一种改进的嵌入式特征选择算法及应用
2022-03-22武小军周文心董永新
武小军,周文心,董永新
(同济大学经济与管理学院,上海 200092)
近年来,人工智能技术的发展和应用呈现爆发式地增长,利用人工智能技术训练辅助决策模型,协助人类完成各种复杂任务已经成为重要的理论研究和实践应用前沿。在决策模型训练的过程中,大数据集中的特征选择是一个影响人工智能决策模型效果好坏的重要影响因素,良好的特征选择不仅能够提高模型预测的准确度,还能够提升模型训练的速度[1]。例如:Amoozegar和Minaei-Bidgoli[2]提出了改进多目标优化粒子群优化算法,并将该算法应用到有几百个特征的数据集上,结果表明该算法在训练速度上相较于其他算法有明显优势,且预测准确率也令人满意。总体来看,特征选择算法不仅可以应用于监督学习中的回归问题[3]和分类问题[4],而且可以提高无监督模型预测的准确性[5],因此大量学者在这个领域进行了深入地探索。
Chandrashekar和Sahin[6]总结认为特征选择算法主要有以下三种方法:过滤法(filter)[7]、嵌入法(embedded)[8]和包装法(wrapper)[9]。过滤法主要应用于数据预处理阶段,该方法将所有的特征按照其得分从高到低进行排序,排除得分较低的特征;嵌入法需要先使用某些机器学习的算法和模型进行训练,得到各个特征的权重,再根据权重来选取特征;包装法让算法自己决定使用哪些特征,是一种特征选择和模型训练同时进行的方法。
嵌入法是一种应用比较广泛的特征选择算法,有许多文献都将其应用到基于支持向量机算法(SVM)的拟合模型构建的研究中。例如:Jiménez-Cordero等[10]提出的嵌入最小-最大值特征选择算法通过搜索策略优化了核函数中的γ,将γ大于0.01的特征保留了下来,形成了最优的特征子集,数值实验表明,该文提出的算法对二分类问题比较有效。又如:Maldonado和López[11]提出了两种类型的罚函数,并基于牛顿法和线搜法提出了改进优化算法来对凹函数进行优化,其方法在绝大部分数据集中,结合SVM方法都较于使用所有特征时模型效果更好。
尽管嵌入特征选择算法已经受到很多学者的关注,但更多的是对二分类问题的研究,对基于多分类问题的最小-最大值特征选择算法的研究还略显不足。本文拟对此问题进行深入探讨,提出一个新的改进算法,并将其应用于钢板缺陷识别工程数据集,以验证算法的有效性。
1 多分类支持向量机与改进嵌入最小-最大值特征选择算法
1.1 多分类支持向量机
首先简要阐述二分类SVM问题:给定标签分别为+1、-1的数据,通过对已知数据集进行训练,预测未知问题。对每组数据i∈S,S代表包含N个数字的集合{1,2,..,N},输入特征xi,xi∈Rm,标签yi∈{+1,-1},yi是xi的类标记。已有大量文献详细介绍了SVM[12-14],故本文不再赘述模型的推导。非线性SVM的原始形式如下:

式中:C为正则项系数,通过非负松弛变量ε对误分类点进行惩罚。Ф是映射函数,将原数据集中的xi映射到高维空间中使问题线性化。但在绝大部分情况下,Ф没有显式。基于此特点,学者考虑通过引入对偶问题和核函数求解(1)。已有许多文献系统地介绍了原问题的对偶问题[15],故本文不再赘述。原问题的对偶问题如下:

式中:λ=(λ1,...,λN)T是拉格朗日乘子向量。核技巧(kernel trick),即引入核函数K(xi,xj)=Ф(xi)′Ф(xj)(Rm×Rm→R)替代Ф,其中(·)’表示向量转置,且K(xi,xj)具有显式。(2)是凸规划问题,因此可以由数学规划软件求得全局最优解。
基于二分类SVM,学者提出多分类SVM,描述如下:给定含N个样本的训练集X={(x1,y1),...,(xN,yN)},其中,xi是k维特征向量,yn∈{1,2,...,M},n=1,...,N。Hsu和Lin指出,解决多分类SVM主要有两种方法:one-against-one(一对一)方法和one-against-all(一对多)方法[16]。有学者指出,一对一方法更适合实际应用[16],同时也是LIBSVM库采用的方法[17]。因此,本文选择使用一对一方法求解多分类SVM问题。
一对一方法在每两个类之间均训练一个二分类SVM,故共需训练个二分类SVM。对于第i类和第j类数据,训练一个SVM即求解以下二次规划问题:

其中,t是第i类和第j类并集的索引。定义dijt=1,如果yt=i;dijt=-1,如果yt=j。不加证明地给出式(3)的对偶形式如下

1.2 改进嵌入最小-最大值特征选择算法
基于Jiménez-Cordero等[10]提出的嵌入最小-最大值特征选择算法,Onel等[18]提出的特征选择算法,提出了一种适用于多分类任务的改进嵌入最小-最大值特征选择算法。引入0~1变量zu∈{0,1},u∈{1,2,...,N},当选择特征i时,zi=1,否则zi=0。优化目标除极大化预测的准确率外,还极小化使用的特征数量,从而降低模型训练的成本。将问题(4)改写如下:

为了在预测准确率和模型复杂度之间进行权衡,提出如下的多目标优化问题。
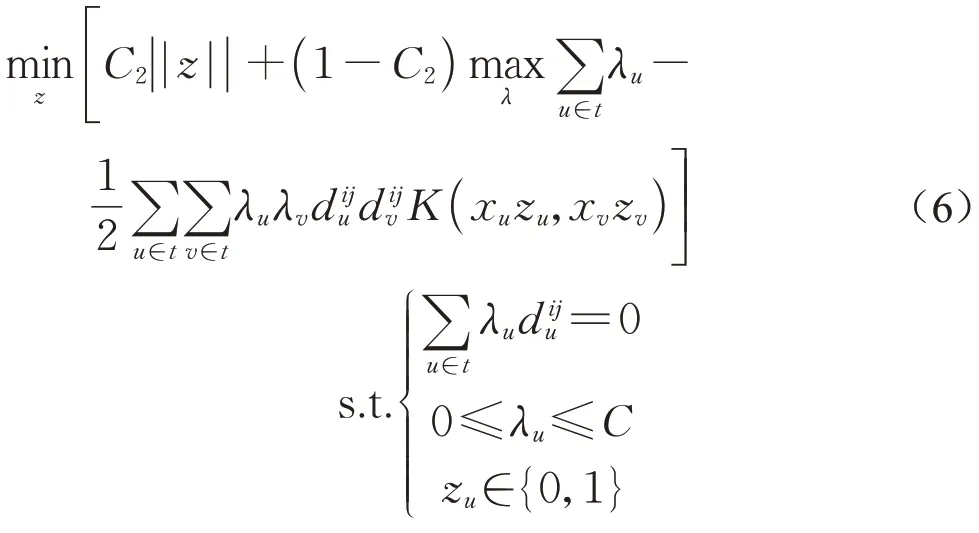
其中,C2为超参数,取值范围位于[0,1]之间。如果C2趋近于0,则模型以极大化预测准确率为目标,模型的复杂度会上升;如果C2趋近于1,模型将使用少量的特征进行训练,会牺牲模型的准确率。
问题(6)的等价问题如下:
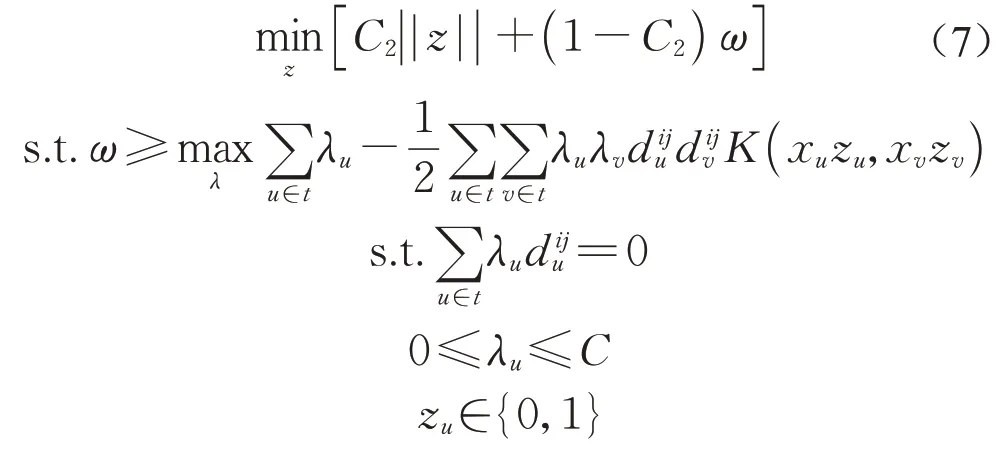
问题(7)是一个由上层问题和一个下层问题叠加起来的一个双层优化问题。根据Mangasarian和Musicant[19]对拉格朗日对偶性的证明,这里不加证明地给出下层问题的拉格朗日函数。设下层问题的第一个约束对应的拉格朗日乘子为v,第i类和第j类数据一共有a个,约束λu≥0对应的拉格朗日乘子为,约束λu≤C对应的拉格朗日乘子为αCu。下层问题的拉格朗日函数为

记diag(dij)是一个a行a列,主对角线上是dij的各个元素,其余位置全是0的矩阵。记GZ=diag(dij)Kdiag(dij),其中K是核函数。则式(8)可以写为

式中:e表示分量均为1,且和λ同阶的列向量。由Karush-Kuhn-Tucker,KKT条件可得

式(12)目标函数第二项的目标是最小化w,w是(11)目标函数的下界,所以式(12)等价于
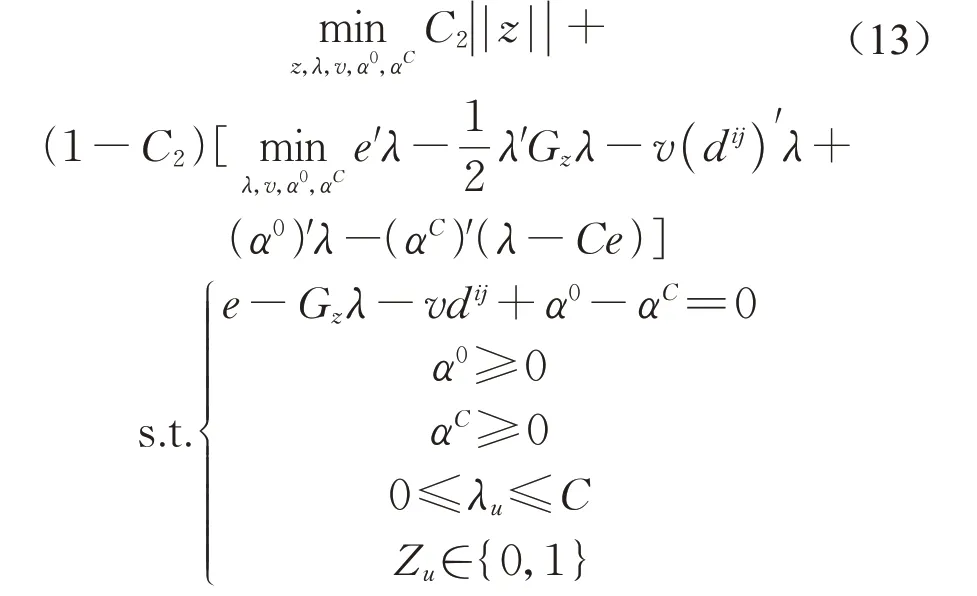
1.3 搜索策略
本节提出的算法用于求解优化问题(13)。由于使用一对一方法,需要训练个SVM,即次外层循环。首先,为了避免过拟合,需要划分出训练集和测试集,分别用͂和Stest表示,这个过程会重复N次,同时,需要确定超参数C2。最优的C2可以通过枚举不断调试。
其次,将S͂分为训练集和验证集,用Strain和Sval表示。对于C和γ进行网格搜索(grid search),在Strain上求解问题(4),并在Sval上计算模型的准确率。搜索完所有C和γ后,给出Sval上预测准确率最高的对应的C和γ,且γ是求解问题(11)的初始值。
接下来,使用C和γ在͂上求解问题(11),返回λ,v,α0,αC的初始值。
获取到上述初始值后,在͂上求解问题(13),得到z*,λ*,v*,(α0)*,(αC)*。并计算在Stest上的模型准确率。
由于0~1变量的引入,在训练第i类和第j类数据时可以直接得到相应最优特征子序列。但由于总共要训练个SVM,因此就不能直观地通过0~1变量的取值选取用于训练的特征。文献[20-22]指出,可以通过信息增益(Information gain,IG)选取最优特征子序列。考虑一个分类系统,以类别C为变量,其可能的取值有C1,C2,...,Cn,每个类别出现的概率分别为P(C1),P(C2),...,P(Cn),其中n是类别总数。此时分类系统的信息熵为

假设T代表特征,记t代表T出现,则根据全概率公式可得

式中,P(t)代表特征T出现的概率代表特征T不出现的概率。由此可以推出信息增益的公式如下:
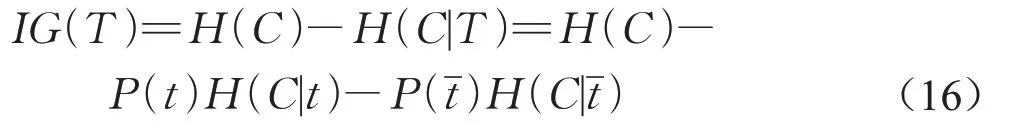
通过设定阈值,可以判断应该选择哪些变量作为训练多分类SVM的特征。以上算法的伪代码在算法1中展示。
2 粒子群优化算法
粒子群优化算法(particle swarm optimization,PSO)是一种经典的启发式算法,使用无质量的例子来模拟鸟群里的鸟。粒子本身有两个属性:速度和位置。每个粒子在搜索空间中单独搜索最优解,记录其所获得的最优值,并将该值与粒子群里的其他粒子共享,经过比较后将最优粒子所获得的最优值作为整个粒子群本轮的全局最优值。而粒子群中所有非最优粒子根据自己找到的个体最优值和整个粒子群的全局最优值来调整其速度和位置。在求解非凸的子问题时,如果使用数学规划软件无法在规定的24h内返回最优解,则改为使用粒子群优化算法求解。

结束对于j的循环
结束对于i的循环
初始状态下,粒子群中所有粒子的均为随机,通过迭代找到最优解。每一轮迭代中,每个粒子根据其个体最优值(pbest)和整个粒子群的全局最优值(gbest)更新自身属性。在找到上述两个最优值后,每个粒子将通过以下两个公式来更新其位置和速度,即
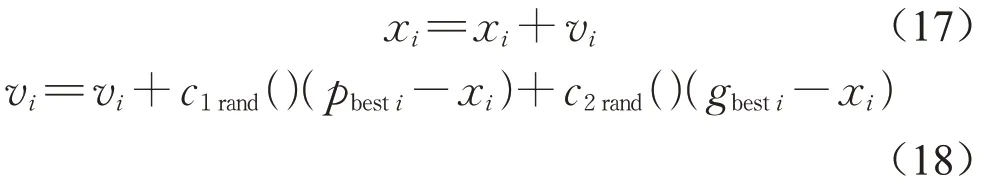
式中:i是粒子群中粒子的个数,i=1,2,...,N;xi是粒子的当前位置;vi是粒子的速度;c1、c2是学习因子,通常均设为2;rand()是介于(0,1)之间的随机数。此外,式(19)也可用以更新粒子的速度

式中:ω是超参数,代表惯性因子,其值非负。图(1)为PSO算法的流程。

图1 PSO算法流程图Fig.1 The flow chart of PSO algorithm
3 数值实验
3.1 钢板缺陷识别工程数据集介绍
钢板是一种重要的工业原材料,其质量很大程度上影响了产成品的质量。本文使用的钢板缺陷识别数据集来自于可以从UCI的网站http://archive.ics.uci.edu/ml下载。该数据集共包含27个特征,7个类别,1941组数据,其特征名称列于表1中。

表1 数据集中的特征名称Tab.1 The name of features in dataset
这是一个多分类问题,共含有7个类别的标签。每个标签的名称及其数量如表2所示。

表2 标签的名称及其数量Tab.2 The name of classes and its numbers
3.2 数据预处理
本数据集中,待分类的类别共7类,以独热编码(one-hot encoding)的形式存储。首先把类别转换成一一对应的形式,即将原数据集中的7列转换成1列。其次,考察特征之间的相关性,排除存在共线性的特征。本文中,根据皮尔逊相关系数进行判断,排除相关系数绝对值大于0.95的特征。各个特征之间的相关系数如图2所示。经过判断,决定排除2、4、6、8、13号特征。

图2 各个特征之间的皮尔逊相关系数Fig.2 The pearson correlation coefficients among different features
由于本文采用一对一方法,因此在训练每个SVM时,都需要将yt=i的标签设为+1,将yt=j的标签设为-1。以上即为数据预处理部分。
3.3 实验设置
本文的所有程序均是在Windows 10环境下,使用Python 3.8编写。对于提出的优化问题,通过调用Gurobi 9.1.1或使用PSO算法进行求解;如果调用Gurobi求解的时间超过24h,即停止计算,选择启发式算法进行求解。
3.4 实验结果
按算法1,先解式(4),对C和γ进行方格搜索。假设C={10-2,10-1,1,..,10,102},γ={10-2,10-1,1,...,10,102}。经过多次实验,得到当C=5,γ=0.1时,模型的平均得分最高。取其中一次的实验结果写入表3(保留两位小数)。

表3 C和γ进行方格搜索得到的模型预测准确率Tab.3 The accuracy on test set using grid search with C andγ
如2.2节所述,超参数C2的不同取值可以在模型复杂度和模型准确率之间进行权衡。选择C2的所有可能取值为0.01,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9。由于设定超参数时尚未应用特征选择算法,意即固定z=1,取C=5,γ=0.1,求解问题(13)。根据文献[13]所述,如果固定γ,那么问题(17)就是一个凸规划问题,可以调用Gurobi进行求解。在S͂上进行求解,在Stest上进行测试,得到的C2与测试集上准确率如图3所示。

图3 C2和模型准确率之间的关系Fig.3 The relationship between C2 and accuracy on test set
从图上可以看出,实验结果同先前假设基本一致,随着C2不断增大,模型在测试集上的准确率不断降低,当C2=0.9时,模型在测试集上的准确率降至44.60%。在该数据集中,选择超参数C2=0.2,能够较好地平衡模型复杂度和模型预测准确率之间的关系。需要强调的是,超参数的选取同数据集本身相关。如文献[10]所述,在数值实验中,将特征选择算法应用到不同数据集时,所选取的C2是不同的,因此作者建议超参数C2应该由用户选取。
选取完C2后,进入到算法1的流程中。由于0~1变量的引入,导致问题(11)和问题(13)的目标函数和约束条件均是非凸的。调用Gurobi解决问题(11)和问题(13)时,未能在规定的24h内求解出可行解,因此使用PSO算法对两个问题进行求解。
本数据集中,选择学习因子c1、c2等于2,惯性因子ω=0.3,粒子个数为22,迭代次数为100次。先训练第i类和第j类数据之间的SVM,返回在该SVM情况下选择的特征。然后使用信息增益算法对返回的个结果进行评估,从而选择合适的变量作为多分类SVM的最终特征。设定信息增益的阈值分别为0.2,0.5,0.8,1,大于该阈值的特征即被选中。被选中特征的数量和模型在测试集上的准确率如图(4)所示。
从图(4)可以看出,随着信息增益阈值不断增大,模型在测试集上的准确率不断变低。因为阈值变大,选取的特征数量会减少,从而导致有用信息的丢失。该数据集中,选取信息增益阈值等于0.5的变量作为训练的特征,这时选择的特征的编号是2,3,4,5,6,7,8,10,11,12,13,14,16,17,19,20。

图4 信息增益阈值和模型预测准确率之间的关系Fig.4 Relationship between threshold of information gain and accuracy on test set
最后将改进嵌入特征选择算法同未经特征选择的多分类SVM进行比较。作为基本假设,改进嵌入特征选择算法在预测准确度上不会优于基准算法且在可以接受的范围内,而训练的速度会快于基准算法,快的“程度”具体取决于用户选取的信息增益阈值。经过实验,基准算法训练SVM的时间是1.19s,在测试集上的准确率是73.8%;而使用改进嵌入特征选择算法训练SVM的时间是1.03s,在测试集上的准确率是71.2%。考虑到sklearn的库函数经过高度优化,且这个数据集的特征数目并不多,如若推广到更高维的数据集中,则提出的特征选择算法在多分类SVM问题中具有广泛的应用前景。
4 结论与不足
本文基于现有多分类SVM研究中的不足,提出了改进嵌入最小-最大值特征选择算法,在最小化特征数量的同时最大化模型预测的准确率。由于引入了0~1变量,该优化问题变成了组合优化问题,在限定时间内未能用数学规划软件求解得出全局最优解,因此选择使用启发式算法求解。
数值实验结果表明,本文提出的算法在该数据集上可以在牺牲可接受程度预测准确率下降的条件下换取模型训练时间的显著下降。
本文将SVM问题中的核函数限定为高斯核函数。然而,应用其他的核函数可能会得到不一样的结论。此外,提出的算法仅仅被应用在一个数据集中,可以考虑使用更多的经典数据集来验证其训练时间和训练精度。最后,未来的研究可以考虑放弃该模型中的0~1变量,转而使用其他评估方法来选取特征,因为这样可以充分利用到凸函数的性质,获得更令人满意的结果。
作者贡献声明:
武小军:提出选题,设计论文框架。
周文心:负责整理文献,算法构建,论文撰写与修订。
董永新:论文算法改进。
