水质氨氮的测定能力验证结果统计和评价分析
2022-03-24张春艳
黄 欢,张 哲,张春艳
(华测检测认证集团股份有限公司,标准物质研究中心,广东 深圳 518000)
能力验证(proficiency testing,PT)作为检验机构检测能力评估的外部手段,既可以保证检验机构测试数据的可比性和有效性,又可以甄别不同检验机构间存在的差异、了解其在行业内的检测水平。统计评价是能力验证计划的重要环节,不同的统计方法和评价方式,最终得到的实验室能力评定结果也会存在差异。而统计方法和评价方式主要由能力验证目的、数据分布情况、离群比例、测试方法特性、经验参考值等因素决定的。因此,如何根据实际情况选择合适的结果统计方法和评价方式是能力验证计划成功的关键。
目前国内的能力验证计划主要参照GB/T 28043-2019进行统计和评价,涉及到的主要统计方法有经典统计方法、稳健统计方法(迭代算法A、四分位法、Q方法/Hampel估计量)、经验模型法(Horwitz函数)、自助法等[1-5]。经典统计方法、稳健统计方法(迭代算法A、四分位法)要求统计的数据先要符合(或近似符合)正态分布,如果数据服从(近似服从)正态分布,为避免离群值干扰,经典统计方法用格拉布斯(Grubbs)准则等统计方法剔除离群值后计算指定值和能力评定标准差,而迭代算法A和四分位法一般具有不错的稳健性(效率和崩溃点),离群值对总体结果偏离影响权重较小,无需先剔除离群值[1]。Q方法/Hampel估计量、经验模型法(Horwitz函数)、自助法对于数据的正态分布情况没有要求,可适用于一些特殊或者数据非正态分布的情况。实验室测试结果计算得到的指定值和标准差通常采用Z或Z’比分数进行能力评定,根据|Z|或|Z’|的大小来判断结果的满意情况。也有一些能力验证采用百分相对差来评价结果,依据百分相对差是否在测试方法的最大允许误差来判断结果的满意情况。
本文把2020年华测检测认证集团股份有限公司标物中心组织的水质氨氮的测定能力验证(GZSCJ-2020-03)作为实例,比较了环境检验领域能力验证常用的统计方法及其统计学特点,探究了水质氨氮的测定能力验证结果评价方式,为环境监测领域的能力验证计划设计、实施、统计分析和结果评价等提供依据,同时促进实验室建设与质量管理能力、环境领域检测水平的提升。
1 能力验证设计与实施
本次能力验证(GZSCJ-2020-03)依据ISO/IEC 17043:2010[6]中的一般要求进行方案设计。承办方向每个参加实验室发放2个样品:A样和B样。发样前均已进行样品均匀性和稳定性检验,样品均匀性和稳定性均符合要求[7]。为保证测试方法的一致性,参加实验室被要求使用HJ 535-2009[8]或GB/T 5750.5-2006[9](9.1方法)进行样品测试。本次计划共有120家实验室参加,最终所有实验室均反馈测试结果。
2 统计分析
2.1 测试结果正态分布检验
为了解水质氨氮测试结果的正态分布情况,作出了A、B样测试结果核密度图(图1、图2)。根据图1、图2可知,Q-Q图均不呈直线,故可认为A、B样测试数据不符合正态分布。同时,由图1、2中核密度曲线可以看出,A、B样核密度曲线均成近似对称分布,分别在0.990 mg/L和2.50 mg/L附近各有一个明显主峰,在主峰两侧有少许不明显的小峰,由此可认为A、B样测试结果都是近似服从正态分布的[10]。因此,本次能力验证测试结果可使用经典统计或稳健统计等方法进行统计分析。

图1 A样结果核密度图Fig.1 Kernel density plot of determined resultsfor sample A
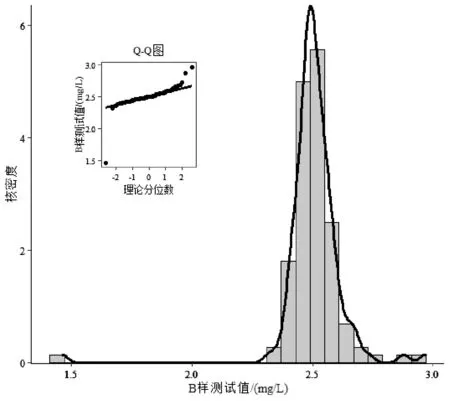
图2 B样结果核密度图Fig.2 Kernel density plot of determined resultsfor sample B
2.2 经典统计方法
经典统计方法通常对测试数据直接计算平均值和标准差,以平均值和标准差作为指定值和能力评定标准差。但由于测试常受到人员、方法、仪器等因素的影响,造成测试数据中存在一定比例的偏离数据主体的结果,需采用格拉布斯(Grubbs)准则等统计方法剔除离群值后再计算平均值和标准差。表1为测试数据采用经典统计方法统计分析得到的结果。由于数据整体比较集中且近似服从正态分布,剔除离群值前后结果均值差异不大,但结果标准差明显变小。
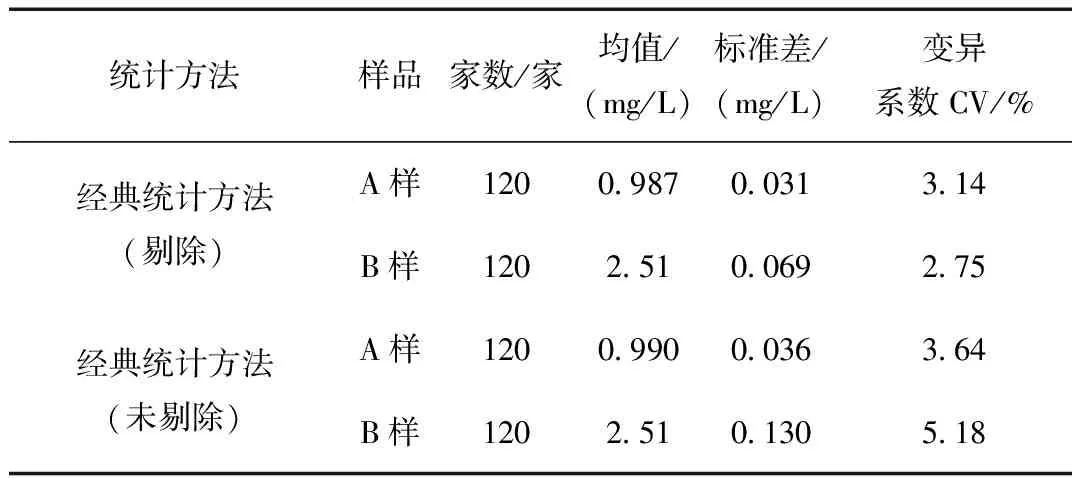
表1 经典统计方法计算结果Table 1 Calculations of classical statistics
2.3 稳健统计方法
2.3.1 四分位法
四分位法是将中位值和标准化四分位距(nIQR)作为数据总体均值和标准差的稳健估计的统计方法。对一组由小到大排列的数据,居于中间位置的数据为中位值,居于下四分之一位置的数据为低四分位数(Q1),居于上四分之一位置的数据为高四分位数(Q3),nIQR等于四分位距(IQR,Q3-Q1)乘以0.7413(标准差校正因子)。四分位法只使用总体数据中段50%的数据,崩溃点为25%,易于操作和计算,因此在许多能力验证中得到应用。此外,四分位法的计算是假设数据服从正态分布的基础上进行的,若数据不服从正态分布,则计算结果可能存在偏差[11]。表2为四分位法计算结果。

表2 四分位法计算结果Table 2 Statistical results of quartile method
2.3.2 迭代算法A
迭代算法A主要依靠winsorisation缩尾法进行原始数据转换,以中位值和nIQR作为初始值,通过不断迭代使其逐渐收敛而得到总体均值和标准差的估计,崩溃点为25%。在多次迭代过程中,离群值被逐步替换,降低了离群值的权重系统,同时充分利用了数据信息,提升了统计量的效率和耐抗性[12]。该方法对于有拖峰或少数小峰的近似正态分布数据仍有不错的效果。具体计算过程可参考GB/T 28043-2019计算公式,再利用EXCEL软件实现计算。迭代算法A计算结果可参见表3。

表3 迭代算法A计算结果Table 3 Statistical results of robust algorithm A
2.3.3 Q方法/Hampel估计量
Q方法是使用基于数据集成对差计算的估计量Q或Qn作为数据总体标准差的估计值的算法。其具有较高的效率和崩溃点,当预期离群值比例大于20%或存在多峰分布时,使用Qn算法或Q算法估计标准差十分有效[11]。Qn算法可适用于每个参加实验室的单一结果(包括重复测试的均值和中位值),而Q算法可适用于每个参加实验室的单一结果(包括重复测试的均值和中位值)和重复测试结果[1]。Hampel估计是不同参加者测试结果均值的高效估计,基于测试数据和标准差(Q、Qn)计算得来。Qn/Hampel法的统计结果可使用R语言编程计算得到,Q/Hampel法可通过Q/Hampel方法网络应用程序来实现统计量的计算[13]。Q方法/Hampel估计量计算结果可参见表4。从统计结果来看,B样数据采用三种稳健方法得到的CV值基本一致,但A样数据使用四分位法算得的CV值较Q方法/Hampel估计量算法和迭代算法A有一定偏离。从图1中可以看出,A样Q-Q图的线性较差,数据正态分布性差,因而四分位法算得的CV值较Q方法/Hampel估计量算法和迭代算法A存在偏离。而Q-Q图的线性更好的B样数据,其四分位法算得的CV值与另外两种稳健方法基本一致。

表4 Q方法/Hampel估计量计算结果Table 4 Statistical results of Q/Hampel method
2.4 经验模型法(Horwitz函数)
Horwitz函数描述了测试浓度与再现性标准差之间的关系,是一种经过大量数据验证的经验模型。能力验证中常用的经验模型法,即是将测试数据的中位值带入到Horwitz函数中,计算出测试方法的再现性标准差作为总体标准差,而中位值作为总体均值[14]。经验模型法可以根据GB/T 28043-2019相关计算公式进行计算。经验模型法计算结果可参见表5,经验模型法计算的结果标准差高于经典方法和稳健方法。经典方法和稳健方法主要是通过测试数据来估计标准差,计算结果会受到样品特性、测试方法和测试水平等因素的影响,而经验模型法作为一种经验方法,总体标准差主要由测试结果的中位值代入经验公式进行估算。根据文献报道,一些测试数据表明测试结果的中位值与标准差不一定服从Horwitz函数[15-16]。因此,经验模型法和其他统计分析方法的计算结果是可能存在差异的。

表5 经验模型法计算结果Table 5 Calculations of empirical model method
2.5 自助法
自助法一种再抽样的过程,通过对原始数据有放回抽取n次,作为一个样本,再重复抽样R次,得到R个样本。计算样本均值抽样分布的均值和标准差作为测试结果的指定值和评定标准差[5,17]。自助法对于数据的正态分布情况没有要求,可适用于一些数据非正态分布的情况,而计算过程可以通过R语言编程来实现。表6为测试数据采用自助法统计分析得到的结果,其与经典统计方法(未剔除)的结果基本一致。
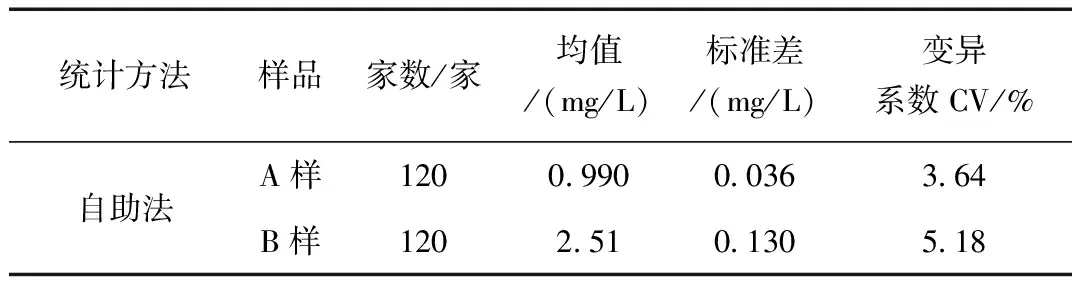
表6 自助法计算结果Table 6 Statistical results of Bootstrap method
3 结果评价
3.1 Z比分数评定实验室能力
本次能力验证计算结果指定值的不确定度(upt)均小于0.3倍的能力评定标准差(0.3σpt),无需使用Z’值进行能力评价[1]。同时,指定测试方法中无相关测试误差的要求,故本计划也未使用百分相对差来评价结果。而Z比分数作为能力验证中一种经典的能力评定方式,可用于经典统计方法、稳健统计方法、经验模型法(Horwitz函数)、自助法等统计方式的结果评价。Z比分数按公式(1)计算:
(1)
式中:x为实验室测试结果;X为指定值;σ为能力评定标准差。|Z|≤2.0为满意结果,2.0<|Z|<3.0为可疑结果, |Z|≥3.0为离群结果。由于能力验证发双考核样,故只有当两个样品结果均满意时才能评价实验室考核结果为满意。如表7所示,不同统计方法得到结果统计量使用Z比分数进行评价。在本机构近四年组织的水质氨氮的测定能力验证项目中,样品浓度范围为0.5~3.0 mg/L,结果满意率在83.0~89.2%左右。本次计划中经典统计方法(未剔除)、自助法和经验模型法(Horwitz函数)法的总体满意率均超过94%,表明这三种方法放宽评判范围,可能造成取伪的情况。而四分位法的CV值最小,相应的总满意率也低于80%,可能出现弃真的情况。迭代算法A和Q方法/Hampel估计量算法的CV值接近,且总满意率较为合适。此外,HJ 535-2009[8]中精密度测试数据显示 1.21 mg/L和1.47 mg/L标准样品测得的实验室间相对标准偏差分别为2.0%和1.4%,因此采用稳健统计方法计算的CV值是可以接受的。由于数据离群值比例低于20%,且计算容易实现,本研究最终选择了迭代算法A作为本次能力验证的统计分析方法[1]。

表7 不同统计方法Z比分数能力评定结果Table 7 Evaluation results of robust statistical Z-score for diverse statistical methods
3.2 分割水平样品的Z比分数
当采用分割水平样品(样品对)的形式来考核实验室能力时,根据每个实验的测试数据(XA和XB)计算出样品对Z比分数,即实验室内Z比分数(ZW)和实验室间Z比分数(ZB),来评价实验室的测试水平[1,18]。首先,样品对(A/B样)的标准化和为XS,标准化差为XD,按公式(2)、(3)计算:
(2)
(3)
再由每一个参加实验室的XS和XD,分别算得XS的中位值Med(XS)和标准四分位数间距nIQR(XS)、XD的中位值Med(XD)和标准四分位数间距nIQR(XD)。最后,按公式(4)、(5)计算ZB和ZW:
ZB=(XS-Med(XS))/nIQR(XS)
(4)
ZW=(XD-Med(XD))/nIQR(XD)
(5)
常规的Z比分数只能表示测试结果与指定值之间的偏离情况,不能区分实验室内差异和实验室间差异,也无法说明造成结果差异的原因(室间系统误差或室内随机误差)。而对于样品对Z比分数,ZB的正负和大小代表实验室的XS与Med(XS)的偏离方向和程度,它反映了实验室检测结果的系统误差;ZW的正负和大小代表实验室的XD与Med(XD)的偏离方向和程度,它反映了实验室检测结果的随机误差。因此,样品对Z比分数可以用于评价结果与指定值的偏离情况,也能解释数据的离散和异常情况。
本计划按CNAS-GL002[18]要求,只有当|ZB|≤2且|ZW|≤2时,实验室结果才判定为满意。对A、B样品数据的XS和XD统计结果评估见表8,ZB为可疑结果(2<|ZB|<3)的有2家(实验室代码为001、112),不满意结果(|ZB|≥3)的有3家(实验室代码为045、098、102);ZW为可疑结果(2<|ZW|<3)的有9家(实验室代码为001、003、035、047、050、059、072、078、094),不满意结果(|ZW|≥3)的有8家(实验室代码为025、028、046、079、098、101、102、112)。最终结果满意率为85%,这与迭代算法A结果采用单一样品Z比分数判定得到的总满意率一致。

表8 样品对Z比分数评价结果Table 8 Evaluation results of sample pairs Z-score
本研究对采用单一样品Z比分数评价的结果和样品对Z比分数进行比较。结果发现,当采用单一样品Z比分数进行评价时,代码为001、025、035、047、072、078的6家实验室结果均为满意(双样品),但其ZW比分数结果表明这些实验室的室内重复性可能存在问题。因此,在能力验证中使用分割水平样品,对于实验室潜在问题的分析具有积极的作用。
4 结 论
不同的统计分析方法,因其假设条件和计算原理的不同,数据计算结果可能存在差异。能力验证组织者需根据实际条件、数据分布情况、方法特性、经验值和能力验证目标等因素,选择最合适的统计方法。本研究中测试数据近似服从正态分布,且离群值比例低于20%,因此使用计算易于实现的迭代算法A进行计算,统计结果采用单一样品Z比分数进行能力评定。
使用分割水平样品进行能力验证,既可以评价结果与指定值的偏离情况,也能解释数据的离散和异常情况。本研究尝试采用样品对Z比分数评价的结果和单一样品Z比分数进行比较。结果表明普通Z比分数判定满意的部分实验室,样品对Z比分数认为其室内重复性可能存在问题。样品对Z比分数对数据不同维度的分析,有利于实验室潜在问题的发掘。
