基于网格索引大表模型的海洋时空数据检索应用研究*
2022-03-17曲腾腾许贵林严小敏程承旗
曲腾腾 许贵林 严小敏 刘 颢 程承旗
(1.北京大学 北京 100871)(2.南宁师范大学北部湾环境演变与资源利用教育部重点实验室 南宁 530001)(3.南宁师范大学广西地表过程与智能模拟重点实验室 南宁 530001)(4.武汉数字工程研究所 武汉 430074)
1 引言
21世纪是海洋经济时代,海洋经济在各国国民经济中的地位和作用越来越突出。我党的十八届五中全会上提出,要牢固树立创新、协调、绿色、开放、共享的发展理念,并就加快转变农业发展方式以及拓展蓝色经济空间、壮大海洋经济、科学开发海洋资源等方面提出了一系列工作要求[1]。在海洋经济建设中,海洋时空大数据体系建设尤为重要。
海洋时空大数据建设依托的数据来源多、处理分析复杂、时空关联强,服务对象和服务形式也将非常广泛。当前海量海洋时空数据的存储与管理存在着数据管理形式单一、灵活性不足等问题;另外,大量海洋时空数据处理系统获取的半结构、非结构性信息难以构建高效的索引结构进行统一管理与实时调度。由此造成多源异构海洋时空数据的服务信息与集成度较弱,协同管理应用技术存在瓶颈;多源异构海洋时空数据严重缺乏高效的信息检索和集成能力以及相应的方法与工具;多源异构海洋时空数据的数据挖掘水平也普遍偏低。因此,攻关更为高效的时空检索技术,是海洋时空大数据建设亟待解决的瓶颈问题。
本文针对多源异构海洋时空大数据,依托Geo-SOT地球剖分理论[2]与北斗网格编码技术[3],利用海洋时空数据的区位编码所本身固有的空间关联能力[4],建立了与区位编码相对应的地球剖分网格索引大表模型。同一地区的不同类型海洋数据索引信息可集中存储在同一个大表单元中[5],从而实现结构化与非结构化一体、栅格与矢量一体、本地与分布式一体的剖分索引。同时该研究利用1.4亿条静态海洋环境数据开展了区域时空查询的典型实验,实验结果表明基于此项研究的海洋时空数据检索响应时间均可保证在100ms以内。由此充分验证了地球剖分网格索引大表模型可解决海洋时空大数据索引难、检索慢的问题,有望在未来进一步提高海洋时空大数据的调度和查询检索服务的效率。
2 基于GeoSOT地球剖分理论的网格索引大表模型
2.1 索引大表剖分组织结构
根据GeoSOT地球剖分网格理论,任何一个面片的编码都可以表示为〈纬向编码,经向编码〉的二元组形式,面片剖分层次隐含表示在编码之中[6]。由于这一编码方案充分考虑了与现有地图分幅方案的兼容[7],因此采用了纬向和经向两个方向进行编码。但地图分幅本质上还是为了查找数据方便而设计的,在使用计算机建立海洋数据索引时完全可以采用处理速度更快的一维面片索引码。
因此我们以面片索引码为主键(Primary Key),建立非关系型“键—值”数据库(Key-Value Store DB)[8]。非关系型的“键—值”数据库采用类似表的形式组织数据,将它们组织成一个“多维”稀疏矩阵,在逻辑上就形成了一张巨大的表。在大表模型的稀疏矩阵中,第一维采用面片索引码为行主键进行排序。第二维定义为属性组,一个属性组是包含多属性列的集合,它们一般具有类似的属性,系统在存储和访问表时,都是以属性组为单元组织。第三维即属性列,理论上,一个属性组中属性列的个数不受限制,属性列的命名方式通常采用“属性组:属性列”的方式。
由此,我们设计了如图1所示的剖分数据统一组织结构。整个存储框架下有许多数据表,数据表的主键是某一层级的GeoSOT编码[9],与实际三维空间中的某一个体块唯一对应。同时由于空间编码具有递归性、唯一性、一致性、有序性的特征,该编码可直接作为数据库索引进行检索查询。每一行数据中记录了原始数据的各类信息,例如类别、用途、物理属性等。这种存储方式能够在一张表上方便地表达出同一空间位置上不同来源、不同类别的数据信息。
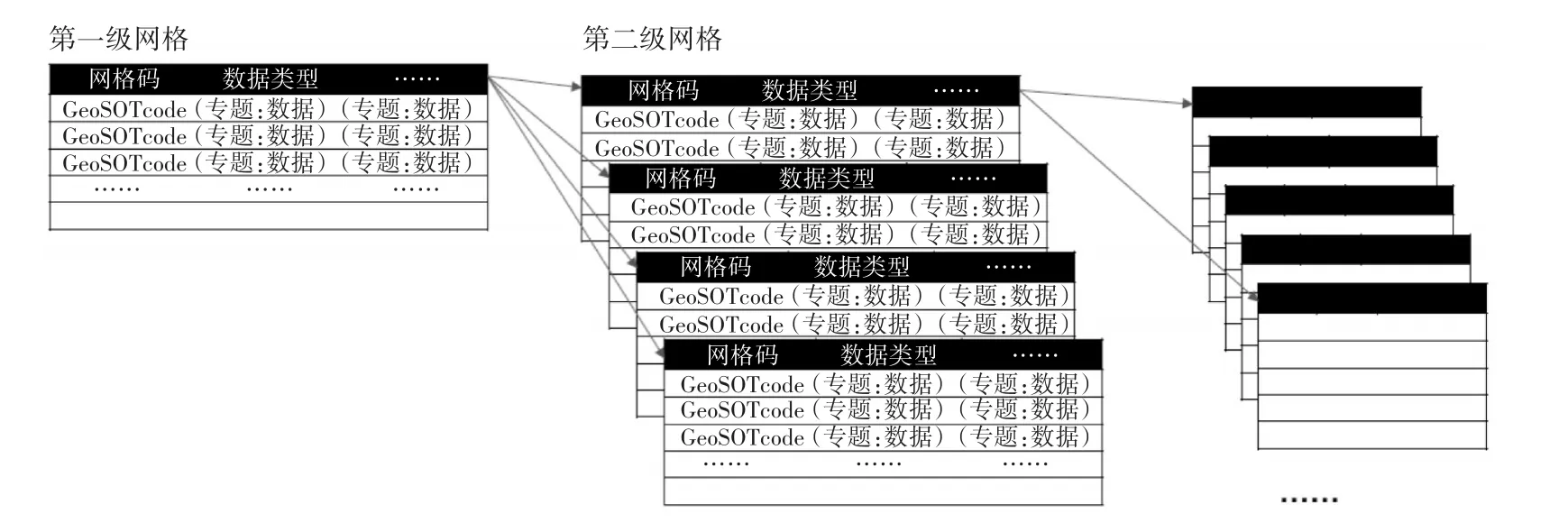
图1 剖分数据统一组织结构
由于空间范围较大时或者选取网格尺度较为精细时网格编码数量激增,不利于存储管理,同时考虑到海洋时空大数据对于多尺度的需求,我们选取“分表”的策略来对逻辑结构进行完善。每一个表都只存储某一层级的编码所对应的数据。每一个父编码都保留对其下一层级子编码所在的数据表的指针。这样在该父编码进行查询之后,如果需要进一步精细查询,能够直接对应到其他表中的子编码所在的数据表。同时,表与表之间的大小可以保持基本统一,有利于实现分布式管理,在应对超大规模和高并发的需求时能够保持负载均衡,提高效率。
2.2 多源数据表逻辑结构
本文对多源海洋时空数据集中每一个基础地理要素(点、线、面)或每一景影像或每一数值场区域添加一个全球唯一的标识码,将GeoSOT编码和海洋数据的原始数据属性值构成一条数据记录。海洋数据通常是不规范的结构化数据,对多源数据的检索往往是多属性检索。本文根据每一类海洋数据的属性特征,分别设计如下表所示的逻辑结构视图,在实际应用中也可以直接利用某类数据原有的数据结构表,只需增加一个如表1所示的“Geo-SOTcode”编码列即可。

表1 海洋数据的数据表逻辑结构(以遥感数据为例)
由此可见,我们设计的海洋数据逻辑结构一般由三部分组成:GeoSOTcode编码、Column key和详细属性列。以遥感数据为例,其中GeoSOTcode编码是索引的主键;Column key列的SatelliteID是遥感数据的卫星编号;属性列包含遥感数据的其他属性信息。
海洋数据剖分索引大表是实现海洋数据元数据索引功能的形式,是指在现有的数据层之上添加海洋数据剖分索引大表来实现从GeoSOTcode编码到数据层中的数据标识之间的转化,通过数据标识来定位查询数据的存储位置实现数据查询的技术[10~11]。通过该技术,可以实现不同数据中心之间海洋数据元数据的统一查询,并能够在数据中心内部支持关联查询和拓扑查询。其核心思想是针对海洋数据的时空信息,即GeoSOTcode编码建立主键索引,然后在剖分索引大表的属性列上建立二级索引。第一级索引是GeoSOTcode编码索引,即对空间对象的区域位置和时间进行检索,第二级索引是对海洋数据的属性列建立索引达到多条件检索。给定一个GeoSOTcode编码,通过第一级索引就可以找到网格内某段时间范围内的所有数据。通过第二级索引,可以进一步筛选出符合要求的数据。
2.3 索引大表优化与分裂后索引大表组织
随着数据量的增长,以及不断有新数据插入,海洋数据剖分索引大表会不断增长。当该表增长到一定大小时,可设置剖分索引大表的最大容量,保证海洋数据索引大表的结构不变的情况。计算机按照先前设计的规则自动分裂剖分索引大表,即一分为二,然后把分裂后子索引大表由其它的主机维护,分裂后的表可以独立增长,再进行分裂,如此反复。由于分裂出来的子表被分布在不同的主机上维护,对大表的操作演化成对各子表的操作,处理效率显然高于对整个大表的操作。又因为网格索引码行键按照八叉树遍历的Z序排列,即位置相邻网格被尽可能地组织在相同或相邻的子表中,从而保证了数据访问效率。
在海洋数据剖分索引大表中,索引数据在存储前经过了排序和压缩,各类属性信息都被连接为字符串并按照属性列的字典序排列。某一张大表在它的生长过程中会分裂为许多子表,新产生的子表可以被指定到任意主机上维护。为了快速地找到子表所在位置,我们还设计了一个描述子表索引的全局元数据表,负责保存和维护系统中所有子表的索引。在索引大表基础上,以GeoSOT提供的八叉树编码索引(O-tree索引[12])为主体,将R树索引嫁接在上面,形成一种新型高效的空间索引结构——GeoSOT剖分索引。
该索引是以 O-tree索引为主枝,将 R-tree[13]嫁接到上面,形成一棵混合的树型结构。这种方式的核心是将一颗大的R-tree分解成若干小的R-tree,将每一棵小的R-tree嫁接到O-tree的对应枝上,这样,合成的O&R-tree一方面保持了O-tree固定空间索引的优势,另一方面,将那些无法用固定网格管理的空间对象(跨网格的对象)用R-tree管理起来。还有就是,新形成的O&R-tree在每个O-tree节点上,生成了一棵小的R-tree,将大的整体复杂的R-tree分散在小范围内管理进行管理,理论上,对于R-tree的任意一枝理论上都可以嫁接到O-tree上,最极端的情况,某一枝也可以隶属于O-tree的根节点。
3 海洋环境数据检索典型实验
3.1 实验环境与实验数据
3.1.1 实验环境
1)硬件环境
本实验使用5台计算机,其中1个作为Master节点,剩余4个作为Slave节点。单台计算机配置如表2所示。

表2 单台计算机硬件环境配置表
2)软件环境
本实验部署了分布式HBase环境,每台计算机安装软件版本如表3所示。

表3 单台计算机软件环境配置表
3.1.2 实验数据
为了验证地球剖分网格索引大表模型对海洋时空数据检索的有效性,实验中使用了包含少量基础海洋地理信息数据和1.4亿条不同大小的仿真遥感元数据的静态海洋环境数据。
其中海洋地理信息数据包括广西龙门港区域的基础地理信息数据、某海洋环境数值预报数据(海温、海浪、洋流、DEM等)、卫星元数据(MODIS、Landsat等)和气象预报数据(降水量、温度、风速等)。详细数据源文件总结如表4所示。

表4 实验使用海洋地理信息数据源表
此外为了扩充数据量至亿级,以验证剖分索引大表模型在海量数据一体化组织与管理中的有效性,我们另外增加了模拟遥感元数据。模拟数据随机生成了1亿条全球范围不同区域、小于1°×1°空间范围的遥感数据,4000万条全球范围不同区域、大于1°×1°空间范围的遥感数据,从而模拟各类遥感元数据,总原始数据记录数量共1.4亿条。模拟遥感元数据的生成步骤如下:
1)随机生成一个坐标(left,down),left的取值范围是[-180°,180°),down的取值范围是[-90°,90°)。
2)随机生成沿东西方向的长度length和南北方向的长度width。在生成大于1°×1°空间范围的遥感数据时,length和width均小于5°;在生成小于1°×1°空间范围的遥感数据时,length和width均小于1°。
3)根据生成的left和length计算right=left+length,如 果 right>180°,则 right=right-360°;up=down+width,如果up>90°,则up=90°。
3.2 基于静态海洋环境数据的时空范围查询试验
本文分别采用数据记录ID、经纬度与时间戳、空间编码和时空编码分别作主键索引的方式对同一时间跨度内不同空间尺度的区域进行区域时空查询实验,以验证基于时空编码的剖分索引大表模型在时空数据查询中较其他方式的有效性,结果如表5所示。
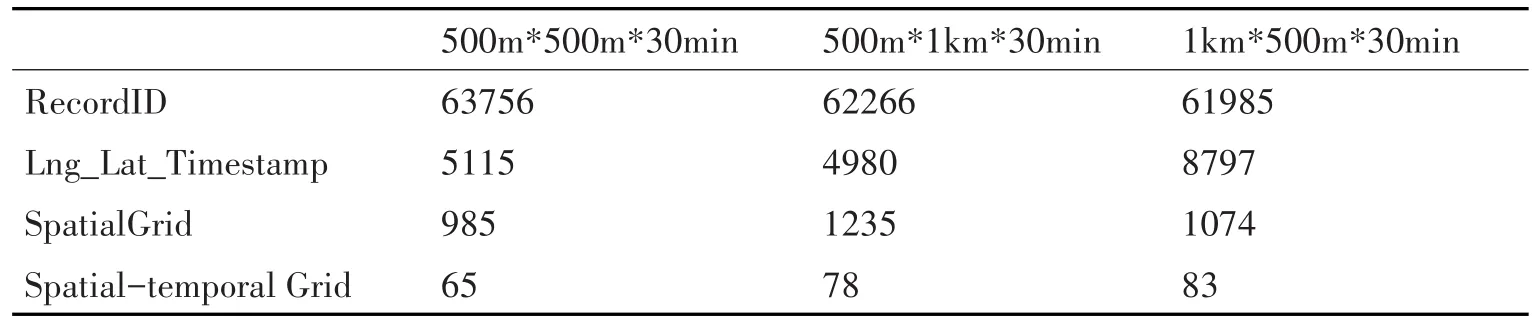
表5 不同条件下的时空范围查询实验结果(单位:ms)
由表中实验结果可知,基于时空编码剖分索引的区域查询方法效率最高,相较于现有方法:比基于记录ID的方式可提升近百倍,比基于经纬度加时间戳的方式,提升约数十倍,比基于空间网格编码加时间的方式,提升约五至十倍。特别是在常用的空间范围公里(km)级,时间范围分钟(min)级的时空检索范围前提下,基于时空编码剖分索引的区域查询效果能够满足检索响应时间均保证在100ms以内,显现出了优越的时空数据检索性能。这主要是因为:
1)面向空间组织管理的剖分索引规模控制优势:针对海洋环境数据组织的时空编码方法直接面向空间管理而非面向数据对象管理,尽管遥感数据规模在1.4亿条级别,但其对应的空间范围是全球的,对应的某一层级剖分网格数量也是固定的。剖分索引大表的规模根据选择的剖分层级不同存在变化,但数据规模始终远少于原始数据记录亿条级别的体量,常常表现为千万甚至百万级别,因而在时空检索中剖分索引大表有更少的索引主键,也具有更好的时空检索效率。
2)分布式数据组织框架的并行化优势:将海洋环境数据部署在多个服务器节点上,不仅使数据组织管理框架具有更好的可扩展性,而且在数据检索中通过多节点并发的任务执行手段也能够充分利用各服务器的计算性能,进一步凸显剖分索引数据组织的效率优势。
4 结语
本文面对多源异构海洋时空大数据缺乏高效时空检索技术的瓶颈问题,依托GeoSOT地球剖分理论建立了地球剖分网格索引大表模型,阐述了索引大表剖分组织结构、多源数据表逻辑结构以及索引大表优化与分裂后索引大表组织方法。同时利用1.4亿条静态海洋环境数据开展了区域时空查询的典型实验,以验证剖分网格索引大表模型对海洋时空数据检索的有效性。实验结果表明在亿条数据规模下,海洋时空数据检索耗时可达毫秒(ms)级,从而验证了分布式环境下的剖分索引大表在海洋时空数据检索中的高效性。
本文虽然在面向海洋时空大数据组织检索研究上取得了新的进展,但实际应用中仍有很多不足需要进一步研究改进:本文所提出的索引模型尚需要通过反复试验和验证,从实验室环境下的模拟数据测试,到海洋现场环境下的实地测试,随着应用场景不断接近真实,理论、方法与技术也需要随之不断地改进和完善,使之更稳定有效。
