拉曼光谱结合机器学习识别肥皂
2022-03-24侯赛文李春宇孔维刚刘金坤屈音璇
侯赛文,李春宇,孔维刚,刘金坤,屈音璇
(1.中国人民公安大学 侦查学院,北京 100038;2.郑州市公安局刑事科学技术研究所,河南 郑州 450000)
肥皂是脂肪酸金属盐的总称[1],是生活中常见的洗涤用品,肥皂中会添加发泡剂、抗氧化剂等,用以改善去污性能[2]。拉曼光谱仪测量时所需样品含量少,不破坏样品,且检验速度快[3],帮助现场勘查人员进行肥皂微量物证检验。
为了研究快速分类肥皂品类的方法,本文引入机器学习方法进行肥皂类别的分类[4]。通过系统聚类的方法对于不同品类的肥皂进行分类,得到5类肥皂,对比三种监督学习的方法的识别准确率,为识别不同种类肥皂找到可行性方法。
1 实验部分
1.1 材料与仪器
不同厂家、不同品牌的肥皂56个样本,按照功能,分为洗涤皂、沐浴皂、药皂、多功能皂。
InVia Raman Microscop激光拉曼光谱仪[5],有5X、20X、50X、100X 四个显微镜镜头,波段激光器具有532,633,785 nm三个激发波段,光谱扫描的范围100~3 200 cm-1,最低波数为10 cm-1,分辨率为1 cm-1。
1.2 实验方法
使用镊子从肥皂样品取一些碎屑,放到干净载玻片上,启动激光拉曼光谱仪。为了减小仪器和环境因素的误差,对肥皂样品通过调整位置,在50X倍率、10%的功率、785 nm波段的条件下,对不同位置测量3次,进行光谱数据收集。
1.3 光谱处理
在实验过程中,由于仪器自身噪声带来的影响,以及宇宙射线的影响,肥皂样品的自身特性,以及实验过程中环境温度、压力的影响,对于得到的拉曼光谱图像(图1)需要进行拉曼光谱预处理,消除误差,得到合理谱图。本文采用拉曼光谱基线校正、归一化处理、高斯滤波的方法,进行原始拉曼光谱图的处理[6-7],得到正常的拉曼谱图(图2)。

图1 原始谱图

图2 预处理谱图
2 结果与讨论
2.1 系统聚类分类
采用系统聚类的方法对预处理的光谱数据进行处理。选择z得分的方法进行数据标准化处理,聚类方法采用组间联接法,数据类型区间选择的是平方欧式距离[8-13],得到图3的聚类树状谱系图。
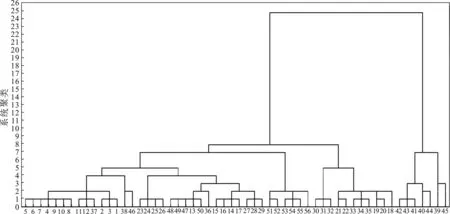
图3 聚类谱系图
通过考察谱系图的距离和细密程度,得到在距离为1的时候分类为23类,类别最多,而由于类别过多,分类效果不是很好[14]。在距离为10~25之间的时候,可以分为2类,类别过少,对于研究肥皂分类的实际应用情况意义不大。在距离为5时,可以分为5类,较为适宜。系统聚类结果见表1。

表1 系统聚类结果
选择距离为5,进行类别分类,作出标签类别见图4。
由图4a得到5种类别的香皂的特征峰。56号在241,530 cm-1;44号在380,959 cm-1;39号在542,1 702 cm-1;20号在150,707 cm-1;11号在 1 416,1 591 cm-1。由于香皂成分比较复杂,不同配方中的香皂因添加的物质不同,影响肥皂中的硬脂酸钠的峰位置,特征峰发生偏移,可以分析出所属不同类别的肥皂。通过观察56种肥皂的种类和功能后,在1类肥皂中,以洗衣皂为主,在2类肥皂中,以沐浴皂为主,在3类肥皂中以药皂为主,4类肥皂为妙晨牌洗衣皂和上海润肤皂,在5类肥皂中以内衣皂为主。图4b、c、d为3种不同类别的肥皂的特征峰比对,可知不同种类间特征峰差异较大,可以归为不同类;同种类间特征峰和峰型一致,可以归为一类。
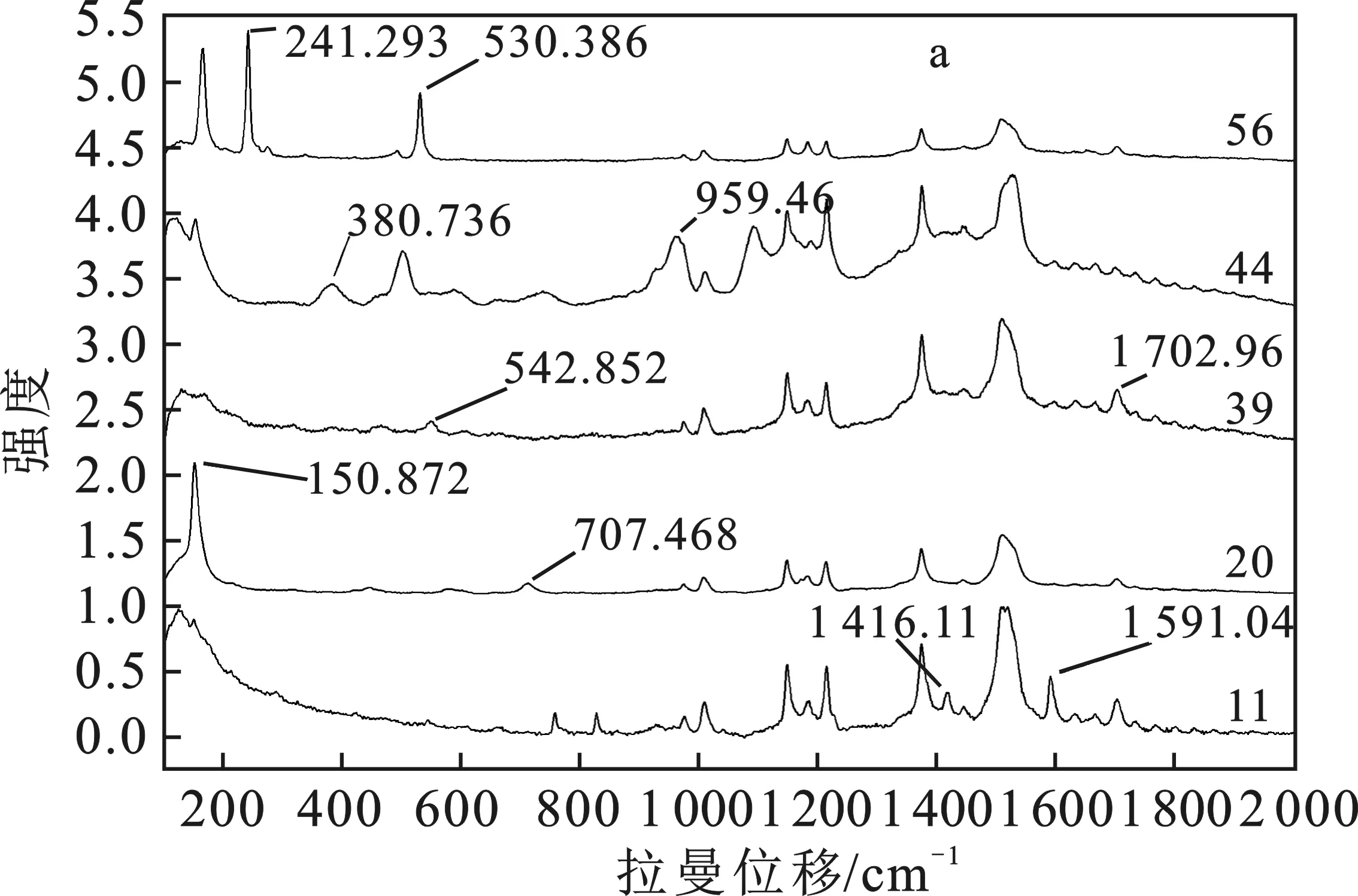
图4 香皂拉曼特征峰比对
2.2 肥皂类别识别
当对肥皂进行类别分类后,但系统聚类不能对于归类样本进行识别,选用三种机器学习方法对于不同类别的肥皂进行识别[15-18]。
2.2.1 朴素贝叶斯分析 朴素贝叶斯将预测给定的未知类别的数据样本X归为具有最大后验概率的类,将X分类到Ci类,此时,P(Ci|X)>P(Cj|X)1≤j≤m,j≠i; 其中P(Ci|X)最大的类为最大后验假定,为了把样本X分类,通过Ci相应的P(X|Ci)P(Ci)进行估算,P(X|Ci)P(Ci)>P(X|Cj)P(Cj)1≤j≤m,j≠i。而影响朴素贝叶斯的算法的准确度与选择的核相关[15],通过选择三角、埃帕内奇尼科夫、盒、高斯的核,探究对于样本识别率的影响,结果见图5。

图5 不同核朴素贝叶斯识别率
由图5可知,核采用高斯的朴素贝叶斯的识别率最高,为92.9%,核采用盒的识别率最低,为50%。通过考察朴素贝叶斯的核采用高斯的混淆图,认识朴素贝叶斯算法对于识别肥皂识别率的影响,结果见图6。

图6 高斯朴素贝叶斯混淆矩阵
由表2可知,样品识别错误的个数相同时对于不同类别的影响不一样,类别中样本越多,识别预测错误影响率越低;同时核朴素贝叶斯对于标签为3的类别率效果最好。

表2 不同标签识别率
2.2.2 支持向量机(SVM)分析 对于SVM的分类效果好坏与选择SVM的核函数具有很密切的联系[16],本文选择多项式核函数作为SVM分类核函数,可以有效分类不同标签的肥皂。SVM多项式核函数为:κ(x,xi)=((x·xi)+1)d,其中,d为阶数,阶数不同时对分类的识别率有影响。本文通过d=1,2,3时得到了对于肥皂分类的影响(表3),d=1时,SVM核也被称为线性SVM核。

表3 不同分类识别率
由表3可知,核函数为多项式时,多项式的阶数不同时,SVM对于标签为1的肥皂的识别率为100%,而对于标签为5的肥皂识别错误率和准确度相同,其中对于标签为2的肥皂类别的识别出错的个数最多,分别为3、4、3。
由图7可知,d=3时,准确率最高,为91.1%;d=2的准确率最低,为87.5%,不同阶数的准确率不同,与阶数大小没有联系。通过综合分析,d=3时,SVM的识别率效果最好。
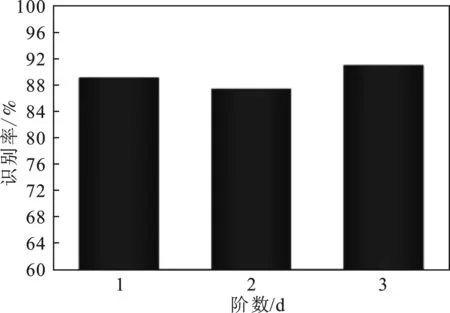
图7 不同阶数SVM识别率
2.2.3 K最近邻(KNN) 影响KNN算法对于模识别的因素一般有K值的大小、分类器中距离度量的影响以及实验数据结构的特异性[17]。其中K值大小的影响比较显著。当K值较小时,分类的结果比较复杂,容易出现过度拟合的后果;当K值过大时,使得分类简单,出现错误的识别概率较大。不同K值对于肥皂识别效果的影响见图8。
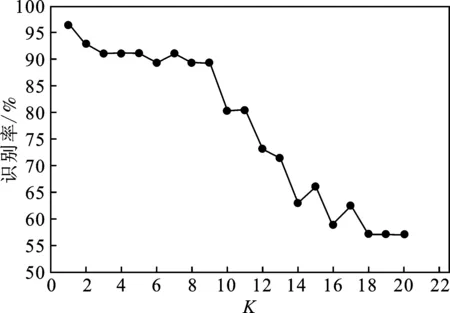
图8 不同K值KNN识别率
由图8可知,随着K值的增大,识别的准确度逐渐下降,其中,在K>9以后,识别的准确度有明显的下降趋势,到K≥18以后有变缓和的趋势。本文通过选用K=1时,距离度量为Euclidean,距离权重为等距离,分析其对于肥皂样品的识别影响,结果见图9和表4。
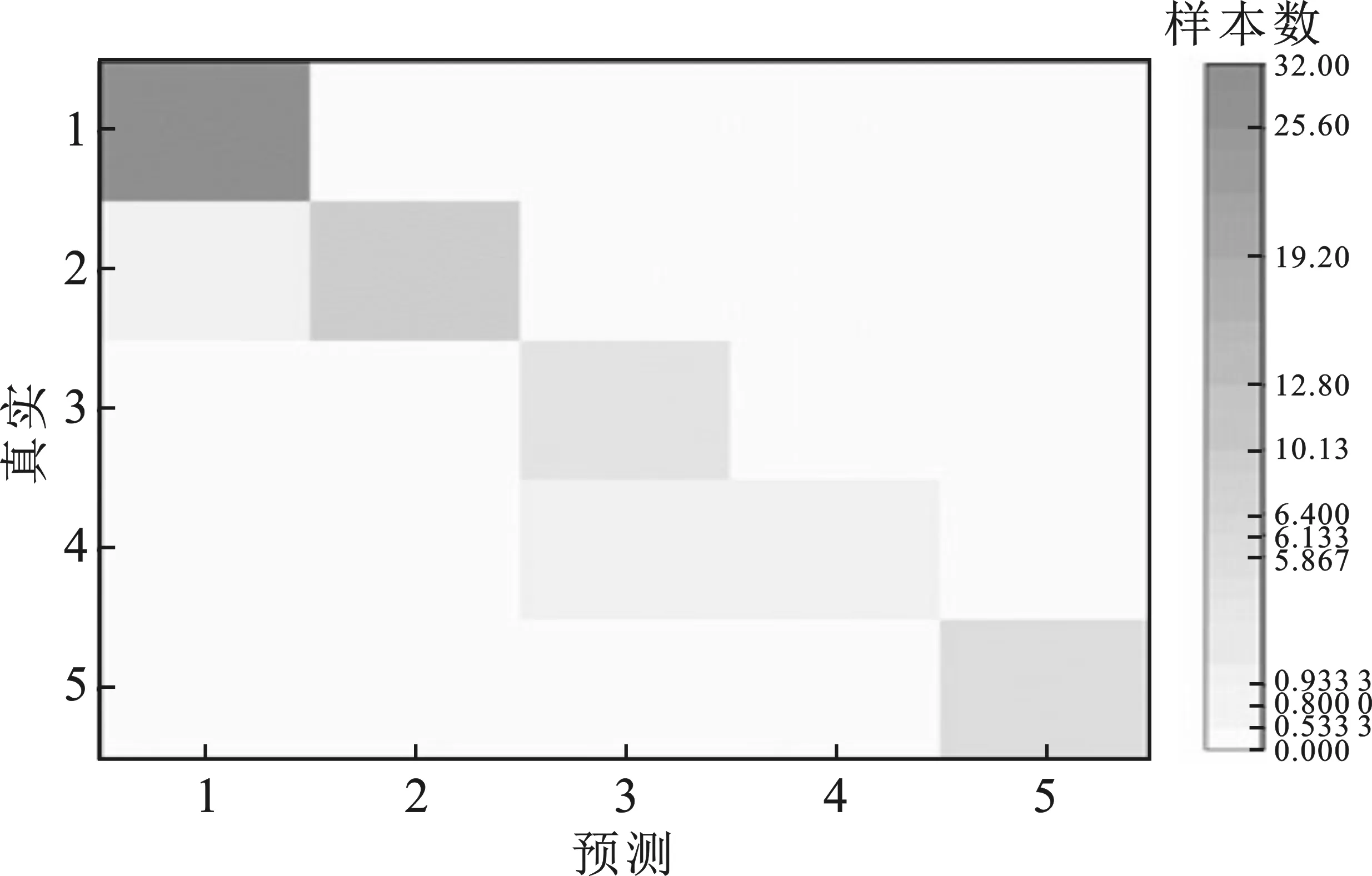
图9 K=1,KNN混淆矩阵

表4 K=1,不同分类识别率
由表4可知,K=1的KNN算法在识别分类肥皂中,总共有两个样本识别错误,2号标签里的11个样本中有一个识别成1号标签;4号标签的2个样本中有一个识别为3号标签。此时,KNN算法的识别率为96.4%。
通过本次实验,得到的机器学习算法对于肥皂识别的方法,比传统的案件过程中对于肥皂的识别通过人工筛查和液相色谱的分析的方法简单和省时,为案件侦查提供了新的物证检验的方法[19]。但是本文中存在数据量少以及准确度的问题,可以通过更多样本数据的收集,进行数据库的建立,建立更加自动化的识别的模型,和便携式拉曼光谱联用[20-21],达到帮助案件现场物证快速检测和民警处理违禁物品检查的目标。
3 结论
通过拉曼光谱谱图并结合系统聚类、朴素贝叶斯、SVM、KNN的方法,对于肥皂样本的识别建立了分析方法,首先通过系统聚类对于不同品牌和不同功能的肥皂数据进行分类,得到5类肥皂的类别,再通过调整朴素贝叶斯、SVM、KNN的算法,通过调整参数,分别找到各个算法下对于肥皂类别的分类准确度的最优的方法,再通过不同算法间的最优模型准确度的比较,得到了K=1时,KNN的模型对于肥皂的识别效果最好,识别率达到96.4%。
