基于分形残差网络的单幅图像超分辨率重建
2022-03-18陈乔松官暘珺范金松王子权
陈乔松,宗 冕,官暘珺,范金松,王子权,邓 欣,王 进
(重庆邮电大学 计算机科学与技术学院数据工程与可视计算重点实验室,重庆 400065)
0 引 言
单幅图像超分辨率重建技术是将一幅低分辨率的图像重建成相应的高分辨率图像。高分辨率图像具有较高的像素密度,可以提供更多的纹理细节,具有更强的信息表达能力。在实际应用中,由于受到硬件和环境的限制,人们很难直接获得高分辨率的图像。因此,利用现有设备,通过超分辨率技术重建出高分辨率图像具有重要的现实意义。
目前,超分辨率重建算法主要分为3类:基于插值的方法、基于重构的方法和基于学习的方法。其中,基于插值的超分辨率算法[1-2]简单、计算量小,但重建效果较差;基于重建的方法[3-5]过度依赖于高分辨率图像的先验知识;基于学习的方法成为了主流的方法,它大致有3类:基于稀疏表示的学习算法[6-7]、基于近邻嵌入的学习算法[8-9]和基于深度学习的算法[10]。
近年来,随着深度学习技术的快速发展,超分辨率重建的效果有了很大的提升。Dong等首次尝试将卷积神经网络(convolutional neural networks,CNNs)应用于超分辨率重建,他们建立了一个三层卷积神经网络模型(super resolution convolutional neural network, SRCNN)[10],以端到端的方式学习从低分辨率图像到高分辨率图像对的非线性映射,在重建效果上有了显著的改善。受此启发,Kim等[11]提出了一个超深卷积网络(very deep convolutional networks, VDSR),VDSR采用20层卷积网络,将残差学习和梯度裁剪方法相结合,加快了网络的收敛速度。Lai等[12]提出的LapSRN算法采用拉普拉斯金字塔网络(laplacian pyramid super resolution network, LapSRN)逐步重建高分辨率图像。Li等[13]提出了多尺度残差网络(multi-scale residual network, MSRN)算法,该算法提出了多尺度残差块,最大限度地提取低分辨率图像的特征,使得重建图片的边缘和轮廓变得更加清晰。
以上大多数超分辨率模型都致力于建立更深、更复杂的网络结构,参数量庞大并且训练困难。而且,大多数模型都平等地处理通道特征图,在处理不同层次的信息时缺乏灵活性,因此,这些模型在一定程度上削弱了CNNs的表征能力。
针对以上问题,本文提出了一种新型的分形残差网络模型。与现有的基于CNNs的方法相比,该模型可以在不牺牲太多资源的情况下获得更好的性能。本文所提模型的创新点主要包括以下3个方面。
1)设计了分形残差网络(fractal residual network,FRN),可以有效而准确地从低分辨率图像中重建出高分辨率图像。
2)对特征提取块之间的跳层连接结构进行了修改,以便更好地进行特征提取。实验结果表明,这些简单而有效的修改可以显著提高超分辨率性能。
3)提出了分形残差注意力块(fractal residual attention block,FRAB),它可以有效地提取多尺度特征,并通过多条交织的路径将它们融合,同时对特征通道间的依赖性进行建模来重新校准特征,以实现准确的局部特征表示。
1 相关工作
1.1 特征提取块
迄今为止,已经有多种特征提取块被提出。特征提取块的比较见图1。
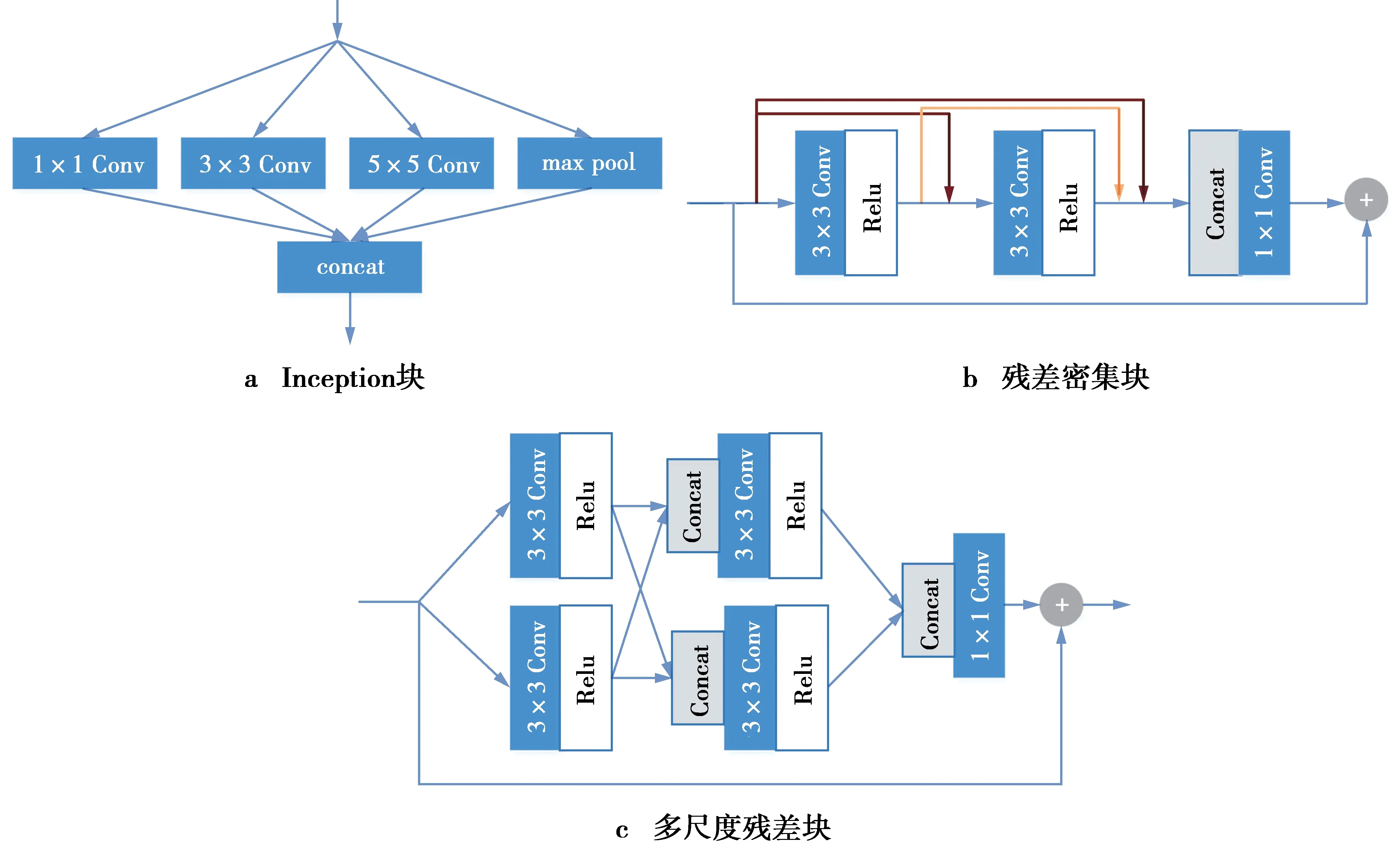
图1 特征提取块的比较Fig.1 Comparison of feature extraction blocks
图1a中的inception块[14]在同一层中使用不同大小的卷积核来提取不同的特征,并且使用信道拼接方式来对特征进行融合,增加了特征的丰富度。Zhang等[15]设计了残差密集块,见图1b,它结合残差密集思想,充分提取局部和全局特征,其中跳跃连接结构可以提供互补的上下文信息。Li等[16]提出了多尺度残差块,见图1c,将多尺度特征融合与局部残差学习相结合,更好地提取图像特征。
1.2 注意力机制
注意力机制在人类感知中起着重要作用,人类视觉会自适应地处理视觉信息并专注于突出区域。注意力机制最初是在机器翻译[15]中提出的,它通过综合考虑来自多个时间步长的输入来进行单步预测。目前,该方法已经广泛应用于许多计算机视觉任务,例如图像生成[17]、图像分类[18-19]和图像恢复[20-21]。Hu等[18]提出了挤压激励网络(squeeze and excitation networks, SENET),该网络设计了一种挤压激励块,它可以自适应地校准特征通道关系以进行图像分类。Zhang等[20]受到SENET的启发,提出一个非常深的残差信道注意网络(residual channel attention networks, RCAN),并在准确性和视觉感知上表现良好。为了改善CNN模型的表示能力,我们引入SENET提出的注意力机制来灵活地缩放通道特征。
2 方法
2.1 基础网络结构
FRN的模型架构见图2,本文提出的网络由4部分组成:浅层特征提取模块、基于分形残差注意力块的深层特征提取模块、上采样模块和重建模块。浅层特征提取模块使用一个3×3卷积来提取原始的底层特征,深层特征提取模块叠加了9个分形残差注意力块,每个块的输出使用1×1卷积进行细化,再将细化的结果与浅层特征提取模块的输出进行融合,改善梯度消失和网络退化问题。上采样模块先分别将浅层特征提取模块和深度特征提取模块的输出利用亚像素卷积放大,再将放大的结果进行融合。最后,重建模块使用1×1卷积得到最终的高分辨率图像。
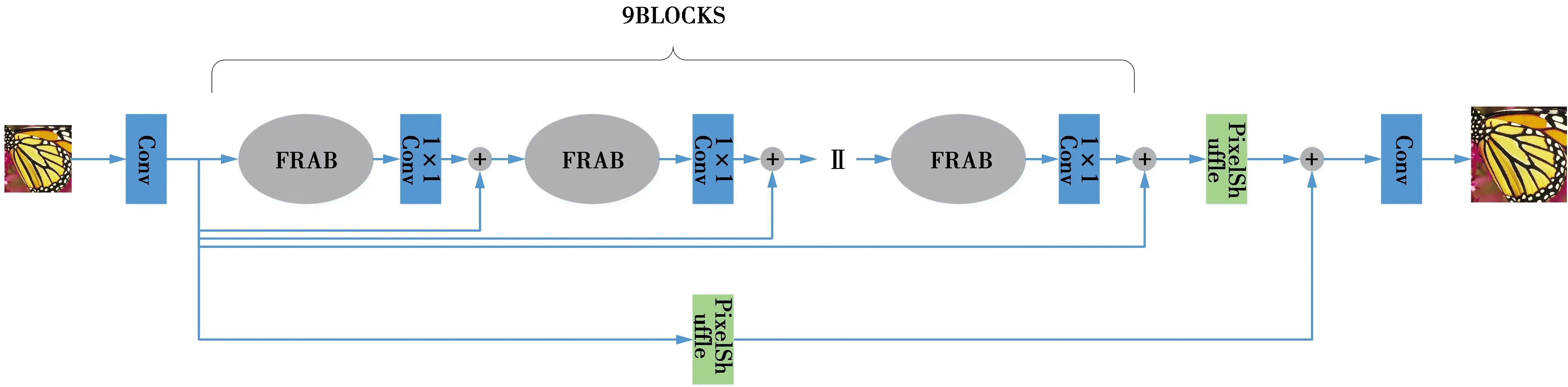
图2 FRN的模型架构Fig.2 Architecture of FRN model
2.2 跳跃连接
由于信道拼接会增加特征的通道数,为后面的卷积操作增加额外的计算时间,因此,采用了跳跃连接,见图3。该结构不仅可以保留低层特征,降低训练难度,还可以使梯度信号直接从高级特征向后传播,减轻梯度消失问题。因此,跳跃连接提高了网络的学习能力,使网络能够学习更复杂的特征。
图3中,考虑了2种设计方案,第1种见图3a,借鉴了稠密网络(densely connected convolutional networks, Densenet)[22]、真实感知网络(photo-realistic image super-resolution network, SRResnet)[23]和重建分类网络(deep reconstruction-classification networks, DRCN)[24]的做法,直接在不同特征提取块间添加跳跃连接。可以通过公式描述如下
Fn=Hdf(F-1+Fn-1)
(1)
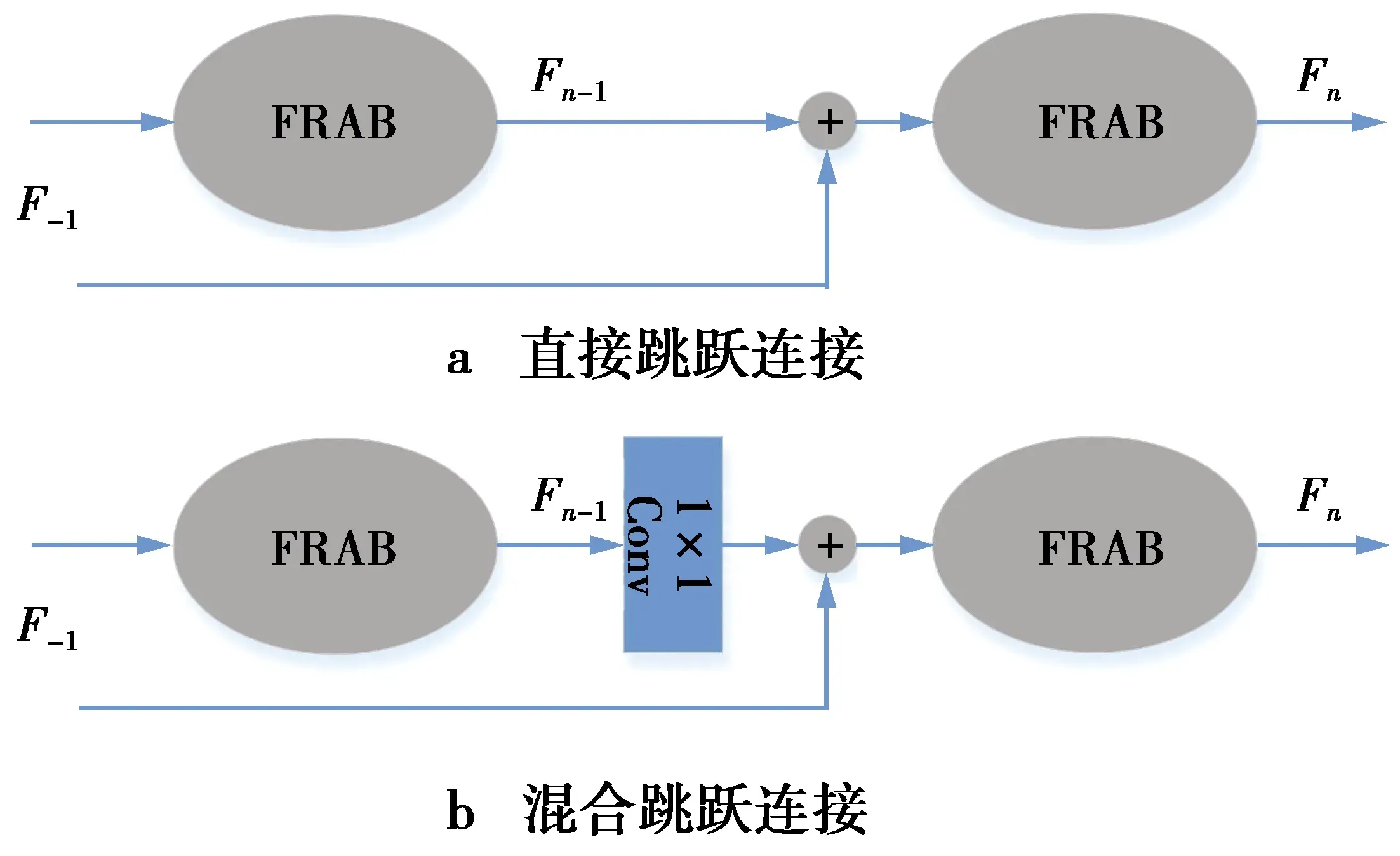
图3 跳跃连接方式Fig.3 Skip connections
(1)式中:F-1代表浅层特征提取模块的输出;Fn-1和Fn分别代表第n-1个和第n个特征提取块的输出;Hdf代表分形残差注意力块。
第2种方案见图3b,利用跳跃连接和1×1卷积层来连接不同的FRAB,第n个FRAB的输出可以表示为
Fn=Hdf(F-1+H1×1(Fn-1))
(2)
(2)式中,H1×1代表1×1卷积操作。我们将对这2种方案进行实验评估,并讨论最佳方案。
2.3 分形残差注意力块
为了自适应地检测和融合不同尺度下的图像特征,提出了分形残差注意力块。分形残差注意力块见图4。在该结构中,不同的路径使用相同大小但网络深度不同的卷积核,从不同路径提取的特征不仅会在网络的尾部融合,而且会在网络的前馈过程中融合。该结构具有以下优点:①不同路径之间的信息可以相互共享,能够生成和组合不同的层次结构特征;②每条路径都可以利用不同路径的梯度来缓解训练过程中的消失梯度问题。并且如果某一条路径学习到对最终重建起到非常重要作用的特征时,那么通过loss的反向传播,就会指导和该路径联合的另外一条路径也学习到这种重要的特征,通过模型内部的不断学习,可以提高整个模型的效果。最好在模块的尾部引入了注意力机制,使得网络具有强大的表达能力。
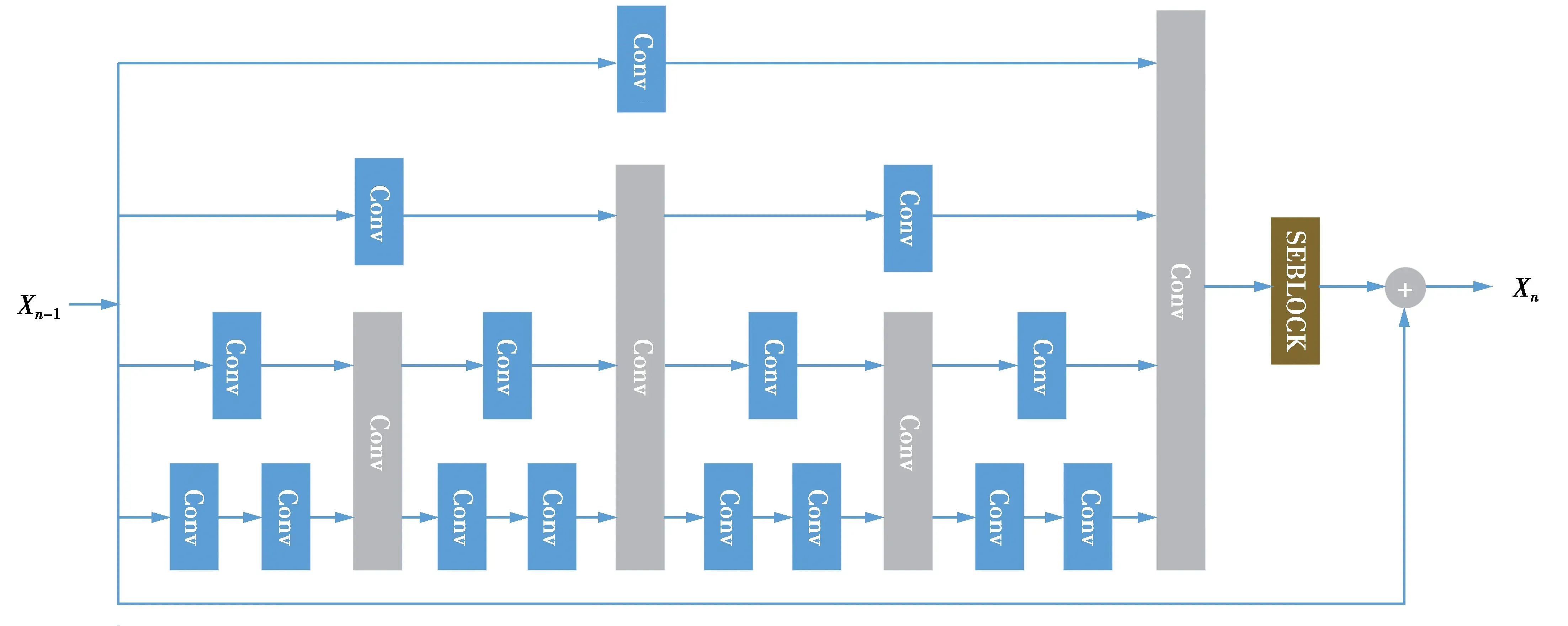
图4 分形残差注意力块Fig.4 Fractal residual attention block
2.4 损失函数
在深度学习中,损失函数起着至关重要的作用。通过最小化损失函数,使模型可以达到收敛状态并减少模型预测值的误差。因此,不同的损失函数会对模型产生重大影响。目前,超分辨率任务中使用的主流损失函数有2种:L1损失函数和L2损失函数。本文算法使用L1损失函数,而不采用可以得到更高峰值信噪比值的L2损失函数。根据VDSR[11]实验结果,使用L2损失函数的模型生成的图片过于平滑,失真较严重。所以本文采用L1损失函数,公式为
(3)
(3)式中:I表示网络重建后的图像;G表示对应的高分辨率图像;i表示第n张训练样本。
3 实 验
3.1 数据集
本文采用Timofte等发布的DIV2K[25]数据集来训练网络,该数据集包含800张训练图片、100张验证图片和100张测试图片。使用800张训练图片进行训练,并使用最后5张验证图片来验证我们的模型。测试集则采用了Set5[26]、Set14[27]、BSDS100[28]、Urban100[29]、Manga109[30]这5个超分辨率重建评价数据集,这些数据集包含各种各样的图像,可以充分评估SR模型的有效性。
3.2 参数设置
本文实验所用GPU型号为NVIDIA GeForce GTX 1070,内存大小为16 GB;软件环境为windows 10,MATLAB R2018b,CUDA v10.1以及计算机视觉库 Pytorch。
在进行训练前,首先将HR图像随机裁剪为48×48的子图,使用Matlab的imresize函数,采用水平、垂直翻转等方式将数据集进行扩增,获得更多训练样本。训练过程采用小批量(mini-batch)学习,小批量学习的数目设置为16。使用Adam优化算法[31]优化网络。初始学习率设置1E-4,每训练200个epoch,学习率减半,总共训练1 000轮。我们将FRAB的数量设置为9,每个FRAB中交织路径的数量为4,FRAB的输出均为64个特征图。
3.3 客观对比
实验结果采用了图像质量的通用客观评价标准:峰值信噪比(PSNR)和结构相似性(SSIM)。PSNR是根据两幅图像对应像素点的灰度值差异来评估图像质量。PSNR的值越大表示图像质量越好,其单位为dB,公式如下
(4)
(4)式中:n为每像素的比特数,一般的灰度图像取8,即像素灰阶数为256,MSE为当前图像X和参考图像Y的均方误差,用eMSE表示为
(5)
(5)式中:H为图像的高度;W为图像的宽度。
SSIM是用来衡量两幅图像相似性的指标,它的取值为[0,1],SSIM的值越接近于1表明重建图像越接近原始图像。它的计算公式如下
SSIM(X,Y) =l(X,Y)×c(X,Y)×s(X,Y)
(6)
(7)
(8)
(9)
(6)—(9)式中:u和σ分别为两幅图像的像素均值和方差,C1,C2,C3设置为常数,目的是避免分母为0的情况。
我们对双三次插值[2]、SRCNN[10]、VDSR[11]、LapSRN[12]、MSRN[13]、DRCN[24]和CARN[32]算法进行了比较。由于MSRN是一种最先进的方法,它不仅使用了多尺度特征提取方法,并且其参数量(6.3M)和我们的方法(6.0M)相近,因此,我们重点与该方法进行对比。此外,我们还引进了集成策略来进一步提高重建效果,集成策略首先将输入图像顺时针旋转90度从而得到4张低分辨率输入图像,然后将这4张图像输入到网络中生成4张高分辨率图像,再将高分辨率图像分别逆时针旋转90度,最后再取4张图像的均值得到最终的高分辨率图像,将使用集成策略的FRN记为FRN+。
评价的结果见表1—表3,与之前所有的方法相比,FRN+在所有数据集上执行效果最好。即使没有集成策略,FRN也优于其他的方法。从表1—表3中可以看出,提出的网络在各个尺度上都优于MSRN。其中,在放大倍数为4的评估中,所提出的方法在Urban100和Manga109上分别以0.44 dB和0.67 dB的性能优于MSRN,在放大倍数为3的评估中,所提出的方法在Urban100和Manga109上分别以0.54 dB和0.59 dB的性能优于MSRN,这证明了提出的网络的有效性。

表1 2倍尺度放大PSNR和SSIM对比Tab.1 2x scaled PSNR and SSIM comparison
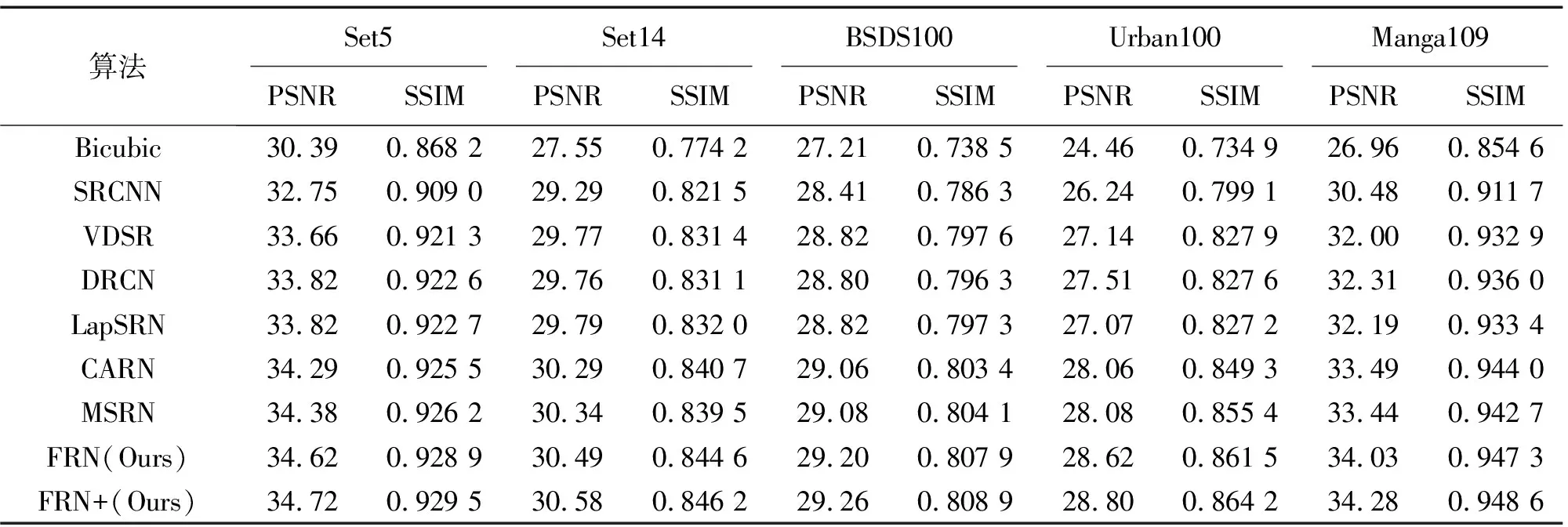
表2 3倍尺度放大PSNR和SSIM对比Tab.2 3x scaled PSNR and SSIM comparison

表3 4倍尺度放大PSNR和SSIM对比Tab.3 4x scaled PSNR and SSIM comparison
3.4 主观对比
为了从视觉感知上进行算法的比较,本文从Urban100数据集中抽取了“img074.png”这张具有代表性的图片进行重建效果的可视化,首先将它用双三次插值(Bicubic)退化缩小4倍,再输入到不同超分辨率重建网络中。实验效果图见图5。可以看到,本文算法相比其他方法,恢复的边缘和纹理更加清晰。
3.5 消融研究
3.5.1 跳跃连接
评估了跳跃连接的2种方案的有效性。表4展示了不同方案模型在Urban100数据集上放大2倍的实验结果。可以看到,直接在不同深度的层之间添加跳跃连接,PSNR指数的值为32.57 dB,只添加1×1卷积,PSNR指数的值为32.67 dB。相比之下,通过在跳跃连接之前添加1×1卷积层可以显著提高恢复精度。这是因为在FRAB提取的特征图与浅层特征提取模块的输出组合之前,先通过1×1卷积层进行自适应调整,可以训练出更多不同的特征,实现高质量的图像恢复。因此,PSNR指数达到了32.70 dB,SSIM指数达到了0.933 4。

表4 跳跃连接对重建质量的消融研究Tab.4 Research on ablation of reconstruction quality by jump connection

图5 放大尺度为4倍的效果对比图Fig.5 Comparison of the results at a magnification scale of 4
3.5.2 交织路径
为了研究交织路径数量对重建性能的影响,我们训练了3个模型,每个模型的FRAB中分别包含2条、3条和4条的交织路径。在这3个模型中,FRAB中的filter数量都为64个。用P=2,P=3,P=4来表示具有不同数量的交织路径的模型。见表5,提取多尺度局部图像特征的路径越复杂,模型的性能越好,这是由于路径越多,FRAB就能够充分利用低层特征,获得更多的高频信息。由于模型P=4在所有数据集上都比其他模型表现好得多,所以我们在FRAB中将4设置为交织路径的默认数量。

表5 交织数量对重建质量的消融研究Tab.5 Research on ablation of interweaving quantity on reconstruction quality
3.5.3 通道注意力机制
为了研究CA机制对性能的贡献,将CA模块去掉以观察效果。表6显示了 CA模块在Urban100数据集上消融研究的结果(“×”代表没有CA的模型,“√”代表有CA的模型)。可以看到,带有CA的模型在×2、×3和×4三个放大因子下比不带CA的模型其PSNR分别提高了0.01,0.07和0.07 dB。这是因为添加了CA模块的网络选择性地加强了带有高频信息的特征图并减弱带有低频信息的特征图,提高了其辨别学习能力,有效地改善了重建性能。
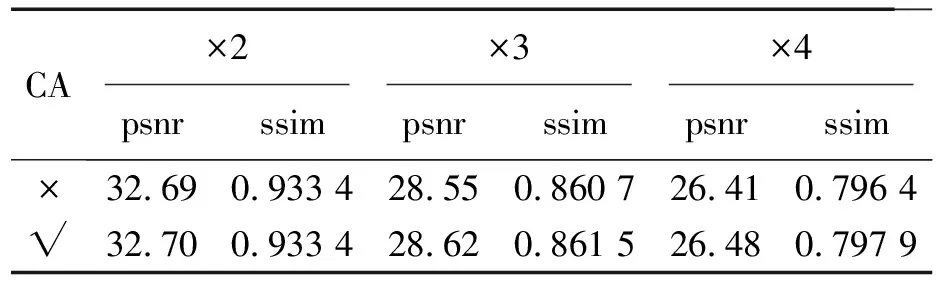
表6 CA模块对重建质量的消融研究Tab.6 Research on CA module Ablation of reconstruction quality
4 结束语
为了解决当前主流算法对低分辨率图像中的细节信息利用不充分的问题,本文提出了一种基于分形残差网络的图像超分辨率重建算法。该算法使用分形残差注意力块来自适应地提取和融合不同尺度的图像特征。另外,对跳跃连接结构进行了改进,使得网络可以训练出更独有的特征,并解决梯度消失问题。 通过在各个数据集上的评测结果可以看出,本文算法可以从低分辨率图像中恢复出更多细节信息,性能上也优于目前大多数的方法。在未来的工作中,将寻找更好的优化策略来进一步提高重建效果。
