网页信息抽取方法综述
2022-03-18王立志
◆王立志
网页信息抽取方法综述
◆王立志
(四川大学网络空间安全学院 四川 610065)
随着互联网的快速发展,网络中的信息正在爆炸式地增长,网页作为网络中信息表达的方式之一,其结构也变得越来越复杂。而如何精确、高效地从网页中获取目标信息成为一个问题。本文总结现有的针对网页的信息抽取方法并加以分类,同时分析其优缺点,最后对未来的研究内容进行展望。
信息抽取;WEB网页;DOM树
根据2021年第48次《中国互联网络发展状况统计报告》所发布的内容,截至2021年6月,我国网站数量达到422万个,这些网站构成了一个巨大的开源信息库。人们可以通过数据分析的方法,从这些海量的互联网数据中获取到具有巨大价值的情报。而网页作为互联网中信息展示与表达的重要方式之一,成为人们从互联网中获取信息的重要入口之一。通过编写爬虫程序访问网页,就能获取到互联网中各个网站的页面信息,作为后续数据挖掘与分析等工作的基础数据。但由于互联网中网页具有数量庞大、页面结构差异大,数据实时性强等特点,因此从不同类型、不同结构的网页中自动抽取目标信息成为一个巨大的挑战。
从页面结构的角度看,网页可以分为两类:
非结构化网页,其页面中包含大量有较高自由度的文本数据,如新闻网页,博客网页等;半结构化网页,其页面中包含有结构较为固定的文本或固定的页面结构,如购物网站的商品页面,新闻网站的导航页面等。
信息抽取解决的问题,是如何从非结构化以及半结构化的页面中,识别并获取到目标信息,即如何将目标信息结构化的问题。其目的是实现从网页中精确地、高效地提取目标信息。随着研究者对该问题的深入研究,出现了许多优秀的网页信息抽取方法,大大推动了网页信息抽取技术的发展。
1 网页信息抽取方法的分类
目前常见的网页信息抽取方法有:基于手工的抽取方法、基于视觉的抽取方法、基于统计的抽取方法,以及基于机器学习与深度学习的抽取方法。
1.1 基于手工的网页信息抽取方法
早期互联网中大多为静态页面,对于获取网页中的信息,较为简单的方法为:利用XPATH、CSS、正则表达式等方法,手工编写对应的提取规则来实现对页面中信息的抽取[1-3]。该方法具有精确度高的特点,能够根据需求对网页中的目标信息进行精确定位与获取,但该方法人工参与度高,耗时长,页面发生变化后便需要再次对提取规则进行修改,维护成本大,不适用于大批量目标网站信息提取的场景。
1.2 基于视觉的网页信息抽取方法
网页的视觉结构能够天然地将信息进行分类,以便于浏览者轻松地定位到自己想要的信息,通过对其视觉结构特征进行分析与处理,能够很好地从人们视觉浏览角度解析页面,从而提高信息提取的准确性,因此,出现了对网页视觉结构上的研究方法。VIPS[4]算法是最早的基于视觉分块的抽取方法,由微软公司所提出。该方法通过使用页面视觉上的分块特征对页面的内容进行抽取与分类。此后,Wei Liu等人提出的VIDE[5]方法、Neil等人[6]所提出的抽取算法以及Narwal等人[7]提出的算法均基于视觉分块特征。基于视觉结构的方法对于结构简单的页面能够有较好的提取效果,但随着网络发展,WEB页面中的结构变得更加复杂,信息也变得不再单一,块与块之间的界限也变得模糊,提取难度也逐渐增大。近期,王卫红[8]等人对视觉信息进行改进,提出了一种基于启发式规则构建可视块与可视块树,然后进行噪声过滤与信息筛选的方法VBIE,该方法对于复杂网页进行信息抽取有较高的精确度与提取效率。
1.3 基于统计的网页信息抽取方法
DOM(Document Object Model)能将HTML结构转化成树形结构,HTML中的每一个标签便对应DOM树中的一个节点,通过DOM树能够很方便地对HTML中的标签进行访问、修改等操作,同时,网页中的信息在DOM树结构上都有相应的特点。因此,也有针对DOM树中信息节点的统计特征的研究。网页中常见的统计特征有:文本密度特征[9-10]、文本字符特征[11]、DOM树结构特征[12]等。Patricia Jiménez等人[13]提出了一种Roller的方法,基于DOM树,通过动态搜索来发现提取信息节点的上下文,该方法能够适应对新网页进行提取,有较好的扩展性;文献[14]则采用了从已知文本中进行推断的方法来进行网页信息的抽取。Sleiman H A等人[15]提出的TEX方法则不需要将HTML页面转化为DOM树,而是采用多字符串对齐的方法对页面文本进行匹配与提取,并通过实验证明该方法的有效性与高效性。对于特定类型的网页,其具有不易变化的特征,因此基于统计的方法能够很好地达到抽取的目的,但在普适性方面还是会有一定的局限性。
1.4 基于机器学习与深度学习的信息抽取方法
随着机器学习与深度学习的快速发展,也有研究者将其结合到网页信息抽取的问题中,通过对DOM树中的各类特征进行分析与处理,然后通过机器学习与深度学习的方法,训练模型来对这些特征进行学习,进而达到信息抽取的目的。文献[11]的方法便基于SVM模型来对网页中的信息进行分类与提取,而Bill Yuchen Lin[16]等人提出了基于两阶段神经网络模型的网页信息提取方法FreeDOM,通过文本与字符信息学习页面中DOM节点的表示,再使用关系神经网络来关联远距离的语义相关性,该方法能经少量网站数据训练后推广到更多的新的站点。Wai F K等人[17]提出了CMDR方法,通过学习网页特征构建神经网络,并与现有的信息提取方法MDR[18]进行结合。Liu J等人[19]提出VIBS算法则是结合了CNN来对页面中的视觉块进行有效地划分。基于机器学习与深度学习的方法能够在统计特征的基础上发现一些更加隐蔽的网页特征,从而能有更好的抽取效果,但模型训练需要研究者事先对训练数据进行标注,并且模型也是在特定类型与场景的网页下进行训练与预测,因此同样也可能存在普适性的问题。
2 评价指标
目前网页信息抽取常见的评价方法为准确率(Precision)、召回率(Recall)以及值,其对应的计算公式为:
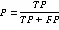
其中表示所抽取到的信息中为正确的部分,表示所抽取到的信息中为错误的部分,表示未被成功抽取的信息中,真实需要抽取的部分。准确率越高,则说明抽取算法的结果越精准,召回率越高,则说明抽取算法的结果越与正确结果相接近,而值则是对抽取算法的一个综合评价指标。
3 结束语
随着互联网发展,从各式各样的WEB页面中提取目标信息成为一个巨大的挑战。本文总结了目前常见的网页信息抽取方法,并对其优点与缺点进行概括。网页信息抽取目前已经有许多优秀的研究方法,并随着技术的进步在不断优化与创新,但这些方法都为针对特定类型或特征结构的网页进行信息抽取,而对于是否有更加普适性的抽取方法还需要继续研究与思考。
[1]Valter Crescenzi,Giansalvatore Mecca,Grammars have exceptions,Inf. Syst. 23(8)(1998)539–565.
[2]Joachim Hammer,Jason McHugh,Hector Garcia-Molina, Semistructured data:the TSIMMIS experience,in:Advances in Databases and Information Systems,1997,pp. 1-8.
[3]Arnaud Sahuguet,Fabien Azavant,Building intelligent web applications using lightweight wrappers,Data Knowl. Eng. 36(3)(2001)283–316.
[4]Deng Cai ,Shipeng Yu ,Ji-Rong Wen ,et al .VIPS :a vi- sion-based page segmentation algorithm[R].USA: Microsoft Technical Report,2003.
[5]Wei Liu,Xiaofeng Meng,Weiyi Meng.ViDE:a vision- based approach for deep web data extraction[J].IEEE Trans.Knowl.Data Eng.,2009,22(3):447-460.
[6]Anderson N,Hong J . Visually extracting data records from the deep web[C]// the 22nd International Conference. ACM,2013.
[7]Narwal N. Improving Web data extraction by noise removal[C]// Communication & Computing. IET,2013.
[8]王卫红,梁朝凯,闵勇. 基于可视块的多记录型复杂网页信息提取算法[J]. 计算机科学,2019.
[9]王海艳,曹攀.基于节点属性与正文内容的海量Web信息抽取方法[J].通信学报,2016,37(10):9-17.
[10]向菁菁,耿光刚,李晓东.一种新闻网页关键信息的提取算法[J].计算机应用,2016,36(08):2082-2086+2120.
[11]周艳平,李金鹏,宋群豹. 一种基于SVM及文本密度特征的网页信息提取方法[J]. 计算机应用与软件,2019,036(010):251-255,261
[12]刘春梅,郭岩,俞晓明,等.针对开源论坛网页的信息抽取研究[J].计算机科学与探索,2017,11(01):114- 123.
[13]P Jiménez,Corchuelo R . Roller:a novel approach to Web information extraction[J]. Knowledge & Information Systems, 2016,208(1):1-45.
[14]Raza M,Gulwani S . Web Data Extraction using Hybrid Program Synthesis:A Combination of Top-down and Bottom-up Inference[C]// SIGMOD/PODS '20:International Conference on Management of Data. 2020.
[15]Sleiman H A,Corchuelo R . TEX:An efficient and effective unsupervised Web information extractor[J]. Knowledge-Based Systems,2013,39(feb.):109-123.
[16]Lin B Y,Sheng Y,Vo N,et al. FreeDOM:A Transferable Neural Architecture for Structured Information Extraction on Web Documents[C]// KDD '20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM,2020.
[17]Wai F K,Yong L W,Thing V,et al. CMDR:Classifying nodes for mining data records with different HTML structures[C]// Region 10 Conference. IEEE,2017:1862-1862.
[18]Yanhong Zhai and Bing Liu. Structured data extraction from the web based on partial tree alignment. IEEE Trans. on Knowl. and Data Eng.,18(12),2006.
[19]Liu J,Lin L,Cai Z,et al. Deep web data extraction based on visual information processing[J].Journal of Ambient Intelligence and Humanized Computing,2017:1-11.
