补过去研究中单一维度的不足;研究内容上,深入学科交叉主题的态势分析,试图解决以往研究中对学科交叉点不够深入的问题。
在学科交叉态势分析上,本研究引入Div学科交叉测度指标以解决Rao-Stirling指标的不足,并通过实证研究证明其在领域主题层面的学科交叉测度的可行性。基于Div指标的时序性分析,发现主题3(心脏信号传感系统)、主题5(电子健康技术)、主题7(电子病历系统)、主题4(健康App和使用行为)、主题2(医疗护理电子系统)的学科交叉程度在近5年呈现波动上升的趋势,可能为医学信息学领域未来的研究热点和潜在的研究前沿。在学科交叉结构分析上,绘制学科共现网络,使用Louvain聚类算法划分学科子群并结合中介中心性测度指标分析不同主题的学科交叉结构,帮助研究人员进一步把握不同主题的学科交叉动态。
本研究存在一定局限性,基于引文信息构建参考文献—学科类别映射表存在一定误差,年份较早的期刊文献可能不在WOS期刊映射表,可能会导致早期期刊文献的学科交叉程度计算偏小,未来研究可以考虑在引文信息基础上再融合期刊信息进行学科类别映射;在学科交叉结构分析上缺乏对动态结构的分析,未来研究可以进一步从不同角度完善该研究框架;另外,微观层面的学科交叉研究不局限于领域主题,未来研究可以在本研究基础上继续聚焦更加细粒度的交叉特征识别。
参考文献
[1]光明网.设置交叉学科:打破科学割据,作彻底联合的努力[EB/OL].https://news.gmw.cn/2021-02/27/content_34647253.htm,2021-05-01.
[2]路甬祥.学科交叉与交叉科学的意义[J].中国科学院院刊,2005,(1):58-60.
[3]中华人民共和国中央人民政府.三部门印发《关于高等学校加快“双一流”建设的指导意见》的通知[EB/OL].http://www.gov.cn/xinwen/2018-08/27/content_5316809.htm,2021-05-01.
[4]国家自然科学基金委员会.关于2019年度国家自然科学基金项目申请与结题等有关事项的通告[EB/OL].http://nsfc.gov.cn/publish/portal0/tab434/info74695.htm,2021-05-01.
[5]国家自然科学基金委员会.学部简介[EB/OL].http://dids.nsfc.gov.cn/index.html,2021-05-01.
[6]中华人民共和国中央人民政府.国务院学位委员会 教育部关于设置“交叉学科”门类、“集成电路科学与工程”和“国家安全学”一级学科的通知[EB/OL].http://www.moe.gov.cn/srcsite/A22/yjss_xwgl/xwgl_xwsy/202101/t20210113_509633.html,2021-05-01.
[7]顾秀丽,黄颖,孙蓓蓓,等.图书情报领域中的交叉科学研究:进展与展望[J].情报学报,2020,39(5):478-491.
[8]Shannon C E.A Mathematical Theory of Communication[J].Bell System Technical Journal,1948,27(3):379-423.
[9]侯海燕,王亚杰,梁国强,等.基于期刊学科分类的学科交叉特征识别方法——以生物医学工程领域為例[J].中国科技期刊研究,2017,28(4):350-357.
[10]Brillouin L,Hellwarth R W.Science and Information Theory[J].Physics Today,1956,9(12):39-40.
[11]Porter A L,Chubin D E.An Indicator of Cross-disciplinary Research[J].Scientometrics,1985,8(3):161-176.
[12]Stirling A.A General Framework for Analysing Diversity in Science,Technology and Society[J].Journal of the Royal Society Interface,2007,4(15):707-719.
[13]Zhang L,Rousseau R,Glnzel W.Diversity of References as an Indicator of the Interdisciplinarity of Journals:Taking Similarity Between Subject Fields Into Account[J].Journal of the Association for Information Science and Technology,2016,67(5):1257-1265.
[14]Leydesdorff L.On the Normalization and Visualization of Author Co-citation Data:Saltons Cosine Versus the Jaccard Index[J].Journal of the American Society for Information Science and Technology,2008,59(1):77-85.
[15]曾德明,于英杰,文金艳,等.基于Web of Science分类的学科交叉融合演化特征分析[J].情报学报,2020,39(8):872-884.
[16]Rafols I,Meyer M.Diversity and Network Coherence as Indicators of Interdisciplinarity:Case Studies in Bionanoscience[J].Scientometrics,2010,82(2):263-287.
[17]李长玲,纪雪梅,支岭.基于E-I指数的学科交叉程度分析——以情报学等5个学科为例[J].图书情报工作,2011,55(16):33-36.
[18]Freeman L C.Centrality in Social Networks Conceptual Clarification[J].Social Networks,1978,1(3):215-239.
[19]陈赛君,陈智高.领域交叉性分析指标与方法新探及其实证研究[J].情报学报,2013,32(11):1184-1195.
[20]李亚婷.图书情报学的学科交叉研究进展[J].情报科学,2017,35(11):156-160,171.
[21]闵超,孙建军.学科交叉研究热点聚类分析——以国内图书情报学和新闻传播学为例[J].图书情报工作,2014,58(1):109-116.
[22]李长玲,刘非凡,郭凤娇.运用重叠社群可视化软件CFinder分析学科交叉研究主题——以情报学和计算机科学为例[J].图书情报工作,2013,57(7):75-80.
[23]李长玲,郭凤娇,支岭.基于SNA的学科交叉研究主题分析——以情报学与计算机科学为例[J].情报科学,2014,32(12):61-66.
[24]李长玲,郭凤娇,魏绪秋.基于时序关键词的学科交叉研究主题分析——以情报学与计算机科学为例[J].情报资料工作,2014,(6):44-48.
[25]杜德慧,李长玲,相富钟,等.基于引文关键词的跨学科相关知识发现方法探讨[J].情报杂志,2020,39(9):189-194.
[26]Xu H,Guo T,Yue Z,et al.Interdisciplinary Topics of Information Science:A Study Based on the Terms Interdisciplinarity Index Series[J].Scientometrics,2016,106(2):583-601.
[27]Dong K,Xu H,Luo R,et al.An Integrated Method for Interdisciplinary Topic Identification and Prediction:A Case Study on Information Science and Library Science[J].Scientometrics,2018,115(2):849-868.
[28]李长玲,高峰,牌艳欣.试论跨学科潜在知识生长点及其识别方法[J/OL].科学学研究:1-14[2021-03-01].https://doi.org/10.16192/j.cnki.1003-2053.20200828.003.
[29]Chi R,Young J.The Interdisciplinary Structure of Research on Intercultural Relations:A Co-citation Network Analysis Study[J].Scientometrics,2013,96(1):147-171.
[30]商宪丽.基于多模主题网络的交叉学科知识组合模式研究——以数字图书馆为例[J].情报科学,2018,36(3):130-137,150.
[31]韩正琪,刘小平,寇晶晶.基于Rao-Stirling指数和LDA模型的领域学科交叉主题识别——以纳米科技为例[J].情报科学,2020,38(2):116-124.
[32]张斌.交叉学科主题探究:从主题聚类视角[J].情报科学,2020,38(10):49-55.
[33]Raimbault J.Exploration of an Interdisciplinary Scientific Landscape[J].Scientometrics,2019,119(2):617-641.
[34]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[35]Piepenbrink A,Nurmammadov E.Topics in the Literature of Transition Economies and Emerging Markets[J].Scientometrics,2015,102(3):2107-2130.
[36]Stirling A.On the Economics and Analysis of Diversity[J].Science Policy Research Unit(SPRU),Electronic Working Papers Series,Paper,1998,28:1-156.
[37]Rousseau R.The Repeat Rate:From Hirschman to Stirling[J].Scientometrics,2018,116(1):645-653.
[38]Leydesdorff L,Wagner C S,Bornmann L.Interdisciplinarity as Diversity in Citation Patterns Among Journals:Rao-Stirling Diversity,Relative Variety,and the Gini Coefficient[J].Journal of Informetrics,2019,13(1):255-269.
[39]Blondel V D,Guillaume J L,Lambiotte R,et al.Fast Unfolding of Communities in Large Networks[J].Journal of Statistical Mechanics:Theory and Experiment,2008,2008(10):10008.
[40]馮佳.研究前沿识别与分析方法研究[D].长春:吉林大学,2017.
[41]Mann G S,Mimno D,McCallum A.Bibliometric Impact Measures Leveraging Topic Analysis[C]//Proceedings of the 6th ACM/IEEE-CS Joint Conference on Digital Libraries,2006:65-74.
[42]Chavarro D,Tang P,Rafols I.Interdisciplinarity and Research on Local Issues:Evidence from a Developing Country[J].Research Evaluation,2014,23(3):195-209.
[43]徐庶睿,章成志,卢超.利用引文内容进行主题级学科交叉类型分析[J].图书情报工作,2017,61(23):15-24.
[44]章成志,徐庶睿,卢超.利用引文内容监测多学科交叉现象的方法与实证[J].图书情报工作,2016,60(19):108-115.
[45]Brown P F,Pietra S A D,Pietra V J D,et al.An Estimate of an Upper Bound for the Entropy of English[J].Computational Linguistics,1992,18(1):31-40.
(责任编辑:陈 媛)
