A new joint model for extracting overlapping relations based on deep learning*
2022-03-19ZHAOMinjunZHAOYaweiZHAOYajieLUOGang
ZHAO Minjun,ZHAO Yawei†,ZHAO Yajie,LUO Gang
(1 School of Engineering Science,University of Chinese Academy of Sciences,Beijing 100049,China;2 AI Lab of KnowLeGene Intelligent Technology Co, Ltd,Beijing 100088,China)(Received 23 March 2020;Revised 25 May 2020)
Abstract With the rapid developments of Internet technologies and popularization of Internet among daily activities, we are surrounded by all kinds of information every moment.Hence, to mine valuable information from massive data has always been a hotspot of research at home and abroad.In this environment, relationship extraction is an important subtask of information extraction, which purpose is to identify the relationship between entities from the text, so as to mine the structured information in the text, that is, fact triplet.In the text, entity overlapping and relationship overlapping are very common phenomena, but the existing joint extraction model cannot effectively solve such problems, so the paper proposes a new joint extraction model, which regards the relationship extraction task as consisting of entity recognition and relationship recognition of two subtasks.The two subtasks are identified using sequence labeling method and multi-classification method, respectively.In the joint extraction process, in order to fully mine the semantic information of the text, the part of speech(POS)and syntactic dependency(Deprel)features were added to the input layer of the model.Attention mechanism is also introduced in the model, which can eliminate the problem of long-distance dependence as sentence length increases.Finally, the paper conducts relationship extraction experiments on the NYT dataset and the WebNLG dataset.The experimental results show that the model proposed in the paper can effectively solve the problem of overlapping relationships and obtain the best extraction effect.
Keywords relation extraction; entity overlapped; joint extraction model; deep learning
Extracting relational facts from unstructured text is an important topic in natural language task, which is widely used in knowledge extraction and automatic construction of knowledge base.A relational fact is often represented as a triplet which contains of two entities and a relation between them, such as
To handle this task, there have been many previous methods which mainly divided into traditional methods and joint extraction methods.Traditional methods[1-2]handle this in a pipeline manner, which separate this task into pipelined subtasks: extracting entities first, and then recognizing relations between extracted entities.However, the pipeline framework ignores the relevance of entity identification and relation prediction[3].Meanwhile, solving the two subtasks in a sequence manner, it leaves the model open to potential error accumulation, since the results of entity recognition may affect the performance of relation classification.Joint extraction models[3-6]are to extract entities and relations together using one single model instead of two.With the success of deep neural networks, NN-based automatic feature learning methods have been applied to extract relations, which reduces the model dependency on manual feature selection.Recent studies show that joint learning model can effectively integrate the information of entity and relation, and therefore achieve better performance in both subtasks than the pipeline method.However, their methods cannot identify overlapping relations, which may lead to poor recall when processing a sentence with overlapping relations.
In the traditional methods of entity recognition and relation extraction, it is common to assume that there is only one relational triplet or multiple un-overlapped relational triplets in each sentence.From practical perspective, triplets, within one sentence, are overlapped in different ways, which is a common scenario and usually being neglected in models.Zeng et al.[7]proposed a method named Copy to tackle this matter.In their paper, they generalized three categories of the sentence based on the level of overlap between the extracted triplets: Normal, Entity Pair Overlap(EPO), and Single Entity Overlap(SEO).
In this paper, we still use the three categories of the sentence classification as Zeng et al.[7]to divide sentences which are illustrated in detail in Fig.1.S1 belongs to Normal class because none of its triplets have overlapped entities; S2 belongs to EPO class since the entity pair
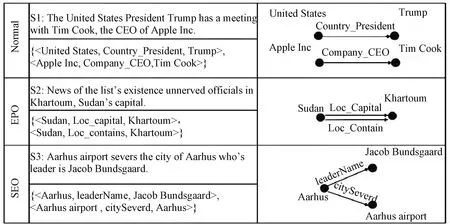
Fig.1 Examples of Normal, EPO, and SEO categories
We propose a new joint model to solves the overlapping relationship, which performs the two tasks of entity recognition and relation extraction simultaneously.In our model, the encoding of the source sentence is used for both entity recognition and relation recognition.It has been proved that models[8-9], which use deep learning methods such as CNN-and RNN-based and combine with Conditional Random Field(CRF)loss function, can achieve good performance in entity identification.We add attention mechanism into entity identification process, since the attention mechanism has been proved successful in capturing long-range dependencies recently.At the same time, in theory, the additional information, such as part-of-speech(POS)and dependency relations(Deprel), enriches the information contained within the input and increases the accuracy of the model.We conduct experiments to verify this theory by concatenating the corresponding vectors into embedding layer, the effect of relation extraction will be improved.In relation recognition task, we consider it as multi-label problem, which cannot be properly dealt with in the previous joint model.The multi-label problem is that an entity appears in variety of relation triples and the entity only mentioned once in the sentence.In our model, we annotate the corresponding relation of the two involved entities with the position of the last word of each entity, since the entity may be represented with multiple words.For example, as shown in Fig.2, the relationship of the relation triplet

Fig.2 An example of NER label and relation label
The key contributions of this paper are given as follows:
1)We proposed a new unified architecture of extracting multi-relations, which performs the entity identification and relation recognition task simultaneously.
2)Our model uses a multi-label method to deal with the overlapping relation problem and the difficulties of labeling the entity that contains multiple words.
3)Our model uses the attention mechanism and the input of this architecture contains more information such as part-of-speech(POS)and grammatical dependencies(Deprel).The overall performance on the multi-relation extraction from NYT dataset is improved 8% on F1 score compare to that from the Copy model.
1 Relation work
Extracting relational triples from a given sentence, without any entity annotation, is an important subject in natural language processing(NLP), because the relational structure is the basis of knowledge acquisition, knowledge construction and knowledge graphs.There are rapid and significant developments of knowledge graphs constructions, such as DBpedia[10]and Freebase[11], hence the accuracy of the relation extracted is more prominent than before.
Earlier works used the idea of pipeline to tackle this problem, they divided the relationship extraction into two separated tasks: Named Entity Recognition(NER)[12]and Relationship Classification(RC)[13].NER models are linear statistical models, such as Hidden Markov Model(HMM)and Conditional Random Fields(CRF)[14].Recently, several neural network structures[15-16]have been successfully applied to NER by recognizing the entity as a sequential token tagging task.Existing RC methods[17]can be divided into handcrafted feature-based methods and neural networks-based methods.
Joint learning model, a unified model, aims to extract entities and relations simultaneously.Recently, Miwa and Bansal[5]uses LSTM-based model to extract entities and relations which uses neutral network to reduce manual work.However, most existing neural models[3-5]implemented in joint learning of entities and relationships only through parameter sharing rather than joint decoding.In the proposed model, the joint learning model is conduct in a pipeline manner, to obtain the relationship triples, they still need to pipe the detected entity pairs to the relationship classifier to identify the relationships between the entities.Zheng et al.[17]introduced a new unified labeling scheme to realize joint decoding, which transformed the task of relational triple extraction into an end-to-end sequence labeling problem that does not require NER or RC.Because the entity and relationship information are integrated into a unified labeling scheme, the model they propose can directly learn the relationship triples as a whole.
Although joint models have achieved good performance in relation extraction, the above methods ignore the problem of overlapping relation triples.A general definition of the overlapping relation triples is when the entity exists in different relational triples, but the times of the entity appears in the sentence is less than the number of triples involves the same entity.Zeng et al.[7]first proposed the problem of overlapping relation, and comes up a sequence-to-sequence(Seq2Seq)model with copy mechanism to solve the problem.Recent, Fu et al.[18]also studied the problem and proposed GraphRel, which using dependency trees as inputs.Although the models improved the performance of the entity recognition and relation extraction when the overlapping scenario is considered, these methods suffer from complex decoding process.Our proposed architecture is joint model that performs the two tasks of entity recognition and relation extraction simultaneously and takes into account of multiple relations and overlapping problem.
2 Our model
For a given sentence without any entity annotated, our goal is to extract the relation triples(h,r,t)from it, whereh,t∈E,r∈R,Eis the set of entities andRis the set of relations.We divide the extract relation task into two sub-tasks: entity recognition and relationship recognition.This newly proposed joint extraction model not only extract entities and recognition relationships simultaneously but also solve the problem of overlapping relationships, as shown in Fig.3.In this section, we provide detailed procedures of the model we proposed.
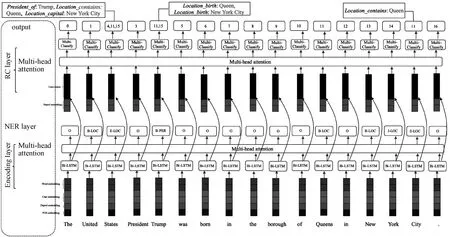
Fig.3 Model for multi-tasks joint extraction of entities and relationships
2.1 Encoding layer
Suppose a sentence is represented asS={w1,…,wl},which containslwords.First, we obtain the word-level embedding of each wordwi∈dw,wheredwis the dimension of word embedding.In this paper, we use the Skip-Gram word2vector model[19]to pre-trained word vector for initializing each word.In order to capture the morphological features of words such as prefixes and suffixes, we used character-level embedding.In addition to the characteristics of the word itself, external information such as part-of-speech(POS)information and dependency relations(Deprel)also contains rich information, which is helpful for the performance of entity recognition and relationship recognition tasks.The word embedding and the character embedding are initialized randomly.
We use Bi-directional LSTM(Bi-LSTM)encoding layer[6], a combination of a forward LSTM layer and a backward LSTM layer, which has been proven to be effective in capturing semantic information between each word in a sentence and in encoding sentence.For each wordwiin the sentence, we take the combination of word embedding, character embedding, POS information and Deprel as Bi-LSTM input:
deprel(wi).
(1)
(2)
And the sentence representation isH={h1,…,hl},wherelis the length of sentence.
Then it is used the input of attention layer.The attention layer is mainly used to calculate the correlation between the current word and other words in the sentence.Here we compute the Attention(A)using multi-head attention[20]which allows the model to jointly attend to information from different representation subspaces.The calculation takes a query and a set of key-value pairs as inputs.The output is computed as weighted sum of values, where the weight is computed by a function of the query with the corresponding key.We compute theAas
(3)
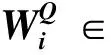
At this point, we can get a word based on a global feature representationZ=[z1,…,zl]at the sentence-level:Z=HAT,whereH∈2dlstm×l.
2.2 The named entity recognition(NER)layer
In this layer, the main task is to identify the boundary and categorize the entity, and we use the BIOE method to annotate the sentence.For example, the annotations corresponding to the entity “New York City” are B-LOC, I-LOC, and E-LOC.The annotation includes two parts, the first part represents the boundary of the entity, whereB-represents the entity’s first token,E-represents the last token of the entity, andI-represents the tokens between the start and the end of the entity; the second part represents the category of the entity.In this paper, the types of entities identified in this category include three types of entities: Location, Organization and Person.
We use Conditional Random Fields(CRF)to identify the entity.The input of the CRF layer is the output of the encoding layerZ=[z1,…,zl].The prediction task of CRF includes two parts: one is to calculate the score of the label corresponding to each wordsi; the other is to calculate the best labeling sequence using the Viterbi algorithm on the transformation matrixTand the score ofsi.The calculation process is as follows:
si=Vf(Uzi+b).
(4)
(5)
(6)
(7)
Wheref(·)is nonlinear activation function, In this paper, we usetanhas activation function.V∈n,U∈datten,b∈,withnis the number of NER tags anddattenis the dimension of attention matrix.The functionC(y1, …,yl)is to calculate the score of the label sequencey={y1, …,yl} of the input sentencesi.The square transition matrixT,T∈(n+2)×(n+2),is a matrix to store all the transition scores from one tag to another within the sentences.Because there are two auxiliary tags,y0andyl,to represent the starting and the ending tags of the sentence respectively, the row and the column of matrixTis bigger than the represented sentence length by 2.Andis the result of the final output label sequence, to be precise, the BIOE label.
In the end, the NER layer is trained using the cross-entropy loss function as the objective function, which is defined as
(8)
2.3 The relation classification(RC)layer
In this section, we introduce the relation recognition task which conceived as a multi-classification problem.The inputs of RC layer are the output of Bi-LSTM layer and Deprel embedding:
di=[hi,depreli],i=1,…,l.
(9)
wherehiis the Bi-LSTM output at timestepi,depreliis Deprel embedding.
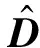
(10)
(11)
whereQandKare both equal toD.
Our goal is to predict the maximum possible relationship category of each tokenwi,i∈1,…,lwith other tokenswj,j∈1,…,landj≠i.Since there may be multiple relationships between tokens, this obstacle is a multi-label problem.For the multi-label problem, there are two solutions.One solution is to use a softmax function to calculate the probability of all relationships between each token.Then we set a threshold, and when the probability of the relationship exceeds the threshold, the relationship is considered to exist.The other method is to use multiple a sigmoid model to classify any kind of relationship between each token.These two methods are essentially the same.In order to reduce hyperparameters in the model, we use the latter to predict the relation between each token.
We calculate the score between tokenswiandwjgiven a relation labelrkas follow
(12)
whereV∈,U∈datten,W∈dattenandb∈.
The probability of tokenwichoses tokenwjas the tail of relation labelrkis
(13)
Finally, we minimize the objective function, which is the cross-entropy loss function:
(14)
whereyi∈Wandri∈are the correct tail entities and relations, andmis the number of tail entities ofwi.
3 Experiments
3.1 Datasets and preprocess
To test the performance of the proposed method, we perform experiments on two public datasets NYT and WebNLG.The New York Times(NYT)dataset was obtained by Riedel et al.[21]using a remote monitoring method.The 1.18 M sentence corpus of this dataset is extracted from 194 k articles of the New York Times from 1987 to 2007, and there are overall 24 relationships.We use the same processing method as Zeng et al.[7]to preprocess the dataset.First, we filter out sentences in the dataset that are longer than 100 words and those that do not contain a relationship.Then 5 000 sentences are randomly selected as the test set, and the rest of sentences(a total of 56 195 sentences)are for training purpose.Among the train set, we take 5 000 sentences are selected as the verification and the rest are the training set.Meanwhile, the sentences are classified based on the degree of relationship overlap contained in the sentences.
The WebNLG[22]was originally created for natural language generation(NLG)task.We follow the method of to filter sentences with more than 100 words and for WebNLG, we use only the first sentence in each instance in our experiments.The number of sentences of every class in NYT and WebNLG dataset are shown in Table 1.In the experimental analysis stage, we analyze the SEO dataset in the NYT dataset in detail.
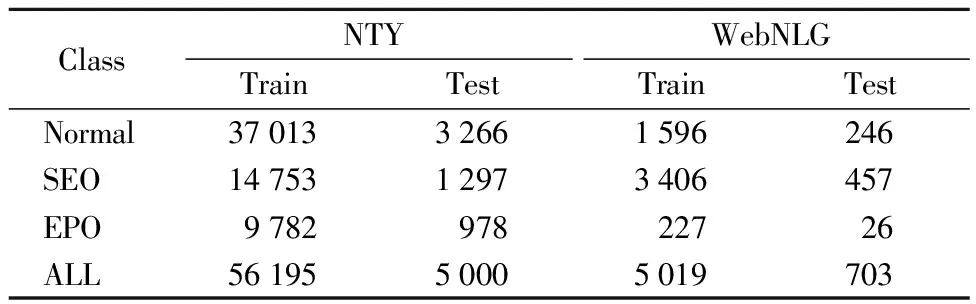
Table 1 The number of Normal, SEO, and EPO categories in the training and test sets
We still use the Stanford NLP tool to perform word segmentation and part-of-speech and dependency relation analysis on sentences for the POS embedding and the Deprel embedding inputs.
3.2 Experimental parameter setting and evaluation metrics
Table 2 shows some parameter settings during our experiment.In these experiments, we use LSTM[23]as the cell of Bi-LSTM layer, which unit number is 64.About the information of the inputs, the word embedding, we use the pre-trained word2vec to initialize, which dimension is 50.The character embedding size is 25, the embedding size of POS and Deprel are all 32.In the attention mechanism, we use multi-head attention[20]which the size of the heads of attention is 8.We use Adam[24]to optimize parameters and if the loss function decreases less or does not decrease within 30 epochs, we will early stop training.The learning rate is 0.001 at the beginning of the training.At the same time, we use dropout to regularize our network.Dropout is used between input embeddings and hidden layers.
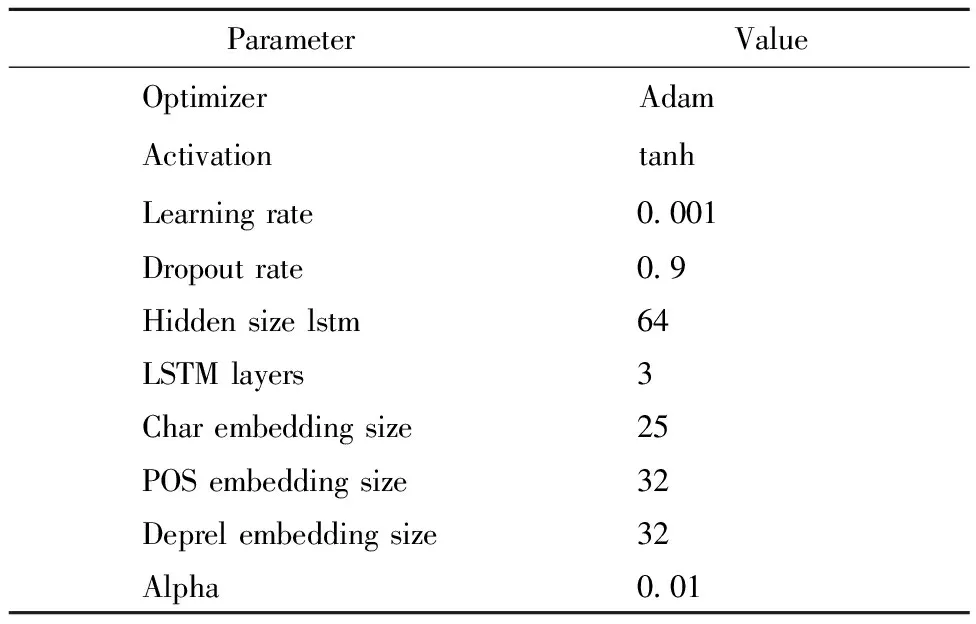
Table 2 Experimental parameter setting
We compare our method with Copy(Zeng et al.[7])and GraphRel(Fu et al.[18]), which conduct the best performance on relational facts extraction.We use a strict evaluation method, that is, an entity is considered correct if and only if its boundaries and types are correct simultaneously; a relationship is correct if and only if the type of this relationship and the entities that the relationship connected are both correct.And we use the standard micro Precision, Recall andF1score to evaluate the results.
3.3 Different types of triples
In this paper, we divided the sentences in the test corpus into three types: Normal, SEO, and EPO.Figure 4 shows the Precision, Recall, andF1value of Copy model, GraphRel, and our model.
As we can see, in NYT dataset, our model achieves the bestF1score, which is 0.667.There is 8% improvement compared with the Copy model, and there is 4.8% improvement compared with the GraphRel model.In the WebNLG dataset, our model also achieves the highestF1score(0.458).Our model outperforms the Copy model and GraphRel model with 18.7% and 2.9% improvements, respectively.These observations verify the effectiveness of our models.
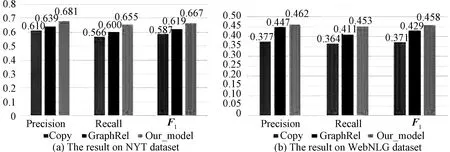
Fig.4 Experimental results on different datasets
We can also observe that, in both NYT and WebNLG dataset, our model precision value and recall value are relatively balanced.We think that the reason is in the structure of the proposed models, in the relationship recognition task, the last word of the entity is multi-classified to identify overlapping relationships.The Copy model apply copy mechanism to find entities for a triplet, and a word can be copied many times when this word needs to participate in multiple different triplets, but Copy cannot solve the situation where the entity consists of multiple words.Not surprisingly, our model recalls more triples and achieves higher recall value.
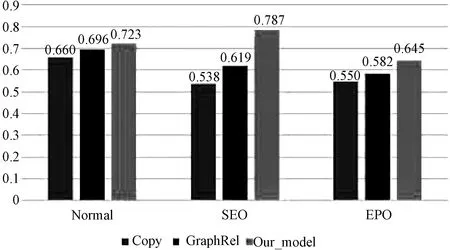
Fig.5 The F1 score on different classes of NYT
To verify the ability of our models in handling the overlapping problem, we conduct further experiments on NYT dataset.Figure 5 shows the results of Copy, GraphRel, and our model in Normal, EPO, and SEO classes.As we can see, our proposed models perform much better than Copy model and GraphRel model in EPO class and SEO classes.Specifically, our models achieve much higher performance on all metrics.Moreover, we notice that the extracted performance of SEO class is 24.9% improvement compared with the Copy model, and 16.7% improvement compared with the GraphRel model, which proves that our proposed models are more suitable for the triplet overlap issues.We think that the reason is that the copy mechanism used by the Copy model is difficult to judge how many triplets are needed for the input sentence.The GraphRel model models text as relational graph, which will miss the semantic information, and at the same time, the embedding of entity nodes in GCN will be smooth.The model proposed in the paper is to separately label the entities and multi-classify the relationships.Finally, output the results of the two subtasks in a strict manner to extract fact triples.
3.4 Add external information and attention mechanism to model
As we all known, part-of-speech(POS)information and dependency relations(Deprel)contain more information for a sentence than word embedding alone, attention mechanism can effectively mine features in text.We aim to verify the impacts of adding the external information, such as POS and Deprel, and adding attention mechanism the in different positions on the performance of entity extraction and relationship recognition tasks, to verify the rationality of our model.We detail analyze the experimental results on NYT’s SEO, where theOriginalhas neither the POS embedding and Deprel embedding in the input for the encoding layer nor the attention layer after Bi-LSTM.In the relation recognition process, neither the Deprel embedding nor attention layers were added.
3.4.1 Add POS embedding
In this experiment, POS information was added to theOriginalmodel, and the results are shown in Table 3.TheInput_add_POSexperiment refers to the results of adding POS embedding to the embedding layer, and theRel_add_POSrefers to the result of adding POS embedding as the input of the relation classification layer.

Table 3 The results of adding POS embedding on SEO dataset
First, from the table above, compared to theOriginal, the Precision, Recall, andF1in theInput_add_POShave improved by approximately 6%, 3%, and 5% respectively.The results of theRel_add_POSare also improved compared to theOriginal, but not as effective as theInput_add_POS.We believe that in the relationship recognition task, the input part is the output from the encoding layer, which contains more complex representations obtained by the part-of-speech information through the neural network.At the same time, from the comparison of theRel_add_POSandInputaddPOS, it is not appropriate to concatenate POS embedding on the input layer of relationship recognition, because it blurs the features obtained during encoding and ends up the lower performance than that ofInput_add_POS.Ignoring the positions of where the POS added, the results of adding the POS is better than theOriginal.
3.4.2 Add Deprel embedding
This group of experiments is to verify the effect of adding dependency relation(Deprel)and the results are shown in Table 4.The first experiment, namedInput_add_deprel, is to concatenate the Deprel embedding with the other input embedding.Compared with theOriginal, the experimental results are improved by approximately 6%, 3% and 4.5% in Precision, Recall andF1, respectively.Rel_add_deprelexperiment is based on experimentInput_add_deprel, hence in the relationship recognition task Deprel embedding is stitched in the input.Compared with theOriginal, the experimental results are improved by approximately 8%, 3.5% and 6% in Precision, Recall, andF1, respectively.This experiment shows that the dependency relation feature has a greater impact on the results in the relationship recognition task.The reason lies within the dependency relationship itself.The dependency relationship naturally contains the grammatical interdependence characteristics between words, and the grammatical interdependence to some extent reflects the semantic interdependence between words.We also see this trend in entity extraction task.

Table 4 The results of adding Deprel embedding on SEO dataset
3.4.3 Add attention mechanism
This group of experiments is to discuss the impact of attention mechanism on entity identification and relationship recognition tasks.The experimental results are shown in Table 5.We also perform attention at the input layer and the embedding layer of the relationship recognition task.TheInput_attentionexperiment is to add an attention mechanism after the Bi-LSTM encoding of the input layer.Compared with theOriginal, the result in Precision, Recall andF1were improved by 1%, 5.5% and 3.4%, respectively.In theRel_attentionexperiment, we add an attention mechanism to the input layer of the relationship recognition task.The experimental results are about 4% improvement over theOriginal, at Precision, Recall andF1.Analyzing the experimental results, we believe that there are two reasons that explain the improvement of the experimental results.The first is the use of the attention mechanism, after the Bi-LSTM encoding of the input layer, obtains the global features between the words in the sentence, especially in the sentence.With the length of the sentence increases, the long-distance dependencies will be forgotten.The attention mechanism can make up for this shortcoming by directly calculating the distance between all vectors.The second is using the attention mechanism in the task of relationship recognition.We intend to assign more weight about the relationship between entities.Even if the position of the entity, within the relation triplet, are currently unknown, the connect represented as relation is strong than other unrelated words or entities.The attention mechanism can focus on this and lays better foundation for later relationship classification.

Table 5 The results of adding attention on SEO dataset
3.5 Case study
Table 6 shows the case study of Copy model and GraphRel model and our proposed model.The first sentence is an easy case and all models can extract accurately.For the second case, although there does not belong to name entity, it should contain the hidden semantic of Italy.Therefore, our model can further predict that A.S.Gubbio 1910 grounds in Italy.The third case is an SEO class in which Copy and GraphRel only discover that Asam pedas is the same as Asam padeh, while our model can locate in Malay Peninsula and come from Malaysia.The fourth case is an EPO class,our model can identify multiple types of relationships between entities.
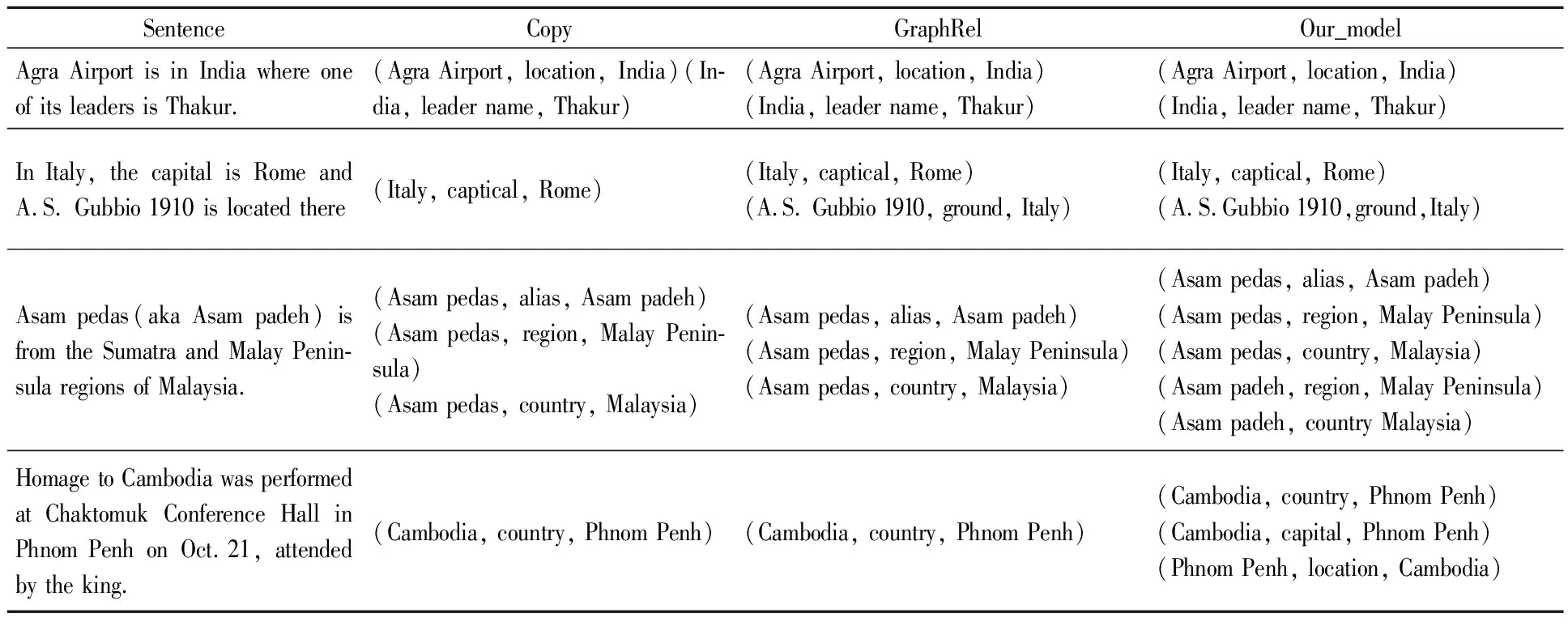
Table 6 Case study of different models
4 Conclusion and future research directions
In this paper, we propose a new joint extraction model to solve the relation extraction task.Relation extraction is composed of entity recognition and relationship recognition.For overlapping relationships, we use the multi-label classification method in the relationship recognition.The labeling method is to label the position of the head and the tail entity in the relationship triple with the corresponding relationship.At the same time, since the entity may contain multiple words, we only use the position of the last word of the entity as the entity’s position in labeling process.At the same time, we not only add part-of-speech(POS)information and dependencies(Deprel)at the input layer, but also employ an attention mechanism at the coding layer.Our experiments have proved that these modifications are effective, and the results of the relationship extraction are significantly improved, comparing with the experimental results of Copy, the Precision, Recall andF1improved by about 7.1%, 8.9% and 8% respectively, on NYT dataset.For future research directions, there are still more to explore.in this article, we just simply spliced the dependencies and did not investigate further of the information on the sentence structure.Recently, many articles have used the graph convolutional neural network to model the syntactic dependency tree, which can mine the sentence structure information and provide more information than simple dependencies we used.At the same time, from another perspective, syntactic dependencies and part-of-speech information depend on external tools.It is also worth to investigate whether we can use only sentence information for relationship extraction to achieve this effect.
杂志排行

中国科学院大学学报的其它文章
- DFT mechanistic insight into the modular strategy involved in the palladium-catalyzed synthesis of cyclopentenones from α,β-unsaturated acid chlorides and alkynes*
- 脱水诱导基因RD特性及功能*
- 对线性幺正光学加密系统的选择明文攻击*
- Ab initio simulations of NO adsorption on hematite(0001)surface: PBE versus PBE+U*
- 基于B/S架构的激光雷达电力巡线可视化管理与分析系统*
- 基于低秩和一维稀疏矩阵分解的多通道SAR-GMTI方法*