一种基于特征聚类和评价的轴承寿命预测新方法
2022-03-18李海浪邹益胜曾大懿刘永志赵市教宋小欣
李海浪, 邹益胜, 曾大懿, 刘永志, 赵市教, 宋小欣
(西南交通大学 机械工程学院,成都 610031)
滚动轴承作为一种机械标准件,被广泛应用于各类机器中。轴承故障会引起整个机械系统发生故障,在实际的工业生产中容易引发安全事故,不仅影响生产,而且严重者会危及人员安全[1]。因此,研究轴承剩余使用寿命十分有意义。轴承剩余寿命的研究方向有两种:基于数据驱动的方法和基于模型的方法[2]。近年来随着人工智能和深度学习的快速发展,基于数据驱动的轴承寿命预测方法逐渐成为主流[3]。
轴承剩余使用寿命的预测包括3个步骤,即信息获取、特征提取和建立模型预测,能否有效提取特征是准确预测轴承剩余寿命的关键之一[4]。提取的特征常会出现一种不理想的状况:特征子集中存在与预测目标无关的特征量,此类特征对于后续模型的预测无用。针对这种状况,可以采用特征选择方法剔除这类特征。按照是否独立于后续的学习算法,特征选择方法可以分成两类框架:过滤式(Filter)特征选择方法和封装式(Wrapper)特征选择方法[5]。Filter方法与后续学习算法无关,一般使用检验准则对特征进行筛选,作为特征预处理步骤。特征评价是常用的Filter方法之一,纳入相关性指标进行选择,以此来移除那些与目标函数不相关的特征。Wrapper方法结合后续的学习算法,寻找所有特征中能使后续学习算法达到较高性能的子集。但是对于大型或中型数据集,Wrapper方法计算复杂度是指数型的,执行时间更长[6]。特征评价独立于后续的学习算法,因而适合大规模数据集,可以快速移除大量不相关特征,通用性较强。同时特征评价可解释性更强,所选出的优良特征可以为轴承设备的检查、维修提供一定的指导,在实际工程应用中更具价值。
目前已有众多学者在特征评价中将相关性作为特征的评价标准之一,在设备寿命预测上取得了不错的成果:谷广宇等[7]在特征评价中纳入相关性指标,选取与运行状态相关的特征,实现了对发动机使用寿命的预测;刘胜兰等[8]在特征评价中考虑相关性的基础上,提出了一种自适应顺序的特征选取方法,并有效预测了轴承的剩余使用寿命。尽管通过特征评价选出的特征和剩余寿命的相关性比较高,但对所选特征之间的相关性高低考虑不足。一些高相关性特征会造成特征冗余,继而影响后续模型的预测精度。通过分析不同特征之间的相关性并进行特征聚类,可以把高度相关的特征聚在同一类中。在聚类之后,从每一个特征簇中挑选出具有高相关、代表性的子集,最终剔除冗余特征达到降低所选特征之间相关性的目的。因此提出了Corr-Kmeans聚类算法,同时为了避免Corr-Kmeans随机初始聚类中心导致聚类结果不稳定,对初始聚类中心确定方法进行了优化。Corr-Kmeans聚类算法和特征评价结合的方法使提取的特征和轴承剩余寿命保持高相关性同时,降低特征之间的相关性。
综上,先用卷积自编码对频域信息提取初始特征;然后利用Corr-Kmeans算法按照相关性将初始特征分为K个类;再基于相关性、单调性和鲁棒性构成的综合评价指标,按照筛选阈值分别在每类中选出优良特征,组成特征子集;最后采用LSTM网络对轴承剩余寿命进行预测。
1 Corr-Kmeans算法和特征评价
1.1 方法的提出
一个良好的特征子集应该满足两点条件[9]:① 所选特征和目标函数之间高相关;② 子集中特征之间的关联性很低。这样的特征子集在预测模型上会取得比较好的预测效果。对于轴承寿命预测特征提取,目前常用的特征评价方法在选取特征时,只考虑了特征子集和剩余寿命之间的高相关性,却忽略了特征之间高相关性带来的影响,所以容易出现以下问题:某些特征它们之间的相关性很高,但是和剩余寿命之间相关性也很高,于是这些特征都被选入最优特征子集中,导致最优特征子集中存在大量冗余特征[10]。这些冗余特征包含的信息量相当,对于后续模型的预测效果没有增益,甚至会降低预测性能[11],因此降低所选特之间的相关性也是很有必要的。
特征评价只考虑了前者,为了同时满足这两个条件,采取以下方式:依照相关性聚类可以将具有较大相关性的特征聚在一起,将初始特征聚为类间相关度低、类内相关度高的几个类;随后对每类特征使用纳入相关性的特征评价来进行特征选择,挑选出各类中的优良特征组成特征子集。其处理过程如图1所示。

图1 聚类和特征评价
为了实现将特征按照相关性的高低进行分类的思路,借鉴聚类方法中的Kmeans算法,用皮尔逊相关系数代替欧式距离对特征之间的相关性进行度量,以此提出Corr-Kmeans聚类算法。将特征聚类后,结合特征评价方法,使用相关性、单调性和鲁棒性3个评价指标构成的综合指标来对特征评价,并按照筛选阈值分别在每类特征中筛选出优良特征组成特征子集。提出的Corr-Kmeans算法和特征评价方法相结合的方法,综合考虑了特征之间的相关性以及评价指标下特征的优良程度,旨在有效识别并移除特征集中的冗余特征,挑选出有利于后续预测的特征子集。
1.2 Corr-Kmeans聚类算法
传统的Kmeans算法使用欧式距离来度量数据间的相似性[12],将数据划分为类内相似度尽可能高、类间相似度尽可能低的K类。为了将特征按照相关性进行聚类,启发式地基于Kmeans聚类的原理,以皮尔逊相关系数取代欧氏距离,来度量特征之间的相关性,由此产生了Corr-Kmeans算法。Corr-Kmeans算法能将特征分为类间特征相关性低、类内特征相关性高的K类。
Corr-Kmeans算法的输入是需要聚类的特征和聚类数目K,具体步骤为:首先在特征中确定K个特征作为初始聚类中心(类心);然后计算其余特征与每个类心的皮尔逊相关系数绝对值,将其分配给相关系数最大的类心代表的类;随后按照每类中的特征取平均值更新类心,重复前两个步骤直至每类包含的特征不再变化或者达到迭代次数为止。皮尔逊相关系数绝对值计算方式如式(1),其值在[0,1]之间,越接近1表示二者相关性越高。整个算法流程具体如表1所示。
(1)

表1 Corr-Kmeans算法
式中:Cov(X,Y)表示X、Y之间的协方差;σX、σY分别表示X、Y的标准差。
Kmeans算法是一种应用广泛的经典聚类算法,但其存在缺陷,即对初始聚类中心敏感。通常情况下Kmeans算法的聚类中心是随机选取,而随机的初始化聚类中心会导致聚类结果不稳定[13],极度容易陷入局部最优解。选择相互距离最远的K个处于高密度区域的点作为初始聚类中心,能有效地降低这种敏感性[14],获得更稳定的聚类结果。基于此思路,在已有Corr-Kmeans算法的基础上提出了一种改进的初始中心确定方法,描述如下:
步骤1从输入的数据中随机选取一个点作为第一个聚类中心;
步骤2对于数据集中的每一个点,计算它与相关性最高的聚类中心的皮尔逊相关性绝对值,并与1作差:D(xi)=1-|ρx,Oi|,其中Oi表示与之相关性最高的聚类中心;
步骤3选择一个新的数据点作为第二个聚类中心,选择的原则是:D(x)较大的点,被选作聚类中心的概率较大;
步骤4重复(2)和(3)直至K个聚类中心被选出来。
1.3 特征评价
轴承剩余寿命预测属于回归预测,轴承的退化过程本质上是一个连续变化的随机过程,一个优良的轴承特征应该满足下列条件:
(1) 特征随着轴承的运作退化而发生变化,即特征和轴承的剩余使用寿命有一定的相关性;
(2) 轴承退化是一个不可逆的单调过程,因此特征的变化也应该具有一定的单调性;
(3) 采集的轴承数据含有噪声,所提特征应该具有一定的抗干扰能力,即鲁棒性。
本文采用文献[15]提出的3个轴承特征评价指标:相关性、单调性和鲁棒性,以此对特征进行评价。首先使用平滑方法将特征分为趋势项和残差项,如式(2)所示
X(tK)=XT(tK)+XR(tK)
(2)
式中:X(tK)表示在时刻tK的特征;XT(tK)是趋势项;XR(tK)是残差项。
特征的相关性(Corr)、单调性(Mon)和鲁棒性(Rob)分别按照式(3)~(5)计算。单独的指标只能片面地评价特征在某一方面的优异性,为了综合利用3个评价指标选择出最优特征子集,将3个指标线性加权作为最终的特征筛选依据。计算如式(6)所示。
Corr(X,T)=
(3)
(4)
(5)
Score=w1Corr(X,T)+w2Mon(X)+w3Rob(X)
(6)
式中:K是总采集时间;δ(·)是阶跃函数。
在线性加权融合之后对特征综合指标根据Min-Max法归一化到[0,1]之间,然后将所有特征按照综合评价指标的大小排序,并按照设定的阈值选取特征。
2 试验验证
2.1 试验数据
试验数据为滚动轴承加速寿命台架试验采集的振动加速度数据,来源于电气和电子工程师协会(IEEE)2012年举办的PHM数据挑战赛[16],该数据集共包含3种工况下的17个滚动轴承的全生命周期振动数据,其中第1、2种工况各7个轴承,第3种工况3个轴承,它们分别命名为Bearing1-1~Bearing1-7,Bearing2-1~Bearing2-7和Bearing3-1~Bearing3-3。数据采样频率为25.6 kHz,每间隔10 s采集一次,采集时间长度为0.1 s,一次采集的振动数据为2 560个振动加速度,直到满足数据说明中的振动加速度达到设定阈值轴承失效条件就停止采集。轴承数据采集试验平台如图2所示。

图2 轴承数据采集试验平台
在进行模型训练时,从数据集中选取一个轴承作为测试集,其余16个轴承作为训练集。随机取轴承Bearing1-3和Bearing2-4依次作为测试集,其余的16个轴承作为训练集训练模型,来验证所提方法的有效性。每个轴承样本按照{(xi,yi)}的方式构建数据集,xi为某轴承第某次采集的振动加速度,yi为该次采集时所对应的剩余寿命,该剩余寿命的定义为当前时刻距离失效时刻间时长占起始时刻到失效时刻时长的比例。按照行数等于采集的次数n,列数等于采集一次的数据的长度2 560,将每个轴承数据集整理为n行,每行长度为2 560的矩阵。第i行的2 560个振动加速度数据表示为xi,对应的yi计算公式如下所示
(7)
式中:i代表该行的行数;n代表总行数。
Bearing1-3一共采集了2 375次,每次采集2 560个振动加速度,其寿命为23 750 s;Bearing2-4一共采集了751次,每次采集2 560个振动加速度,其寿命为7 510秒。按照上述介绍,若样本Bearing1-3第500次采集数据,其剩余寿命为18 750 s,对应的标签yi=0.789 8。这样的标签划分方式客观上也是对预测标签进行了归一化,能够降低预测模型的学习难度,更好地拟合输入和标签之间的关系。
2.2 模 型
轴承振动信号往往是多维数据而且含有噪声,预测模型会面临特征维数灾难和提取特征不佳的问题。考虑到频域信号是按照频率大小进行排列,相比于原始振动信号的分布更为规律,因此对原始轴承振动时域信号作快速傅里叶变换,转化为频域信号[17]。卷积自编码网络作为常用的无监督学习方法,具有强大的特征自提取能力,利用卷积自编码来提取初始特征,其网络结构如图3所示。
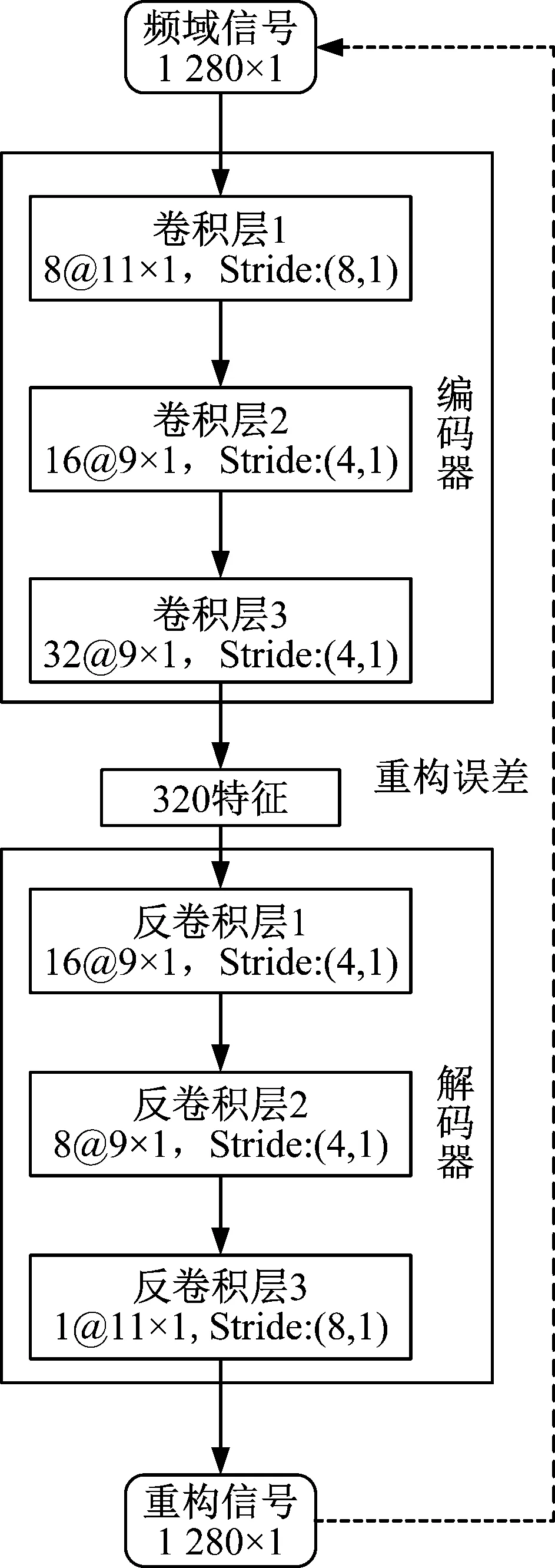
图3 卷积自编码网络结构
其中,卷积自编码的输入是1 280×1的频域信号,编码器包括三层卷积层,卷积核的数目分别为8、16和32,卷积核的大小分别为11×1、9×1和9×1,卷积的步幅为(8,1)、(4,1)和(4,1)。解码器包括三层反卷积层,其中卷积核的数目分别为32、8和1,卷积核的大小分别为9×1、9×1和11×1,卷积的步幅为(4,1)、(4,1)和(8,1),与解码过程相对应。模型训练时,训练步数为20 000,并使用衰减学习率保证前期训练速度的同时防止后期难以收敛。
将卷积自编码提取的320维特征作为初始特征,使用Corr-Kmeans算法对初始特征按照特征之间的相关性聚类,截止迭代次数为150次。本文以K=3为例进行试验,按照相关性把初始特征划分为3个类,其中ntrain表示训练集的样本总数。示意图如图4所示。
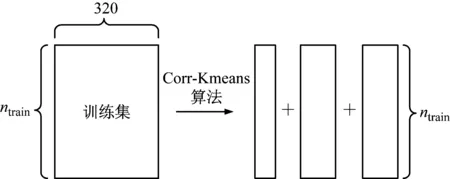
图4 Corr-Kmeans聚类
对每类特征进行特征评价时,为了保证所选特征和标签之间的高相关性,给予相关性较大的权重,剩下的权重两个评价指标平均分配,因此3个评价指标的权重设定为[18]:w1=0.6,w2=0.2,w3=0.2。计算出综合得分后,将每类中所有特征得分归一化到[0,1]之间。由于综合得分是线性的,和每个指标正相关,所以综合得分越大,表明此特征对轴承剩余寿命预测越有效,应该保留。按照阈值为0.5的标准,挑选出大于阈值的特征组成特征子集。需要注意的是,在聚类和特征评价两个阶段,应当保留所选优良特征子集包含的特征在初始特征中所对应的列序号,作为测试集选择特征子集的准则。
LSTM单元为三层LSTM加一层全连接。三层LSTM隐藏神经元数目分别设置为:170,40,10,步长选择为5。全连接层的神经元数量为1,激活函数采用relu函数。模型训练时,采用的优化器为adam,训练步数为11 000,初始学习率为0.005,并且采用衰减学习率的方式,学习率衰减因子设置为0.95。最后采用加权平均的方法对预测结果进行平滑处理。
整个轴承寿命预测流程图如图5所示。
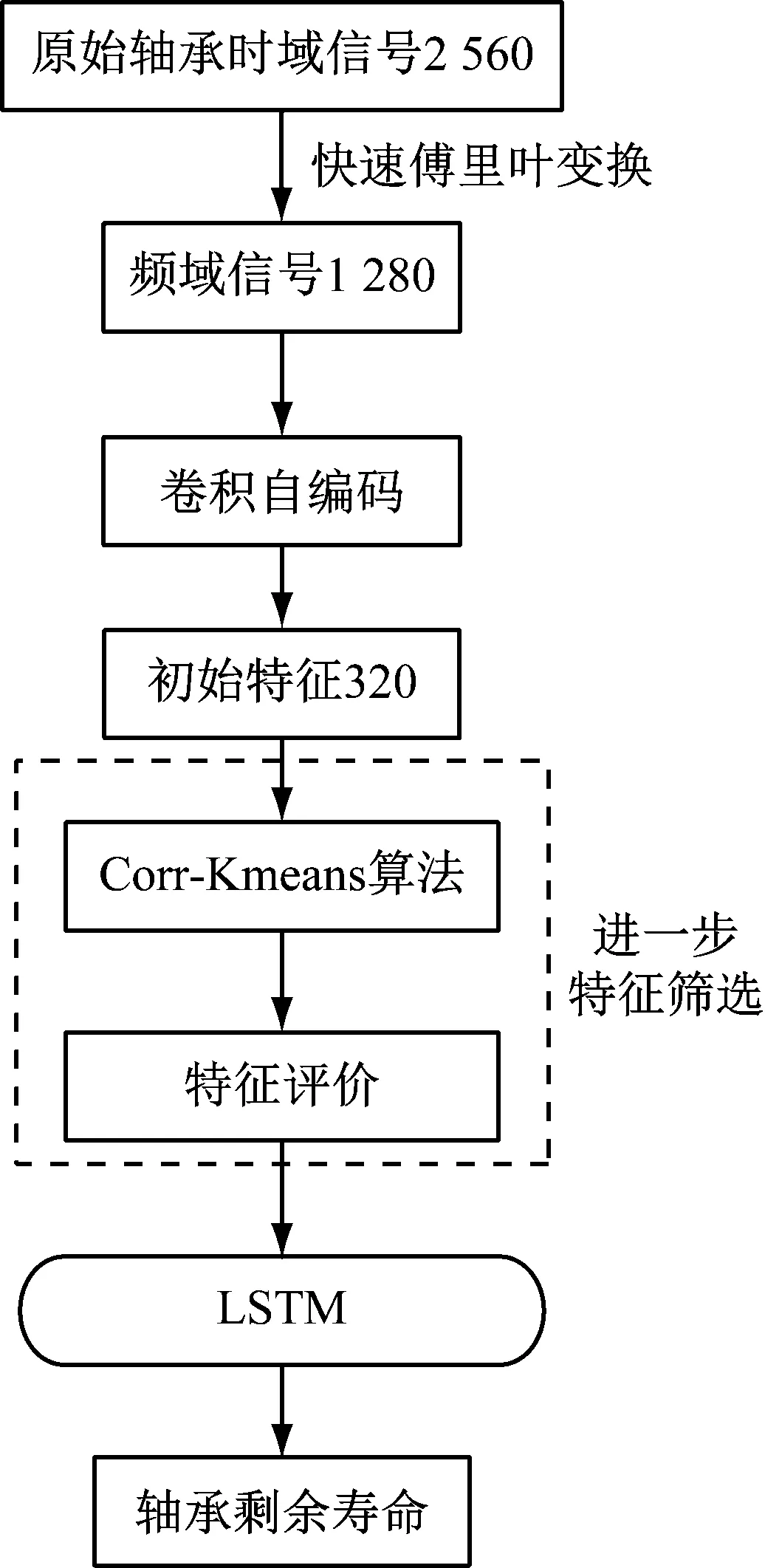
图5 总流程图
3 试验结果
3.1 聚类结果稳定性分析
为了有效避免Corr-Kmeans聚类算法随机选取初始中心导致聚类结果不稳定的问题,本文设计了一种新的初始聚类中心选择算法。为了证明其有效性,按照文献[19]计算方法计算聚类结果不稳定性,计算结果用lnstab值表示,其值越低表示该算法聚类结果越稳定,计算方法如式(8)和(9)所示。对两组训练集以本文方法和随机确定初始聚类中心方法分别聚类20次,两种方法的lnstab值计算结果如表2所示。
(8)
(9)

表2 聚类结果稳定性
式中:b表示聚类次数,b=20;Ci表示第i次聚类结果;d(Ci,Cj)表示两个聚类结果之间的距离;n表示样本数目,n=320;Ci(Xk)表示Ci聚类结果中样本Xk所对应的标签。
从表2可以看出,在两个测试轴承上,本文所提的聚类中心初始算法的lnstab值均比随机初始化聚类中心的lnstab值低,说明了本文所提方法能够获得更加稳定的聚类效果。
3.2 相关性验证
卷积自编码提取特征后,得到320维初始特征。经过Corr-Kmeans算法按照相关性划分成3类,对每类特征进行特征评价,挑选出优良特征组成组成最终的特征子集。特征评价挑选出的3类优良特征为A、B和C。为了验证Corr-Kmeans算法按照相关性聚类的有效性,计算类内每维特征与其他特征的皮尔逊相关系数绝对值,得到相关系数三角矩阵[20],如式(10)所示,并取矩阵中的平均值作为类内特征相关性系数;依次计算某类特征中的每维特征跟另一类特征中的每维特征的皮尔逊相关系数绝对值,得到相关性系数矩阵,取矩阵的平均值作为类间特征相关性系数。以Bearing1-3和Bearing2-4测试时,得到各自的类内特征相关性系数和类间特征相关性系数,如表3所示。
(10)
式中:n代表此类中的特征数量;|ρ12|是此类中的第一维特征跟第二维特征之间的皮尔逊相关性系数绝对值,以此类推。
表3中A表示A类的类内特征相关性系数,A-B表示A类和B类的类间特征相关性系数,以此类推。从表3中可以看出,类间特征相关性系数均低于相对应的类内特征相关性系数,表明Corr-Kmeans算法在将特征按照相关性划分是有效的,能将特征划分为类内相关性高、类间相关性低的3个类。Corr-Kmeans算法结合特征评价,目的在于使所选特征子集和时间序列保持高相关的同时,降低特征子集内部之间的相关性。为了进一步验证其在降低特征子集内部之间的相关性上的有效性,与初始特征只经过特征评价的方法作对比。在Bearing1-3和Bearing2-4上,分别计算最终特征子集的类内特征相关性系数,得到的结果如表4所示。

表3 类内和类间特征相关性系数

表4 特征子集相关性系数
从表4中可以得知,Corr-Kmeans算法在一定程度上能够降低最终所选特征子集的相关性,表明此方法是可行的。
3.3 不同方法预测结果对比
本文对于初始特征的进一步筛选主要由Corr-Kmeans算法和特征评价两部分组成。为了验证该方法相比特征评价的优势性,将其与初始特征只经过特征评价的方法对比,同时与主流的基于相关性评价方法进行比较[21];为了验证Corr-Kmeans算法改进的有效性,也设置了一组传统Kmeans结合特征评价的对比试验;最后设置了一组仅用初始特征做预测的对比试验,用于验证整个特征筛选环节的优势性。预测模型均采用同一参数的LSTM网络。
以轴承Bearing1-3和Bearing2-4依次作为测试集进行试验,采用上述5种方法提取的特征分别对轴承进行剩余寿命预测。Bearing1-3的预测结果如表5所示,Bearing2-4的预测结果如表6所示。图中横坐标表示数据序号,实则代表的是使用时间,纵坐标为当前时间点对应的剩余寿命占总寿命的百分比,实线为预测的寿命值,虚线为实际的寿命值。
从表5和表6中可以看出,无论对于测试集Bearing1-3还是Bearing2-4,对初始特征使用了特征评价后,预测效果在整体上都有一定的提升,在轴承的寿命晚期表现得更加明显,单一的相关性评价方法反而使得预测精度不佳。在特征评价的基础上,配合Corr-Kmeans聚类算法,预测效果又有了进一步的提升,在轴承的寿命晚期预测值也向真实值贴紧得更密切,可以证明Corr-Kmeans算法结合特征评价相比单一的特征评价是有优势的。同时传统的Kmeans结合特征评价并没有显著的提升,由此证明了Corr-Kmeans的有效性。整个现象说明Corr-Kmeans算法结合特征评价的方法是有效的,对于轴承剩余寿命预测精度有提升。为了更加精确地描述种方法的预测结果,按照式(11)和(12)对两种方法预测结果的平均误差emean和最大误差emax进行了计算,计算结果如表7所示。

表6 Bearing2-4不同方法的预测结果对比
(13)
通过对表7的分析,按照式(13)计算误差相对下降百分比。对于Bearing1-3,本文方法相比于其余4种方法预测精度的平均误差分别降低了53.2%、78.6%、44.1%和46.9%,最大误差分别降低了46.7%、77.8%、33.5%和43.7%;对于Bearing2-4,平均误差分别降低了65.5%、78.6%、31.9%和46.4%,最大误差分别降低了31.1%、39.2%、1.8%和3.1%。

表7 不同方法的预测误差
上述结果表明,本文方法预测精度优于单一特征评价方法,同时误差是5种方法中最低的,证明了本文所提方法提取的特征更有利于轴承的剩余寿命预测,有更好的预测效果。
3.4 训练与预测时长比较
上述5种方法所需的训练时长与预测时长如表8所示。其中训练时长包括数据的读取与预处理,以及模型训练;预测时长指的是加载预训练模型对某一时刻采集的信号进行轴承剩余寿命预测。

表8 训练时长与预测时长
由于Corr-Kmeans聚类算法用皮尔逊相关系数来度量两个样本之间的相关性,计算量较大,所以在数据预处理阶段所耗时间长于其他4种方法,但后续的模型训练与预测时间是基本相同的。尽管本文方法前期的数据预处理花费时间较长,而在线预测时间还是远小于信号获取过程中的时间间隔的,因此较长的离线训练并不会影响模型的实时性。同时在实际应用中,往往更加注重模型的预测时间与预测精度,因此还是具有一定的优势性的。
3.5 基于留一法的预测结果
为了更全面地验证该方法的有效性和适用性,采用留一法进行预测试验。留一法即每次只采用一个轴承作为测试集,其余轴承作为训练集,模型训练完毕后,利用测试集进行测试。3种方法的平均误差emean和最大误差emax如表9所示。
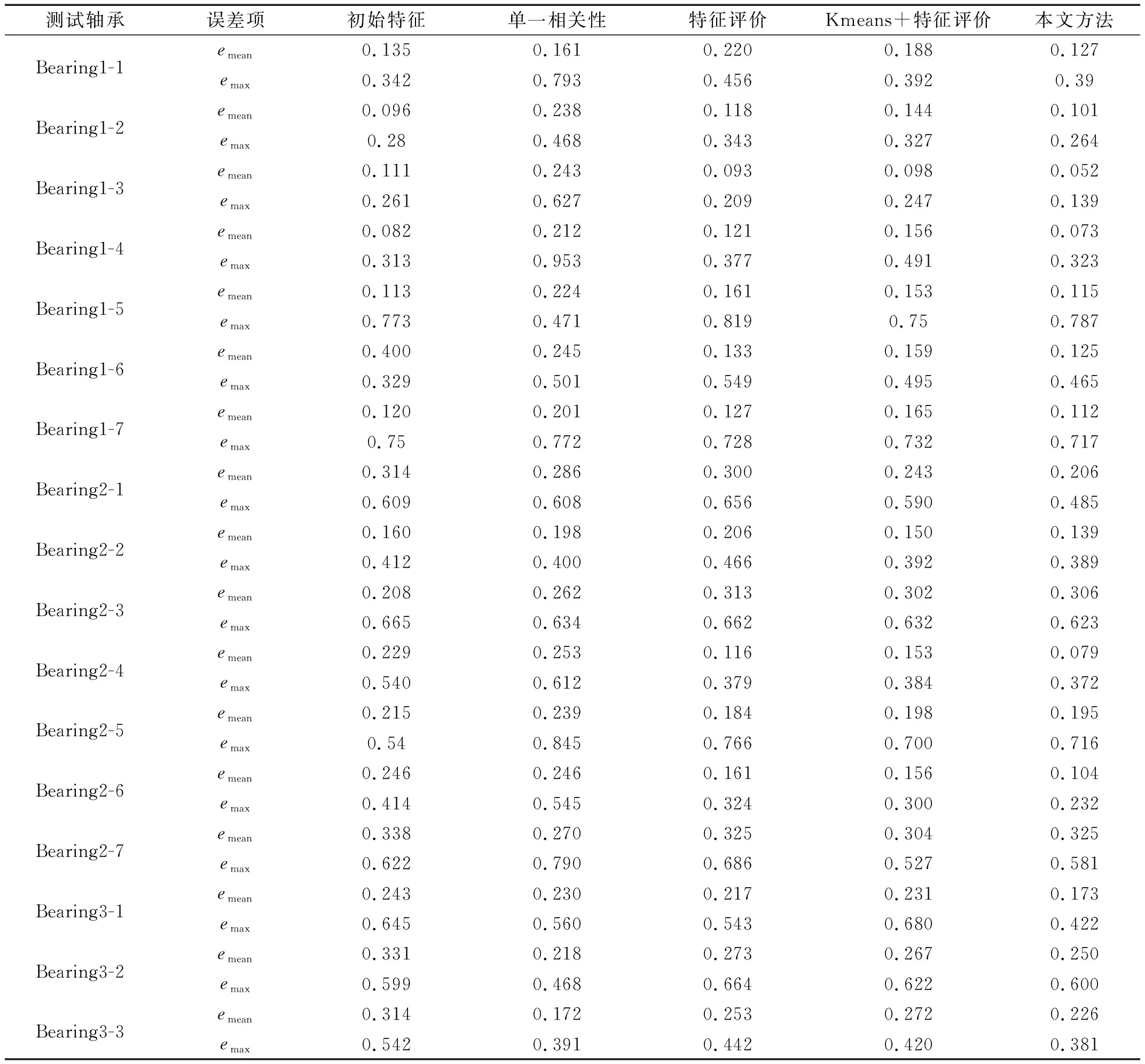
表9 留一法试验结果


表10 综合试验误差统计
进一步分析表10的结果,可以看出本文方法的预测精度是优于单一特征评价方法的,相比其余几种方法,综合平均误差和综合最大误差也都是最低的,说明本方法是有效的。
为了进一步探究不同的Corr-Kmeans聚类数目K对预测精度的影响,分别进行了K值为2,4和5时的试验,综合误差结果如表11所示。

表11 不同K值综合误差统计
分析表11和表10中的结果,可见K=3或者K=4时,其预测效果是优于其他几种方法的,综合误差和平均误差均低于所对比的方法。
4 结 论
在预测轴承剩余寿命时,针对单一的特征评价方法在对轴承特征进行选择时,仅考虑了所选特征与时间序列的高相关性,对特征之间高相关性的考虑不足的问题,提出了一种基于特征聚类和评价的轴承寿命预测新方法,并得到了以下结论:
(1) 提出了一种Corr-Kmeans聚类算法,该算法能够将特征按照相关性进行聚类;提出了一种改进的Corr-Kmeans初始聚类中心确定方法,相比于随机初始聚类中心,聚类结果更加稳定。
(2) Corr-Kmeans聚类算法和特征评价相结合的方法,能使特征与时间序列保持高相关性的同时,降低特征之间的相关性,最终所选的特征子集更有利于轴承剩余寿命预测。
(3) 该方法相比单一的特征评价方法和用初始特征直接预测等方法精度均有一定的提升,同时在不同的工况下也表现出了较好的适用性。
