任意方向自然场景文本识别
2022-03-18景小荣
朱 莉,陈 宏,景小荣,3
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.四川师范大学 物理与电子工程学院,成都 610101;.重庆邮电大学 移动通信技术重庆市重点实验室,重庆 400065)
0 引 言
随着智能设备的普及,人们可轻易地获取图像。文本作为图像中的高层语义信息,能够帮助人们更好地理解图像。将图像中的文本信息转换为计算机可读可编辑的字符,对提高多媒体检索能力、工业自动化水平、场景理解能力等具有重要意义。与自然场景文本识别相对应的是光学字符识别,光学字符识别一般针对的是白底黑字,易于区分的文档类文本,文档类文本的识别目前已经得到了很好的解决。而在自然场景文本中,由于文字类型多样,场景复杂多变,场景噪声等因素的存在,其识别被视作计算机视觉领域一项极具挑战性的任务。
早期的场景文本识别分别对单个字符进行检测和分类,再将分类结果转换为序列信息[1-4]。这类方法需要字符级别的标注信息,人工标注的成本过高。同时字符分类和检测的错误会累计并直接影响最终的识别精度。
受语音识别技术的启发,近年来,几乎所有的算法都将场景文本识别看作序列预测问题[5-11]。基于序列的场景文本识别算法,常常用到序列特征提取器长短时记忆模块(long short-term memory,LSTM)[12]或者编码-解码-注意力模块(encode-decode-attention,EDA)[13]。由于LSTM的状态转换层采用的全连接,因此,进行序列特征提取前需要将二维信息压缩成一维序列,这势必会造成重要信息的丢失或者引入不必要的噪声。而EDA模块是一种编解码注意力机制,解码过程中循环使用上一次解码输出作为下一次解码输入,这种机制容易造成蝴蝶效应,一个解码错误会导致一连串的错误。
为了解决基于序列的方法存在的问题,出现了基于二维视角的文本识别方法,该方法在保持图像二维信息的同时进行预测。文献[14]使用分割网络,对输入图像进行像素级的分类。文献[15]为了保存图像的二维信息使用二维时序分类(two-dimensional connectionist temporal classification,2D-CTC)算法进行预测。这类方法虽然保存了图像的二维信息,却也忽略了图像的序列信息。
为了解决现有方法存在的问题,本文提出一种新的任意方向的自然场景文本识别算法,通过3个方面提高识别性能:①使用高分辨率分割网络对图像进行像素级的分类;②将文本识别看作一个时空序列预测问题,在特征提取阶段使用卷积长短时记忆模块(convolutional long short-term memory,ConvLSTM)[16]提取文本的时空序列信息;③在网络中加入字符注意力机制,告诉网络应该把注意力放在图像的什么位置。
1 网络框架
为了解决现有文本识别方法存在的问题,提出一种新的任意方向的自然场景文本识别方法,与该方法对应的网络结构见图1。在该结构中,包括高分辨率分割模块、ConvLSTM模块和字符掩模模块,下面分别给出详细的说明。
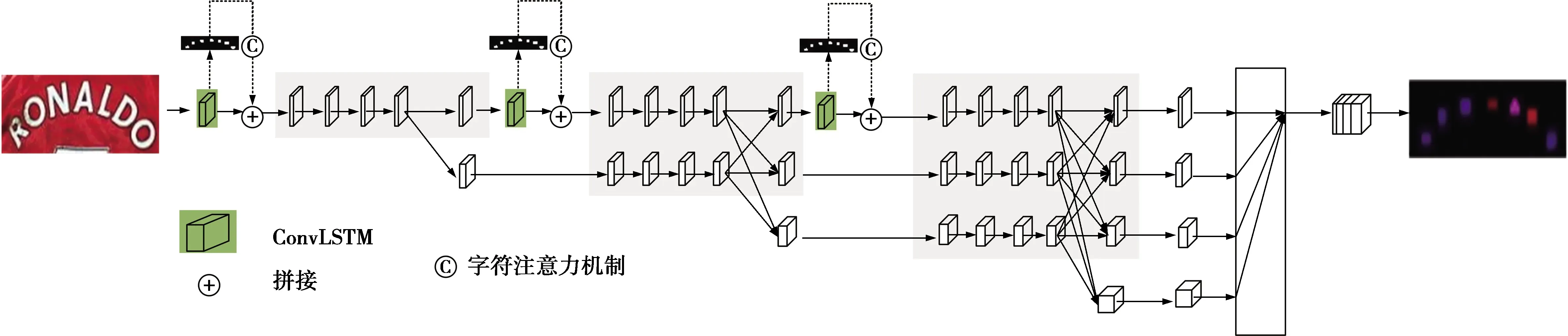
图1 任意方向场景文本识别框架Fig.1 Any direction scene text recognition architecture
1.1 高分辨率分割网络
本文提出的任意方向场景文本识别算法使用的基础框架是高分辨率分割网络(high resolution network,HRNet)[17]。HRNet网络结构简化示意图见图2,其中1×,2×,4×,8×分别表示不同分辨率的特征。以往的分割网络沿用了分类网络的串行连接高低分辨率卷积的结构,在此结构的基础上,为了恢复高分辨率通常采用上采样操作,但上采样本身并不能完整地弥补局部信息的丢失。针对这一问题,HRNet提出一种新的并行连接高低分辨率卷积网络。整个网络始终保持高分辨率特征,逐步引入低分辨率卷积,并且将不同分辨率的卷积并行连接。同时,通过不断在多分辨率特征之间进行信息交换,来提升高分辨率和低分辨率特征的表达能力,让多分辨率特征之间更好地相互促进。其中,在进行多分辨率特征之间的信息交换时,高分辨率降到低分辨率采用步长为2的3*3卷积;低分辨率特征到高分辨率特征时,先利用1*1卷积进行通道数的匹配,再利用最近邻插值的方式来提高分辨率;相同分辨率的特征则采用恒等映射。

图2 HRNet网络结构Fig.2 HRNet network framework
1.2 ConvLSTM模块
考虑到文本的上下文通常都有联系,经典的文本识别算法常把文本识别看作序列预测问题。而LSTM是文本识别任务中最常用的序列特征提取器,由于LSTM的状态转换层是全连接,因此,使用LSTM进行序列特征提取时需要将二维图像压缩成一维序列信息,会造成空间信息的丢失。针对这个现象,本文将文本识别看作时空序列预测问题,本文在HRNet的基础上,引入了ConvLSTM模块,ConvLSTM可在保证图像二维信息的同时提取文本的序列信息。下面详细说明LSTM和ConvLSTM分别如何提取信息。
1)LSTM信息提取。传统的文本识别方法把文本识别看作序列预测问题,并使用LSTM进行序列特征提取。LSTM有3个门,分别为遗忘门fi、记忆门ii和输出门ot。LSTM中的门是一种让信息选择性通过的方法,LSTM门结构示意图见图3,主要由sigmoid激活函数跟元素点乘操作组成。sigmoid函数输出[0,1]的数,这个数代表了信息保留的比率,例如数值1代表信息全部保留。
LSTM的内部结构示意图见图4,遗忘门的作用是选择性地舍弃上一个状态ct-1的信息。使用sigmoid激活函数作用于输入ht-1,xt,计算式为
ft=σ(wf[ht-1,xt]+bf)
(1)
it=σ(wi[ht-1,xt]+bi)
(2)
(3)
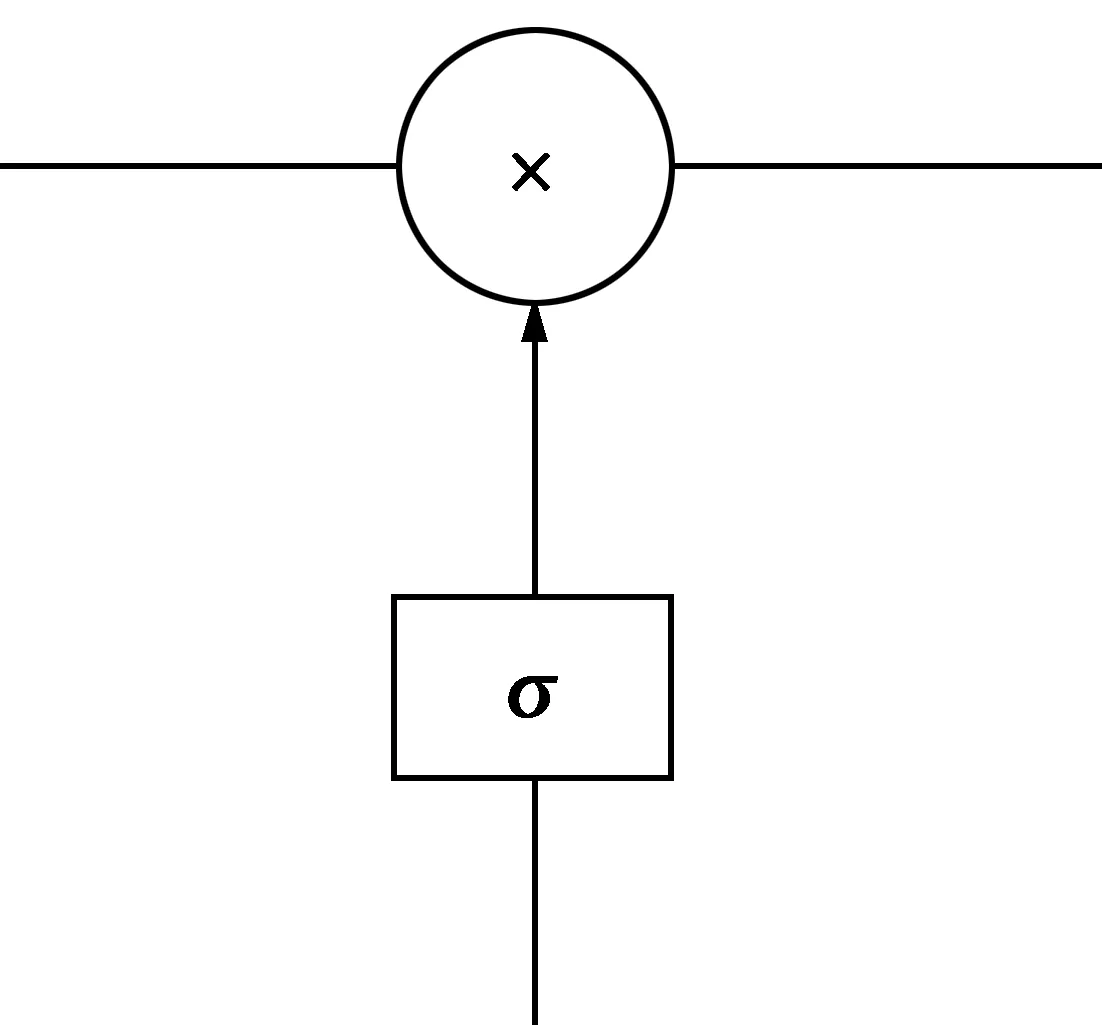
图3 LSTM门结构示意图Fig.3 LSTM door structure diagram

图4 LSTM内部结构示意图Fig.4 LSTM schematic diagram of internal structure
将遗忘门跟记忆门作用的结果相加,即可得到下一个状态ct,计算式为
(4)
输出门的作用是决定网络最终的输出状态。输出门的计算如(5)式,和(1)式,(2)式一样,使用sigmoid激活函数作用于ht-1,xt。对(4)式得到的ct使用tanh进行归一化后再与输出门得到的输出ot做元素点乘操作得到网络最终的输出状态ht。
ot=σ(wo[ht-1,xt]+bo)
(5)
ht=ot⊗tanh(ct)
(6)
(1)—(6)式中:wn,bn(n代表f,i,c,o)均为需要网络学习的权重参数;⊗代表元素点乘,等价于卷积操作。由此可见,LSTM的状态转换层均为全连接,见图5,因此,LSTM的输入只能是序列信息,这也成为了使用LSTM进行序列特征提取的性能瓶颈。

图5 FC-LSTM示意图Fig.5 Diagram of FC-LSTM
2)ConvLSTM信息提取。使用LSTM进行序列特征提取,必须将二维图像压缩为一维序列,这必然会丢失信息。文本识别准确地说应该是一个空间序列预测问题,ConvLSTM正好是解决空间序列信息的有力武器,ConvLSTM过程示意图见图6,ConvLSTM将LSTM中的状态转换层换成了卷积层,按照(7)—(12)式进行计算。本文使用ConvLSTM替换LSTM,有效地提取到了文本的时空序列信息,提升了最终的识别精度。

图6 ConvLSTM示意图Fig.6 Diagram of ConvLSTM
(7)
it=σ(wi⊗[ht-1,xt]+bi)
(8)
(9)
(10)
ot=σ(wo⊗[ht-1,xt]+bo)
(11)
ht=ot⊗tanh(ct)
(12)
1.3 字符掩模模块
场景文本有许多噪声,为了解决这个问题,常在网络中加入注意力机制。受文献[14]启发,在网络中使用字符掩模,可以帮助网络将注意力放在应该注意的地方。字符掩模模块加在每个ConvLSTM的后面,字符掩模模块的计算式为
Fo=Fi⊕(Fi⊗Cdb)
(13)
(13)式中:Fi,Fo分别代表输入和输出特征;⊕,⊗分别代表元素相加和元素相乘;Cdb代表对字符掩模模块的输出特征p进行近似二值化,计算式为
(14)
(14)式中,k代表二值化的程度,根据经验值k设置为50。字符掩模模块是由二层卷积和一个二分类的softmax函数组成,字符掩模模块的输出特征p中的所有元素都是0~1的概率值。对输出特征p中的所有元素使用可微分近似二值化函数得到非0即1的值,可以加大网络对前景的注意力,同时削弱对背景区域的关注。值得注意的是,可微分二值化函数仅在网络微调阶段使用。这是因为网络微调阶段的精度较高,网络中间得到的输出更加可信,此时,对分类分数高于0.5的概率值置1,对分类分数小于0.5的概率值置0,可以有效地抑制背景,高亮前景。
1.4 文本转录模块
网络输出为H×W×C的概率图,其中,H,W分别代表输出图像的高和宽;C代表网络预测的类别数。文本转录模块就是将概率图转换为文本信息,见图7。文本转录模块的步骤为①手动设置一个阈值,将概率图转换为二值图,这里的阈值根据经验设置为225;②根据二值图得到外轮廓的最小外接矩形,计算矩形所在区域的概率图的各通道概率值之和,取概率值最大的通道数的索引为最终的预测类别;③按照从左到右的顺序排列字符,得到最终的文本信息。
2 训练策略
2.1 标 签
网络的中间使用了字符注意力机制,它需要字符框标注信息辅助网络学习每个字符的位置。直接使用原始的字符框标注容易造成相邻字符粘连,因此,本文使用原始框标注的1/2大小用于辅助定位网络中间的字符信息。针对网络输出,为了避免网络对文本的边缘学习效果不佳,使用原始框1/4大小的区域代表整个字符。网络中间的标签需要将字符框的1/2大小区域像素值置为1,其余区域的像素值置为0。网络最终输出的标签需要将字符框的1/4大小区域像素值置为字符编码后的数值。字符编码对应关系为数字0-9编码后的值为1-10,字母a-z编码后的值为11-36,其余的一律编码为0。
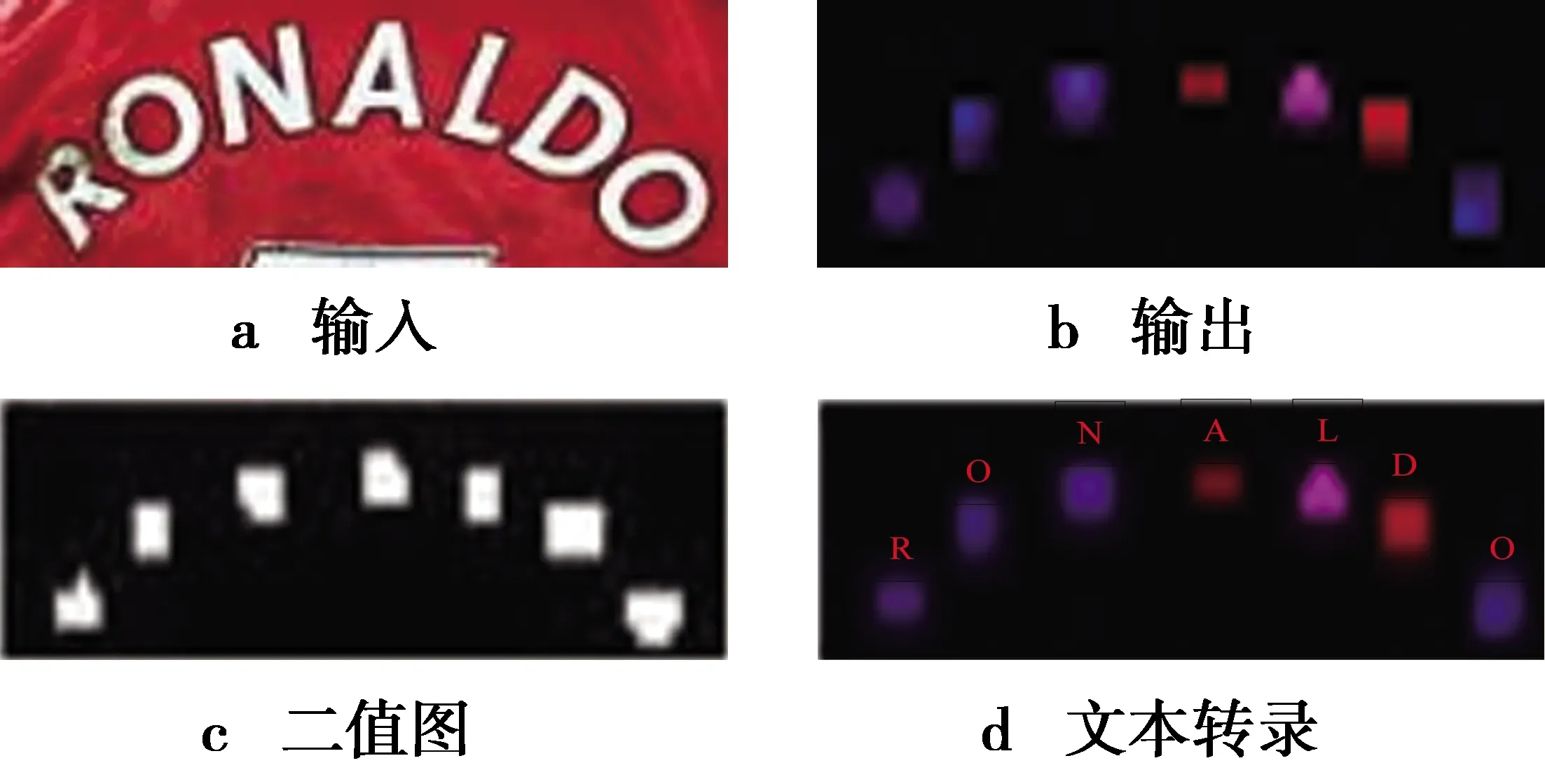
图7 文本转录模块Fig.7 Text transcription module
2.2 损失函数
与文献[14]相同,网络的损失由2部分组成,表示为
(15)
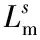
Lo的计算式为
(16)
(16)式中:c∈{0,1,…,C-1};yc代表真实的类别标签;pc代表网络对该像素点的类别预测概率;Wij是每个像素点的权重平衡因子。
假设N=H×W,Npos表示前景的像素点个数,则Wij的计算式为
(17)

(18)
(18)式中,Hs,Ws分别表示对应层的输出图像的高和宽。
3 数据集和实验细节
3.1 数据集
本文提出的算法只需在合成数据集SynthText上训练,不需要真实数据对网络进行微调。在通用的6个测试集上进行网络性能评估,包括规则文本数据集IIIT5K、低分辨率和强噪声的文本数据集SVT、透视文本数据集SVTP、弯曲文本数据集CUTE等。值得注意的是,本文均采用无词典识别方式,直接通过网络预测的输出计算正确率,正确率为正确识别的文本数跟所有文本总数的比值。
1) SynthText[18]是用于场景文本检测的数据集。原始数据集包含有80万的场景文本图像,每幅图上包含有多个文本。该数据集中的文本字体多样,背景复杂,且文本方向具有任意性。该数据集中的每个字符都有文本框标注。最终,从该数据集中裁剪出约7百万的数据用于文本识别。
2) IC03[19]过滤掉非字母数字字符或少于3个的单词的图像后还包含860张可用于文本识别训练的图像。
3) IC13[20]大部分数据继承自IC03,包含233张原图,裁剪后包含1 015张图像。
4) IIIT5K是由Mishra等[21]提出的。该数据集包含3 000张剪裁过的文本图像,大部分图像是规则的。
5) SVT是由Wang等[3]提出的。该数据集从谷歌街景中获取,共包含647张文本图像,由于该数据的低分辨率和强噪声导致该数据集的识别十分具有挑战性。
6) SVTP[22]是专为透视文本识别而设计的。包含238张跟SVT取自相同地址的街道拍摄图像,裁剪后包含645张图像。
7) CUTE是由文献[23]提出的,该数据集虽然只有288张图像,但该数据集大部分图像都是严重的弯曲文本,因此,该数据集相较其他数据集更具有挑战性。
3.2 实验细节
固定输入图像尺寸,高设置为64,宽设置为256。在训练阶段使用数据增强,包括模糊、随机亮度、对比度、色度、饱和度、随机旋转。特别地,设置随机旋转角度为[-15°,15°]。使用自适应矩估计(adaptive moment estimation,Adam)[24]进行网络优化,网络的学习率初始化为10-4,学习率每3万步下降为原来的0.1,降至10-6时不再变化。网络分类的类别数为37,包括10个阿拉伯数字,26个英文字母,1个背景。
4 实验结果和分析
4.1 自对照实验
为了方便描述,将本文进行的所有对比实验进行编号,自对照实验见表1。表1共包含8个实验,其中,实验1,2,3为不同大小的HRNet基础框架的性能比较,HRNet根据模型的大小分为了3种分割网络,分别记为hrnet-w18-v1,hrnet-w18-v2,hrnet-w48-v2;实验4,5,6在实验1,2,3的基础上分别加入了数据增强;实验7在实验6的基础上增加了字符注意力机制;实验8在实验7的基础上加入了ConvLSTM模块。在进行自对照实验时,采用了最具有挑战性的弯曲文本数据集CUTE作为测试数据,同时使用正确率(accuracy)定量评估不同因素对性能的影响。

表1 自对照实验的正确率Tab.1 Accuracy of ablation experiment
由表1可知,实验1,2,3中性能最好的为hrnet-w48-v2,相较于另外2个基础框架,hrnet-w48-v2模型较大,牺牲了部分运行时间,但获得的收益是十分明显的,正确率超过hrnet-w18-v1约18%。实验4,5,6使用本文提到的数据增强方法可以带来约2%的性能提升。基于此,本文选择了实验6即hrnet-w48-v2-aug作为后续实验的基础框架。实验7加入本文提出的字符注意力机制,可以在基础框架上获取1.3%的性能提升,充分说明了字符注意力机制的有效性。实验8引入本文提出的时空序列特征提取模块ConvLSTM,同样带来了1%的性能提升。
4.2 与现有算法的对比实验
除了自对照实验,还将本文算法跟世界领先水平的算法进行了比较,将现有的场景文本识别算法分为基于序列和基于二维视角两大类,将本文提出的算法分别跟这两大类的经典算法进行比较,实验结果分别见表2、表3。

表2 与基于序列的文本识别算法的正确率比较Tab.2 Accuracy comparison with sequence-based text recognition algorithms %
由表2可知,本文提出的算法在超过一半的标准数据集上取得了领先。现有的经典算法往往仅在某一类文本上有不错的表现,如文献[23]专门针对水平文本进行网络设计,在水平文本识别上取得了不错的性能,但无法处理倾斜甚至弯曲的文本。文献[28]专门针对不规则文本设计网络,但该算法仅在数据集SVTP上超过了本文提出算法的0.1%,在更加复杂的弯曲文本数据集CUTE上,本文提出的算法远超文献[28]。因此,与基于序列的识别算法相比,本文提出的算法能在任意方向的场景文本识别中取得非常不错的效果。
与同样基于二维视角的场景文本识别算法相比,本文提出的算法仍然取得了非常不错的成绩,见表3。

表3 与基于二维视角的文本识别算法的正确率比较Tab.3 Accuracy comparison with text recognition algorithms based on two-dimensional perspective %
文献[29]跟本文一样,使用ConvLSTM进行时空序列特征提取,由于本文额外的字符注意力机制,本文提出的算法几乎在所有数据集上的性能都优于文献[29]。文献[14]虽然也使用了字符注意力机制,但本文提出的算法在超过一半的标注数据集上的性能要优于文献[14],这得益于本文使用的时空序列特征提取ConvLSTM模块。可以看到,本文提出的算法是文献[29]和文献[14]这2个算法优势的结合。
综上,从定量的角度分析,本文提出的算法能在任意方向的场景文本识别中取得不错的效果。
4.3 实验结果
为了进一步体现本文提出算法的性能,接下来给出识别结果示意图进行定性分析。为了方便描述,将实验结果按照图8进行展示。图8是由5张图拼接而来,其中,第1张图为文本真值标注;第2张图为输入;第3张图为网络输出的概率图进行二值化后的二值图;第4张图为网络输出的概率图;第5张图为网络最终的识别结果。

图8 实验结果拼接图Fig.8 Experimental results mosaic
按照图8的实验结果拼接图,本文提出的算法在CUTE,IIIT,SVTP等数据集上的识别结果示例图见图9。图9列出的识别示例中包含了强噪声、光照不均、低分辨率等情形。图9中,第1行存在不同颜色、不同字体、不同尺寸的文本;第2行的文本均存在严重弯曲;第3行中的文本清晰度极低,肉眼都难以识别;第4—6行中的文本存在仿射变换、文本被遮挡、光照不均等问题。无论上述哪种情形,本文提出的算法均能有效识别,足以说明本文提出算法的有效性。
5 总 结
本文针对任意方向的自然场景文本提出了一种新的识别算法。在该算法中,首先使用高低分辨率分割网络进行有效的特征提取;然后使用ConvLSTM在保持二维空间信息的同时进行序列特征提取;设计字符注意机制使得模型的注意力在字符上,同时使用可微分二值化函数进一步加大网络对前景的注意力,削弱对背景区域的关注;最后使用文本转录模块将网络输出的概率图转换为文本。在多个数据集上对本文提出的算法进行测试,结果表明,该算法能对任意方向的文本进行有效识别。

图9 文本识别结果示意图Fig.9 Schematic diagram of text recognition results
本文提出的算法虽然设计了字符注意力机制,但使用的是字符框区域表示字符前景,这个字符框区域难免大于或小于真实的字符区域,造成字符注意力的引导信息不够准确,因此,可以考虑使用提供更加准确的像素级的字符区域进行前背景引导。同时,由于网络的输出是概率图,需要将概率图转录为文本,在这个过程中,本文使用的是将转录的文本按照从左到右的顺序进行排列组成最后的文本行。这样做的一大弊端是,网络无法识别上下排列的文本。因此,如何设计一个更加合理的转录模块是下一步工作需要考虑的问题。
