基于安全洗牌和差分隐私的联邦学习模型安全防护方法
2022-03-23刘文龙刘圣龙江伊雯
粟 勇 刘文龙 刘圣龙 江伊雯
1(南瑞集团有限公司(国网电力科学研究院有限公司) 南京 211100)2(江苏瑞中数据股份有限公司 南京 211100)3(国家电网有限公司大数据中心 北京 110000) (284666776@qq.com)
2016年谷歌提出的联邦学习(federated learning)是一种新兴的人工智能基础技术,其出发点是希望能够在解决大数据交叉流通中的数据安全和隐私保护问题的同时,高效地展开多节点多终端沟通参与的机器学习.在联邦学习模型中,采用分布式的概念,多个客户端都存放数据,并在本地对数据进行分析运算,最终将各自的运算结果上传到共享的集成模型中.参与到联邦学习模型中的多个客户端地位相同,共同为模型工作并共享成果.经过实验证明,分布式的联邦学习模型所取得的成效与以往将各类数据整合到一起进行集中运算的结果并无太大出入,分布式的结构使得联邦学习模型具有不需要昂贵的加密硬件、平台开源等优点.在解决隐私保护问题上,将加密机制融合到联邦学习框架中,这种创新的分布式计算在合法合规的基础上,能够更有效地保护涉密数据,保证信息不被泄露,相比于简单的数据脱敏更加安全可靠.
联邦学习的优势也来源于其独特的特征[1].首先,联邦学习基于分布式计算架构,各方的数据保存在本地,这样既不会泄露隐私也不会违反法规.其次,集成模型是公开共享的,每个联邦学习参与方都可以按照各自的需求实现各自的使用目的.联邦学习的建模效果类似于传统的深度学习,联邦就意味着数据联盟,不同的参与方都有各自的带有其目的性的运算框架.目前联邦学习虽然解决了各个参与方的训练样本等数据隐私问题,但现有的相关差分隐私保护技术的使用主要关注模型训练过程中样本隐私和参数隐私,不能解决联邦学习模型发布本地使用的模型安全隐私,同时如何安全发布原始的联邦学习模型,以及保证用户对模型的效用也是一个重要的技术难点.
本文针对现有技术的不足,提出一种基于安全洗牌和差分隐私的联邦学习模型安全防护方法,该方法能够保护联邦学习模型拥有者的隐私、保证用户获得的联邦模型的效用.
1 相关理论知识
1.1 联邦学习隐私保护
联邦学习系统解决了部分数据孤岛问题,但其本身还存在很多薄弱点和脆弱性.在联邦学习中,交换数据需要进行多轮通信,在通信过程中通信信道的不安全会带来很大的安全隐患;由于对数据的交换过程中会有多方参与,联邦学习的客户端鱼龙混杂,可能会有第三方利用模型参数和训练数据实施攻击;虽然聚合算法对部分异常数据进行识别并剔除,但参与联邦学习的开发者们可能难以分辨哪些是隐私数据,哪些不是.在联邦学习中,每个客户端都能够接触到模型参数以及训练数据,这些数据很可能遭到一些恶意客户端篡改或将权重发送给服务器,从而影响全局模型.
常见联邦学习的隐私威胁包括:
1) 成员推断攻击(membership inference attacks)[2].推断攻击是一种推断训练数据细节的方法,通过检查训练数据集中是否存在特定的数据来获取信息.
2) 无意的数据泄露与通过推理重构(unintentional data leakage & reconstruction through inference)[3].恶意的客户端可以通过全局模型来重构其他客户端的训练数据.
提高联邦学习隐私保护能力的方法包括:
1) 差分隐私(differential privacy)[4].对样本添加噪声,并尽量使总体样本的统计性质(均值、方差等)保持不变.
2) 安全多方计算(secure multi-party computation)[5].多方联合计算一个函数,且各方都不泄露各自的数据.
3) 验证网络(verifynet)[6].验证服务器端是否可靠.
差分隐私技术在数据采集或发布前对数据进行扰动处理,即在数据集中添加噪声,使数据变得不清晰,从而隐藏真实数据.对于具有一定相关背景知识,通过比对和猜测数据库查询结果得到隐私信息的差分攻击行为,差分隐私技术具有显著的防护效果.差分隐私包括本地差分隐私(LDP)和集中式差分隐私(CDP)2类,主要工作包括RAPPOR[7]、PROCHLO(ESA 的实现)[8]、混洗放大[9]、ARA[10]等.
1.2 洗牌算法
洗牌算法是一种用来解决需要和洗牌一样产生随机场景的问题的算法[11].目的是产生一串等概率的随机列,使得很难去预测牌的顺序,洗牌算法是常见的随机问题,在玩游戏,随机排序时经常用到.安全洗牌算法则是在洗牌过程中加入加密过程,使得在洗牌过程中得到的置乱矩阵是经过混沌加密后得到的加密矩阵.
洗牌之后,如果能够保证每一个数出现在所有位置上的概率是相等的,保证得到最终的带噪声的联邦学习模型参数置乱密文,密文无法直接对其进行获取并破解,从而对用户发布原始联邦学习数据模型起到加密保护的作用.
效用(utility)可以描述为通过特定查询或查询集从数据中获得真实信息的程度.在联邦学习中,每个客户端都能够接触到模型参数以及训练数据,一个可行的好的差分隐私算法的基本特征是保持效用和隐私之间的适当平衡,目前已有的工作都没有考虑联邦学习在效用与隐私之间的最佳平衡.本文提出一种基于安全洗牌和差分稳私的联邦学习模型安全防护方法.
2 联邦学习模型安全防护方法SFLSDP
2.1 SFLSDP安全防护方法
本文基于安全洗牌和差分隐私技术提出了一种新型的联邦学习模型安全防护方法SFLSDP,能保护联邦学习模型拥有者的隐私,保证用户获得的联邦模型的效用.该方法的工作流程如图1所示:

图1 SFLSDP流程
2.2 SFLSDP流程
SFLSDP主要步骤有3个,分别为基于差分隐私的噪声生成、安全洗牌加密和安全洗牌解密.
2.2.1 基于差分隐私的噪声生成
联邦模型拥有者利用差分隐私对联邦学习的模型参数进行加噪声,生成带噪声的模型参数.各参数说明如表1所示.

(1)
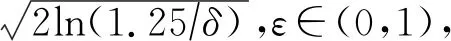

表1 参数说明

图2 安全洗牌加密流程
2.2.2 安全洗牌加密
安全洗牌加密过程中,该模型利用用户授权密钥和安全洗牌算法加密模型参数,并将加密的联邦学习模型参数发送给用户,如图2所示.

2) 初始化逻辑映射控制参数s=4,d=0.9,f=0.9,g=0.1,并初始迭代映射i=200,给定密钥key={x,y},其中x和y是混沌映射的2个初始值.
3) 以密钥key为初始值,通过迭代映射m×n+i对混沌序列值,舍弃i对值,得到m×n对的混沌序列值,并将其分别存储于大小为m×n的1维数组P和Q中,如式(2):
(2)
4) 对P和Q中的元素运行如下的安全洗牌算法运算,得到2个整数值的1维矩阵P′和Q′:
算法1.安全洗牌算法.
输入:数组A[n];
输出:数组B[n].
① 初始化数组B[n];
② fori=0 ton-1
③ 随机选取1个元素A[s],s的值在0到数组A索引最大值之间;
④ 将B[n-1-i]=A[s],同时将A[s]从数组A中删除,A中s下标后的元素依次往前移动,更新A的实际数组大小;
⑤ end for
⑥ 返回数组B.
5) 通过对P′和Q′进行排序,生成2个长度为m×n的1维伪随机序列矩阵P″和Q″,其元素取值为[0,m×n-1]内不等的整数.
6) 对于1维伪随机序列P″和Q″中的各元素P″[k]和Q″[k]进行变换,将其映射为大小为m×n的2维置乱矩阵X,Y,其中,x(i,j),y(i,j)分别为2维置乱矩阵X,Y的元素.
7) 利用置乱矩阵X先对矩阵AΠ进行置乱,得到临时模型参数置乱中间结果,再用Y对临时模型参数置乱中间结果进行位置置乱,得到最终带噪声的联邦学习模型参数置乱密文.
2.2.3 安全洗牌解密
用户在本地使用联邦学习模型时,利用用户授权密钥和安全洗牌算法解密模型参数密文,得到带噪声的联邦学习模型,如图3所示.用户将自己的数据作为带噪声的联邦学习模型的输入,得到期望的输出结果.

图3 安全洗牌解密流程
用户收到带噪声的联邦学习模型参数置乱密文和密钥key={x,y}后,需要执行联邦学习模型拥有者的逆运算操作;使用该模型对自己的数据进行处理.具体过程如下:
1) 给定与联邦学习模型拥有者加密过程相同的密钥key={x,y},与加密过程相同,由密钥x,y生成置乱矩阵X,Y;
2) 利用置乱矩阵Y先对带噪声的联邦学习模型参数置乱密文进行置乱,得到临时模型参数置乱中间结果,再用X对临时模型参数置乱中间结果进行位置置乱,得到可以使用的带噪声的参数模型.
3 SFLSDP算法安全性分析
3.1 差分隐私保护能力分析
由于在原数据集中利用差分隐私加入了噪声,所以公布的数据集是不准确的,具体不准确的程度要看加入多少噪声.但是这并不影响对数据集进行统计分析,还是可以统计分析出数据集的总体趋势信息,得到数据集有价值的规律.差分隐私实际上也正是隐私保护程度和数据效用之间的权衡.

P[M(D)∈s]≤eεP[M(D′)∈s]+δ,
(3)
其中,M(D)=f(D)+Y.高斯机制的定义比拉普拉斯噪声复杂,主要原因有3个参数:ε表示隐私预算.高斯分布的标准差δ表示松弛项,决定噪声的尺度,和噪声成负相关,δ设置为多少就表示只能容忍多少的概率违反严格差分隐私.高斯机制对数据集中的敏感信息添加噪声后进行转化,σ作为符合特定高斯分布的噪声,需要在隐私保护过程中对隐私和准确性进行权衡.SFLSDP中给出用于模糊每个敏感样本的办法,将高斯噪声添加到这些样本中,通过调整参数σ和s来达到平衡隐私保护、敏感度和预测精度的要求.大量实验表明,隐私预算和效用成正比,和隐私保护成反比,即尽可能少量地隐私预算才能更好地提升隐私保护能力.
在差分隐私中,数据隐私化的工作转移到每个参与方,采用的扰动机制通过随机实现.
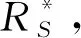
证明.第1批n1行数据将与之前已经讨论过的方法完全相同.因此,第1批数据的概率比是相同的.随机响应比(RR1) 或第1批数据的概率比为
(4)
第2批有n2行数据进行洗牌,这里的概率比为
(5)
这个过程将重复t个批次,整个数据的总概率比基数为

(6)
如果n1≅n2≅…≅nt,可以得到

(7)
因此,隐私预算ε为
(8)
因此,安全洗牌算法的随机响应比RR∞是一个很小的分数,可以提供良好的隐私预算.
3.2 抵御成员推断攻击能力分析
本文方法能够有效抵御成员推断攻击,主要有以下2方面原因:
1) 经过差分隐私训练模型,较小的隐私预算(即更强的隐私保护)给目标模型引入了更多的随机性,从而干扰了目标模型的输出;
2) 从单条记录的角度看,差分隐私添加的噪声导致2个相同记录的预测概率也可能不同.因此,较小的隐私预算导致目标模型对2个相同的记录输出不同的预测概率的可能性更高.
为了验证和分析本文方法的防御成员推断攻击性能,本节给出测试样例,在不违反输入输出计数损失函数的情况下,在编码数据库上使用查询函数进行测试.该数据库包含个人信息,在洗牌之前每行对应用户唯一ID.已知与查询相关的属性名称,这些属性可以绑定在一起以单一属性形式呈现.
硬件实验环境:处理器Intel Core i5-8300H @ 2.30 GHz;显卡Nvidia GeForce GTX 1060;内存8 GB;主硬盘512 GB.数据集规模为100万条记录.
例如,以6个人的4个属性(姓名、年龄、身高、体重)为数据集,查询“数据库中有多少人年龄小于40岁,体重超过60公斤?”.查询函数返回属性“体重”“年龄”作为生成最终报告的相关属性,示例数据中这2个属性会联系在一起.将属性数据输入安全洗牌器,采用洗牌方法对其中每个批次相关属性行进行混洗,将相关属性对(体重,年龄)保存在一行中,维系每人的体重和其年龄,而每个对(体重,年龄)都会因安全洗牌改变自己的唯一ID.其他不相关属性(姓名、身高)的行会随机变化位置,不仅更改了它们的唯一ID,而且还更改了它们的归属权重.由于安全洗牌算法采用无法使用生成的查询报告返回到实际数据库的方式,无法分析结果与存储在数据库中特定个人相关的所有信息,因此SFLSDP具有很强的隐私保护性,能有效抵御成员推断攻击.
表2示出洗牌前后的数据表.对于给定的查询Q,SFLSDP在生成差分隐私报告后计算风险函数,并通过最小化风险,找到最佳随机化函数以生成最终查询结果.如果任何差分隐私报告违反了损失函数的界限,模型将再次从客户端获取新输入并更新模型,继续该过程.通过这种方式,将在保持隐私性的同时,从数据中获得最大的效用.图4给出关于SFLSDP的性能随平均批 次大小变化情况,差分参数随平均批次大小的变化而改变,差分隐私性能比较稳定.

表2 洗牌前后数据表内容

图4 性能随参数变化实验结果
由实验得知,本文方法在对数据添加噪声的扰乱机制基础上,利用安全加密算法对数据进行二次混沌映射,利用置乱矩阵对带噪声的联邦学习模型进行置乱,提高了数据的随机性,提供了更加模糊、更加高效的隐私防护效果.
4 结 论
与现有技术相比,本文方法使模型拥有者利用差分隐私保护了真实联邦学习模型的隐私性,且对训练完成的模型参数添加噪声,避免对神经网络训练模型产生干扰,保证了带噪声的联邦学习模型的效用.安全洗牌和授权密钥的结合保证只有授权用户才能得到带噪声的联邦学习模型,从而实现了联邦学习模型本地使用的安全发布.本文提出的联邦学习安全防护方法可以广泛地应用于工业制造、医疗卫生、智能交通等领域,为用户提供能够均衡隐私性与效用的解决方案.
