基于生成对抗网络的水墨动画电影风格化方法
2022-03-22黄东晋俞乐洋刘金华丁友东
黄东晋 李 娜 俞乐洋 刘金华 丁友东
(上海大学上海电影学院,上海 200072)

水墨是中国特有的绘画形式,通过墨色的焦、浓、重、淡、清五色传达无限的情感。不同于西方的水彩、油画,中国水墨画用少量笔触来描绘特定的风格或场景,表现出艺术家的创作意图和艺术个性。传统水墨动画由艺术家参与制作,创作流程较为复杂,创作周期也相对冗长。水墨动画是在传统水墨画的基础上,将水墨与动画合理结合。
随着计算机技术的发展,运用三维技术与水墨的结合,在工业界出现了一些优秀的水墨动画短片,如 《鱼戏莲》《秋实》等,在科研界出现了关于风格迁移的研究。在神经风格迁移之前,这项研究被称为非真实感渲染 (Non-photorealistic Rendering,NPR),它使用不同的画笔来输出艺术笔触,并像手绘一样描绘特定对象。杨丽洁等提出一个动画生成工具,通过重建中国水墨画中的笔画,动态模拟水墨画原有的绘画过程。2020年,他们又提出一个绘画工具,通过对照片上粗略勾勒的线条进行风格化,生成具有花卉水墨画风格的艺术笔画5。
风格迁移是近年来计算机视觉领域的一个研究热点。在给定内容图片和风格图片的条件下,风格迁移旨在使用风格图片的纹理风格对内容图片进行渲染,同时保证其内容的原始语义结构。以往的风格迁移多集中于西方艺术,本文聚焦于中国水墨动画的研究,提出一种新的基于生成对抗网络的水墨动画电影风格化方法,实现将艺术家绘制的水墨风格画从一张图片迁移至整个视频序列。利用基于patch的训练方式,通过关键帧的学习,既不需要冗长的预训练,也不需要大量的训练数据集。在生成网络中使用群组归一化替换批量归一化,以减少batch size的影响,加快网络的迭代收敛速度。此外,加入深度视频先验算法解决生成视频闪烁的问题。
1 相关工作
风格迁移技术主要分为传统风格迁移技术、基于卷积神经网络的风格迁移和基于生成对抗网络的风格迁移。
传统迁移技术主要包括早期的NPR和纹理迁移。NPR根据渲染方式的不同分为笔触渲染、图像滤波和图像类比三类。Meier提出了一种基于笔触渲染的画笔模型来模拟油画的生成过程;Winnemöller等引入双边滤波器和高斯差分滤波器来自动生成卡通风格的图像;Hertzmann等首次提出图像类比的概念,在监督下改变原图的风格。纹理迁移主要用于纹理合成,输入图像基于参考图像填充纹理,使生成的图像具有与样本图像相似的纹理风格,适合处理纹理简单的图像。Efros等通过使用马尔科夫随机场模型,选择距离像素最近的场的纹理段进行填充。这种方法每次填充一个像素值都需要遍历纹理段,时间成本过高。为了解决上述问题,Wei等使用矢量量化来提高时间性能;Han等提出一种新颖的基于样本的多尺度纹理合成算法,实现基于不同尺度的低分辨率图像的纹理合成。上述传统的风格迁移技术可以生成多种艺术作品,但这些技术只考虑了低层细节特征,没有提取图像高层语义特征;同时,模型泛化能力较差,只能以特定的风格进行渲染。为了解决这些不足,神经风格迁移应运而生。
Gatys等首次提出基于深度学习的神经风格迁移,利用预训练的VGG-19模型提取图像的内容特征,通过Gram矩阵计算图像的风格特征。内容和风格分开计算,噪声图像通过迭代优化,逐渐具有一副图像的内容细节和另一幅艺术图像的风格特征。这种方法比较灵活,可以组合任意艺术图片和内容图片,但是一张图片的生成需要多次迭代优化,耗时较长。为了减少图像风格化的计算时间,Johnson等提出了一种基于模型迭代的风格迁移方法,比Gatys等基于图像迭代的方法快三个数量级。基于模型迭代的方法通过大量图像训练特定风格的前馈生成网络,计算负担转移到模型的学习阶段。经过训练的模型可以实现实时、快速的风格迁移。之后,基于此方法,各种改进或扩展的方法层出不穷。Du moulin等提出了CIN(Conditional Instance Nor malization),即基于训练好的风格化模型,可以在IN(Instance Nor malization)层进行仿射变换,得到不同的风格效果,实现单一模型迁移多种风格。受CIN层的启发,Huang等提出了 AdaIN(Adaptive Instance Nor malization)。AdaIN利用迁移通道均值和方差的统计值在特征空间进行风格迁移,首次实现实时任意风格迁移。上述基于卷积神经网络(Convolutional Neural Net wor k,CNN)的图像风格迁移方法,得益于深度卷积神经网络的特征提取能力。通过提取图像的抽象特征表示,利用特征分布的统计量作为图像风格的描述,可以灵活高效地迁移图像风格。这种描述方法可以很好地表征风格,但它依赖于具有巨大参数的特征提取网络。
随着深度学习的进一步发展,生成对抗网络 (Generative Adversarial Net wor k,GAN)凭借其强大的生成能力在图像翻译的应用中取得了巨大的成功。与基于CNN的风格法不同,基于GAN的图像风格迁移方法不需要任何预先定义的描述计算风格。鉴别器拟合图像数据隐式计算风格,实现图像风格迁移。此外,通过对抗训练来适应图像数据的分布,使得图像的风格迁移变得更加真实。作为图像翻译的代表作,Isola等提出的Pix2Pix模型,使用大量配对图像进行监督训练,得到一对一的图像翻译网络,可以很好地完成图像风格迁移。但是Pix2Pix的训练需要大量的成对的图像数据,极大地限制了其推广应用。Zhu等提出了一种无监督对抗网络Cycle GAN,它包含两对生成对抗网络,用于双向域转换。通过循环一致性损失来去除域之间的配对约束,有助于更好地保持图像的内容结构。He等基于生成对抗网络,使用空白、笔触和墨水清洗损失实现了照片到中国水墨画的翻译。最近,Xue等将中国山水画的创作分为草图生成和上色两个阶段,基于Sketch GAN生成中国山水画线稿,基于Paint-GAN实现线稿到图像的翻译。然而,上述所有基于GAN的图像风格迁移方法都需要预先收集足够数量的风格图像,这在实际应用中是一个比较困难的问题。针对这一问题,Texler等提出基于patch的训练策略解决小样本学习问题。受他们的启发,将这种训练策略引入到本文方法中,然而直接将其应用到水墨动画风格迁移时,生成的动画会出现闪烁问题,这正是本文接下来重点解决的问题。
风格迁移进一步扩展到视频领域的工作称为视频风格迁移,除了完成每一帧的风格迁移之外,还要考虑生成视频的连贯性,解决视频闪烁问题。大多数视频风格迁移方法都依赖于现有的图像风格迁移方法。Ruder等在Gatys等方法的基础上,加入光流约束计算运动物体的边界,实现风格化视频的连贯性。虽然这种方法解决了视频闪烁问题,但光流计算带来了更多的计算开销,降低了风格化的速度。Gao等采用CIN进行多种风格的视频传输,他们结合了一个Flow Net和两个Conv LST M模块来估计光流并引入时间约束。然而通过光流计算实现上述时间约束,光流估计的精度会影响风格化视频的相干性。同时由于使用的基本图像风格迁移方法,风格的多样性也受到限制。Li等以数据驱动方式提出一种可学习线性变换矩阵的风格迁移算法,它能够实现任意图像与视频的风格迁移。然而,其风格迁移后的结果中的风格却不那么明显。为了避免使用光流计算,我们采用深度视频先验算法,来实现稳定的生动风格模式的视频风格迁移。
2 本文方法
本文研究内容如图1所示。给定一段N帧视频序列I,指定一组关键帧I∈I,对于每个关键帧I,提供风格化后的关键帧S,实现将S的风格迁移到整个视频序列I中。Texler提出基于patch的训练策略既不需要冗长的预训练过程,也不需要大量的训练数据集。他们展示了仅使用少数风格化的样例来训练网络,实现视频风格迁移。本研究尝试应用同样方法来实现水墨动画风格迁移,但是产生了视频闪烁的问题。因此,本文提出一种新的基于生成对抗网络的方法,实现水墨动画风格迁移。本文方法主要分为三步:首先,采用基于patch的训练策略,扩大数据集;然后,基于生成对抗网络实现风格迁移;最后,将风格化后的视频序列采用深度视频先验算法,解决生成视频闪烁问题。

图1 本文研究内容
2.1 数据集的构建
由于采用少量的数据集,为了避免网络的过拟合,本文采用基于patch的训练策略构建数据集(图2),从关键帧中随机采样较小的矩形patch作为生成器的输入,将生成的风格化图像分batch馈送给判别器以计算损失并反向传播误差。patch的裁剪是随机的,这样模拟了一个大且多样的数据集用于训练,防止网络过拟合。这种训练策略类似于Ulyanov等用于纹理合成的训练策略,即在单张样例图像上训练具有有限感受野的网络,然后使用它来推断更大的纹理,从而保留样例图像的基本低级特征。这个关键思想是利用神经网络的卷积特性——即使网络是在较小的patch上训练的,也可以用来合成较大的图像。

图2 基于patch的训练策略
2.2 网络结构
本文模型采用生成对抗网络设计,包括生成器和鉴别器。生成器学习水墨风格的数据分布,生成水墨风格的图像;鉴别器将生成图像和真实图像作为输入。通过学习尽可能区分生成图像和真实图像,生成器最终生成鉴别器无法区分的、符合真实数据分布的图像。
生成器结构如图3所示,由3个卷积层、7个残差模块层、2个上采样层和2个卷积层组成。通过3个卷积层提取图像特征,通过残差模块进行图像的风格迁移,然后通过上采样层还原图像的特征,最后通过卷积层生成图像。除最终输出层外,所有非残差卷积层均使用群组归一化处理 (Group Normalization)和Leaky Rel u激活函数。采用群组归一化操作减少batch size的影响,加快网络的迭代收敛速度。同时,激活层采用Leaky Rel u函数解决了正区间梯度消失和某些神经元不被激活的问题。最后采用tach激活函数保证输出图像在0到255之间。此外,在生成器网络的编解码器之间增加跳跃连接。通过跳跃连接,编码器低层所捕获的特征可以传输到解码器的更高层,为低层特征提供了更快的传输通道,减少了低层特征信息在传输中的丢失,尽可能地保持图像内容。

图3 生成器网络结构
鉴别器网络结构如图4所示,本文使用Patch-GAN模型,前4个卷积层提取输入图像的特征,最后一个卷积层将其转换为一维特征向量后输出,实现判别的目的。

图4 鉴别器网络结构
本文的目标是学习关键帧X和其水墨风格对应帧Y之间的映射函数F。给定成对的训练样本(x,y),其中x∈X和y∈Y,我们学习F的目标包含三个不同的损失:用于将生成图像的分布和风格化图像的分布进行匹配的对抗损失L、直接在风格化输出上计算的色彩损失L、根据I mage N-et上预先训练的VGG网络提取的特征所计算的感知损失L。
·对抗损失L
我们使用以下目标函数对映射函数F及其鉴别器D的输出应用对抗损失,得到更稳定的训练。

式 (1)中,X、Y为源域X域和目标域Y域;x和y分别是X域图像和图像Y域,F为X域到Y域映射的生成器,D为判别X域到Y域生成图像的判别器。x~p(x)和y~p(y)表示数据分布。
·色彩损失L
虽然单靠对抗损失就足以学习映射F,但当在网络输出和原始风格图像之间计算额外的L损失时,生成器更好地保持稳定和加快训练,如式 (2)所示:
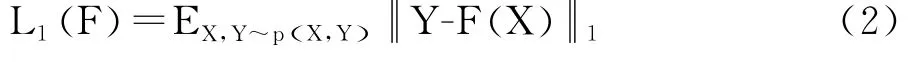
·感知损失L
通过使用在不同深度的I mage Net上训练的VGG-19模型的特征图上计算出的感知损失,可以实现额外的改进:

式 (3)中,VGG(·)为第d层的特征图,Y表示输入图片,F(X)表示生成图片为输入数据。D是VGG-19的深度集,在本文中,D=0,3,5。
·目标函数L
我们最终的目标函数如下:

式 (4)中,超参数λ、λ和λ是控制三个损失函数相关重要性的权重因子,它们会影响不同损失函数的相对重要性。
2.3 闪烁后处理算法
处理时间一致性是视频风格化方法的中心任务。当独立地对单帧进行风格化时,生成的风格化动画通常包含强烈的时间闪烁。虽然这种效果对于传统的手绘动画来说是很自然的,但是当观看较长时间时,观察者可能会感到不舒服。本文将上述风格迁移后的视频采用深度视频先验 (Deep Video Prior,DVP)算法来解决生成视频闪烁问题。DVP指的是在利用视频来训练卷积网络的过程中,视频不同帧之间对应patch的网络预测输出是一致的。视频中的闪烁现象类似于时域中的 “噪声”,可以通过DVP来进行校正。
设I为时间步长为t的输入视频帧,通过映射函数F可得到相应的处理帧P=F(I)。闪烁后处理算法旨在设计一个函数g为P生成时间一致的视频O,算法流程如图5所示。使用一个全卷积网络g(· ;θ)模仿原始算法F,训练只使用一个视频用于训练g,并且在每次迭代中只使用一帧。在训练时对g进行随机初始化,要实现的目标如式 (5)所示:

图5 深度视频先验算法

式 (5)中,L测量g(·;θ)和P之间的距离。当O接近P且闪烁被过度拟合之前,停止训练。在本文中g采用U-Net网络,L采用感知损失。
3 实验结果与分析
本文实验硬件环境使用Intel Xeon E5-2620处理器,内存为64GB的NVIDIA TITAN XP显卡。软件环境采用64位Ubuntu操作系统,Python 3.7、CUDA 10.2、Py Torch 1.6.0等相关工具包。使用Adam优化器,学习率设置为0.004,迭代训练200次。对于超参数,设置λ=0.5、λ=2、λ=6,patch size大小设置为36pix。
3.1 实验结果对比
为了验证本文提出的方法对水墨动画的风格迁移的有效性,主要进行三组对比实验定性和定量的评估本文方法与Texler等的算法。选用动画电影《大鱼海棠》的某一分镜头作为第一组实验数据,总长9s。使用FFmpeg将分镜拆分成一帧一帧的图像,总计拆成207帧图像。在这段视频中,选定关键帧为第1帧、第65帧和第106帧,因为这三帧中人物变化较大。图6展示了第1帧、第65帧、第106帧的原始图片和将其分别风格化后的风格图片效果。图7为Texler方法和本文方法实验结果对比图。从图7第一、二列可以看到,Texler等的方法没有进行视频去闪烁,生成的结果右上角都存在噪点。第三、四列本文方法生成的图片效果清晰,在运动物体上有很好的稳定性,能很好地去除闪烁。

图6 多张关键帧风格化成的风格图片效果

图7 第一组实验结果对比图
另外选用 《妖猫传》的一个分镜头作为实验数据,总长为13s,用FFmpeg处理成302帧。因为这个分镜场景变化简单,所以关键帧只选择其中一帧,如图8所示。图8中对关键帧采用不同的水墨风格,在第二组和第三组对比实验中,我们将同一个分镜风格化成不同的水墨风格。图8(b)的风格迁移结果如图9所示,第一列Texler等的方法天空出现噪点。图8(c)的风格迁移结果如图10所示,可以看到第一列Texler等的方法左上角天空中的云比较模糊。整体上来说,本文的方法迁移效果质量完成度高,在运动的物体上具有很好的稳定性。

图8 同一关键帧风格化成不同的风格图片效果

图9 第二组实验结果对比图

图10 第三组实验结果对比图
3.2 客观评价
为了进一步验证本文算法的有效性,客观评价Texler等人的方法与本文方法的差异性,将图7、图9和图10三组对比实验生成的关键帧,与实验中提供的风格化后的关键帧S(见图1),使用峰值信噪比PSNR(Peak Signal to Noise Ratio)和结构相似性SSI M(Str uctural Si milarity)进行计算。PSNR用于衡量图像之间的差异,评估图像的生成质量,单位为d B。SSI M用来衡量图像的结构相似性,按人眼的感受来衡量两张图像的相似性,比传统方式更符合人眼视觉感知。PSNR和SSI M这两个值越大代表风格化的图像质量越高。
从表1可以观察出,在三组对比实验中,本文方法在PSNR和SSI M分数都要高一些,说明本文方法生成的图像质量更高,生成的图像与实验中提供的风格化后的关键帧图像具有更高的相似性。从而验证了本文方法在水墨动画风格迁移的有效性。
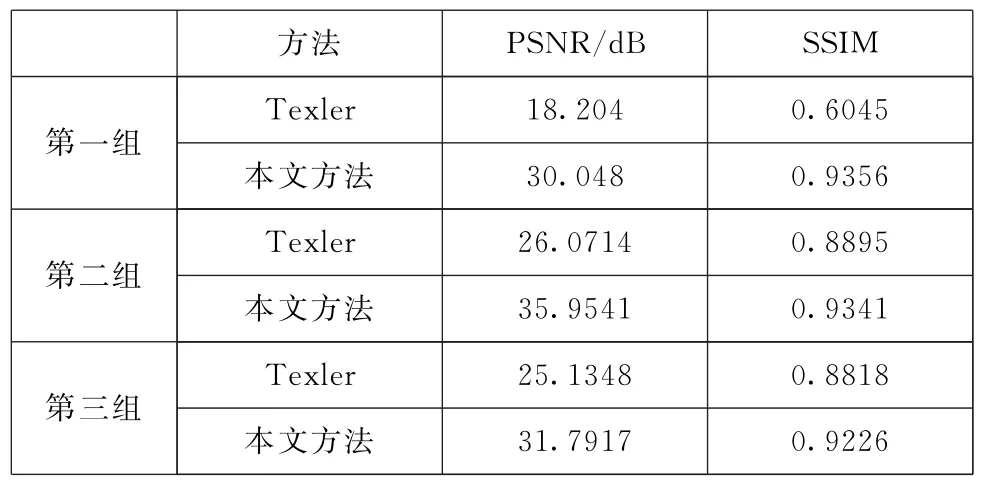
表1 三组对比实验定量分析结果
3.3 用户评价
除了上述实验结果的对比之外,本文还对水墨动画风格迁移结果进行视觉质量的用户评估:让20名参与者观看三组对比实验的生成结果。以风格化后的关键帧效果为标准,每段风格化视频从整体视觉质量和视频连贯性两个方面进行评分,总分为5分。计算每个视频的平均分结果如图11所示。根据评分结果来看,本文算法在两个方面的评分均高于Texler等人的算法。因此,本文提出的基于生成对抗网络的水墨动画电影风格化方法,既能表达令人满意的水墨风格,又能保证生成视频的连贯性。
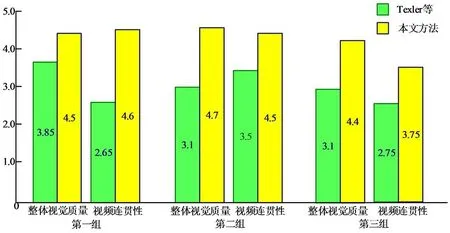
图11 用户评价平均分
4 结语
现有水墨动画风格迁移存在数据集不足、生成动画闪烁等问题。本文以水墨动画为研究对象,提出基于生成对抗网络的水墨动画电影风格化方法,通过关键帧的学习,很好地实现水墨动画风格迁移。针对数据集不足问题,采用基于patch的训练策略构建数据集;针对生成视频闪烁的问题,提出了加入视频先验算法进行解决。实验结果表明,该方法能够有效地将关键帧的风格迁移至整段视频,并产生较好的视觉效果。
下一步研究将继续优化算法,整合到水墨动画制作系统中,快速生成高质量的水墨动画电影,辅助艺术家的水墨动画创作。
