基于深度学习的 高中学生课堂坐姿识别研究
2022-03-24李柏翰衣俊峰李欣蔚王支勇魏艳涛
李柏翰 衣俊峰 李欣蔚 王支勇 魏艳涛



摘要:随着人工智能技术在教育领域的不断交叉融合,校园信息化和网络化逐渐由数字化转向智能化。通过机器自动识别学生的课堂行为活动可帮助教师高效精准地获取学生课堂状态,并进行科学分析。近年来,高中生由长期不良坐姿导致的脊柱侧弯和近视比例不断攀升,对青少年的身体健康产生巨大的威胁。本文通过深度学习技术对深圳某高中采集的225名学生的9种正确及不良坐姿的图片数据进行处理和模型训练,分别使用Densenet和Xception网络获得7种坐姿80%以上的准确率,并将其用于学生课堂状态识别,有效助力学生课堂坐姿的提醒。
关键词:深度学习;智慧校园;计算机视觉;行为识别
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2022)06-0000-04
● 引言
课堂行为识别是教学领域的重要基本活动,在人工智能教育的应用中,计算机视觉与课堂场景相结合对于智慧校园的信息化和网络化建设具有较大应用价值。该技术的应用一方面可以改善传统课堂和录播系统需要消耗教师大量精力进行观察的问题,减轻评课负担,有利于教师教学方法和教学策略的改进和调整,另一方面也便于学生对自己课上行为和学习状态有更深入的了解并及時反思,有效提高中小学课堂的教学质量水平。[1-3]
据统计,截至2019年3月,深圳市高中阶段青少年脊柱侧弯比例高达5%,近视比例为82%,而且有不断升高趋势。脊柱侧弯和近视多由坐姿不良导致,因此,针对处于生长发育关键时期的高中生每天维持长达8~11个小时的久坐的现象,采集常见课堂学生姿态数据,利用深度学习相关算法对高中生的坐姿进行有效区分,实现对坐姿的监控识别具有非常重要的现实意义,此技术的应用可为有效避免学生坐姿不良而导致的骨骼和视力问题提供有力的支持。
● 数据采集和标注
1.数据采集
根据学生常见的正确及不良坐姿,以及颈椎、腰椎及腿部等不同形态的组合,将坐姿做如下几种形态分类:①正面写作业坐直。②手撑着头向一边斜(不分左右)。③驼背(正面)。④驼背(侧面)。⑤跷二郎腿(侧面)。⑥跷二郎腿(正面)。⑦正面坐直。⑧玩手机。⑨向一侧趴着(不分左右)。因教室桌椅排布有部分遮挡,本文最终采用单个人摆拍的方式进行数据采集。同时,为了避免背景对识别效果的影响,场景选择背景单一的教学楼墙壁前光线强弱明暗度一致的时刻进行拍摄,目的是使采集的数据有相同的外部条件。
经过筛选共采集了深圳某高中高一年级225名学生的9类行为共计2025张坐姿图片,将采集的图片分类后进行数据预处理,使用旋转、放大、剪切、空间颜色变化等方式对训练集进行增强处理,按照1∶9的比例生成最终图片,数据增强后,训练集约有18225张图片,图片格式为JPG。
2.数据标注
使用Labellmg软件对图片进行标注,对相应图片里的目标学生进行图框标记,便于后续算法模型的学习。所标范围应尽可能包含有效数据,避免噪音数据对于结果的影响,图片的存储格式为xml。
● 模型算法
1.YOLO_v3检测算法
用于目标检测算法常用的有两种:①Faster-CNN算法。该算法分为特征学习和分类两部分,运算速度较慢,但是结果准确率较高。②基于YOLO框架的目标检测算法。该算法采用全自动端到端的方式实现,速度快精度高,使用范围较为广泛。本文采用YOLO_v3版本进行实验。
YOLO目标检测算法是通过卷积神经网络将图像进行网格划分特征提取,图像被分割成S×S个不同区域,针对网格中心落在具体的位置预测边界框、置信度和类别。该算法包含53个卷积层,可以提取深层次的图像特征,并使用不同尺寸预选框的Anchors boxes机制采集相同网格的特征,根据预测边框与真实值的交并结合置信度选取预选框采集图像特征。根据具体的应用场景选取合适的数据集、合理的网格分布和参数训练策略。笔者就网络中的核心部分做进一步概述。
①IOU:IOU的值用来衡量两个边界框之间重叠部分的相对大小,假如有两个边界框,它们重叠部分的大小除以它们总面积的值就是其IOU的大小。IOU的值越大,该预测边界的准确度就越高,一般以0.5作为其阈值。
②Bounding box:Bounding box用来帮助机器判断一个网格单元中是否含有待检测的物体。它包含5个值:X、Y、W、H和置信度。Bounding box的中心坐标用X和Y表示,W和H的乘积表示预测边框的大小,置信度值则表示预测的box和正确的标注数据的IOU值,也就是该预测的准确度,一般选择有最大置信度值的Bounding box来预测这个物体。
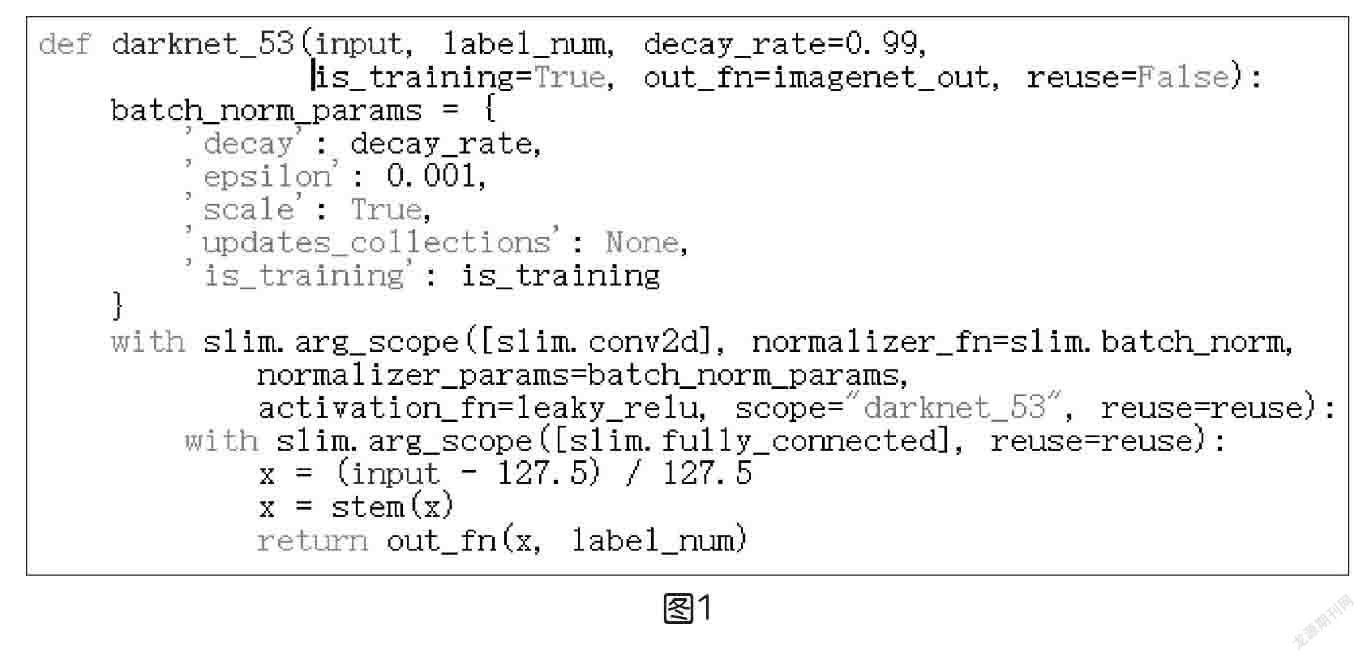
③实现YOLO_v3算法的核心方式是将图像用三种大小不同的网格进行划分(分别是13*13,26*26,52*52),然后对输入图像的特征进行提取,得到其feature map。例如52*52,就是将图像划分成52*52个网格单元。每个单元网格里都有多个Bounding box,假如某个网格单元里拥有正确的标注数据中某个物体的坐标,那么该网格单元就会起到预测这个物体的作用。[4]实验所用YOLO程序部分代码如图1所示。
2.分类算法的选择
本研究使用迁移学习对数据进行分类训练,选用Densenet和Xception网络分别测试,通过修改学习率(learning rate)和batch_size探讨主要参数对识别性能、运行时间的影响。
(1)Densenet算法
Densenet与Resnet的思路较为类似,Resnet在传统的卷积层间增加了旁路连接,梯度流经恒等函数到达更前层。而Densenet的区别是该网络前后层连接的密集程度比较高,前面全部层的输出都作为后续层的输入,即dense block的设计,每一层输出的feature map都小于100。这种连接方式使梯度和特征的传递效率大大提高,参数的数量也在一定程度上更加轻量化。另外,因为层数较多使层与层之间的关联性减弱,Densenet将每一层的损失与输入直接连接起来,从而缓解了梯度消失的现象。[5]
(2)Xception算法
Xception是Google继Inception后提出的对Inception_v3的另一种改进版本,后者的核心思想是通过多尺寸的卷积核对输入数据进行卷积运算,卷积核的排布是1×1的卷积核连接多层并列的3×3卷积核运算,此运算方式可以大大降低卷积运算的计算量。而Xception在Inception的基础上采用了depthwise separable convolution运算模式,即将一个卷积层分裂为两个关联的卷积运算,第一个卷积层的filter与输入的channel进行映射卷积,第二个卷积层则只负责对前面的结果进行合并,此种模式计算量根据乘法原理使运行效率大大提高。[6]
● 实验与结果分析
1.实验环境
深度学习的模型训练量较大,需要高性能的专门处理图像数据的GPU服务器作为支撑,本文所需的实验环境如表1所示。
2.实验结果分析
本文使用不同的深度学习算法对数据进行模型计算,采用控制变量法对参数进行不同的设置,对比不同的参数和算法模型所得出准确率、运算时间等输出量优劣。
①分别测试不同算法模型的下的学习率和batch_size的最佳值。
首先在batch_size=16时,分别运行出Xception和Densenet在学习率为0.00001,0.0001,0.001,0.005时的准确率,实验结果如图2所示。
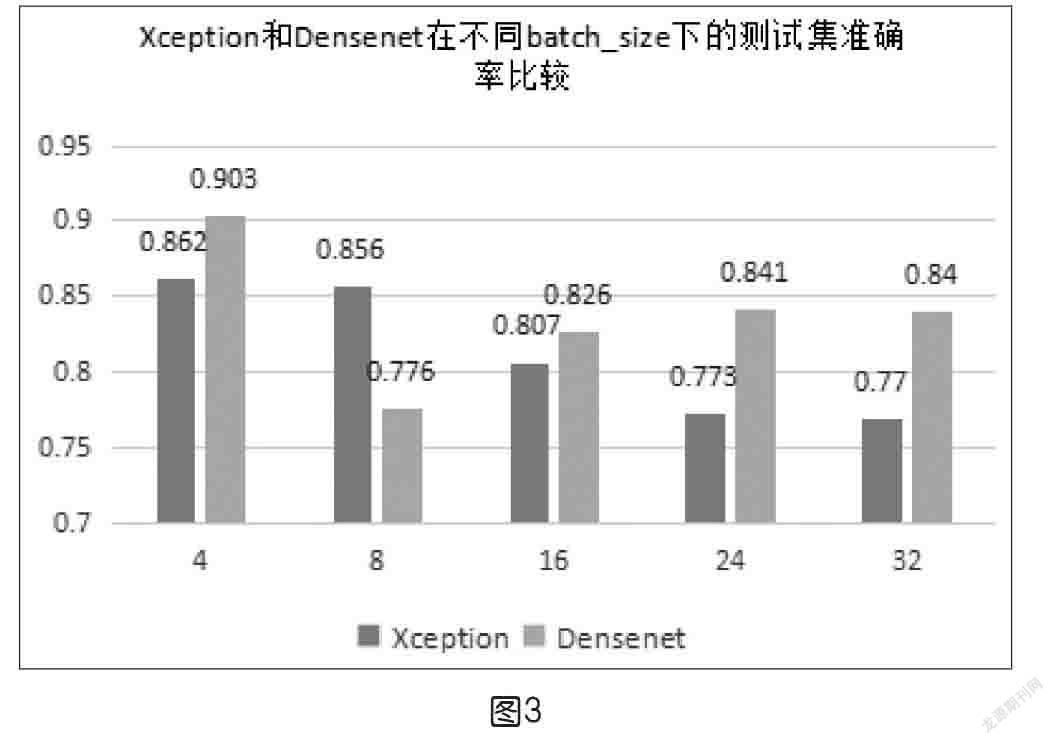
由此可知,在学习率为0.0001时,算法的准确率较高,因此笔者在学习率(learning rate)=0.0001时分别进行了batch_size=4,8,16,24, 32的实验,实验结果如图4所示。
由图3可知,随着batch_size数值的不断增加,算法的准确率也随之下降,从准确率的角度来看,在batch_size=4时有最高的准确率,但是训练时间比较长(如表2)。所以从训练时间长短和准确率综合来看,batch_size=16更占优势。
根据上述数据分析可得:在学习率=0.00001,0.001,0.005,batch_size=16时,xception的准确率都高于Densenet的对应值,但在学习率=0.0001,batch_size=4,16,24,32时,Densenet的准确率高于Xception。因为选取的参数为Learing rate=0.0001,batch_size=16,在这种参数下Densenet的准确率更优,所以笔者最终选择了Densenet网络。
②不同坐姿在不同学习率和batch_size下各自的准确率。
由于各个动作姿势和角度的不同,不同的坐姿在相同的参数下会有不同的准确率,为了更好地掌握各个坐姿识别准确率的反馈状况,还要进行细化不同坐姿的学习率测试,根据前面的数据,将batch_size设定为16。
根据实验结果,在学习率=0.0001,batch_size=16时,“写作业驼背”的准确率为66.7%,“侧面翘二郎腿”的准确率为56%,其余动作的识别均能达到80%及以上的准确率,满足后期进行数据融合的前期要求。
③数据融合后的图片的效果检测。
通过融合算法将YOLO_v3和Xception、Densenet分别进行功能整合,即YOLO算法识别学生在图片中不同坐姿的位置,并将其进行标注,Xception和Densenet對识别的坐姿进行分类,从而判断坐姿所属的种类,Xception模型融合的效果,及具体的坐姿会标注在图框的左上角,实时反馈图片的分类结果。
● 结论与展望
本文主要运用深度学习技术识别课堂上学生的不良坐姿。其中,对坐正、用手撑着头向一边倾斜、驼背(分正侧面)、趴向一侧写作业、跷二郎腿(分正侧面)以及玩手机等9个动作进行识别和分类,使用融合算法将YOLO_v3和Xception、Densenet分别进行关联,从而达到7个种类的测试集80%的识别效果。实验不足之处:①数据样本量采集渠道单一,可以拍摄更多种类图片进行训练,结合视频动态图像进行课堂行为分析,进一步增加数据的覆盖范围及准确率。②算法模型上采用迁移学习的策略,算法可以进行更多尝试和调试。
对学生在课堂上导致脊柱侧弯和近视的不良坐姿的发现,早期预防能够更好地纠正与治疗,希望基于深度学习技术的应用及时地对坐姿不良的学生进行干预。还可以结合课堂监控、手环及手机APP对学生的课堂状态进行观察、数据收集和分析全方位预防脊柱侧弯、近视等疾病的蔓延。
参考文献:
[1]秦道影.基于深度学习的学生课堂行为识别[D].武汉:华中师范大学,2019.
[2]何秀玲,杨凡,陈增照,等.基于人体骨架和深度学习的学生课堂行为识别[J].现代教育技术,2020,30(11):8.
[3]刘新运,叶时平,张登辉.改进的多目标回归学生课堂行为检测方法[J].计算机工程与设计,2020,41(09):6.
[4]Redmon J,Divvala S,Girshick R,et al.You Only Look Once:Unified,Real-Time Object Detection[C].Computer Vision & Pattern Recognition. IEEE,2016.
[5]Huang G,Liu Z,Laurens V,et al.Densely Connected Convolutional Networks[J].IEEE Computer Society,2016.
[6]William Byers.Deep Learning:What Mathematics Can Teach Us About the Mind [M].Singapore:World Scientific,2014.
本文是广东省教育技术中心2020年度教育信息化应用融合创新青年课题(课题立项号:20JX07037)的研究成果。
