基于信息熵理论的黄土高原小流域雨量站网优化
2022-03-28丁文峰韩昊宇王协康郭宜薇王一然
丁文峰,韩昊宇,3,王协康,郭宜薇,王一然
(1.长江水利委员会 长江科学院,湖北 武汉 430010;2.水利部 山洪地质灾害防治工程技术研究中心,湖北 武汉 430010;3.长江勘测规划设计有限责任公司,湖北 武汉 430010;4.四川大学 水力学与山区河流开发保护国家重点实验室,四川 成都 610065)
准确获取降雨数据对流域水文过程模拟和水资源管理有重要意义。目前从获取流域降雨信息的技术手段看,主要有两种,一是基于地面雨量站网的降雨量监测,二是基于雷达卫星的遥感测量。遥感手段获取的网格降雨数据在捕捉降雨的时空变异性上优于传统地面雨量站网,但在使用时仍然需要地面雨量站网数据对其进行校准和评价。此外,由于其空间分辨率普遍较低,在小流域降雨数据获取方面并不理想。传统地面雨量站网不仅能直接观测点降雨量且观测精度较高,但受流域地形等多种因素的影响,地面雨量站网的布设密度和空间布局等对流域面雨量影响很大,如何科学布设地面雨量站网一直是水文气象研究领域关注的重要问题。Mishra和Coulibaly比较了多种水文站网设计方法,包括统计方法、空间插值方法、基于流域地理特征方法、用户调查方法、混合方法和基于熵的水文站网设计方法,并指出基于信息熵的雨量站网设计是最具前景的方法。Krstanovic和Singh将信息熵应用于雨量站网设计,基于最大熵准则(POME)将降雨数据进行正态化处理并计算密度函数,对路易斯安那州的地面雨量监测站网进行了评估。由于降雨等自然现象是重尾分布,假设数据为正态分布计算信息熵具有争议性。Vicente等发现边际熵与巴西北部的总降水量有很好的相关性,降雨量较高的地区,概率分布往往更均匀。但是以上研究都是在单一判别准则的基础上通过添加或减少站点的方法来实现雨量站点的优化,而水文监测站点的最佳选址是一个多目标问题。Alfonso等通过最大化多元联合熵和最小化总相关性来优化水位监测站网,结合遗传算法来逼近多目标优化。多目标优化的优点是在不同的情况下提供不同的可行解,然而,监测站网的选择与确定十分复杂,为了解决假设分布的争议,Li和Singh在计算信息熵时,使用数据离散化处理降雨数据,并提出了最大信息最小冗余准则(maximum information minimum redundancy,MIMR),将多目标问题转为单目标问题,避免了多目标优化的复杂性,又保留了通过权重获得不同可行解的优势。
根据水文站网规划技术导则,国内的雨量站网规划与优化主要采取雨量站网密度分析方法中的抽站法和流域水文模型法,精度评价时大都采用流域面雨量精度作为雨量站网规划和优化的目标函数,且多针对大中尺度流域,而针对小流域尺度地面雨量站点的监测布局缺乏相关研究。黄土高原位于中国干旱半干旱区,水资源缺乏,降雨比较集中且分布极不均匀,如何科学布设地面雨量站点,准确获取流域降雨信息不仅对水资源优化利用有重要意义,而且对流域水文循环和水文模型研究也具有重要科学意义。岔巴沟流域位于黄土高原丘陵沟壑区第一副区,多年来,由于科研生产实践的需要,流域内布设有11个雨量站,雨量站点密度远大于水文站网规划技术导则中的相关要求,为评估和优化黄土高原小流域地面雨量站网提供了研究对象。因此,以岔巴沟流域为例,基于信息熵理论,使用不同时间尺度的降雨序列评估岔巴沟流域的雨量站网的合理性,并对其进行优化,以期为今后黄土高原小流域雨量站网布设提供依据。
1 材料与方法
1.1 研究区概况与数据来源
岔巴沟是无定河的二级支流,大理河的一级支流。地处东经109°47′,北纬37°31′,属于黄土高原丘陵沟壑区的第一副区。岔巴沟流域面积205 km,海拔高度900~1 100 m。流域出口曹坪站以上集水面积187 km,属半干旱区,为温带大陆性季风气候,干燥少雨,降雨年内分配不均,大部分集中于6—9月,且多是高强度短历时暴雨。
本文选取岔巴沟流域11个雨量站点的降雨数据,站点分布如图1和表1所示。
表1 流域站点名称及位置
Tab. 1 Name and location of rainfall stations
序号 站名 北纬/(°) 东经/(°) 高程/m 1 和民墕 37.767 109.800 1 212 2 刘家坬 37.767 109.850 1 129 3 朱家阳湾 37.733 109.850 1 080 4 马虎墕 37.750 109.917 1 097 5 杜家山 37.733 109.950 1 072 6 万家墕 37.683 109.883 1 105 7 王家墕 37.700 109.883 1 112 8 姬家岺 37.717 109.967 1 049 9 牛薛沟 37.667 109.933 1 057 10 桃园山 37.700 110.000 1 048 11 曹坪 37.650 109.983 1 006

图1 研究区域及雨量站位置Fig. 1 Research area and the location of rainfall stations
研究时间为2001—2010年中每年5—10月,该数据来自于《黄河流域水文年鉴》。由于汛期降水为该流域降水量的主要来源,本文使用汛期降雨量来代替年降雨量。
1.2 研究方法
Shannon在1984年提出了信息熵理论,基于概率计算得到了随机变量的不确定性程度,即随机变量包含的信息量,从而解决了对信息的量化问题。在水文气象、水文和水资源中,常用的基本信息度量指标包括边缘信息熵、条件信息熵、联合信息熵、互信息和冗余信息熵。本研究基于这些指标首先对岔巴沟流域11个雨量站点间的信息进行信息熵计算,分析他们之间信息的相互关系和信息传递规律等,然后根据信息阈值及统计学方法进行站网的优化布局。
1)边缘信息熵
假设某一随机变量X
的n
个可能取值x
(i
=1,2,3,···,n
)发生概率为p
,p
,p
,···,p
,边缘信息熵定义为:
k
为任意正常数,取k
=1;底数b
取不同值时信息熵的量纲不同,当b
=2时,其量纲为bit(比特,即Binary Digit),当b
=e(自然对数底)时,其量纲为nat(纳特,Natural Digit),当b
=10时,其量纲为dit(迪特,Decimal Digit),本文中b
取2。边缘信息熵描述了随机变量X
的离散程度和不确定性程度,其离散程度越高相应的不确定性越大。2)联合信息熵
对于多维随机变量,联合信息熵被定义为随机变量保留的总体信息的度量。以2维随机变量(X
,Y
)为例,其联合信息熵的计算公式为:
p
(x
,y
) 为2维随机变量(X
,Y
)的联合分布概率。在两个随机变量上进行延伸,可得多维随机变量所保留的总体信息。多维联合信息熵定义为:

3)互信息
2维随机变量(X
,Y
),由Y
(X
)推导出X
(Y
)的信息,定义为:
T
(X
,Y
)为2维随机变量(X
,Y
)间的互信息。将式(4)展开化简可得:
由式(5)可知,互信息描述了2个随机变量之间共有的信息量,其值的大小反应了随机变量之间的相关性大小。它优于皮尔逊相关系数,因为它捕获了线性和非线性依赖关系,而皮尔逊相关系数仅适用于线性关系。
4)总相关
总相关描述多维随机变量之间的信息冗余,即度量随机变量之间的重复信息量。总相关的定义为:
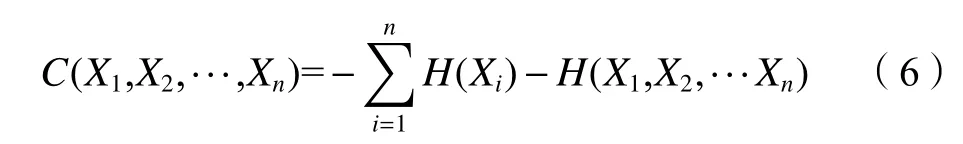
C
(X
, X
,···,X
)为随机变量X
, X
,···,X
间的重复信息量。1.3 数据处理方法
熵的定义中包含了概率分布,因此计算概率分布成为信息熵计算的关键。概率分布估计方法主要分为两类:1)基于概率分布函数(probability distribution function,pdf)的拟合及其参数估算;2)非参数密度估计。对于pdf估计中,正态分布作为典型分布得到了广泛的应用。然而,自然界中流量、降雨等自然现象都是重尾分布,分布选择的不合适,概率分布的计算就会不准确,在非参数密度估计中则避免了这一误差。非参数估计方法主要包括直方图法、数学地板函数法。由于在水文站网设计下的信息熵计算,不需要精确量化的信息保留状态,只要能在信息内容上保持站点之间的相对关系,这个近似估计就是合理的。因此,本研究采用数学地板函数法对数据进行离散化,其表达式为:式中,x
为随机变量X
的原始取值,X
为数据序列的离散值,a
为可调整的因子,「·」表示取整函数。该方法是与a
相关的舍入法,a
的大小与随机变量的种类不同而变化。例如:对径流数据进行离散化时,a
=150;对降雨、水位和流量数据进行离散化时,a
通常可取1、3或5;在本文中,取a
=3。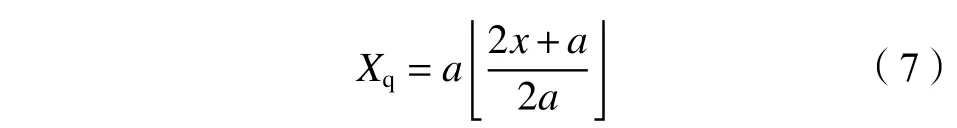
X
=[1,2,1,2,1,3,3],X
=[1,2,2,2,1,3,2],融合得到新的变量X
=〈X
,X
〉 = [11,22,12,22,11,33,32],其中〈·〉表示变量融合。将X
中的可能取值的不同值按大小排列并取排列后取值对应的位置索引代替X
中的可能取值,得到新的X
=[1,3,2,3,1,3,4]。利用式(1)和(2)进行验证,可知H
(X
)=H
(X
,X
),即合并前后的信息量保持不变。多维离散型随机变量的联合信息熵表示为:

总相关可用式(6)计算,也可以利用变量分组性质和变量合并来进行计算,其公式为:

T
(〈X
,X
,···,X
〉,〈X
X
,···,X
〉)。1.4 雨量站网络优化算法
Li为解决水文站网优化问题提出了最大信息最小冗余MIMR算法,使用该算法,可对水文网络站点的重要性进行排序,使得所选站点集有最大化整体信息、最大信息转移能力和最小化冗余信息。
假设共有N
个站点,S
表示已选入最优网络的k
个站点,F
表示待选的m
个站点,k
+m
=N
,则优化算法的信息熵公式表示为:
为了规避多目标优化的复杂性,方便计算站点的重要性,将多目标问题转为单目标问题:

式中,λλ为权重,两者之和为1。
为了解决雨量站网优化问题,Li等推广了MIMR算法。首先,设置联合信息熵的阈值,计算各站点的边缘信息熵,选择边缘信息熵最大的站点为中心站点;再使用MIMR算法对站点进行排序,当达到阈值时,得到水文网络站点的优化最终决策。用公式表示为:
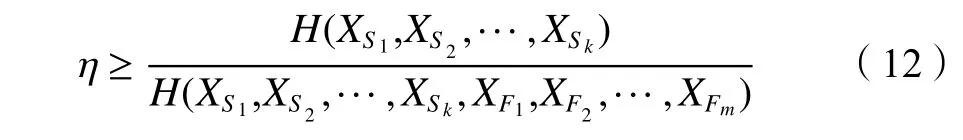
式中,η为阈值,当η≥95%时,即得到了水文站网的优化最终决策。
1.5 统计方法
使用泰森多边形计算11个雨量站的流域年均降雨量作为参考数据,评估雨量站网优化设计的可靠性。采用了3种统计指标,相关系数r
、相对偏差RBS、纳西效率系数NS。
x
为11个雨量站的流域年降雨量;x
为雨量站网络优化后的流域年降雨量;n
为研究期间时段总数,取值为2001, 2002,···, 2010;i
表示第i
个时段;x
和x
分别表示优化前和优化后的降雨年平均值。2 结果分析
2.1 岔巴沟流域降雨量时空变化分析
根据2001—2010年岔巴沟流域实测降雨资料,采用泰森多边形方法计算流域多年降雨量和流域汛期的多年平均月降雨量,年降雨量和汛期各月降雨量,见图2。从图2(a)可以看出,流域近10 a降雨量无明显变化趋势,其中,2009年降雨量最大(545 mm),2008年降雨量最小(355 mm)。月平均降雨量如图2(b)所示,流域多年汛期月平均降雨量分别为42.40、58.70、89.30、145.24、92.80、33.40 mm,其中,8月降雨量最大,5月和10月降雨量较小,7、8、9这3个月占汛期总降雨量的71%。

图2 流域年降雨量及汛期月平均降雨量Fig. 2 Annual rainfall and flood season month average rainfall
根据11个雨量站的实测降雨资料,统计2001—2010年流域平均年降雨量空间分布。采用样条函数法进行空间插值计算岔巴沟流域降雨量的空间变化见图3。从图3可以看出:岔巴沟流域西南部海拔较高,处于西南部的王家墕、和民墕降雨较多;东北部海拔较低,处于东北部的杜家山、姬家岺降雨较少。总的来说,流域汛期多年平均降雨量呈现西南到东北递减趋势。
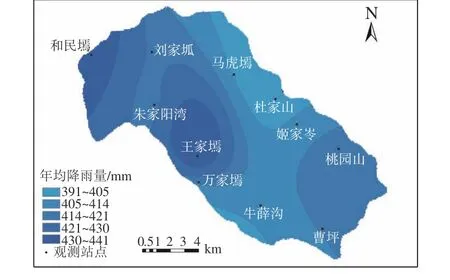
图3 年平均降雨量空间分布Fig. 3 Spatial distribution of average annual rainfall
对岔巴沟2001—2010年降雨资料进行统计,得到各雨量站暴雨场次及年均暴雨量(表2)。从表2可以看出:万家墕、王家墕、牛薛沟3个站点监测到11场暴雨;马虎墕监测到的暴雨场次最少(8场),且年均暴雨量较少,为79.3 mm;其他各站点年均暴雨量无明显差异,岔巴沟流域内暴雨分布较均匀。
表2 2001—2010年暴雨场次及年均暴雨量
Tab. 2 Number of rainstorm events and average annual rainfall from 2001 to 2010
序列 站名 暴雨场次 年平均暴雨量/mm 1 和民墕 10 88.26 2 刘家坬 10 90.00 3 朱家阳湾 9 85.77 4 马虎墕 8 79.30 5 杜家山 10 85.61 6 万家墕 11 89.05 7 王家墕 11 88.27 8 姬家岺 9 87.11 9 牛薛沟 11 90.32 10 桃园山 9 88.90 11 曹坪 10 88.34
2.2 岔巴沟流域降雨信息熵
为了计算不同时间尺度下的岔巴沟流域雨量站网信息熵,使用不同时间间隔对日降雨量进行采样,分别得到日、周、15 d时间尺度的降雨序列。
根据式(11)可知,权重λ、λ对流域雨量站网信息熵有重要影响。对权重λ、λ进行敏感性分析,发现权重λ在0.5到1.0变化(λ从0.5到0变化)时,雨量站网始终保持信息的稳定,因此本研究中取λ=0.8,λ=0.2。对连续的降雨序列使用式(7)进行离散化处理后,使用MIMR准则,联合信息熵、互信息和总相关为雨量站的选取提供依据(表3)。日、周、15 d时间尺度的降雨序列,中心站点分别为站点7、站点1、站点10。由年降雨量分布图3中可知,站点7、1、10的年均降雨量都较大,MIMR准则会选择年均降雨量较大的站点为中心站点。
表3 不同时间尺度降雨序列联合信息熵、互信息和总相关迭代计算
Tab. 3 Joint Entropy , Transinformation , and Total Correlation of rainfall 1-day,weekly and 15 days series
日时间尺度 周时间尺度 15 d时间尺度迭代步骤站点 H T C 站点 H T C 站点 H T C 1 7 1.39 1.07 0 1 3.86 3.84 0 10 4.74 4.73 0 2 10 2.29 1.91 0.46 7 5.84 5.66 1.85 1 6.43 6.43 2.97 3 1 2.86 2.32 1.24 11 6.58 6.30 4.88 4 6.75 6.75 7.24 4 3 3.11 2.51 2.32 10 6.88 6.54 8.36 11 6.83 6.83 11.89 5 11 3.32 2.55 3.44 3 7.08 6.64 12.02 9 6.87 6.87 16.55 6 4 3.42 2.54 4.68 5 7.16 6.63 15.69 5 6.87 6.87 21.14 7 9 3.51 2.41 5.94 6 7.21 6.45 19.43 3 6.89 6.82 25.79 8 5 3.54 2.25 7.22 4 7.21 6.18 23.20 7 6.89 6.73 30.49 9 6 3.60 1.94 8.52 9 7.21 5.45 27.00 6 6.89 6.30 35.18 10 2 3.65 1.32 9.83 8 7.22 3.82 30.77 8 6.89 4.68 39.79 11 83.69— — 27.23— — 26.89— —
通过式(3)、(5)和(6)计算得出,不同时间尺度降雨序列的H
、T
、C
随着迭代次数的变化,如图4所示。图4反映了H
、T
、C
随着迭代次数的变化,联合熵随站点增多逐渐变大,并逐渐趋向稳定,即总体信息量趋向稳定。不同时间尺度的联合熵达到稳定的迭代次数不同,日尺度在9次,周尺度在7次,月尺度在5次,时间尺度越大,稳定得越快。互信息先随站点增多而增大,在联合熵达到稳定后有减小的趋势,说明联合熵稳定后,站点之间的信息传递越来越少,站点之间的冗余信息越来越多。
图4 不同时间尺度各站点降雨序列的联合熵H、互信息T、总相关C随迭代次数变化趋势Fig. 4 Variation of each station rainfall sequence Joint Entropy H, Transinformation T, and Total Correlation C under different time scales
通过式(12)计算得出各站点联合信息熵的阈值,见图5。不同时间尺度的雨量站网雨量信息在迭代一定次数后,趋势稳定。日时间尺度的雨量站点排序为7、10、1、3、11、4、9、5、6、2、8;在迭代8次之后,阈值达到了95.8%,即8个站点的雨量信息即可反映流域95.8%的雨量信息,这8个站可作为优化后的雨量站网。周时间尺度的站点排序为1、7、11、10、3、5、6、4、9、8、2;在迭代5次后,阈值达到95.1%,即5个站点的雨量信息即可反映流域95.1%的雨量信息,这5个站可作为优化后的雨量站网。15 d时间尺度的站点排序为10、1、4、11、9、5、3、7、6、8、2,在迭代3次后,阈值达到97.9%,即3个站点的雨量信息即可反映流域97.9%的雨量信息,这3个站可作为优化后的雨量站网。结合联合熵、互信息、冗余信息的计算进行分析,在用周、15 d时间尺度对降雨量进行采样后,降雨量出现重复信息较多的现象,使得冗余信息出现了较大增长。在计算阈值时,较大的时间尺度会在迭代次数较少的时候出现稳定的状态,但通过站点排序,不同时间尺度中,站点8、2一直排在最后两位。8号站点可能是因为其地理位置离站点5、10较近;站点1的在日时间尺度、周时间尺度中都是中心站点,在15 d时间尺度中是位于第2位;站点2位于末位的原因可能是其携带的信息与站点1有大量的重复信息。

图5 3种采样间隔的阈值计算Fig. 5 Threshold calculation in three sampling intervals
2.3 岔巴沟流域雨量站点布局优化
根据日、周和15 d时间尺度降雨序列边缘熵、联合信息熵、互信息计算结果,对岔巴沟流域的雨量站网进行优化。日时间尺度降雨量站网的数量为8个,分别为1、7、11、10、3、5、6、4号站点,阈值达到了95.8%;周时间尺度降雨量站网的数量为5个,分别为1、5、6、7、11号站点,阈值达到了95.1%;15 d时间尺度降雨量站网的数量为3个,分别为1、5、11号站点,阈值达到了97.9%。通过MIMR准则,保留了降雨量较大的站点,站点1和民墕站以及流域出口站点11曹坪站;保留了降雨量较小的站点,站点5杜家山。优化后的雨量站网增大了这些站点的流域控制面积,另外,结合暴雨统计,也同时保留了监测暴雨场次较多的站点。
通过泰森多边形法计算了流域雨量站点优化前后的流域雨量(表4),利用式(13)~(15),计算了3个时间尺度下流域站点优化前后降雨量间的相关系数r
、相对偏差(RBS)、纳西效率系数(NS)3个统计参数,见表5。总体来看,统计结果说明优化后雨量站网计算的流域平均降雨量与实测值间存在较好相关性。表4 雨量站网优化前后流域年均降雨量
Tab. 4 Average annual rainfall in catchment before and after rainfall networks optimized
优化后年降雨量(15 d)/mm 2001 456.93 455.30 464.60 469.71 2002 395.24 394.71 399.12 394.11 2003 423.91 431.21 433.10 428.35 2004 357.88 365.23 351.97 347.85 2005 354.74 354.36 340.67 318.45 2006 503.55 501.89 509.03 500.99 2007 482.81 481.13 501.67 491.02 2008 331.84 324.38 322.85 293.46 2009 516.79 504.93 521.94 500.70 2010 350.57 350.93 352.25 372.41年份优化前年降雨量/mm优化后年降雨量(日)/mm优化后年降雨量(周)/mm
表5 不同时间尺度下流域站点优化前后降雨量间的3个统计参数
Tab. 5 Three statistical variables before and after rainfall networks optimized under the different time scales
时间尺度 r RBS/% NS日0.99 0.88 0.86周0.24 0.55 1.37 15 d 0.99 0.98 0.93
为评估地面雨量站网优化前后流域降雨量的空间变异情况,根据优化前后地面雨量站点的平均日、周、15 d时间尺度的雨量信息,利用克里金插值方法,生成了流域日、周、15 d时间尺度的流域降雨量空间分布图(图6)。从图6中可以看出,优化前后日时间尺度流域降雨量空间分布状况基本一致,说明优化后的地面雨量站可以反映日时间尺度的降雨空间分异状况。而对于周和15 d时间尺度而言,随时间尺度的增大,流域降雨量的空间分布在优化前后变化较大,特别是15 d时间尺度,优化前后流域降雨量空间分布发生了明显改变,说明优化后的地面雨量站雨量信息并不能反映流域降雨量的空间分布。这主要是由于优化前地面雨量站点本就分布不均匀,经优化后,强化了这种雨量站点的空间不均匀性所致。
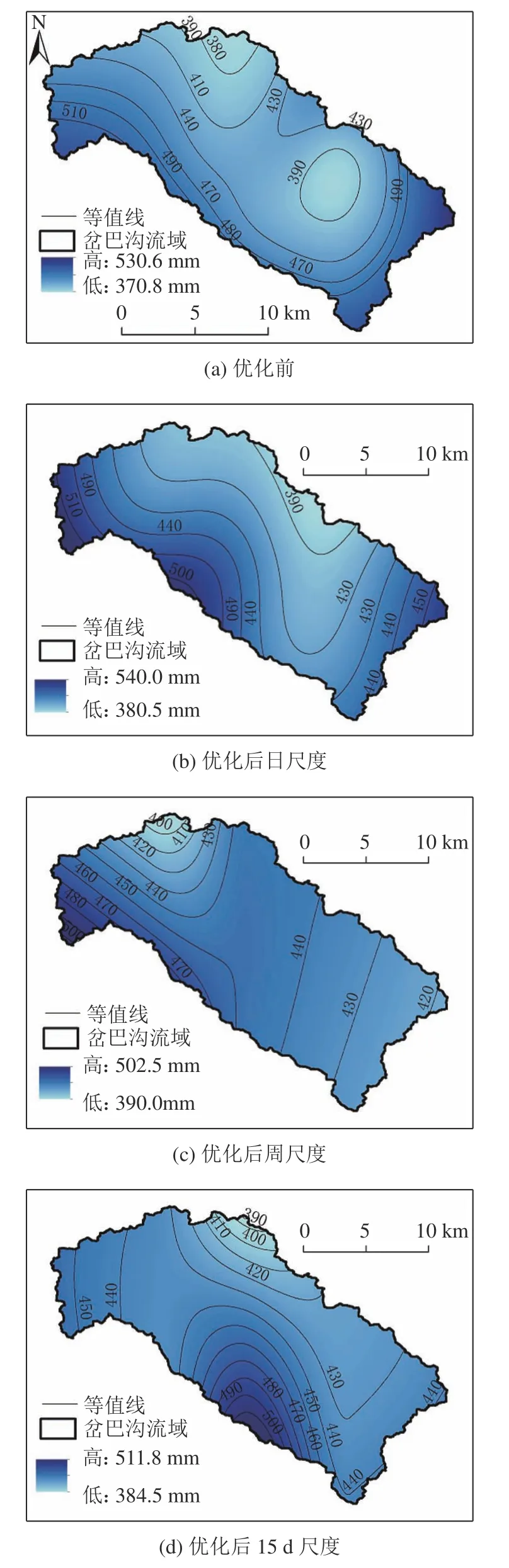
图6 雨量站网优化前后不同时间尺度流域降雨量空间分布Fig. 6 Rainfall spatial distribution of different time scales before and after rainfall networks optimized in catchment
3 结 论
基于信息熵理论和MIMR准则,通过联合熵阈值计算,使用不同时间尺度的降雨序列对岔巴沟流域11个雨量站点组成的站网体系进行了评价和优化,结论如下:
1)不同时间尺度降雨序列的总体信息量随站点增多趋向稳定;互信息先增大后减小,站点之间的信息传递越来越少;站点之间的冗余信息随站点增加一直增大,站点之间的重复信息越来越多。另外,时间尺度越大,联合熵稳定的越快,冗余信息越多。
2) 3个时间尺度雨量站点优化前后的流域面均雨量变化不大,但在反映流域降雨量空间分布上,优化前后日时间尺度流域降雨量空间分布状况基本一致,而对于周和15 d时间尺度而言,随时间尺度的增大,流域降雨量的空间分布在优化前后变化较大,优化后的地面雨量站雨量信息并不能反映流域降雨量的空间分布。
3)以日、周和15 d时间尺度的流域雨量站网降雨序列信息熵值为优化雨量站网的依据,确定了不同时间尺度岔巴沟流域雨量站网最佳数量和分布,结果表明优化后的流域雨量站网能较好的反映流域降雨信息。
