人脸深度伪造检测综述
2022-03-23王志浩
孙 毅 王志浩 邓 佳 李 犇 杨 彬 唐 胜
1(北京理工大学网络空间安全学院 北京 100081)2(中国科学院计算技术研究所 北京 100190)3(北京市公安局网络安全保卫总队 北京 100029) (3120195532@bit.edu.cn)
随着互联网的快速发展,数字媒体信息在其中的传播也越来越迅速和广泛,伴随着深度学习以及卷积神经网络的发展,出现了由神经网络生成的虚假图像以及视频.该类方法对影视行业以及艺术创作等提供了新的思路和方法,但也对政治和金融等对个人公信力要求比较严格的行业提出了鉴伪要求.如何鉴别互联网中传播的数字媒体的真实性成为亟待解决的问题.
早期虚假数字媒体的生成主要使用Photoshop等软件直接对图像进行修改.近年来,随着深度学习尤其是神经网络的发展,深度学习在许多的视觉任务上开始超过人类,其中有一类神经网络被称为生成对抗网络(GAN)[1],主要用于生成任务,可以生成非常逼真的图像.由生成对抗网络等生成方法衍生出许多伪造图片以及伪造视频的生成方法,其中最引人注目的也是危害最大的一类是更换人脸的伪造视频.该方法将一个人的脸或表情替换到另一个人的脸上,生成的视频逼真度较高,且制作成本较低,其恶意使用给社会稳定以及个人名誉安全带来非常严重的威胁.现已有不法分子将明星的脸换到色情视频上,给明星本人带来了极大的名誉损害.
针对上述情况,国内外已针对伪造视频发布了相关法律法规:美国最早于2018年就提出《2018年恶意伪造禁令法案》,对制作深度伪造内容当事人以及明知内容仍然继续分发的社交平台进行处罚;在2019年美国众议院提出《深度伪造责任法案》,要求创建深度伪造的人应该在其创建的视频或者图片上加入该视频为伪造的水印或标志,否则属于犯罪行为;同年美国两党议员分别在众议院、参议院提出《2019年深度伪造报告法案》,对伪造视频进行定义以及划分其监管责任.同时欧盟主要通过保护个人信息以及对虚假信息进行治理,从法律层面限制深度伪造.2019年11月,中国国家互联网信息办公室、文化和旅游部、国家广播电视总局联合印发《网络音视频信息服务管理规定》,其中规定生成的非真实音视频应当在发布时予以标识,不得利用其制作、发布、传播虚假新闻信息,该规定于2020年1月1日开始实施.同时国内也有不少学者[2-3]研究了现有的伪造视频潜在的危害,并提出了治理建议.
伪造视频的出现也引起了国内外学者的高度关注,越来越多的学者开始投身于伪造检测相关研究中[4].前期研究者们称伪造视频为“Deepfake”,该名称来自于红迪网(Reddit)的1名用户,其在2017年底使用“Deepfake”作为用户名发布了一段利用女明星面孔合成的色情视频,掀起了一阵轰动.因此在一段时间内“Deepfake”也成为了这一类技术[5]的代名词.近段时间随着越来越多伪造算法的出现,学术界更多地使用“forgery”(伪造品)来指代伪造视频.同时,研究者们为了促进伪造检测的发展,提出了许多伪造检测数据集用来对伪造检测算法进行评价.针对伪造视频的检测一方面可以促进对生成对抗网络痕迹以及合成视频痕迹的研究,另一方面有着非常高的实用价值,利用该技术可以对互联网中的视频进行有针对性的检测,从而鉴别其中的虚假信息,有助于维护互联网秩序和社会的稳定.
由于伪造检测近些年来发展迅速,有大量相关数据集以及算法的发布,因此本文针对伪造视频检测算法进行梳理和总结,对其技术路线进行分类和整理,并对其检测结果进行分析,指出目前伪造检测研究中面临的问题和挑战,旨在为伪造检测技术的研究和发展提供方向性指导.
1 人脸伪造公开数据集
伪造检测不同于传统的图像分类、目标检测、语义分割等任务,其数据集随时间不断更新.一方面伪造算法在不断的发展,新的伪造算法会修复旧的算法存在的问题,使其生成的视频更加逼真,更加难以分辨,因此需要更新数据集,增加新的伪造算法生成的数据;另一方面,随着伪造检测算法的发展,先前数据集的准确率已经达到顶点,需要新的数据集更好地衡量检测算法的优劣.因此在过去的几年间,研究者们提出了很多伪造数据集,这些伪造数据集朝着更大量的视频数量、更多的伪造算法数以及更高质量的伪造视频方向发展.有关现有伪造数据集的详细信息如表1所示:
现有的伪造数据集中,有一些数据集会给出其使用的伪造算法,有些则不提供,伪造算法可以根据是否更换人脸身份信息分为2类:一类在生成新人脸时替换人脸身份信息,即人脸的身份信息会发生变化(图1中左边2张人脸图像生成右下角人脸图像时,保留了左下角人脸图像的背景、头发、耳朵等,但是眼睛、鼻子、嘴巴等人脸身份信息被左上角的图像替换);另一类是仅仅更换人脸表情,人脸身份信息保持不变(图1中左边2张图生成为右上角人脸图像时,保留了左上角人物的五官及背景,仅有表情发生了变化).

图1 伪造分类
产生伪造视频涉及的算法中有些基于生成对抗网络,生成对抗网络主要由生成器和鉴别器2部分组成,其中生成器用于生成伪造数据,鉴别器用于鉴别生成器生成的数据,从而促使生成器生成更加逼真的数据.也有基于自编码器的算法,自编码器主要由2部分组成:一部分是编码器,另一部分是解码器.编码器将人脸信息提取到一个高纬度的特征空间,之后在特征空间中对2张人脸进行混合,再使用解码器得到更换人脸后的图片.还有基于人脸图像编辑的算法,该算法首先提取面部区域及人脸关键点,之后利用计算机图形学的3D渲染方法将2张图像融合,最后作一些后处理操作使其更加平滑.
下面按照伪造检测数据集出现的时间顺序对其进行介绍,主要介绍其数据量以及使用的伪造算法.
1) UADFV
Li等人[6]使用带有后处理的深度伪造方法生成伪造视频,构造了一个包含49个真人视频和49个伪造视频的数据集.该数据集是最早的公开伪造检测方向的数据集,但缺点是数据量较少,且质量不高.
2) DeepfakeTIMIT
Pavel等人基于VidTIMIT[7]构建一个伪造检测数据集DeepfakeTIMIT[8],该数据集使用基于生成对抗网络的开源软件生成伪造数据.该文认为视频质量是伪造检测的关键问题,因此生成的数据集中包含320个高质量视频和320个低质量视频.
3) FaceForensics++
数据集FaceForensics++[9]是目前学术界普遍使用的一个数据集,拥有1 000个真实视频,使用4种伪造方法,分别为DeepFakes[5],Face2Face[10],FaceSwap[11],Neural Textures[12].其中有DeepFakes和FaceSwap是更换人脸身份信息的方法,另外2个是不更换人脸身份信息的方法.后来又添加了来自CVPR 2020的FaceShifer[13]方法,因此伪造视频一共有5 000个.同时对数据集划分了训练集、验证集、测试集,使其成为一个标准的伪造检测评价基准.该文认为视频质量是影响伪造检测的重大因素,因此构造了3种不同压缩率的视频,分别为原视频(Raw)、高质量视频(c23或HQ)、低质量视频(c40或LQ).通过实验也证明视频质量越低,检测伪造人脸越困难.不仅如此,还在数据集上测试了许多伪造检测算法的有效性,得出在该数据集上的最好模型是XceptionNet[14]的结论,为该方向的研究奠定了坚实的基础.从近2年的学术发展来看,该数据集得到了学术界的广泛认可.
4) DFD
数据集DFD(deep fake detection)[15]是Google和JigSaw提供,该数据集是由28位演员在各种场景下拍摄获得的,一共含有3 000多个伪造视频.该数据集并未提及其使用的伪造算法,目前已委托FaceForensics++作者进行管理,可与FaceForensics++一同下载.
5) Celeb-DFV1 & V2
Li等人[16]先于2019年9月发布了V1版本的数据集,之后于2020年3月又将其扩大成V2版本数据集.由于V1已经包含在V2中,因此仅介绍V2版本数据集的情况.该文认为现有数据集的质量较低,和目前互联网上流传的视频有很大的出入,因此提出了Celeb-DF数据集,该数据集包含5 639个高质量的伪造视频,这些视频是由590个真实视频生成的.作者对现有伪造数据中的几个问题进行了修复,比如分辨率太低、颜色不匹配、人脸区域不匹配、时序闪烁等.
6) DeeperForensics-1.0
文献[17]提出的数据集DeeperForensics-1.0有6万个视频(一共包含1 760万帧),其中有1万个视频是伪造视频,其余是真实视频.其中作者采集的是用于替换人脸的视频,而被替换的视频直接使用了FaceForensics++的高质量视频(c23视频压缩)数据集中的1 000个.同时作者对生成的伪造视频作了不同程度的干扰以检验检测算法的鲁棒性.在伪造方法方面,该文提出了一种名为DF-VAE的算法来生成伪造视频.该方法分为3步,分别是提取人脸结构、解耦人脸结构以及人脸ID信息合成,最后根据光流对生成结果进行平滑.
7) DFDC p & DFDC
DFDCp[18]是伪造检测挑战(DFDC[19])数据集的预览数据集,该数据集由具有2种面部修改算法生成的5 224个视频组成.文献[15]在征集参与者的同意后展开了对数据的搜集,考虑到性别、肤色、年龄等属性的多样性,录制了具有任意背景的视频,从而带来了视觉的多样性.最后,定义了1组用于评估性能的特定指标,并测试了2个伪造检测的模型,提供参考性能基线.不过在最后的正式比赛中,作者并未使用该指标,而是将其更换为二分类交叉熵损失.DFDC[19]数据集为Facebook在Kaggle举办的正赛使用的数据集,该比赛提供了12万个视频用来训练,其中真实和伪造视频的比例大约为1∶5,且视频分辨率较高.鉴于比赛的公平性并未提供伪造的具体算法.该比赛引起了世界范围内来自学术界以及社会的专业人士的广泛关注,吸引到共计2 265个队伍参加.
8) ForgeryNet
ForgeryNet[20]为商汤科技在CVPR 2021上发表的一个数据集,该数据集规模很大,有99 630个真实视频以及121 617个伪造视频.且其最大的亮点是提出了该领域新的任务.比如:三分类,分为真实、伪造且更换人脸身份信息、伪造且不更换人脸信息;多分类,根据伪造方法进行分类,也可称为溯源;基于语义分割寻找图片中伪造区域,该任务需要找出像素级别的伪造区域;该文还认为在现实世界中,真实视频片段和虚假视频片段可能是混合的,因此提出了一个时序定位的任务,输入一段视频,需要定位出伪造以及真实视频的时间片段.在伪造方法方面,该文一共涉及17种伪造方法,其中有更换人脸身份信息的算法,也有不更换人脸身份信息的算法.
9) FFW
FFW[21]也发表在CVPR 2021,作者认为目前的伪造视频数据集大多在画面中只有一个人脸,只需判断是不是该人脸被伪造.而在现实世界中,视频中可能出现很多个人脸,此时视频环境更加复杂,因此该文提出了复杂人物场景的伪造检测数据集.在视频帧中,有一部分人脸是伪造得到的,另一部分人脸是真实人脸,这种模式对伪造检测算法提出了更高的要求.该数据集共有1万个视频,平均每帧有3张人脸.作者一共使用了3种伪造算法,其中2种是基于学习的DeepFaceLab[22]和FSGAN[23],1种是基于图形学的FaceSwap[11].
10) OpenForensics
数据集OpenForensics[24]来自ICCV 2021,该数据集作者与FFW的作者观点类似,同样也认为在数据集中应出现干扰人脸,在图片中仅仅一部分人脸是伪造的,其余是真实的人脸.不同点是该数据集是基于图片的,并且作者将该任务定义为一个语义分割任务,需要得到在人脸部分的每个像素点的真假的分割结果,这与ForgeryNet中的图像分割任务基本一致.最终作者搜集了11万张左右的图片,真假比例大约为1∶2.该文使用基于生成对抗网络的伪造算法,并且使用了一些技术来修复边缘以及颜色的不一致,最后使用一个Xception的二分类网络对生成的伪造图片进行筛选,只有该分类网络不能识别的图片才保留.
11) KoDF
KoDF[25]来自ICCV 2021,是一种基于韩国人的伪造检测算法数据集.该数据集包含237 942个视频,其中62 166为真,175 776为假,真视频长度为90 s,伪造视频长度为15 s(有些长的为30 s).该数据集使用6种伪造算法,分别为FaceSwap[11],DeepFaceLab[22],FSGAN[26],FOMM[27],ATFHP[28]和Wav2Lip[29].
12) Vox-DeepFake
Vox-DeepFake[30]是一个基于人脸身份信息的伪造数据集.该文从另一个角度定义了伪造检测:待测图片与参考人脸相比是否为同一个人,从而基于人脸身份信息对其检测.因此基于VoxCeleb[31]构建了一个具有参考人脸的伪造数据集,该数据集共搜集了4 000人的200多万条视频,每条视频的长度为10 s.使用3种伪造方法,包括DeepFakes[5],FSGAN[23]以及FaceShifter[13].目前该数据集还未公开.
2 人脸伪造检测算法
国内外学者从各种角度研究了如何鉴别伪造视频,提出了很多相关算法.本文从伪造检测的不同研究角度出发,对现有的伪造检测算法进行了归纳,展现各种方法的异同.首先是针对伪造痕迹的方法,比如从人脸固有特征出发,发掘真脸与假脸在生理特征上的不同点;将图片转化到频域,基于频谱上的一些特征来发掘伪造痕迹;从伪造方法出发,发掘生成对抗网络的固有痕迹.其次是充分利用卷积神经网络的优点,通过修改网络结构来检测伪造视频.接下来是利用视频的时序性特点进行伪造检测.然后从人脸身份信息出发,在实际应用中更加注重对关键人物的保护,因此可以使用真实图片来辅助检测.最后从提高检测算法的泛化性出发,以应对新出现的伪造算法.
在伪造检测领域,普遍使用的评价标准有2个:一个是准确率(Accuracy),另一个是AUC(area under curve),AUC被定义为ROC曲线下的面积,ROC曲线全称为受试者工作特征曲线,是反映敏感性和特异性连续变量的综合指标.下面介绍各个伪造检测算法时将用到的评价标准.
2.1 基于人脸固有特征的方法
一方面,人脸本身有着一定的固定结构,比如五官的相对位置和固定的形状,另一方面人在说话时会出现一系列生理特征,比如眨眼、唇语、脸部皮肤下毛细血管的流动等.
Falko等人[32]发现,经过伪造的视频在眼睛、牙齿、面部轮廓等视觉特征上存在一些瑕疵.因此作者构建了一个由ProGAN[33]生成的人脸、DeepFakes[5]和Face2Face[10]伪造算法生成的人脸构成的数据集.之后作者使用了逻辑回归以及多层感知机2个算法对上述数据进行了训练和测试,其中多层感知机在输入特征为眼睛和牙齿时获得了最好的效果,在AUC指标上取得了0.851的结果.
Yang等人[34]根据伪造图片将合成的面部区域拼接到原始图像中来创建的事实,认为这样会引入3D头部姿势上的瑕疵.作者首先通过可视化真实人脸和伪造人脸在头部运动上的余弦距离说明可以通过头部的运动分辨真假.此后通过1个SVM分类器对Dlib[35]提取到的68点人脸关键点估计的头部姿态进行分类来判断伪造视频,在UADFV数据集上进行了测试,在视频伪造检测的AUC指标上取得了0.974的结果.
Shruti等人[36]认为每个人在说话时都有其固定的面部以及头部运动习惯,因此可以抽取这些运动习惯作为参考.该文选取OpenFace2[37]工具对人物抽取特征,使用了抽取到的16个AU(运动单元)特征以及4个其他特征(包括头部x轴坐标、头部z轴坐标、嘴角水平距离、上下唇3D垂直距离),之后计算这20个特征的皮尔逊相关系数作为1个190维的特征向量,最后使用OneClassSVM对这些特征进行分类.在其自己构造的美国领导人以及政客数据集上对提出的方法进行了测试.结果证明在190维特征向量中,有29个特征起到十分重要的作用,在使用这29个特征时,在各个数据集上都取得了很好的效果,其中最低的AUC指标也达到0.96,充分证明了该文方法的有效性.
Alexandros等人[38]认为伪造视频在嘴唇的连贯性上存在瑕疵.具体来说,对于真实视频,人在说话时其唇读信息内容是可以被识别的;而对于伪造视频,其由于是对单帧进行伪造,并未作帧间的平滑,并且在伪造或者替换表情时会破坏原有的嘴唇运动,导致其唇读内容异常,因此使用唇读内容识别的方法可以检测出伪造视频.其流程如图2所示,首先对视频中的人脸进行检测和对齐,并切出嘴部区域,之后将图片转化为灰度图,接下来训练一个基于ResNet18[39]的3D卷积神经网络来提取特征,之后将提取到的特征输入MS-TCN[40]进行唇读分类任务.在做完这些预训练任务后,将前面的特征提取卷积神经网络参数固定,只训练后面的MS-TCN部分用来分类真假,采用这种方式来确保前半部分网络提取到的是唇读相关的特征.此外用消融实验证明了不论是从零开始训练网络还是放开全部网络进行微调,效果都不如只微调MS-TCN,这充分证明卷积神经网络提取到了重要的唇读先验假设.最后在FaceForensics++上对其方法进行了验证.为了验证算法的泛化性,作者在实验中进行了不同伪造方法的交叉验证,对于FaceForensics++中的4种伪造方法,挑选其中3个训练,使用最后一种没有出现在训练集中的伪造方法作为测试,在这种设置下训练的4个模型的平均AUC指标达到0.971.另外还在其他数据集上进行了交叉验证,也获得了不错的效果.除此之外,对原始数据作了7种数据干扰,包括调整色彩饱和度、调整对比度、随机对图片中的一小块进行消除、对图片添加噪声、对图片进行高斯模糊、对图片进行像素化模糊和对图片进行压缩,实验结果表明该方法有着很强的抗干扰能力.

图2 基于唇读的伪造检测
除了上面提到的算法以外,还有许多研究者从不同的人脸固有特征角度进行检测,比如Tackhyun[41]使用人脸的眨眼特征来进行伪造检测;Qi等人[42]使用人脸在心跳时的肤色变化来检测伪造视频;这些人脸固有特征是由于伪造算法本身的瑕疵引起的,因此这些算法存在着一定的时效性,即如果伪造算法在生成时修复这些瑕疵,那么这些算法将无法正确检测.因此该方向的一些算法在泛化性上都不是很好,如何寻找出一个具有泛化性的判别依据是这类方法亟待解决的问题.
2.2 基于频谱特征的方法
许多的学者认为伪造的图像在频域会留有一定的信息,并且使用这些信息可以鉴别伪造视频.
Chen等人[43]提出了一种使用注意力机制将空间域特征和频域特征组合的伪造检测算法.该方法先使用人脸语义分割将人脸的五官分割出来,之后使用注意力机制和卷积神经网络提取空间域特征;接下来将图片经过离散傅里叶变换后通过注意力机制以及卷积神经网络提取频域特征,最后将这些特征融合在一起进行分类.此外在骨干网络中添加了基于注意力的层,以提高其泛化能力.
Qian等人[44]认为频域中存在一些伪造线索,因为频域给出了一个与图像互补的视角,在频域中可以很好地描述微小的伪造瑕疵和压缩错误.因此提出了一种称为F3-Net(frequency in face forgery network)的网络结构,该结构考虑了2个不同且互补的分支,其中一个是频域自适应的图像分解分支;另一个是图像细节频率统计信息分支.该文使用离散余弦变换得到频域信息,之后设计了一个双流协作学习框架对上面的2个分支进行学习.最后在FaceForensics++数据集上进行了测试,在高质量视频上AUC评价指标得到了0.993的结果,低质量视频上得到了0.958的结果,该方法在低质量的视频上相较于其他方法领先幅度很大.
Liu等人[45]观察到上采样是大多数人脸伪造生成时的必要步骤,认为累积上采样会导致频域的明显变化,尤其是相位谱,因此提出了一种基于空间相位浅层学习(SPSL)的方法.该方法结合空间图像和相位谱来捕获面部伪造的上采样特征,从理论上分析了利用相位谱的有效性.此外,注意到对于伪造检测任务,局部纹理信息比高级语义信息更重要,因此通过使网络变浅使得网络更加专注于局部区域,减少网络的感受野.该文通过实验证明了其算法的有效性,在FaceForensics++的高质量视频和低质量视频的AUC指标上分别取得了0.953 2和0.828 2的结果.
Li等人[46]认为现有的伪造检测算法存在2个问题:第1个问题是现有算法使用交叉熵作为损失函数的判别力是不够的,因为其并没有明确鼓励类内紧凑和类间可分;第2个问题是现有的基于卷积神经网络提取的特征以及手工选择的特征并不够充分发现伪造痕迹,因此提出了一种基于频率感知判别特征的学习框架,设计了一种单中心损失函数(SCL),它仅压缩真实人脸的类内变化,同时增强嵌入空间中的类间差异,以此让网络可以以更小的优化难度学习更多的具有判别力判别特征.该文还提出了基于自适应频率特征的生成模块,以完全数据驱动的方式挖掘频率线索.最后通过实验证明了其算法的有效性,在FaceForensics++上的高质量视频和低质量视频上的AUC指标分别达到了0.993和0.924.
Luo等人[47]发现当前基于卷积神经网络的检测器倾向于过度拟合特定于方法的颜色纹理,因此泛化性较差;同时观察到图像噪声去除了颜色纹理并暴露了真实区域和篡改区域之间的差异,因此利用高频噪声进行面部伪造检测.该文设计了3个功能模块,以充分利用高频特性:第1个是多尺度高频特征提取模块,它提取多尺度的高频噪声并构成一种新的特征;第2个是残差引导的空间注意力模块,它引导低维度RGB特征提取器从另外一个角度更多地关注伪造痕迹;第3个是跨模态注意力模块,它利用2种互补模态之间的相关性来促进彼此的特征学习.通过在FaceForensics++中4种伪造方法之间以及FaceForensics++和其他数据集比如DFDC,CelebDF等上作了交叉实验,验证了其算法具有很好的泛化性.
Chen等人[48]认为大多数现有方法将人脸伪造检测视为二分类问题,在不考虑局部区域之间相关性的情况下,这些方法不足以学习泛化特征并且容易过拟合.该文提出了一个多尺度块相似性模块(MPSM),用来测量局部区域特征之间的相似性,并形成一个鲁棒的、高层的相似性模式;还提出了一个RGB频率注意模块(RFAM)来融合RGB和频域中的特征,以获得更全面的局部特征表示,进一步提高相似性模式的可靠性.在FaceForensics++数据集上验证了该方法的有效性,在高质量数据集和低质量数据集的AUC指标上分别取得到了0.994 6和0.952 1的结果.
基于频谱的方法由于提供了图片的另一个角度,因此在泛化性上有一定的优势.而现有的图片视频压缩方法多数也与频域相关,因此基于频域的方法在鲁棒性尤其是抗压缩上有着不错的效果.长远来看,基于频域的思路将成为换脸检测中重要的研究方向,有很好的发展前景.
2.3 基于生成对抗网络固有痕迹的方法
许多学者认为使用生成对抗网络生成的伪造人脸与现实世界中拍照得到的人脸相比,留有一定的痕迹以及纹理信息,这些信息可以作为生成对抗网络的指纹,通过检测这些指纹可以辅助检测伪造视频.
Wang等人[49]提出了一种名为FakeSpotter的方法,该方法基于监控神经元行为检测伪造.通过对神经元的研究表明,神经元可以作为深度学习系统的测试标准,尤其是在面对对抗性攻击的情况下.监控神经元行为也可以作为检测伪造的方法,因为逐层神经元激活模式可能会捕获更细微的特征.在生成对抗网络合成的4种伪造数据集,以及加入4种扰动攻击的数据集上的实验结果表明了该方法的有效性和鲁棒性.
Luca等人[50]提出了一种基于伪造痕迹的检测方法,该方法能够检测隐藏在图像中的伪造痕迹:一种在图像生成过程中留下的指纹.通过期望最大化(EM)算法提取1组局部特征,用于对底层卷积生成过程进行建模.通过在5种不同生成对抗网络结构(GDWCT[51],StarGAN[52],AttGAN[53],StyleGAN[54],StyleGAN2[55])以及CelebA[56](作为真实数据)上使用朴素分类器的实验,证明了该方法在区分不同生成对抗网络结构和相应生成过程方面的有效性.
Liu等人[57]对真实和伪造人脸进行了对比,得出了2个结果:首先,伪造人脸的纹理与真实人脸有很大不同;其次,全局纹理统计对干扰更稳健,并在来自不同生成对抗网络和数据集的伪造人脸上可区分.受此启发,该文提出了一种名为Gram-Net的架构,它利用全局图像纹理表示进行鲁棒的伪造检测.实验结果表明,该方法对图像干扰(下采样、JPEG压缩、模糊和噪声)更健壮,对训练阶段未见过的GAN模型中伪造检测表现也很好.
Yang等人[58]认为现有的基于生成对抗网络的伪造指纹检测都集中在单个模型上,不能泛化到不同随机种子、数据集、损失函数等条件下的新训练模型上.因此提出了一种基于模型结构溯源的方法,该方法首先构造了一个图像转换的预训练任务,之后在训练时使用基于图像块的对比学习来和多分类任务一同训练的方式优化DNA-Det.该文在多种生成对抗网络上对其方法进行了验证,实验结果表明该方法可以完成对模型结构的溯源,且优于其他方法.
基于换脸算法固有痕迹的方法主要依托于其生成时遗留的一些痕迹,这些痕迹主要由生成对抗网络产生,因此在基于生成对抗网络生成的伪造视频上检测效果较好.并且由于不同的生成对抗网络有不同的痕迹,因此该方法可以用于溯源.
2.4 基于神经网络结构的方法
随着ImageNet等标准数据集的建立,神经网络架构在近年来获得了巨大发展.常见的神经网络架构有VGG[59],InceptionV3[60],Xception[14],ResNet[39],DenseNet[61],EfficientNet[62]以及最近获得极大关注的基于Transformer[63]的ViT[64]等.大部分伪造检测算法将伪造检测看作一个二分类问题,因此直接使用这些设计好的模型或者对这些设计好的模型结构进行修改,成为伪造检测的重要方向.
Afchar等人[65]提出了一种检测视频中人脸伪造的方法,该方法重点关注用于生成超逼真伪造视频的2种最新技术:DeepFakes[5]和Face2Face[10].基于压缩会严重降低数据质量的情况,该文提出了2个网络,它们都是浅层网络,以专注于图像的细节特性.在现有数据集和在线搜集的视频构成的数据集上评估了该方法.实验结果表明在DeepFakes和Face2Face上表现优异,检测正确率分别超过98%和95%.
Belhassen等人[66]提出了一种使用深度学习进行伪造检测的算法.为了克服目前卷积神经网络学习捕捉图像语义的特征,而不是检测伪造特征的问题,该文开发了一种新的卷积层,专门设计用于抑制图像内容并自适应地学习伪造特征.作者在自己搜集的数据集上的一系列实验证明该方法可以检测几种不同的伪造视频,平均准确率达到99.10%.
Zhou等人[67]提出了一种用于人脸伪造检测的双分支网络.其中基于人脸分类分支对人脸是否被伪造进行分类,基于图像块的三元组分支在隐写特征上进行训练,以确保来自同一图像的块在嵌入空间中是接近的,之后在学习到的特征上训练SVM对每个块进行分类.最后,将2个分支的分数融合以识别伪造人脸.此外,使用2个不同的在线人脸伪造应用程序创建了一个数据集,在收集的数据集上评估了双分支网络,最终在该数据集的AUC指标达到了0.927,证明了该方法的有效性.
Huy等人[68]提出可以使用胶囊网络来检测伪造图像以及视频,其中图片先经过VGG[59]提取特征,之后通过所提出的胶囊网络,其由3个主要胶囊和2个输出胶囊组成,输出胶囊中一个用于真实图像,另一个用于伪造图像.在其搜集的数据集上取得了99.23%的视频级别准确率.
FaceForensics++[9]发布时,作者对比了现有的一些分类网络在其数据集上的检测效果,发现以Xception[14]作为主干网络,输入人脸图片可以获得最好的检测结果,在FaceForensics++上取得了95.73%的准确率.Xception[14]将卷积神经网络中的Inception[38]模块解释为常规卷积和深度可分离卷积操作之间的折中情况.深度可分离卷积可以理解为具有最大分离数量的Inception模块.Xception在ImageNet数据集上略胜于Inception V3,并且在包含3.5亿张图像和17 000个类别的更大图像分类数据集上明显优于Inception V3.由于Xception在伪造检测方向显著优于其他模型,在此之后Xception已经成为FaceForensics++数据集上的基准算法.
DFDC[19]比赛公布结果后,有参赛者公布了其解决方案,比如:Nicolò等人[69]研究了不同训练设置的卷积神经网络模型的集成.在其方案中,使用多个EfficientNetB4进行集成.比赛中有许多选手都选用EfficientNet[62]系列的网络结构,下面简单介绍该模型.Tan等人[62]系统地研究了影响模型大小的一些参数,比如网络深度、宽度和分辨率等.基于此提出了一种新的缩放方法.该方法使用简单而高效的复合系数统一缩放深度/宽度/分辨率所有维度.此外还使用神经架构搜索设计一种新的网络,并将其放大以获得一系列模型,称为EfficientNets,相较之前的卷积神经网络实现了更好的准确性和效率.EfficientNet-B7在ImageNet上达到了84.3%的准确率.
Dang等人[70]提出利用注意力机制改善分类任务的特征图.认为神经网络学习到的注意力图突出显示了篡改区域,可以进一步改进分类结果,并且还可以可视化伪造区域,因此搜集了一个包含多种类型的面部伪造的大型数据库DFFD.使用VGG16[59]作为骨干网络并加入提出的注意力机制可以得到最好的AUC指标,最高可以达到0.996 7.
在伪造检测初期,基于改进神经网络的图像算法发展迅猛,但是近年来随着基于视频时序的方法出现,研究者们将更多的精力放在了使用时序信息来检测伪造视频.
2.5 基于视频时序的方法
鉴于现有大多数的伪造视频是通过逐帧进行伪造,最后合成得到的,并未作帧之间的平滑,因此在帧之间会存在伪造引起的不一致性.有许多的学者将研究方向集中在基于视频时序信息的伪造检测上,并且取得了非常好的效果.
David等人[71]提出了一种时间自适应方法来检测伪造视频.该方法使用卷积神经网络提取帧级别特征,然后使用这些特征训练循环神经网络.针对从多个视频网站搜集的300个伪造视频以及300个真实视频来评估其算法,最终该算法在其搜集的数据集上的AUC指标为0.971.
Ekraam等人[72]和David等人[71]使用的方法思路基本相同,先对视频进行人脸检测,切出人脸区域,人脸对齐后使用卷积神经网络提取图像特征,最后再使用循环神经网络提取时序信息.该方法使用FaceForensics++数据集中的Deepfake,Face2Face,FaceSwap数据来评估其算法的有效性,在这3种伪造方法上分别达到了96.9%,94.35%以及96.3%的准确率.
Wang等人[73]研究了3D卷积神经网络在检测被操纵视频方面的泛化性.在FaceForensics++中4种篡改的视频上进行了实验,实验包括3种:第1种是训练网络检测所有被伪造的视频;第2种是分别单独检测每种伪造技术;第3种是进行伪造方法上的交叉检测.结果表明,基于视频的这些方法在测试集和训练集同源,即测试集使用的伪造方法和训练集的伪造方法一致时(即第1种和第2种),基于时序的方法有很好的效果.但是在未知伪造方法的数据集上(第3种)精度会有着很大的下降.
Sun等人[74]认为挖掘伪造视频的时序特征并利用它们是十分重要的,因此提出了一个名为LRNet的框架.首先预测每一帧的68点人脸关键点,之后通过跟踪等方式对关键点的位置进行校准,最后构建了2个循环神经网络,将得到的人脸关键点坐标以及坐标在时序上的差值输入进行分类.由于在分类时不需要使用图片底层特征以及卷积神经网络,因此网络更轻量级,更容易训练.同时由于不直接输入图片而是输入图片的人脸关键点提取结果,该方法在检测高度压缩或高噪声的视频方面表现出很强的健壮性.在FaceForensics++数据集的AUC指标上取得了0.999的成绩.同时,在面对高度压缩的视频时,AUC指标仅下降0.042.
Zheng等人[75]探索了基于视频的人脸伪造检测,提出一个端到端框架,它由2个阶段组成:第1阶段是全时间卷积网络(FTCN).FTCN的关键修改是将空间卷积核大小减小到1,同时保持时间卷积核大小不变.这种特殊的设计有利于模型提取时间特征并提高泛化能力.第2阶段是时序注意力机制网络,如图3所示,旨在探索在视频中长序列的时间一致性.在FaceForensics++中的4种伪造方法上进行了跨伪造方法实验(使用其中3个训练,剩余的测试),最终在AUC指标上达到了0.997的平均值,同时也在其他数据集上进行了交叉实验,都取得了很好的效果,说明该算法有着很好的泛化性.
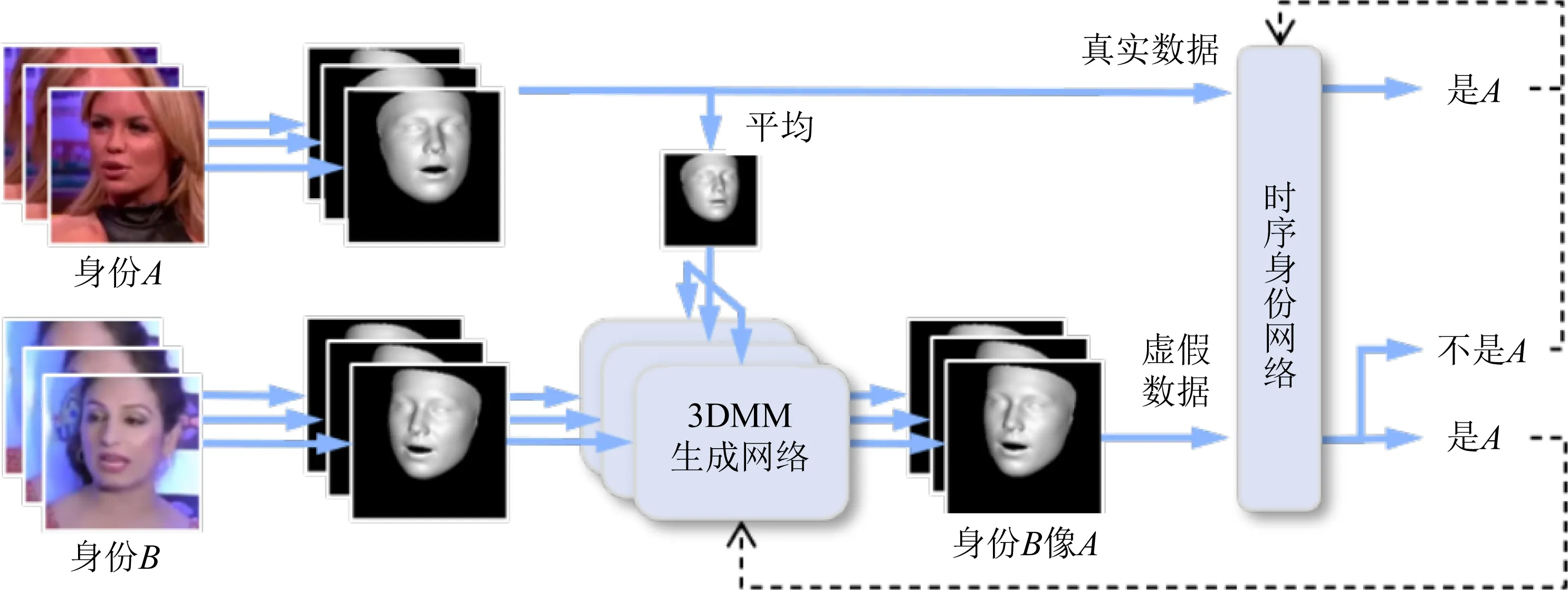
图4 基于人脸身份信息的伪造检测
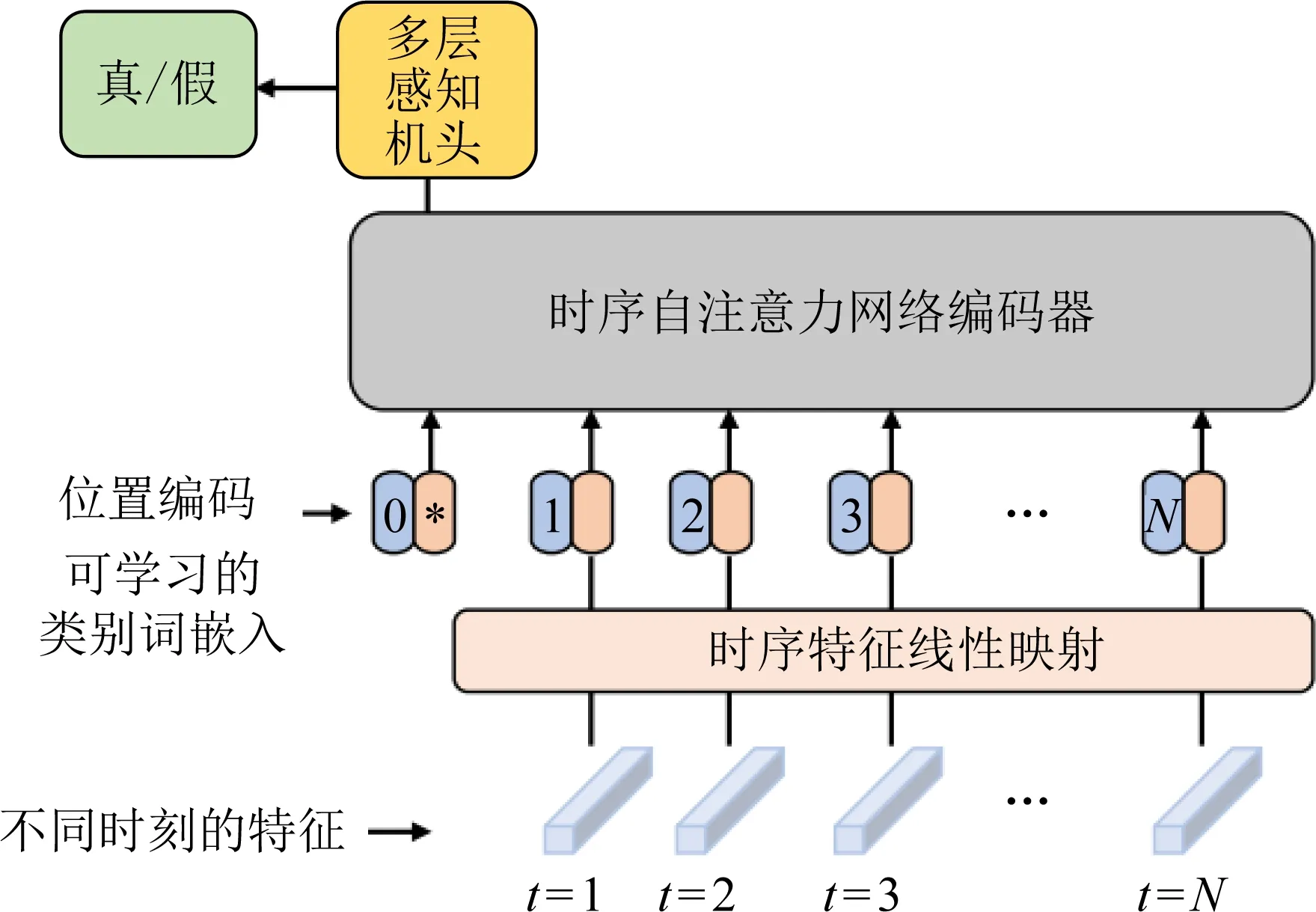
图3 基于时序自注意力网络的伪造检测
Zhang等人[76]认为视频帧在时序上可能存在不一致,因此提出了一种基于时序采样的3D卷积神经网络(TD-3DCNN)检测伪造视频.在该方法中,从视频中采样固定长度的帧输入3D卷积神经网络以提取不同尺度的特征并识别其真假.使用帧序列随机丢弃操作来采样视频中的帧,将其作为一种简单而有效的数据增强.在Celeb-DF(v2)以及DFDC上的AUC指标上分别取得了0.888 3以及0.789 7的结果.
基于视频时序的方法目前已经成为伪造检测中十分重要的一种方法,并且其在精度以及泛化性方面都远超基于单帧的方法,该方向未来还有非常大的发展潜力.
2.6 基于人脸身份信息的方法
近年来,有学者将注意力放在基于人脸身份信息的伪造检测上.从实际应用的角度来讲,领导人、军政要人、金融系统中的重要人物、明星等受到伪造视频的影响相对较大,因此针对该类特定人物的伪造检测是十分必要的;从学术上,如何对一个人的人脸特征进行完善的建模以区分其真实与伪造,是一个有待研究的问题.因此许多学者从刻画人脸信息出发,研究基于人脸身份信息的伪造检测.
前述使用人脸固有特征的论文也是针对特定人物的,Shruti等人[36]通过提取AU等特征刻画一个人在说话时的固定模式,不仅可以根据该特征分辨真实和伪造视频,还可以区分不同身份的人.有关实验部分前面已有叙述,这里不再赘述.
Davide等人[77]提出了ID-Reveal,通过度量学习和对抗性训练策略学习时序面部特征,特别是一个人在说话时面部如何移动.如图4所示,其最大优点是不需要任何伪造视频训练数据,只需在真实视频上进行训练.此外还利用高级语义特征进行分类,使得该方法有很高的泛化性和鲁棒性.在几个公开基准进行的实验表明,仅仅使用真实视频进行训练,该方法就显示出很高的泛化性,比如在DFDCp数据集的AUC指标上取得了0.91的结果,此结果也说明在未来如果出现新的伪造算法,该方法依然可以起作用.
Dong等人[30]提出了一种已知目标人脸身份信息的伪造检测算法.该方法将可疑视频以及目标身份信息(参考人脸)作为输入,输出关于可疑视频中的身份是否与目标身份相同的结果,其动机是防止最有害的伪造视频传播,保护目标人的信息安全.作者认为基于身份的方法不同在于其他检测算法去尝试检测图像伪影,它更加侧重于鉴别可疑视频中的身份是否真实.为了促进基于身份信息检测的研究,该文提出了一个新的大规模数据集Vox-DeepFake,其中每个伪造都与从目标身份中搜集的多个参考图像相关联.还提出了一个简单的基于身份的检测算法称为OuterFace,可作为进一步研究的基线.即使在没有加入伪造视频的情况下进行训练,OuterFace算法也实现了很高检测精度,并且可以很好地泛化到不同的伪造方法,有着一定的鲁棒性.
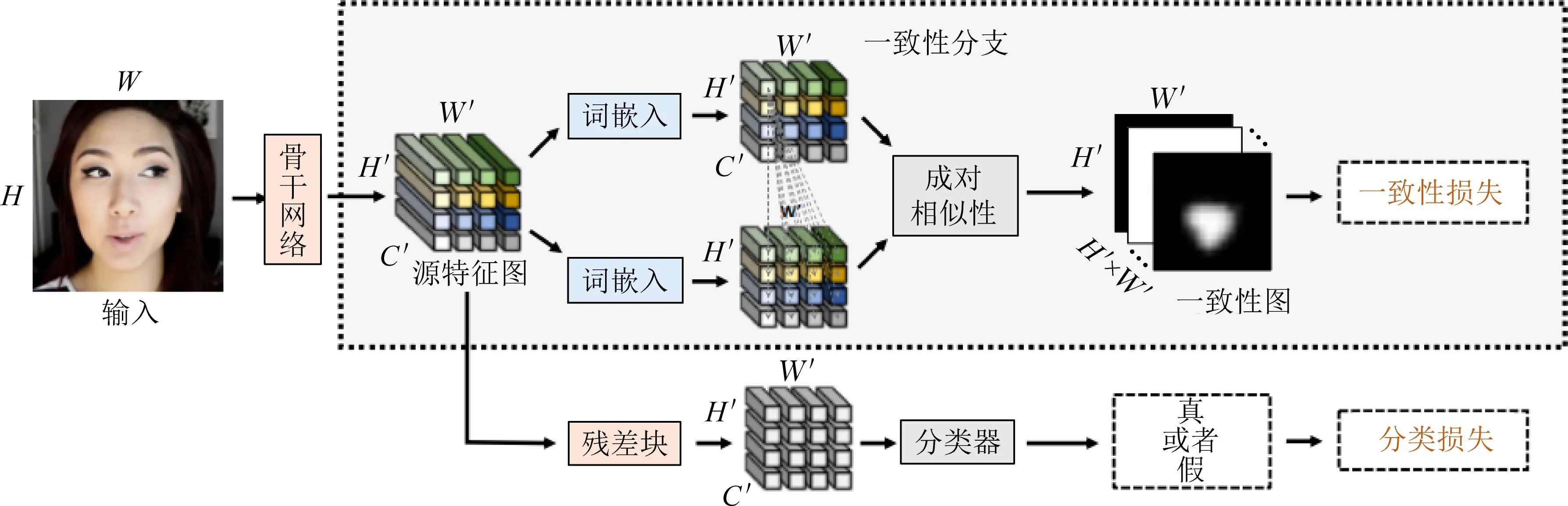
图5 基于图像一致性的伪造检测
基于人脸身份信息检测的方法是最近的一个研究方向,该方法一方面可以减少针对所有人都检测带来的巨大计算量,另一方面由于该方法有可以参考的人脸信息,因此在一定程度上可以克服伪造检测领域中一直存在的泛化性问题.
2.7 基于提高检测泛化性的方法
泛化性一直是伪造检测中非常重要也是非常难解决的一个问题,现有的许多伪造检测算法在伪造数据集上表现很好,但是在新的伪造方法上表现比较差.而在现实世界中伪造检测方法是不断更新的,之前伪造算法的瑕疵很有可能在新出现的伪造算法上已不存在.因此,针对原来的伪造算法的检测算法在新的伪造方法上有极大概率是不能正常工作的.如何提高该任务的泛化性是亟待解决的问题,一些研究者们从这个思路出发,作出了一定的探索.
Zhang等人[78]为了提高检测的泛化性,提出了一个生成对抗网络模拟器AutoGAN,它可以生成由几个流行的生成对抗网络模型共享的过程产生的图片.通用生成对抗网络模型中包含的上采样部分会引入可分辨的特征,并且从理论上证明这种特征表现为频域中频谱的复制,因此该方法基于频谱输入而不是基于像素输入.作者通过该方法训练基于频谱的分类器,可以检测即使在训练期间没有出现的生成对抗模型产生的图像.实验表明在检测由CycleGAN[54]等生成的伪造图像方面达到了最好的效果.
Zhao等人[79]提出了一种使用伪造图像中源特征不一致的线索检测深度伪造图像的方法.该方法基于这种假设,在经过伪造生成过程后,可以保留和提取图像的不同源特征,因此引入了成对自洽学习(pair-wise self-consistency learning, PCL)的一种表示学习方法,如图5所示.由于该方法需要像素级别的标签,而现有的很多数据集没有该细粒度的标签,因此该文提出了一个图像合成方法,称为不一致图像生成器(inconsistency image generator, I2G),可为PCL提供带丰富标签的训练数据.I2G在检测人脸的关键点后,直接将其中一个人的人脸部分替换为另一个人的人脸,以此生成包含不同源特征的图片.在实验中测试了2个不同设置下的实验结果:第1种设置是既使用数据中的真实数据和伪造数据,又使用I2G生成的数据,该方法在该设置下在FaceForensics++上的AUC指标取得0.997 9的成绩;另一种设置是只使用数据集中的真实数据以及I2G生成的数据,该设置可以重点测试伪造视频检测的泛化性,在FaceForensics++真实数据上训练的模型其FaceForensics++以及DFD上的AUC指标分别为0.991 1和0.990 7,证实该方法有极强的泛化性.
Li等人[80]提出了一种称为面部X射线的伪造检测算法.该算法提出的人脸X射线是一个灰度图像,它揭示了输入图像是否可以分解为来自不同来源的2幅图像的混合.作者认为伪造图像存在混合边界,而真实图像没有混合边界,正是基于这样的观察:大多数现有的人脸操作方法都有一个共同的步骤,即将改变后的人脸混合到现有的背景图像中.该算法具有很强的泛化性,因为它仅假设存在混合步骤,并且不依赖于与特定面部处理技术相关的任何伪造知识.实验表明该方法在应用于未训练过的伪造时仍然有效,在FaceForensics++上的AUC指标上测试取得了0.985 2的结果,证明了其方法的泛化性.
Davide等人[81]基于现有方法在未知伪造检测算法上性能显著下降的问题,设计了一种基于学习的伪造检测器,它可以适应新的伪造方法,并且适用于在训练期间只有少数伪造样本的情况.该方法使模型学习一种基于自动编码器的取证隐空间,该空间可用于区分真假图像.将学习到的隐空间当作异常检测器,如果图像与真实图像的集群相距足够远,则其将被检测为假图像.通过在其搜集的数据集上进行实验表明,在未知伪造方法设置下准确率达85%,在已知伪造方法,但已知样本数量很少设置下准确率达到了95%.
Du等人[82]受深度伪造的细粒度性质和空间局部性特征的启发,提出了一种局部感知自动编码器(LAE)来弥合泛化差距.在训练过程中,使用逐像素掩码来规范LAE的局部解释,以强制模型从伪造区域学习内在表示.作者进一步提出了一个主动学习框架来选择具有挑战性的样本,只需3%的训练数据的人脸区域标注,大大减少了标注工作.通过在自己搜集的3个深度伪造检测任务的实验结果表明,该方法有很好的泛化性.
从提高泛化性角度出发的思路越来越受到学术界的关注,目前最新的趋势是在训练时仅仅使用真实样本,或者在训练时从真实样本中构造虚假样本.由于未使用伪造样本,因此对所有的伪造样本都有一定的泛化能力.目前这类算法在伪造数据集上效果还有待提高,其泛化性水平也有待时间验证.
3 实验分析
表2对第2节提及的伪造检测算法进行了整理,对于各种算法分别列出归类类别、是否进行泛化性测试、使用的模型、检测结果和使用的数据集.由于涉及到不同的伪造检测方法和数据集,对结果的分析带来很大的影响,因此本节先对各种检测方法的相同点和不同点进行梳理.
上述鉴伪方法的相同点有:1)检测流程大致相同.现有大多数方法都需要先将人脸图片从图片中切分出来,有些方法比如基于视频时序的方法还会对人脸进行对齐操作.2)许多方法都使用了FaceForensics++这个数据集,因此可以大致比较出各种算法在该数据集上实验结果的差异.当然也有很多的算法是在其自己搜集的数据集上进行的实验,且有些数据集还未公开.3)目前各种算法使用的评价标准是一致的,常用的评价标准为准确率(Acc)和AUC.
上述鉴伪方法的不同点有:1)现有算法的实验设置不同,比如基于视频时序信息的方法使用视频中的连续帧,而基于图片的方法使用视频中随机抽出的帧.同为基于图片的方法,也会出现不同方法每个视频使用的帧的数量不一致的问题,有些使用270帧,有些100帧等.2)各种方法使用人脸检测方法、人脸切分区域大小、是否进行人脸对齐等细节上都有些不同.3)数据集使用方式不同,有些算法使用同源数据集进行实验,也有些方法使用非同源数据进行实验,给直接比较各类实验结果带来些困难.
尽管存在着许多相同点和不同点,本文尝试从表2中得出以下结论:
第一,检测效果较好的是基于视频连续帧的方法[74-75],该类方法在最近1年间得到了迅速的发展.
第二,目前大部分方法还未作泛化性测试,还是在同源数据集上进行的.而基于提高泛化性的方法,尤其是其中只使用真实数据来训练的方法[79]对多种伪造算法都有不错的检测效果,说明其挖掘到伪造视频的一些共同特征,该类方法有着很高的实用价值.
第三,基于频域、人脸固有特征、生成方法固有痕迹的算法也都获得了很大的发展,这些方法的成功说明目前伪造方法仍然存在着一些瑕疵和问题,而这些问题往往会成为伪造检测的突破口.
第四,从检测结果来看,目前绝大多数方法的准确率指标都已达到95%,但是这些指标都是在公开数据集上得到的,在实际互联网环境中会有较大幅度的下降,准确率只有70%左后.

表2 检测方法结果分析
4 总结与展望
伪造检测的相关研究对维护社会稳定具有很大的意义,不同于其他的检测任务,不能简单地依赖人工审核,部分伪造图像的真实度已经超过人眼识别的能力,使用基于计算机视觉的算法进行自动鉴伪已经迫在眉睫.本文对现有的伪造检测数据集以及检测算法进行了梳理和总结,并对其检测效果进行了对比和分析,最后本文根据该领域存在的一些问题对未来进行了展望.
目前学术界对该方向的探索多以分类为主,以寻找更好的特征为主要手段来提高检测效果.现有的伪造检测多使用公开的伪造数据集进行评测,避免了在实际使用中面临诸多问题,如网络中传输引起的压缩问题、分辨率问题、噪声干扰问题、模型泛化性问题等.接下来本文从实用角度提出3个发展方向,希望能对未来的研究提供一些参考.
1) 基于人脸身份信息的伪造检测.
该方向的算法有着很高的实用价值.一方面,目前互联网中的数据是海量的,因此对互联网中所有的数字媒体都进行伪造检测是不现实的,需要耗费大量的计算资源,另一方面国家领导人、军政要人、金融系统中的重点人物等的伪造检测需求是非常急迫的,有关这类关键人物的伪造视频会严重破坏社会稳定.另外基于人脸身份信息的伪造检测可以利用真实人脸进行参考,因此在检测精度和泛化性上存在一定的优势.现阶段基于人脸身份信息的算法[30,77]还处于探索阶段,本文认为如何充分利用人脸身份信息提高伪造检测的效果,对伪造检测实用场景下的研究具有很大意义.
2) 伪造视频溯源研究.
伪造算法在生成伪造图像的过程中会留下伪造痕迹,而且不同的伪造方法在产生的痕迹上往往不同,因此通过挖掘指纹的方法[58]进行伪造检测会具有更好的可解释性,并有利于在源头对伪造视频进行控制.溯源算法的研究不同于传统二分类伪造检测,其尝试发现伪造算法之间微小的差异,有助于探索伪造图像的本质特点.
3) 伪造对抗攻防.
大部分伪造视频具有一定的恶意性,伪造者为了让伪造视频传播得更广泛,很可能对伪造检测模型进行攻击.当对伪造视频通过恶意手段增加对抗噪声后会导致鉴伪模型精度下降,甚至出现直接判错的情况[83].对抗攻击与伪造方法结合,将是伪造检测的另一大威胁,未来如何在对抗环境下进行伪造检测也将成为该方向的一个研究重点.
