基于NLP的大学生自主学习智能问答系统设计
2022-03-16谷宗运殷云霞
谷宗运,汪 庆,殷云霞
安徽中医药大学 医药信息工程学院,安徽 合肥 230012
近年来,学校教育正面临着由规模化向个性化、信息化到智能化的过渡和转变,智能教育得到国家和教育行业的高度关注。2019 年国务院印发《中国教育现代化 2035》,提出了智能教育发展的战略任务,旨在推进智能教育以及相关应用的发展。随着大数据与人工智能技术的进步,“互联网+教育”发展取得了明显成效,并在新冠病毒疫情防控期间发挥了重要教学服务作用。自新冠病毒疫情以来,许多高校都在积极探索“互联网+教育”的在线教学及线上线下混合式教学等新教学模式。这类新型教学模式的推广与应用,对大学生的自主学习能力及信息获取能力要求非常高。
在自主学习过程中,学生遇到问题时通常会通过搜索引擎来查找答案,具体的方法是在浏览器上输入问题搜索答案。这种方法存在两个问题:一是从网上庞大的冗余信息中,提取到自己所需要的答案,会耗费一些时间和精力,影响自主学习进程;二是很多时候搜索引擎不能正确理解用户语义,搜索的结果与学生想要的结果相去甚远,虽耗费了时间和精力,但一无所获。对于自主学习过程中遇到的问题,如果不能实时、精准、有效地解决,不仅会降低学生的自主学习质量还会打击他们的自主学习积极性。智能问答系统(question answering system,QA)[1]是信息检索系统的一种高级形式,它能用准确、简洁的自然语言回答用户用自然语言提出的问题,已被广泛应用在医疗[2]、农业[3]、文旅[4]、教育[5]等领域。智能问答系统能在一定程度上解决传统引擎存在的问题,推进智能教育的发展。
智能问答系统可以为学生提供更加精准的信息服务,故研究智能问答系统具有重要的现实意义。而智能问答系统关键是问答模型的设计与实现,基于此本工作的重点是利用大数据及NLP技术设计并训练智能问答模型。具体的内容包括以下几个方面:先对选用的公开数据集进行数据预处理,以适用模型的训练;接着设计基于BERT的智能问答模型,并用预处理数据对模型进行训练;最后测试模型并分析结果。本文的主要贡献有如下三点:1)用智能问答系统解决大学生自主学习问题;2)用自动生成答案的方式实现智能问答系统;3)把BERT技术应用到智能问答系统任务中,并显著提高了智能问答系统性能。
1 智能问答系统相关工作
智能问答系统实现算法主要分为两类[6]:一类是文本匹配式(如图1所示),其主要方法是基于问答数据集训练问题-答案匹配模型,通过问题相似度来找到符合的答案并自动回答,该方法的答案具有合理性、正确性、严谨性等优点。但文献[7]中指出由于需要对问题库里面的所有的问题进行检索,执行速度会随着问题库规模的增大而降低,所以该方法在大规模问题库中找到符合的答案是困难且耗时的。另一类是文本生成式(如图2所示),其主要方法是用数据集训练一个答案生成模型,根据用户问题自动生成答案文本,该方法具备真正意义上的智能问答,已逐渐成为智能问答研究主流方向。
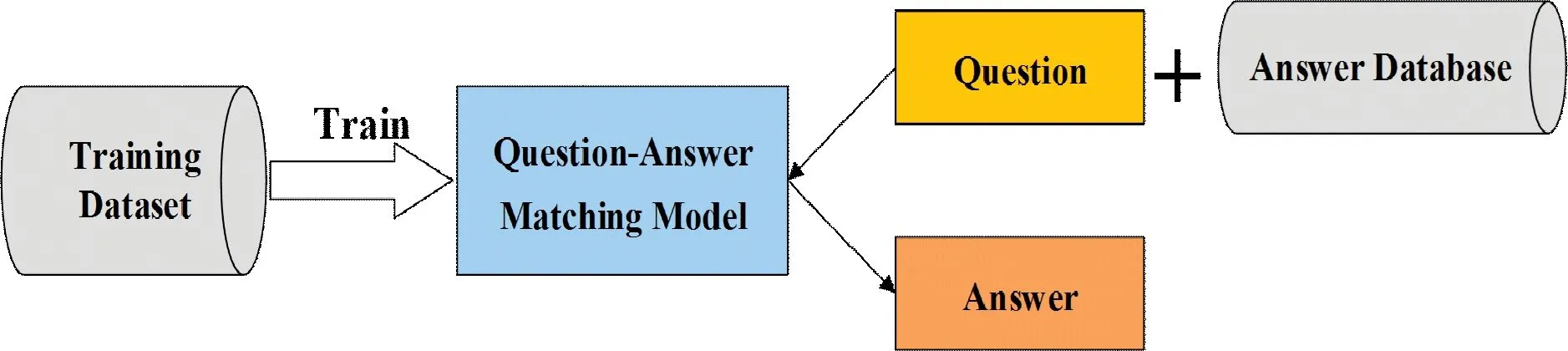
图1 文本匹配式智能问答算法流程
在智能问答模型实现上,预训练的神经网络语言模型受到越来越多的关注。随着ELMo(embeddings from language models)[8]、OpenAI GPT(generative pre-trained transformer)[9]及BERT[10]等预训练模型提出,预训练取得了显著进展。BERT模型采用了多层自注意力机制 Transformer 结构[11](如图3所示),通过加深网络的方式增强对文本信息的挖掘能力。另外,BERT 基于无监督的语料数据进行学习的,可以减少数据搜集和人工标注的成本。基于这些优势,BERT模型被广泛应用到各类具体的NLP任务中,并且已经被证明在许多NLP任务中是相当有效的。
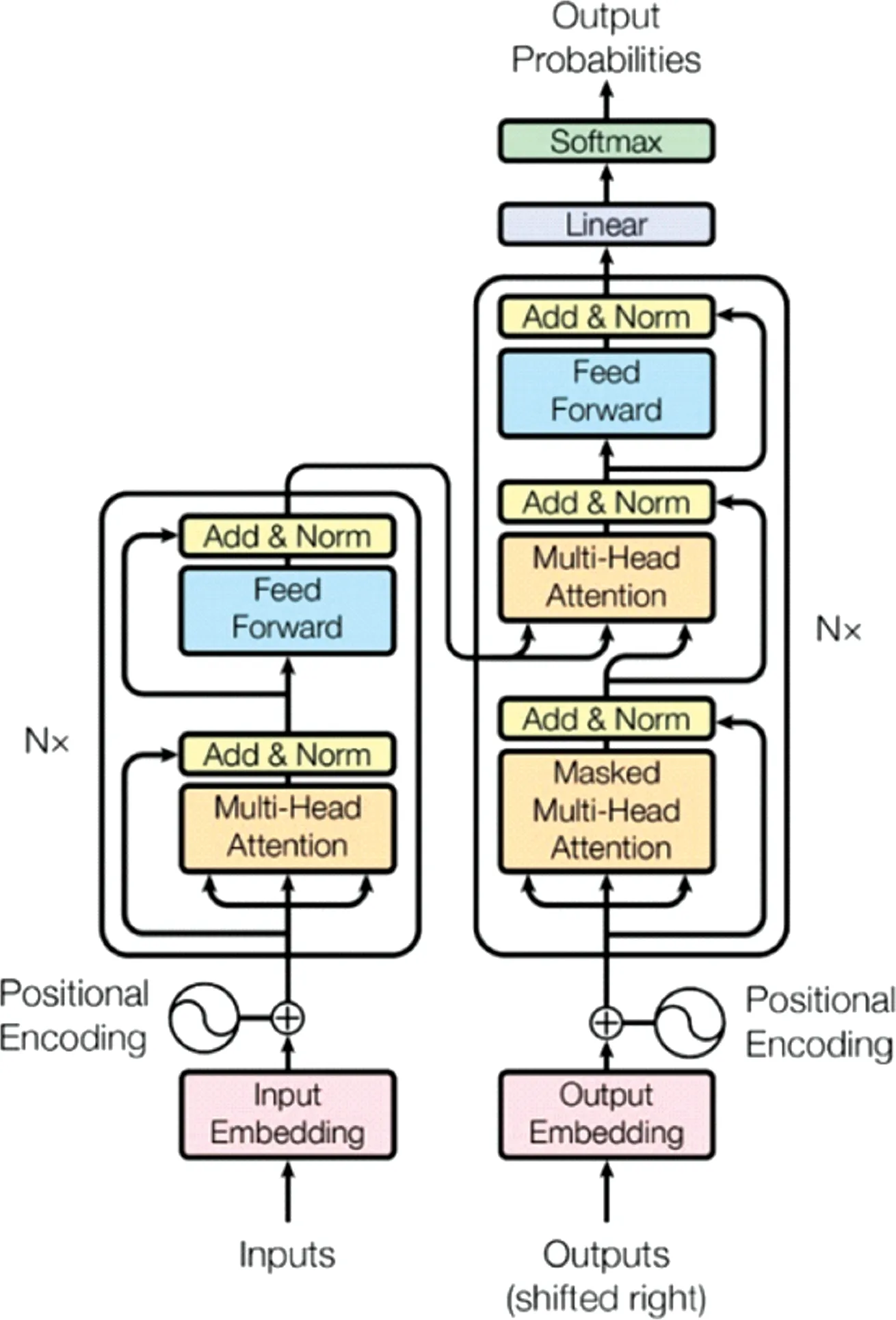
图3 Transformer模型网络架构
2 自主学习智能问答模型设计
文献[12]提出了一种BERT融合模型(BERT-fused model),并通过实验得出“简单使用BERT初始化NMT的编码器效果不好,将BERT作为特征在NMT中更有效”的结论。采用BERT-fused的做法,自主学习QA模型由BERT模型和改进的NMT模型组成,其中NMT与标准NMT[13]一样由encoder layer和decoder layer组成,但在标准NMT基础上增加了BERT-encoder和BERT-decoder两个注意力模块。自主学习QA模型整体架构如图4a)所示,输入Question序列后,首先被转换成由图4b)模块[10]处理的BERT表示。然后,通过BERT编码器注意模块,每个NMT的encoder layer(图4c))与从BERT获得的表示进行交互,并最终输出利用BERT和NMT编码器的融合表示。NMT的decoder layer(图4d))工作原理与之类似,它也融合了BERT表示和NMT编码器表示。

注:a)模型整体网络架构;b)BERT模型网络架构;c)encoder layer网络架构;d)decoder layer网络架构。
自主学习QA算法具体步骤如下所示:
Step1:输入Question序列χ;
Step2:将χ转换成BERT的表示,即给定一个任意x∈χ输入到BERT预训练模型中,得到表征输出HB=BERT(x);
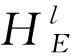

FFN(χ)=max(0,W1χ+b1)W2+b2, (2)
这里会得到第l层的输出值为式(3):
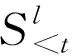

Step5:遇到句尾标识符解码过程终止,输出Question。
3 实验与结果分析
3.1 实验数据集
由于笔者所在学校为医药类院校,医学生占主体地位。所以笔者先从医学类开始,训练医学智能问答系统供临床专业学生自主学习用。为了训练和测试模型,使用了中文医学问答数据集cMedQA2[14]。该数据集问题是中国医学问答在线论坛用户的问题或症状的描述,答案是医生相应的回答或诊断建议。在训练模型前,通过进一步整合数据为问答对的形式对这个数据集进行了预处理。最终数据共包含226 267对中文医学问答。模型训练时,采用随机划分数据集的方法,将数据集中的70%划分为训练集,20%划分为验证集,剩余的10%为测试集。
3.2 实验方法
设定NMT模型的嵌入尺寸为512,FFN层为1 024,共六层。BERT-fused模型的encoder和decoder模块的参数使用随机初始化。使用Adam作为我们的优化算法,其中设置第一个transformer block 的learning rate=2×10-5,按照1/0.95的速率增长,越深层学习率越大。使用束搜索算法并设置宽度和长度惩罚因子分别为5和0.8,dropout设置为0.1。
3.3 实验结果
为了评价模型的结果,我们引入NLP中常用评测指标BLUE(Bilingual Evaluation Understudy)。它可以计算机器翻译译文与参考译文之间的相似度,算法思想是机器翻译的译文越接近人工翻译的结果,其翻译质量就越高。对于模型在cMedQA2数据集训练后的测试结果,使用BLUE来评价模型生成回答任务,BLUE值越高则代表预测的回答越接近于给定的真实值,测试结果如表1所示。通过研究近几年的智能问答系统现状,本文选取了几种主流的方法进行对比分析。从表1中可以看出BERT-fused模型效果表现最好,这表明了BERT-fused模型在自主学习QA任务上的优越性。
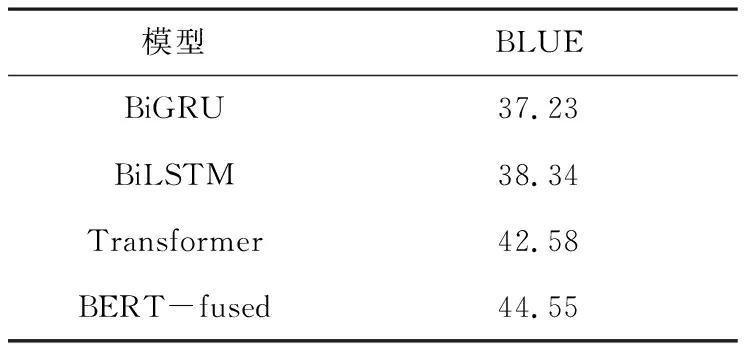
表1 模型在测试集上的BLUE值
为了更直观的观察BERT-fused模型的表现,表2列举了部分cMedQA2测试集中的预测样例。问题(Q)表示输入encoder的问题,真实值答案(A)表示问题对应的真实答案,预测值答案(A)表示模型预测的答案,即decoder输出的内容。从表2可以看出:模型生成答案的表述基本是通顺的;对于同一问题,预测值的表达意思基本与真实值相符;但长语句中还存在语句不通顺和错别字的情况,初步分析是训练样本量不够大,fine-tune的效果还没达到最优。

表2 模型在cMedQA2测试集上的预测样例
4 总结与展望
智能问答系统可以实时、精准、有效地解决大学生自主学习过程中遇到的学习问题,能有效提高大学生的自主学习积极性和自主学习中解决问题的处理效率,在解决大学生答疑方面具有较高的使用价值。本文基于NLP技术,融合BERT模型,设计了能自动生成答案的自主学习智能问答模型。针对医学生临床上经常会遇到的问题,在中文医学问答数据集cMedQA2上进行模型的训练和测试,实验结果比其它模型性能优越。通过对模型的输出结果可视化研究,发现在生成的长语句Question中还存在语句不通顺和错别字的情况。在未来的研究工作中尝试从数据、layer等层面改进,如对于问答中的超长文本,尝试用不同的截断处理;继续用下游任务对标的语料继续pretrain,然后再fine-tune以提升性能;尝试用不同层的输出做concat,各种交叉组合完成下游任务等。为了使自主学习智能问答系统具有更大的应用价值,解决不同学科的大学生自主学习问题,下一步工作我们将进一步扩大训练数据,并将常识性知识也融入系统中。
